Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
2,163 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAP%3C/text%3E%3C/svg%3E)
This works,
df = pd.read_csv('/dbfs/mnt/ajviswan/forest_efficiency/2020-04-26_2020-05-26.csv')
sdf = spark.createDataFrame(df)
sdf.head()
But spark read does not work.
df = spark.read.csv('/dbfs/mnt/ajviswan/forest_efficiency/2020-04-26_2020-05-26.csv')
df
Returns an error,
Py4JJavaError: An error occurred while calling o3781.csv.
: java.lang.NoClassDefFoundError: org/apache/spark/sql/sources/v2/ReadSupport

Hello @Ajay Prasadh Viswanathan ,
Welcome to Microsoft Q&A platform.
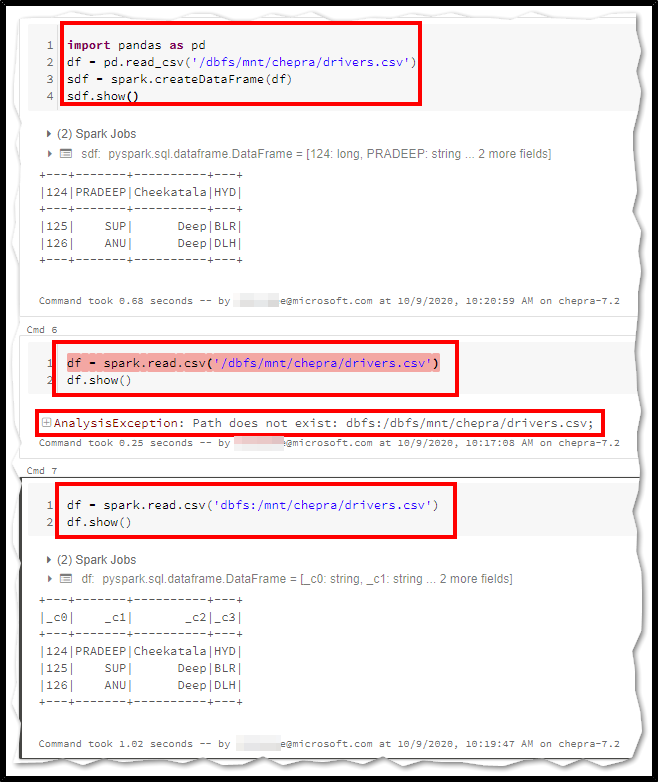
To read via spark methods from mount points you shouldn't include the /dbfs/mnt as /dbfs/mnt/ajviswan/forest_efficiency/2020-04-26_2020-05-26.csv prefix, you can use dbfs:/mnt as dbfs:/mnt/ajviswan/forest_efficiency/2020-04-26_2020-05-26.csv instead.
Hope this helps. Do let us know if you any further queries.
----------------------------------------------------------------------------------------
Do click on "Accept Answer" and Upvote on the post that helps you, this can be beneficial to other community members.
Hi, that does not help. I still have the error.
df = spark.read.csv("dbfs:/mnt/ajviswan/CPUPrediction/CPUPrediction_2020_09_17.csv")
gives
java.lang.NoClassDefFoundError: org/apache/spark/sql/sources/v2/ReadSupport
.
Some more strange things,
I can read the head of the file from shell,
%sh
head /dbfs/mnt/ajviswan/CPUPrediction/CPUPrediction_2020_09_17.csv
works and I see the contents of the file. I am using databricks and cosmos gen1. It looks like an issue with spark in databricks.
Hello @Ajay Prasadh Viswanathan ,
In order to investigate further, could you please help me understand, how you have mounted Cosmos Gen1?
Hello @PRADEEPCHEEKATLA-MSFT , I have commented my mounting code in the other thread.
Hello @PRADEEPCHEEKATLA-MSFT ,
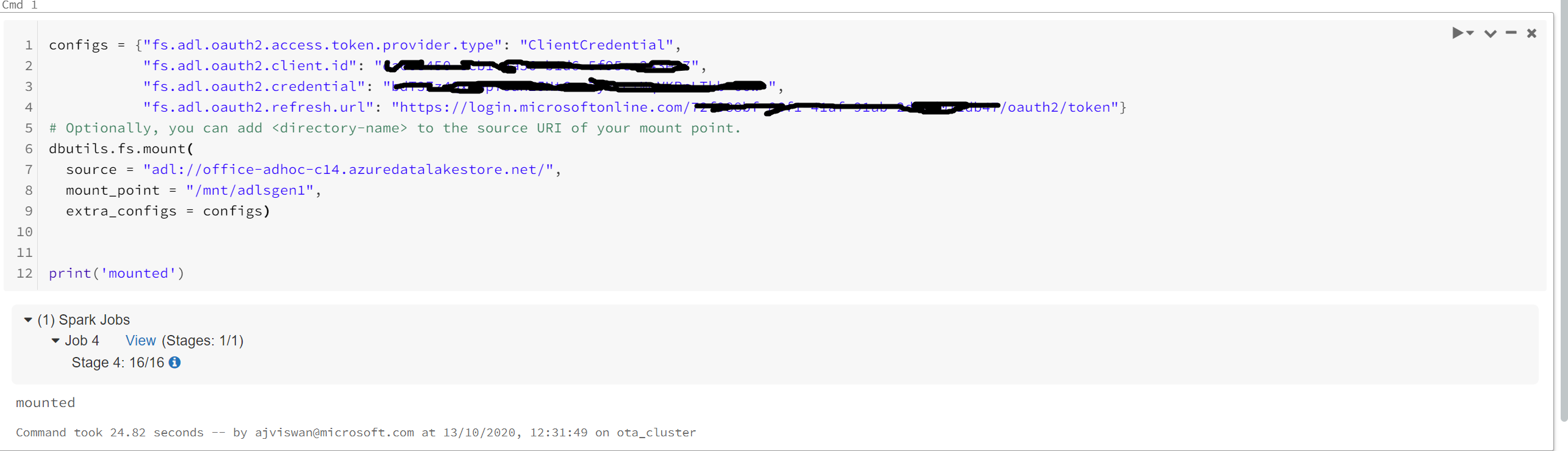
Yes I have mounted the dataset,
configs = {"fs.adl.oauth2.access.token.provider.type": "ClientCredential",
"fs.adl.oauth2.client.id": "xxxx",
"fs.adl.oauth2.credential": "xxxxx",
"fs.adl.oauth2.refresh.url": "https://login.microsoftonline.com/xxxx/oauth2/token"}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "adl://office-adhoc-c14.azuredatalakestore.net/local/users/ajviswan",
mount_point = "/mnt/ajviswan",
extra_configs = configs)
print('mounted')
After mounting, I can read the data via python and the bash terminal.
pd.read_csv("/dbfs/mnt/ajviswan/CPUPrediction/CPUPrediction_2020_09_17.csv")
works,
%sh
head /dbfs/mnt/ajviswan/CPUPrediction/CPUPrediction_2020_09_17.csv
also works.
But the spark read does not work,
df = spark.read.csv("dbfs:/mnt/ajviswan/CPUPrediction/CPUPrediction_2020_09_17.csv")
I get, Caused by: java.lang.ClassNotFoundException: org.apache.spark.sql.sources.v2.ReadSupport
Cluster configuration is,
7.3 LTS (includes Apache Spark 3.0.1, Scala 2.12)
Hello @Ajay Prasadh Viswanathan ,
I have tested on Azure Databricks Runtime: 7.3 LTS (includes Apache Spark 3.0.1, Scala 2.12).
To mount an Azure Data Lake Storage Gen1 resource or a folder inside it, use the following command:
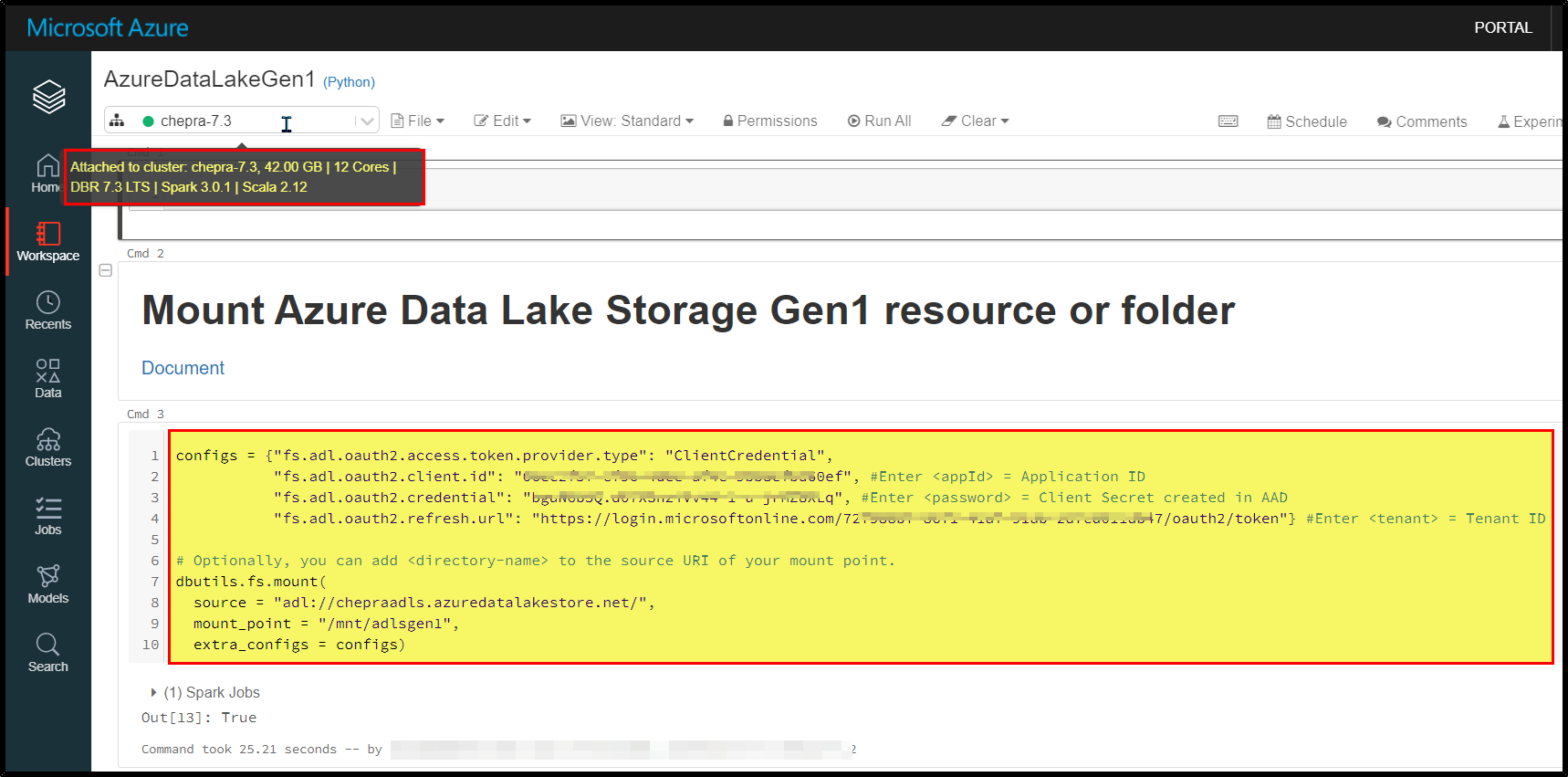
And able to read via spark methods from mount points.
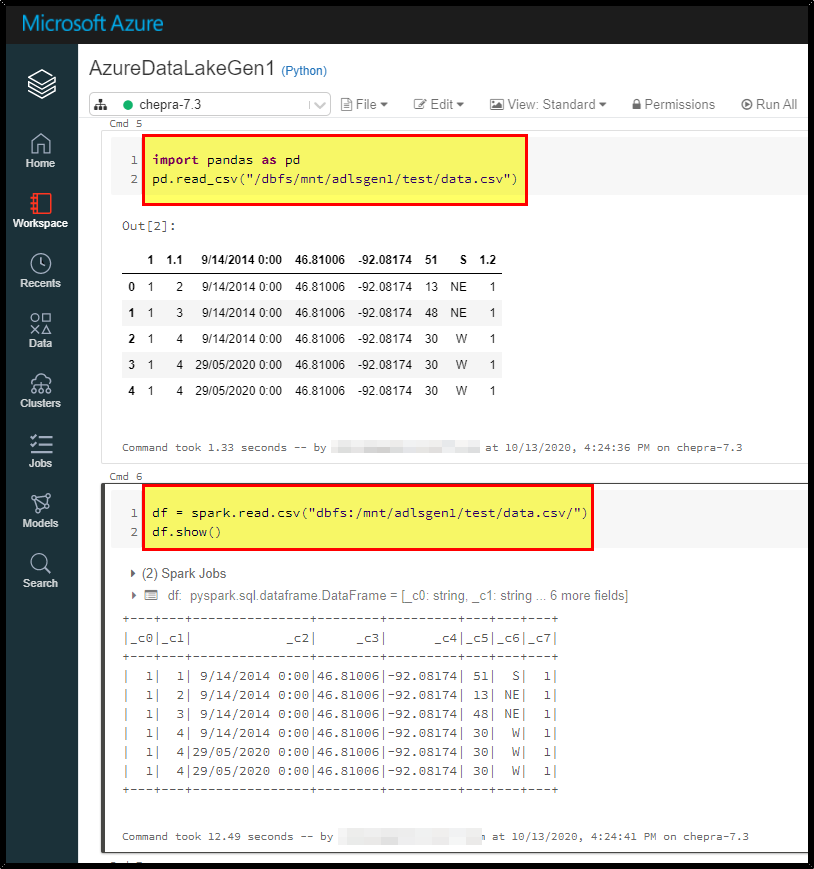
Reference: Azure Databricks - Azure Data Lake Storage Gen1
Hope this helps. Do let us know if you any further queries.
----------------------------------------------------------------------------------------
Do click on "Accept Answer" and Upvote on the post that helps you, this can be beneficial to other community members.
Hi @PRADEEPCHEEKATLA-MSFT , I have followed the instructions exactly.
I mounted correctly.
I am able to read the data through python.
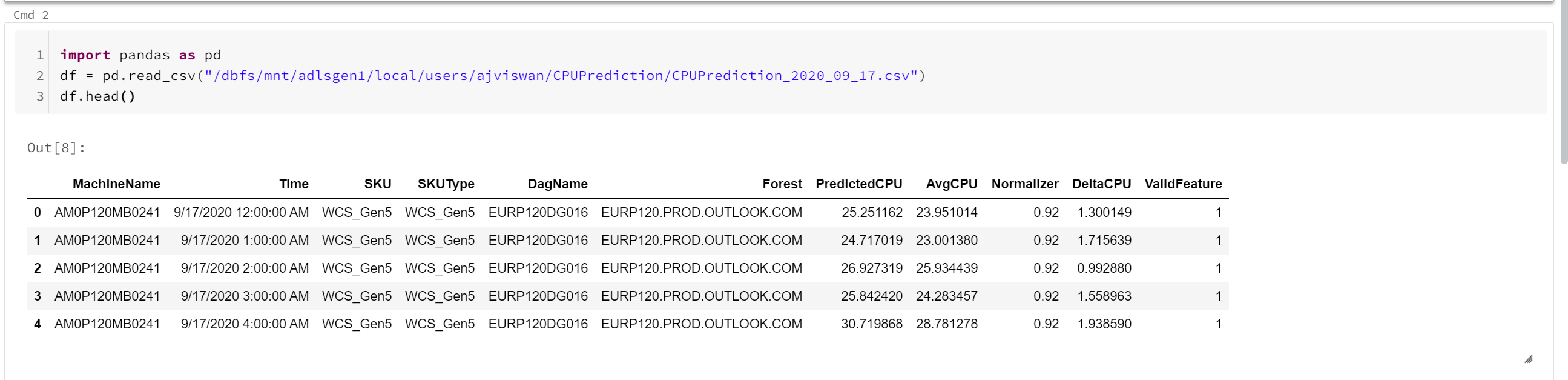
I am unable to read it through spark.
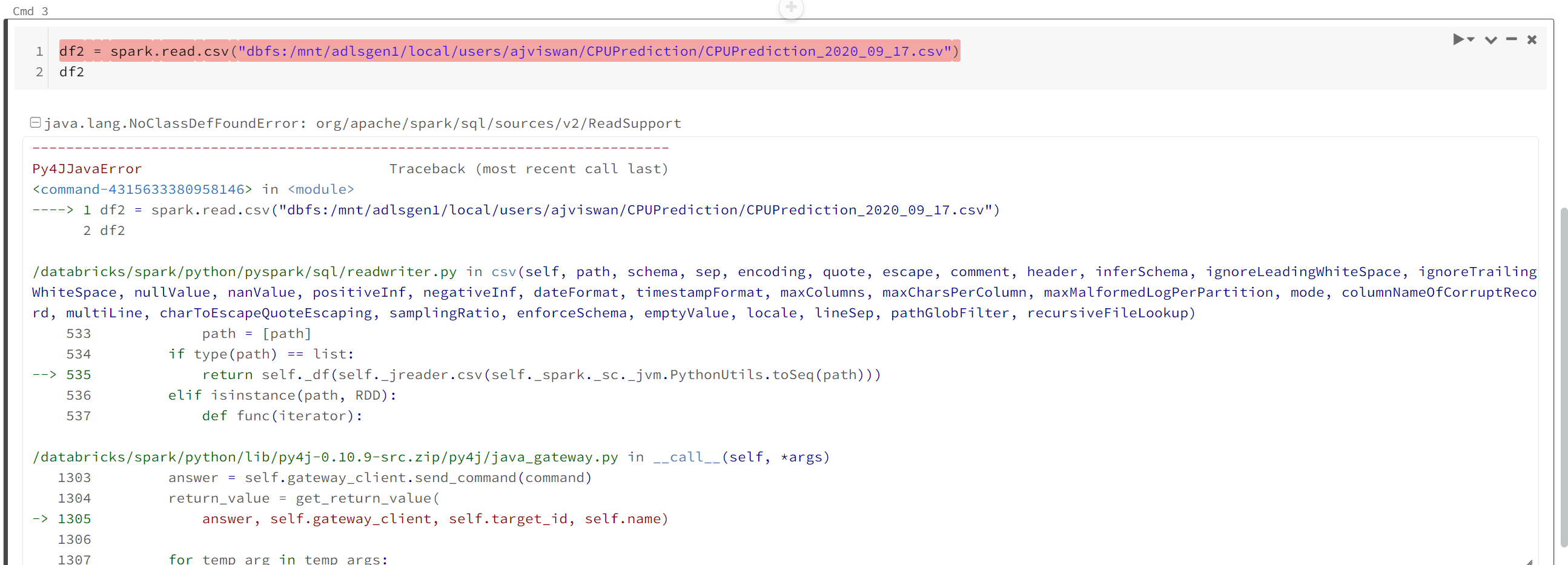
My data is in AAD wall in cosmos adls1 accessible from an aad account(ajviswan_debug@prdtrs01.prod.outlook.com), my databricks is in under a corpaccount(ajviswan). My intuition is that if it was a mounting related issue, it should have complained when I tried mounting. I should not have been able to read through python if it was a data mounting issue. But I can read through python and not through spark, it seems like I am missing something big. It would be really great if you can help me and my team with this.
Hello @Ajay Prasadh Viswanathan ,
This issue looks strange. For a deeper investigation and immediate assistance on this issue, if you have a support plan you may file a support ticket.
Thank you for the help @PRADEEPCHEEKATLA-MSFT . I have created a report through my azure portal. I will close this for now and post updates if it is resolved.