Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article delves into the internals of high availability (HA) and cross-region disaster recovery (DR) for Azure DocumentDB, outlining the design and capabilities of these features. It provides insights for effective in-region and cross-region strategy planning to ensure reliability and business continuity.
Azure DocumentDB cluster anatomy
An Azure DocumentDB cluster is composed of one or more horizontally scaled physical shards (nodes). Each physical shard includes dedicated compute resources and remote premium SSD storage. The compute and storage resources of a physical shard are exclusive to a single database and not shared across clusters or databases.
In clusters with multiple horizontally scaled shards, every shard has an identical compute and storage configuration. Regardless of the number of shards, all cluster resources are hosted within the same Azure region.
Azure DocumentDB uses locally redundant storage (LRS), ensuring all data is synchronously replicated three times within the cluster's physical location. Azure Storage transparently manages these replicas, verifies data integrity using cyclic redundancy checks (CRCs), and repairs any detected corruption using redundant data. Additionally, checksums are applied to network traffic to prevent data corruption during storage and retrieval.
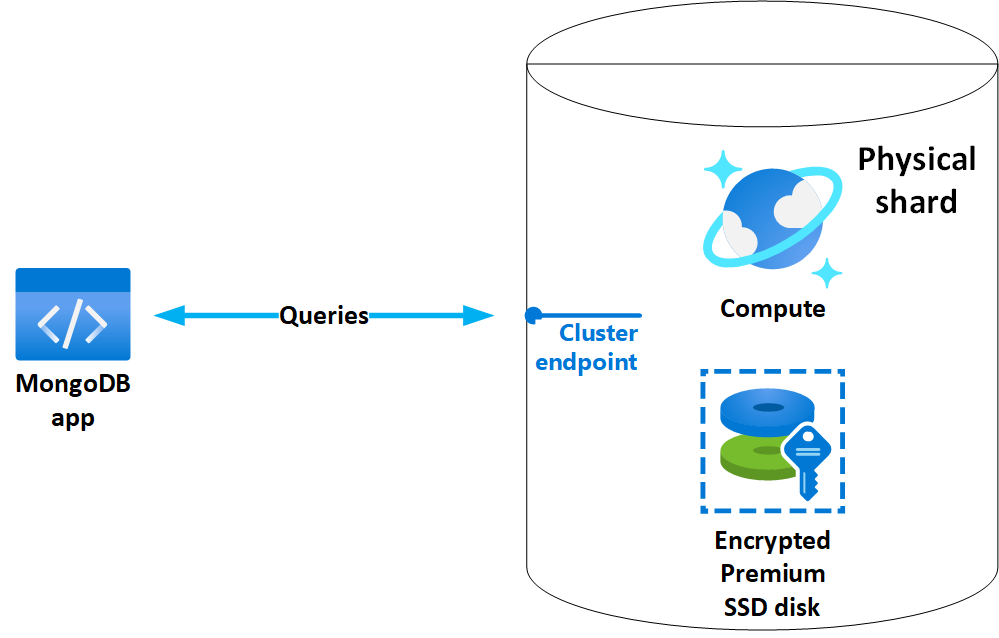 Figure 1. Azure DocumentDB cluster components.
Figure 1. Azure DocumentDB cluster components.
Whether your application connects to a single shard or multishard cluster, it uses a single connection string and endpoint. This abstraction simplifies distributed database operations, making it as straightforward to connect to a multi-shard setup as to a standalone MongoDB database.
In-region high availability (HA)
For production workloads, it is highly recommended to enable in-region high availability (HA) to meet modern reliability standards. While HA can be disabled for development or experimental clusters to reduce costs, it is critical for maintaining database availability in production.
HA can be toggled during cluster provisioning or at any time after the cluster is created. It is available in all Azure regions that support Azure DocumentDB, regardless of specific regional capabilities.
When HA is enabled, each primary physical shard in the cluster is paired with a standby shard. The standby shard mirrors the compute and storage configuration of its primary counterpart. This results in six data replicas per shard—three on the primary shard and three on the standby. In regions with availability zones (AZs), primary and standby shards are deployed in separate zones.
Data is synchronously replicated between each primary and standby shard. Writes are acknowledged only after being successfully committed to both shards, ensuring strong consistency within the HA cluster. In other words, a standby physical shard is an always up-to-date full replica of its primary physical shard providing strong consistency within the highly available cluster.
 Figure 2. Azure DocumentDB cluster with and without in-region high availability (HA) enabled.
Figure 2. Azure DocumentDB cluster with and without in-region high availability (HA) enabled.
In the event of a primary shard failure, the service automatically performs a failover to its standby shard. During failover, all read and write requests are redirected to the standby shard, which becomes the new primary. Write operations in progress during the failover are retried within the service to ensure continuity. A replacement shard is then created to re-establish synchronous replication, becoming the new standby.
Cross-region replication: Regional disaster recovery (DR)
Although rare, regional outages can disrupt access to your database. Cross-region replication provides a robust disaster recovery (DR) strategy, ensuring access to your data even during large-scale disruptions.
With cross-region replication, you can create a replica cluster in a different Azure region. Each shard in the replica cluster asynchronously replicates data from its counterpart in the primary cluster. This replication model ensures eventual consistency while minimizing performance impact on the primary cluster.
Asynchronous replication avoids the need for each write operation to be immediately delivered to and confirmed by replicas before a "write complete" acknowledgment is sent back to the application. However, this means that some writes completed on the primary cluster may not yet be replicated to the replica cluster, resulting in replication lag. The extent of replication lag depends on the intensity of write operations on the primary cluster and the overall load on both the primary and replica clusters.
In this setup:
- The primary cluster in Region A handles all reads and writes.
- The replica cluster in Region B supports read-only access, enabling high-performance read operations closer to applications or users in that region.
Applications can perform OLTP queries on the primary cluster in region A and intense read operations such as OLAP/reporting queries can be pointed to the replica cluster in region B.
Applications can use a dynamic global read-write connection string, which always points to the cluster open for writes. During a regional outage, the replica cluster in Region B can be promoted to accept writes. The global connection string automatically updates to point to the promoted cluster, ensuring uninterrupted write operations.
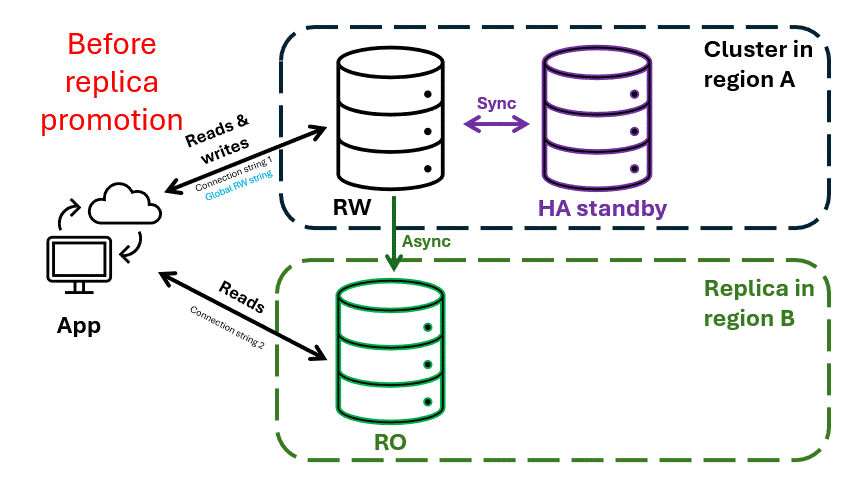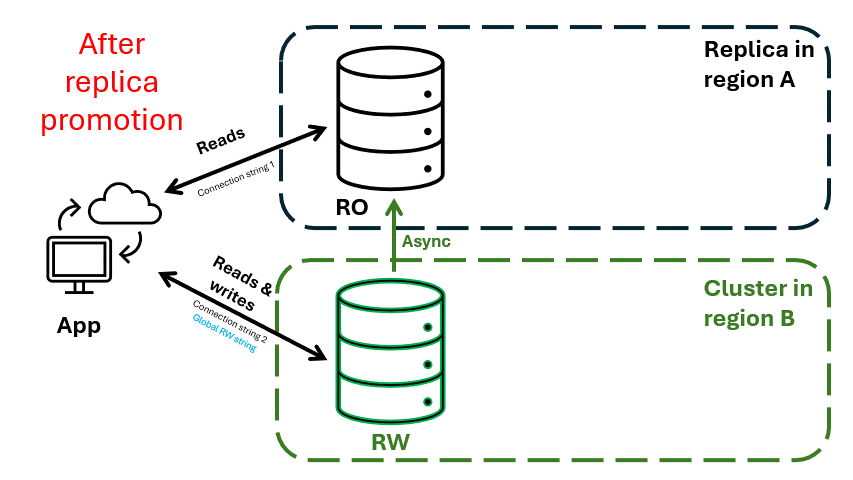 Figure 3. Regional disaster recovery (DR) with an Azure DocumentDB cluster with cross-region replication enabled. Cluster in region B is promoted to become the new read-write cluster. Cluster in region A becomes a replica cluster.
Figure 3. Regional disaster recovery (DR) with an Azure DocumentDB cluster with cross-region replication enabled. Cluster in region B is promoted to become the new read-write cluster. Cluster in region A becomes a replica cluster.
Failover modes for cross-region DR
The replica cluster in region B can take over the read-write role in three ways. The mechanism is the same in each case—reverse the replication direction and switch the global read-write connection string—but the trigger and the data-loss characteristics differ.
Forced promotion
Forced promotion is a user-initiated failover. The service immediately switches the replica to read-write mode and the former primary to read-only. Because replication is asynchronous, any writes that were committed on the former primary but not yet replicated are lost on the new primary. The cluster is fully available for writes as soon as the role switch completes.
Graceful promotion
Graceful promotion is also user-initiated, but unlike forced promotion, it preserves all writes. The service performs these steps:
- Stops accepting new writes on the primary cluster in region A.
- Drains the replication queue so the replica in region B is byte-for-byte caught up with the former primary.
- Promotes the replica in region B to read-write.
- Demotes the former primary in region A to read-only and reverses replication direction.
Because the queue must drain before the switch, the application sees a short write-availability pause. The pause duration is bounded by the current replication lag, which is typically small under normal load but can grow during write spikes.
Service-managed failover
Service-managed failover is initiated by Azure DocumentDB itself. The service continuously monitors the health of the primary region and the reachability of the primary cluster. When it determines that the primary region is unavailable and the cluster can't be recovered locally, it triggers a promotion of the replica in region B. Because the primary isn't reachable, the replication queue can't be drained first, so the failover behaves like an automated forced promotion: it might lose writes that hadn't yet been replicated when the outage began.
Service-managed failover is an opt-in setting on the primary cluster. When it's disabled (the default), a regional outage requires a user-initiated promotion of the replica.
Summary of in-region availability and cross-region DR capabilities
The following table summarizes primary considerations for enabling and managing in-region high availability and the available cross-region failover modes.
| Scenario | Azure DocumentDB feature | Zero data loss | Protection from region-wide outages | Automatic failover | No connection string change |
|---|---|---|---|---|---|
| Physical shard failure | In-region high availability (HA) | ✔️ | ❌ | ✔️ | ✔️ |
| Regional outage, user-initiated | Cross-region replica + forced promotion | ❌ | ✔️ | ❌ | ✔️† |
| Planned region switch, user-initiated | Cross-region replica + graceful promotion | ✔️ | ✔️ | ❌ | ✔️† |
| Regional outage, service-initiated | Cross-region replica + service-managed failover | ❌ | ✔️ | ✔️ | ✔️† |
† When using the global read-write connection string.