Quickstart: Create a skillset in the Azure portal
In this quickstart, you learn how a skillset in Azure AI Search adds optical character recognition (OCR), image analysis, language detection, text translation, and entity recognition to generate text-searchable content in a search index.
You can run the Import data wizard in the Azure portal to apply skills that create and transform textual content during indexing. Input is your raw data, usually blobs in Azure Storage. Output is a searchable index containing AI-generated image text, captions, and entities. Generated content is queryable in the portal using Search explorer.
To prepare, you create a few resources and upload sample files before running the wizard.
Prerequisites
An Azure account with an active subscription. Create an account for free.
Create an Azure AI Search service or find an existing service. You can use a free service for this quickstart.
An Azure Storage account with Azure Blob Storage.
Note
This quickstart uses Azure AI services for the AI transformations. Because the workload is so small, Azure AI services is tapped behind the scenes for free processing for up to 20 transactions. You can complete this exercise without having to create an Azure AI multi-service resource.
Set up your data
In the following steps, set up a blob container in Azure Storage to store heterogeneous content files.
Download sample data consisting of a small file set of different types.
Sign in to the Azure portal with your Azure account.
Create an Azure Storage account or find an existing account.
Choose the same region as Azure AI Search to avoid bandwidth charges.
Choose the StorageV2 (general purpose V2).
In Azure portal, open your Azure Storage page and create a container. You can use the default access level.
In Container, select Upload to upload the sample files. Notice that you have a wide range of content types, including images and application files that aren't full text searchable in their native formats.
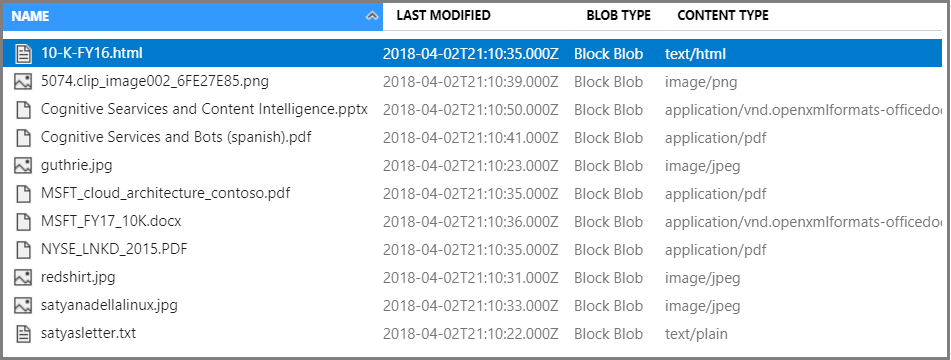
You're now ready to move on the Import data wizard.
Run the Import data wizard
Sign in to the Azure portal with your Azure account.
Find your search service. On the Overview page, select Import data on the command bar to create searchable content in four steps.

Step 1: Create a data source
In Connect to your data, choose Azure Blob Storage.
Choose an existing connection to the storage account and select the container you created. Give the data source a name, and use default values for the rest.
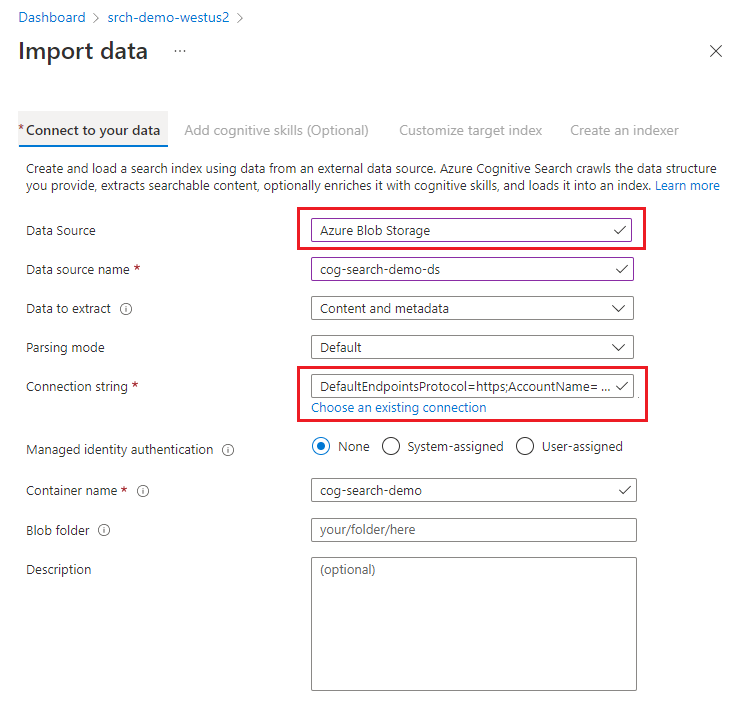
Continue to the next page.
If you get Error detecting index schema from data source, the indexer that powers the wizard can't connect to your data source. Most likely, the data source has security protections. Try the following solutions and then rerun the wizard.
| Security feature | Solution |
|---|---|
| Resource requires Azure roles, or its access keys are disabled | Connect as a trusted service or connect using a managed identity |
| Resource is behind an IP firewall | Create an inbound rule for Search and for the Azure portal |
| Resource requires a private endpoint connection | Connect over a private endpoint |
Step 2: Add cognitive skills
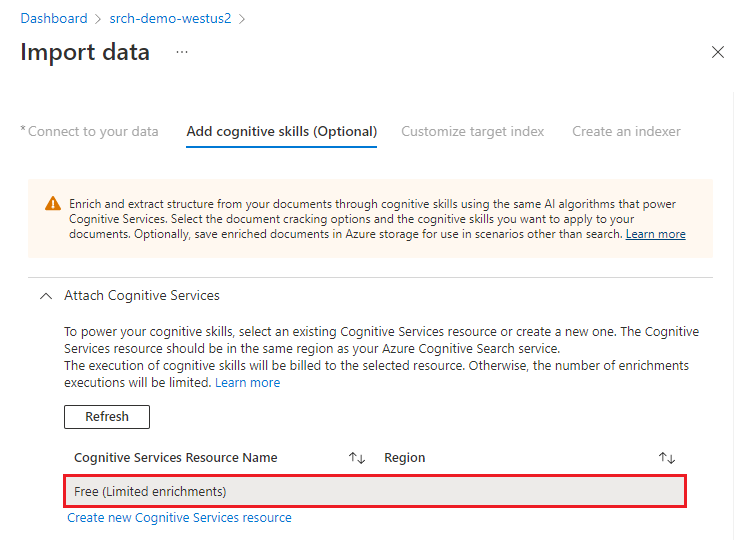
Next, configure AI enrichment to invoke OCR, image analysis, and natural language processing.
For this quickstart, we're using the Free Azure AI services resource. The sample data consists of 14 files, so the free allotment of 20 transactions on Azure AI services is sufficient for this quickstart.
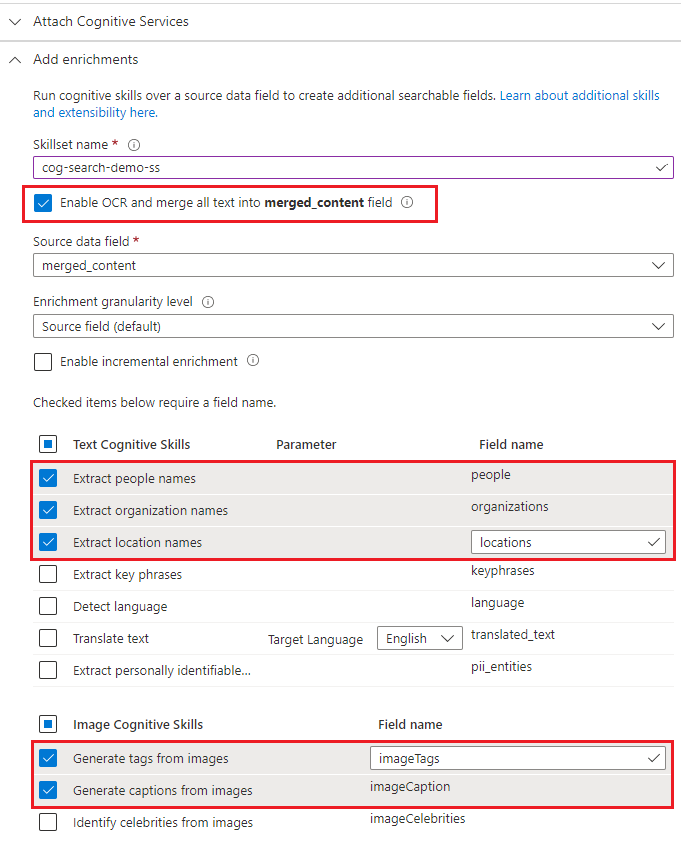
Expand Add enrichments and make six selections.
Enable OCR to add image analysis skills to wizard page.
Choose entity recognition (people, organizations, locations) and image analysis skills (tags, captions).
Continue to the next page.
Step 3: Configure the index
An index contains your searchable content and the Import data wizard can usually create the schema by sampling the data source. In this step, review the generated schema and potentially revise any settings.
For this quickstart, the wizard does a good job setting reasonable defaults:
Default fields are based on metadata properties of existing blobs, plus the new fields for the enrichment output (for example,
people,organizations,locations). Data types are inferred from metadata and by data sampling.Default document key is metadata_storage_path (selected because the field contains unique values).
Default attributes are Retrievable and Searchable. Searchable allows full text search a field. Retrievable means field values can be returned in results. The wizard assumes you want these fields to be retrievable and searchable because you created them via a skillset. Select Filterable if you want to use fields in a filter expression.
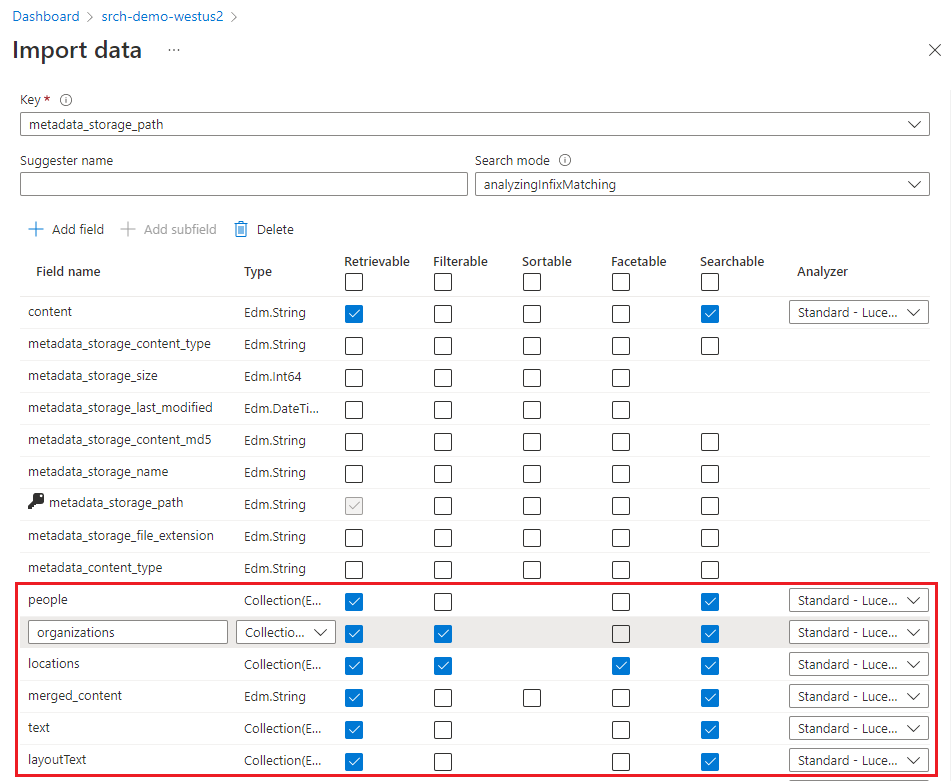
Marking a field as Retrievable doesn't mean that the field must be present in the search results. You can control search results composition by using the select query parameter to specify which fields to include.
Continue to the next page.
Step 4: Configure the indexer
The indexer drives the indexing process. It specifies the data source name, a target index, and frequency of execution. The Import data wizard creates several objects, including an indexer that you can reset and run repeatedly.
In the Indexer page, accept the default name and select Once.
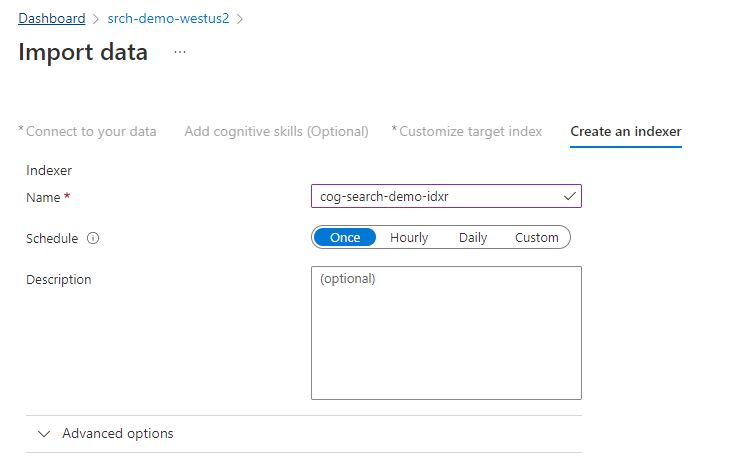
Select Submit to create and simultaneously run the indexer.
Monitor status
Select Indexers from the left navigation pane to monitor status, and then select the indexer. Skills-based indexing takes longer than text-based indexing, especially OCR and image analysis.
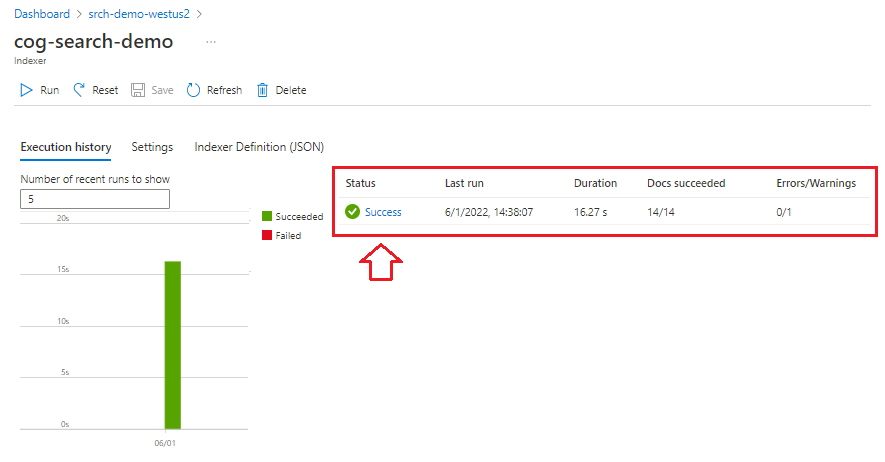
To view details about execution status, select Success (or Failed) to view execution details.
In this demo, there are a few warnings: "Could not execute skill because one or more skill input was invalid." It tells you that a PNG file in the data source doesn't provide a text input to Entity Recognition. This warning occurs because the upstream OCR skill didn't recognize any text in the image, and thus couldn't provide a text input to the downstream Entity Recognition skill.
Warnings are common in skillset execution. As you become familiar with how skills iterate over your data, you might begin to notice patterns and learn which warnings are safe to ignore.
Query in Search explorer
After an index is created, use Search explorer to return results.
On the left, select Indexes and then select the index. Search explorer is on the first tab.
Enter a search string to query the index, such as
satya nadella. The search bar accepts keywords, quote-enclosed phrases, and operators:"Satya Nadella" +"Bill Gates" +"Steve Ballmer"
Results are returned as verbose JSON, which can be hard to read, especially in large documents. Some tips for searching in this tool include the following techniques:
Switch to JSON view to specify parameters that shape results.
Add
selectto limit the fields in results.Add
countto show the number of matches.Use CTRL-F to search within the JSON for specific properties or terms.
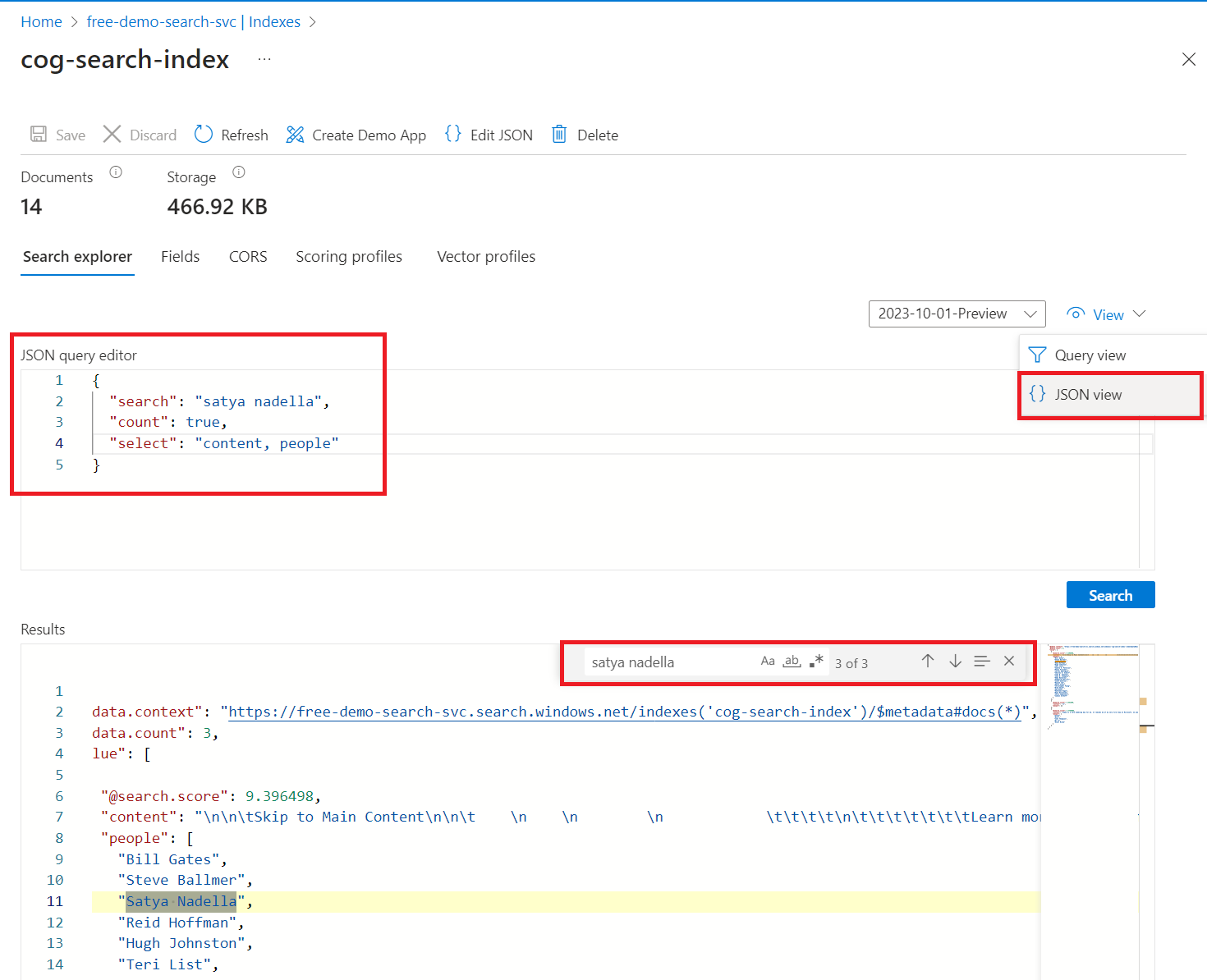
Here's some JSON you can paste into the view:
{
"search": "\"Satya Nadella\" +\"Bill Gates\" +\"Steve Ballmer\"",
"count": true,
"select": "content, people"
}
Tip
Query strings are case-sensitive so if you get an "unknown field" message, check Fields or Index Definition (JSON) to verify name and case.
Takeaways
You've now created your first skillset and learned the basic steps of skills-based indexing.
Some key concepts that we hope you picked up include the dependencies. A skillset is bound to an indexer, and indexers are Azure and source-specific. Although this quickstart uses Azure Blob Storage, other Azure data sources are possible. For more information, see Indexers in Azure AI Search.
Another important concept is that skills operate over content types, and when working with heterogeneous content, some inputs are skipped. Also, large files or fields might exceed the indexer limits of your service tier. It's normal to see warnings when these events occur.
Output is routed to a search index, and there's a mapping between name-value pairs created during indexing and individual fields in your index. Internally, the wizard sets up an enrichment tree and defines a skillset, establishing the order of operations and general flow. These steps are hidden in the wizard, but when you start writing code, these concepts become important.
Finally, you learned that you can verify content by querying the index. In the end, what Azure AI Search provides is a searchable index, which you can query using either the simple or fully extended query syntax. An index containing enriched fields is like any other. You can incorporate standard or custom analyzers, scoring profiles, synonyms, faceted navigation, geo-search, or any other Azure AI Search feature.
Clean up resources
When you're working in your own subscription, it's a good idea at the end of a project to identify whether you still need the resources you created. Resources left running can cost you money. You can delete resources individually or delete the resource group to delete the entire set of resources.
You can find and manage resources in the portal, using the All resources or Resource groups link in the left-navigation pane.
If you used a free service, remember that you're limited to three indexes, indexers, and data sources. You can delete individual items in the portal to stay under the limit.
Next step
You can create skillsets using the portal, .NET SDK, or REST API. To further your knowledge, try the REST API by using a REST client and more sample data.