Administración del espacio de archivo para bases de datos en Azure SQL Database
Se aplica a:![]() Azure SQL Database
Azure SQL Database
En este artículo se describen los diferentes tipos de espacio de almacenamiento para bases de datos en Azure SQL Database y los pasos que se pueden realizar cuando el espacio de archivo asignado se tiene que administrar de forma explícita.
Información general
Con Azure SQL Database, hay patrones de carga de trabajo donde la asignación de archivos de datos subyacentes para las bases de datos puede llegar a ser mayor que la cantidad de páginas de datos que se usan. Esta condición puede darse cuando el espacio usado aumenta y posteriormente se eliminan los datos. El motivo es que el espacio de archivo asignado no se reclama automáticamente cuando se eliminan los datos.
Es posible que sea necesario supervisar el uso del espacio de archivo y reducir los archivos de datos en los escenarios siguientes:
- Permitir el crecimiento de datos en un grupo elástico si el espacio de archivo asignado para sus bases de datos alcanza el tamaño máximo del grupo.
- Permitir la reducción del tamaño máximo de una instancia única de base de datos o grupo elástico.
- Permitir cambiar una instancia única de base de datos o grupo elástico a un nivel de servicio o un nivel de rendimiento diferente con un tamaño máximo inferior.
Nota:
Las operaciones de reducción no deben considerarse una operación de mantenimiento normal. Los archivos de datos y de registro que crecen debido a operaciones empresariales periódicas y repetitivas no requieren operaciones de reducción.
Supervisión del uso del espacio del archivo
La mayoría de las métricas de espacio de almacenamiento que aparecen en las API siguientes solo miden el tamaño de las páginas de datos que se usan:
- API de métricas basadas en Azure Resource Manager, como get-metrics de PowerShell
Sin embargo, las siguientes API también miden el tamaño del espacio asignado para las bases de datos y los grupos elásticos:
- T-SQL: sys.resource_stats
- T-SQL: sys.elastic_pool_resource_stats
Descripción de los tipos de espacio de almacenamiento para una base de datos
Comprender las cantidades de espacio de almacenamiento siguientes es importante para administrar el espacio de archivo de una base de datos.
| Cantidad de base de datos | Definición | Comentarios |
|---|---|---|
| Espacio de datos usado | La cantidad de espacio usado para almacenar los datos de la base de datos. | Por lo general, el espacio usado aumenta (disminuciones) en las inserciones (eliminaciones). En algunos casos, el espacio usado no cambia en las inserciones o eliminaciones, según la cantidad y el patrón de datos implicados en la operación y las posibles fragmentaciones. Por ejemplo, al eliminar una fila de cada página de datos no disminuye necesariamente el espacio usado. |
| Espacio de datos asignado | La cantidad de espacio de archivo de formato disponible para almacenar datos de la base de datos. | La cantidad de espacio asignado crece automáticamente, pero nunca disminuye después de las eliminaciones. Este comportamiento garantiza que las futuras inserciones son más rápidas puesto que no es necesario volver a formatear el espacio. |
| Espacio de datos asignado, pero no usado | La diferencia entre la cantidad de espacio de datos asignado y el espacio de datos usado. | Esta cantidad representa la cantidad máxima de espacio libre que se puede reclamar mediante la reducción de archivos de datos de base de datos. |
| Tamaño máximo de datos | La cantidad máxima de espacio que se puede usar para almacenar datos de base de datos. | La cantidad de espacio de datos asignado no puede crecer por encima del tamaño máximo de datos. |
En el siguiente diagrama se ilustra la relación entre los diferentes tipos de espacio de almacenamiento para una base de datos.
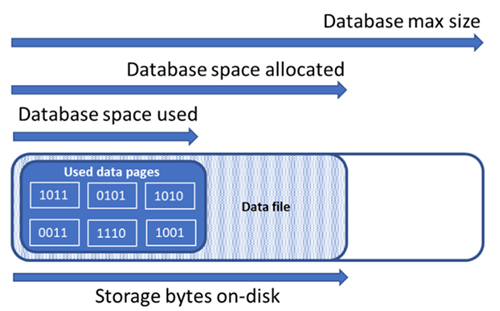
Consulta de la información de espacio de archivos en una base de datos única
Use la siguiente consulta de sys.database_files para devolver la cantidad de espacio de archivos de base de datos asignado y la cantidad de espacio asignado sin usar. Las unidades de resultado de la consulta están en MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Descripción de los tipos de espacio de almacenamiento para un grupo elástico
Comprender las cantidades de espacio de almacenamiento siguientes es importante para administrar el espacio de archivo de un grupo elástico.
| Cantidad de grupo elástico | Definición | Comentarios |
|---|---|---|
| Espacio de datos usado | La suma del espacio de datos utilizado por todas las bases de datos en el grupo elástico. | |
| Espacio de datos asignado | La suma del espacio de datos asignado por todas las bases de datos en el grupo elástico. | |
| Espacio de datos asignado, pero no usado | La diferencia entre la cantidad de espacio de datos asignado y el espacio de datos usado por todas las base de datos del grupo elástico. | Esta cantidad representa la cantidad máxima de espacio asignado para el grupo elástico que se puede reclamar mediante la reducción de archivos de datos de base de datos. |
| Tamaño máximo de datos | La cantidad máxima de espacio de datos que puede usar el grupo elástico para todas sus bases de datos. | El espacio asignado para el grupo elástico no puede exceder el tamaño máximo del grupo elástico. Si se da esta condición, el espacio asignado que no se usa se puede reclamar mediante la reducción de archivos de datos de base de datos. |
Nota:
El mensaje de error "El grupo elástico ha alcanzado su límite de almacenamiento" indica que se ha asignado suficiente espacio a los objetos de base de datos para cumplir el límite de almacenamiento del grupo elástico, pero puede haber espacio sin usar en la asignación de espacio de datos. Considere la posibilidad de aumentar el límite de almacenamiento del grupo elástico, o como una solución a corto plazo, la opción de liberar espacio de datos con las muestras de la sección Reclamación del espacio asignado sin usar. También debe tener en cuenta el posible impacto negativo en el rendimiento por la reducción de los archivos de base de datos; consulte la sección Mantenimiento de índices después de la reducción.
Consulta de la información de espacio de almacenamiento en un grupo elástico
Las consultas siguientes pueden utilizarse para determinar las cantidades de espacio de almacenamiento para un grupo elástico.
Espacio usado de datos de grupo elástico
Modifique la siguiente consulta para devolver la cantidad de espacio usado de datos del grupo elástico. Las unidades de resultado de la consulta están en MB.
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Espacio de datos de grupo elástico asignado y espacio asignado sin usar
Modifique los ejemplos siguientes para devolver una tabla que muestre el espacio asignado y sin usar para cada base de datos de un grupo elástico. La tabla ordena las bases de datos desde las que tienen más hasta las que tienen menos cantidad de espacio asignado sin usar. Las unidades de resultado de la consulta están en MB.
Los resultados de la consulta para determinar el espacio asignado para cada base de datos del grupo se pueden agregar juntos para determinar el espacio total asignado para el grupo elástico. El espacio de grupo elástico asignado no puede exceder el tamaño máximo del grupo elástico.
Importante
El módulo de Azure Resource Manager para PowerShell todavía es compatible con Azure SQL Database, pero todo el desarrollo futuro se realizará para el módulo Az.Sql. El módulo de AzureRM continuará recibiendo correcciones de errores hasta diciembre de 2020 como mínimo. Los argumentos para los comandos del módulo Az y los módulos AzureRm son esencialmente idénticos. Para obtener más información sobre la compatibilidad, vea Presentación del nuevo módulo Az de Azure PowerShell.
El script de PowerShell requiere el módulo SQL Server PowerShell, consulte el artículo de descarga del módulo de PowerShell para la instalación.
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get space allocated in MB and space allocated unused in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of space allocated unused
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
La captura de pantalla siguiente es un ejemplo de la salida del script:

Tamaño máximo de datos del grupo elástico
Modifique la siguiente consulta T-SQL para devolver el tamaño máximo de datos de los grupos elásticos grabados. Las unidades de resultado de la consulta están en MB.
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Reclamación del espacio asignado sin usar
Importante
Los comandos de reducción afectan al rendimiento de la base de datos mientras se está ejecutando y, si es posible, se deben ejecutar durante períodos de poco uso.
Reducción de archivos de datos
Debido a un posible impacto en el rendimiento de la base datos, Azure SQL Database no reduce automáticamente los archivos de datos. Sin embargo, los clientes pueden reducirlos mediante un procedimiento de autoservicio en el momento que estimen oportuno. No debe ser una operación programada periódicamente, sino un evento único en respuesta a una reducción importante en el consumo de espacio usado por los archivos de datos.
Sugerencia
No se recomienda reducir los archivos de datos si la carga de trabajo normal de la aplicación hará que los archivos vuelvan a tener el mismo tamaño asignado.
En Azure SQL Database, puede usar los comandos DBCC SHRINKDATABASE o DBCC SHRINKFILE para reducir los archivos:
DBCC SHRINKDATABASEreduce todos los datos y archivos de registro de una base de datos con un solo comando. El comando reduce un archivo de datos a la vez, lo que puede llevar mucho tiempo para bases de datos más grandes. También reduce el archivo de registro, que normalmente no es necesario porque Azure SQL Database reduce los archivos de registro automáticamente según sea necesario.- El comando
DBCC SHRINKFILEadmite escenarios más avanzados:- Puede tener como objetivo archivos individuales según sea necesario, en lugar de reducir todos los archivos de la base de datos.
- Cada comando
DBCC SHRINKFILEse puede ejecutar en paralelo con otros comandosDBCC SHRINKFILEpara reducir varios archivos al mismo tiempo y disminuir el tiempo total de la reducción, a costa de un mayor uso de recursos y una mayor probabilidad de bloquear las consultas de usuario, si se ejecutan durante la reducción. - Si el final del archivo no contiene datos, puede reducir el tamaño de archivo asignado mucho más rápido especificando el argumento
TRUNCATEONLY. Esto no requiere el movimiento de datos dentro del archivo.
- Para obtener más información sobre estos comandos de reducción, consulte DBCC SHRINKDATABASE y DBCC SHRINKFILE.
Los ejemplos siguientes se deben ejecutar mientras está conectado a la base de datos de usuario de destino, no a la base de datos master.
Para usar DBCC SHRINKDATABASE para reducir todos los archivos de datos y de registro de una base de datos determinada:
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
En Azure SQL Database, una base de datos puede tener uno o varios archivos de datos, creados automáticamente a medida que los datos crecen. Para determinar el diseño de archivo de la base de datos, incluido el tamaño usado y asignado de cada archivo, consulte la vista del catálogo sys.database_files con el siguiente script de ejemplo:
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
Puede ejecutar una reducción en un archivo único mediante el comando DBCC SHRINKFILE; por ejemplo:
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
Debe tener en cuenta el posible impacto negativo en el rendimiento por la reducción de los archivos de base de datos; consulte la sección Mantenimiento de índices después de la reducción.
Reducir el archivo de registro de transacciones
A diferencia de los archivos de datos, Azure SQL Database reduce automáticamente el archivo de registro de transacciones para evitar un uso de espacio excesivo que pueda provocar errores de espacio insuficiente. No suele ser necesario que los clientes reduzcan el archivo de registro de transacciones.
En los niveles de servicio Premium y Crítico para la empresa, si el registro de transacciones aumenta demasiado, puede contribuir de forma significativa al consumo de almacenamiento local para alcanzar el límite de almacenamiento local máximo. Si el consumo de almacenamiento local se aproxima al límite, los clientes pueden optar por reducir el registro de transacciones mediante el comando DBCC SHRINKFILE, tal y como se muestra en el ejemplo siguiente. Esta operación libera espacio de almacenamiento local en cuanto se completa el comando, sin necesidad de esperar a la operación de reducción automática periódica.
El siguiente ejemplo se debe ejecutar mientras está conectado a la base de datos de usuario de destino, no a la base de datos master.
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
Reducción automática
Como alternativa para la reducción manual de archivos de datos, se puede habilitar la reducción automática para una base de datos. Sin embargo, la reducción automática es menos eficaz al reclamar espacio de archivo que DBCC SHRINKDATABASE y DBCC SHRINKFILE.
La reducción automática está deshabilitada de forma predeterminada, lo cual se recomienda para la mayoría de las bases de datos. Si es necesario habilitar la reducción automática, se recomienda deshabilitarla una vez que se hayan alcanzado los objetivos de administración del espacio, en lugar de mantenerla habilitada de forma permanente. Para más información, vea Consideraciones para AUTO_SHRINK.
La reducción automática, por ejemplo, puede ser útil en el escenario específico en el que un grupo elástico contiene muchas bases de datos que experimentan un crecimiento y una reducción significativos del espacio de archivo de datos utilizado, lo que causa que el grupo se acerque al límite máximo de tamaño. No se trata de un escenario habitual.
Para habilitar la reducción automática, ejecute el siguiente comando mientras está conectado a su base de datos (no a la base de datos master).
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
Para más información sobre este comando, consulte las opciones de DATABASE SET.
Mantenimiento de índices después de la reducción
Una vez completada una operación de reducción en los archivos de datos, es posible que los índices se fragmenten. Esto reduce la eficacia de optimización del rendimiento para determinadas cargas de trabajo, como consultas que usan exploraciones grandes. Si se produce una degradación del rendimiento una vez completada la operación de reducción, considere la posibilidad de realizar el mantenimiento de índices para volver a generar los índices. Tenga en cuenta que las recompilaciones de índice requieren espacio libre en la base de datos y, por lo tanto, pueden hacer que el espacio asignado aumente, lo que contrarresta el efecto de la reducción.
Para obtener más información sobre el mantenimiento de índices, consulte Optimización del mantenimiento de índices para mejorar el rendimiento de las consultas y reducir el consumo de recursos.
Reducir bases de datos grandes
Cuando el espacio asignado a la base de datos es de cientos de gigabytes o superior, la reducción puede requerir un tiempo significativo para completarse, a menudo medido en horas o días para bases de datos de varios terabytes. Hay optimizaciones del proceso y procedimientos recomendados que puede usar para que este proceso sea más eficiente y tenga un menor impacto en las cargas de trabajo de las aplicaciones.
Capturar línea base de uso de espacio
Antes de iniciar la reducción, capture el espacio actual usado y asignado en cada archivo de base de datos ejecutando la siguiente consulta de uso de espacio:
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Una vez completada la reducción, puede ejecutar esta consulta de nuevo y comparar el resultado con la línea base inicial.
Truncar archivos de datos
Se recomienda ejecutar primero la reducción para cada archivo de datos con el parámetro TRUNCATEONLY. De esta forma, si hay espacio asignado pero sin usar al final del archivo, se quita rápidamente y sin ningún movimiento de datos. El siguiente comando de ejemplo trunca el archivo de datos con file_id 4:
DBCC SHRINKFILE (4, TRUNCATEONLY);
Una vez que se ejecute este comando para cada archivo de datos, puede volver a ejecutar la consulta de uso de espacio para ver la reducción del espacio asignado, si existe. También puede ver espacio asignado para la base de datos en Azure Portal.
Evaluar la densidad de página de índice
Si truncar archivos de datos no ha dado como resultado una reducción suficiente del espacio asignado, tendrá que reducir los archivos de datos. Tenga en cuenta que, como paso opcional pero recomendado, primero debe determinar la densidad media de página de los índices de la base de datos. Para la misma cantidad de datos, la reducción se completará más rápido si la densidad de página es alta, ya que tendrá que mover menos páginas. Si la densidad de página es baja para algunos índices, considere la posibilidad de realizar un mantenimiento en estos índices para aumentar la densidad de página antes de reducir los archivos de datos. Esto también permitirá una mayor reducción del espacio de almacenamiento asignado.
Para determinar la densidad de página de todos los índices de la base de datos, use la consulta siguiente. La densidad de página se notifica en la columna avg_page_space_used_in_percent.
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Si hay índices con un recuento de páginas alto que tienen una densidad de página inferior al 60-70 %, considere la posibilidad de volver a generar o reorganizar estos índices antes de reducir los archivos de datos.
Nota:
Para bases de datos más grandes, la consulta para determinar la densidad de página puede tardar mucho tiempo (horas) en completarse. Además, la recompilación o reorganización de índices grandes también requiere un uso considerable de tiempo y recursos. Tiene que elegir entre dedicar más tiempo a aumentar la densidad de páginas o disminuir la duración de la reducción y lograr un mayor ahorro de espacio.
Si hay varios índices con baja densidad de página, es posible que pueda reconstruirlos en paralelo en varias sesiones de base de datos para acelerar el proceso. Sin embargo, asegúrese de que no se acerca a los límites de recursos de la base de datos al hacerlo y deje suficiente capacidad de aumento de recursos para las cargas de trabajo de aplicaciones que pueden estar ejecutándose. Supervise el consumo de recursos (CPU, E/S de datos, E/S de registro) en Azure Portal o mediante la vista sys.dm_db_resource_stats e inicie reconstrucciones paralelas adicionales solo si el uso de recursos en cada una de estas dimensiones sigue siendo sustancialmente inferior al 100 %. Si el uso de CPU, E/S de datos o E/S de registro es del 100 %, puede escalar la base de datos para tener más núcleos de CPU y aumentar el rendimiento de E/S. Esto puede permitir que se recompilen paralelos adicionales para completar el proceso más rápido.
Comando de recompilación del índice de muestra
A continuación se muestra un comando de muestra para recompilar un índice y aumentar su densidad de página mediante la instrucción ALTER INDEX:
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
Este comando inicia una recompilación de índice en línea y reanudable. Esto permite que las cargas de trabajo simultáneas sigan usando la tabla mientras la reconstrucción está en curso y le permite reanudar la reconstrucción si se interrumpe por cualquier motivo. Sin embargo, este tipo de reconstrucción es más lento que una reconstrucción sin conexión, lo que bloquea el acceso a la tabla. Si no es necesario que otras cargas de trabajo accedan a la tabla durante la reconstrucción, establezca las opciones ONLINE y RESUMABLE en OFF y quite la cláusula WAIT_AT_LOW_PRIORITY.
Para obtener más información sobre el mantenimiento de índices, consulte Optimización del mantenimiento de índices para mejorar el rendimiento de las consultas y reducir el consumo de recursos.
Reducir varios archivos de datos
Como se ha indicado anteriormente, reducir con el movimiento de datos es un proceso de larga duración. Si la base de datos tiene varios archivos de datos, puede acelerar el proceso reduciendo varios archivos de datos en paralelo. Para ello, abra varias sesiones de base de datos y use DBCC SHRINKFILE en cada sesión con un valor file_id diferente. De forma similar a la recompilación de índices anterior, asegúrese de que tiene suficiente capacidad de aumento de recursos (CPU, E/S de datos, E/S de registro) antes de iniciar cada nuevo comando de reducción paralela.
El siguiente comando de ejemplo reduce el archivo de datos con file_id 4, intentando reducir su tamaño asignado a 52 000 MB moviendo páginas dentro del archivo:
DBCC SHRINKFILE (4, 52000);
Si desea reducir el espacio asignado para el archivo al mínimo posible, ejecute la instrucción sin especificar el tamaño de destino:
DBCC SHRINKFILE (4);
Si una carga de trabajo se ejecuta simultáneamente con la reducción, puede empezar a usar el espacio de almacenamiento liberado por la reducción antes de que esta se complete y trunque el archivo. En este caso, la reducción no podrá reducir el espacio asignado al destino especificado.
Puede mitigar esto reduciendo cada archivo en pasos más pequeños. Esto significa que, en el comando DBCC SHRINKFILE, se establece el destino que es ligeramente menor que el espacio asignado actual para el archivo, como se ve en los resultados de la consulta de uso de espacio de base de referencia. Por ejemplo, si el espacio asignado para el archivo con file_id 4 es 200 000 MB y desea reducirlo a 100 000 MB, primero puede establecer el destino en 170 000 MB:
DBCC SHRINKFILE (4, 170000);
Una vez completado este comando, habrá truncado el archivo y reducido su tamaño asignado a 170 000 MB. Después puede repetir este comando, estableciendo el destino primero en 140 000 MB, luego en 110 000 MB, etc., hasta que el archivo se rebaje al tamaño deseado. Si el comando se completa pero el archivo no se trunca, use pasos más pequeños, por ejemplo, 15 000 MB en lugar de 30 000 MB.
Para supervisar el progreso de reducción de todas las sesiones de reducción simultáneas, puede usar la consulta siguiente:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Nota:
El progreso de la reducción puede no ser lineal y el valor de la columna percent_complete puede permanecer prácticamente sin cambios durante largos períodos de tiempo, aunque la reducción sigue en curso.
Una vez que se haya completado la reducción para todos los archivos de datos, vuelva a ejecutar la consulta de uso de espacio (o compruebe en Azure Portal) para determinar la reducción resultante en el tamaño de almacenamiento asignado. Si todavía hay una gran diferencia entre el espacio usado y el espacio asignado, puede recompilar los índices como se describe anteriormente. Esto puede aumentar más el espacio asignado de forma temporal, pero reducir los archivos de datos de nuevo después de recompilar los índices debería producir una reducción más profunda del espacio asignado.
Errores transitorios durante la reducción
En ocasiones, un comando de reducción puede fallar con varios errores, como tiempos de espera e interbloqueos. En general, estos errores son transitorios y no se repiten si se repite el mismo comando. Si se produce un error en la reducción, se conserva el progreso que ha realizado hasta ahora en mover páginas de datos y se puede ejecutar de nuevo el mismo comando de reducción para seguir reduciendo el archivo.
El siguiente script de ejemplo muestra cómo se puede ejecutar la reducción en un bucle de reintentos para volver a intentar automáticamente hasta un número configurable de veces cuando se produce un error de tiempo de espera o un error de interbloqueo. Este enfoque de reintentar se aplica a muchos otros errores que pueden producirse durante la reducción.
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
Además de los tiempos de espera y los interbloqueos, la reducción puede producir errores debido a determinados problemas conocidos.
Los errores devueltos y los pasos de mitigación son los siguientes:
- Error número 49503, mensaje de error: . *Is: No se ha podido mover la página %d:%d porque se trata de una página de un almacén de versiones persistentes no consecutivas. Motivo de la parada de la página: %ls. Marca de tiempo de la parada de la página: %I64d.
Este error se produce cuando hay transacciones activas de larga duración que han generado versiones de fila en el almacén de versiones persistentes (PVS). Las páginas que contienen estas versiones de fila no se pueden mover por reducción, por lo que no puede avanzar y se produce este error.
Para mitigarlo, tiene que esperar hasta que se hayan completado estas transacciones de larga duración. Como alternativa, puede identificar y finalizar estas transacciones de larga duración, pero esto puede afectar a la aplicación si no controla correctamente los errores de transacción. Una forma de buscar transacciones de larga duración es ejecutando la consulta siguiente en la base de datos donde ejecutó el comando reducir:
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
Puede finalizar una transacción usando el comando KILL y especificando el valor asociado session_id del resultado de la consulta:
KILL 4242; -- replace 4242 with the session_id value from query results
Precaución
La finalización de una transacción puede afectar negativamente a las cargas de trabajo.
Una vez finalizadas o completadas las transacciones de larga duración, una tarea en segundo plano interna limpiará las versiones de fila que ya no son necesarias después de algún tiempo. Puede supervisar el tamaño de PVS para medir el progreso de la limpieza con la consulta siguiente. Ejecute la consulta en la base de datos donde ejecutó el comando reducir:
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
Una vez que el tamaño de PVS notificado en la columna persistent_version_store_size_gb se reduce considerablemente en comparación con su tamaño original, la reanudación de la reducción debería tener éxito.
- Número de error: 5223, mensaje de error: %.*ls: Página vacía %d:%d no se pudo desasignar.
Este error puede producirse si hay operaciones de mantenimiento de índice en curso, como ALTER INDEX. Vuelva a intentar el comando reducir una vez completadas estas operaciones.
Si este error persiste, es posible que tenga que volver a crear el índice asociado. Para buscar el índice que se va a recompilar, ejecute la siguiente consulta en la misma base de datos donde ejecutó el comando reducir:
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
Antes de ejecutar esta consulta, reemplace los marcadores de posición <file_id> y <page_id> por los valores reales del mensaje de error que recibió. Por ejemplo, si el mensaje es Página vacía 1:62669no se pudo desasignar, entonces <file_id> es 1 y <page_id> es 62669.
Vuelva a recompilar el índice identificado por la consulta y vuelva a intentar el comando reducir.
- Número de error: 5201, mensaje de error: DBCC SHRINKDATABASE: Se omitió el id. de archivo %d del id. de la base de datos %d porque el archivo no tiene suficiente espacio disponible que recuperar.
Este error significa que el archivo de datos no se puede encoger más. Puede pasar al siguiente archivo de datos.
Pasos siguientes
Para información sobre los tamaños máximos de base de datos, consulte:
- Límites del modelo de compra basado en núcleo virtual de Azure SQL Database para una base de datos única
- Límites de recursos para bases de datos únicas que utilizan el modelo de compra basado en DTU
- Límites del modelo de compra basado en núcleo virtual de Azure SQL Database para grupos elásticos
- Límites de recursos para grupos elásticos que utilizan el modelo de compra basado en DTU
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de