Leer páginas
Se aplica a:![]() SQL Server
SQL Server
La E/S de una instancia del Motor de base de datos de SQL Server incluye lecturas lógicas y físicas. Una lectura lógica se produce cada vez que el Motor de base de datos solicita una página de la caché del búfer. Si la página no se encuentra actualmente en la caché del búfer, una lectura física copia primero la página desde el disco a la caché.
El motor relacional controla las solicitudes de lectura generadas por una instancia del Motor de base de datos, mientras que el motor de almacenamiento las optimiza. El motor relacional determina el método de acceso más eficaz (como un recorrido de tabla, un recorrido de índice o una lectura con clave); los métodos de acceso y los componentes del administrador de búferes del motor de almacenamiento determinan el patrón general de las lecturas que se llevarán a cabo y optimizan las lecturas necesarias para implementar el método de acceso. El subproceso que ejecuta el lote programa las lecturas.
Lectura anticipada
El Motor de base de datos admite un mecanismo de optimización del rendimiento denominado lectura anticipada. La lectura anticipada prevé las páginas de datos y de índice necesarias para cumplir un plan de ejecución de consultas y lleva las páginas a la caché del búfer antes de ser utilizadas por la consulta. Esto permite que el cálculo y la E/S se superpongan, aprovechando al completo la CPU y el disco.
El mecanismo de lectura anticipada permite que el Motor de base de datos lea hasta 64 páginas contiguas (512 KB) de un archivo. Esta lectura se realiza como única lectura por dispersión y recopilación en el número adecuado de búferes (probablemente no contiguos) de la caché del búfer. Si alguna de las páginas del intervalo ya está presente en la caché del búfer, la página correspondiente de la lectura se descartará cuando se complete la lectura. Es posible que el intervalo de páginas también se "recorte" en cada final si las páginas correspondientes ya están presentes en la caché.
Hay dos tipos de lectura anticipada: uno para las páginas de datos y uno para las páginas de índice.
Leer páginas de datos
Los recorridos de tablas que se utilizan para leer páginas de datos son muy eficaces en el Motor de base de datos. Las páginas del Mapa de asignación de índices (IAM) de una base de datos de SQL Server enumeran las extensiones que utiliza una tabla o un índice. El motor de almacenamiento puede leer la IAM para generar una lista ordenada de las direcciones de disco que deben leerse. Esto permite al motor de almacenamiento optimizar sus operaciones de E/S como lecturas secuenciales de gran tamaño que se realizan en un orden basado en su ubicación en el disco. Para más información sobre las páginas de IAM, consulte Administrar el espacio utilizado por los objetos.
Leer páginas de índice
El motor de almacenamiento lee las páginas de índice en serie, ordenadas por clave. Por ejemplo, esta ilustración muestra una representación simplificada de un conjunto de páginas hoja que contienen un conjunto de claves y el nodo del índice intermedio que asigna las páginas hoja. Para más información sobre la estructura de las páginas en un índice, consulte Estructuras de índices agrupados.
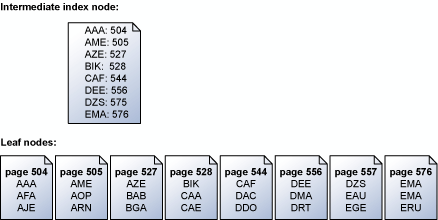
El motor de almacenamiento utiliza la información de la página de índice intermedio que se encuentra por encima del nivel hoja para programar las lecturas anticipadas en serie de las páginas que contienen las claves. Si se realiza una solicitud para todas las claves de "ABC" a "DEF", el motor de almacenamiento lee primero la página de índice por encima de la página hoja. Sin embargo, no solo lee cada página de datos individual secuencialmente desde la página 504 a la página 556 (la última con claves en el intervalo especificado). En cambio, el motor de almacenamiento recorre la página de índice intermedio y genera una lista con las páginas hoja que deben leerse. A continuación, el motor de almacenamiento programa todas las lecturas según el orden establecido en la clave. El motor de almacenamiento reconoce también que las páginas 504/505 y las páginas 527/528 son contiguas, y realiza una única lectura por dispersión para recuperar las páginas adyacentes en una sola operación. Cuando hay muchas páginas que tienen que recuperarse con una operación en serie, el motor de almacenamiento programa un bloque de lecturas cada vez. Cuando se completa un subconjunto de estas lecturas, el motor de almacenamiento programa un número igual de lecturas nuevas hasta que se hayan programado todas las lecturas que se necesitan.
El motor de almacenamiento utiliza la captura previa para agilizar las búsquedas en una tabla base desde índices no clúster. Las filas hoja de un índice no clúster contienen punteros a las filas de datos que incluyen cada valor de clave específico. Mientras el motor de almacenamiento examina las páginas hoja del índice no clúster, también comienza a programar lecturas asincrónicas de las filas de datos cuyos punteros ya se han recuperado. Esto permite al motor de almacenamiento recuperar las filas de la tabla subyacente antes de completar el recorrido del índice no clúster. La captura previa se usa independientemente de si la tabla dispone de un índice clúster o no. SQL Server Enterprise usa más capturas previas que otras ediciones de SQL Server, lo que permite la lectura anticipada de más páginas. El nivel de captura previa no se puede configurar en ninguna edición. Para más información sobre índices no agrupados, consulte Estructuras de índices no agrupados.
Recorrido avanzado
En SQL Server Enterprise, la característica de examen avanzado permite que varias tareas compartan exámenes de tabla completos. Si el plan de ejecución de una instrucción Transact-SQL requiere un recorrido de las páginas de datos de una tabla y el Motor de base de datos detecta que la tabla ya se recorre en otro plan de ejecución, el Motor de base de datos combina el segundo recorrido con el primero en la ubicación actual del segundo. El Motor de base de datos lee cada página una vez y pasa las filas de cada página a ambos planes de ejecución. Esto continúa hasta que se llega al final de la tabla.
En ese momento, el primer plan de ejecución dispone de los resultados completos de un recorrido, pero el segundo plan de ejecución aún debe recuperar las páginas de datos que se leyeron antes combinarse con el recorrido en curso. A continuación, el recorrido del segundo plan de ejecución vuelve a la primera página de datos de la tabla y recorre hasta donde se combinó con el primer recorrido. De esta forma, se puede combinar cualquier número de recorridos. El Motor de base de datos seguirá pasando por las páginas de datos en bucle hasta completar todos los recorridos. Este mecanismo también se denomina "recorrido cíclico" y demuestra por qué no se puede garantizar el orden de los resultados devueltos de una instrucción SELECT sin una cláusula ORDER BY.
Por ejemplo, supongamos que dispone de una tabla con 500.000 páginas. El UsuarioA ejecuta una instrucción Transact-SQL que requiere un recorrido de la tabla. Cuando el recorrido lleva procesadas 100 000 páginas, el UsuarioB ejecuta otra instrucción Transact-SQL que recorre la misma tabla. El Motor de base de datos programa un conjunto de solicitudes de lectura de las páginas siguientes a la 100 001 y devuelve las filas de cada página a ambos recorridos. Cuando el recorrido llega a la página 200 000, el UsuarioC ejecuta otra instrucción Transact-SQL que recorre la misma tabla. Comenzando con la página 200 001, el Motor de base de datos devuelve las filas de cada página que lee a los tres recorridos. Después de leer la fila 500.000, el recorrido del UsuarioA está completo y los recorridos del UsuarioB y el UsuarioC vuelven a la página 1 y comienzan a leer las páginas a partir de la primera. Cuando el Motor de base de datos llega a la página 100 000, se completa el recorrido de UserB. El recorrido del UsuarioC se mantiene en solitario hasta que llega a la página 200.000. En este momento, finalizan todos los recorridos.
Sin el recorrido avanzado, cada usuario tendría que competir por espacio en búfer y se produciría una contención en el brazo del disco. Entonces se leerían las mismas páginas una vez por cada usuario, en lugar de leerlas una vez y compartirlas entre varios usuarios, lo que ralentizaría el rendimiento y consumiría muchos recursos.
Consulte también
Guía de arquitectura de páginas y extensiones
Escribir páginas
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de