Exploración de datos con NumPy y Pandas
Los científicos de datos pueden usar diversas herramientas y técnicas para explorar, visualizar y manipular datos. Una de las formas más comunes en las que los científicos de datos trabajan con los datos es mediante el lenguaje de programación Python y algunos paquetes específicos para el procesamiento de datos.
Qué es NumPy
NumPy es una biblioteca de Python que ofrece una funcionalidad comparable a la de herramientas matemáticas como MATLAB y R. Aunque NumPy simplifica considerablemente la experiencia del usuario, también ofrece funciones matemáticas completas.
Qué es Pandas
Pandas es una biblioteca de Python muy conocida para el análisis y la manipulación de datos. Pandas es como la aplicación de hoja de cálculo de Python: proporciona una funcionalidad fácil de usar para las tablas de datos.
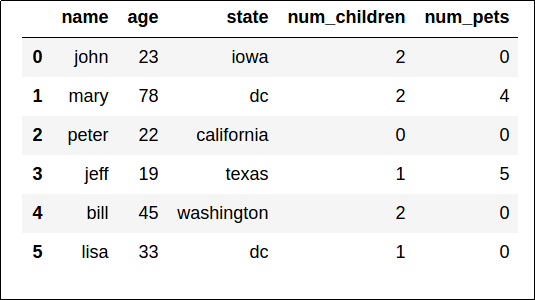
Exploración de datos en un cuaderno de Jupyter Notebook
Los cuadernos de Jupyter Notebooks son una forma conocida de ejecutar scripts básicos mediante el explorador web. Normalmente, estos cuadernos son una sola página web, dividida en secciones de texto y secciones de código que se ejecutan en el servidor en lugar de en la máquina local. Al ejecutar código en cuadernos de Jupyter Notebook en un servidor, puede empezar a trabajar rápidamente sin necesidad de instalar Python u otras herramientas en el equipo local.
Prueba de hipótesis
La exploración y el análisis de datos suele ser un proceso iterativo en el que el científico de datos toma una muestra de los datos y realiza las siguientes tareas para analizarlos y probar hipótesis:
- Limpiar los datos para controlar errores, valores que faltan y otros problemas.
- Aplicación de técnicas estadísticas para comprender mejor los datos y cómo se puede esperar que la muestra represente la población de datos del mundo real, lo que permite una variación aleatoria.
- Visualizar los datos para determinar las relaciones entre variables y, en el caso de un proyecto de aprendizaje automático, identificar las características que potencialmente se pueden predecir de la etiqueta.
- Revisión de hipótesis y repetición del proceso.