Matrices de confusión
Los datos pueden considerarse continuos, categóricos u ordinales (categóricos, pero con un orden). Las matrices de confusión son un medio de evaluar el rendimiento de un modelo categórico. Para saber cómo funcionan, primero vamos a refrescar nuestros conocimientos sobre los datos continuos. A través de esto, podemos ver cómo las matrices de confusión son simplemente una extensión de los histogramas que ya conocemos.
Distribuciones de datos continuos
Cuando queremos comprender los datos continuos, el primer paso suele ser ver cómo se distribuyen. Imagine el siguiente histograma:
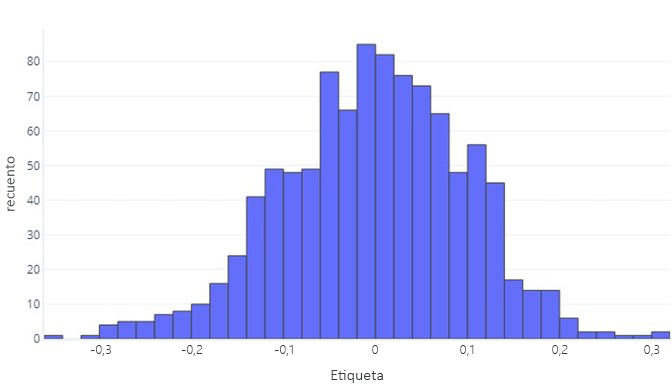
Podemos ver que la etiqueta es, por término medio, aproximadamente cero y que la mayoría de los puntos de datos se encuentra entre -1 y 1. Aparece como simétrico: hay un número aproximadamente igual de números más pequeños y más grandes que la media. Si quisiéramos, podríamos usar una tabla en lugar de un histograma, pero podría ser difícil de manejar.
Distribuciones de datos categóricos
En algunos aspectos, los datos categóricos no son tan diferentes de los datos continuos. Podemos seguir generando histogramas para evaluar la forma en que aparecen normalmente los valores para cada etiqueta. Por ejemplo, una etiqueta binaria (verdadero/falso) podría aparecer con una frecuencia como esta:
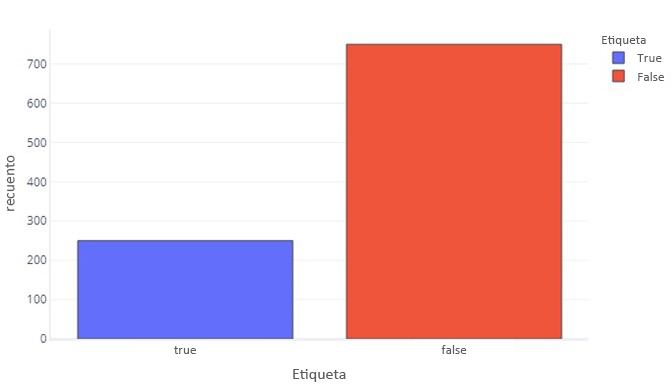
Esto nos indica que hay 750 muestras con la etiqueta "false" y 250 con la etiqueta "true".
Una etiqueta para tres categorías es parecida:
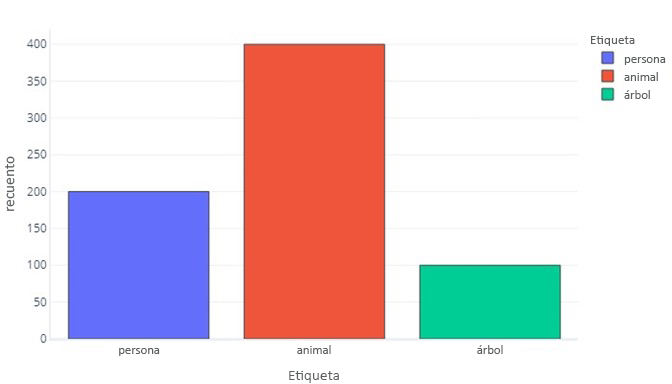
Esto nos indica que hay 200 muestras que son "persona", 400 que son "animal" y 100 que son "árbol".
Como las etiquetas de categorías son más sencillas, a menudo podemos mostrar estas como tablas simples. Los dos gráficos anteriores quedarían así:
| Etiqueta | False | True |
|---|---|---|
| Count | 750 | 250 |
Y:
| Etiqueta | Person | Animal | Árbol |
|---|---|---|---|
| Count | 200 | 400 | 100 |
Consulta de las predicciones
Podemos examinar las predicciones que realiza el modelo igual que observamos las etiquetas reales de nuestros datos. Por ejemplo, podríamos ver que, en el conjunto de pruebas, nuestro modelo predijo "false" 700 veces y "true" 300 veces.
| Predicción de modelos | Count |
|---|---|
| False | 700 |
| True | 300 |
Proporciona información directa sobre las predicciones que realiza nuestro modelo, pero no nos dice cuáles de ellas son correctas. Aunque podemos usar una función de costo para comprender la frecuencia con la que se dan las respuestas correctas, la función de costo no nos dirá qué tipos de errores se están cometiendo. Por ejemplo, el modelo podría adivinar correctamente todos los valores "true", pero también adivinar "true" cuando debería haber adivinado "false".
La matriz de confusión
La clave para comprender el rendimiento del modelo es combinar la tabla de predicción del modelo con la tabla de etiquetas de datos reales:
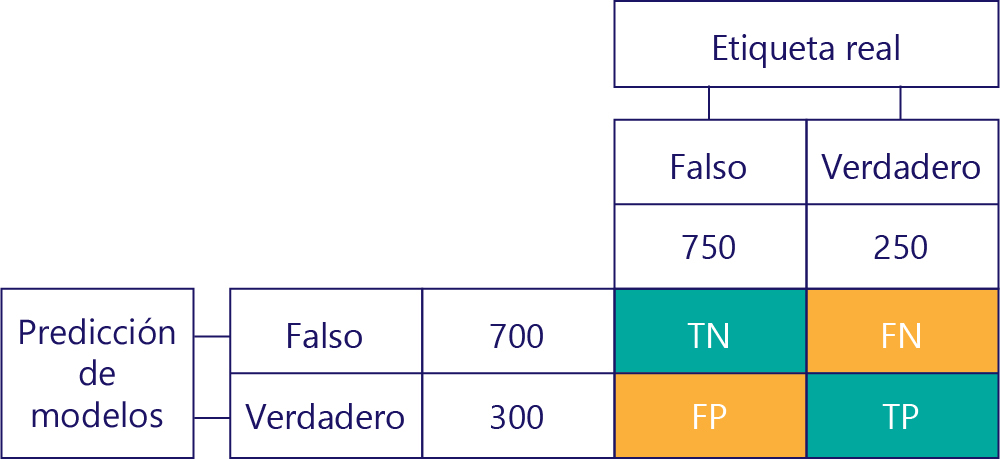
El cuadrado que no hemos rellenado se denomina matriz de confusión.
Cada celda de la matriz de confusión nos indica algo sobre el rendimiento del modelo. Se trata de verdaderos negativos (VN), falsos negativos (FN), falsos positivos (FP) y verdaderos positivos (VP).
Vamos a explicar estos acrónimos uno por uno y a reemplazarlos por valores reales. Los cuadrados azules-verdes significan que el modelo hizo una predicción correcta y, los cuadrados naranjas, que el modelo hizo una predicción incorrecta.
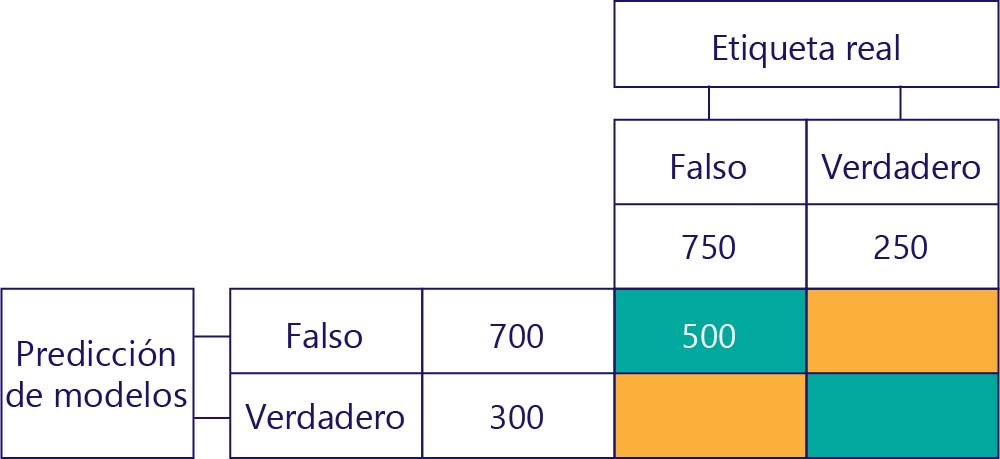
Verdaderos negativos (VN)
El valor superior izquierdo mostrará el número de veces que el modelo predijo "false y la etiqueta real también fue "false". En otras palabras, se muestra cuántas veces el modelo predijo correctamente "false". Supongamos que, en nuestro ejemplo, esto ha ocurrido 500 veces:
Falsos negativos (FN)
El valor superior derecho indica cuántas veces el modelo predijo "false", pero la etiqueta real fue "true". Ahora sabemos que son 200. ¿Cómo lo hago? Dado que el modelo predijo "false" 700 veces y 500 de esas veces lo hizo correctamente. Por lo tanto, 200 veces debe haber predicho "false" cuando no debería haberlo hecho.

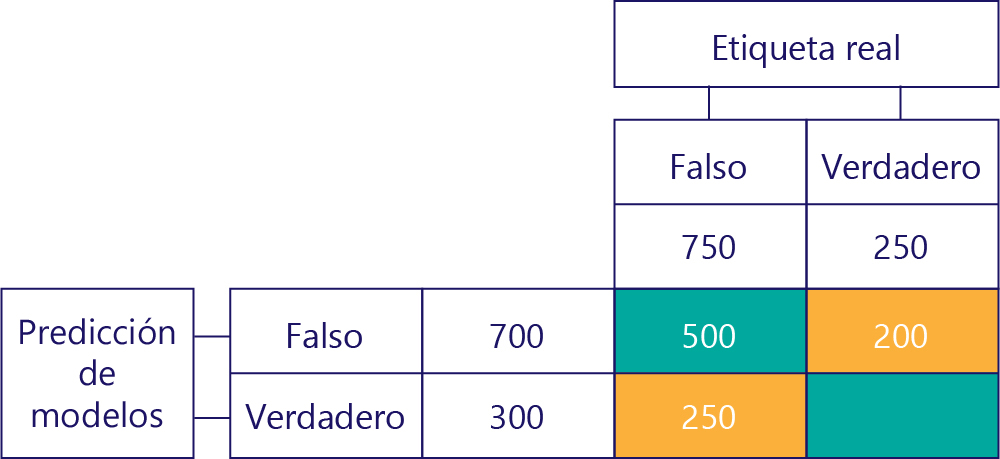
Falsos positivos (FP)
El valor inferior izquierdo contiene falsos positivos. Esto nos indica cuántas veces predijo el modelo "true", pero la etiqueta real era "false". Ahora sabemos que son 250, porque hubo 750 veces que la respuesta correcta fue "false". 500 de estas veces aparecen en la celda superior izquierda (VN):
Verdaderos positivos (VP)
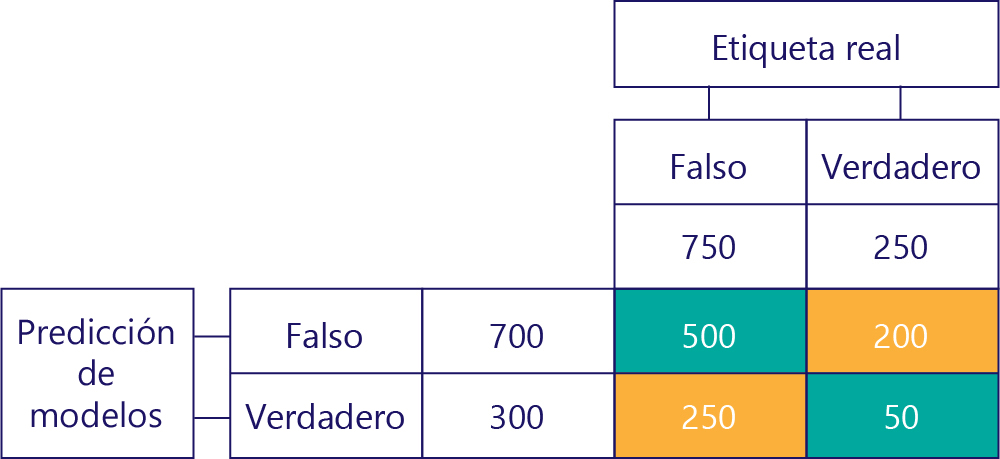
Por último, tenemos verdaderos positivos. Este es el número de veces que el modelo predijo correctamente "true". Sabemos que son 50 por dos motivos. En primer lugar, el modelo predijo "true" 300 veces, pero 250 veces fue incorrecto (celda inferior izquierda). En segundo lugar, había 250 veces que la respuesta correcta fue "true", pero 200 veces el modelo predijo "false".
La matriz final
Normalmente, simplificamos ligeramente nuestra matriz de confusión, de la siguiente manera:
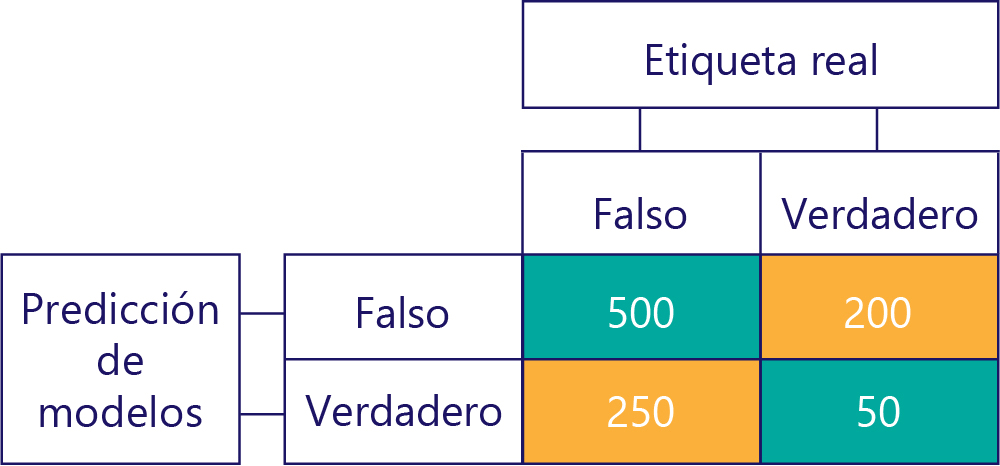
Hemos coloreado las celdas para resaltar cuándo el modelo realizó predicciones correctas. A partir de esto, sabemos no solo la frecuencia con la que el modelo realizó determinados tipos de predicciones, sino también la frecuencia con la que esas predicciones fueron correctas o incorrectas.
Las matrices de confusión también se pueden construir cuando hay más etiquetas. Por ejemplo, para nuestro ejemplo de persona, animal o árbol, podríamos obtener una matriz como esta:
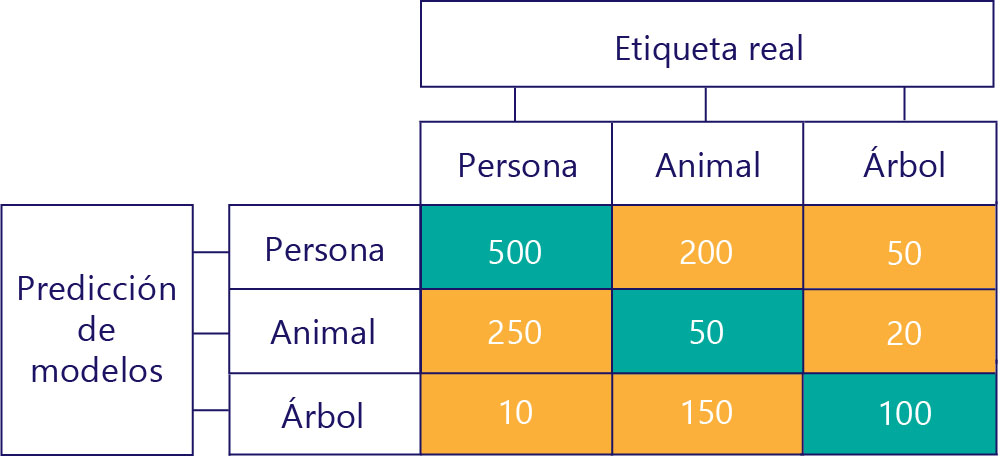
Cuando hay tres categorías, ya no se aplican métricas como verdaderos positivos, pero todavía podemos ver exactamente con qué frecuencia el modelo ha cometido ciertos tipos de errores. Por ejemplo, podemos ver que el modelo predijo esa "persona" 200 veces cuando el resultado correcto real fue "animal".