Funciones de costo frente a métricas de evaluación
En las últimas unidades hemos empezado a ver una división en las funciones de costo, que enseña el modelo, y las métricas de evaluación, que es cómo evaluamos el modelo nosotros mismos.
Todas las funciones de costo pueden ser métricas de evaluación
Todas las funciones de costo pueden ser métricas de evaluación, aunque no necesariamente intuitivas. Pérdida logarítmica, por ejemplo: los valores no son intuitivos.
Algunas métricas de evaluación no pueden ser funciones de costo.
- Es difícil que algunas métricas de evaluación se conviertan en funciones de costo.
- Esto se debe a restricciones prácticas y matemáticas.
- A veces, las cosas no son fáciles de calcular (por ejemplo, "lo perruno que es algo").
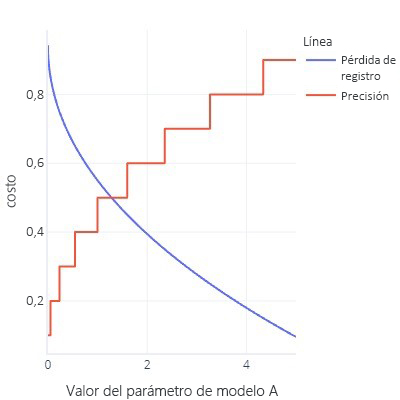
- Las funciones de costo son idealmente suaves. Por ejemplo, la precisión es útil, pero si cambiamos ligeramente el modelo, no se notará. Dado que el ajuste es un procedimiento con muchos cambios pequeños, da la impresión de que las modificaciones no llevarán a la mejora.
- Gráfico de función de costo con una gran cantidad de bits planos
- Actualice las curvas ROC de antes. Para ello, es necesario cambiar el umbral a todo tipo de valores, pero al final del día, nuestro modelo solo tendrá uno (0,5).
No todo es malo.
Puede ser frustrante descubrir que no podemos utilizar nuestra métrica favorita como función de costo. Pero hay un aspecto positivo, que está relacionado con el hecho de que todas las métricas son simplificaciones de lo que queremos conseguir; ninguna es perfecta. Lo que esto significa es que los modelos complejos a menudo "hacen trampa": encuentran una manera de obtener costos bajos sin encontrar realmente una regla general que resuelva nuestro problema. Tener una métrica que no actúe como función de costo nos permite realizar una "comprobación de integridad" de que el modelo no ha encontrado la forma de hacer trampas. Si sabemos que un modelo está tomando atajos, podemos replantear nuestra estrategia de entrenamiento.
Ya hemos visto este "engaño" varias veces. Por ejemplo, cuando los modelos sobreajustan los datos de entrenamiento, básicamente están "memorizando" las respuestas correctas en lugar de encontrar una regla general que podamos aplicar con éxito a otros datos. Utilizamos conjuntos de datos de prueba como "comprobación de integridad" para verificar que el modelo no acaba de hacer esto. También hemos visto que, con datos desequilibrados, los modelos pueden aprender a dar siempre la misma respuesta (por ejemplo, "false") sin tener en cuenta las características, porque, por término medio, esto es correcto y proporciona un pequeño error.
Los modelos complejos también encuentran atajos de otras maneras. A veces, los modelos complejos pueden sobreajustar la propia función de costo. Por ejemplo, imaginemos que intentamos construir un modelo que pueda dibujar perros. Tenemos una función de costo que comprueba que la imagen es marrón, muestra una textura peluda y contiene un objeto del tamaño adecuado. Con esta función de costo, un modelo complejo podría aprender a crear una bola de pelo marrón, no porque se parezca a un perro, sino porque proporciona un costo bajo y es fácil de generar. Si tenemos una métrica externa que cuente el número de patas y cabezas (lo que no se puede utilizar fácilmente como función de costo porque no son métricas suaves), nos daremos cuenta rápidamente de si nuestro modelo está haciendo trampas, y nos replantearemos cómo lo estamos entrenando. Por el contrario, si nuestra métrica alternativa obtiene una buena puntuación, podemos tener cierta confianza en que el modelo ha captado la idea de cómo debe ser un perro, en lugar de limitarse a engañar a la función de costo para obtener un valor bajo.