Regresión lineal múltiple y R cuadrado
En esta unidad, se contrastará la regresión lineal múltiple con la regresión lineal simple. También veremos una métrica llamada R2, que se usa normalmente para evaluar la calidad de un modelo de regresión lineal.
Regresión lineal múltiple
La regresión lineal múltiple modela la relación entre varias características y una sola variable. Matemáticamente, es lo mismo que la regresión lineal simple y normalmente se ajusta con la misma función de costo, pero con más características.
En lugar de modelar una sola relación, esta técnica modela simultáneamente varias relaciones, que se tratan como independientes entre sí. Por ejemplo, si predecimos cuán enfermo se pone un perro en función de los parámetros age y body_fat_percentage, se encuentran dos relaciones:
- Cómo age aumenta o reduce la posibilidad de enfermedad
- Cómo body_fat_percentage aumenta o reduce la posibilidad de enfermedad
Si solo estamos trabajando con dos características, podemos visualizar nuestro modelo como una superficie 2D plana, igual que podemos modelar la regresión lineal simple como una línea. Exploraremos esto en el siguiente ejercicio.
La regresión lineal múltiple tiene suposiciones
El hecho de que el modelo espere que las características sean independientes se denomina suposición de modelo. Cuando las suposiciones del modelo no son ciertas, las predicciones del modelo pueden ser erróneas.
Por ejemplo, la edad probablemente predice cuán enfermos se ponen los perros, ya que los perros mayores enferman más, junto con el hecho de si a los perros se les ha enseñado a jugar al frisbi; probablemente todos los perros mayores sepan jugar al frisbi. Si incluyéramos los parámetros age y knows_frisbee en nuestro modelo como características, es probable que el resultado fuera que knows_frisbee es un buen indicador de enfermedad y que se subestima la importancia de age. Esto es un poco absurdo, porque saber jugar al frisbi seguramente no causa enfermedades. Por el contrario, dog_breed puede también ayudarnos a predecir enfermedades, pero no hay ninguna razón para pensar que age predice dog_breed, por lo que podríamos incluirlos en un solo modelo.
Bondad de ajuste: R2
Sabemos que se pueden usar funciones de costo para evaluar cómo un modelo se ajusta a los datos sobre los que se entrena. Los modelos de regresión lineal tienen una medida relacionada especial llamada R2 (R cuadrado). R2 es un valor entre 0 y 1 que nos indica cómo se ajusta un modelo de regresión lineal a los datos. Cuando se habla de que las correlaciones son sólidas, a menudo quiere decir que el valor de R2 era grande.
R2 usa las matemáticas más allá de todo aquello de lo que hablamos en este curso, pero podemos pensar en ello de forma intuitiva. Fijémonos en el ejercicio anterior en el que analizamos la relación entre age y core_temperature. Un R2 de 1 significaría que se podrían usar los años para predecir perfectamente quién tenía temperatura alta y quién la tenía baja. Por el contrario, un 0 significaría simplemente que no había ninguna relación entre los años y la temperatura.
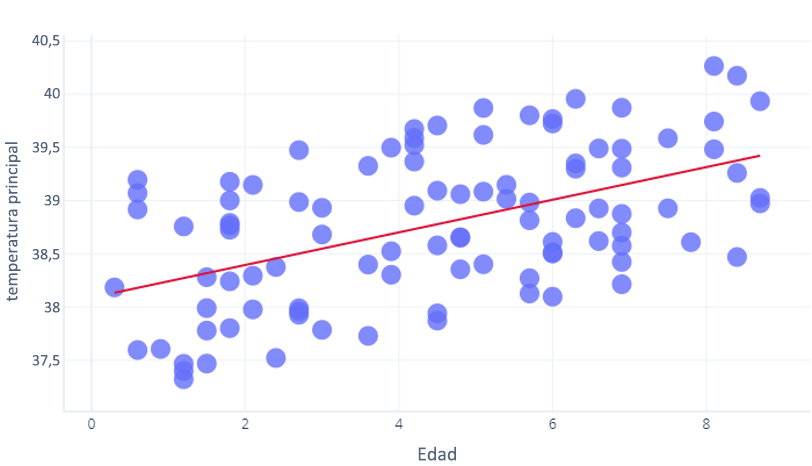
La realidad está en algún lugar intermedio. Nuestro modelo podría predecir la temperatura hasta cierto grado (por lo que es mejor que R2 = 0), pero los puntos variaron ligeramente con respecto a esta predicción (por lo que es menor que R2 = 1).
R2 es solo la mitad de la historia.
Los valores de R2 se aceptan ampliamente, pero no son una medida perfecta que podamos usar de forma aislada. Estos valores sufren cuatro limitaciones:
- Debido a cómo se calcula R2, cuantas más muestras tenemos, mayor será el R2. Esto puede hacer que pensemos que un modelo es mejor que otro modelo (idéntico), simplemente porque los valores de R2 se calcularon con diferentes cantidades de datos.
- Los valores de R2 no nos dicen cómo funcionará un modelo con datos nuevos y no vistos anteriormente. Los estadísticos lo superan al calcular una medida complementaria, llamada valor P, de la que no vamos a hablar. En el aprendizaje automático, a menudo se prueba explícitamente el modelo en otro conjunto de datos.
- Los valores de R2 no nos dicen la dirección de la relación. Por ejemplo, un valor de R2 de 0,8 no nos indica si la línea está inclinada hacia arriba o hacia abajo. Tampoco nos dice el grado de inclinación de la línea.
También vale la pena tener en cuenta que no hay criterios universales para lo que hace que un valor R2 sea "lo suficientemente bueno". Por ejemplo, en la mayoría de la física, es poco probable que las correlaciones que no estén muy cercanas a 1 se consideren útiles, pero al modelar sistemas complejos, los valores de R2 tan bajos como 0,3 podrían considerarse excelentes.