Resistencia y alta disponibilidad en microservicios
Sugerencia
Este contenido es un extracto del libro electrónico, ".NET Microservices Architecture for Containerized .NET Applications" (Arquitectura de microservicios de .NET para aplicaciones de .NET contenedorizadas), disponible en Documentación de .NET o como un PDF descargable y gratuito que se puede leer sin conexión.

Tratar errores inesperados es uno de los problemas más difíciles de resolver, especialmente en un sistema distribuido. Gran parte del código que los desarrolladores escriben implica controlar las excepciones, y aquí también es donde se dedica más tiempo a las pruebas. El problema es más complejo que escribir código para controlar los errores. ¿Qué ocurre cuando se produce un error en la máquina en que se ejecuta el microservicio? No solo es necesario detectar este error de microservicio (un gran problema de por sí), sino también contar con algo que reinicie su microservicio.
Un microservicio debe ser resistente a errores y poder reiniciarse a menudo en otra máquina a efectos de disponibilidad. Esta resistencia también se refiere al estado que se guardó en nombre del microservicio, en los casos en que el estado se puede recuperar a partir del microservicio, y al hecho de si el microservicio puede reiniciarse correctamente. En otras palabras, debe haber resistencia en la capacidad de proceso (el proceso puede reiniciarse en cualquier momento), así como en el estado o los datos (sin pérdida de datos y que se mantenga la consistencia de los datos).
Los problemas de resistencia se agravan durante otros escenarios, como cuando se producen errores durante la actualización de una aplicación. El microservicio, trabajando con el sistema de implementación, debe determinar si puede avanzar a la versión más reciente o, en su lugar, revertir a una versión anterior para mantener un estado consistente. Deben tenerse en cuenta cuestiones como si están disponibles suficientes máquinas para seguir avanzando y cómo recuperar versiones anteriores del microservicio. Este enfoque requiere que el microservicio emita información sobre el estado para que la aplicación en conjunto y el orquestador puedan tomar estas decisiones.
Además, la resistencia está relacionada con cómo deben comportarse los sistemas basados en la nube. Como se ha mencionado, un sistema basado en la nube debe estar preparado para los errores e intentar recuperarse automáticamente de ellos. Por ejemplo, en caso de errores de red o de contenedor, las aplicaciones de cliente o los servicios de cliente deben disponer de una estrategia para volver a intentar enviar mensajes o solicitudes, ya que en muchos casos, los errores en la nube son parciales. En la sección Implementar aplicaciones resistentes de esta guía se explica cómo controlar errores parciales. Se describen técnicas como los reintentos con retroceso exponencial o el patrón de interruptor en .NET mediante el uso de bibliotecas como Polly, que ofrece una gran variedad de directivas para controlar este asunto.
Administración del estado y diagnóstico en microservicios
Puede parecer obvio, y a menudo se pasa por alto, pero un microservicio debe notificar su estado y diagnóstico. En caso contrario, hay poca información desde una perspectiva operativa. Correlacionar eventos de diagnóstico en un conjunto de servicios independientes y tratar los desajustes en el reloj de la máquina para dar sentido al orden de los eventos suponen un reto. De la misma manera que interactúa con un microservicio según protocolos y formatos de datos acordados, hay una necesidad de estandarizar cómo registrar los eventos de estado y diagnóstico que, en última instancia, terminan en un almacén de eventos para que se consulten y se vean. En un enfoque de microservicios, es fundamental que distintos equipos se pongan de acuerdo en un formato de registro único. Debe haber un enfoque coherente para ver los eventos de diagnóstico en la aplicación.
Comprobaciones de estado
El estado es diferente del diagnóstico. El estado trata de cuando el microservicio informa sobre su estado actual para que se tomen las medidas oportunas. Un buen ejemplo es trabajar con los mecanismos de actualización e implementación para mantener la disponibilidad. Aunque un servicio podría actualmente estar en mal estado debido a un bloqueo de proceso o un reinicio de la máquina, puede que el servicio siga siendo operativo. Lo último que debe hacer es realizar una actualización que empeore esta situación. El mejor método consiste en realizar una investigación en primer lugar o dar tiempo a que el microservicio se recupere. Los eventos de estado de un microservicio nos ayudan a tomar decisiones informadas y, en efecto, ayudan a crear servicios de reparación automática.
En la sección Implementación de comprobaciones de estado en servicios de ASP.NET Core de esta guía se explica cómo usar una nueva biblioteca de ASP.NET HealthChecks en sus microservicios para que puedan informar sobre su estado a un servicio de supervisión para que se tomen las medidas oportunas.
También tiene la opción de usar una biblioteca de código abierto excelente llamada AspNetCore.Diagnostics.HealthChecks, que está disponible en GitHub y como un paquete NuGet. Además, la biblioteca realiza comprobaciones de estado, concretamente de dos tipos:
- Ejecución: comprueba si el microservicio se está ejecutando, es decir, si puede aceptar solicitudes y responder a estas.
- Preparación: comprueba si las dependencias del microservicio, como la base de datos o los servicios de cola, están listas, de modo que el microservicio pueda funcionar como debería.
Utilización de secuencias de eventos de diagnóstico y registro
Los registros ofrecen información sobre cómo se ejecuta una aplicación o un servicio, incluidos las excepciones, las advertencias y los mensajes informativos simples. Normalmente, cada registro se presenta en un formato de texto con una línea por evento, aunque las excepciones también suelen mostrar el seguimiento de la pila en varias líneas.
En las aplicaciones monolíticas basadas en servidor, puede escribir registros en un archivo en disco (un archivo de registro) y, luego, analizarlo con cualquier herramienta. Puesto que la ejecución de la aplicación se limita a un servidor o una máquina virtual fijos, por lo general no es demasiado complejo analizar el flujo de eventos. Sin embargo, en una aplicación distribuida en que se ejecutan varios servicios a través de muchos nodos en un clúster de orquestador, poder correlacionar los eventos distribuidos supone un reto.
Una aplicación basada en microservicio no debe intentar almacenar la secuencia de salida de eventos o archivos de registro por sí misma y ni siquiera intentar administrar el enrutamiento de los eventos a una ubicación central. Debe ser transparente, lo que significa que cada proceso solo debe escribir su secuencia de eventos en una salida estándar que la infraestructura de entorno de ejecución donde se está ejecutando recopilará por debajo. Un ejemplo de estos enrutadores de secuencia de eventos es Microsoft.Diagnostic.EventFlow, que recopila secuencias de eventos de varios orígenes y las publica en sistemas de salida. Estos pueden incluir salidas estándar simples para un entorno de desarrollo, o sistemas en la nube como Azure Monitor y Azure Diagnostics. También hay buenas plataformas y herramientas de análisis de registros de otros fabricantes que pueden buscar, alertar, informar y supervisar registros, incluso en tiempo real, como Splunk.
Cómo los orquestadores administran la información sobre el estado y el diagnóstico
Crear una aplicación basada en microservicio implica enfrentarse a cierto grado de complejidad. Por supuesto, un único microservicio es fácil de tratar, pero docenas o cientos de tipos y miles de instancias de microservicios es un problema complejo. No solo se trata de crear la arquitectura del microservicio; también necesita alta disponibilidad, capacidad de direccionamiento, resistencia, estado y diagnóstico si pretende disponer de un sistema estable y cohesivo.
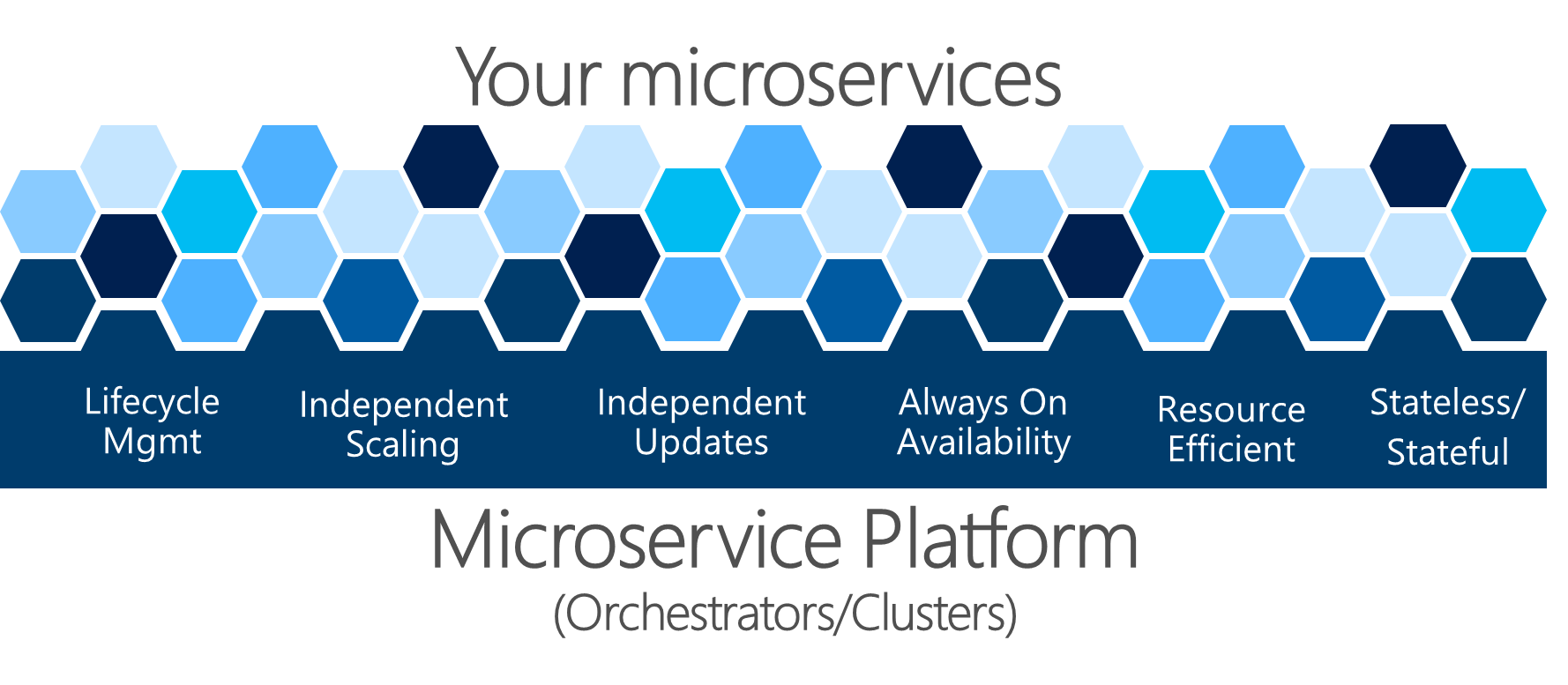
Figura 4-22. Una plataforma de microservicio es fundamental para la administración del estado de una aplicación
Es difícil que pueda resolver por su cuenta los problemas complejos que se muestran en la figura 4-22. Los equipos de desarrollo deben centrarse en solucionar problemas empresariales y crear aplicaciones personalizadas con enfoques basados en microservicio. No deben centrarse en solucionar problemas de infraestructura complejos; si fuera así, el coste de cualquier aplicación basada en microservicio sería enorme. Por tanto, hay plataformas orientadas a microservicios, denominadas orquestadores o clústeres de microservicio, que tratan de solucionar los problemas complejos de crear y ejecutar un servicio y usar de forma eficaz los recursos de infraestructura. Este enfoque reduce las complejidades de crear aplicaciones que usan un enfoque de microservicios.
Distintos orquestadores podrían parecer similares, pero las comprobaciones de diagnóstico y estado que ofrece cada uno de ellos difieren en las características y el estado de madurez, y a veces dependen de la plataforma del sistema operativo, como se explica en la sección siguiente.
Recursos adicionales
La aplicación Twelve-Factor. XI. Logs: Treat logs as event streams (Registros: tratar los registros como secuencias de eventos)
https://12factor.net/logsRepositorio de GitHub Microsoft Diagnostic EventFlow Library.
https://github.com/Azure/diagnostics-eventflow¿Qué es Azure Diagnostics?
https://learn.microsoft.com/azure/azure-diagnosticsConectar equipos Windows con el servicio Azure Monitor
https://learn.microsoft.com/azure/azure-monitor/platform/agent-windowsRegistrar lo importante: usar el bloque de aplicación de registro semántico
https://learn.microsoft.com/previous-versions/msp-n-p/dn440729(v=pandp.60)Sitio oficial de Splunk.
https://www.splunk.com/API EventSource Class para el seguimiento de eventos para Windows (ETW)
https://learn.microsoft.com/dotnet/api/system.diagnostics.tracing.eventsource
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de