Planeamiento de capacidad para Active Directory Domain Services
Este tema está escrito originalmente por Ken Brumfield, Responsable de programas de Microsoft y proporciona recomendaciones para el planeamiento de capacidad para Active Directory Domain Services (AD DS).
Objetivos del planeamiento de capacidad
El planeamiento de capacidad no es lo mismo que la solución de problemas de incidentes de rendimiento. Están estrechamente relacionados, pero son muy diferentes. Los objetivos del planeamiento de capacidad son:
- Implementación y funcionamiento correctos de un entorno
- Minimización el tiempo dedicado a solucionar problemas de rendimiento.
En el planeamiento de capacidad, una organización podría tener un objetivo de línea base de uso del procesador del 40 % durante los períodos máximos para satisfacer los requisitos de rendimiento del cliente y adaptarse al tiempo necesario para actualizar el hardware en el centro de datos. Mientras que, para recibir notificaciones de incidentes de rendimiento anómalos, se podría establecer un umbral de alerta de supervisión en el 90 % durante un intervalo de 5 minutos.
La diferencia es que cuando se supera continuamente un umbral de administración de capacidad (un evento único no es un problema), agregar capacidad (es decir, agregar más procesadores o más rápidos) sería una solución o escalar el servicio entre varios servidores sería una solución. Los umbrales de alerta de rendimiento indican que la experiencia del cliente está sufriendo actualmente y se necesitan pasos inmediatos para solucionar el problema.
Como analogía: la administración de la capacidad consiste en prevenir un accidente de automóvil (conducción defensiva, asegurarse de que los frenos funcionen correctamente, etc.), mientras que la solución de problemas de rendimiento es lo que hacen la policía, el departamento de bomberos y los profesionales médicos de emergencias después de un accidente. Esto tema trata sobre "conducción defensiva", al estilo de Active Directory.
En los últimos años, la guía de planeamiento de capacidad para el escalado vertical de los sistemas ha cambiado drásticamente. Los siguientes cambios en las arquitecturas del sistema han desafiado las suposiciones fundamentales sobre el diseño y el escalado de un servicio:
- Plataformas de servidor de 64 bits
- Virtualización
- Mayor atención al consumo de energía
- Almacenamiento en SSD
- Escenarios de nube
Además, el enfoque cambia de un ejercicio de planeamiento de capacidad basado en servidores a un ejercicio de planeamiento de capacidad basado en servicios. Active Directory Domain Services (AD DS), un servicio distribuido y maduro que muchos productos de Microsoft y de terceros usan como back-end, se convierten en uno de los productos más críticos en cuanto a su correcto planeamiento para garantizar la capacidad necesaria para que se ejecuten otras aplicaciones.
Requisitos de línea base para la guía de planeamiento de capacidad
A lo largo de este artículo, se esperan los siguientes requisitos de línea base:
- Los lectores han leído y están familiarizados con el documento Directrices de optimización del rendimiento para Windows Server 2012 R2.
- La plataforma Windows Server es una arquitectura basada en x64. Pero incluso si el entorno de Active Directory está instalado en Windows Server 2003 x86 (ahora más allá del final del ciclo de vida de soporte técnico) y tiene un árbol de información de directorio (DIT) que tiene menos de 1,5 GB de tamaño y que se puede mantener fácilmente en memoria, las directrices de este artículo siguen siendo aplicables.
- El planeamiento de capacidad es un proceso continuo y se debe revisar periódicamente cómo cumple el entorno las expectativas.
- La optimización se producirá en varios ciclos de vida del hardware a medida que cambian los costos del hardware. Por ejemplo, la memoria se vuelve más barata, el costo por núcleo disminuye o cambia el precio de las distintas opciones de almacenamiento.
- Planee teniendo en cuenta el período de actividad máxima del día. Se recomienda examinarlo en intervalos de 30 minutos o de una hora. Un intervalo mayor puede ocultar los picos reales y uno menor puede verse distorsionado por "picos transitorios".
- Planee teniendo en cuenta el crecimiento durante el ciclo de vida del hardware para la empresa. Esto puede incluir una estrategia de actualización o adición de hardware de forma escalonada o una actualización completa cada tres a cinco años. Cada uno necesitará una "estimación" del crecimiento de la carga en Active Directory. Los datos históricos, si se han recopilado, le ayudarán con esta evaluación.
- Planee teniendo en cuenta la tolerancia a errores. Una vez que se llega a una estimación de N, planee escenarios que incluyan N – 1, N – 2, N – x.
Agregue servidores adicionales según la necesidad de la organización de asegurarse de que la pérdida de uno o varios servidores no supere las estimaciones máximas de capacidad máxima.
Tenga en cuenta también que es necesario integrar el plan de crecimiento y el plan de tolerancia a errores. Por ejemplo, si se requiere un controlador de dominio para admitir la carga, pero la estimación es que la carga se duplicará en el próximo año y requerirá dos controladores de dominio en total, no habrá suficiente capacidad para admitir la tolerancia a errores. La solución sería empezar con tres controladores de dominio. También se podría planear agregar el tercer controlador de dominio después de 3 o 6 meses si los presupuestos están ajustados.
Nota
Agregar aplicaciones compatibles con Active Directory podría tener un impacto notable en la carga del controlador de dominio, tanto si la carga procede de los servidores de aplicaciones como de los clientes.
Proceso de tres pasos para el ciclo de planeamiento de capacidad
En el planeamiento de capacidad, decida primero qué calidad de servicio se necesita. Por ejemplo, un centro de datos principal admite un mayor nivel de simultaneidad y requiere una experiencia más coherente para los usuarios y las aplicaciones que lo consumen, lo que requiere una mayor atención a la redundancia y minimizar los cuellos de botella de la infraestructura y del sistema. Por el contrario, una ubicación satélite con unos pocos usuarios no necesita el mismo nivel de simultaneidad y tolerancia a errores. Por lo tanto, es posible que la oficina satélite no necesite tanta atención para optimizar el hardware y la infraestructura subyacentes, lo que puede dar lugar a un ahorro de costos. Todas las recomendaciones y directrices que se indican aquí son para un rendimiento óptimo y se pueden relajar selectivamente para escenarios con requisitos menos exigentes.
La siguiente pregunta es: ¿virtualizado o físico? Desde la perspectiva del planeamiento de capacidad, no hay ninguna respuesta correcta o incorrecta; solo hay un conjunto diferente de variables con el que trabajar. Los escenarios de virtualización se reducen a una de estas dos opciones:
- "Asignación directa" con un invitado por host (donde la virtualización existe únicamente para abstraer el hardware físico del servidor)
- "Host compartido"
Los escenarios de pruebas y producción indican que el escenario de "asignación directa" se puede tratar de forma idéntica a un host físico. Sin embargo, el "host compartido" presenta una serie de consideraciones descritas con más detalle más adelante. El escenario de "host compartido" significa que AD DS también compite por los recursos y hay penalizaciones y consideraciones de optimización para hacerlo.
Teniendo en cuenta estas consideraciones, el ciclo de planeamiento de capacidad es un proceso iterativo de tres pasos:
- Medir el entorno existente, determinar dónde se encuentran actualmente los cuellos de botella del sistema y obtener los aspectos básicos del entorno necesarios para planear la cantidad de capacidad necesaria.
- Determinar el hardware necesario según los criterios descritos en el paso 1.
- Supervisar y validar que la infraestructura implementada funcione dentro de las especificaciones. Algunos datos recopilados en este paso se convierten en la línea base del siguiente ciclo de planeamiento de capacidad.
Aplicación del proceso
Para optimizar el rendimiento, asegúrese de que estos componentes principales estén seleccionados y optimizados correctamente para las cargas de las aplicaciones:
- Memoria
- Red
- Storage
- Procesador
- Net Logon
Los requisitos de almacenamiento básicos de AD DS y el comportamiento general del software cliente bien escrito permiten entornos de 10 000 a 20 000 usuarios para evitar una gran inversión en el planeamiento de capacidad con respecto al hardware físico, ya que casi cualquier sistema moderno de clase servidor controlará la carga. Dicho esto, la tabla siguiente resume cómo evaluar un entorno existente para seleccionar el hardware correcto. Cada componente se analiza en detalle en secciones posteriores para ayudar a los administradores de AD DS a evaluar su infraestructura mediante recomendaciones de línea base y principios específicos del entorno.
En general:
- Cualquier dimensionamiento basado en los datos actuales solo será preciso para el entorno actual.
- En el caso de las estimaciones, espere que la demanda crezca durante el ciclo de vida del hardware.
- Determine si aumentar el tamaño hoy y crecer en un entorno más grande, o agregar capacidad a lo largo del ciclo de vida.
- Para la virtualización, se aplican todos los mismos principios y metodologías de planeamiento de capacidad, salvo que se debe agregar la sobrecarga de la virtualización a cualquier cosa relacionada con el dominio.
- El planeamiento de capacidad, como cualquier cosa que intenta hacer predicciones, no es una ciencia precisa. No espere que las cosas se calculen perfectamente y con una precisión del 100 %. Las instrucciones aquí son la recomendación más ajustada; agregue capacidad para mayor seguridad y valide continuamente que el entorno permanece en el objetivo.
Tablas de resumen de recopilación de datos
Nuevo entorno
| Componente | Estimaciones |
|---|---|
| Tamaño de almacenamiento y base de datos | De 40 KB a 60 KB por cada usuario |
| RAM | Tamaño de base de datos Recomendaciones de sistema operativo base Aplicaciones de terceros |
| Red | 1 GB |
| CPU | 1000 usuarios simultáneos por cada núcleo |
Criterios generales de evaluación
| Componente | Criterios de evaluación | Consideraciones de planeamiento |
|---|---|---|
| Tamaño de almacenamiento y base de datos | La sección titulada "Para activar el registro del espacio en disco que se libera mediante la desfragmentación" de Límites de almacenamiento | |
| Rendimiento del almacenamiento y la base de datos |
|
|
| RAM |
|
|
| Red |
|
|
| CPU |
|
|
| NetLogon |
|
|
Planificación
Durante mucho tiempo, la recomendación de la comunidad para el dimensionamiento de AD DS ha sido "poner tanta RAM como el tamaño de la base de datos". Por lo general, esa recomendación es todo por lo que deben preocuparse la mayoría de los entornos. Pero el ecosistema que consume AD DS se ha vuelto mucho más grande, como los propios entornos de AD DS, desde su introducción en 1999. Aunque el aumento de la potencia de proceso y el cambio de arquitecturas x86 a arquitecturas x64 ha hecho que los aspectos más sutiles del ajuste de tamaño para el rendimiento no sean pertinentes para un conjunto mayor de clientes que ejecutan AD DS en hardware físico, el crecimiento de la virtualización ha vuelto a introducir las preocupaciones de optimización a un público mayor que antes.
Por lo tanto, las instrucciones siguientes tratan sobre cómo determinar y planear las demandas de Active Directory como servicio, independientemente de si se implementa en un escenario físico, una combinación de virtual y físico, o un escenario puramente virtualizado. Por lo tanto, desglosaremos la evaluación en cada uno de los cuatro componentes principales: almacenamiento, memoria, red y procesador. En resumen, para maximizar el rendimiento en AD DS, el objetivo es acercarse lo más posible al límite del procesador.
RAM
Simplemente, cuanto más se pueda almacenar en caché en RAM, menos necesario es acceder al disco. Para maximizar la escalabilidad del servidor, la cantidad mínima de RAM debe ser la suma del tamaño de la base de datos actual, el tamaño total de SYSVOL, la cantidad recomendada del sistema operativo y las recomendaciones del proveedor para los agentes (antivirus, supervisión, copia de seguridad, etc.). Se debe agregar una cantidad adicional para dar cabida al crecimiento durante la vida útil del servidor. Esto será subjetivo del entorno en función de las estimaciones de crecimiento de la base de datos en función de los cambios del entorno.
En entornos en los que maximizar la cantidad de RAM no es rentable (por ejemplo, una ubicación satélite) o no es factible (el DIT es demasiado grande), consulte la sección Almacenamiento para asegurarse de que el almacenamiento se haya diseñado adecuadamente.
Un corolario que aparece en el contexto general del dimensionamiento de la memoria es el dimensionamiento del archivo de paginación. En el mismo contexto que todo lo demás relacionado con la memoria, el objetivo es minimizar el acceso al disco, que es mucho más lento. Por lo tanto, la pregunta debe pasar de "¿cómo se debe ajustar el tamaño del archivo de paginación?" a "¿cuánta RAM se necesita para minimizar la paginación?" La respuesta a esta última pregunta se describe en el resto de esta sección. Esto deja la mayor parte de la discusión sobe el dimensionamiento del archivo de paginación al campo de las recomendaciones generales del sistema operativo y la necesidad de configurar el sistema para volcados de memoria, que no están relacionados con el rendimiento de AD DS.
Evaluando
La cantidad de RAM que necesita un controlador de dominio (DC) es realmente un ejercicio complejo por estas razones:
- Alta posibilidad de error al intentar usar un sistema existente para medir la cantidad de RAM necesaria, ya que LSASS lo truncará en condiciones de presión de memoria, desinflando artificialmente la necesidad.
- El hecho subjetivo es que un controlador de dominio individual solo necesita almacenar en caché lo que es "interesante" para sus clientes. Esto significa que los datos que se deben almacenar en caché en un controlador de dominio de un sitio que solo tiene un servidor Exchange serán muy diferentes de los datos que se deben almacenar en caché en un controlador de dominio que solo autentique a los usuarios.
- El trabajo de evaluar la RAM para cada controlador de dominio caso a caso es prohibitivo y cambia a medida que cambia el entorno.
- Los criterios subyacentes a la recomendación ayudarán a tomar decisiones fundamentadas:
- Cuanto más se pueda almacenar en caché en RAM, menos necesario es acceder al disco.
- El almacenamiento es con mucho el componente más lento de un equipo. El acceso a los datos en medios de almacenamiento basados en eje y en SSD se encuentra en el orden de 1 000 000 de veces más lento que el acceso a los datos de la memoria RAM.
Por lo tanto, para maximizar la escalabilidad del servidor, la cantidad mínima de RAM es la suma del tamaño de la base de datos actual, el tamaño total de SYSVOL, la cantidad recomendada del sistema operativo y las recomendaciones del proveedor para los agentes (antivirus, supervisión, copia de seguridad, etc.). Agregue cantidades adicionales para dar cabida al crecimiento durante la vida útil del servidor. Esto será subjetivo del entorno en función de las estimaciones de crecimiento de la base de datos. Sin embargo, en el caso de las ubicaciones satélite con un pequeño conjunto de usuarios finales, estos requisitos se pueden relajar, ya que estos sitios no tendrán que almacenar en caché tanto para atender la mayoría de las solicitudes.
En entornos en los que maximizar la cantidad de RAM no es rentable (por ejemplo, una ubicación satélite) o no es factible (el DIT es demasiado grande), consulte la sección Almacenamiento para asegurarse de que el almacenamiento tenga el tamaño correcto.
Nota
Un corolario en el dimensionamiento de la memoria es el dimensionamiento del archivo de paginación. Dado que el objetivo es minimizar el uso del disco, que es mucho más lento, la pregunta pasa de "¿cómo se debe dimensionar el archivo de paginación?" a "¿cuánta RAM se necesita para minimizar la paginación?" La respuesta a esta última pregunta se describe en el resto de esta sección. Esto deja la mayor parte de la discusión sobe el dimensionamiento del archivo de paginación al campo de las recomendaciones generales del sistema operativo y la necesidad de configurar el sistema para volcados de memoria, que no están relacionados con el rendimiento de AD DS.
Consideraciones de virtualización para la memoria RAM
Evite la confirmación excesiva de memoria en el host. El objetivo fundamental al optimizar la cantidad de RAM es minimizar la cantidad de tiempo dedicado en el acceso al disco. En escenarios de virtualización, el concepto de confirmación excesiva de memoria se produce cuando se asigna más RAM a los invitados que la que existe en la máquina física. Esto, por sí mismo, no es un problema. Se convierte en un problema cuando la memoria total utilizada activamente por todos los invitados supera la cantidad de RAM del host y el host subyacente comienza a paginar. El rendimiento se convierte en algo relacionado con el disco en los casos en los que el controlador de dominio accede al archivo NTDS.dit para obtener datos, o el controlador de dominio accede al archivo de paginación para obtener datos, o el host accede al disco para obtener datos que el invitado piensa que están en memoria RAM.
Ejemplo de resumen de cálculo
| Componente | Memoria estimada (ejemplo) |
|---|---|
| RAM recomendada para el sistema operativo base (Windows Server 2008) | 2 GB |
| Tareas internas de LSASS | 200 MB |
| Agente de supervisión | 100 MB |
| Antivirus | 100 MB |
| Base de datos (catálogo global) | 8,5 GB |
| Espacio de amortiguación para que se ejecute la copia de seguridad y los administradores inicien sesión sin impacto | 1 GB |
| Total | 12 GB |
Recomendado: 16 GB
A lo largo del tiempo, se puede suponer que se agregarán más datos a la base de datos y el servidor probablemente estará en producción entre 3 y 5 años. En función de una estimación de crecimiento del 33 %, 16 GB serían una cantidad razonable de RAM para poner en un servidor físico. En una máquina virtual, dada la facilidad con la que se puede modificar la configuración y se puede agregar RAM a la máquina virtual, a partir de 12 GB con un plan para supervisar y actualizar en el futuro sería razonable.
Red
Evaluando
Esta sección tiene menos que ver con la evaluación de las demandas relacionadas con el tráfico de replicación, que se centra en el tráfico que atraviesa la WAN y se trata exhaustivamente en Tráfico de replicación de Active Directory, y se trata más de evaluar el ancho de banda total y la capacidad de red necesaria, incluido el de las consultas de cliente, las aplicaciones de directiva de grupo, etc. En el caso de los entornos existentes, esto se puede recopilar mediante los contadores de rendimiento "Network Interface(*)\Bytes Received/sec" y "Network Interface(*)\Bytes Sent/sec". Tome muestras de los contadores de la interfaz de red en intervalos de 15, 30 o 60 minutos. Cualquier intervalo menor generalmente será demasiado volátil para obtener buenas medidas; cualquier intervalo mayor suavizará excesivamente los picos diarios.
Nota
Por lo general, la mayoría del tráfico de red en un controlador de dominio es saliente, ya que el controlador de dominio responde a las consultas de cliente. Esta es la razón de centrarse en el tráfico saliente, aunque se recomienda evaluar también cada entorno para el tráfico entrante. Se pueden usar los mismos enfoques para abordar y revisar los requisitos del tráfico de red entrante. Para obtener más información, consulte el artículo de Knowledge Base 929851: El intervalo predeterminado de puertos dinámicos para TCP/IP ha cambiado desde Windows Vista y en Windows Server 2008.
Necesidades de ancho de banda
El planeamiento de la escalabilidad de red abarca dos categorías distintas: la cantidad de tráfico y la carga de CPU debida al tráfico de red. Cada uno de estos escenarios es sencillo en comparación con algunos de los otros temas de este artículo.
Al evaluar la cantidad de tráfico que se debe admitir, hay dos categorías únicas de planeamiento de capacidad para AD DS en términos de tráfico de red. La primera es el tráfico de replicación que transcurre entre controladores de dominio y se trata exhaustivamente en el artículo de referencia Tráfico de replicación de Active Directory y sigue siendo pertinente para las versiones actuales de AD DS. La segunda es el tráfico de cliente a servidor dentro del sitio. Uno de los escenarios más sencillos de planear, el tráfico dentro del sitio, recibe principalmente solicitudes pequeñas de los clientes en relación con las grandes cantidades de datos enviados de vuelta a los clientes. Por lo general, 100 MB serán adecuados en entornos de hasta 5000 usuarios por servidor, en un sitio. Se recomienda usar un adaptador de red de 1 GB y la compatibilidad con el Escalado del lado de la recepción (RSS) para cualquier valor superior a 5000 usuarios. Para validar este escenario, especialmente en el caso de escenarios de consolidación de servidores, examine el valor de Network Interface(*)\Bytes/sec en todos los controladores de dominio de un sitio, súmelo y divídalo por el número de controladores de dominio objetivo para asegurarse de que haya una capacidad adecuada. La manera más fácil de hacerlo es usar la vista "Área apilada" en Confiabilidad de Windows y Monitor de rendimiento (anteriormente conocida como Perfmon), asegurándose de que todos los contadores tengan la misma escala.
Considere el ejemplo siguiente (también conocido como una manera realmente compleja de validar que la regla general es aplicable a un entorno específico). Se realizan las siguientes suposiciones:
- El objetivo es reducir la superficie al menor número de servidores posible. Lo ideal es que un servidor lleve la carga y se implemente un servidor adicional para la redundancia (escenario N + 1).
- En este escenario, el adaptador de red actual solo admite 100 MB y está en un entorno conmutado. El uso máximo objetivo de ancho de banda de red es del 60 % en un escenario de N (pérdida de un controlador de dominio).
- Cada servidor tiene unos 10 000 clientes conectados a él.
Conocimientos obtenidos de los datos del gráfico (Network Interface(*)\Bytes Sent/sec):
- El día laborable comienza a subir alrededor de las 5:30 y baja a las 7:00 p. m.
- El período más ocupado va de las 8:00 a las 8:15 a. m., con más de 25 bytes enviados por segundo en el controlador de dominio más ocupado.
Nota
Todos los datos de rendimiento son históricos. Por lo tanto, el punto de datos máximo a las 8:15 indica la carga de las 8:00 a las 8:15.
- Hay picos antes de las 4:00 a. m., con más de 20 bytes enviados por segundo en el controlador de dominio más ocupado, lo que podría indicar una carga desde diferentes zonas horarias o una actividad de la infraestructura en segundo plano, como las copias de seguridad. Puesto que el pico a las 8:00 a. m. supera esta actividad, no es pertinente.
- Hay cinco controladores de dominio en el sitio.
- La carga máxima es de aproximadamente 5,5 MB/s por cada controlador de dominio, que representa el 44 % de la conexión de 100 MB. Con estos datos, se puede calcular que el ancho de banda total necesario entre las 8:00 a. m. y las 8:15 a. m. es de 28 MB/s.
Nota
Tenga cuidado con el hecho de que los contadores de envío y recepción de la interfaz de red están en bytes y el ancho de banda de red se mide en bits. 100 MB ÷ 8 = 12.5 MB, 1 GB ÷ 8 = 128 MB.
Conclusiones:
- Este entorno actual cumple el nivel N+1 de tolerancia a errores con un uso objetivo del 60 %. Desconectar un sistema cambiará el ancho de banda por servidor de aproximadamente 5,5 MB/s (44 %) a aproximadamente 7 MB/s (56 %).
- En función del objetivo indicado anteriormente de consolidar en un servidor, esto supera el uso objetivo máximo y teóricamente el posible uso de una conexión de 100 MB.
- Con una conexión de 1 GB, esto representará el 22 % de la capacidad total.
- En condiciones de funcionamiento normales en el escenario N + 1, la carga de cliente se distribuirá relativamente uniformemente a unos 14 MB/s por servidor o el 11 % de la capacidad total.
- Para asegurarse de que la capacidad sea adecuada durante la falta de disponibilidad de un controlador de dominio, los objetivos de funcionamiento normales por servidor serían aproximadamente de un 30 % de uso de red o 38 MB/s por cada servidor. Los objetivos de conmutación por error serían de un 60 % del uso de red o 72 MB/s por servidor.
En resumen, la implementación final de los sistemas debe tener un adaptador de red de 1 GB y estar conectado a una infraestructura de red que admita dicha carga. Una nota adicional es que, dada la cantidad de tráfico de red generado, la carga de CPU de las comunicaciones de red puede tener un impacto significativo y limitar la escalabilidad máxima de AD DS. Este mismo proceso se puede usar para calcular la cantidad de comunicación entrante al controlador de dominio. Pero, dado el predominio del tráfico saliente en relación con el tráfico entrante, es un ejercicio académico para la mayoría de los entornos. Es importante garantizar la compatibilidad del hardware con RSS en entornos con más de 5000 usuarios por servidor. En escenarios con un tráfico de red elevado, el equilibrio de la carga de interrupción puede ser un cuello de botella. Esto se puede detectar porque el valor de Processor(*)% Interrupt Time se distribuye de forma desigual entre las CPU. Las NIC habilitadas para RSS pueden mitigar esta limitación y aumentar la escalabilidad.
Nota
Se puede usar un enfoque similar para calcular la capacidad adicional necesaria al consolidar centros de datos o retirar un controlador de dominio de una ubicación satélite. Simplemente recopile el tráfico saliente y entrante a los clientes y esa será la cantidad de tráfico que ahora estará presente en los vínculos WAN.
En algunos casos, es posible que experimente más tráfico de lo esperado porque el tráfico es más lento, como cuando la comprobación de certificados no cumple los tiempos de espera agresivos de la WAN. Por este motivo, el dimensionamiento y el uso de WAN deben ser un proceso iterativo y continuo.
Consideraciones de virtualización para el ancho de banda de red
Es fácil hacer recomendaciones para un servidor físico: 1 GB para servidores que admitan más de 5000 usuarios. Una vez que varios invitados empiecen a compartir una infraestructura de conmutador virtual subyacente, se necesita atención adicional para asegurarse de que el host tenga el ancho de banda de red adecuado para admitir a todos los invitados del sistema y, por tanto, requiere un rigor adicional. Esto no es más que una extensión de garantizar la infraestructura de red en la máquina host. Esto es independientemente de si la red incluye el controlador de dominio que se ejecuta como invitado de máquina virtual en un host con el tráfico de red que pasa por un conmutador virtual o si se conecta directamente a un conmutador físico. El conmutador virtual es solo un componente más en el que el enlace ascendente debe admitir la cantidad de datos que se transmiten. Por lo tanto, el adaptador de red físico del host físico vinculado al conmutador debe ser capaz de admitir la carga del controlador de dominio más todos los demás invitados que comparten el conmutador virtual conectado al adaptador de red físico.
Ejemplo de resumen de cálculo
| Sistema | Ancho de banda máximo |
|---|---|
| DC 1 | 6,5 MB/s |
| DC 2 | 6,25 MB/s |
| DC 3 | 6,25 MB/s |
| DC 4 | 5,75 MB/s |
| DC 5 | 4,75 MB/s |
| Total | 28,5 MB/s |
Recomendado: 72 MB/s (28,5 MB/s dividido por 40 %)
| Número de sistemas objetivo | Ancho de banda total (según aparece anteriormente) |
|---|---|
| 2 | 28,5 MB/s |
| Comportamiento normal resultante | 28,5 ÷ 2 = 14,25 MB/s |
Como siempre, se puede hacer la suposición de que la carga de cliente aumentará con el tiempo y se debe planear este crecimiento lo mejor posible. La cantidad recomendada para planear permitiría un crecimiento estimado del tráfico de red del 50 %.
Almacenamiento
El planeamiento del almacenamiento tiene dos componentes:
- Capacidad o tamaño del almacenamiento
- Rendimiento
Se invierte una gran cantidad de tiempo y documentación en planear la capacidad, lo que hace que a menudo se pase completamente por alto el rendimiento. Con los costos de hardware actuales, la mayoría de los entornos no son lo suficientemente grandes como para que ninguno de ellos sea realmente un problema, y la recomendación de "poner tanta RAM como el tamaño de la base de datos" normalmente cubre el resto, aunque puede ser excesiva para las ubicaciones satélite en entornos más grandes.
Ajuste de tamaño
Evaluación del almacenamiento
En comparación con hace 13 años, cuando se presentó Active Directory, un tiempo en el que las unidades de 4 GB y 9 GB eran los tamaños de unidad más comunes, el ajuste de tamaño de Active Directory no es ni siquiera una consideración para todos excepto para los entornos más grandes. Con los tamaños de disco duro más pequeños disponibles de aproximadamente 180 GB, todo el sistema operativo, SYSVOL y NTDS.dit pueden caber fácilmente en una unidad. Por lo tanto, se recomienda poner en desuso una gran inversión en esta área.
La única recomendación que se debe tener en cuenta es asegurarse de que esté disponible el 110 % del tamaño del archivo NTDS.dit para habilitar la desfragmentación. Además, se deben hacer preparativos para el crecimiento durante la vida útil del hardware.
La primera consideración y la más importante es evaluar el tamaño de NTDS.dit y SYSVOL. Estas medidas llevarán al dimensionamiento del disco fijo y la asignación de RAM. Debido al costo (relativamente) bajo de estos componentes, las matemáticas no necesitan ser rigurosas y precisas. Puede encontrar contenido sobre cómo evaluarlo para entornos nuevos y existentes en la serie de artículos Almacenamiento de datos. Específicamente, consulte los siguientes artículos:
Para entornos existentes: la sección titulada "Para activar el registro del espacio en disco que se libera mediante la desfragmentación" de Límites de almacenamiento.
Para nuevos entornos: el artículo titulado Estimaciones de crecimiento para usuarios y unidades organizativas de Active Directory.
Nota
Los artículos se basan en las estimaciones de tamaño de datos realizadas en el momento de la publicación de Active Directory en Windows 2000. Use tamaños de objeto que reflejen el tamaño real de los objetos de su entorno.
Al revisar los entornos existentes con varios dominios, puede haber variaciones en los tamaños de base de datos. Cuando esto sea cierto, use los tamaños de catálogo global (GC) y no GC más pequeños.
El tamaño de la base de datos puede variar entre las versiones del sistema operativo. Los controladores de dominio que ejecutan sistemas operativos anteriores, como Windows Server 2003, tienen un tamaño de base de datos menor que un controlador de dominio que ejecuta un sistema operativo posterior, como Windows Server 2008 R2, especialmente cuando se habilitan características como la Papelera de reciclaje de Active Directory o las Credenciales móviles.
Nota
- En el caso de los nuevos entornos, observe que las estimaciones del artículo Estimaciones de crecimiento para usuarios y unidades organizativas de Active Directory indican que 100 000 usuarios (en el mismo dominio) consumen aproximadamente 450 MB de espacio. Tenga en cuenta que los atributos rellenados pueden tener un gran impacto en la cantidad total. Los atributos se rellenarán en muchos objetos tanto por productos de terceros como por Microsoft, incluidos Microsoft Exchange Server y Lync. Se prefiere una evaluación basada en la cartera de productos del entorno, pero el ejercicio de detallar los cálculos matemáticos y pruebas de estimaciones precisas para todos menos los entornos más grandes pueden no merecer realmente un tiempo y esfuerzo significativos.
- Asegúrese de que esté disponible el 110 % del tamaño del archivo NTDS.dit como espacio libre para habilitar la desfragmentación sin conexión y planee el crecimiento durante un período de vida útil de hardware de tres a cinco años. Dado que el almacenamiento es barato, es seguro calcular el almacenamiento en un 300 % del tamaño del DIT como asignación de almacenamiento para adaptarse al crecimiento y la posible necesidad de la desfragmentación sin conexión.
Consideraciones de virtualización para el almacenamiento
En un escenario en el que se asignan varios archivos de disco duro virtual (VHD) en un único volumen, se usa un disco de tamaño fijo de al menos un 210 % (100 % del DIR + 110 % de espacio disponible) del tamaño del DIT para asegurarse de que haya espacio adecuado reservado.
Ejemplo de resumen de cálculo
| Datos recopilados en la fase de evaluación | Size |
|---|---|
| Tamaño del archivo NTDS.dit | 35 GB |
| Modificador para permitir la desfragmentación sin conexión | 2,1 GB |
| Almacenamiento total necesario | 73,5 GB |
Nota
Este almacenamiento necesario se suma al almacenamiento necesario para SYSVOL, el sistema operativo, el archivo de paginación, los archivos temporales, los datos almacenados en caché local (como los archivos del instalador) y las aplicaciones.
Rendimiento del almacenamiento
Evaluación del rendimiento del almacenamiento
Como el componente más lento de cualquier equipo, el almacenamiento puede tener el mayor impacto adverso en la experiencia del cliente. Para aquellos entornos lo suficientemente grandes como para los que las recomendaciones de dimensionamiento de RAM no sean factibles, las consecuencias de pasar por alto el planeamiento del almacenamiento para el rendimiento pueden ser perjudiciales. Además, las complejidades y las variedades de la tecnología de almacenamiento aumentan aún más el riesgo de error, ya que la pertinencia de los procedimientos recomendados de larga duración de "poner sistema operativo, los registros y la base de datos" en discos físicos independientes está limitado en escenarios útiles. Esto se debe a que el procedimiento recomendado de larga duración se basa en la suposición de que un "disco" es un eje dedicado y esto permite que la E/S esté aislada. Estas suposiciones que hacen que esto sea cierto ya no son pertinentes con la introducción de:
- RAID
- Nuevos tipos de almacenamiento y escenarios de almacenamiento virtualizado y compartido
- Ejes compartidos en una red de área de almacenamiento (SAN)
- Archivo VHD en una SAN o un almacenamiento conectado a la red
- Unidades de estado sólido
- Arquitecturas de almacenamiento en capas (por ejemplo, SSD, almacenamiento en caché de nivel de almacenamiento, almacenamiento basado en un eje mayor)
Específicamente, el almacenamiento compartido (RAID, SAN, NAS, JBOD (por ejemplo, Espacios de almacenamiento), VHD) tiene la capacidad de tener suscripciones y cargas excesivas por parte otras cargas de trabajo que se ubiquen en el almacenamiento de back-end. También agregan el desafío de que los problemas de la SAN, la red y el controlador (todo lo que hay entre el disco físico y la aplicación de AD) pueden provocar limitaciones o retrasos. Como aclaración, estas no son configuraciones "incorrectas", son configuraciones más complejas que requieren que todos los componentes funcionen correctamente, lo que requiere atención adicional para garantizar que el rendimiento sea aceptable. Consulte el Apéndice C, subsección "Introducción a las SAN" y el Apéndice D más adelante en este documento para obtener explicaciones más detalladas. Además, aunque las unidades de estado sólido no tienen la limitación de los discos giratorios (unidades de disco duro) con respecto a permitir que solo se procese una operación de E/S a la vez, siguen teniendo limitaciones de E/S, y es posible cargar y suscribir en exceso los discos SSD. En resumen, el objetivo final de todos los esfuerzos de rendimiento del almacenamiento, independientemente de la arquitectura y el diseño de almacenamiento subyacentes, es asegurarse de que esté disponible la cantidad necesaria de operaciones de entrada y salida por segundo (IOPS) y que esas IOPS se produzcan dentro de un período de tiempo aceptable (como se especifica en otra parte de este documento). Para aquellos escenarios con almacenamiento conectado localmente, consulte el Apéndice C para conocer los conceptos básicos sobre cómo diseñar escenarios de almacenamiento local tradicionales. Estos principios se suelen aplicar a capas de almacenamiento más complejas y también ayudarán en el diálogo con los proveedores que admiten soluciones de almacenamiento de back-end.
- Dada la amplia gama de opciones de almacenamiento disponibles, se recomienda aprovechar la experiencia de los equipos de soporte técnico y los proveedores de hardware para asegurarse de que la solución específica satisfaga las necesidades de AD DS. Las cifras siguientes son la información que se proporcionaría a los especialistas de almacenamiento.
En entornos en los que la base de datos es demasiado grande para mantenerse en RAM, use los contadores de rendimiento para determinar cuánta E/S se debe admitir:
- LogicalDisk(*)\Avg Disk sec/Read (por ejemplo, si el archivo NTDS.dit se almacena en la unidad D:/, la ruta de acceso completa sería LogicalDisk(D:)\Avg Disk sec/Read)
- LogicalDisk(*)\Avg Disk sec/Write
- LogicalDisk(*)\Avg Disk sec/Transfer
- LogicalDisk(*)\Reads/sec
- LogicalDisk(*)\Writes/sec
- LogicalDisk(*)\Transfers/sec
Estos valores se deben muestrear en intervalos de 15/30/60 minutos para crear puntos de referencia de las demandas del entorno actual.
Evaluación de los resultados
Nota
El enfoque se centra en las lecturas de la base de datos, ya que suele ser el componente más exigente; la misma lógica se puede aplicar a las escrituras en el archivo de registro sustituyendo LogicalDisk(<registro de NTDS>)\Avg Disk sec/Write y LogicalDisk(<registro de NTDS>)\Writes/sec):
- LogicalDisk(<NTDS>)\Avg Disk sec/Read indica si el almacenamiento actual tiene el tamaño adecuado. Si los resultados son aproximadamente iguales al tiempo de acceso al disco de ese tipo de disco, LogicalDisk(<NTDS>)\Reads/sec es una medida válida. Consulte las especificaciones del fabricante del almacenamiento en el back-end, pero los intervalos correctos para LogicalDisk(<NTDS>)\Avg Disk sec/Read serían aproximadamente:
- 7200: de 9 a 12,5 milisegundos (ms)
- 10 000: de 6 a 10 ms
- 15 000: de 4 a 6 ms
- SSD: de 1 a 3 ms
-
Nota
Existen recomendaciones que indican que el rendimiento del almacenamiento se degrada de 15 ms a 20 ms (según el origen). La diferencia entre los valores anteriores y las demás instrucciones es que los valores anteriores son el intervalo de funcionamiento normal. Las demás recomendaciones son la guía de solución de problemas para identificar cuándo se degrada significativamente la experiencia del cliente y se vuelve notable. Consulte el Apéndice C para obtener una explicación más detallada.
- LogicalDisk(<NTDS>)\Reads/sec es la cantidad de E/S que se está llevando a cabo.
- Si LogicalDisk(<NTDS>)\Avg Disk sec/Read está dentro del intervalo óptimo para el almacenamiento de back-end, se puede usar directamente LogicalDisk(<NTDS>)\Reads/sec para dimensionar el almacenamiento.
- Si LogicalDisk(<NTDS>)\Avg Disk sec/Read no está dentro del intervalo óptimo para el almacenamiento de back-end, se necesitan E/S adicionales según la siguiente fórmula: (LogicalDisk(<NTDS>)\Avg Disk sec/Read) ÷ (Tiempo de acceso al disco físico) × (LogicalDisk(<NTDS>)\Avg Disk sec/Read)
Consideraciones:
- Tenga en cuenta que si el servidor está configurado con una cantidad de RAM por debajo de la óptima, estos valores serán inexactos con fines de planeamiento. Estarán erróneamente en el lado alto y se pueden seguir usando como el peor escenario.
- Agregar u optimizar la RAM llevará específicamente a una disminución de la cantidad de E/S de lectura (LogicalDisk(<NTDS>)\Reads/Sec). Esto significa que es posible que la solución de almacenamiento no sea tan sólida como se calculó inicialmente. Desafortunadamente, cualquier instrucción más específica que esta declaración general depende del entorno de la carga del cliente y no se pueden proporcionar instrucciones generales. La mejor opción es ajustar el tamaño del almacenamiento después de optimizar la RAM.
Consideraciones de virtualización para el rendimiento
De forma similar a todas las explicaciones sobre virtualización anteriores, la clave aquí es asegurarse de que la infraestructura compartida subyacente pueda admitir la carga del controlador de dominio más los demás recursos que usan el medio compartido subyacente y todas las rutas de acceso a él. Esto es cierto si un controlador de dominio físico comparte el mismo medio subyacente en una infraestructura SAN, NAS o iSCSI que otros servidores o aplicaciones, ya sea un invitado que usa el acceso a una infraestructura SAN, NAS o iSCSI que comparte el medio subyacente, o si el invitado usa un archivo VHD que reside en medios compartidos localmente o en una infraestructura SAN, NAS o iSCSI. El ejercicio de planeamiento consiste en asegurarse de que los medios subyacentes puedan admitir la carga total de todos los consumidores.
Además, desde una perspectiva de invitado, dado que hay rutas de acceso de código adicionales que se deben recorrer, hay un impacto en el rendimiento por tener que pasar por un host para acceder a cualquier almacenamiento. No es sorprendente que las pruebas de rendimiento del almacenamiento indiquen que la virtualización tiene un impacto en el rendimiento que es subjetivo respecto al uso del procesador del sistema host (consulte el Apéndice A: Criterios de dimensionamiento de CPU), que obviamente se ve influenciado por los recursos del host solicitados por el invitado. Esto contribuye a las consideraciones sobre virtualización relacionadas con las necesidades de procesamiento en un escenario virtualizado (consulte Consideraciones de virtualización para el procesamiento).
Para que esto sea más complejo, hay una variedad de opciones de almacenamiento diferentes que están disponibles y todas tienen diferentes impactos en el rendimiento. Como estimación segura al migrar de físico a virtual, use un multiplicador de 1,10 para ajustar las diferentes opciones de almacenamiento para invitados virtualizados en Hyper-V, como el almacenamiento de acceso directo y los adaptadores SCSI o IDE. Los ajustes que se deben realizar al transferir entre los distintos escenarios de almacenamiento no son pertinentes en cuanto a si el almacenamiento es local, SAN, NAS o iSCSI.
Ejemplo de resumen de cálculo
Determinar la cantidad de E/S necesaria para un sistema en estado correcto en condiciones de funcionamiento normales:
- LogicalDisk(<Unidad de la base de datos NTDS>)\Transfers/sec durante el período de actividad máxima de 15 minutos
- Para determinar la cantidad de E/S necesaria para el almacenamiento cuando se supera la capacidad del almacenamiento subyacente:
IOPS necesarias = (LogicalDisk(<Unidad de la base de datos NTDS>)\Avg Disk sec/Read ÷ <Target Avg Disk sec/Read>) × LogicalDisk(<Unidad de la base de datos NTDS>)\Read/sec
| Contador | Valor |
|---|---|
| Real: LogicalDisk(<Unidad de la base de datos NTDS>)\Avg Disk sec/Transfer | 0,02 segundos (20 milisegundos) |
| Objetivo: LogicalDisk(<Unidad de la base de datos NTDS>)\Avg Disk sec/Transfer | 0,01 segundos |
| Multiplicador para el cambio en la E/S disponible | 0,02 ÷ 0,01 = 2 |
| Nombre del valor | Valor |
|---|---|
| LogicalDisk(<Unidad de la base de datos NTDS>)\Transfers/sec | 400 |
| Multiplicador para el cambio en la E/S disponible | 2 |
| IOPS totales necesarias durante el período máximo | 800 |
Para determinar la velocidad a la que se desea activar la memoria caché:
- Determine el tiempo máximo aceptable para activar la memoria caché. Es la cantidad de tiempo que se debe tardar en cargar toda la base de datos desde el disco o, en escenarios en los que no se puede cargar toda la base de datos en RAM, este sería el tiempo máximo para rellenar la RAM.
- Determine el tamaño de la base de datos, excepto el espacio en blanco. Para más información, consulte Evaluación del almacenamiento.
- Divida el tamaño de la base de datos entre 8 KB; que será el total de E/S necesaria para cargar la base de datos.
- Divida el número total de E/S por el número de segundos del período de tiempo definido.
Tenga en cuenta que la tasa calculada, aunque precisa, no será exacta porque las páginas cargadas previamente se expulsan si ESE no está configurado para tener un tamaño fijo de caché y AD DS usa de manera predeterminada el tamaño de caché variable.
| Puntos de datos que se van a recopilar | Valores |
|---|---|
| Tiempo máximo aceptable para la activación | 10 minutos (600 segundos) |
| Tamaño de base de datos | 2 GB |
| Paso de cálculo | Fórmula | Resultado |
|---|---|---|
| Cálculo del tamaño de la base de datos en páginas | (2 GB × 1024 × 1024) = Tamaño de la base de datos en KB | 2 097 152 KB |
| Cálculo del número de páginas de la base de datos | 2 097 152 KB ÷ 8 KB = Número de páginas | 262 144 páginas |
| Cálculo de las IOPS necesarias para activar completamente la memoria caché | 262 144 páginas ÷ 600 segundos = IOPS necesarias | 437 IOPS |
Processing
Evaluación del uso de procesador de Active Directory
En la mayoría de los entornos, después de que el almacenamiento, la RAM y las redes se hayan ajustado correctamente, como se describe en la sección Planeamiento, la administración de la cantidad de capacidad de procesamiento será el componente que merece la mayor atención. Hay dos desafíos en la evaluación de la capacidad de CPU necesaria:
Si las aplicaciones del entorno se comportan bien o no en una infraestructura de servicios compartidos, y se describe en la sección titulada "Seguimiento de búsquedas costosas e ineficaces" del artículo Creación de aplicaciones más eficaces habilitadas para Microsoft Active Directory o migración de llamadas SAM de nivel inferior a llamadas LDAP.
En entornos más grandes, la razón por la que esto es importante es que las aplicaciones codificadas de forma deficiente pueden impulsar la volatilidad de la carga de la CPU, "robar" una cantidad de tiempo extraordinaria de CPU a otras aplicaciones, aumentar artificialmente las necesidades de capacidad y distribuir de forma desigual la carga en los controladores de dominio.
Como AD DS es un entorno distribuido con una gran variedad de clientes potenciales, estimar el gasto de un "cliente único" es subjetivo del entorno debido a los patrones de uso y al tipo y la cantidad de aplicaciones que utilizan AD DS. En resumen, al igual que en la sección de redes, para una aplicabilidad amplia, esto se aborda mejor desde la perspectiva de evaluar la capacidad total necesaria en el entorno.
En el caso de los entornos existentes, dado que el ajuste de tamaño del almacenamiento se explicó anteriormente, se da por supuesto que el almacenamiento ahora tiene el tamaño correcto y, por tanto, los datos relacionados con la carga del procesador son válidos. Para repetir, es fundamental asegurarse de que el cuello de botella en el sistema no es el rendimiento del almacenamiento. Cuando existe un cuello de botella y el procesador está esperando, hay estados inactivos que desaparecerán una vez que se quite el cuello de botella. A medida que se quitan los estados de espera del procesador, por definición, aumenta el uso de la CPU, ya que ya no tiene que esperar a los datos. Por lo tanto, recopile los contadores de rendimiento "Logical Disk(<Unidad de la base de datos NTDS>)\Avg Disk sec/Read" y "Process(lsass)\% Processor Time". Los datos de "Process(lsass)\% Processor Time" serán artificialmente bajos si "Logical Disk(<Unidad de la base de datos NTDS>)\Avg Disk sec/Read" supera los 10/15 ms, que es un umbral general que Microsoft admite para solucionar problemas de rendimiento relacionados con el almacenamiento. Como antes, se recomienda que los intervalos de muestra sean de 15, 30 o 60 minutos. Cualquier intervalo menor generalmente será demasiado volátil para obtener buenas medidas; cualquier intervalo mayor suavizará excesivamente los picos diarios.
Introducción
Para planear la capacidad de los controladores de dominio, la potencia de procesamiento requiere la mayor atención y comprensión. Al ajustar el tamaño de los sistemas para garantizar el máximo rendimiento, siempre hay un componente que es el cuello de botella y, en un controlador de dominio de tamaño correcto, será el procesador.
De forma similar a la sección de redes, en la que se revisa la demanda del entorno sitio a sitio, se debe hacer lo mismo para la capacidad de proceso demandada. A diferencia de la sección de redes, donde las tecnologías de redes disponibles superan con creces la demanda normal, preste más atención al dimensionamiento de la capacidad de CPU. Como cualquier entorno de tamaño incluso moderado, cualquier cosa que supere unos miles de usuarios simultáneos puede poner una carga significativa en la CPU.
Desafortunadamente, debido a la enorme variabilidad de las aplicaciones cliente que aprovechan AD, una estimación general de usuarios por CPU es inaplicable a todos los entornos. Específicamente, las demandas de proceso están sujetas al comportamiento del usuario y al perfil de aplicación. Por lo tanto, se debe dimensionar de forma individual cada entorno.
Perfil de comportamiento objetivo del sitio
Como se mencionó anteriormente, al planear la capacidad de un sitio completo, el objetivo es dirigirse a un diseño con un diseño de capacidad de N + 1, de modo que un error en un sistema durante el período máximo permita la continuación del servicio con un nivel razonable de calidad. Esto significa que, en un escenario de "N", la carga en todos los equipos debe ser inferior al 100 % (mejor aún, inferior al 80 %) durante los períodos máximos.
Además, si las aplicaciones y los clientes del sitio usan los procedimientos recomendados para buscar los controladores de dominio (es decir, mediante la función DsGetDcName), los clientes se deben distribuir de manera relativamente uniforme con picos transitorios menores debido a cualquier número de factores.
En el ejemplo siguiente, se realizan las siguientes suposiciones:
- Cada uno de los cinco controladores de dominio del sitio tiene cuatro CPU.
- El uso total de CPU objetivo durante el horario laborable está por debajo del 40 % en condiciones de funcionamiento normales ("N + 1") y del 60 % en caso contrario ("N"). Durante las horas no laborables, el uso de CPU objetivo es del 80 % porque se espera que el software de copia de seguridad y otras operaciones de mantenimiento consuman todos los recursos disponibles.
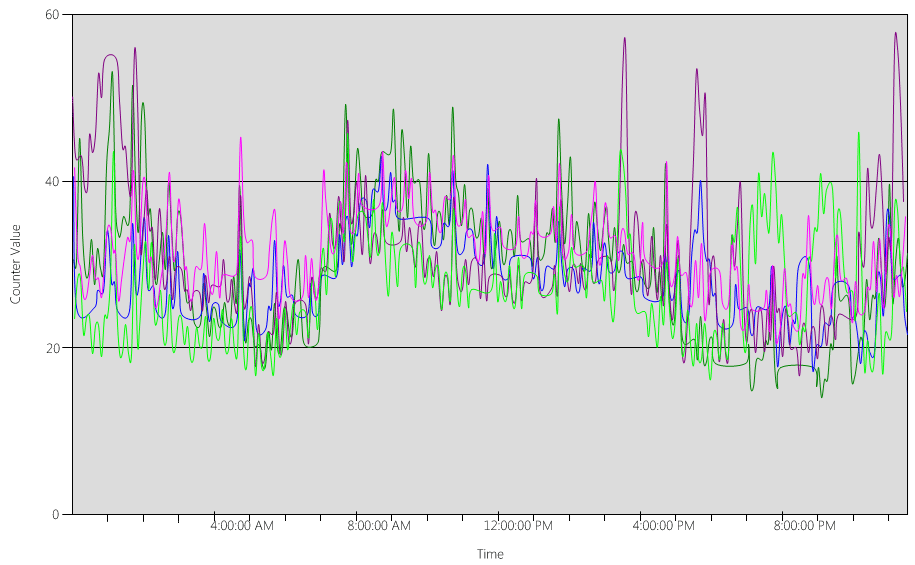
Análisis de los datos del gráfico (Processor Information(_Total)\% Processor Utility) para cada uno de los controladores de dominio:
En su mayor parte, la carga se distribuye de manera relativamente uniforme, que es lo que se esperaría cuando los clientes usan el localizador de controlador de dominio y tienen búsquedas bien escritas.
Hay una serie de picos de cinco minutos del 10 %, con algunos que llegan al 20 %. Por lo general, a menos que provoquen que se supere el objetivo del plan de capacidad, no merece la pena investigarlos.
El período máximo de todos los sistemas está comprendido entre las 8:00 a. m. y las 9:15 a. m. Con una transición fluida desde aproximadamente las 5:00 a. m. hasta las 5:00 p. m., esto es generalmente indicativo del ciclo empresarial. Los picos más aleatorios de uso de CPU en un escenario equipo a equipo entre las 5:00 p. m. y las 4:00 a. m. estarían fuera de los problemas de planeamiento de capacidad.
Nota
En un sistema bien administrado, estos picos podrían ser software de copia de seguridad en ejecución, exámenes completos del sistema del antivirus, inventario de hardware o software, implementación de software o revisiones, etc. Dado que se encuentran fuera del ciclo empresarial máximo del usuario, no se superan los objetivos.
Dado que cada sistema está aproximadamente al 40 % y todos los sistemas tienen el mismo número de CPU, si se produce un error en uno o se desconecta, los sistemas restantes se ejecutarían en un 53 % estimado (la carga del 40 % del sistema se divide uniformemente y se agrega a la carga existente del 40 % del sistema A y del sistema C). Por varias razones, esta suposición lineal no es perfectamente precisa, pero proporciona suficiente precisión para medir.
Escenario alternativo: dos controladores de dominio en ejecución al 40 %: se produce un error en un controlador de dominio, la CPU estimada en el resto sería un 80 %. Esto supera con mucho los umbrales descritos anteriormente para el plan de capacidad y también comienza a limitar gravemente la cantidad de espacio del 10 % al 20 % visto en el perfil de carga anterior, lo que significa que los picos llevarían al controlador de dominio entre el 90 % y el 100 % durante el escenario "N" y, definitivamente, se degrada la capacidad de respuesta.
Cálculo de las demandas de CPU
El contador de objetos de rendimiento "Process\% Processor Time" suma la cantidad total de tiempo que emplean todos los subprocesos de una aplicación en la CPU y se divide por la cantidad total de tiempo del sistema que ha transcurrido. El efecto de esto es que una aplicación de varios subprocesos en un sistema de varias CPU puede superar el 100 % del tiempo de CPU, y se interpretaría de forma MUY diferente al valor de "Processor Information\% Processor Utility". En la práctica, el valor de "Process(lsass)\% Processor Time" se puede ver como el número de CPU en ejecución al 100 % que son necesarias para admitir las demandas del proceso. Un valor del 200 % significa que son necesarias 2 CPU, cada una al 100 %, para admitir la carga completa de AD DS. Aunque una CPU que se ejecuta con una capacidad del 100 % es la más rentable desde la perspectiva del dinero invertido en CPU y el consumo de energía, por varias razones detalladas en el Apéndice A, se produce una mejor capacidad de respuesta en un sistema multisubproceso cuando el sistema no está en ejecución al 100 %.
Para dar cabida a picos transitorios en la carga de cliente, se recomienda establecer como objetivo una CPU en período máximo de entre el 40 % y el 60 % de la capacidad del sistema. En el caso del ejemplo anterior, esto significaría que se necesitarían entre 3,33 (objetivo del 60 %) y 5 CPU (objetivo del 40 %) para la carga de AD DS (proceso lsass). Se debe agregar capacidad adicional según las demandas del sistema operativo base y otros agentes necesarios (como antivirus, copia de seguridad, supervisión, etc.). Aunque el impacto de los agentes se debe evaluar para cada entorno, se puede realizar una estimación de entre el 5 % y el 10 % de una sola CPU. En el ejemplo actual, esto sugeriría que son necesarias entre 3,43 (objetivo del 60 %) y 5,1 CPU (objetivo del 40 %) durante los períodos máximos.
La manera más fácil de hacerlo es usar la vista "Área apilada" en Confiabilidad de Windows y Monitor de rendimiento (perfmon), asegurándose de que todos los contadores tengan la misma escala.
Se supone que:
- El objetivo es reducir la superficie al menor número de servidores posible. Lo ideal es que un servidor lleve la carga y se agregue un servidor adicional para la redundancia (escenario N + 1).
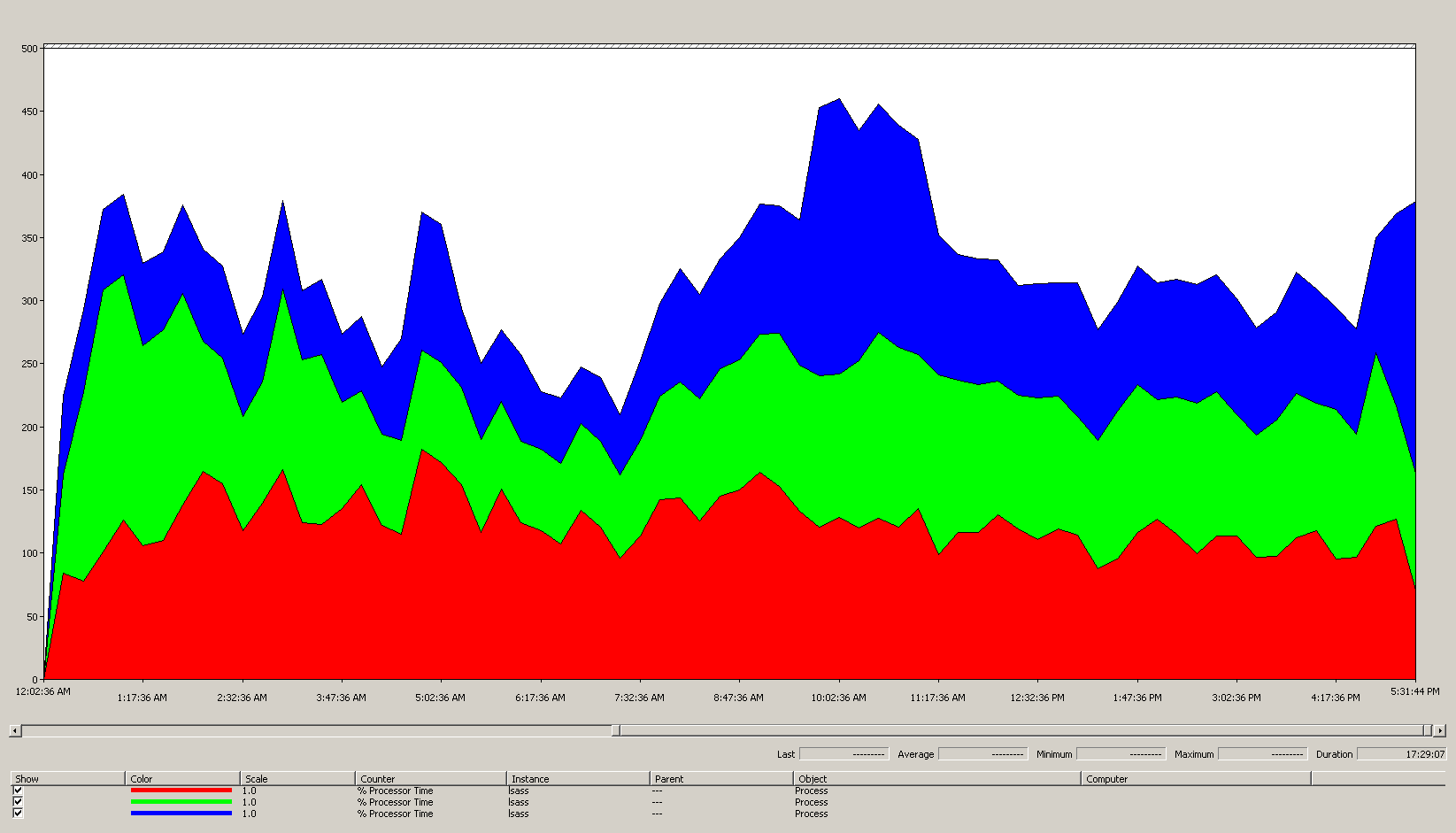
Conocimientos obtenidos de los datos del gráfico (Process(lsass)\% Processor Time):
- El día laborable comienza a subir alrededor de las 7:00 y baja a las 5:00 p. m.
- El período más ocupado es de 9:30 a 11:00 a. m.
Nota
Todos los datos de rendimiento son históricos. El punto de datos máximo a las 9:15 indica la carga de las 9:00 a las 9:15.
- Hay picos antes de las 7:00 a. m., lo que podría indicar una carga desde diferentes zonas horarias o una actividad de la infraestructura en segundo plano, como las copias de seguridad. Puesto que el pico a las 9:30 a. m. supera esta actividad, no es pertinente.
- Hay tres controladores de dominio en el sitio.
En la carga máxima, lsass consume aproximadamente el 485 % de una CPU o 4,85 CPU que se ejecuten al 100 %. Según las matemáticas anteriores, esto significa que el sitio necesita aproximadamente 12,25 CPU para AD DS. Agregue las sugerencias anteriores del 5 % al 10 % para los procesos en segundo plano y eso significa que para sustituir el servidor hoy se necesitarían aproximadamente de 12,30 a 12,35 CPU para admitir la misma carga. Ahora, es necesario tener en cuenta una estimación del entorno en cuanto al crecimiento.
Cuándo ajustar las ponderaciones de LDAP
Hay varios escenarios en los que se debe tener en cuenta el ajuste de LdapSrvWeight. En el contexto del planeamiento de capacidad, esto se haría cuando la aplicación o las cargas de usuario no se equilibran uniformemente, o los sistemas subyacentes no se equilibran uniformemente en términos de funcionalidad. Los motivos para hacerlo más allá del planeamiento de capacidad están fuera del ámbito de este artículo.
Hay dos razones comunes para ajustar loas ponderaciones de LDAP:
- El emulador de PDC es un ejemplo que afecta a cada entorno para el que el comportamiento de la carga de usuario o la aplicación no se distribuye uniformemente. Dado que ciertas herramientas y acciones tienen como destino el emulador de PDC (como las herramientas de administración de directiva de grupo, los segundos intentos en caso de errores de autenticación, el establecimiento de la confianza, etc.), los recursos de CPU en el emulador de PDC pueden ser más demandados que en otras partes del sitio.
- Solo es útil ajustar esto si hay una diferencia notable en el uso de CPU para reducir la carga en el emulador de PDC y aumentar la carga en otros controladores de dominio permitirá una distribución más uniforme de la carga.
- En este caso, establezca LDAPSrvWeight entre 50 y 75 para el emulador de PDC.
- Servidores con diferente número de CPU (y velocidades) en un sitio. Por ejemplo, supongamos que hay dos servidores de ocho núcleos y un servidor de cuatro núcleos. El último servidor tiene la mitad de procesadores que los otros dos servidores. Esto significa que una carga de cliente bien distribuida aumentará la carga media de CPU del equipo de cuatro núcleos hasta aproximadamente el doble que en los equipos de ocho núcleos.
- Por ejemplo, los dos equipos de ocho núcleos estarían en ejecución al 40 % y el equipo de cuatro núcleos estaría en ejecución al 80 %.
- Además, tenga en cuenta el impacto de la pérdida de un equipo de ocho núcleos en este escenario, específicamente el hecho de que el equipo de cuatro núcleos ahora se sobrecargaría.
Ejemplo 1: PDC
| Sistema | Uso con valores predeterminados | Nuevo LdapSrvWeight | Nuevo uso estimado |
|---|---|---|---|
| DC 1 (emulador de PDC) | 53 % | 57 | 40% |
| DC 2 | 33 % | 100 | 40% |
| DC 3 | 33 % | 100 | 40% |
El aprendizaje aquí es que si se transfiere o se utiliza el rol de emulador de PDC, especialmente a otro controlador de dominio del sitio, habrá un aumento drástico en el nuevo emulador de PDC.
Con el ejemplo de la sección Perfil de comportamiento objetivo del sitio, se da por supuesto que los tres controladores de dominio del sitio tenían cuatro CPU. ¿Qué debería ocurrir, en condiciones normales, si uno de los controladores de dominio tenía ocho CPU? Habría dos controladores de dominio con un uso del 40 % y uno con un 20 %. Aunque esto no es malo, hay una oportunidad de equilibrar la carga un poco mejor. Aproveche las ponderaciones de LDAP para lograrlo. Un escenario de ejemplo sería:
Ejemplo 2: diferentes números de CPU
| Sistema | Processor Information\ % Processor Utility(_Total) Uso con valores predeterminados |
Nuevo LdapSrvWeight | Nuevo uso estimado |
|---|---|---|---|
| DC 1 de 4-CPU | 40 | 100 | 30 % |
| DC 2 de 4-CPU | 40 | 100 | 30 % |
| DC 3 de 8-CPU | 20 | 200 | 30 % |
Tenga mucho cuidado con estos escenarios. Como se pudo ver anteriormente, las matemáticas se ven realmente bonitas sobre el papel. Sin embargo, en todo este artículo, el planeamiento de un escenario "N + 1" es de importancia primordial. Se debe calcular para cada escenario el impacto de un controlador de dominio que se queda sin conexión. En el escenario inmediatamente anterior en el que la distribución de la carga es uniforme, con el fin de garantizar una carga del 60 % durante un escenario de "N", con la carga equilibrada uniformemente en todos los servidores, la distribución estará bien porque las relaciones permanecen coherentes. Al examinar el escenario de ajuste del emulador de PDC y, en general, cualquier escenario en el que la carga de usuario o de aplicación esté desequilibrada, el efecto es muy diferente:
| Sistema | Uso optimizado | Nuevo LdapSrvWeight | Nuevo uso estimado |
|---|---|---|---|
| DC 1 (emulador de PDC) | 40% | 85 | 47 % |
| DC 2 | 40% | 100 | 53 % |
| DC 3 | 40% | 100 | 53 % |
Consideraciones de virtualización para el procesamiento
Hay dos capas de planeamiento de capacidad que se deben realizar en un entorno virtualizado. En el nivel de host, de forma similar a la identificación del ciclo empresarias descrito anteriormente para el procesamiento del controlador de dominio, es necesario identificar los umbrales durante el período máximo. Dado que los principios subyacentes son los mismos para una máquina host que programa subprocesos de invitado en la CPU que para obtener subprocesos de AD DS en la CPU de una máquina física, se recomienda el mismo objetivo del 40 % al 60 % en el host subyacente. En la capa siguiente, la capa de invitado, dado que los principios de la programación de subprocesos no han cambiado, el objetivo dentro del invitado permanece en el intervalo del 40 % al 60 %.
En un escenario de asignación directa, un invitado por host, todo el planeamiento de capacidad realizado hasta este punto se debe agregar a los requisitos (RAM, disco, red) del sistema operativo del host subyacente. En un escenario de host compartido, las pruebas indican que hay un impacto del 10 % en la eficacia de los procesadores subyacentes. Esto significa que si un sitio necesita 10 CPU al objetivo del 40 %, la cantidad recomendada de CPU virtuales para asignar entre todos los "N" invitados sería 11. En un sitio con una distribución mixta de servidores físicos y servidores virtuales, el modificador solo se aplica a las máquinas virtuales. Por ejemplo, si un sitio tiene un escenario "N + 1", un servidor físico o de asignación directa con 10 CPU sería aproximadamente equivalente a un invitado con 11 CPU en un host, con 11 CPU reservadas para el controlador de dominio.
A lo largo del análisis y cálculo de las cantidades de CPU necesarias para admitir la carga de AD DS, las cifras de CPU que se asignan a lo que se puede comprar en términos de hardware físico no necesariamente se asignan de forma exacta. La virtualización elimina la necesidad de redondear. La virtualización reduce el esfuerzo necesario para agregar capacidad de proceso a un sitio, dada la facilidad con la que se puede agregar una CPU a una máquina virtual. No elimina la necesidad de evaluar con precisión la potencia de proceso necesaria para que el hardware subyacente esté disponible cuando sea necesario agregar CPU adicionales a los invitados. Como siempre, recuerde planear y supervisar el crecimiento de la demanda.
Ejemplo de resumen de cálculo
| Sistema | CPU máxima |
|---|---|
| DC 1 | 120% |
| DC 2 | 147 % |
| DC 3 | 218 % |
| CPU total en uso | 485 % |
| Número de sistemas objetivo | Ancho de banda total (según aparece anteriormente) |
|---|---|
| CPU necesarias en el objetivo del 40 % | 4,85 ÷ 4 = 12,25 |
Como repetición, debido a la importancia de este punto, recuerde planear el crecimiento. Suponiendo un crecimiento del 50 % en los próximos tres años, este entorno necesitará 18,375 CPU (12,25 × 1,5) en el plazo de tres años. Un plan alternativo sería revisar después del primer año y agregar capacidad adicional según sea necesario.
Carga de la autenticación de cliente de confianza cruzada para NTLM
Evaluación de la carga de la autenticación de cliente de confianza cruzada
Muchos entornos pueden tener uno o varios dominios conectados por una confianza. Una solicitud de autenticación para una identidad en otro dominio que no usa la autenticación Kerberos debe atravesar una confianza mediante el canal seguro del controlador de dominio a otro controlador de dominio, ya sea en el dominio de destino o en el siguiente dominio de la ruta de acceso al dominio de destino. El número de llamadas simultáneas mediante el canal seguro que un controlador de dominio puede realizar a un controlador de dominio de un dominio de confianza se controla mediante una configuración conocida como MaxConcurrentAPI. En el caso de los controladores de dominio, garantizar que el canal seguro pueda controlar la cantidad de carga se logra mediante uno de los dos enfoques: ajuste de MaxConcurrentAPI o, dentro de un bosque, creando confianzas de acceso directo. Para medir el volumen de tráfico en una confianza individual, consulte Cómo realizar el ajuste del rendimiento para la autenticación NTLM mediante la configuración MaxConcurrentApi.
Durante la recopilación de datos, esto, al igual que con todos los demás escenarios, se debe recopilar durante los períodos de actividad máxima del día para que los datos sean útiles.
Nota
Los escenarios dentro del bosque y entre bosques pueden hacer que la autenticación recorra varias confianzas y se deba optimizar cada fase.
Planificación
Hay varias aplicaciones que usan la autenticación NTLM de manera predeterminada o la usan en un escenario de configuración determinado. Los servidores de aplicaciones crecen en capacidad y dan servicio a un número cada vez mayor de clientes activos. También hay una tendencia en los clientes de mantener abiertas las sesiones durante un tiempo limitado y volver a conectarse periódicamente (como la sincronización de extracción de correo electrónico). Otro ejemplo común para una carga elevada de NTLM son los servidores proxy web que requieren autenticación para el acceso a Internet.
Estas aplicaciones pueden provocar una carga significativa para la autenticación NTLM, lo que puede suponer un esfuerzo significativo en los controladores de dominio, especialmente cuando los usuarios y los recursos están en dominios diferentes.
Hay varios enfoques para administrar la carga de confianza cruzada, que en la práctica se usan conjuntamente en lugar de en un escenario excluyente. Las opciones posibles son:
- Reduzca la autenticación de cliente de confianza cruzada ubicando los servicios que consume un usuario en el mismo dominio en el que reside el usuario.
- Aumente el número de canales seguros disponibles. Esto es importante para el tráfico dentro del bosque y entre bosques, y se conoce como confianzas de acceso directo.
- Optimice la configuración predeterminada de MaxConcurrentAPI.
Para optimizar MaxConcurrentAPI en un servidor existente, la ecuación es:
New_MaxConcurrentApi_setting ≥ (semaphore_acquires + semaphore_time-outs) × average_semaphore_hold_time ÷ time_collection_length
Para obtener más información, consulte el artículo de KB 2688798: Cómo realizar el ajuste del rendimiento para la autenticación NTLM mediante la configuración MaxConcurrentApi.
Consideraciones de virtualización
Ninguno, se trata de una configuración de ajuste del sistema operativo.
Ejemplo de resumen de cálculo
| Tipo de datos | Value |
|---|---|
| Adquisiciones de semáforo (mínimo) | 6161 |
| Adquisiciones de semáforo (máximo) | 6762 |
| Tiempos de espera del semáforo | 0 |
| Promedio de tiempo de retención del semáforo | 0,012 |
| Duración de la recopilación (segundos) | 1:11 minutos (71 segundos) |
| Fórmula (según KB 2688798) | ((6762 – 6161) + 0) × 0,012 / |
| Valor mínimo de MaxConcurrentAPI | ((6762 – 6161) + 0) × 0,012 ÷ 71 = 0,101 |
Para este sistema durante este período de tiempo, los valores predeterminados son aceptables.
Supervisión del cumplimiento de los objetivos de planeamiento de capacidad
A lo largo de este artículo, se ha explicado que el planeamiento y el escalado van dirigidos a los objetivos de uso. Este es un gráfico de resumen de los umbrales recomendados que se deben supervisar para asegurarse de que los sistemas funcionan dentro de los umbrales de capacidad adecuados. Tenga en cuenta que no son umbrales de rendimiento, sino umbrales de planeamiento de capacidad. Un servidor que opere por encima de estos umbrales funcionará, pero es el momento de empezar a validar que todas las aplicaciones se comportan bien. Si dichas aplicaciones se comportan bien, es hora de empezar a evaluar las actualizaciones de hardware u otros cambios de configuración.
| Category | Contador de rendimiento | Intervalo/muestreo | Destino | Advertencia |
|---|---|---|---|---|
| Procesador | Processor Information(_Total)\% Processor Utility | 60 min | 40% | 60% |
| RAM (Windows Server 2008 R2 o versiones anteriores) | Memory\Available MB | < 100 MB | N/D | < 100 MB |
| RAM (Windows Server 2012) | Memory\Long-Term Average Standby Cache Lifetime(s) | 30 min | Se debe probar | Se debe probar |
| Red | Network Interface(*)\Bytes Sent/sec Network Interface(*)\Bytes Received/sec |
30 min | 40% | 60% |
| Almacenamiento | LogicalDisk(<Unidad de la base de datos NTDS>)\Avg Disk sec/Read LogicalDisk(<Unidad de la base de datos NTDS>)\Avg Disk sec/Write |
60 min | 10 ms | 15 ms |
| Servicios de AD | Netlogon(*)\Average Semaphore Hold Time | 60 min | 0 | 1 segundo |
Apéndice A: Criterios de dimensionamiento de CPU
Definiciones
Procesador (microprocesador): un componente que lee y ejecuta instrucciones de programas
CPU: unidad central de procesamiento
Procesador de varios núcleos: varias CPU en el mismo circuito integrado
Multi-CPU: varias CPU, no en el mismo circuito integrado
Procesador lógico: un motor de procesamiento lógico desde la perspectiva del sistema operativo
Esto incluye con hipersubprocesamiento, un núcleo en un procesador de varios núcleos o un procesador de un solo núcleo.
Como los sistemas de servidor actuales tienen varios procesadores, varios procesadores de varios núcleos e hipersubprocesamiento, esta información se generaliza para cubrir ambos escenarios. Por lo tanto, se usará el término procesador lógico porque representa la perspectiva del sistema operativo y las aplicaciones sobre los motores procesamiento disponibles.
Paralelismo de nivel de subproceso
Cada subproceso es una tarea independiente, ya que cada subproceso tiene su propia pila e instrucciones. Dado que AD DS tiene multisubprocesamiento y el número de subprocesos disponibles se puede optimizar como se indica en Cómo ver y establecer la directiva LDAP en Active Directory mediante Ntdsutil.exe, se escala bien entre varios procesadores lógicos.
Paralelismo de nivel de datos
Esto implica compartir datos entre varios subprocesos dentro de un proceso (en el caso del proceso de AD DS por sí solo) y entre varios subprocesos de varios procesos (en general). Con precaución por simplificar demasiado el caso, esto significa que los cambios en los datos se reflejan en todos los subprocesos en ejecución en todos los distintos niveles de caché (L1, L2, L3) en todos los núcleos que ejecutan dichos subprocesos, así como en la actualización de la memoria compartida. El rendimiento se puede degradar durante las operaciones de escritura, en tanto que todas las distintas ubicaciones de memoria sean coherentes antes de que el procesamiento de instrucciones pueda continuar.
Consideraciones sobre velocidad de CPU frente a varios núcleos
La regla general es que los procesadores lógicos más rápidos reducen la duración que se tarda en procesar una serie de instrucciones, mientras que más procesadores lógicos significa que se pueden ejecutar más tareas al mismo tiempo. Estas reglas generales se desglosan a medida que los escenarios se vuelven intrínsecamente más complejos, con consideraciones de recuperación de datos de la memoria compartida, espera del paralelismo de nivel de datos y la sobrecarga de administrar varios subprocesos. Esto también es el motivo por el que la escalabilidad en sistemas de varios núcleos no es lineal.
Tenga en cuenta las siguientes analogías en estas consideraciones: piense en una autopista, en la que cada subproceso es un automóvil individual, cada carril es un núcleo y el límite de velocidad es la velocidad del reloj.
- Si solo hay un automóvil en la autopista, no importa si hay dos carriles o 12 carriles. Ese automóvil solo irá tan rápido como permita el límite de velocidad.
- Supongamos que los datos que necesita el subproceso no están disponibles inmediatamente. La analogía sería que un segmento de carretera está fuera de servicio. Si solo hay un automóvil en la carretera, no importa cuál sea el límite de velocidad hasta que se vuelva a abrir el carril (se recuperan los datos de la memoria).
- A medida que aumenta el número de automóviles, aumenta la sobrecarga necesaria para administrar el número de automóviles. Compare la experiencia de conducción y la cantidad de atención necesaria cuando la carretera está prácticamente vacía (por ejemplo, tarde por la noche) frente a cuando el tráfico es pesado (por ejemplo, media tarde, pero no hora punta). Además, tenga en cuenta la cantidad de atención necesaria al conducir en una autopista de dos carriles, donde solo hay otro carril para preocuparse de lo que hacen los conductores, frente a una autopista de seis carriles donde hay que preocuparse por lo que hacen muchos otros conductores.
Nota
La analogía sobre el escenario de hora punta se extiende en la sección siguiente: Tiempo de respuesta/Cómo afecta al rendimiento la disponibilidad del sistema.
Como resultado, los detalles sobre usar más procesadores o más rápidos se convierten en muy subjetivos del comportamiento de la aplicación, que en el caso de AD DS es muy específico del entorno e incluso varía de servidor a servidor dentro de un entorno. Esta es la razón por la que las referencias anteriores del artículo no invierten mucho en ser demasiado precisas y se incluye un margen de seguridad en los cálculos. Al tomar decisiones de compra controladas por un presupuesto, se recomienda optimizar primero el uso de los procesadores al 40 % (o el número deseado para el entorno), antes de considerar la posibilidad de comprar procesadores más rápidos. El aumento de la sincronización entre más procesadores reduce la verdadera ventaja de más procesadores respecto a la progresión lineal (2× número de procesadores proporciona menos de 2× potencia de proceso adicional disponible).
Nota
La ley de Amdahl y la ley de Gustafson son los conceptos pertinentes aquí.
Tiempo de respuesta/Cómo afecta al rendimiento la disponibilidad del sistema
La teoría de colas es el estudio matemático de las líneas de espera (colas). En la teoría colas, la Ley de utilización se representa mediante la ecuación:
U k = B ÷ T
Donde U k es el porcentaje de utilización, B es la cantidad de tiempo ocupado y T es el tiempo total que se observó el sistema. Traducido al contexto de Windows, esto significa el número de subprocesos del intervalo de 100 nanosegundos (ns) que se encuentran en estado En ejecución dividido por el número de intervalos de 100 ns que estaban disponibles en un intervalo de tiempo determinado. Esta es exactamente la fórmula para calcular el porcentaje de utilidad del procesador (consulte objeto Processor y PERF_100NSEC_TIMER_INV).
La teoría de colas también proporciona la fórmula: N = U k ÷ (1 – U k) para calcular el número de elementos en espera en función del uso (N es la longitud de la cola). La creación de gráficos en todos los intervalos de uso proporciona las siguientes estimaciones sobre cuánto tiempo tarda la cola en tener el procesador en una carga de CPU determinada.
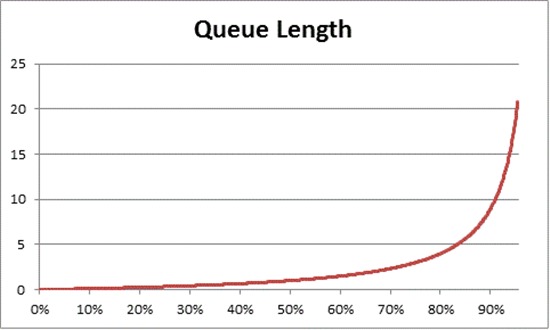
Se observa que después de una carga de CPU del 50 %, en promedio siempre hay una espera de otro elemento en la cola, con un aumento notablemente rápido después de aproximadamente un 70 % de uso de CPU.
Volviendo a la analogía de conducción usada anteriormente en esta sección:
- Las horas ocupadas de "media tarde" estarían, hipotéticamente, en algún lugar del intervalo del 40 % al 70 %. Hay suficiente tráfico como para que la capacidad de elegir cualquier carril no esté restringida en gran medida y la posibilidad de que otro conductor esté en el camino, aunque alta, no requiere el nivel de esfuerzo para "encontrar" un hueco seguro entre otros automóviles de la carretera.
- Se observará que, a medida que el tráfico se acerca a la hora punta, el sistema de carreteras se aproxima al 100 % de capacidad. Cambiar de carril puede ser muy difícil porque los automóviles están tan cerca que se debe ejercer mayor precaución para hacerlo.
Este es el motivo por el que los promedios a largo plazo de capacidad que se han calculado de forma conservadora en un 40 % permiten un espacio para picos anormales en la carga, ya sean dichos picos transitorios (como consultas mal codificadas que se ejecutan durante unos minutos) o ráfagas anómalas en la carga general (la mañana del primer día después de un fin de semana largo).
La declaración anterior relativa a que el cálculo del porcentaje de tiempo de procesador es el mismo que la Ley de utilización es un poco una simplificación para la facilidad del lector general. Para aquellos más rigurosos matemáticamente:
- Traducción de PERF_100NSEC_TIMER_INV
- B = número de intervalos de 100 ns que un subproceso "Inactivo" pasa en el procesador lógico. El cambio en la variable "X" en el cálculo de PERF_100NSEC_TIMER_INV
- T = número total de intervalos de 100 ns en un intervalo de tiempo determinado. El cambio en la variable "Y" en el cálculo de PERF_100NSEC_TIMER_INV.
- U k = porcentaje de uso del procesador lógico del "Subproceso inactivo" o porcentaje de tiempo de inactividad.
- Trabajando con las matemáticas:
- U k = 1 – porcentaje de tiempo de procesador
- Porcentaje de tiempo de procesador = 1 – U k
- Porcentaje de tiempo de procesador = 1 – B / T
- Porcentaje de tiempo de procesador = 1 – X1 – X0 / Y1 – Y0
Aplicación de los conceptos al planeamiento de capacidad
Las matemáticas anteriores pueden hacer que tomar determinaciones sobre el número de procesadores lógicos necesarios en un sistema parezca abrumadoramente complejo. Este es el motivo por el que el enfoque para dimensionar los sistemas se centra en determinar el uso máximo objetivo en función de la carga actual y calcular el número de procesadores lógicos necesarios para llegar allí. Además, aunque las velocidades del procesador lógico tendrán un impacto significativo en el rendimiento, las eficiencias de caché, los requisitos de coherencia de memoria, la programación y la sincronización de subprocesos, y la carga de cliente con un equilibrio imperfecto tendrán impactos significativos en el rendimiento que variarán servidor a servidor. Con el costo relativamente barato de la potencia de proceso, intentar analizar y determinar el número perfecto de CPU necesarias se convierte en un ejercicio académico más que en proporcionar valor empresarial.
El cuarenta por ciento no es un requisito difícil y rápido, es un comienzo razonable. Varios consumidores de Active Directory requieren varios niveles de capacidad de respuesta. Puede haber escenarios en los que los entornos se pueden ejecutar con un uso del 80 % o el 90 % como promedio sostenido, ya que los tiempos de espera aumentados para el acceso al procesador no afectarán notablemente al rendimiento del cliente. Es importante reiterar que hay muchas áreas en el sistema que son mucho más lentas que el procesador lógico del sistema, incluido el acceso a la RAM, el acceso al disco y la transmisión de la respuesta en la red. Todos estos elementos se deben optimizar conjuntamente. Ejemplos:
- Agregar más procesadores a un sistema que se ejecuta al 90 % y que está relacionado con el disco probablemente no mejorará significativamente el rendimiento. Un análisis más profundo del sistema probablemente identificará que hay una gran cantidad de subprocesos que ni siquiera llegan al procesador porque están esperando a que se complete la E/S.
- La resolución de los problemas relacionados con el disco puede significar que los subprocesos que anteriormente empleaban mucho tiempo en estado de espera ya no estarán en estado de espera por la E/S y habrá más competencia por el tiempo de CPU, lo que significa que el uso del 90 % en el ejemplo anterior irá al 100 % (porque no puede aumentar más). Ambos componentes se deben optimizar conjuntamente.
Nota
El valor de Processor Information(*)\% Processor Utility puede superar el 100 % en sistemas que tienen un modo "Turbo". Aquí es donde la CPU supera la velocidad calificada del procesador durante períodos cortos. Consulte la documentación de los fabricantes de CPU y la descripción del contador para obtener más información.
La discusión sobre las consideraciones sobre el uso completo del sistema también incluye los controladores de dominio como invitados virtualizados. Tiempo de respuesta/Cómo afecta al rendimiento la disponibilidad del sistema se aplica tanto al host como al invitado en un escenario virtualizado. Por este motivo, en un host con solo un invitado, un controlador de dominio (y, en general, cualquier sistema) tiene casi el mismo rendimiento que en el hardware físico. Agregar invitados adicionales a los hosts aumenta el uso del host subyacente, lo que aumenta los tiempos de espera para obtener acceso a los procesadores, como se explicó anteriormente. En resumen, el uso del procesador lógico se debe administrar tanto en el nivel de host como en el de invitado.
Extendiendo las analogías anteriores, siendo la autopista el hardware físico, la máquina virtual invitada sería análoga a un autobús (un autobús rápido que va directamente al destino que el viajero quiere). Imagine los cuatro escenarios siguientes:
- No es hora punta, un viajero toma un autobús que está casi vacío y el autobús toma una carretera que también está casi vacía. Como no hay tráfico con el que competir, el viajero tiene un buen paseo fácil y llega tan rápido como si el viajero hubiera ido conduciendo. Los tiempos de viaje del viajero siguen estando restringidos por el límite de velocidad.
- No es hora punta, por lo que el autobús está casi vacío, pero la mayoría de los carriles de la carretera están cerrados, por lo que la autopista sigue congestionada. El viajero está en un autobús casi vacío en un camino congestionado. Aunque el viajero no tiene mucha competencia en el autobús sobre dónde sentarse, el tiempo total de viaje sigue dictado por el resto del tráfico.
- Es hora punta, por lo que la autopista y el autobús están congestionados. No solo el viaje tarda más, sino que subir y bajar del autobús es una pesadilla porque la gente está hombro con hombro y la autopista no está mucho mejor. Agregar más autobuses (procesadores lógicos al invitado) no significa que quepan más fácilmente en la carretera, ni que el viaje se vaya a acortar.
- El escenario final, aunque la analogía se puede estar extendiendo un poco, se produce cuando el autobús está lleno, pero la carretera no está congestionada. Aunque el viajero seguirá teniendo problemas para subir y bajar del autobús, el viaje será eficaz una vez que el autobús esté en la carretera. Este es el único escenario en el que agregar más autobuses (procesadores lógicos al invitado) mejorará el rendimiento del invitado.
A partir de ahí, es relativamente fácil extrapolar que hay una serie de escenarios entre el estado 0 % utilizado y el estado 100 % utilizado de la carretera y el estado 0 % utilizado y 100 % utilizado del autobús que tienen distintos grados de impacto.
Aplicar los principios anteriores por encima del 40 % de CPU como objetivo razonable para el host así como para el invitado es un inicio razonable para el mismo razonamiento anterior, la cantidad de puesta en cola.
Apéndice B: Consideraciones relacionadas con diferentes velocidades de procesador y el efecto de la administración de energía del procesador en las velocidades de procesador
A lo largo de las secciones sobre la selección del procesador, se da por supuesto que el procesador se ejecuta al 100 % de la velocidad del reloj durante todo el tiempo que se recopilan los datos y que los sistemas de sustitución tendrán procesadores de la misma velocidad. A pesar de que ambas suposiciones en la práctica son falsas, especialmente con Windows Server 2008 R2 y versiones posteriores, donde el plan de energía predeterminado es Equilibrado, la metodología permanece, ya que es el enfoque conservador. Aunque la tasa potencial de errores puede aumentar, solo aumenta el margen de seguridad a medida que aumentan las velocidades del procesador.
- Por ejemplo, en un escenario en el que se demandan 11,25 CPU, si los procesadores estaban en ejecución a media velocidad cuando se recopilaban los datos, la estimación más precisa podría ser 5,125 ÷ 2.
- Es imposible garantizar que duplicar las velocidades del reloj duplicaría la cantidad de procesamiento que se produce durante un período de tiempo determinado. Esto se debe al hecho de que la cantidad de tiempo que los procesadores dedican a esperar a la memoria RAM u otros componentes del sistema podría permanecer igual. El efecto neto es que los procesadores más rápidos pueden estar un mayor porcentaje del tiempo inactivos mientras esperan a que se recuperen los datos. De nuevo, siendo conservadores, se recomienda seguir con el denominador común más bajo y evitar intentar calcular un nivel de precisión potencialmente falso suponiendo una comparación lineal entre las velocidades del procesador.
Como alternativa, si las velocidades del procesador en el hardware de sustitución son inferiores a las del hardware actual, sería seguro aumentar la estimación de los procesadores necesarios en una cantidad proporcional. Por ejemplo, si se calcula que se necesitan 10 procesadores para mantener la carga en un sitio, los procesadores actuales se ejecutan a 3,3 Ghz y los procesadores de sustitución se ejecutarán a 2,6 Ghz, es una disminución del 21 % en velocidad. En este caso, la cantidad recomendada serían 12 procesadores.
Dicho esto, esta variabilidad no cambiaría los objetivos de uso del procesador de administración de capacidad. Dado que las velocidades del reloj del procesador se ajustarán dinámicamente en función de la carga demandada, la ejecución del sistema bajo cargas superiores generará un escenario en el que la CPU invierte más tiempo en un estado de velocidad de reloj superior, lo que hace que el objetivo final sea un 40 % de uso en un estado de velocidad del reloj del 100 % en el pico. Cualquier valor inferior generará ahorros de energía, ya que las velocidades de CPU se limitarán durante los escenarios que no sean el pico máximo.
Nota
Una opción sería desactivar la administración de energía en los procesadores (estableciendo el plan de energía en Alto rendimiento) mientras se recopilan los datos. Esto proporcionaría una representación más precisa del consumo de CPU en el servidor objetivo.
Para ajustar las estimaciones para diferentes procesadores, solía ser seguro, excluyendo otros cuellos de botella del sistema descritos anteriormente, suponer que duplicar las velocidades del procesador duplicaría la cantidad de procesamiento que se podía realizar. En la actualidad, la arquitectura interna de los procesadores es lo suficientemente diferente entre los procesadores, que una manera más segura de medir los efectos del uso de distintos procesadores de los que se tomaron los datos es aprovechar el punto de referencia SPECint_rate2006 de Standard Performance Evaluation Corporation.
Busque las puntuaciones de SPECint_rate2006 para el procesador que está en uso y el que se planea usar.
- En el sitio web de Standard Performance Evaluation Corporation, seleccione Results, resalte CPU2006 y seleccione Search all SPECint_rate2006 results.
- En Simple Request, escriba los criterios de búsqueda para el procesador objetivo, por ejemplo, Processor Matches E5-2630 (baselinetarget) y Processor Matches E5-2650 (baseline).
- Busque la configuración del servidor y del procesador que se va a usar (o algo cercano, si no está disponible una coincidencia exacta) y anote el valor de las columnas Result y # Cores.
Para determinar el modificador, use la siguiente ecuación:
((Valor de la puntuación por cada núcleo de la plataforma objetivo) × (MHz por núcleo de la plataforma de línea base)) ÷ ((valor de la puntuación por cada núcleo de la línea base) × (MHz por núcleo de la plataforma objetivo))
Según el ejemplo anterior:
(35,83 × 2000) ÷ (33,75 × 2300) = 0,92
Multiplique el número estimado de procesadores por el modificador. En el caso anterior, para pasar del procesador E5-2650 al procesador E5-2630, multiplique las 11,25 CPU calculadas × 0,92 = 10,35 procesadores necesarios.
Apéndice C: Aspectos básicos sobre la interacción del sistema operativo con el almacenamiento
Los conceptos de teoría de colas descritos en Tiempo de respuesta/Cómo afecta al rendimiento la disponibilidad del sistema también se aplican al almacenamiento. Es necesario tener cierta familiaridad con cómo controla el sistema operativo la E/S para aplicar estos conceptos. En el sistema operativo Microsoft Windows, se crea una cola para contener las solicitudes de E/S para cada disco físico. Sin embargo, es necesario hacer una aclaración sobre el disco físico. Los controladores de matriz y las SAN presentan agregaciones de ejes al sistema operativo como discos físicos únicos. Además, los controladores de matriz y las SAN pueden agregar varios discos en un conjunto de matrices y, a continuación, dividir este conjunto de matrices en varias "particiones", que a su vez se presentan al sistema operativo como varios discos físicos (consulte la ilustración).
En esta figura, los dos ejes se reflejan y se dividen en áreas lógicas para el almacenamiento de datos (Datos 1 y Datos 2). El sistema operativo ve estas áreas lógicas como discos físicos independientes.
Aunque esto puede resultar muy confuso, se usa la terminología siguiente en este apéndice para identificar las distintas entidades:
- Eje: el dispositivo que está instalado físicamente en el servidor.
- Matriz: una colección de ejes agregados por un controlador.
- Partición de matriz: una partición de la matriz agregada
- LUN: una matriz, se usa al hacer referencia a las SAN.
- Disco: lo que el sistema operativo observa como un único disco físico.
- Partición: una partición lógica de lo que el sistema operativo percibe como un disco físico.
Consideraciones sobre la arquitectura del sistema operativo
El sistema operativo crea una cola de E/S de tipo Primero en entrar/Primero en salir (FIFO) para cada disco que se observa; este disco puede representar un eje, una matriz o una partición de matriz. Desde la perspectiva del sistema operativo con respecto al control de E/S, cuantas más colas activas, mejor. Una cola FIFO se serializa, lo que significa que todas las operaciones de E/S emitidas al subsistema de almacenamiento se deben procesar en el orden en el que llegó la solicitud. Al correlacionar cada disco observado por el sistema operativo con un eje o matriz, el sistema operativo ahora mantiene una cola de E/S para cada conjunto único de discos, lo que elimina la contención de recursos de E/S escasos entre discos y aísla la demanda de E/S a un solo disco. Como excepción, Windows Server 2008 presenta el concepto de priorización de E/S, y las aplicaciones diseñadas para usar la prioridad "Baja" salen de este orden normal y toman un asiento trasero. Las aplicaciones que no están codificadas específicamente para aprovechar la prioridad "Baja" tienen como valor predeterminado "Normal".
Introducción a los subsistemas de almacenamiento simples
A partir de un ejemplo simple (una sola unidad de disco duro dentro de un equipo), se proporcionará un análisis componentes a componente. Al desglosar esto en los principales componentes del subsistema de almacenamiento, el sistema consta de:
- 1: HD Ultra Fast SCSI de 10 000 RPM (Ultra Fast SCSI tiene una velocidad de transferencia de 20 MB/s)
- 1: Bus SCSI (el cable)
- 1: Adaptador Ultra Fast SCSI
- 1: Bus PCI de 32 bits a 33 MHz
Una vez identificados los componentes, se puede calcular una idea de la cantidad de datos que pueden transitar el sistema o la cantidad de E/S que se puede controlar. Tenga en cuenta que la cantidad de E/S y la cantidad de datos que pueden transitar el sistema están correlacionadas, pero no son lo mismo. Esta correlación depende de si la E/S del disco es aleatoria o secuencial y el tamaño del bloque. (Todos los datos se escriben en el disco como un bloque, pero diferentes aplicaciones usan tamaños de bloque diferentes). En función de los componentes:
Disco duro: un disco duro promedio de 10 000 RPM tiene un tiempo de búsqueda de 7 milisegundos (ms) y un tiempo de acceso de 3 ms. El tiempo de búsqueda es la cantidad promedio de tiempo que tarda la cabeza de lectura y escritura en moverse a una ubicación del plato. El tiempo de acceso es la cantidad promedio de tiempo que se tarda en leer o escribir los datos en el disco, una vez que la cabeza está en la ubicación correcta. Por lo tanto, el tiempo medio para leer un bloque único de datos en un HD de 10 000 RPM constituye una búsqueda y un acceso, con un total de aproximadamente 10 ms (o 0,010 segundos) por bloque de datos.
Cuando cada acceso al disco requiere el movimiento de la cabeza a una nueva ubicación del disco, el comportamiento de lectura y escritura se conoce como "aleatorio". Por lo tanto, cuando todas las operaciones de E/S son aleatorias, un HD de 10 000 RPM puede controlar aproximadamente 100 E/S por segundo (IOPS) (la fórmula es 1000 ms por segundo dividido entre 10 ms por cada E/S o 1000/10=100 IOPS).
Por otro lado, cuando todas las operaciones de E/S se producen desde sectores adyacentes en el HD, esto se conoce como E/S secuencial. La E/S secuencial no tiene tiempo de búsqueda porque cuando se completa la primera operación de E/S la cabeza de lectura y escritura está al principio de donde se almacena el siguiente bloque de datos en el HD. Por lo tanto, un HD de 10 000 RPM es capaz de controlar aproximadamente 333 E/S por segundo (1000 ms por segundo dividido entre 3 ms por cada E/S).
Nota
En este ejemplo, no se refleja la memoria caché del disco, donde normalmente se conservan los datos de un cilindro. En este caso, son necesarios 10 ms en la primera operación de E/S y el disco lee todo el cilindro. El resto de operaciones de E/S secuenciales se satisfacen desde la memoria caché. Como resultado, las memorias caché en disco pueden mejorar el rendimiento de la E/S secuencial.
Hasta ahora, la velocidad de transferencia del disco duro no ha sido pertinente. Si el disco duro es Ultra Wide de 20 MB/s o Ultra3 de 160 MB/s, la cantidad real de IOPS que puede controlar un HD de 10 000 RPM es ~100 en aleatorio o ~300 E/S en secuencial. Dado que los tamaños de bloque cambian en función de la aplicación que escribe en la unidad, la cantidad de datos que se extraen por cada E/S es diferente. Por ejemplo, si el tamaño del bloque es de 8 KB, 100 operaciones de E/S leerán o escribirán en el disco duro un total de 800 KB. Sin embargo, si el tamaño del bloque es de 32 KB, 100 operaciones de E/S leerán o escribirán 3200 KB (3,2 MB) en el disco duro. Siempre que la velocidad de transferencia de SCSI supere la cantidad total de datos transferidos, disponer de una unidad de velocidad de transferencia "más rápida" no aportará nada. Consulte las tablas siguientes para ver la comparación.
Descripción 7200 RPM con búsqueda de 9 ms, acceso de 4 ms 10 000 RPM con búsqueda de 7 ms, acceso de 3 ms 15 000 RPM con búsqueda de 4 ms, acceso de 2 ms E/S aleatoria 80 100 150 E/S secuencial 250 300 500 Unidad de 10 000 RPM Tamaño de bloque de 8 KB (Jet de Active Directory) E/S aleatoria 800 KB/s E/S secuencial 2400 KB/s Placa base SCSI (bus): comprender cómo afecta la "placa base SCSI (bus)" o, en este escenario, el cable de cinta, al rendimiento del subsistema de almacenamiento depende del conocimiento del tamaño del bloque. Básicamente, la pregunta sería, ¿cuántas operaciones de E/S puede controlar el bus si la E/S es en bloques de 8 KB? En este escenario, el bus SCSI es de 20 MB/s (o 20480 KB/s). 20480 KB/s divididos por bloques de 8 KB produce un máximo de aproximadamente 2500 IOPS admitidas por el bus SCSI.
Nota
Las cifras de la tabla siguiente representan un ejemplo. La mayoría de los dispositivos de almacenamiento conectados actualmente usan PCI Express, que proporciona un rendimiento mucho mayor.
Operaciones de E/S admitidas por el bus SCSI por tamaño de bloque Tamaño de bloque de 2 KB Tamaño de bloque de 8 KB (Jet de AD) (SQL Server 7.0/SQL Server 2000) 20 MB/s 10 000 2,500 40 MB/s 20.000 5\.000 128 MB/s 65 536 16 384 320 MB/s 160 000 40 000 Como se puede determinar a partir de este gráfico, en el escenario presentado e independientemente del uso, el bus nunca será un cuello de botella, ya que el máximo del eje es de 100 E/S, muy por debajo de cualquiera de los umbrales anteriores.
Nota
Se supone que el bus SCSI es 100 % eficaz.
Adaptador SCSI: para determinar la cantidad de E/S que puede controlar, es necesario comprobar las especificaciones del fabricante. Dirigir las solicitudes de E/S al dispositivo adecuado requiere un procesamiento de algún tipo, por lo que la cantidad de E/S que se puede controlar depende del procesador del adaptador SCSI (o controlador de matriz).
En este ejemplo, se supone que se pueden controlar 1000 E/S.
Bus PCI: se trata de un componente que a menudo se pasa por alto. En este ejemplo, esto no será el cuello de botella; sin embargo, a medida que los sistemas se escalan verticalmente, puede convertirse en un cuello de botella. Como referencia, un bus PCI de 32 bits que funcione a 33 Mhz puede transferir en teoría 133 MB/s de datos. A continuación, se muestra la ecuación:
32 bits ÷ 8 bits por byte × 33 MHz = 133 MB/s.
Tenga en cuenta que es el límite teórico; en realidad, solo se alcanza el 50 % del máximo, aunque en determinados escenarios de ráfaga, se puede obtener una eficiencia del 75 % durante períodos cortos.
Un bus PCI de 64 bits a 66 Mhz puede admitir un máximo teórico de (64 bits ÷ 8 bits por byte × 66 Mhz) = 528 MB/s. Además, cualquier otro dispositivo (por ejemplo, el adaptador de red, un segundo controlador SCSI, etc.) reducirá el ancho de banda disponible, ya que el ancho de banda se comparte y los dispositivos competirán por recursos limitados.
Después del análisis de los componentes de este subsistema de almacenamiento, el eje es el factor de limitación en la cantidad de E/S que se puede solicitar y, por tanto, la cantidad de datos que pueden transitar en el sistema. Específicamente, en un escenario de AD DS, se trata de 100 E/S aleatorias por segundo en incrementos de 8 KB, para un total de 800 KB por segundo al acceder a la base de datos Jet. Por otro lado, el rendimiento máximo de un eje que se asigne exclusivamente a los archivos de registro sufriría las siguientes limitaciones: 300 E/S secuenciales por segundo en incrementos de 8 KB, para un total de 2400 KB (2,4 MB) por segundo.
Ahora, después de analizar una configuración sencilla, la tabla siguiente muestra dónde se producirá el cuello de botella a medida que se cambien o agreguen componentes del subsistema de almacenamiento.
| Notas | Análisis de cuellos de botella | Disco | En bus | Adapter (Adaptador) | Bus PCI |
|---|---|---|---|---|---|
| Esta es la configuración del controlador de dominio después de agregar un segundo disco. La configuración del disco representa el cuello de botella a 800 KB/s. | Adición de 1 disco (Total=2) La E/S es aleatoria. Tamaño de bloque de 4 KB HD de 10 000 RPM |
Total de 200 E/S Total de 800 KB/s. |
|||
| Después de agregar 7 discos, la configuración del disco sigue representando el cuello de botella a 3200 KB/s. | Adición de 7 discos (Total=8) La E/S es aleatoria. Tamaño de bloque de 4 KB HD de 10 000 RPM |
Total de 800 E/S. Total de 3200 KB/s |
|||
| Después de cambiar la E/S a secuencial, el adaptador de red se convierte en el cuello de botella porque está limitado a 1000 IOPS. | Adición de 7 discos (Total=8) La E/S es secuencial. Tamaño de bloque de 4 KB HD de 10 000 RPM |
Se pueden leer y escribir en el disco 2400 E/S, el controlador está limitado a 1000 IOPS. | |||
| Después de sustituir el adaptador de red por un adaptador SCSI que admite 10 000 IOPS, el cuello de botella vuelve a ser la configuración del disco. | Adición de 7 discos (Total=8) La E/S es aleatoria. Tamaño de bloque de 4 KB HD de 10 000 RPM Actualización del adaptador SCSI (ahora admite 10 000 E/S) |
Total de 800 E/S. Total de 3200 KB/s |
|||
| Después de aumentar el tamaño del bloque a 32 KB, el bus se convierte en el cuello de botella porque solo admite 20 MB/s. | Adición de 7 discos (Total=8) La E/S es aleatoria. Tamaño de bloque de 32 KB HD de 10 000 RPM |
Total de 800 E/S. Se pueden leer y escribir en el disco 25 600 KB/s (25 MB/s). El bus solo admite 20 MB/s. |
|||
| Después de actualizar el bus y agregar más discos, el disco sigue siendo el cuello de botella. | Adición de 13 discos (Total=14) Adición de un segundo adaptador SCSI con 14 discos La E/S es aleatoria. Tamaño de bloque de 4 KB HD de 10 000 RPM Actualización a un bus SCSI de 320 MB/s |
2800 E/S 11 200 KB/s (10,9 MB/s) |
|||
| Después de cambiar la E/S a secuencial, el disco sigue siendo el cuello de botella. | Adición de 13 discos (Total=14) Adición de un segundo adaptador SCSI con 14 discos La E/S es secuencial. Tamaño de bloque de 4 KB HD de 10 000 RPM Actualización a un bus SCSI de 320 MB/s |
8400 E/S 33 600 KB/s (32,8 MB/s) |
|||
| Después de agregar unidades de disco duro más rápidas, el disco sigue siendo el cuello de botella. | Adición de 13 discos (Total=14) Adición de un segundo adaptador SCSI con 14 discos La E/S es secuencial. Tamaño de bloque de 4 KB HD de 15 000 RPM Actualización a un bus SCSI de 320 MB/s |
14 000 E/S 56 000 KB/s (54,7 MB/s) |
|||
| Después de aumentar el tamaño del bloque a 32 KB, el bus PCI se convierte en el cuello de botella. | Adición de 13 discos (Total=14) Adición de un segundo adaptador SCSI con 14 discos La E/S es secuencial. Tamaño de bloque de 32 KB HD de 15 000 RPM Actualización a un bus SCSI de 320 MB/s |
14 000 E/S 448 000 KB/s (437 MB/s) es el límite de lectura y escritura en el eje. El bus PCI admite un máximo teórico de 133 MB/s (75 % de eficiencia en el mejor de los casos). |
Introducción a RAID
La naturaleza de un subsistema de almacenamiento no cambia drásticamente cuando se introduce un controlador de matriz; simplemente sustituye al adaptador SCSI en los cálculos. Lo que cambia es el costo de leer y escribir datos en el disco cuando se usan distintos niveles de matriz (por ejemplo, RAID 0, RAID 1 o RAID 5).
En RAID 0, los datos se seccionan en todos los discos del conjunto RAID. Esto significa que, durante una operación de lectura o escritura, se extrae o inserta una parte de los datos en cada disco, lo que aumenta la cantidad de datos que pueden transitar el sistema durante el mismo período de tiempo. Por lo tanto, en un segundo, en cada eje (suponiendo de nuevo unidades de 10 000 RPM) se pueden realizar 100 operaciones de E/S. La cantidad total de E/S que se puede admitir es de N ejes por 100 E/S por segundo por eje (produce 100*N operaciones de E/S por segundo).

En RAID 1, los datos se reflejan (duplican) en un par de ejes para la redundancia. Por lo tanto, cuando se realiza una operación de E/S de lectura, los datos se pueden leer de ambos ejes del conjunto. Esto hace que esté disponible la capacidad de E/S de ambos discos durante una operación de lectura. La advertencia es que las operaciones de escritura no obtienen ninguna ventaja de rendimiento en un RAID 1. Esto se debe a que se deben escribir los mismos datos en ambas unidades por motivos de redundancia. Aunque no se tarda más, ya que la escritura de datos se produce simultáneamente en ambos ejes; dado que ambos ejes están ocupados duplicando los datos, una operación de E/S de escritura evita básicamente que se produzcan dos operaciones de lectura. Por lo tanto, cada E/S de escritura cuesta dos E/S de lectura. Se puede crear una fórmula a partir de esa información para determinar el número total de operaciones de E/S que se producen:
E/S de lectura + 2 × E/S de escritura = Total de E/S disponible de disco consumida
Cuando se conoce la proporción de lecturas frente a escrituras y el número de ejes, la siguiente ecuación se puede derivar de la ecuación anterior para identificar el número máximo de E/S que puede admitir la matriz:
Número máximo de IOPS por eje × 2 ejes × [(% Lecturas + % Escrituras) ÷ (% Lecturas + 2 × % Escrituras)] = Total de IOPS
RAID 1+0 se comporta exactamente igual que RAID 1 con respecto al gasto de lectura y escritura. Sin embargo, ahora la E/S está seccionada en cada conjunto reflejado. Si
Número máximo de IOPS por eje × 2 ejes × [(% Lecturas + % Escrituras) ÷ (% Lecturas + 2 × % Escrituras)] = E/S total
En un conjunto RAID 1, cuando se seccionan varios (N) conjuntos RAID 1, la E/S total que se puede procesar se convierte en N × E/S por cada conjunto RAID 1:
N × {Número máximo de IOPS por eje × 2 ejes × [(% Lecturas + % Escrituras) ÷ (% Lecturas + 2 × % Escrituras)] } = Total de IOPS
En RAID 5, a veces conocido como RAID N+1, los datos se seccionan en N ejes y la información de paridad se escribe en el eje "+1". Sin embargo, RAID 5 es mucho más caro al realizar una E/S de escritura que RAID 1 o RAID 1+0. RAID 5 realiza el siguiente proceso cada vez que se envía una E/S de escritura a la matriz:
- Leer los datos antiguos
- Leer la paridad antigua
- Escribir los datos nuevos
- Escribir la nueva paridad
Dado que cada solicitud de E/S de escritura que el sistema operativo envía al controlador de matriz requiere que se completen cuatro operaciones de E/S, las solicitudes de escritura enviadas tardan cuatro veces más en completarse que una única E/S de lectura. Para derivar una fórmula para traducir las solicitudes de E/S desde la perspectiva del sistema operativo a la que experimentan los ejes:
E/S de lectura + 4 × E/S de escritura = E/S total
De forma similar, en un conjunto RAID 1, cuando se conoce la proporción de lecturas y escrituras y el número de ejes, la siguiente ecuación se puede derivar de la ecuación anterior para identificar la E/S máxima que puede admitir la matriz (tenga en cuenta que el número total de ejes no incluye la "unidad" perdida para la paridad):
Número de IOPS por eje × (ejes – 1) × [(% Lecturas + % Escrituras) ÷ (% Lecturas + 4 × % Escrituras)] = Total de IOPS
Introducción a las SAN
Al expandir la complejidad del subsistema de almacenamiento, cuando se introduce una SAN en el entorno, los principios básicos descritos no cambian, sin embargo, se debe tener en cuenta el comportamiento de E/S de todos los sistemas conectados a la SAN. Como una de las principales ventajas de usar una SAN es una cantidad adicional de redundancia sobre el almacenamiento conectado interna o externamente, el planeamiento de capacidad ahora debe tener en cuenta las necesidades de tolerancia a errores. Además, se incorporan más componentes que se deben evaluar. División de una SAN en sus componentes:
- Disco duro SCSI o Canal de fibra
- Placa base del canal de la unidad de almacenamiento
- Unidades de almacenamiento
- Módulo de controlador de almacenamiento
- Conmutadores SAN
- Adaptadores de bus host
- Bus PCI
Al diseñar cualquier sistema para la redundancia, se incluyen componentes adicionales para dar cabida a errores potenciales. Al planear la capacidad, es muy importante excluir el componente redundante de los recursos disponibles. Por ejemplo, si la SAN tiene dos módulos de controlador, la capacidad de E/S de un módulo de controlador es todo lo que se debe usar para el rendimiento total de E/S disponible para el sistema. Esto se debe a que, si se produce un error en un controlador, el controlador restante deberá procesar toda la carga de E/S demandada por todos los sistemas conectados. Dado que todo el planeamiento de capacidad se realiza para períodos de uso máximo, los componentes redundantes no se deben tener en cuenta en los recursos disponibles y el uso máximo planeado no debe superar el 80 % de saturación del sistema (para dar cabida a ráfagas o un comportamiento anómalo del sistema). Del mismo modo, el conmutador SAN redundante, la unidad de almacenamiento y los ejes no se deben tener en cuenta en los cálculos de E/S.
Al analizar el comportamiento de la unidad de disco duro SCSI o Canal de fibra, el método para analizar el comportamiento como se describió anteriormente no cambia. Aunque hay ciertas ventajas y desventajas en cada protocolo, el factor de limitación por cada disco es la limitación mecánica del disco duro.
El análisis del canal en la unidad de almacenamiento es exactamente el mismo que el cálculo de los recursos disponibles en el bus SCSI, o el ancho de banda (por ejemplo, 20 MB/s) dividido por el tamaño de bloque (por ejemplo, 8 KB). Donde esto se desvía del ejemplo anterior simple es en la agregación de varios canales. Por ejemplo, si hay 6 canales y cada uno admite una velocidad de transferencia máxima de 20 MB/s, la cantidad total de E/S y la transferencia de datos que está disponible es de 100 MB/s (esto es correcto, no es de 120 MB/s). Una vez más, la tolerancia a errores es un jugador importante en este cálculo, en caso de pérdida de un canal completo, el sistema solo queda con 5 canales en funcionamiento. Por lo tanto, para asegurarse de seguir cumpliendo las expectativas de rendimiento en caso de error, el rendimiento total de todos los canales de almacenamiento no debe superar los 100 MB/s (se supone que la carga y la tolerancia a errores se distribuye uniformemente entre todos los canales). Convertir esto en un perfil de E/S depende del comportamiento de la aplicación. En el caso de la E/S de Jet de Active Directory, esto se correlacionaría con aproximadamente 12 500 E/S por segundo (100 MB/s ÷ 8 KB por cada E/S).
A continuación, se requieren las especificaciones del fabricante de los módulos de controlador para comprender el rendimiento que puede admitir cada módulo. En este ejemplo, la SAN tiene dos módulos de controlador que admiten 7500 E/S cada uno. El rendimiento total del sistema puede ser de 15 000 IOPS si no se desea redundancia. Al calcular el rendimiento máximo en caso de error, la limitación es el rendimiento de un controlador (o 7500 IOPS). Este umbral está muy por debajo del máximo de 12 500 IOPS (suponiendo un tamaño de bloque de 4 KB) que pueden admitir todos los canales de almacenamiento y, por tanto, actualmente es el cuello de botella en el análisis. Aún con fines de planeamiento, la E/S máxima deseada para la que se va a planear sería de 10 400 E/S.
Cuando los datos salen del módulo de controlador, transitan por una conexión de Canal de fibra clasificada en 1 GB/s (1 Gigabit por segundo). Para correlacionar esto con las demás métricas, 1 GB/s se convierte en 128 MB/s (1 GB/s ÷ 8 bits/byte). Dado que esto supera el ancho de banda total de todos los canales de la unidad de almacenamiento (100 MB/s), esto no afectará al sistema. Además, dado que solo se trata de uno de los dos canales (la conexión de Canal de fibra adicional de 1 GB/s para la redundancia), si se produce un error en una conexión, la conexión restante sigue teniendo capacidad suficiente para controlar todas las transferencias de datos demandadas.
En su ruta hacia el servidor, los datos probablemente transitarán por un conmutador SAN. Dado que el conmutador SAN tiene que procesar la solicitud de E/S entrante y reenviarla por el puerto adecuado, el conmutador tendrá un límite para la cantidad de E/S que se puede controlar; sin embargo, serán necesarias las especificaciones del fabricante para determinar cuál es ese límite. Por ejemplo, si hay dos conmutadores y cada conmutador puede controlar 10 000 IOPS, el rendimiento total será de 20 000 IOPS. Una vez más, la tolerancia a errores es un problema, si se produce un error en un conmutador, el rendimiento total del sistema será de 10 000 IOPS. Como se desea no superar el 80 % de uso en el funcionamiento normal, el objetivo debe ser utilizar no más de 8000 E/S.
Por último, el HBA instalado en el servidor también tendría un límite en cuanto a la cantidad de E/S que puede controlar. Normalmente, se instala un segundo HBA para la redundancia, pero igual que con el conmutador SAN, al calcular la E/S máxima que se puede controlar, el rendimiento total de N – 1 HBA es la escalabilidad máxima del sistema.
Consideraciones sobre el almacenamiento en caché
Las memorias caché son uno de los componentes que pueden afectar significativamente al rendimiento general en cualquier punto del sistema de almacenamiento. El análisis detallado de los algoritmos de almacenamiento en caché está fuera del ámbito de este artículo; sin embargo, vale la pena destacar algunas instrucciones básicas sobre el almacenamiento en caché en subsistemas de disco:
El almacenamiento en caché mejora la E/S de escritura secuencial sostenida, ya que puede almacenar en búfer muchas operaciones de escritura más pequeñas en bloques de E/S más grandes y distribuir el almacenamiento en menos bloques, pero de tamaño más grande. Esto reducirá la E/S aleatoria total y la E/S secuencial total, lo que proporcionará más disponibilidad de recursos para otras E/S.
El almacenamiento en caché no mejora el rendimiento de E/S de escritura sostenido del subsistema de almacenamiento. Solo permite almacenar en búfer las escrituras hasta que los ejes estén disponibles para confirmar los datos. Cuando toda la E/S disponible de los ejes del subsistema de almacenamiento está saturada durante largos períodos, la memoria caché se rellenará finalmente. Para vaciar la memoria caché, es necesario asignar suficiente tiempo entre ráfagas, o ejes adicionales, para proporcionar suficiente E/S para permitir que la memoria caché se vacíe.
Las memorias caché más grandes solo permiten almacenar en búfer más datos. Esto significa que se puede dar cabida a períodos de saturación más largos.
En un subsistema de almacenamiento en funcionamiento normal, el sistema operativo experimentará un rendimiento de escritura mejorado, ya que los datos solo se deben escribir en la memoria caché. Una vez que el medio subyacente esté saturado con la E/S, la memoria caché se llenará y el rendimiento de escritura volverá a la velocidad del disco.
Al almacenar en caché la E/S de lectura, el escenario en el que la memoria caché es más ventajosa se produce cuando los datos se almacenan secuencialmente en el disco y la memoria caché puede leer con antelación (supone que el siguiente sector contiene los datos que se solicitarán a continuación).
Cuando la E/S de lectura es aleatoria, es poco probable que el almacenamiento en caché en el controlador de la unidad proporcione cualquier mejora en la cantidad de datos que se pueden leer desde el disco. No existe ninguna mejora si el tamaño de caché basado en la aplicación o el sistema operativo es mayor que el tamaño de caché basado en hardware.
En el caso de Active Directory, la memoria caché solo está limitada por la cantidad de RAM.
Consideraciones sobre SSD
Los SSD son un animal completamente diferente a los discos duros basados en eje. Sin embargo, los dos criterios clave siguen siendo: "¿cuántas IOPS puede controlar?" y "¿cuál es la latencia de esas IOPS?" En comparación con los discos duros basados en eje, los discos SSD pueden controlar mayores volúmenes de E/S y pueden tener latencias más bajas. En general, y en el momento de escribir este documento, aunque los SSD siguen siendo costosos en una comparación de costo por gigabyte, son muy baratos en términos de costo por E/S y merecen una consideración significativa en términos de rendimiento del almacenamiento.
Consideraciones:
- Tanto las IOPS como las latencias son muy subjetivas de los diseños del fabricante y, en algunos casos, se ha observado que tienen un rendimiento más deficiente que las tecnologías basadas en eje. En resumen, es más importante revisar y validar las especificaciones del fabricante unidad por unidad y no dar por supuesta ninguna generalidad.
- Los tipos de IOPS pueden tener cifras muy diferentes en función de si son de lectura o escritura. Los servicios de AD DS, en general, que se basan principalmente en lecturas, se verán menos afectados que otros escenarios de aplicación.
- "Resistencia de escritura": este es el concepto que indica que las celdas del SSD se agotarán finalmente. Los diferentes fabricantes tratan este desafío de diferentes formas. Al menos para la unidad de base de datos, el perfil de E/S de lectura predominante permite minimizar la importancia de este problema, ya que los datos no son altamente volátiles.
Resumen
Una manera de pensar en el almacenamiento es imaginar la fontanería doméstica. Imagine que la IOPS de los medios en los que se almacenan los datos es el sumidero principal del hogar. Cuando está obstruido (por ejemplo, por raíces en la tubería) o limitado (está saturado o es demasiado pequeño), todos los desagües del hogar se atascan cuando se utiliza demasiada agua (demasiados invitados). Esto es perfectamente análogo a un entorno compartido en el que uno o varios sistemas aprovechan el almacenamiento compartido SAN/NAS/iSCSI con el mismo medio subyacente. Se pueden adoptar diferentes enfoques para resolver los distintos escenarios:
- Un sumidero saturado o infradimensionado requiere una sustitución y corrección completas. Esto sería similar a agregar hardware nuevo o redistribuir los sistemas que usan el almacenamiento compartido entre toda la infraestructura.
- Una tubería "obstruida" normalmente significa la identificación de uno o varios problemas infractores y la eliminación de esos problemas. En un escenario de almacenamiento, podrían ser copias de seguridad de nivel de sistema o almacenamiento, exámenes antivirus sincronizados en todos los servidores o software de desfragmentación sincronizado que se ejecuta durante los períodos máximos.
En cualquier diseño de fontanería, varios sumideros alimentan el sumidero principal. Si algo detiene uno de esos sumideros o un punto de unión, solo se atascará lo que hay detrás de ese punto de unión. En un escenario de almacenamiento, podría tratarse de un conmutador sobrecargado (escenario SAN/NAS/iSCSI), problemas de compatibilidad de controladores (combinación de controlador/firmware HBA/storport.sys incorrecta) o copia de seguridad/antivirus/desfragmentación. Para determinar si la "tubería" de almacenamiento es lo suficientemente grande, es necesario medir las IOPS y el tamaño de las operaciones de E/S. Se deben sumar en cada unión para garantizar un "diámetro de tubería" adecuado.
Apéndice D: Discusión sobre la solución de problemas de almacenamiento: entornos en los que proporcionar al menos tanta RAM como el tamaño de la base de datos no es una opción viable
Resulta útil comprender por qué existen estas recomendaciones para que se puedan dar cabida a los cambios en la tecnología de almacenamiento. Estas recomendaciones existen por dos motivos. El primero es el aislamiento de E/S, de modo que los problemas de rendimiento (es decir, la paginación) en el eje del sistema operativo no afecten al rendimiento de la base de datos y los perfiles de E/S. El segundo es que los archivos de registro de AD DS (y la mayoría de las bases de datos) son secuenciales por naturaleza, y las memorias caché y las unidades de disco duro basadas en eje tienen una gran ventaja de rendimiento cuando se usan con E/S secuencial en comparación con los patrones de E/S más aleatorios del sistema operativo y casi puramente aleatorios de la unidad de base de datos de AD DS. Al aislar la E/S secuencial en una unidad física independiente, se puede aumentar el rendimiento. El desafío que presentan las opciones de almacenamiento actuales es que las suposiciones fundamentales que subyacen a estas recomendaciones ya no son verdaderas. En muchos escenarios de almacenamiento virtualizado, como iSCSI, SAN, NAS y los archivos de imagen de disco virtual, el medio de almacenamiento subyacente se comparte entre varios hosts, lo que niega completamente tanto el "aislamiento de E/S" como los aspectos de "optimización de E/S secuencial". De hecho, estos escenarios agregan una capa adicional de complejidad en la que otros hosts que acceden al medio compartido pueden degradar la capacidad de respuesta del controlador de dominio.
En el planeamiento del rendimiento del almacenamiento, hay tres categorías que se deben tener en cuenta: estado de caché en frío, estado de caché activa y copia de seguridad o restauración. El estado de caché en frío se produce en escenarios como, por ejemplo, cuando se reinicia inicialmente el controlador de dominio o se reinicia el servicio de Active Directory y no hay datos de Active Directory en la RAM. El estado de caché activa se produce cuando el controlador de dominio está en un estado estable y la base de datos está almacenada en caché. Es importante tener en cuenta esto, ya que impulsarán perfiles de rendimiento muy diferentes y tener suficiente RAM para almacenar en caché toda la base de datos no ayuda al rendimiento cuando la memoria caché está inactiva. Se puede considerar el diseño de rendimiento para estos dos escenarios con la siguiente analogía, el calentamiento de la memoria caché en frío es un "esprint" y la ejecución de un servidor con una memoria caché activa es un "maratón".
En el caso del escenario de caché en frío y de caché activa, la pregunta se convierte en la rapidez con la que el almacenamiento puede mover los datos del disco a la memoria. La activación de la memoria caché es un escenario en el que, con el tiempo, el rendimiento mejora a medida que más consultas reutilizan los datos, aumenta la tasa de aciertos de caché y disminuye la frecuencia de la necesidad de acceder al disco. Como resultado, disminuye el impacto adverso en el rendimiento de acceder al disco. Cualquier degradación del rendimiento es solo transitoria mientras se espera a que la memoria caché se active y aumente hasta el tamaño máximo permitido, que depende del sistema. La conversación se puede simplificar en la rapidez con la que se pueden obtener los datos del disco y es una medida sencilla de las IOPS disponibles para Active Directory, que es subjetiva de las IOPS disponibles en el almacenamiento subyacente. Desde la perspectiva del planeamiento, dado que la activación de la memoria caché y los escenarios de copia de seguridad y restauración se producen de forma excepcional, normalmente se producen fuera de las horas y son subjetivos respecto a la carga del controlador de dominio, no existen recomendaciones generales, excepto que estas actividades se programen para horas no punta.
AD DS, en la mayoría de los escenarios, es principalmente de E/S de lectura, normalmente una proporción del 90 % de lectura y el 10 % de escritura. La E/S de lectura suele ser el cuello de botella de la experiencia del usuario y, con la E/S de escritura, hace que el rendimiento de escritura se degrade. Dado que la E/S del archivo NTDS.dit es principalmente aleatoria, las memorias caché tienden a proporcionar una ventaja mínima en la E/S de lectura, lo que hace que sea mucho más importante configurar correctamente el almacenamiento para el perfil de E/S de lectura.
En condiciones de funcionamiento normales, el objetivo del planeamiento del almacenamiento es minimizar los tiempos de espera de una solicitud de AD DS que se va a devolver desde el disco. Esto significa básicamente que el número de operaciones de E/S pendientes sea menor o equivalente al número de rutas de acceso al disco. Hay varias formas de medir esto. En un escenario de supervisión del rendimiento, la recomendación general es que LogicalDisk(<Unidad de la base de datos NTDS>)\Avg Disk sec/Read sea inferior a 20 ms. El umbral de funcionamiento deseado debe ser mucho menor, preferiblemente lo más cercano posible a la velocidad del almacenamiento, en el intervalo de 2 a 6 milisegundos (0,002 a 0,006 segundos) según el tipo de almacenamiento.
Ejemplo:
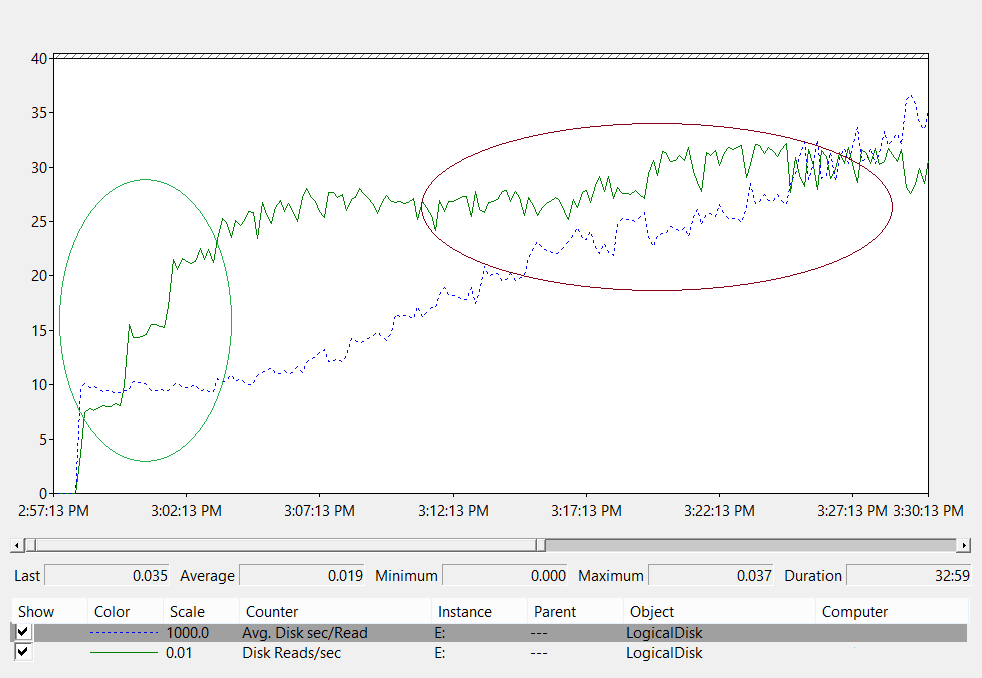
Análisis del gráfico:
- Óvalo verde de la izquierda: la latencia sigue siendo uniforme con un valor de 10 ms. La carga aumenta de 800 IOPS a 2400 IOPS. Este es el valor mínimo absoluto de la rapidez con la que el almacenamiento subyacente puede procesar una solicitud de E/S. Esto está sujeto a los detalles de la solución de almacenamiento.
- Óvalo burdeos de la derecha: el rendimiento permanece plano desde la salida del círculo verde hasta el final de la recopilación de datos, mientras que la latencia continúa aumentando. Esto demuestra que, cuando los volúmenes de solicitudes superan las limitaciones físicas del almacenamiento subyacente, más tiempo pasarán las solicitudes en la cola esperando que se envíen al subsistema de almacenamiento.
Aplicación de este conocimiento:
- Impacto en un usuario que consulta la pertenencia a un grupo grande: supongamos que esto requiere leer 1 MB de datos del disco, la cantidad de E/S y cuánto tiempo tardará se puede evaluar de la siguiente manera:
- Las páginas de la base de datos de Active Directory tienen un tamaño de 8 KB.
- Es necesario leer desde el disco un mínimo de 128 páginas.
- Suponiendo que no se almacena en caché nada, en el valor mínimo (10 ms), esto tardará un mínimo de 1,28 segundos en cargar los datos del disco para devolverlos al cliente. A 20 ms, donde el rendimiento del almacenamiento ha superado hace mucho el máximo y también es el máximo recomendado, tardará 2,5 segundos en obtener los datos del disco para devolverlos al usuario final.
- A qué velocidad se activará la memoria caché: suponiendo que la carga del cliente va a maximizar el rendimiento en este ejemplo de almacenamiento, la memoria caché se activará a una velocidad de 2400 IOPS × 8 KB por cada E/S. O bien, aproximadamente 20 MB/s por segundo, cargando aproximadamente 1 GB de la base de datos en RAM cada 53 segundos.
Nota
Es normal que en períodos cortos se observe una subida de latencias cuando los componentes leen o escriben de forma agresiva en el disco, como cuando se realiza una copia de seguridad del sistema o cuando AD DS ejecuta la recolección de elementos no utilizados. Se debe proporcionar espacio adicional al de los cálculos para dar cabida a estos eventos periódicos. El objetivo es proporcionar un rendimiento suficiente para dar cabida a estos escenarios sin afectar al funcionamiento normal.
Como se puede ver, hay un límite físico basado en el diseño del almacenamiento para la rapidez con la que se puede activar la memoria caché. Lo que activará la memoria caché son las solicitudes de cliente entrantes hasta la velocidad que puede proporcionar el almacenamiento subyacente. La ejecución de scripts para la "activación previa" de la memoria caché durante las horas punta proporcionará competencia para la carga impulsada por las solicitudes de cliente reales. Esto puede afectar negativamente a la entrega de datos que los clientes necesitan antes porque, por diseño, generará competencia por recursos de disco escasos, ya que los intentos artificiales de activar la memoria caché cargarán datos que no son pertinentes para los clientes que se conectan al controlador de dominio.