Novedades de Desduplicación de datos
Se aplica a: Windows Server 2022, Windows Server 2019, Windows Server 2016; Azure Stack HCI, versiones 21H2 y 20H2
Desduplicación de datos en Windows Server se ha optimizado para ser altamente eficaz, flexible y administrable a escala de nube privada. Para más información sobre la pila de almacenamiento definida por software en Windows Server, consulte Novedades de Espacios de almacenamiento en Windows Server.
Windows Server 2022
Desduplicación de datos no tiene mejoras adicionales en Windows Server 2022.
Windows Server 2019
Desduplicación de datos presenta las siguientes mejoras en Windows Server 2019:
| Funcionalidad | Nueva o actualizada | Descripción |
|---|---|---|
| Compatibilidad con ReFS | Nuevo | Almacene hasta 10 veces más datos en el mismo volumen con desduplicación y compresión para el sistema de archivos ReFS. (Solo hace falta un clic para activarlo con Windows Admin Center). El almacenamiento de fragmentos de tamaño variable con compresión opcional maximiza las tasas de ahorro, mientras que la arquitectura de posprocesamiento de varios procesos mantiene un impacto mínimo en el rendimiento. Admite volúmenes de hasta 64 TB y desduplicará los primeros 4 TB de cada archivo. |
Windows Server 2016
Desduplicación de datos presenta las siguientes mejoras a partir de Windows Server 2016:
| Funcionalidad | Nueva o actualizada | Descripción |
|---|---|---|
| Compatibilidad con volúmenes grandes | Actualizado | Antes de Windows Server 2016, los volúmenes debían tener un tamaño específico para la renovación esperada, y aquellos tamaños de volúmenes por encima de los 10 TB no eran buenos candidatos para la desduplicación. En Windows Server 2016, Desduplicación de datos admite tamaños de volúmenes de hasta 64 TB. |
| Compatibilidad con archivos de gran tamaño | Actualizado | Antes de Windows Server 2016, los archivos cuyo tamaño se aproximase a 1 TB no eran buenos candidatos para la desduplicación. En Windows Server 2016, los archivos de hasta 1 TB son totalmente compatibles. |
| Compatibilidad con Nano Server | Nuevo | Desduplicación de datos está disponible y es totalmente compatible con la nueva opción de implementación de Nano Server para Windows Server 2016. |
| Compatibilidad con copia de seguridad simplificada | Nuevo | Las aplicaciones de copia de seguridad virtualizadas de Windows Server 2012 R2, como Data Protection Manager de Microsoft, se admitían a través de una serie de pasos de configuración manual. En Windows Server 2016, se ha agregado un nuevo tipo de uso predeterminado (Copia de seguridad) para una implementación fluida de Desduplicación de datos para aplicaciones virtualizadas de copia de seguridad. |
| Compatibilidad con las actualizaciones graduales de sistema operativo de clúster | Nuevo | Desduplicación de datos es totalmente compatible con la nueva característica Actualización gradual de sistema operativo de clúster de Windows Server 2016. |
Compatibilidad con volúmenes grandes
¿Qué valor aporta este cambio?
Con el fin de obtener el mejor rendimiento de Desduplicación de datos en Windows Server 2012 R2, los tamaños de los volúmenes deben ajustarse correctamente para asegurarse de que el trabajo de optimización pueda mantenerse al día con la tasa de cambios de datos o abandono. Normalmente, esto significa que Desduplicación de datos es eficaz solo en volúmenes de 10 TB o menos, dependiendo de los patrones de escritura de la carga de trabajo.
A partir de Windows Server 2016, Desduplicación de datos tiene un rendimiento excelente en volúmenes de hasta 64 TB.
¿Qué funciona de manera diferente?
En Windows Server 2012 R2, la canalización de trabajos de Desduplicación de datos utiliza un único subproceso y una cola de E/S para cada volumen. Para asegurarse de que los trabajos de optimización no se retrasen, lo que haría que se redujera la tasa de ahorro global del volumen, es necesario dividir los grandes conjuntos de datos en volúmenes menores. El tamaño de volumen apropiado depende de la renovación esperada para ese volumen. Por término medio, el máximo es de ~ 6-7 TB para volúmenes de alta renovación y de ~ 9-10 TB para volúmenes de baja renovación.
A partir de Windows Server 2016, la canalización de trabajo de Desduplicación de datos se ha rediseñado para ejecutar varios subprocesos en paralelo con varias colas de E/S para cada volumen. Esto se traduce en un rendimiento que anteriormente solo era posible dividiendo los datos en varios volúmenes menores. Este cambio se representa en la siguiente imagen:
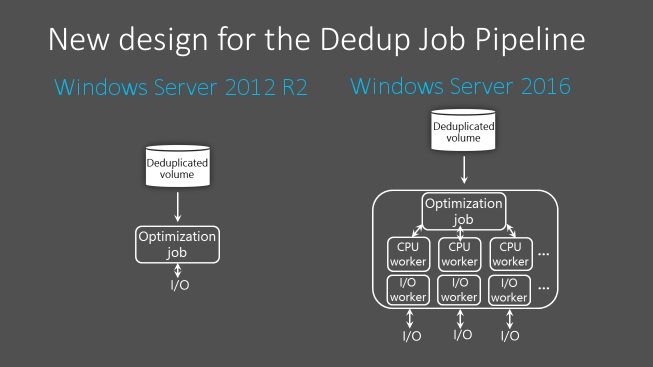
Estas optimizaciones se aplican a todos los trabajos de Desduplicación de datos, no solo al trabajo de optimización.
Compatibilidad con archivos de gran tamaño
¿Qué valor aporta este cambio?
En Windows Server 2012 R2, los archivos muy grandes no son buenos candidatos para Desduplicación de datos debido a la reducción del rendimiento de la canalización de procesamiento de desduplicación. En Windows Server 2016, la desduplicación de archivos de hasta 1 TB es muy eficaz, lo que permite a los administradores aplicar ahorros de desduplicación a un mayor grupo de cargas de trabajo. Por ejemplo, pueden desduplicarse archivos muy grandes que normalmente se asocian con cargas de trabajo de copia de seguridad.
¿Qué funciona de manera diferente?
A partir de Windows Server 2016, Deduplicación de datos hace uso de nuevas estructuras de mapa de flujo y otras mejoras "bajo el capó" para aumentar el rendimiento de optimización y el rendimiento de acceso. Además, la canalización de procesamiento de desduplicación ahora puede reanudar la optimización después de una conmutación por error en lugar de reiniciar. Estos cambios hacen que la desduplicación en archivos de hasta 1 TB sea altamente eficaz.
Compatibilidad con Nano Server
¿Qué valor aporta este cambio?
Nano Server es una nueva opción de implementación desatendida de Windows Server 2016 que requiere una superficie de recursos del sistema mucho más pequeña, se inicia mucho más rápido y requiere menos actualizaciones y reinicios que la opción de implementación de Windows Server Core. Desduplicación de datos es totalmente compatible con Nano Server. Para más información sobre Nano Server, consulte Getting Started with Nano Server (Introducción a Nano Server).
Configuración simplificada de aplicaciones virtualizadas de copia de seguridad
¿Qué valor aporta este cambio?
Aunque Desduplicación de datos para aplicaciones virtualizadas de copia de seguridad es un escenario admitido en Windows Server 2012 R2, requiere el ajuste manual de la configuración de desduplicación. A partir de Windows Server 2016, la configuración de Desduplicación de datos para aplicaciones virtualizadas de copia de seguridad se simplifica radicalmente. Utiliza una opción de tipo de uso predefinido al habilitar la desduplicación para un volumen, como las opciones del Servidor de archivos de uso general y VDI.
Compatibilidad con las actualizaciones graduales de sistema operativo de clúster
¿Qué valor aporta este cambio?
Los clústeres de conmutación por error de Windows Server que ejecutan Desduplicación de datos pueden tener una combinación de nodos que ejecutan versiones de Desduplicación de datos de Windows Server 2012 R2 junto con nodos que ejecutan versiones de Desduplicación de datos de Windows Server 2016. Esta mejora proporciona un acceso de datos completo a todos los volúmenes desduplicados durante una actualización gradual de clúster, lo que permite la implementación gradual de la nueva versión de Desduplicación de datos en un clúster de Windows Server 2012 R2 existente sin incurrir en tiempo de inactividad para actualizar todos los nodos a la vez.
¿Qué funciona de manera diferente?
Con versiones anteriores de Windows Server, un clúster de conmutación por error de Windows Server requería que todos los nodos del clúster tuvieran exactamente la misma versión de Windows Server. A partir de Windows Server 2016, la funcionalidad de actualización gradual de clústeres permite que un clúster se ejecute en modo mixto. Desduplicación de datos es compatible con esta nueva configuración de clúster en modo mixto para habilitar el acceso de datos completo durante una actualización gradual de clúster.