Inicio rápido: Reconocimiento de intenciones con el servicio de voz y LUIS
Importante
LUIS se retirará el 1 de octubre de 2025. Desde el 1 de abril de 2023, no se pueden crear nuevos recursos de LUIS. Se recomienda migrar las aplicaciones de LUIS al reconocimiento del lenguaje conversacional para aprovechar el soporte continuo del producto y las capacidades multilingües.
El reconocimiento del lenguaje conversacional (CLU) está disponible para C# y C++ con el SDK de Voz versión 1.25 o posterior. Consulte el inicio rápido para reconocer intenciones con el SDK de Voz y CLU.
Documentación de referencia | Paquete (NuGet) | Ejemplos adicionales en GitHub
En este inicio rápido, usará el SDK de Voz y el servicio Language Understanding (LUIS) para reconocer los intentos de los datos de audio capturados de un micrófono. En concreto, usará el SDK de Voz para capturar la voz y un dominio predefinido de LUIS para identificar las intenciones de automatización doméstica, como encender y apagar una luz.
Requisitos previos
- Una suscripción a Azure: cree una cuenta gratuita
- Cree un recurso de idioma en Azure Portal. Puede usar el plan de tarifa gratis (
F0) para probar el servicio y actualizarlo más adelante a un plan de pago para producción. Esta vez no necesitará un recurso de voz. - Obtenga la clave de recurso de idioma y la región. Una vez implementado el recurso de Idioma, seleccione Ir al recurso para ver y administrar claves.
Creación de una aplicación de LUIS para el reconocimiento de la intención
Para completar el inicio rápido de reconocimiento de la intención, deberá crear una cuenta de LUIS y un proyecto mediante el portal de la versión preliminar de LUIS. Este inicio rápido requiere una suscripción de LUIS en una región donde el reconocimiento de intenciones esté disponible. No se requiere una suscripción al servicio de voz.
Lo primero que debe hacer es crear una cuenta y una aplicación de LUIS mediante el portal de vista previa de LUIS. La aplicación de LUIS que cree usará un dominio precompilado para la automatización doméstica, que proporciona intenciones, entidades y expresiones de ejemplo. Cuando termine, tendrá un punto de conexión de LUIS que se ejecuta en la nube al que puede llamar mediante el SDK de Voz.
Siga estas instrucciones para crear una aplicación de LUIS:
Cuando haya terminado, necesitará cuatro cosas:
- Volver a publicar con la preparación para la voz activada
- La clave principal de LUIS
- La ubicación de LUIS
- El identificador de la aplicación de LUIS
Aquí es donde puede encontrar esta información en el portal de vista previa de LUIS:
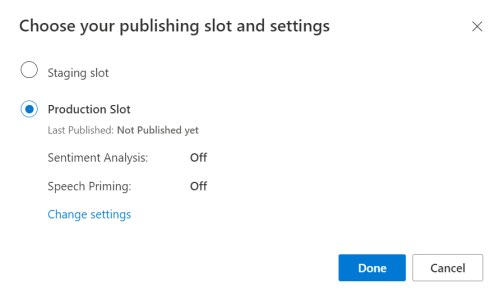
En el portal de la versión preliminar de LUIS, seleccione la aplicación y, a continuación, seleccione el botón Publicar.
Seleccione el espacio de producción; si usa
en-US, seleccione Cambiar configuración y cambie la opción Preparación para la voz a la posición On. A continuación, seleccione el botón Publicar.Importante
Se recomienda encarecidamente la preparación para la voz, ya que mejorará la precisión del reconocimiento de voz.
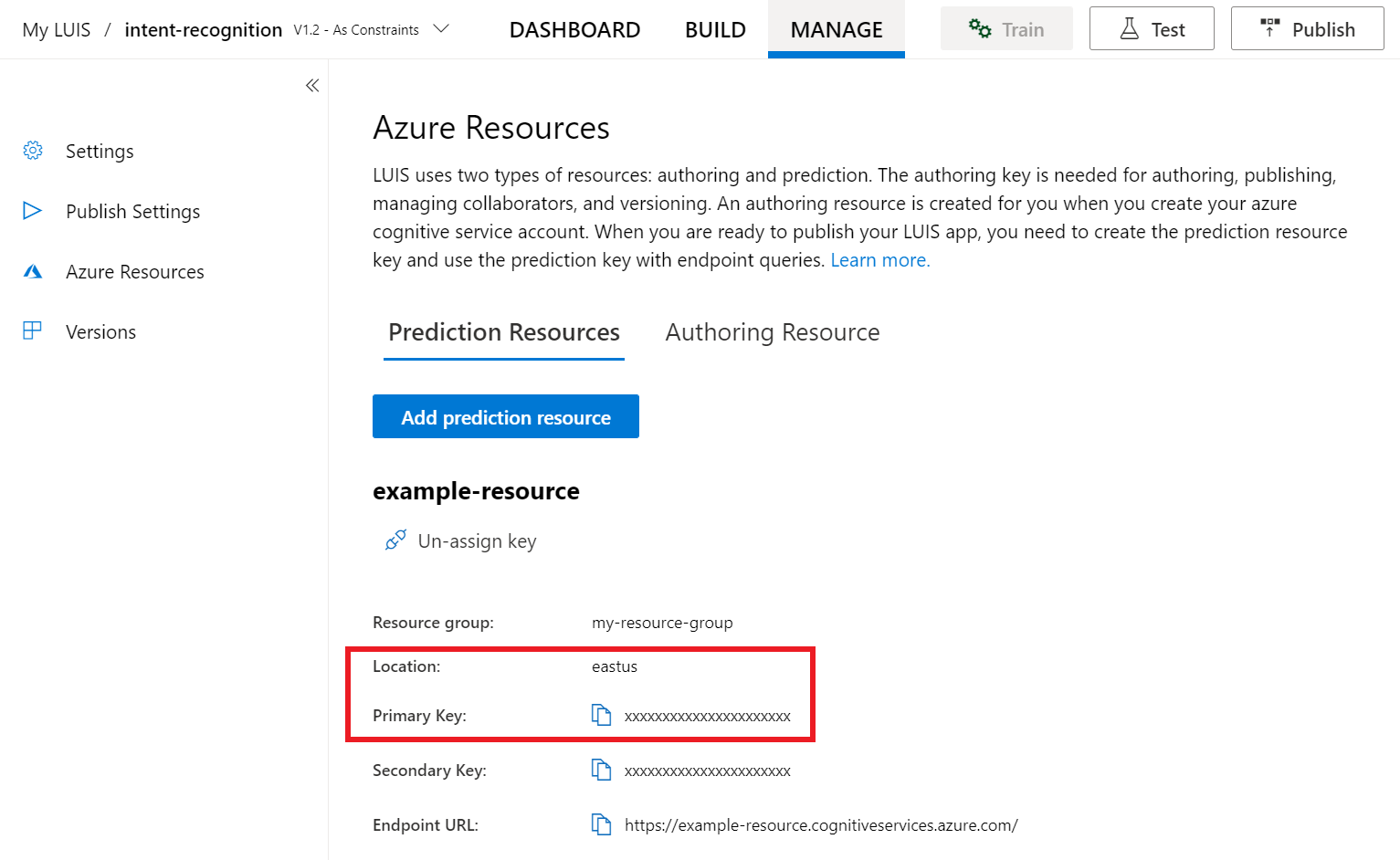
En el portal de vista previa de LUIS, seleccione Administrary, después, seleccione Recursos de Azure. En esta página, encontrará la clave y la ubicación de LUIS (que a veces se denomina región) para su recurso de predicción de LUIS.
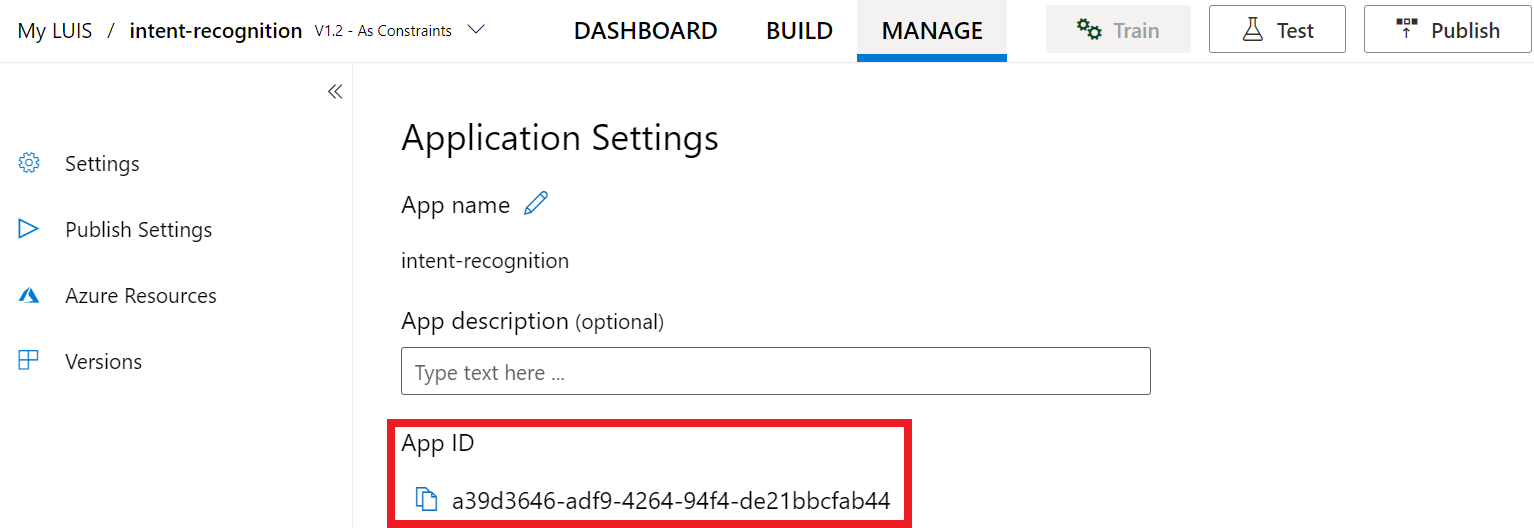
Una vez que tenga la clave y ubicación, necesitará el identificador de la aplicación. Seleccione Configuración. El id. de la aplicación está disponible en esta página.
Abra el proyecto en Visual Studio.
Después abra el proyecto en Visual Studio.
- Inicie Visual Studio 2019.
- Cargue el proyecto y abra
Program.cs.
Inicio con código reutilizable
Vamos a agregar código que funcione como el esqueleto del proyecto. Tenga en cuenta que ha creado un método asincrónico llamado RecognizeIntentAsync().
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
public static async Task RecognizeIntentAsync()
{
}
static async Task Main()
{
await RecognizeIntentAsync();
Console.WriteLine("Please press <Return> to continue.");
Console.ReadLine();
}
}
}
Creación de una configuración de Voz
Para poder inicializar un objeto IntentRecognizer, es preciso crear una configuración que use la clave y ubicación del recurso de predicción de LUIS.
Importante
La clave de inicio y las claves de creación no funcionarán. Debe usar la clave de predicción y la ubicación que creó anteriormente. Para más información, consulte Creación de una aplicación de LUIS para el reconocimiento de la intención.
Inserte este código en el método RecognizeIntentAsync(). Asegúrese de actualizar estos valores:
- Reemplace
"YourLanguageUnderstandingSubscriptionKey"por la clave de predicción de LUIS. - Reemplace
"YourLanguageUnderstandingServiceRegion"por la ubicación de LUIS. Use Identificador de región en Región.
Sugerencia
Si necesita ayuda para encontrar estos valores, consulte Creación de una aplicación de LUIS para el reconocimiento de la intención.
Importante
Recuerde quitar la clave del código cuando haya terminado y no hacerla nunca pública. En el caso de producción, use una forma segura de almacenar sus credenciales y acceder a ellas, como Azure Key Vault. Consulte el artículo Seguridad de servicios de Azure AI para más información.
var config = SpeechConfig.FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
En este ejemplo se usa el método FromSubscription() para compilar la clase SpeechConfig. Para ver una lista completa de los métodos disponibles, consulte Clase SpeechConfig.
El SDK de Voz se usará de forma predeterminada para reconocer el uso de en-us como idioma. Para más información sobre cómo elegir el idioma de origen, vea Procedimiento para reconocer la voz.
Inicialización de IntentRecognizer
Ahora, vamos a crear un objeto IntentRecognizer. Este objeto se crea dentro de una instrucción using para garantizar la versión correcta de los recursos no administrados. Inserte este código en el método RecognizeIntentAsync(), justo debajo de la configuración de Voz.
// Creates an intent recognizer using microphone as audio input.
using (var recognizer = new IntentRecognizer(config))
{
}
Adición de un objeto LanguageUnderstandingModel e intenciones
Debe asociar un objeto LanguageUnderstandingModel con el reconocedor de intenciones y agregar las intenciones que desee que se reconozcan. Vamos a usar las intenciones del dominio precompilado para la automatización doméstica. Inserte este código en la instrucción using de la sección anterior. Asegúrese de reemplazar "YourLanguageUnderstandingAppId" por el identificador de la aplicación de LUIS.
Sugerencia
Si necesita ayuda para encontrar este valor, consulte Creación de una aplicación de LUIS para el reconocimiento de la intención.
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
En este ejemplo se usa la función AddIntent() para agregar intenciones individualmente. Si desea agregar todas las intenciones de un modelo, use AddAllIntents(model) y pase el modelo.
Reconocimiento de una intención
En el objeto IntentRecognizer, va a llamar al método RecognizeOnceAsync(). Este método permite que el servicio Voz sepa que solo va a enviar una frase para el reconocimiento y que, una vez que se identifica la frase, se detendrá el reconocimiento de voz.
Dentro de la instrucción using, agregue este código debajo del modelo.
// Starts recognizing.
Console.WriteLine("Say something...");
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
var result = await recognizer.RecognizeOnceAsync();
Visualización de los resultados (o errores) del reconocimiento
Cuando el servicio Voz devuelva el resultado del reconocimiento, querrá hacer algo con él. Vamos a imprimir el resultado en la consola.
Dentro de la instrucción using, debajo de RecognizeOnceAsync(), agregue este código:
// Checks result.
switch (result.Reason)
{
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id: {result.IntentId}.");
var json = result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
Console.WriteLine($" Language Understanding JSON: {json}.");
break;
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.NoMatch:
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
break;
case ResultReason.Canceled:
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
break;
}
Comprobación del código
En este momento, el código debe tener esta apariencia:
Nota
Se han agregado algunos comentarios a esta versión.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
using System;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Intent;
namespace helloworld
{
class Program
{
public static async Task RecognizeIntentAsync()
{
// </skeleton_1>
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
// The default language is "en-us".
// <create_speech_configuration>
var config = SpeechConfig.FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
// </create_speech_configuration>
// <create_intent_recognizer_1>
// Creates an intent recognizer using microphone as audio input.
using (var recognizer = new IntentRecognizer(config))
{
// </create_intent_recognizer_1>
// <add_intents>
// Creates a Language Understanding model using the app id, and adds specific intents from your model
var model = LanguageUnderstandingModel.FromAppId("YourLanguageUnderstandingAppId");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer.AddAllIntents(model);
// <recognize_intent>
// Starts recognizing.
Console.WriteLine("Say something...");
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
var result = await recognizer.RecognizeOnceAsync();
// </recognize_intent>
// <print_results>
// Checks result.
switch (result.Reason)
{
case ResultReason.RecognizedIntent:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent Id: {result.IntentId}.");
var json = result.Properties.GetProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
Console.WriteLine($" Language Understanding JSON: {json}.");
break;
case ResultReason.RecognizedSpeech:
Console.WriteLine($"RECOGNIZED: Text={result.Text}");
Console.WriteLine($" Intent not recognized.");
break;
case ResultReason.NoMatch:
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
break;
case ResultReason.Canceled:
var cancellation = CancellationDetails.FromResult(result);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
}
break;
}
// </print_results>
// <create_intent_recognizer_2>
}
// </create_intent_recognizer_2>
// <skeleton_2>
}
static async Task Main()
{
await RecognizeIntentAsync();
Console.WriteLine("Please press <Return> to continue.");
Console.ReadLine();
}
}
}
// </skeleton_2>
Compilación y ejecución de la aplicación
Ya está listo para compilar la aplicación y probar el reconocimiento de voz con el servicio Voz.
- Compile el código: en la barra de menús de Visual Studio, elija Compilar>Compilar solución.
- Inicie la aplicación: en la barra de menús, elija Depurar>Iniciar depuración o presione F5.
- Inicie el reconocimiento: se le pedirá que diga una frase en inglés. La voz se envía al servicio Voz, se transcribe como texto y se representa en la consola.
Documentación de referencia | Paquete (NuGet) | Ejemplos adicionales en GitHub
En este inicio rápido, usará el SDK de Voz y el servicio Language Understanding (LUIS) para reconocer los intentos de los datos de audio capturados de un micrófono. En concreto, usará el SDK de Voz para capturar la voz y un dominio predefinido de LUIS para identificar las intenciones de automatización doméstica, como encender y apagar una luz.
Requisitos previos
- Una suscripción a Azure: cree una cuenta gratuita
- Cree un recurso de idioma en Azure Portal. Puede usar el plan de tarifa gratis (
F0) para probar el servicio y actualizarlo más adelante a un plan de pago para producción. Esta vez no necesitará un recurso de voz. - Obtenga la clave de recurso de idioma y la región. Una vez implementado el recurso de Idioma, seleccione Ir al recurso para ver y administrar claves.
Creación de una aplicación de LUIS para el reconocimiento de la intención
Para completar el inicio rápido de reconocimiento de la intención, deberá crear una cuenta de LUIS y un proyecto mediante el portal de la versión preliminar de LUIS. Este inicio rápido requiere una suscripción de LUIS en una región donde el reconocimiento de intenciones esté disponible. No se requiere una suscripción al servicio de voz.
Lo primero que debe hacer es crear una cuenta y una aplicación de LUIS mediante el portal de vista previa de LUIS. La aplicación de LUIS que cree usará un dominio precompilado para la automatización doméstica, que proporciona intenciones, entidades y expresiones de ejemplo. Cuando termine, tendrá un punto de conexión de LUIS que se ejecuta en la nube al que puede llamar mediante el SDK de Voz.
Siga estas instrucciones para crear una aplicación de LUIS:
Cuando haya terminado, necesitará cuatro cosas:
- Volver a publicar con la preparación para la voz activada
- La clave principal de LUIS
- La ubicación de LUIS
- El identificador de la aplicación de LUIS
Aquí es donde puede encontrar esta información en el portal de vista previa de LUIS:
En el portal de la versión preliminar de LUIS, seleccione la aplicación y, a continuación, seleccione el botón Publicar.
Seleccione el espacio de producción; si usa
en-US, seleccione Cambiar configuración y cambie la opción Preparación para la voz a la posición On. A continuación, seleccione el botón Publicar.Importante
Se recomienda encarecidamente la preparación para la voz, ya que mejorará la precisión del reconocimiento de voz.
En el portal de vista previa de LUIS, seleccione Administrary, después, seleccione Recursos de Azure. En esta página, encontrará la clave y la ubicación de LUIS (que a veces se denomina región) para su recurso de predicción de LUIS.
Una vez que tenga la clave y ubicación, necesitará el identificador de la aplicación. Seleccione Configuración. El id. de la aplicación está disponible en esta página.
Abra el proyecto en Visual Studio.
Después abra el proyecto en Visual Studio.
- Inicie Visual Studio 2019.
- Cargue el proyecto y abra
helloworld.cpp.
Inicio con código reutilizable
Vamos a agregar código que funcione como el esqueleto del proyecto. Tenga en cuenta que ha creado un método asincrónico llamado recognizeIntent().
#include "stdafx.h"
#include <iostream>
#include <speechapi_cxx.h>
using namespace std;
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
void recognizeIntent()
{
}
int wmain()
{
try
{
recognizeIntent();
}
catch (exception e)
{
cout << e.what();
}
cout << "Please press a key to continue.\n";
cin.get();
return 0;
}
Creación de una configuración de Voz
Para poder inicializar un objeto IntentRecognizer, es preciso crear una configuración que use la clave y ubicación del recurso de predicción de LUIS.
Importante
La clave de inicio y las claves de creación no funcionarán. Debe usar la clave de predicción y la ubicación que creó anteriormente. Para más información, consulte Creación de una aplicación de LUIS para el reconocimiento de la intención.
Inserte este código en el método recognizeIntent(). Asegúrese de actualizar estos valores:
- Reemplace
"YourLanguageUnderstandingSubscriptionKey"por la clave de predicción de LUIS. - Reemplace
"YourLanguageUnderstandingServiceRegion"por la ubicación de LUIS. Use Identificador de región en Región.
Sugerencia
Si necesita ayuda para encontrar estos valores, consulte Creación de una aplicación de LUIS para el reconocimiento de la intención.
Importante
Recuerde quitar la clave del código cuando haya terminado y no hacerla nunca pública. En el caso de producción, use una forma segura de almacenar sus credenciales y acceder a ellas, como Azure Key Vault. Consulte el artículo Seguridad de servicios de Azure AI para más información.
auto config = SpeechConfig::FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
En este ejemplo se usa el método FromSubscription() para compilar la clase SpeechConfig. Para ver una lista completa de los métodos disponibles, consulte Clase SpeechConfig.
El SDK de Voz se usará de forma predeterminada para reconocer el uso de en-us como idioma. Para más información sobre cómo elegir el idioma de origen, vea Procedimiento para reconocer la voz.
Inicialización de IntentRecognizer
Ahora, vamos a crear un objeto IntentRecognizer. Inserte este código en el método recognizeIntent(), justo debajo de la configuración de Voz.
// Creates an intent recognizer using microphone as audio input.
auto recognizer = IntentRecognizer::FromConfig(config);
Adición de un objeto LanguageUnderstandingModel e intenciones
Debe asociar un objeto LanguageUnderstandingModel con el reconocedor de intenciones y agregar las intenciones que desee que se reconozcan. Vamos a usar las intenciones del dominio precompilado para la automatización doméstica.
Inserte este código debajo de IntentRecognizer. Asegúrese de reemplazar "YourLanguageUnderstandingAppId" por el identificador de la aplicación de LUIS.
Sugerencia
Si necesita ayuda para encontrar este valor, consulte Creación de una aplicación de LUIS para el reconocimiento de la intención.
// Creates a Language Understanding model using the app id, and adds specific intents from your model
auto model = LanguageUnderstandingModel::FromAppId("YourLanguageUnderstandingAppId");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
En este ejemplo se usa la función AddIntent() para agregar intenciones individualmente. Si desea agregar todas las intenciones de un modelo, use AddAllIntents(model) y pase el modelo.
Reconocimiento de una intención
En el objeto IntentRecognizer, va a llamar al método RecognizeOnceAsync(). Este método permite que el servicio Voz sepa que solo va a enviar una frase para el reconocimiento y que, una vez que se identifica la frase, se detendrá el reconocimiento de voz. Por motivos de simplicidad, esperaremos a que se complete la devolución futura.
Inserte este código debajo del modelo:
cout << "Say something...\n";
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
auto result = recognizer->RecognizeOnceAsync().get();
Visualización de los resultados (o errores) del reconocimiento
Cuando el servicio Voz devuelva el resultado del reconocimiento, querrá hacer algo con él. Vamos a hacer algo tan sencillo como imprimir el resultado en la consola.
Inserte este código debajo de auto result = recognizer->RecognizeOnceAsync().get();:
// Checks result.
if (result->Reason == ResultReason::RecognizedIntent)
{
cout << "RECOGNIZED: Text=" << result->Text << std::endl;
cout << " Intent Id: " << result->IntentId << std::endl;
cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl;
}
else if (result->Reason == ResultReason::RecognizedSpeech)
{
cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl;
}
else if (result->Reason == ResultReason::NoMatch)
{
cout << "NOMATCH: Speech could not be recognized." << std::endl;
}
else if (result->Reason == ResultReason::Canceled)
{
auto cancellation = CancellationDetails::FromResult(result);
cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl;
if (cancellation->Reason == CancellationReason::Error)
{
cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl;
cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl;
cout << "CANCELED: Did you update the subscription info?" << std::endl;
}
}
Comprobación del código
En este momento, el código debe tener esta apariencia:
Nota
Se han agregado algunos comentarios a esta versión.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
#include "stdafx.h"
#include <iostream>
#include <speechapi_cxx.h>
using namespace std;
using namespace Microsoft::CognitiveServices::Speech;
using namespace Microsoft::CognitiveServices::Speech::Intent;
void recognizeIntent()
{
// </skeleton_1>
// Creates an instance of a speech config with specified subscription key
// and service region. Note that in contrast to other services supported by
// the Cognitive Services Speech SDK, the Language Understanding service
// requires a specific subscription key from https://www.luis.ai/.
// The Language Understanding service calls the required key 'endpoint key'.
// Once you've obtained it, replace with below with your own Language Understanding subscription key
// and service region (e.g., "westus").
// The default recognition language is "en-us".
// <create_speech_configuration>
auto config = SpeechConfig::FromSubscription(
"YourLanguageUnderstandingSubscriptionKey",
"YourLanguageUnderstandingServiceRegion");
// </create_speech_configuration>
// <create_intent_recognizer>
// Creates an intent recognizer using microphone as audio input.
auto recognizer = IntentRecognizer::FromConfig(config);
// </create_intent_recognizer>
// <add_intents>
// Creates a Language Understanding model using the app id, and adds specific intents from your model
auto model = LanguageUnderstandingModel::FromAppId("YourLanguageUnderstandingAppId");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer->AddIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer->AddAllIntents(model);
// <recognize_intent>
cout << "Say something...\n";
// Starts intent recognition, and returns after a single utterance is recognized. The end of a
// single utterance is determined by listening for silence at the end or until a maximum of about 30
// seconds of audio is processed. The task returns the recognition text as result.
// Note: Since RecognizeOnceAsync() returns only a single utterance, it is suitable only for single
// shot recognition like command or query.
// For long-running multi-utterance recognition, use StartContinuousRecognitionAsync() instead.
auto result = recognizer->RecognizeOnceAsync().get();
// </recognize_intent>
// <print_results>
// Checks result.
if (result->Reason == ResultReason::RecognizedIntent)
{
cout << "RECOGNIZED: Text=" << result->Text << std::endl;
cout << " Intent Id: " << result->IntentId << std::endl;
cout << " Intent Service JSON: " << result->Properties.GetProperty(PropertyId::LanguageUnderstandingServiceResponse_JsonResult) << std::endl;
}
else if (result->Reason == ResultReason::RecognizedSpeech)
{
cout << "RECOGNIZED: Text=" << result->Text << " (intent could not be recognized)" << std::endl;
}
else if (result->Reason == ResultReason::NoMatch)
{
cout << "NOMATCH: Speech could not be recognized." << std::endl;
}
else if (result->Reason == ResultReason::Canceled)
{
auto cancellation = CancellationDetails::FromResult(result);
cout << "CANCELED: Reason=" << (int)cancellation->Reason << std::endl;
if (cancellation->Reason == CancellationReason::Error)
{
cout << "CANCELED: ErrorCode=" << (int)cancellation->ErrorCode << std::endl;
cout << "CANCELED: ErrorDetails=" << cancellation->ErrorDetails << std::endl;
cout << "CANCELED: Did you update the subscription info?" << std::endl;
}
}
// </print_results>
// <skeleton_2>
}
int wmain()
{
try
{
recognizeIntent();
}
catch (exception e)
{
cout << e.what();
}
cout << "Please press a key to continue.\n";
cin.get();
return 0;
}
// </skeleton_2>
Compilación y ejecución de la aplicación
Ya está listo para compilar la aplicación y probar el reconocimiento de voz con el servicio Voz.
- Compile el código: en la barra de menús de Visual Studio, elija Compilar>Compilar solución.
- Inicie la aplicación: en la barra de menús, elija Depurar>Iniciar depuración o presione F5.
- Inicie el reconocimiento: se le pedirá que diga una frase en inglés. La voz se envía al servicio Voz, se transcribe como texto y se representa en la consola.
Documentación de referencia | Ejemplos adicionales en GitHub
En este inicio rápido, usará el SDK de Voz y el servicio Language Understanding (LUIS) para reconocer los intentos de los datos de audio capturados de un micrófono. En concreto, usará el SDK de Voz para capturar la voz y un dominio predefinido de LUIS para identificar las intenciones de automatización doméstica, como encender y apagar una luz.
Requisitos previos
- Una suscripción a Azure: cree una cuenta gratuita
- Cree un recurso de idioma en Azure Portal. Puede usar el plan de tarifa gratis (
F0) para probar el servicio y actualizarlo más adelante a un plan de pago para producción. Esta vez no necesitará un recurso de voz. - Obtenga la clave de recurso de idioma y la región. Una vez implementado el recurso de Idioma, seleccione Ir al recurso para ver y administrar claves.
También debe instalar el SDK de Voz para su entorno de desarrollo y crear un proyecto de ejemplo vacío.
Creación de una aplicación de LUIS para el reconocimiento de la intención
Para completar el inicio rápido de reconocimiento de la intención, deberá crear una cuenta de LUIS y un proyecto mediante el portal de la versión preliminar de LUIS. Este inicio rápido requiere una suscripción de LUIS en una región donde el reconocimiento de intenciones esté disponible. No se requiere una suscripción al servicio de voz.
Lo primero que debe hacer es crear una cuenta y una aplicación de LUIS mediante el portal de vista previa de LUIS. La aplicación de LUIS que cree usará un dominio precompilado para la automatización doméstica, que proporciona intenciones, entidades y expresiones de ejemplo. Cuando termine, tendrá un punto de conexión de LUIS que se ejecuta en la nube al que puede llamar mediante el SDK de Voz.
Siga estas instrucciones para crear una aplicación de LUIS:
Cuando haya terminado, necesitará cuatro cosas:
- Volver a publicar con la preparación para la voz activada
- La clave principal de LUIS
- La ubicación de LUIS
- El identificador de la aplicación de LUIS
Aquí es donde puede encontrar esta información en el portal de vista previa de LUIS:
En el portal de la versión preliminar de LUIS, seleccione la aplicación y, a continuación, seleccione el botón Publicar.
Seleccione el espacio de producción; si usa
en-US, seleccione Cambiar configuración y cambie la opción Preparación para la voz a la posición On. A continuación, seleccione el botón Publicar.Importante
Se recomienda encarecidamente la preparación para la voz, ya que mejorará la precisión del reconocimiento de voz.
En el portal de vista previa de LUIS, seleccione Administrary, después, seleccione Recursos de Azure. En esta página, encontrará la clave y la ubicación de LUIS (que a veces se denomina región) para su recurso de predicción de LUIS.
Una vez que tenga la clave y ubicación, necesitará el identificador de la aplicación. Seleccione Configuración. El id. de la aplicación está disponible en esta página.
Apertura del proyecto
- Abra el entorno de desarrollo integrado que prefiera.
- Cargue el proyecto y abra
Main.java.
Inicio con código reutilizable
Vamos a agregar código que funcione como el esqueleto del proyecto.
package speechsdk.quickstart;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
/**
* Quickstart: recognize speech using the Speech SDK for Java.
*/
public class Main {
/**
* @param args Arguments are ignored in this sample.
*/
public static void main(String[] args) {
} catch (Exception ex) {
System.out.println("Unexpected exception: " + ex.getMessage());
assert(false);
System.exit(1);
}
}
}
Creación de una configuración de Voz
Para poder inicializar un objeto IntentRecognizer, es preciso crear una configuración que use la clave y ubicación del recurso de predicción de LUIS.
Inserte este código en el bloque try/catch en main(). Asegúrese de actualizar estos valores:
- Reemplace
"YourLanguageUnderstandingSubscriptionKey"por la clave de predicción de LUIS. - Reemplace
"YourLanguageUnderstandingServiceRegion"por la ubicación de LUIS. Use Identificador de región en Región.
Sugerencia
Si necesita ayuda para encontrar estos valores, consulte Creación de una aplicación de LUIS para el reconocimiento de la intención.
Importante
Recuerde quitar la clave del código cuando haya terminado y no hacerla nunca pública. En el caso de producción, use una forma segura de almacenar sus credenciales y acceder a ellas, como Azure Key Vault. Consulte el artículo Seguridad de servicios de Azure AI para más información.
// Replace below with with specified subscription key (called 'endpoint key' by the Language Understanding service)
String languageUnderstandingSubscriptionKey = "YourLanguageUnderstandingSubscriptionKey";
// Replace below with your own service region (e.g., "westus").
String languageUnderstandingServiceRegion = "YourLanguageUnderstandingServiceRegion";
// Creates an instance of intent recognizer with a given speech configuration.
// Recognizer is created with the default microphone audio input and default language "en-us".
try (SpeechConfig config = SpeechConfig.fromSubscription(languageUnderstandingSubscriptionKey, languageUnderstandingServiceRegion);
En este ejemplo se usa el método FromSubscription() para compilar la clase SpeechConfig. Para ver una lista completa de los métodos disponibles, consulte Clase SpeechConfig.
El SDK de Voz se usará de forma predeterminada para reconocer el uso de en-us como idioma. Para más información sobre cómo elegir el idioma de origen, vea Procedimiento para reconocer la voz.
Inicialización de IntentRecognizer
Ahora, vamos a crear un objeto IntentRecognizer. Inserte este código justo debajo de la configuración de Voz.
IntentRecognizer recognizer = new IntentRecognizer(config)) {
Adición de un objeto LanguageUnderstandingModel e intenciones
Debe asociar un objeto LanguageUnderstandingModel con el reconocedor de intenciones y agregar las intenciones que desee que se reconozcan. Vamos a usar las intenciones del dominio precompilado para la automatización doméstica.
Inserte este código debajo de IntentRecognizer. Asegúrese de reemplazar "YourLanguageUnderstandingAppId" por el identificador de la aplicación de LUIS.
Sugerencia
Si necesita ayuda para encontrar este valor, consulte Creación de una aplicación de LUIS para el reconocimiento de la intención.
// Creates a language understanding model using the app id, and adds specific intents from your model
LanguageUnderstandingModel model = LanguageUnderstandingModel.fromAppId("YourLanguageUnderstandingAppId");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
En este ejemplo se usa la función addIntent() para agregar intenciones individualmente. Si desea agregar todas las intenciones de un modelo, use addAllIntents(model) y pase el modelo.
Reconocimiento de una intención
En el objeto IntentRecognizer, va a llamar al método recognizeOnceAsync(). Este método permite que el servicio Voz sepa que solo va a enviar una frase para el reconocimiento y que, una vez que se identifica la frase, se detendrá el reconocimiento de voz.
Inserte este código debajo del modelo:
System.out.println("Say something...");
// Starts recognition. It returns when the first utterance has been recognized.
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
Visualización de los resultados (o errores) del reconocimiento
Cuando el servicio Voz devuelva el resultado del reconocimiento, querrá hacer algo con él. Vamos a hacer algo tan sencillo como imprimir el resultado en la consola.
Inserte este código debajo de la llamada a recognizeOnceAsync().
// Checks result.
if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent Id: " + result.getIntentId());
System.out.println(" Intent Service JSON: " + result.getProperties().getProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult));
}
else if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent not recognized.");
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error) {
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
Comprobación del código
En este momento, el código debe tener esta apariencia:
Nota
Se han agregado algunos comentarios a esta versión.
//
// Copyright (c) Microsoft. All rights reserved.
// Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
//
// <skeleton_1>
package speechsdk.quickstart;
import com.microsoft.cognitiveservices.speech.*;
import com.microsoft.cognitiveservices.speech.intent.*;
/**
* Quickstart: recognize speech using the Speech SDK for Java.
*/
public class Main {
/**
* @param args Arguments are ignored in this sample.
*/
public static void main(String[] args) {
// </skeleton_1>
// <create_speech_configuration>
// Replace below with with specified subscription key (called 'endpoint key' by the Language Understanding service)
String languageUnderstandingSubscriptionKey = "YourLanguageUnderstandingSubscriptionKey";
// Replace below with your own service region (e.g., "westus").
String languageUnderstandingServiceRegion = "YourLanguageUnderstandingServiceRegion";
// Creates an instance of intent recognizer with a given speech configuration.
// Recognizer is created with the default microphone audio input and default language "en-us".
try (SpeechConfig config = SpeechConfig.fromSubscription(languageUnderstandingSubscriptionKey, languageUnderstandingServiceRegion);
// </create_speech_configuration>
// <create_intent_recognizer>
IntentRecognizer recognizer = new IntentRecognizer(config)) {
// </create_intent_recognizer>
// <add_intents>
// Creates a language understanding model using the app id, and adds specific intents from your model
LanguageUnderstandingModel model = LanguageUnderstandingModel.fromAppId("YourLanguageUnderstandingAppId");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName1", "id1");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName2", "id2");
recognizer.addIntent(model, "YourLanguageUnderstandingIntentName3", "any-IntentId-here");
// </add_intents>
// To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
// recognizer.addAllIntents(model);
// <recognize_intent>
System.out.println("Say something...");
// Starts recognition. It returns when the first utterance has been recognized.
IntentRecognitionResult result = recognizer.recognizeOnceAsync().get();
// </recognize_intent>
// <print_result>
// Checks result.
if (result.getReason() == ResultReason.RecognizedIntent) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent Id: " + result.getIntentId());
System.out.println(" Intent Service JSON: " + result.getProperties().getProperty(PropertyId.LanguageUnderstandingServiceResponse_JsonResult));
}
else if (result.getReason() == ResultReason.RecognizedSpeech) {
System.out.println("RECOGNIZED: Text=" + result.getText());
System.out.println(" Intent not recognized.");
}
else if (result.getReason() == ResultReason.NoMatch) {
System.out.println("NOMATCH: Speech could not be recognized.");
}
else if (result.getReason() == ResultReason.Canceled) {
CancellationDetails cancellation = CancellationDetails.fromResult(result);
System.out.println("CANCELED: Reason=" + cancellation.getReason());
if (cancellation.getReason() == CancellationReason.Error) {
System.out.println("CANCELED: ErrorCode=" + cancellation.getErrorCode());
System.out.println("CANCELED: ErrorDetails=" + cancellation.getErrorDetails());
System.out.println("CANCELED: Did you update the subscription info?");
}
}
// </print_result>
// <skeleton_2>
} catch (Exception ex) {
System.out.println("Unexpected exception: " + ex.getMessage());
assert(false);
System.exit(1);
}
}
}
// </skeleton_2>
Compilación y ejecución de la aplicación
Presione F11, o seleccione Ejecutar>Depurar. Los próximos 15 segundos de la entrada de voz del micrófono se reconocen y se registran en la ventana de consola.
Documentación de referencia | Paquete (npm) | Ejemplos adicionales en GitHub | Código fuente de la biblioteca
En este inicio rápido, usará el SDK de Voz y el servicio Language Understanding (LUIS) para reconocer los intentos de los datos de audio capturados de un micrófono. En concreto, usará el SDK de Voz para capturar la voz y un dominio predefinido de LUIS para identificar las intenciones de automatización doméstica, como encender y apagar una luz.
Requisitos previos
- Una suscripción a Azure: cree una cuenta gratuita
- Cree un recurso de idioma en Azure Portal. Puede usar el plan de tarifa gratis (
F0) para probar el servicio y actualizarlo más adelante a un plan de pago para producción. Esta vez no necesitará un recurso de voz. - Obtenga la clave de recurso de idioma y la región. Una vez implementado el recurso de Idioma, seleccione Ir al recurso para ver y administrar claves.
También debe instalar el SDK de Voz para su entorno de desarrollo y crear un proyecto de ejemplo vacío.
Creación de una aplicación de LUIS para el reconocimiento de la intención
Para completar el inicio rápido de reconocimiento de la intención, deberá crear una cuenta de LUIS y un proyecto mediante el portal de la versión preliminar de LUIS. Este inicio rápido requiere una suscripción de LUIS en una región donde el reconocimiento de intenciones esté disponible. No se requiere una suscripción al servicio de voz.
Lo primero que debe hacer es crear una cuenta y una aplicación de LUIS mediante el portal de vista previa de LUIS. La aplicación de LUIS que cree usará un dominio precompilado para la automatización doméstica, que proporciona intenciones, entidades y expresiones de ejemplo. Cuando termine, tendrá un punto de conexión de LUIS que se ejecuta en la nube al que puede llamar mediante el SDK de Voz.
Siga estas instrucciones para crear una aplicación de LUIS:
Cuando haya terminado, necesitará cuatro cosas:
- Volver a publicar con la preparación para la voz activada
- La clave principal de LUIS
- La ubicación de LUIS
- El identificador de la aplicación de LUIS
Aquí es donde puede encontrar esta información en el portal de vista previa de LUIS:
En el portal de la versión preliminar de LUIS, seleccione la aplicación y, a continuación, seleccione el botón Publicar.
Seleccione el espacio de producción; si usa
en-US, seleccione Cambiar configuración y cambie la opción Preparación para la voz a la posición On. A continuación, seleccione el botón Publicar.Importante
Se recomienda encarecidamente la preparación para la voz, ya que mejorará la precisión del reconocimiento de voz.
En el portal de vista previa de LUIS, seleccione Administrary, después, seleccione Recursos de Azure. En esta página, encontrará la clave y la ubicación de LUIS (que a veces se denomina región) para su recurso de predicción de LUIS.
Una vez que tenga la clave y ubicación, necesitará el identificador de la aplicación. Seleccione Configuración. El id. de la aplicación está disponible en esta página.
Inicio con código reutilizable
Vamos a agregar código que funcione como el esqueleto del proyecto.
<!DOCTYPE html>
<html>
<head>
<title>Microsoft Azure AI Speech SDK JavaScript Quickstart</title>
<meta charset="utf-8" />
</head>
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
</body>
</html>
Adición de elementos de la interfaz de usuario
Ahora vamos a agregar algunos elementos básicos de la interfaz de usuario, como cuadros de entrada, a hacer referencia a JavaScript del SDK de voz y a capturar un token de autorización si está disponible.
Importante
Recuerde quitar la clave del código cuando haya terminado y no hacerla nunca pública. En el caso de producción, use una forma segura de almacenar sus credenciales y acceder a ellas, como Azure Key Vault. Consulte el artículo Seguridad de servicios de Azure AI para más información.
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
<div id="content" style="display:none">
<table width="100%">
<tr>
<td></td>
<td><h1 style="font-weight:500;">Microsoft Azure AI Speech SDK JavaScript Quickstart</h1></td>
</tr>
<tr>
<td align="right"><a href="https://learn.microsoft.com/azure/ai-services/speech-service/overview" target="_blank">Subscription</a>:</td>
<td><input id="subscriptionKey" type="text" size="40" value="subscription"></td>
</tr>
<tr>
<td align="right">Region</td>
<td><input id="serviceRegion" type="text" size="40" value="YourServiceRegion"></td>
</tr>
<tr>
<td align="right">Application ID:</td>
<td><input id="appId" type="text" size="60" value="YOUR_LANGUAGE_UNDERSTANDING_APP_ID"></td>
</tr>
<tr>
<td></td>
<td><button id="startIntentRecognizeAsyncButton">Start Intent Recognition</button></td>
</tr>
<tr>
<td align="right" valign="top">Input Text</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:200px"></textarea></td>
</tr>
<tr>
<td align="right" valign="top">Result</td>
<td><textarea id="statusDiv" style="display: inline-block;width:500px;height:100px"></textarea></td>
</tr>
</table>
</div>
<script src="microsoft.cognitiveservices.speech.sdk.bundle.js"></script>
<script>
// Note: Replace the URL with a valid endpoint to retrieve
// authorization tokens for your subscription.
var authorizationEndpoint = "token.php";
function RequestAuthorizationToken() {
if (authorizationEndpoint) {
var a = new XMLHttpRequest();
a.open("GET", authorizationEndpoint);
a.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
a.send("");
a.onload = function() {
var token = JSON.parse(atob(this.responseText.split(".")[1]));
serviceRegion.value = token.region;
authorizationToken = this.responseText;
subscriptionKey.disabled = true;
subscriptionKey.value = "using authorization token (hit F5 to refresh)";
console.log("Got an authorization token: " + token);
}
}
}
</script>
<script>
// status fields and start button in UI
var phraseDiv;
var statusDiv;
var startIntentRecognizeAsyncButton;
// subscription key, region, and appId for LUIS services.
var subscriptionKey, serviceRegion, appId;
var authorizationToken;
var SpeechSDK;
var recognizer;
document.addEventListener("DOMContentLoaded", function () {
startIntentRecognizeAsyncButton = document.getElementById("startIntentRecognizeAsyncButton");
subscriptionKey = document.getElementById("subscriptionKey");
serviceRegion = document.getElementById("serviceRegion");
appId = document.getElementById("appId");
phraseDiv = document.getElementById("phraseDiv");
statusDiv = document.getElementById("statusDiv");
startIntentRecognizeAsyncButton.addEventListener("click", function () {
startIntentRecognizeAsyncButton.disabled = true;
phraseDiv.innerHTML = "";
statusDiv.innerHTML = "";
});
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
startIntentRecognizeAsyncButton.disabled = false;
document.getElementById('content').style.display = 'block';
document.getElementById('warning').style.display = 'none';
// in case we have a function for getting an authorization token, call it.
if (typeof RequestAuthorizationToken === "function") {
RequestAuthorizationToken();
}
}
});
</script>
Creación de una configuración de Voz
Antes de inicializar un objeto SpeechRecognizer, debe crear una configuración que use la clave y la región de suscripción. Inserte este código en el método startRecognizeOnceAsyncButton.addEventListener().
Nota
El SDK de Voz se usará de forma predeterminada para reconocer el uso de en-us como idioma. Para más información sobre cómo elegir el idioma de origen, vea Procedimiento para reconocer la voz.
// if we got an authorization token, use the token. Otherwise use the provided subscription key
var speechConfig;
if (authorizationToken) {
speechConfig = SpeechSDK.SpeechConfig.fromAuthorizationToken(authorizationToken, serviceRegion.value);
} else {
if (subscriptionKey.value === "" || subscriptionKey.value === "subscription") {
alert("Please enter your Microsoft Azure AI Speech subscription key!");
return;
}
startIntentRecognizeAsyncButton.disabled = false;
speechConfig = SpeechSDK.SpeechConfig.fromSubscription(subscriptionKey.value, serviceRegion.value);
}
speechConfig.speechRecognitionLanguage = "en-US";
Creación de una configuración de audio
Ahora, debe crear un objeto AudioConfig que apunte al dispositivo de entrada. Inserte este código en el método startIntentRecognizeAsyncButton.addEventListener(), justo debajo de la configuración de Voz.
var audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
Inicialización de IntentRecognizer
Ahora, se creará el objeto IntentRecognizer con los objetos SpeechConfig y AudioConfig creados anteriormente. Inserte este código en el método startIntentRecognizeAsyncButton.addEventListener().
recognizer = new SpeechSDK.IntentRecognizer(speechConfig, audioConfig);
Adición de un objeto LanguageUnderstandingModel e intenciones
Debe asociar un objeto LanguageUnderstandingModel con el reconocedor de intenciones y agregar las intenciones que desee que se reconozcan. Vamos a usar las intenciones del dominio precompilado para la automatización doméstica.
Inserte este código debajo de IntentRecognizer. Asegúrese de reemplazar "YourLanguageUnderstandingAppId" por el identificador de la aplicación de LUIS.
if (appId.value !== "" && appId.value !== "YOUR_LANGUAGE_UNDERSTANDING_APP_ID") {
var lm = SpeechSDK.LanguageUnderstandingModel.fromAppId(appId.value);
recognizer.addAllIntents(lm);
}
Nota
El SDK de Voz solo admite puntos de conexión de LUIS v2.0. Debe modificar manualmente la dirección URL del punto de conexión v3.0 que se encuentra en el campo de consulta de ejemplo para usar un patrón de dirección URL v2.0. Los puntos de conexión de LUIS v2.0 siempre siguen uno de estos dos patrones:
https://{AzureResourceName}.cognitiveservices.azure.com/luis/v2.0/apps/{app-id}?subscription-key={subkey}&verbose=true&q=https://{Region}.api.cognitive.microsoft.com/luis/v2.0/apps/{app-id}?subscription-key={subkey}&verbose=true&q=
Reconocimiento de una intención
En el objeto IntentRecognizer, va a llamar al método recognizeOnceAsync(). Este método permite que el servicio Voz sepa que solo va a enviar una frase para el reconocimiento y que, una vez que se identifica la frase, se detendrá el reconocimiento de voz.
Inserte este código debajo de la adición del modelo:
recognizer.recognizeOnceAsync(
function (result) {
window.console.log(result);
phraseDiv.innerHTML = result.text + "\r\n";
statusDiv.innerHTML += "(continuation) Reason: " + SpeechSDK.ResultReason[result.reason];
switch (result.reason) {
case SpeechSDK.ResultReason.RecognizedSpeech:
statusDiv.innerHTML += " Text: " + result.text;
break;
case SpeechSDK.ResultReason.RecognizedIntent:
statusDiv.innerHTML += " Text: " + result.text + " IntentId: " + result.intentId;
// The actual JSON returned from Language Understanding is a bit more complex to get to, but it is available for things like
// the entity name and type if part of the intent.
statusDiv.innerHTML += " Intent JSON: " + result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
phraseDiv.innerHTML += result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult) + "\r\n";
break;
case SpeechSDK.ResultReason.NoMatch:
var noMatchDetail = SpeechSDK.NoMatchDetails.fromResult(result);
statusDiv.innerHTML += " NoMatchReason: " + SpeechSDK.NoMatchReason[noMatchDetail.reason];
break;
case SpeechSDK.ResultReason.Canceled:
var cancelDetails = SpeechSDK.CancellationDetails.fromResult(result);
statusDiv.innerHTML += " CancellationReason: " + SpeechSDK.CancellationReason[cancelDetails.reason];
if (cancelDetails.reason === SpeechSDK.CancellationReason.Error) {
statusDiv.innerHTML += ": " + cancelDetails.errorDetails;
}
break;
}
statusDiv.innerHTML += "\r\n";
startIntentRecognizeAsyncButton.disabled = false;
},
function (err) {
window.console.log(err);
phraseDiv.innerHTML += "ERROR: " + err;
startIntentRecognizeAsyncButton.disabled = false;
});
Comprobación del código
<!DOCTYPE html>
<html>
<head>
<title>Microsoft Cognitive Services Speech SDK JavaScript Quickstart</title>
<meta charset="utf-8" />
</head>
<body style="font-family:'Helvetica Neue',Helvetica,Arial,sans-serif; font-size:13px;">
<div id="warning">
<h1 style="font-weight:500;">Speech Recognition Speech SDK not found (microsoft.cognitiveservices.speech.sdk.bundle.js missing).</h1>
</div>
<div id="content" style="display:none">
<table width="100%">
<tr>
<td></td>
<td><h1 style="font-weight:500;">Microsoft Cognitive Services Speech SDK JavaScript Quickstart</h1></td>
</tr>
<tr>
<td align="right"><a href="https://docs.microsoft.com/azure/cognitive-services/speech-service/quickstarts/intent-recognition?pivots=programming-language-csharp#create-a-luis-app-for-intent-recognition" target="_blank">LUIS Primary Key</a>:</td>
<td><input id="subscriptionKey" type="text" size="40" value="subscription"></td>
</tr>
<tr>
<td align="right">LUIS Location</td>
<td><input id="serviceRegion" type="text" size="40" value="YourServiceRegion"></td>
</tr>
<tr>
<td align="right">LUIS App ID:</td>
<td><input id="appId" type="text" size="60" value="YOUR_LANGUAGE_UNDERSTANDING_APP_ID"></td>
</tr>
<tr>
<td></td>
<td><button id="startIntentRecognizeAsyncButton">Start Intent Recognition</button></td>
</tr>
<tr>
<td align="right" valign="top">Input Text</td>
<td><textarea id="phraseDiv" style="display: inline-block;width:500px;height:200px"></textarea></td>
</tr>
<tr>
<td align="right" valign="top">Result</td>
<td><textarea id="statusDiv" style="display: inline-block;width:500px;height:100px"></textarea></td>
</tr>
</table>
</div>
<!-- Speech SDK reference sdk. -->
<script src="https://aka.ms/csspeech/jsbrowserpackageraw"></script>
<!-- Speech SDK USAGE -->
<script>
// status fields and start button in UI
var phraseDiv;
var statusDiv;
var startIntentRecognizeAsyncButton;
// subscription key and region for speech services.
var subscriptionKey, serviceRegion, appId;
var SpeechSDK;
var recognizer;
document.addEventListener("DOMContentLoaded", function () {
startIntentRecognizeAsyncButton = document.getElementById("startIntentRecognizeAsyncButton");
subscriptionKey = document.getElementById("subscriptionKey");
serviceRegion = document.getElementById("serviceRegion");
appId = document.getElementById("appId");
phraseDiv = document.getElementById("phraseDiv");
statusDiv = document.getElementById("statusDiv");
startIntentRecognizeAsyncButton.addEventListener("click", function () {
startIntentRecognizeAsyncButton.disabled = true;
phraseDiv.innerHTML = "";
statusDiv.innerHTML = "";
let audioConfig = SpeechSDK.AudioConfig.fromDefaultMicrophoneInput();
if (subscriptionKey.value === "" || subscriptionKey.value === "subscription") {
alert("Please enter your Microsoft Cognitive Services Speech subscription key!");
startIntentRecognizeAsyncButton.disabled = false;
return;
}
var speechConfig = SpeechSDK.SpeechConfig.fromSubscription(subscriptionKey.value, serviceRegion.value);
speechConfig.speechRecognitionLanguage = "en-US";
recognizer = new SpeechSDK.IntentRecognizer(speechConfig, audioConfig);
// Set up a Language Understanding Model from Language Understanding Intelligent Service (LUIS).
// See https://www.luis.ai/home for more information on LUIS.
if (appId.value !== "" && appId.value !== "YOUR_LANGUAGE_UNDERSTANDING_APP_ID") {
var lm = SpeechSDK.LanguageUnderstandingModel.fromAppId(appId.value);
recognizer.addAllIntents(lm);
}
recognizer.recognizeOnceAsync(
function (result) {
window.console.log(result);
phraseDiv.innerHTML = result.text + "\r\n";
statusDiv.innerHTML += "(continuation) Reason: " + SpeechSDK.ResultReason[result.reason];
switch (result.reason) {
case SpeechSDK.ResultReason.RecognizedSpeech:
statusDiv.innerHTML += " Text: " + result.text;
break;
case SpeechSDK.ResultReason.RecognizedIntent:
statusDiv.innerHTML += " Text: " + result.text + " IntentId: " + result.intentId;
// The actual JSON returned from Language Understanding is a bit more complex to get to, but it is available for things like
// the entity name and type if part of the intent.
statusDiv.innerHTML += " Intent JSON: " + result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult);
phraseDiv.innerHTML += result.properties.getProperty(SpeechSDK.PropertyId.LanguageUnderstandingServiceResponse_JsonResult) + "\r\n";
break;
case SpeechSDK.ResultReason.NoMatch:
var noMatchDetail = SpeechSDK.NoMatchDetails.fromResult(result);
statusDiv.innerHTML += " NoMatchReason: " + SpeechSDK.NoMatchReason[noMatchDetail.reason];
break;
case SpeechSDK.ResultReason.Canceled:
var cancelDetails = SpeechSDK.CancellationDetails.fromResult(result);
statusDiv.innerHTML += " CancellationReason: " + SpeechSDK.CancellationReason[cancelDetails.reason];
if (cancelDetails.reason === SpeechSDK.CancellationReason.Error) {
statusDiv.innerHTML += ": " + cancelDetails.errorDetails;
}
break;
}
statusDiv.innerHTML += "\r\n";
startIntentRecognizeAsyncButton.disabled = false;
},
function (err) {
window.console.log(err);
phraseDiv.innerHTML += "ERROR: " + err;
startIntentRecognizeAsyncButton.disabled = false;
});
});
if (!!window.SpeechSDK) {
SpeechSDK = window.SpeechSDK;
startIntentRecognizeAsyncButton.disabled = false;
document.getElementById('content').style.display = 'block';
document.getElementById('warning').style.display = 'none';
}
});
</script>
</body>
</html>
Creación del origen del token (opcional)
En caso de que desea hospedar la página web en un servidor web, opcionalmente puede proporcionar un origen del token para la aplicación de demostración. De esa forma, la clave de la suscripción nunca saldrá el servidor, lo que permitirá a los usuarios utilizar las funcionalidades de voz sin escribir ningún código de autorización.
Cree un nuevo archivo llamado token.php. En este ejemplo se supone que el servidor web admite el lenguaje de scripting PHP con cURL habilitado. Escriba el siguiente código:
<?php
header('Access-Control-Allow-Origin: ' . $_SERVER['SERVER_NAME']);
// Replace with your own subscription key and service region (e.g., "westus").
$subscriptionKey = 'YourSubscriptionKey';
$region = 'YourServiceRegion';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'https://' . $region . '.api.cognitive.microsoft.com/sts/v1.0/issueToken');
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, '{}');
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type: application/json', 'Ocp-Apim-Subscription-Key: ' . $subscriptionKey));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
echo curl_exec($ch);
?>
Nota
Los tokens de autorización tienen una vigencia limitada. Este ejemplo simplificado no muestra cómo actualizar automáticamente tokens de autorización. Como usuario, puede volver a cargar la página manualmente o presione la tecla F5 para actualizarla.
Compilación y ejecución local del ejemplo
Para iniciar la aplicación, haga doble clic en el archivo index.html o ábralo con el explorador web que prefiera. Presenta una sencilla GUI que le permite escribir la clave, región y el identificador de aplicación de LUIS. Una vez que se han especificado esos campos, puede hacer clic en el botón adecuado para desencadenar un reconocimiento mediante el micrófono.
Nota
Este método no funciona en el explorador Safari. En Safari, la página web de ejemplo debe estar hospedada en un servidor web; Safari no permite la carga de sitios web desde un archivo local para usar el micrófono.
Compilación y ejecución del ejemplo mediante un servidor web
Para iniciar la aplicación, abra el explorador web que prefiera y apunte a la dirección URL pública en la que hospeda la carpeta, escriba la región y el identificador de aplicación de LUIS, y desencadene un reconocimiento mediante el micrófono. Si lo ha configurado, adquirirá un token del origen del token y comenzará a reconocer comandos orales.
Documentación de referencia | Paquete (PyPi) | Ejemplos adicionales en GitHub
En este inicio rápido, usará el SDK de Voz y el servicio Language Understanding (LUIS) para reconocer los intentos de los datos de audio capturados de un micrófono. En concreto, usará el SDK de Voz para capturar la voz y un dominio predefinido de LUIS para identificar las intenciones de automatización doméstica, como encender y apagar una luz.
Requisitos previos
- Una suscripción a Azure: cree una cuenta gratuita
- Cree un recurso de idioma en Azure Portal. Puede usar el plan de tarifa gratis (
F0) para probar el servicio y actualizarlo más adelante a un plan de pago para producción. Esta vez no necesitará un recurso de voz. - Obtenga la clave de recurso de idioma y la región. Una vez implementado el recurso de Idioma, seleccione Ir al recurso para ver y administrar claves.
También debe instalar el SDK de Voz para su entorno de desarrollo y crear un proyecto de ejemplo vacío.
Creación de una aplicación de LUIS para el reconocimiento de la intención
Para completar el inicio rápido de reconocimiento de la intención, deberá crear una cuenta de LUIS y un proyecto mediante el portal de la versión preliminar de LUIS. Este inicio rápido requiere una suscripción de LUIS en una región donde el reconocimiento de intenciones esté disponible. No se requiere una suscripción al servicio de voz.
Lo primero que debe hacer es crear una cuenta y una aplicación de LUIS mediante el portal de vista previa de LUIS. La aplicación de LUIS que cree usará un dominio precompilado para la automatización doméstica, que proporciona intenciones, entidades y expresiones de ejemplo. Cuando termine, tendrá un punto de conexión de LUIS que se ejecuta en la nube al que puede llamar mediante el SDK de Voz.
Siga estas instrucciones para crear una aplicación de LUIS:
Cuando haya terminado, necesitará cuatro cosas:
- Volver a publicar con la preparación para la voz activada
- La clave principal de LUIS
- La ubicación de LUIS
- El identificador de la aplicación de LUIS
Aquí es donde puede encontrar esta información en el portal de vista previa de LUIS:
En el portal de la versión preliminar de LUIS, seleccione la aplicación y, a continuación, seleccione el botón Publicar.
Seleccione el espacio de producción; si usa
en-US, seleccione Cambiar configuración y cambie la opción Preparación para la voz a la posición On. A continuación, seleccione el botón Publicar.Importante
Se recomienda encarecidamente la preparación para la voz, ya que mejorará la precisión del reconocimiento de voz.
En el portal de vista previa de LUIS, seleccione Administrary, después, seleccione Recursos de Azure. En esta página, encontrará la clave y la ubicación de LUIS (que a veces se denomina región) para su recurso de predicción de LUIS.
Una vez que tenga la clave y ubicación, necesitará el identificador de la aplicación. Seleccione Configuración. El id. de la aplicación está disponible en esta página.
Apertura del proyecto
- Abra el entorno de desarrollo integrado que prefiera.
- Cree un proyecto y un archivo llamado
quickstart.pyy, a continuación, ábralo.
Inicio con código reutilizable
Vamos a agregar código que funcione como el esqueleto del proyecto.
import azure.cognitiveservices.speech as speechsdk
print("Say something...")
Creación de una configuración de Voz
Para poder inicializar un objeto IntentRecognizer, es preciso crear una configuración que use la clave y ubicación del recurso de predicción de LUIS.
Inserte este código en quickstart.py. Asegúrese de actualizar estos valores:
- Reemplace
"YourLanguageUnderstandingSubscriptionKey"por la clave de predicción de LUIS. - Reemplace
"YourLanguageUnderstandingServiceRegion"por la ubicación de LUIS. Use Identificador de región en Región.
Sugerencia
Si necesita ayuda para encontrar estos valores, consulte Creación de una aplicación de LUIS para el reconocimiento de la intención.
Importante
Recuerde quitar la clave del código cuando haya terminado y no hacerla nunca pública. En el caso de producción, use una forma segura de almacenar sus credenciales y acceder a ellas, como Azure Key Vault. Consulte el artículo Seguridad de servicios de Azure AI para más información.
# Set up the config for the intent recognizer (remember that this uses the Language Understanding key, not the Speech Services key)!
intent_config = speechsdk.SpeechConfig(
subscription="YourLanguageUnderstandingSubscriptionKey",
region="YourLanguageUnderstandingServiceRegion")
En este ejemplo se crea el objeto SpeechConfig mediante la clave y la región de LUIS. Para ver una lista completa de los métodos disponibles, consulte Clase SpeechConfig.
El SDK de Voz se usará de forma predeterminada para reconocer el uso de en-us como idioma. Para más información sobre cómo elegir el idioma de origen, vea Procedimiento para reconocer la voz.
Inicialización de IntentRecognizer
Ahora, vamos a crear un objeto IntentRecognizer. Inserte este código justo debajo de la configuración de Voz.
# Set up the intent recognizer
intent_recognizer = speechsdk.intent.IntentRecognizer(speech_config=intent_config)
Adición de un objeto LanguageUnderstandingModel e intenciones
Debe asociar un objeto LanguageUnderstandingModel con el reconocedor de intenciones y agregar las intenciones que desee que se reconozcan. Vamos a usar las intenciones del dominio precompilado para la automatización doméstica.
Inserte este código debajo de IntentRecognizer. Asegúrese de reemplazar "YourLanguageUnderstandingAppId" por el identificador de la aplicación de LUIS.
Sugerencia
Si necesita ayuda para encontrar este valor, consulte Creación de una aplicación de LUIS para el reconocimiento de la intención.
# set up the intents that are to be recognized. These can be a mix of simple phrases and
# intents specified through a LanguageUnderstanding Model.
model = speechsdk.intent.LanguageUnderstandingModel(app_id="YourLanguageUnderstandingAppId")
intents = [
(model, "HomeAutomation.TurnOn"),
(model, "HomeAutomation.TurnOff"),
("This is a test.", "test"),
("Switch to channel 34.", "34"),
("what's the weather like", "weather"),
]
intent_recognizer.add_intents(intents)
En este ejemplo se usa la función add_intents() para agregar una lista de intenciones definidas explícitamente. Si desea agregar todas las intenciones de un modelo, use add_all_intents(model) y pase el modelo.
Reconocimiento de una intención
En el objeto IntentRecognizer, va a llamar al método recognize_once(). Este método permite que el servicio Voz sepa que solo va a enviar una frase para el reconocimiento y que, una vez que se identifica la frase, se detendrá el reconocimiento de voz.
Inserte este código debajo del modelo.
intent_result = intent_recognizer.recognize_once()
Visualización de los resultados (o errores) del reconocimiento
Cuando el servicio Voz devuelva el resultado del reconocimiento, querrá hacer algo con él. Vamos a hacer algo tan sencillo como imprimir el resultado en la consola.
Debajo de la llamada a recognize_once(), agregue este código.
# Check the results
if intent_result.reason == speechsdk.ResultReason.RecognizedIntent:
print("Recognized: \"{}\" with intent id `{}`".format(intent_result.text, intent_result.intent_id))
elif intent_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(intent_result.text))
elif intent_result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(intent_result.no_match_details))
elif intent_result.reason == speechsdk.ResultReason.Canceled:
print("Intent recognition canceled: {}".format(intent_result.cancellation_details.reason))
if intent_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(intent_result.cancellation_details.error_details))
Comprobación del código
En este momento, el código debe tener esta apariencia.
Nota
Se han agregado algunos comentarios a esta versión.
# Copyright (c) Microsoft. All rights reserved.
# Licensed under the MIT license. See LICENSE.md file in the project root for full license information.
# <skeleton>
import azure.cognitiveservices.speech as speechsdk
print("Say something...")
# </skeleton>
"""performs one-shot intent recognition from input from the default microphone"""
# <create_speech_configuration>
# Set up the config for the intent recognizer (remember that this uses the Language Understanding key, not the Speech Services key)!
intent_config = speechsdk.SpeechConfig(
subscription="YourLanguageUnderstandingSubscriptionKey",
region="YourLanguageUnderstandingServiceRegion")
# </create_speech_configuration>
# <create_intent_recognizer>
# Set up the intent recognizer
intent_recognizer = speechsdk.intent.IntentRecognizer(speech_config=intent_config)
# </create_intent_recognizer>
# <add_intents>
# set up the intents that are to be recognized. These can be a mix of simple phrases and
# intents specified through a LanguageUnderstanding Model.
model = speechsdk.intent.LanguageUnderstandingModel(app_id="YourLanguageUnderstandingAppId")
intents = [
(model, "HomeAutomation.TurnOn"),
(model, "HomeAutomation.TurnOff"),
("This is a test.", "test"),
("Switch to channel 34.", "34"),
("what's the weather like", "weather"),
]
intent_recognizer.add_intents(intents)
# </add_intents>
# To add all of the possible intents from a LUIS model to the recognizer, uncomment the line below:
# intent_recognizer.add_all_intents(model)
# Starts intent recognition, and returns after a single utterance is recognized. The end of a
# single utterance is determined by listening for silence at the end or until a maximum of about 30
# seconds of audio is processed. It returns the recognition text as result.
# Note: Since recognize_once() returns only a single utterance, it is suitable only for single
# shot recognition like command or query.
# For long-running multi-utterance recognition, use start_continuous_recognition() instead.
# <recognize_intent>
intent_result = intent_recognizer.recognize_once()
# </recognize_intent>
# <print_results>
# Check the results
if intent_result.reason == speechsdk.ResultReason.RecognizedIntent:
print("Recognized: \"{}\" with intent id `{}`".format(intent_result.text, intent_result.intent_id))
elif intent_result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("Recognized: {}".format(intent_result.text))
elif intent_result.reason == speechsdk.ResultReason.NoMatch:
print("No speech could be recognized: {}".format(intent_result.no_match_details))
elif intent_result.reason == speechsdk.ResultReason.Canceled:
print("Intent recognition canceled: {}".format(intent_result.cancellation_details.reason))
if intent_result.cancellation_details.reason == speechsdk.CancellationReason.Error:
print("Error details: {}".format(intent_result.cancellation_details.error_details))
# </print_results>
Compilación y ejecución de la aplicación
Ejecute el ejemplo desde la consola o en el IDE:
python quickstart.py
Los próximos 15 segundos de la entrada de voz del micrófono se reconocen y se registran en la ventana de consola.
Documentación de referencia | Paquete (Go) | Ejemplos adicionales en GitHub
El SDK de Voz para Go no admite el reconocimiento de intenciones. Seleccione otro lenguaje de programación o la referencia de Go y los ejemplos vinculados desde el principio de este artículo.
Documentación de referencia | Paquete (descarga) | Ejemplos adicionales en GitHub
El SDK de Voz para Objective-C admite el reconocimiento de intenciones, aunque no tenemos ninguna guía disponible aún. Seleccione otro lenguaje de programación para empezar a trabajar y conocer los conceptos, o consulte la referencia de Objective-C y los ejemplos vinculados desde el principio de este artículo.
Documentación de referencia | Paquete (descarga) | Ejemplos adicionales en GitHub
El SDK de Voz para Swift admite el reconocimiento de intenciones, aunque no tenemos ninguna guía disponible aún. Seleccione otro lenguaje de programación para empezar a trabajar y conocer los conceptos, o consulte la referencia de Swift y los ejemplos vinculados desde el principio de este artículo.
Referencia de la API de REST de conversión de voz en texto | Referencia de la API de REST de conversión de voz en texto para audios de corta duración | Ejemplos adicionales sobre GitHub
Puede usar la API de REST para el reconocimiento de intenciones, aunque no tenemos ninguna guía disponible aún. Seleccione otro lenguaje de programación para empezar a trabajar y conocer los conceptos.
La interfaz de la línea de comandos de Voz (CLI) admite el reconocimiento de intenciones, aunque no tenemos ninguna guía disponible aún. Seleccione otro lenguaje de programación para empezar a trabajar y conocer los conceptos, o consulte Información general de la CLI de Voz para obtener más información sobre la CLI.