Explicación de la visualización y agregación de métricas de Azure Monitor
En este artículo se explica la agregación de métricas en la base de datos de series temporales que respalda las métricas personalizadas y las métricas de la plataforma Azure Monitor. El artículo también se aplica a las métricas estándar de Application Insights.
Esta información de este artículo es compleja y se proporciona para aquellos que desean profundizar más en el sistema de métricas. No es necesario comprenderlo para usar las métricas de Azure Monitor de forma eficaz.
Información general y términos
Al agregar una métrica a un gráfico, el Explorador de métricas preselecciona automáticamente la agregación predeterminada. El valor predeterminado tiene sentido en escenarios básicos, pero puede usar agregaciones diferentes para obtener más información sobre la métrica. Para ver diferentes agregaciones en un gráfico, es necesario comprender cómo las administra el Explorador de métricas.
Primero, vamos a definir claramente algunos términos:
- Valor de métrica: valor de medida único que se recopila para un recurso específico.
- Base de datos de serie temporal: Una base de datos optimizada para el almacenamiento y la recuperación de puntos de datos, donde todos contienen un valor y una marca de tiempo correspondiente.
- Período de tiempo: período de tiempo genérico.
- Intervalo de tiempo: período de tiempo entre la recopilación de dos valores de métrica.
- Intervalo de tiempo: período de tiempo que se muestra en un gráfico. El valor predeterminado típico es 24 horas. Solo están disponibles intervalos específicos.
- Granularidad de tiempo o intervalo de agregación: período de tiempo que se usa para agregar valores juntos para permitir la presentación en un gráfico. Solo están disponibles intervalos específicos. El mínimo actual es 1 minuto. El valor de granularidad de tiempo debe ser menor que el intervalo de tiempo seleccionado para que sea útil. De lo contrario, solo se muestra un valor para todo el gráfico.
- Tipo de agregación: tipo de estadística calculada a partir de varios valores de métrica.
- Agregado: proceso de tomar varios valores de entrada y usarlos después para generar un valor de salida único a través de las reglas definidas por el tipo de agregación. Por ejemplo, tomar un promedio de varios valores.
Resumen del proceso
Las métricas son una serie de valores almacenados con una marca de tiempo. En Azure, la mayoría de las métricas se almacenan en la base de datos de la serie temporal de Métricas de Azure. Al trazar un gráfico, los valores de las métricas seleccionadas se recuperan de la base de datos y, a continuación, se agregan por separado en función de la granularidad de tiempo elegida (también conocida como intervalo de agregación). Puede seleccionar el tamaño de la granularidad de tiempo mediante el selector de tiempo del explorador de métricas. Si no realiza una selección explícita, la granularidad de tiempo se selecciona automáticamente en función del intervalo de tiempo seleccionado actualmente. Una vez se haya seleccionado, los valores de métricas que se capturaron durante cada intervalo de granularidad de tiempo se agregan y se colocan en el gráfico: un punto de datos por cada intervalo.
Tipos de agregación
Hay cinco tipos de agregaciones básicas disponibles en el Explorador de métricas. El Explorador de métricas oculta las agregaciones que no son pertinentes y no se pueden usar para una métrica determinada.
- Suma: suma de todos los valores capturados en el intervalo de agregación. A veces se conoce como agregación total.
- Recuento: número de medidas capturadas en el intervalo de agregación. El recuento considera el valor de la medida, solo el número de registros.
- Media: media de los valores de la métrica capturados en el intervalo de agregación. Para la mayoría de las métricas, este valor es la suma o el recuento.
- Min: el menor valor capturado en el intervalo de agregación.
- Max: el mayor valor capturado en el intervalo de agregación.
Por ejemplo, supongamos que un gráfico muestra la métrica de salida de red total para una máquina virtual con la agregación SUM en el último intervalo de tiempo de 24 horas. El intervalo de tiempo y la granularidad se pueden cambiar desde la parte superior derecha del gráfico, tal como se puede observar en la siguiente captura de pantalla.

En el caso de una granularidad de tiempo de 30 minutos y un intervalo de tiempo de 24 horas:
- El gráfico se dibuja a partir de 48 puntos de datos. Es decir, puntos de datos agregados de 1 minuto de 24 horas x 2 puntos de datos por hora (60 min/30 min).
- El gráfico de líneas conecta 48 puntos en el área de trazado del gráfico.
- Cada punto de datos representa la suma de todos los bytes de salida de red enviados durante cada uno de los períodos de tiempo de 30 minutos correspondientes.

Haga clic en las imágenes de esta sección para ver las versiones más grandes.
Si cambia la granularidad de tiempo a 15 minutos, el gráfico se elabora a partir de 96 puntos de datos agregados. Es decir, 60 min/15 min = 4 puntos de datos por hora x 24 horas.

En el caso de una granularidad de tiempo de 5 minutos, obtendrá 24 x (60/5) = 288 puntos.
En el caso de una granularidad de tiempo de 1 minuto (la menor posible en el gráfico), obtendrá 24 x 60/1 = 1440 puntos.

Los gráficos son diferentes para estas sumas, tal como se muestra en las capturas de pantallas anteriores. Observe que esta máquina virtual tiene numerosas salidas de resultados en un período de tiempo pequeño en relación con el resto de la ventana de tiempo.
La granularidad de tiempo permite ajustar la relación de "señal a ruido" en un gráfico. Las agregaciones superiores quitan el ruido y suavizan los picos. Observe las variaciones en el gráfico de 1 minuto inferior y cómo se suavizan a medida que los valores de granularidad son más altos.
Este comportamiento de suavizado es importante cuando se envían estos datos a otros sistemas, por ejemplo, alertas. Normalmente, no quiere recibir alertas sobre picos breves de un tiempo de CPU superior al 90 %. Sin embargo, si la CPU permanece en el 90 % durante 5 minutos, es probable que sea importante. Si configura una regla de alertas en la CPU (o en cualquier métrica), una granularidad de tiempo mayor puede reducir el número de alertas falsas que recibe.
Es importante establecer lo que es "normal" para que la carga de trabajo sepa qué intervalo de tiempo es el mejor. Esta es una de las ventajas de las alertas dinámicas, que es un tema diferente que no se trata aquí.
Recopilación de las métricas por parte del sistema
La recopilación de datos varía según la métrica.
Nota:
Los siguientes ejemplos se simplifican para ilustrar y los datos de métricas reales incluidos en cada agregación se ven afectados por los datos disponibles cuando se produce la evaluación.
Frecuencia de recopilación de medidas
Existen dos tipos de períodos de recopilación.
Regular: la métrica se recopila en un intervalo de tiempo coherente que no varía.
Basada en la actividad: la métrica se recopila en función del momento en que se produce una transacción de un tipo determinado. Cada transacción tiene una entrada de métrica y una marca de tiempo. No se recopilan en intervalos regulares, por lo que hay un número variable de registros durante un período de tiempo determinado.
Granularidad
La granularidad mínima es de 1 minuto, pero el sistema subyacente puede capturar los datos más rápido en función de la métrica. Por ejemplo, el porcentaje de CPU de una máquina virtual de Azure se captura en un intervalo de tiempo de 15 segundos. Dado que se realiza un seguimiento de los errores HTTP como transacciones, muchos pueden superar fácilmente más de un minuto. Otras métricas, como el almacenamiento de SQL, se capturan cada 20 minutos. Esta opción depende del proveedor y el tipo de recursos individuales. La mayoría intenta proporcionar el intervalo más pequeño posible.
Dimensiones, división y filtrado
Las métricas se capturan para cada recurso individual. Sin embargo, el nivel en el que las métricas se recopilan, se almacenan y se pueden representar mediante gráficos puede variar. Este nivel se representa mediante otras métricas disponibles en las dimensiones de las métricas. Cada proveedor de recursos individual define el grado de detalle de los datos que recopila. Azure Monitor solo define cómo se deben presentar y almacenar estos detalles.
Al representar una métrica mediante gráficos en el explorador de métricas, tiene la opción de "dividir" el gráfico por una dimensión. La división de un gráfico significa que está examinando los datos subyacentes para obtener más detalles y ver que los datos se han filtrado o representado mediante gráficos en el explorador de métricas.
Por ejemplo, Microsoft.ApiManagement/service tiene la ubicación como dimensión para muchas métricas.
La capacidad es una métrica de este tipo. Tener la dimensión de la ubicación implica que el sistema subyacente almacena un registro de métricas para la capacidad de cada ubicación, en lugar de solo uno para la cantidad agregada. A continuación, puede recuperar o dividir esa información en un gráfico de métricas.
Al examinar la duración total de las solicitudes de puerta de enlace, hay dos dimensiones (ubicación y nombre de host), lo que le permite conocer la ubicación de una duración y el nombre de host del que procede.
Una de las métricas más flexibles, Solicitudes, tiene siete dimensiones diferentes.
Consulte el artículo de métricas compatibles con Azure Monitor para obtener más información sobre cada métrica y las dimensiones disponibles. Además, la documentación de cada proveedor y tipo de recursos puede proporcionar información adicional sobre las dimensiones y lo que miden.
Puede usar la división y el filtrado juntos para profundizar en un problema. A continuación se presenta un ejemplo de un gráfico que muestra el promedio de bytes de escritura de disco para un grupo de máquinas virtuales en un grupo de recursos. Tenemos una acumulación de todas las máquinas virtuales con esta métrica, pero es posible que queramos profundizar en ver cuáles son responsables de los picos en torno a las 06:00. ¿Son la misma máquina? ¿Cuántas máquinas intervienen?

Haga clic en las imágenes de esta sección para ver las versiones más grandes.
Cuando se aplica la división, podemos ver los datos subyacentes, pero es un poco complicado. En el gráfico anterior, se agregan 20 máquinas virtuales. En este caso, hemos usado nuestro mouse para mantener el puntero sobre el pico grande a las 06:00, que nos indica que CH-DCVM11 es la causa. Sin embargo, es difícil ver el resto de los datos asociados a esa máquina virtual debido a que otras máquinas virtuales están abarrotando el gráfico.

El uso del filtrado nos permite limpiar el gráfico para ver lo que está ocurriendo realmente. Puede activar o desactivar las máquinas virtuales que quiere ver. Observe las líneas de puntos. Se mencionan en una sección posterior.

Para obtener más información sobre cómo mostrar datos de dimensiones divididos en un gráfico del explorador de métricas, vea Características avanzadas del Explorador de métricas: filtros y división.
Valores NULL y cero
Cuando el sistema espera datos de métricas de un recurso, pero no los recibe, registra un valor NULL. Un valor NULL es diferente de un valor cero, lo que es importante en el cálculo de agregaciones y gráficos. Los valores NULL no se cuentan como medidas válidas.
Los valores NULL se muestran de manera diferente en distintos gráficos. Los trazados de un gráfico de dispersión omiten la presentación de un punto en el gráfico. Los gráficos de barras omiten la presentación de la barra. En los gráficos de líneas, los valores NULL puede aparecer como líneas discontinuas o de puntos, como las que se muestran en la captura de pantalla de la sección anterior. Al calcular los promedios que incluyen valores NULL, hay menos puntos de datos de los que tomar el promedio. A veces, este comportamiento puede dar lugar a una caída inesperada en los valores de un gráfico, aunque menor que si el valor se convierte en un valor cero y se utiliza como un punto de datos válido.
Las métricas personalizadas usan siempre valores NULL cuando no se reciben datos. Con las métricas de la plataforma, cada proveedor de recursos decide si se deben usar valores cero o NULL en función de lo que sea más conveniente para una métrica determinada.
Las alertas de Azure Monitor usan los valores que el proveedor de recursos escribe en la base de datos de métricas, por lo que es importante saber cómo el proveedor de recursos administra los valores NULL mediante la visualización de los datos en primer lugar.
Funcionamiento de la agregación
Los gráficos de métricas del sistema anterior muestran diferentes tipos de datos agregados. El sistema agrega previamente los datos para que los gráficos solicitados puedan mostrarse con mayor rapidez sin muchos cálculos repetidos.
En este ejemplo:
- Recopilamos una métrica transaccional ficticia denominada errores HTTP
- Servidor es una dimensión para la métrica de errores HTTP.
- Tenemos tres servidores: servidor A, B y C.
Para simplificar la explicación, comenzaremos solo con el tipo de agregación SUM.
Agregación de subminuto a 1 minuto
Los primeros datos de métrica sin procesar se recopilan y almacenan en la base de datos de métricas de Azure Monitor. En este caso, cada servidor tiene registros de transacciones almacenados con una marca de tiempo porque Servidor es una dimensión. Dado que el menor período de tiempo que se puede ver como cliente es de 1 minuto, esas marcas de tiempo se agregan primero a valores de métricas de 1 minuto para cada servidor individual. En el gráfico siguiente se muestra el proceso de agregación para el servidor B. Los servidores A y C se realizan de la misma manera y tienen datos diferentes.

Los valores agregados de 1 minuto resultantes se almacenan como nuevas entradas en la base de datos de métricas para que se puedan recopilar para cálculos posteriores.

Agregación de dimensión
Los cálculos de 1 minuto se contraen después por dimensión y se almacenan de nuevo como registros individuales. En este caso, todos los datos de todos los servidores individuales se agregan a una métrica de intervalo de 1 minuto y se almacenan en la base de datos de métricas para su uso en agregaciones posteriores.

Para mayor claridad, en la siguiente tabla se muestra el método de agregación.
| Período | Servidor A | el servidor B | servidor C | Suma (A+B+C) |
|---|---|---|---|---|
| Minuto 1 | 1 | 1 | 1 | 3 |
| Minuto 2 | 0 | 5 | 1 | 6 |
| Minuto 3 | 0 | 5 | 1 | 6 |
| Minuto 4 | 2 | 3 | 4 | 9 |
| Minuto 5 | 1 | 0 | 3 | 4 |
| Minuto 6 | 1 | 0 | 4 | 5 |
| Minuto 7 | 1 | 2 | 4 | 7 |
| Minuto 8 | 0 | 1 | 0 | 1 |
| Minuto 9 | 1 | 1 | 4 | 6 |
| Minuto 10 | 2 | 1 | 0 | 3 |
Anteriormente solo se muestra una dimensión, pero este mismo proceso de agregación y almacenamiento se produce para todas las dimensiones que admite una métrica.
- Recopile valores en un conjunto agregado de 1 minuto mediante esa dimensión. Almacene dichos valores.
- Contraiga la dimensión en una operación SUM agregada de 1 minuto. Almacene dichos valores.
Vamos a introducir otra dimensión de errores HTTP denominada NetworkAdapter. Supongamos que tenemos un número variable de adaptadores por servidor.
- El servidor A tiene un adaptador.
- El servidor B tiene dos adaptadores.
- El servidor C tiene tres adaptadores.
Recopilaremos los datos de las siguientes transacciones por separado. Se marcarán con:
- Hora
- Valor A
- El servidor del que procede la transacción
- El adaptador del que procede la transacción
Cada uno de estos flujos de subminutos se agregará a los valores de serie temporal de 1 minuto y se almacenará en la base de datos de métricas de Azure Monitor:
- Servidor A, adaptador 1
- Servidor B, adaptador 1
- Servidor B, adaptador 2
- Servidor C, adaptador 1
- Servidor C, adaptador 2
- Servidor C, adaptador 3
Además, también se almacenarán las siguientes agregaciones contraídas:
- Servidor A, adaptador 1 (dado que no hay nada para contraer, se almacenará de nuevo)
- Servidor B, adaptador 1+2
- Servidor C, adaptador 1+2+3
- TODOS los servidores, TODOS los adaptadores
Esto muestra que las métricas con grandes cantidades de dimensiones tienen un mayor número de agregaciones. No es importante conocer todas las permutaciones, solo tiene que comprender el razonamiento. El sistema quiere tener los datos individuales y los datos agregados almacenados para una recuperación rápida para el acceso en cualquier gráfico. El sistema selecciona la agregación almacenada más relevante o los datos sin procesar subyacentes, en función de lo que elija mostrar.
Agregación sin dimensiones
Dado que esta métrica tiene una dimensión Servidor, puede llegar a los datos subyacentes para los servidores A, B y C anteriores a través de la división y el filtrado, tal como se explicó anteriormente en este artículo. Si la métrica no tiene Servidor como dimensión, como cliente solo puede acceder a las sumas de 1 minuto agregadas que se muestran en negro en el diagrama. Es decir, los valores 3, 6, 6, 9, etc. El sistema tampoco hará el trabajo subyacente para agregar valores de división, nunca los usaría en el explorador de métricas ni los enviaría a través de la API REST de métricas.
Visualización de granularidad de tiempo superior a 1 minuto
Si solicita métricas con una granularidad mayor, el sistema utiliza las sumas agregadas de 1 minuto para calcular las sumas de las granularidades de tiempo mayor. A continuación, las líneas de puntos muestran el método de suma para las granularidades de tiempo de 2 y 5 minutos. Una vez más, se muestra solo el tipo de agregación SUM para simplificar.
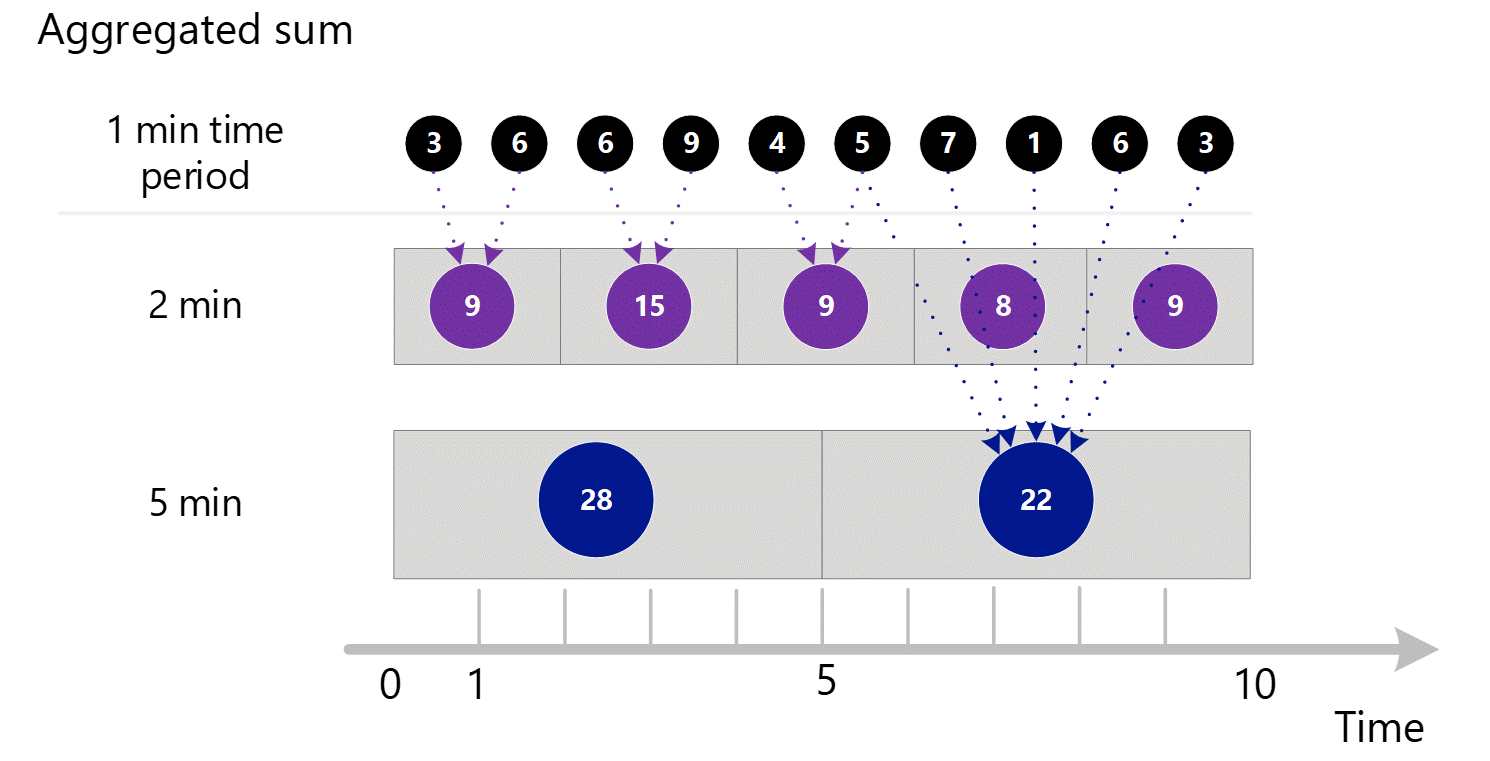
Para la granularidad de tiempo de 2 minutos.
| Período | Suma |
|---|---|
| Minuto 1 y 2 | (3 + 6) = 9 |
| Minuto 3 y 4 | (6 + 9) = 15 |
| Minuto 4 y 5 | (4 + 5) = 9 |
| Minuto 6 y 7 | (7 + 1) = 8 |
| Minuto 8 y 9 | (6 + 3) = 9 |
Para la granularidad de tiempo de 5 minutos.
| Período | Suma |
|---|---|
| Minuto (de 1 a 5) | 3 + 6 + 6 + 9 + 4 = 28 |
| Minuto (de 6 a 10) | 5 + 7 + 1 + 6 + 3 = 22 |
El sistema utiliza los datos agregados almacenados que proporcionan el mejor rendimiento.
A continuación se muestra el diagrama más grande para el proceso de agregación de 1 minuto anterior. Se han dejado algunas de las flechas para mejorar la legibilidad.

Ejemplo más complejo
A continuación se muestra un ejemplo más grande que usa valores de una métrica ficticia denominada tiempo de respuesta HTTP en milisegundos. Se presentan otros niveles de complejidad.
- Se muestra la agregación para Suma, Recuento, Min y Max. y el cálculo para Media.
- Se muestran los valores NULL y cómo afectan a los cálculos.
Considere el ejemplo siguiente. En los cuadros y flechas se muestran ejemplos de cómo se agregan y calculan los valores.
El mismo proceso de agregación previa de 1 minuto que se describe en la sección anterior se produce para Suma, Recuento, Min y Max. Sin embargo, el promedio no se agrega previamente. Se vuelve a calcular con datos agregados para evitar errores de cálculo.

Considere el minuto 6 para la agregación de 1 minuto tal y como se resalta. Este minuto es el punto en el que el servidor B se desconectó y dejó de notificar datos, quizás debido a un reinicio.
En el minuto 6 anterior, los tipos de agregación de 1 minuto calculados son:
| Tipo de agregación | Value | Notas |
|---|---|---|
| Sum | 53+20=73 | |
| Count | 2 | Muestra el efecto de los valores NULL. El valor habría sido 3 si el servidor estuviera en línea. |
| Mínima | 20 | |
| Máxima | 53 | |
| Average | 73 / 2 | Siempre es la suma dividida por el recuento. Nunca se almacena y se vuelve a calcular siempre para cada granularidad de tiempo mediante los números agregados de esa granularidad. Observe el recálculo de las granularidades de 5 minutos y de 10 minutos como se resaltan anteriormente. |
El color de texto rojo indica valores que pueden considerarse fuera del intervalo normal y muestra cómo se propagan (o no) a medida que aumenta la granularidad del tiempo. Observe cómo los valores de Min y Max indican que hay anomalías subyacentes, mientras que Media y Suma pierden esa información a medida que aumenta la granularidad de tiempo.
También puede ver que los valores NULL ofrecen un cálculo de promedio mejor que si se usaran ceros en su lugar.
Nota
Aunque no es el caso de este ejemplo, Count es igual a Sum en los casos en los que una métrica siempre se captura con el valor de 1. Esto es habitual cuando una métrica realiza un seguimiento de la aparición de un evento transaccional, por ejemplo, el número de errores HTTP, que se menciona en un ejemplo anterior de este artículo.