Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Al comprender cómo se almacenan, organizan y usan los blobs y los contenedores en producción, puede optimizar mejor los sacrificios entre el costo y el rendimiento.
En este tutorial se muestra cómo generar y visualizar estadísticas como el crecimiento de datos a lo largo del tiempo, los datos agregados a lo largo del tiempo, el número de archivos modificados, los tamaños de instantánea de blobs, los patrones de acceso a cada nivel y cómo se distribuyen los datos actualmente y a lo largo del tiempo (por ejemplo: datos entre niveles, tipos de archivo, en contenedores y tipos de blobs).
En este tutorial, aprenderá a:
- Generación de un informe de inventario de blobs
- Configuración de un área de trabajo de Synapse
- Configuración de Synapse Studio
- Generación de datos analíticos en Synapse Studio
- Visualizar los resultados en Power BI
Prerrequisitos
Una suscripción a Azure: cree una cuenta gratuita
Una cuenta de almacenamiento de Azure: cree una cuenta de almacenamiento
Asegúrese de que la identidad de usuario tiene asignado el rol Colaborador de datos de Storage Blob.
Generación de un informe de inventario
Habilite los informes de inventario de blobs para su cuenta de almacenamiento. Consulte Habilitación de los informes de inventario de blobs de Azure Storage.
Es posible que tenga que esperar hasta 24 horas después de habilitar los informes de inventario para que se genere el primer informe.
Configuración de un área de trabajo de Synapse
Creación de un área de trabajo de Azure Synapse. Consulte Creación de un área de trabajo de Azure Synapse.
Nota
Como parte de la creación del área de trabajo, creará una cuenta de almacenamiento que tenga un espacio de nombres jerárquico. Azure Synapse almacena tablas de Spark y registros de aplicación en esta cuenta. Azure Synapse hace referencia a esta cuenta como la cuenta de almacenamiento principal. Para evitar confusiones, en este artículo se usa el término cuenta de informes de inventario para hacer referencia a la cuenta que contiene informes de inventario.
En el área de trabajo de Synapse, asigne el rol Colaborador a la identidad de usuario. Consulte Azure RBAC: rol de Propietario para el área de trabajo.
Conceda permiso al área de trabajo de Synapse para acceder a los informes de inventario de la cuenta de almacenamiento; para ello, vaya a la cuenta de informes de inventario y asigne el rol Colaborador de datos de Storage Blob a la identidad administrada del sistema del área de trabajo. Consulte Asignación de roles de Azure mediante Azure Portal.
Vaya a la cuenta de almacenamiento principal y asigne el rol Colaborador de Blob Storage a su identidad de usuario.
Configuración de Synapse Studio
Abra el área de trabajo en Synapse Studio. Consulte Abrir Synapse Studio.
En Synapse Studio, asegúrese de que la identidad tiene asignado el rol de Administrador de Synapse. Consulte Synapse RBAC: rol de Administrador de Synapse para el área de trabajo.
Creación de un grupo de Apache Spark. Consulte Creación de un grupo de Apache Spark sin servidor.
Configuración y ejecución del cuaderno de ejemplo
En esta sección, generará datos estadísticos que visualizará en un informe. Para simplificar este tutorial, en esta sección se usa un archivo de configuración de ejemplo y un cuaderno de PySpark de ejemplo. El cuaderno contiene una colección de consultas que se ejecutan en Azure Synapse Studio.
Modificación y carga del archivo de configuración de ejemplo
Descargue el archivo BlobInventoryStorageAccountConfiguration.json.
Actualice los siguientes marcadores de posición de ese archivo:
Establezca
storageAccountNameen el nombre de la cuenta de informes de inventario.Establezca
destinationContaineren el nombre del contenedor que contiene los informes de inventario.Establezca
blobInventoryRuleNameen el nombre de la regla de informes de inventario que ha generado los resultados que desea analizar.Establezca
accessKeyen la clave de cuenta de la cuenta de informes de inventario.
Cargue este archivo en el contenedor de la cuenta de almacenamiento principal que especificó al crear el área de trabajo de Synapse.
Importación del cuaderno de PySpark de ejemplo
Descargue el cuaderno de ejemplo ReportAnalysis.ipynb.
Nota
Asegúrese de guardar este archivo con la extensión
.ipynb.Abra el área de trabajo en Synapse Studio. Consulte Abrir Synapse Studio.
En Synapse Studio, seleccione la pestaña Desarrollar.
Seleccione el signo más (+) para agregar un elemento.
Seleccione Importar, vaya al archivo de ejemplo que descargó, seleccione ese archivo y seleccione Abrir.
Aparecerá el cuadro de diálogo Propiedades.
En el cuadro de diálogo Propiedades, seleccione el vínculo Configurar sesión.
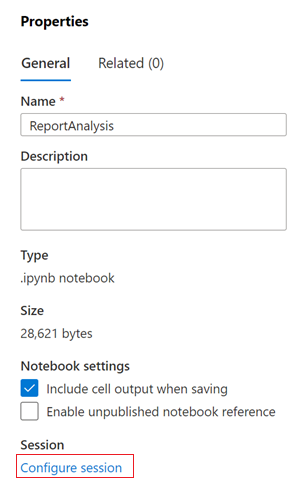
Se abre el cuadro de diálogo Configurar sesión.
En la lista desplegable Asociar a del cuadro de diálogo Configurar sesión, seleccione el grupo de Spark que creó anteriormente en este artículo. Después, seleccione el botón Aplicar.
Modificación del cuaderno de Python
En la primera celda del cuaderno de Python, establezca el valor de la variable
storage_accounten el nombre de la cuenta de almacenamiento principal.Actualice el valor de la variable
container_nameen el nombre del contenedor en esa cuenta que especificó al crear el área de trabajo de Synapse.Seleccione el botón Publicar.
Ejecución del cuaderno de PySpark
En el cuaderno de PySpark, seleccione Ejecutar todo.
Tardará unos minutos en iniciar la sesión de Spark y otros minutos para procesar los informes de inventario. La primera ejecución podría tardar un tiempo si hay numerosos informes de inventario que procesar. Las ejecuciones posteriores solo procesarán los nuevos informes de inventario creados desde la última ejecución.
Nota
Si realiza algún cambio en el cuaderno, asegúrese de publicar esos cambios mediante el botón Publicar.
Para comprobar que el cuaderno se ejecutó correctamente, seleccione la pestaña Datos.
Debería aparecer una base de datos denominada reportdata en la pestaña Área de trabajo del panel Datos. Si esta base de datos no aparece, es posible que tenga que actualizar la página web.
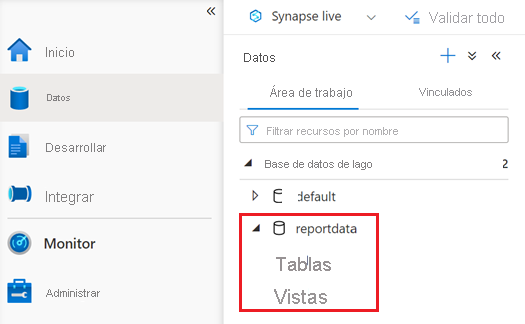
La base de datos contiene un conjunto de tablas. Cada tabla contiene información obtenida mediante la ejecución de las consultas desde el cuaderno de PySpark.
Para examinar el contenido de una tabla, expanda la carpeta Tablas de la base de datos reportdata. A continuación, haga clic con el botón derecho en una tabla, seleccione Seleccionar script SQL y, después, seleccione Seleccionar las 100 filas SUPERIORES.
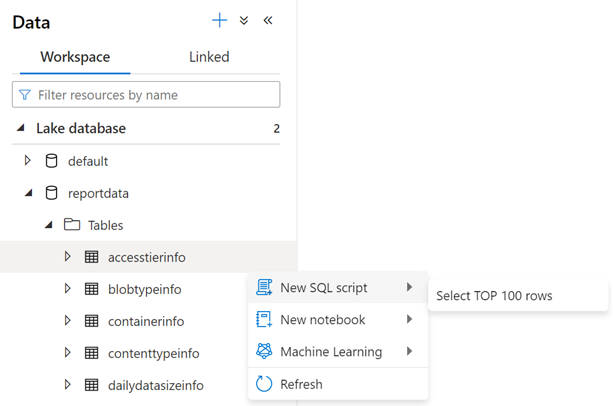
Puede modificar la consulta según sea necesario y seleccionar Ejecutar para ver los resultados.

Visualización de los datos
Descargue el archivo de informe de ejemplo ReportAnalysis.pbit.
Abra Power BI Desktop. Para obtener instrucciones de instalación, consulte Obtener Power BI Desktop.
En Power BI, seleccione Archivo, Abrir informe y, después, Examinar informes.
En el cuadro de diálogo Abrir, cambie el tipo de archivo a archivos de plantilla de Power BI (*.pbit).

Vaya a la ubicación del archivo ReportAnalysis.pbit que descargó y seleccione Abrir.
Aparece un cuadro de diálogo que le pide que proporcione el nombre del área de trabajo de Synapse y el nombre de la base de datos.
En el cuadro de diálogo, establezca el campo synapse_workspace_name en el nombre del área de trabajo y establezca el campo database_name en
reportdata. A continuación, seleccione el botón Cargar.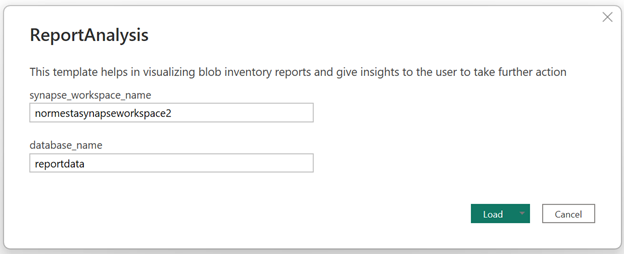
Aparece un informe que proporciona visualizaciones de los datos recuperados por el cuaderno. Las imágenes siguientes muestran los tipos de gráficos que aparecen en este informe.
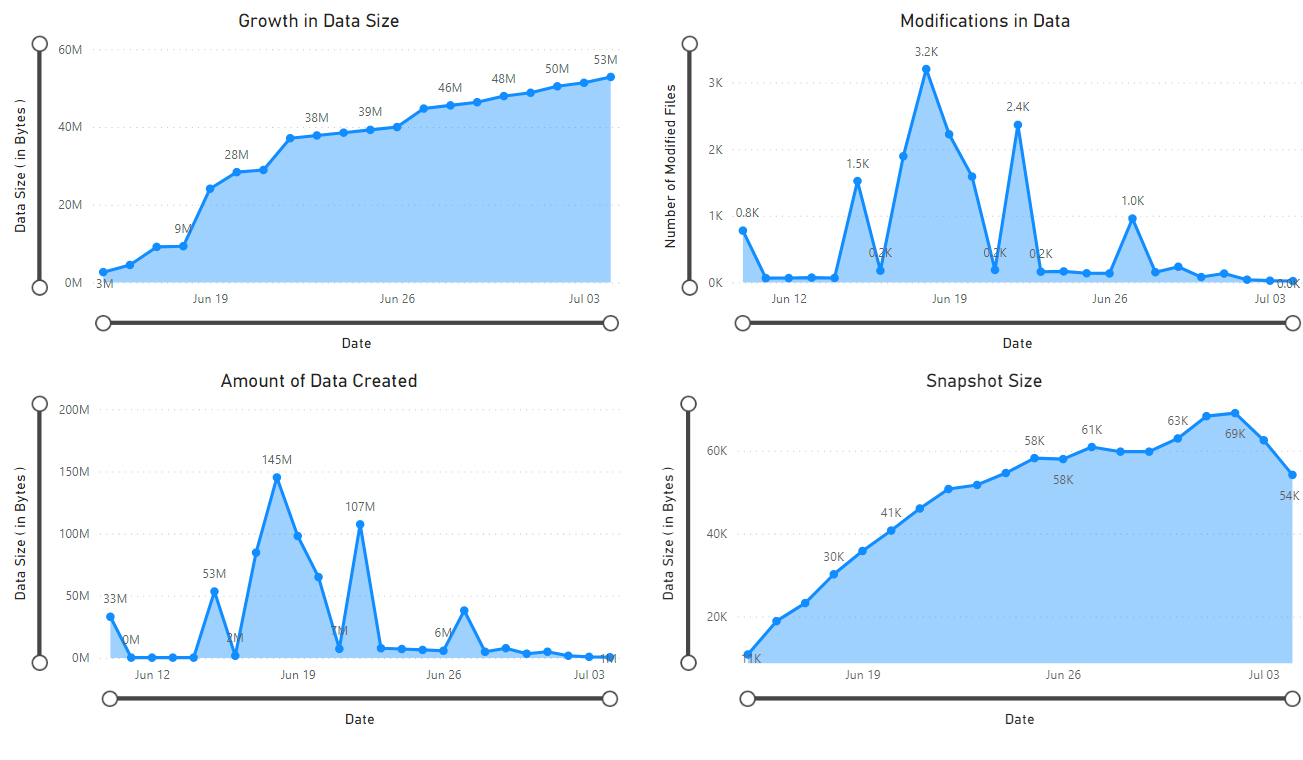
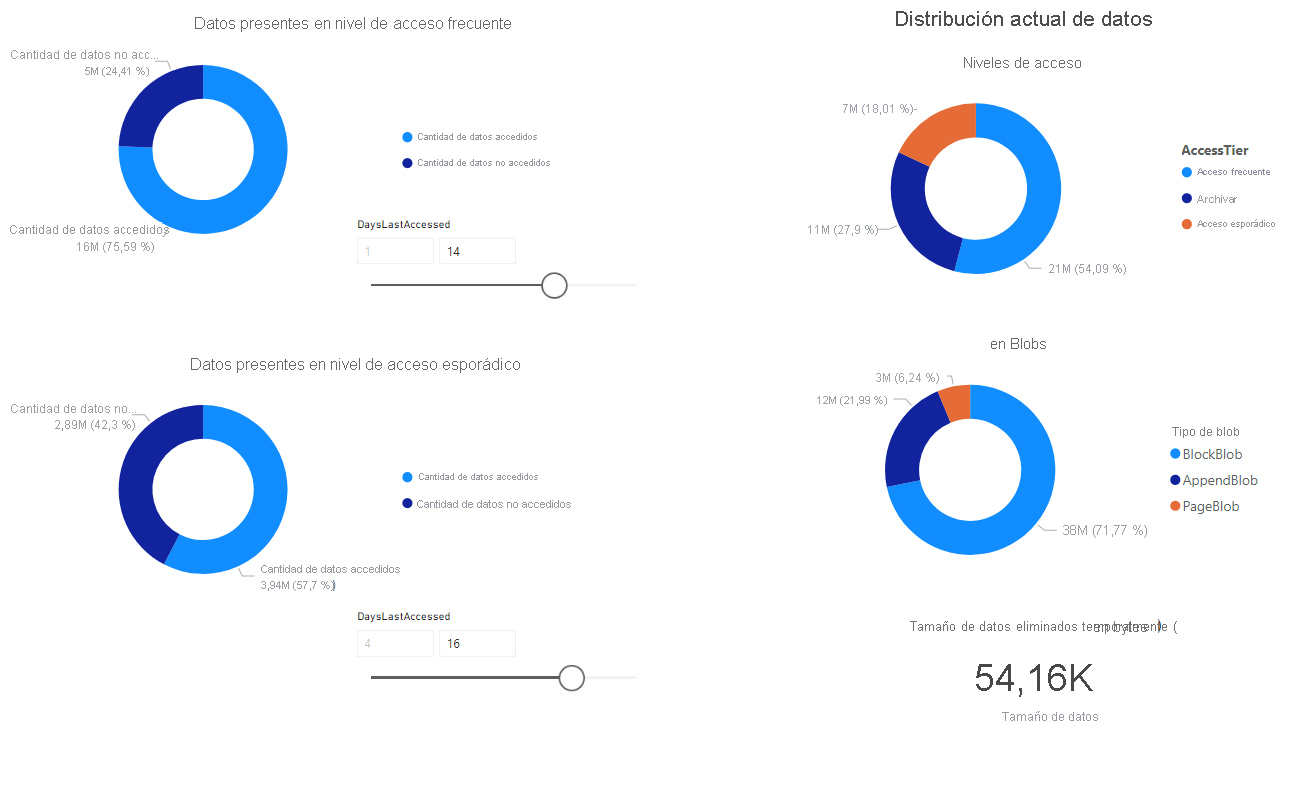
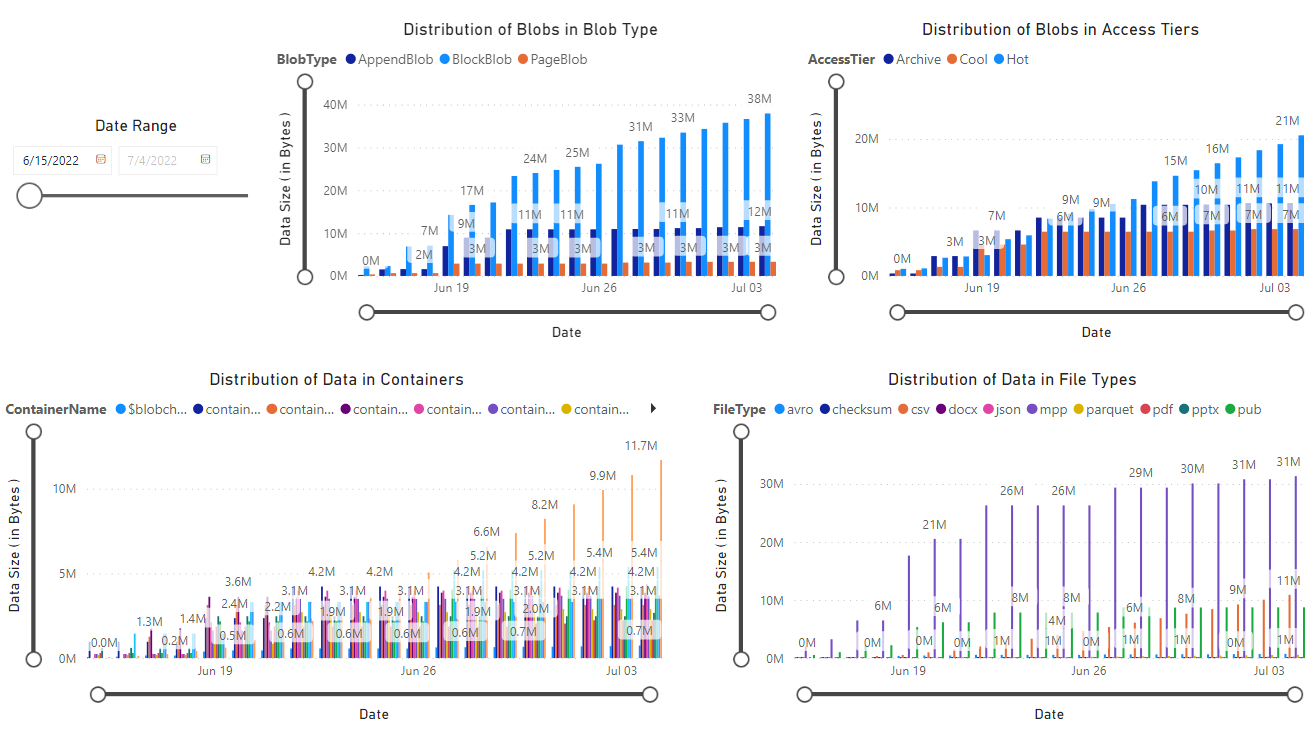
Pasos siguientes
Configure una canalización de Azure Synapse para seguir ejecutando el cuaderno a intervalos regulares. De este modo, puede procesar nuevos informes de inventario a medida que se crean. Después de la ejecución inicial, cada una de las siguientes ejecuciones analizará los datos incrementales y, después, actualizará las tablas con los resultados de ese análisis. Para obtener instrucciones, consulte Integración con canalizaciones.
Obtenga información sobre las formas de analizar contenedores individuales en la cuenta de almacenamiento. Consulte estos artículos:
Tutorial: Cálculo de las estadísticas de contenedor mediante Databricks
Obtenga información sobre las formas de optimizar los costos en función del análisis de los blobs y contenedores. Consulte estos artículos:
Planeamiento y administración de costos de Azure Blob Storage
Estimación del coste de archivar datos
Optimizar los costes mediante la administración automática del ciclo de vida de los datos