Eventos
31 mar, 23 - 2 abr, 23
Evento de aprendizaje de Fabric, Power BI y SQL más grande. 31 de marzo – 2 de abril. Use el código FABINSIDER para ahorrar $400.
Regístrate hoyEste explorador ya no se admite.
Actualice a Microsoft Edge para aprovechar las características y actualizaciones de seguridad más recientes, y disponer de soporte técnico.
Se aplica a:
 SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
En este artículo se resumen las nuevas características, mejoras, características en desuso y descontinuadas, y el comportamiento y los cambios importantes en las versiones más recientes de SQL Server Analysis Services (SSAS).
Esta actualización incluye una mejora en el algoritmo de cifrado de la operación de escritura de esquema. Esta mejora puede requerir que actualice las bases de datos de modelos tabulares y multidimensionales para garantizar el cifrado adecuado. Para más información, consulte Actualización del cifrado.
Esta versión presenta Horizontal Fusion, una optimización del plan de ejecución de consultas destinada a reducir el número de consultas de origen de datos necesarias para generar y devolver resultados. Varias consultas de origen de datos más pequeñas se fusionan juntas en una consulta de origen de datos más grande. Menos consultas de origen de datos significan menos recorridos de ida y vuelta y menos exámenes costosos en orígenes de datos de gran tamaño, lo que da lugar a mejoras de rendimiento daX considerables y a una demanda de procesamiento reducida en el origen de datos. Las consultas DAX se ejecutan más rápido con Horizontal Fusion, especialmente en el modo DirectQuery. Además, la escalabilidad también aumenta.
Esta mejora permite al motor de Analysis Services analizar consultas DAX en un origen de datos directQuery e identificar las operaciones independientes del motor de almacenamiento. Después, el motor puede ejecutar esas operaciones en el origen de datos en paralelo. Al ejecutar operaciones en paralelo, el motor de Analysis Services puede mejorar el rendimiento de las consultas aprovechando la escalabilidad de orígenes de datos de gran tamaño. Para asegurarse de que el procesamiento de consultas no sobrecarga el origen de datos, use el valor de la propiedad MaxParallelism para especificar un número fijo de subprocesos que se pueden usar para las operaciones paralelas.
Esta versión presenta compatibilidad con modelos de Power BI con conexiones de DirectQuery a SQL Server modelos de Analysis Services 2022. Los modeladores de datos y los autores de informes que usan mayo de 2022 y versiones posteriores de Power BI Desktop ahora pueden combinar otros datos importados y DirectQuery de modelos de Power BI, Azure Analysis Services y ahora SSAS 2022.
Para más información, consulte Uso de DirectQuery para modelos semánticos y Analysis Services | Documentación de Power BI.
En primer lugar, se introdujo en Power BI y ahora en SSAS 2022, MDX Fusion incluye la optimización del motor de fórmulas (FE), lo que reduce el número de consultas del motor de almacenamiento (SE) por consulta MDX. Las aplicaciones cliente que usan expresiones multidimensionales (MDX) para consultar datos de modelo o conjunto de datos, como Microsoft Excel, verán un rendimiento mejorado de las consultas. Los patrones de consulta MDX comunes ahora requieren menos consultas SE en las que anteriormente se requerían numerosas consultas SE para admitir una granularidad diferente. Menos consultas SE significan exámenes menos costosos en modelos grandes, lo que da lugar a importantes mejoras de rendimiento, especialmente al conectarse a modelos tabulares en el modo Direct Query.
Para más información, consulte Anuncio del rendimiento mejorado de consultas MDX en Power BI | Blog de Microsoft Power BI.
Esta versión incluye una precisión mejorada para la propiedad de memoria del servidor QueryMemoryLimit y la propiedad DbpropMsmdRequestMemoryLimit cadena de conexión.
En primer lugar, se introdujo en SSAS 2019, la propiedad de memoria del servidor QueryMemoryLimit solo se aplica a las colas de memoria en las que se crean los resultados intermedios de la consulta DAX durante el procesamiento de consultas. Ahora en SSAS 2022, también se aplica a las consultas MDX, que cubren de forma eficaz todas las consultas. Puede controlar mejor las consultas costosas de procesos que dan lugar a una materialización significativa. Si la consulta alcanza el límite especificado, el motor cancela la consulta y devuelve un error al autor de la llamada, lo que reduce el impacto en otros usuarios simultáneos.
Las aplicaciones cliente pueden reducir aún más la memoria permitida por consulta especificando la propiedad DbpropMsmdRequestMemoryLimit cadena de conexión. Especificado en Kilobytes, esta propiedad invalida el valor de la propiedad de memoria del servidor QueryMemoryLimit para una conexión.
Esta versión presenta un nuevo valor que especifica sesgo de consulta corta con cancelación rápida para el valor de la propiedad Threadpool\SchedulingBehavior. Esta configuración de propiedad mejora los tiempos de respuesta de las consultas de usuario en escenarios de alta simultaneidad. Para más información, consulte Intercalación de consultas: configuración.
Esta versión presenta el nivel de compatibilidad 1600 para los modelos tabulares. El nivel de compatibilidad 1600 coincide con la funcionalidad más reciente de Power BI y Azure Analysis Services.
No hay características en desuso anunciadas con esta versión.
En esta versión se descontinuan las siguientes características:
| Modo o categoría | Característica |
|---|---|
| Tabular | 1100 y 1103 Niveles de compatibilidad |
| Multidimensional | Minería de datos |
| Modo Power Pivot | PowerPivot para SharePoint |
Los niveles de compatibilidad del modelo tabular 1100 y 1103 se descontinuan en esta versión. Para evitar un cambio importante, actualice los modelos al nivel de compatibilidad 1200 antes de actualizar una versión anterior de SSAS a SSAS 2022.
No hay ningún cambio de comportamiento en esta versión.
SQL Server Analysis Services actualizaciones acumulativas se incluyen con SQL Server actualizaciones acumulativas. Para obtener más información sobre y descargar la actualización acumulativa más reciente, consulte actualización acumulativa más reciente de SQL Server 2019. Las páginas de KB de actualización acumulativa resumen los problemas conocidos, las mejoras y las correcciones de todas las características de SQL Server, incluido SSAS. Aquí se describen detalles adicionales para las actualizaciones de características principales de SSAS.
Con CU5, los clientes basados en DAX ahora pueden usar funciones superDAX y patrones de consulta con modelos multidimensionales, lo que proporciona un rendimiento mejorado al consultar datos del modelo. SuperDAX introdujo por primera vez optimizaciones de consultas DAX para modelos tabulares con Power BI y SQL Server Analysis Services 2016. SuperDAXMD ahora aporta estas mejoras a los modelos multidimensionales.
Un anuncio independiente en el blog de Power BI resalta cómo los usuarios de Power BI pueden beneficiarse de esta mejora del rendimiento del modelo multidimensional mediante la descarga de la versión más reciente de Power BI Desktop. Los informes interactivos existentes en el servicio Power BI pueden beneficiarse sin ningún paso adicional, ya que Power BI genera automáticamente las consultas SuperDAX optimizadas. Power BI detecta automáticamente las conexiones a modelos multidimensionales con compatibilidad con SuperDAX y usa las mismas funciones DAX optimizadas y patrones de consulta que ya usa en modelos tabulares. Aunque Power BI puede cambiar automáticamente a SuperDAXMD, en sus propias soluciones de inteligencia empresarial, es posible que tenga que optimizar manualmente los patrones de consulta DAX.
Los patrones de consulta optimizados deben usar la función SUMMARIZECOLUMNS para reemplazar la función SUMMARIZE estándar menos eficaz. Use variables DAX, VAR, para calcular expresiones solo una vez en el lugar de definición y, a continuación, volver a usar los resultados en cualquier otra expresión DAX sin tener que volver a realizar el cálculo. Otras funciones SuperDAX, y quizá menos comunes son SUBSTITUTEWITHINDEX, ADDMISSINGITEMS, así como NATURALLEFTOUTERJOIN y NATURALINNERJOIN, ISONORAFTER y GROUPBY. SELECTCOLUMNS y UNION también son funciones SuperDAX.
Para obtener más información sobre cómo FUNCIONA DAX con modelos multidimensionales y patrones y restricciones importantes que se deben tener en cuenta, asegúrese de ver DAX para modelos multidimensionales.
En esta versión se presenta el nivel de compatibilidad 1500 para los modelos tabulares.
La intercalación de consultas es una configuración del sistema en modo tabular que puede mejorar los tiempos de respuesta a las consultas de usuario en escenarios de alta simultaneidad. La intercalación de consultas con sesgo de consulta corto permite que las consultas simultáneas compartan recursos de CPU. Para obtener más información, vea Intercalación de consultas.
Los grupos de cálculo pueden reducir significativamente el número de medidas redundantes mediante la agrupación de expresiones de medida comunes como elementos de cálculo. Los grupos de cálculo se muestran en los clientes de informes como una tabla con una sola columna. Cada valor de la columna representa un cálculo reutilizable (o elemento de cálculo) que se puede aplicar a cualquiera de las medidas. Un grupo de cálculo puede tener cualquier número de elementos de cálculo. Cada elemento de cálculo se define mediante una expresión DAX. Para más información, consulte Grupos de cálculo.
El valor de la propiedad ClientCacheRefreshPolicy ahora se admite en SSAS 2019 y versiones posteriores. Esta configuración de propiedad ya está disponible para Azure Analysis Services. El servicio Power BI almacena en caché los datos del icono del panel y los datos de informe para la carga inicial de Live Connect informe, lo que provoca un número excesivo de consultas de caché que se envían al motor y, en casos extremos, sobrecargan el servidor. La propiedad ClientCacheRefreshPolicy permite invalidar este comportamiento en el nivel de servidor. Para obtener más información, vea Propiedades generales.
Esta característica ofrece la posibilidad de adjuntar un modelo tabular como una operación en línea. Adjunto en línea se puede usar para la sincronización de réplicas de solo lectura en entornos locales de escalabilidad horizontal de consultas. Para realizar una operación de asociación en línea, use la opción AllowOverwrite del comando Adjuntar XMLA.

Esta operación puede requerir el doble de memoria del modelo para mantener la versión anterior en línea mientras se carga la nueva versión.
Un patrón de uso típico podría ser el siguiente:
DB1 (versión 1) ya está adjuntado al servidor B de solo lectura.
DB1 (versión 2) se procesa en el servidor de escritura A.
DB1 (versión 2) se desasocia y coloca en una ubicación accesible para el servidor B (ya sea a través de una ubicación compartida o mediante Robocopy, etc.).
El <comando Attach> con AllowOverwrite=True se ejecuta en el servidor B con la nueva ubicación de DB1 (versión 2).
Sin esta característica los administradores, en primer lugar, deben desasociar la base de datos y, después, adjuntar la nueva versión de la base de datos. Esto conduce a tiempo de inactividad cuando la base de datos no está disponible para los usuarios y las consultas que se realicen producirán un error.
Cuando se especifica esta nueva marca, la versión 1 de la base de datos se elimina de forma atómica en la misma transacción sin tiempo de inactividad. Sin embargo, tiene como contrapartida que ambas bases de datos se cargan en memoria de forma simultánea.
Esta mejora permite relaciones de varios a varios entre tablas donde ambas columnas no son únicas. Puede definirse una relación entre una tabla de hechos y dimensiones con una granularidad mayor que la columna clave de la dimensión. Esto evita tener que normalizar las tablas de dimensiones y puede mejorar la experiencia del usuario, dado que el modelo resultante tiene un menor número de tablas con columnas agrupadas lógicamente.
Las relaciones de varios a varios requieren que los modelos estén en el nivel de compatibilidad 1500 y superior. Puede crear relaciones de varios a varios mediante Visual Studio 2019 con proyectos de Analysis Services VSIX update 2.9.2 y versiones posteriores, la API del modelo de objetos tabulares (TOM), tabular Model Scripting Language (TMSL) y la herramienta Editor tabular de código abierto.
La siguiente configuración de propiedades proporciona una gobernanza de recursos mejorada:
Estas propiedades pueden establecerse mediante la última versión de SQL Server Management Studio (SSMS). Esta configuración ya está disponible para Azure Analysis Services.
No hay características en desuso anunciadas con esta versión.
No hay características no interrumpidas anunciadas con esta versión.
No hay cambios importantes en esta versión.
No hay ningún cambio de comportamiento en esta versión.
SQL Server 2017 Analysis Services ve algunas de las mejoras más importantes desde SQL Server 2012. Basándose en el éxito del modo tabular (introducido por primera vez en SQL Server 2012 Analysis Services), esta versión hace que los modelos tabulares sean más eficaces que nunca.
El modo multidimensional y el modo Power Pivot para SharePoint son un elemento básico para muchas implementaciones de Analysis Services. En el ciclo de vida del producto de Analysis Services, estos modos están maduros. No hay características nuevas para ninguno de estos modos en esta versión. Sin embargo, se incluyen correcciones de errores y mejoras de rendimiento.
Las características que se describen aquí se incluyen en SQL Server 2017 Analysis Services. Pero para aprovecharlas, también debe usar las versiones más recientes de Visual Studio con proyectos de Analysis Services y SQL Server Management Studio (SSMS). Los proyectos de Analysis Services y SSMS se actualizan mensualmente con características nuevas y mejoradas que suelen coincidir con la nueva funcionalidad en SQL Server.
Aunque es importante obtener información sobre todas las características nuevas, también es importante saber qué está en desuso y se interrumpe en esta versión y versiones futuras. Para más información, consulte Características en desuso en SSAS 2017.
Echemos un vistazo a algunas de las principales características nuevas de esta versión.
Para aprovechar muchas de las nuevas características y funcionalidades que se describen aquí, los modelos tabulares nuevos o existentes deben establecerse o actualizarse al nivel de compatibilidad 1400. Los modelos con el nivel de compatibilidad 1400 no pueden implementarse en SQL Server 2016 SP1 o versiones anteriores, ni degradarse a niveles de compatibilidad inferiores. Para más información, consulte Nivel de compatibilidad para los modelos tabulares de Analysis Services.
En Visual Studio, puede seleccionar el nuevo nivel de compatibilidad 1400 al crear nuevos proyectos de modelo tabular.
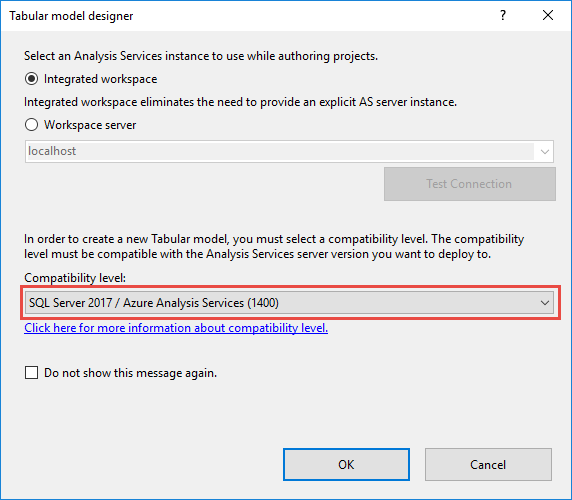
Para actualizar un modelo tabular existente en Visual Studio, en Explorador de soluciones, haga clic con el botón derecho en Model.bim y, a continuación, en Propiedades, establezca la propiedad Nivel de compatibilidad en SQL Server 2017 (1400).
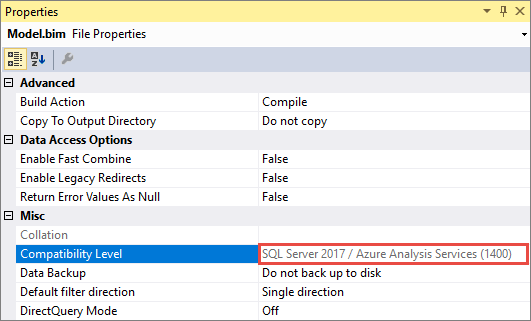
Es importante tener en cuenta que, una vez que actualice un modelo existente a 1400, no se puede cambiar a una versión anterior. Asegúrese de mantener una copia de seguridad de la base de datos del modelo 1200.
En lo que respecta a la importación de datos de orígenes de datos en los modelos tabulares, SSDT presenta la experiencia moderna obtener datos para los modelos en el nivel de compatibilidad 1400. Esta característica nueva se basa en una funcionalidad similar de Power BI Desktop y Microsoft Excel 2016. La experiencia moderna get data proporciona inmensas funcionalidades de transformación de datos y mashup de datos mediante el generador de consultas Get Data y expresiones M.
La experiencia moderna obtener datos proporciona compatibilidad con una amplia gama de orígenes de datos. En el futuro, las actualizaciones incluirán compatibilidad con aún más.
Una interfaz de usuario eficaz e intuitiva facilita la selección de los datos y las funcionalidades de transformación y mashup de datos.
La experiencia moderna Obtener datos y las funcionalidades de mashup de M no se aplican a los modelos tabulares existentes actualizados desde el nivel de compatibilidad de 1200 a 1400. La nueva experiencia solo se aplica a los nuevos modelos creados en el nivel de compatibilidad 1400.
En esta versión se presentan sugerencias de codificación, una característica avanzada que se usa para optimizar el procesamiento (actualización de datos) de modelos tabulares grandes en memoria. Para comprender mejor la codificación, vea notas del producto sobre el ajuste del rendimiento de los modelos tabulares en SQL Server notas del producto de Analysis Services de 2012 para comprender mejor la codificación.
La codificación de valores proporciona un mejor rendimiento de las consultas para las columnas que normalmente solo se usan para agregaciones.
Se prefiere la codificación hash para las columnas group-by (a menudo valores de tabla de dimensiones) y claves externas. Las columnas de cadena siempre están codificadas por hash.
Las columnas numéricas pueden usar cualquiera de estos métodos de codificación. Cuando Analysis Services inicia el procesamiento de una tabla, si la tabla está vacía (con o sin particiones) o se realiza una operación de procesamiento de tabla completa, se toman valores de muestra para cada columna numérica para determinar si se debe aplicar la codificación hash o el valor. De forma predeterminada, se elige la codificación de valor cuando la muestra de valores distintos de la columna es lo suficientemente grande; de lo contrario, la codificación hash suele proporcionar una mejor compresión. Es posible que Analysis Services cambie el método de codificación después de que la columna se procese parcialmente en función de más información sobre la distribución de datos y reinicie el proceso de codificación; sin embargo, esto aumenta el tiempo de procesamiento y es ineficaz. En las notas del producto de optimización del rendimiento se describe la recodificación con más detalle y se describe cómo detectarlo mediante SQL Server Profiler.
Las sugerencias de codificación permiten al modelador especificar una preferencia para el método de codificación dado un conocimiento previo de la generación de perfiles de datos o en respuesta a volver a codificar eventos de seguimiento. Dado que la agregación sobre columnas codificadas por hash es más lenta que las columnas codificadas por valores, la codificación de valores se puede especificar como una sugerencia para estas columnas. No se garantiza que se aplique la preferencia. Se trata de una sugerencia en lugar de una configuración. Para especificar una sugerencia de codificación, establezca la propiedad EncodingHint en la columna. Los valores posibles son "Default", "Value" y "Hash". El siguiente fragmento de código de metadatos basados en JSON del archivo Model.bim especifica la codificación de valor para la columna Importe de ventas.
{
"name": "Sales Amount",
"dataType": "decimal",
"sourceColumn": "SalesAmount",
"formatString": "\\$#,0.00;(\\$#,0.00);\\$#,0.00",
"sourceProviderType": "Currency",
"encodingHint": "Value"
}
En los modelos tabulares, puede modelar jerarquías de elementos primarios y secundarios. Las jerarquías con un número diferente de niveles suelen denominarse jerarquías desiguales. De forma predeterminada, las jerarquías desiguales se muestran con espacios en blanco para los niveles situados por debajo del elemento secundario más bajo. Este es un ejemplo de una jerarquía desigual en un organigrama:
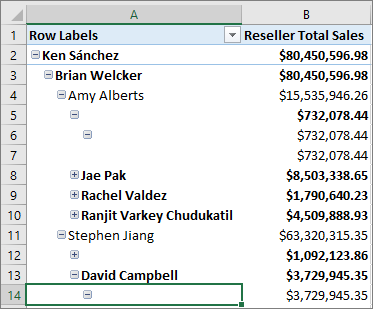
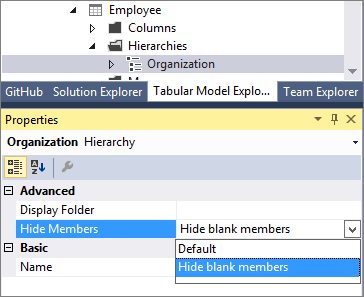
En esta versión se incluye la propiedad Ocultar miembros . Puede establecer la propiedad Ocultar miembros de una jerarquía en Hide blank members(Ocultar miembros en blanco).
Nota
Los miembros en blanco del modelo se representan mediante un valor DAX en blanco, en lugar de una cadena vacía.
Cuando se establece en Hide blank members(Ocultar miembros en blanco) y se implementa el modelo, se muestra una versión de la jerarquía más fácil de leer en los clientes de informes, como Excel.
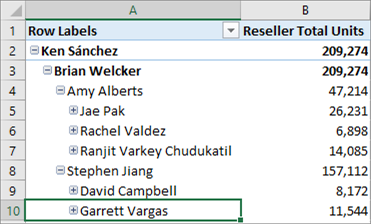
Ahora puede definir un conjunto de filas personalizado que contribuya a un valor de medida. La opción Filas de detalles es similar a la acción de obtención de detalles predeterminada de los modelos multidimensionales. Permite a los usuarios finales ver la información con más detalle que el nivel agregado.
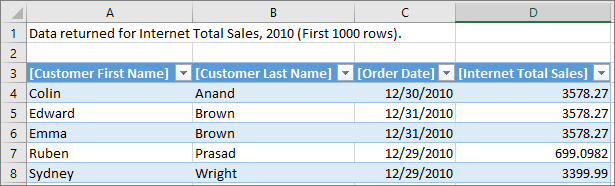
En la siguiente tabla de dinámica se muestran las ventas totales por Internet por año del modelo tabular de ejemplo de Adventure Works. Para ver las filas de detalles, haga clic con el botón derecho en una celda con un valor agregado de la medida y, después, haga clic en Mostrar detalles .

De forma predeterminada, se muestran los datos asociados en la tabla de ventas por Internet. Este comportamiento limitado no suele ser significativo para el usuario, ya que la tabla podría no tener las columnas necesarias para mostrar información útil, como el nombre del cliente y la información del pedido. Con Filas de detalles, puede especificar una propiedad Expresión de filas de detalles para las medidas.
La propiedad Expresión de filas de detalles para las medidas permite a los autores de modelos personalizar las columnas y las filas que se devuelven al usuario final.
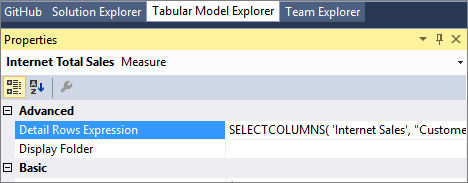
La función DAX SELECTCOLUMNS se usa normalmente en una expresión de filas de detalle. En el ejemplo siguiente se definen las columnas que se devuelven para las filas de la tabla de ventas por Internet del modelo tabular de ejemplo de Adventure Works:
SELECTCOLUMNS(
'Internet Sales',
"Customer First Name", RELATED( Customer[Last Name]),
"Customer Last Name", RELATED( Customer[First Name]),
"Order Date", 'Internet Sales'[Order Date],
"Internet Total Sales", [Internet Total Sales]
)
Una vez que se ha definido la propiedad y se ha implementado el modelo, se devuelve un conjunto de filas personalizado cuando el usuario selecciona Mostrar detalles. Se respeta automáticamente el contexto de filtro de la celda que se ha seleccionado. En este ejemplo, solo se muestran las filas del valor 2010:
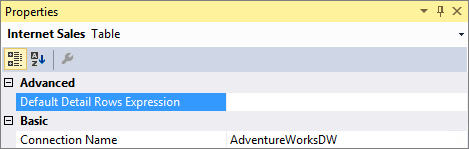
Además de las medidas, las tablas también tienen una propiedad para definir una expresión de filas de detalles. La propiedad Expresión de filas de detalles predeterminada actúa como valor predeterminado para todas las medidas de la tabla. Las medidas que no tienen su propia expresión definida heredan la expresión de la tabla y muestran el conjunto de filas definido para la tabla. Esto permite la reutilización de expresiones y las nuevas medidas agregadas a la tabla posteriormente heredan automáticamente la expresión.
En esta versión se incluye una nueva función DAX DETAILROWS que devuelve el conjunto de filas definido por la expresión de filas de detalles. Funciona de forma similar a la instrucción DRILLTHROUGH en MDX, que también es compatible con las expresiones de filas de detalles definidas en modelos tabulares.
La siguiente consulta DAX devuelve el conjunto de filas definido por la expresión de filas de detalles para la medida o su tabla. Si no se define ninguna expresión, se devuelven los datos de la tabla de ventas por Internet, ya que es la tabla que contiene la medida.
EVALUATE DETAILROWS([Internet Total Sales])
En esta versión se presenta la seguridad de nivel de objeto para tablas y columnas. Además de restringir el acceso a los datos de tabla y columna, se pueden proteger los nombres de tabla y columna confidenciales. Esto ayuda a impedir que un usuario malintencionado detecte la existencia de una tabla.
La seguridad de nivel de objeto debe establecerse mediante los metadatos basados en JSON, el lenguaje de scripting de modelos tabulares (TMSL) o el modelo de objetos tabulares (TOM).
Por ejemplo, el código siguiente ayuda a proteger la tabla Product del modelo tabular de ejemplo de Adventure Works. Para ello, establece la propiedad MetadataPermission de la clase TablePermission en None.
//Find the Users role in Adventure Works and secure the Product table
ModelRole role = db.Model.Roles.Find("Users");
Table productTable = db.Model.Tables.Find("Product");
if (role != null && productTable != null)
{
TablePermission tablePermission;
if (role.TablePermissions.Contains(productTable.Name))
{
tablePermission = role.TablePermissions[productTable.Name];
}
else
{
tablePermission = new TablePermission();
role.TablePermissions.Add(tablePermission);
tablePermission.Table = productTable;
}
tablePermission.MetadataPermission = MetadataPermission.None;
}
db.Update(UpdateOptions.ExpandFull);
Las DMV son consultas en SQL Server Profiler que devuelven información sobre las operaciones del servidor local y el estado del servidor. Esta versión incluye mejoras en las vistas de administración dinámica (DMV) para los modelos tabulares en los niveles de compatibilidad 1200 y 1400.
DISCOVER_CALC_DEPENDENCY Ahora funciona con modelos tabulares 1200 y superiores. Los modelos tabulares 1400 y superiores muestran dependencias entre particiones M, expresiones M y orígenes de datos estructurados. Para más información, consulte el blog de Analysis Services.
MDSCHEMA_MEASUREGROUP_DIMENSIONS Mejoras se incluyen para esta DMV, que usan varias herramientas de cliente para mostrar la dimensionalidad de la medida. Por ejemplo, la característica Explorar en tablas dinámicas de Excel permite al usuario explorar en profundidad dimensiones relacionadas con las medidas seleccionadas. Esta versión corrige las columnas de cardinalidad, que anteriormente mostraban valores incorrectos.
Una de las partes más importantes de la nueva funcionalidad DAX es la nueva función IN Operator / CONTAINSROW para expresiones DAX. Esto es similar al operador TSQL IN que se suele usar para especificar varios valores en una cláusula WHERE .
Antes, lo habitual era especificar filtros de valores múltiples mediante el operador lógico OR , como en la expresión de medida siguiente:
Filtered Sales:=CALCULATE (
[Internet Total Sales],
'Product'[Color] = "Red"
|| 'Product'[Color] = "Blue"
|| 'Product'[Color] = "Black"
)
Esto se ha simplificado mediante el operador IN :
Filtered Sales:=CALCULATE (
[Internet Total Sales], 'Product'[Color] IN { "Red", "Blue", "Black" }
)
En este caso, el operador IN hace referencia a una tabla de una sola columna con tres filas, una para cada uno de los colores especificados. Observe que la sintaxis del constructor de tabla usa llaves.
El operador IN es funcionalmente equivalente a la función CONTAINSROW :
Filtered Sales:=CALCULATE (
[Internet Total Sales], CONTAINSROW({ "Red", "Blue", "Black" }, 'Product'[Color])
)
El operador IN también se puede usar eficazmente con constructores de tabla. Por ejemplo, las siguientes medidas filtran por combinaciones de color y categoría del producto:
Filtered Sales:=CALCULATE (
[Internet Total Sales],
FILTER( ALL('Product'),
( 'Product'[Color] = "Red" && Product[Product Category Name] = "Accessories" )
|| ( 'Product'[Color] = "Blue" && Product[Product Category Name] = "Bikes" )
|| ( 'Product'[Color] = "Black" && Product[Product Category Name] = "Clothing" )
)
)
Con el nuevo operador IN , la expresión de medida anterior ahora es equivalente a la siguiente:
Filtered Sales:=CALCULATE (
[Internet Total Sales],
FILTER( ALL('Product'),
('Product'[Color], Product[Product Category Name]) IN
{ ( "Red", "Accessories" ), ( "Blue", "Bikes" ), ( "Black", "Clothing" ) }
)
)
Además de todas las nuevas características, Analysis Services, SSDT y SSMS también incluyen las siguientes mejoras:
Las siguientes características están en desuso en esta versión:
| Modo o categoría | Característica |
|---|---|
| Multidimensional | Minería de datos |
| Multidimensional | Grupos de medida vinculados remotos |
| Tabular | Modelos en el nivel de compatibilidad 1100 y 1103 |
| Tabular | Propiedades del modelo de objetos tabulares: Column.TableDetailPosition, Column.IsDefaultLabel, Column.IsDefaultImage |
| Herramientas | SQL Server Profiler para captura de seguimiento La sustitución es usar el Generador de perfiles de eventos extendidos integrado en SQL Server Management Studio. Consulte Monitor Analysis Services with SQL Server Extended Events. |
| Herramientas | Server Profiler para reproducción de seguimiento Sustitución. No hay ningún sustituto. |
| Objetos de administración de seguimiento y API de seguimiento | Objetos de Microsoft.AnalysisServices.Trace (contiene las API para los objetos Trace y Replay de Analysis Services). La sustitución abarca varias partes: - Configuración de seguimiento: Microsoft.SqlServer.Management.XEvent - Lectura de seguimiento: Microsoft.SqlServer.XEvent.Linq - Trace Replay: None |
En esta versión se descontinuan las siguientes características:
| Modo o categoría | Característica |
|---|---|
| Tabular | Valor de la propiedad de memoria VertiPaqPagingPolicy (2), habilite la paginación en el disco mediante archivos asignados de memoria. |
| Multidimensional | Particiones remotas |
| Multidimensional | Grupos de medida vinculados remotos |
| Multidimensional | Reescritura de dimensiones |
| Multidimensional | Dimensiones vinculadas |
No hay cambios importantes en esta versión.
Cambios en MDSCHEMA_MEASUREGROUP_DIMENSIONS y DISCOVER_CALC_DEPENDENCY, detallados en el anuncio novedades de SQL Server 2017 CTP 2.1 para Analysis Services.
SQL Server 2016 Analysis Services incluye muchas mejoras nuevas que proporcionan un rendimiento mejorado, creación de soluciones más sencilla, administración automatizada de bases de datos, relaciones mejoradas con filtrado cruzado bidireccional, procesamiento de particiones paralelas y mucho más. En el centro de la mayoría de las mejoras de esta versión se encuentra el nuevo nivel de compatibilidad 1200 para bases de datos de modelo tabular.
SQL Server 2016 Service SP1 Analysis Services proporciona un rendimiento y una escalabilidad mejorados gracias al reconocimiento de Non-Uniform Memory Access (NUMA) y la asignación de memoria optimizada basada en Intel Threading Building Blocks (Intel TBB). Esta nueva funcionalidad ayuda a reducir el costo total de propiedad (TCO) dando cabida a más usuarios en menos servidores empresariales, pero más eficaces.
En concreto, SQL Server 2016 SP1 Analysis Services incluye mejoras en estas áreas principales:
Las pruebas de rendimiento y de escalabilidad muestran unas mejoras considerables en el rendimiento de las consultas al ejecutar SQL Server 2016 SP1 Analysis Services en servidores empresariales de varios nodos.
Aunque la mayoría de las mejoras de esta versión son específicas de los modelos tabulares, también se han realizado varias mejoras en los modelos multidimensionales, como la optimización ROLAP de recuento distintivo para orígenes de datos como DB2 y Oracle, la compatibilidad de selección múltiple detallada con Excel 2016 y las optimizaciones de consultas de Excel.
En el caso de los modelos tabulares 1200, las operaciones de metadatos en SSDT son mucho más rápidas que los modelos tabulares 1100 o 1103. Si se compara, en el mismo hardware, la creación de una relación en un modelo establecido en el nivel de compatibilidad de SQL Server 2014 (1103) con 23 tablas tarda 3 segundos, mientras que la misma relación en un modelo creado que se ha establecido en el nivel de compatibilidad 1200 tarda menos de un segundo.
Con esta versión, ya no necesita dos versiones de SSDT para generar proyectos BI y relacionales. SQL Server Data Tools para Visual Studio 2015 agrega plantillas de proyecto para soluciones de Analysis Services, incluidos los proyectos tabulares de Analysis Services usados para la creación de modelos en el nivel de compatibilidad 1200. También se incluyen otras plantillas de proyecto de Analysis Services para soluciones de minería de datos y multidimensionales, pero en el mismo nivel funcional (1100 o 1103) que en versiones anteriores.
Ahora hay disponibles carpetas para mostrar para los modelos tabulares 1200. Definidas en SQL Server Data Tools y representadas en aplicaciones cliente como Excel o Power BI Desktop, las carpetas de visualización ayudan organizar grandes cantidades de medidas en carpetas individuales y agregan una jerarquía visual para explorar más fácilmente las listas de campos.
Como novedad de esta versión se ha introducido un enfoque integrado para permitir los filtros cruzados bidireccionales en los modelos tabulares, lo que elimina la necesidad de usar soluciones DAX manuales para propagar el contexto de filtro en las relaciones entre tablas. Los filtros solo se generan automáticamente cuando la dirección se puede establecer con un alto grado de certeza. Si hay ambigüedad en el formulario de varias rutas de consultas en relaciones de tabla, no se creará automáticamente un filtro. Vea Filtros cruzados bidireccionales para modelos tabulares en SQL Server 2016 Analysis Services para obtener más información.
Ahora puede almacenar metadatos traducidos en un modelo tabular 1200. Los metadatos del modelo incluyen campos para Culture, títulos traducidos y descripciones traducidas. Para agregar traducciones, use el comando Model>Translations en SQL Server Data Tools. Consulte Traducciones en modelos tabulares (Analysis Services) para obtener más información.
Ahora es posible actualizar un modelo tabular 1100 o 1103 a 1200 cuando el modelo contiene tablas pegadas. Se recomienda usar SQL Server Data Tools. En SSDT, establezca CompatibilityLevel en 1200 y, a continuación, implemente en una instancia de SQL Server 2017 de SQL Server Analysis Services. Para obtener información detallada, vea Compatibility Level for Tabular models in Analysis Services .
Una tabla calculada es una construcción de solo modelo basada en una consulta o una expresión de DAX en SSDT. Cuando se implementa en una base de datos, una tabla calculada no se distingue de las tablas normales.
Existen varios usos para las tablas calculadas, incluida la creación de nuevas tablas para exponer una tabla existente en un rol específico. El ejemplo clásico es una tabla de fechas que funciona en varios contextos (fecha de pedido, fecha de envío etc.). Mediante la creación de una tabla calculada para un rol determinado, ahora puede activar una relación de tabla para facilitar la interacción de datos o consultas con la tabla calculada. Otro uso de las tablas calculadas es combinar partes de las tablas existentes en una tabla completamente nueva que solo existe en el modelo. Consulte Creación de una tabla calculada para obtener más información.
Con la corrección de fórmulas en un modelo tabular 1200, SSDT actualizará automáticamente las medidas que hacen referencia a una columna o tabla cuyo nombre se ha cambiado.
Para admitir varios entornos, como entornos de preproducción y prueba, Visual Studio permite a los desarrolladores crear varias configuraciones de proyecto con el administrador de configuración. Los modelos multidimensionales ya aprovechan esto, pero los modelos tabulares no lo hacían. Con esta versión, ahora puede usar el administrador de configuración para realizar la implementación en servidores diferentes.
En esta versión, una instancia de Analysis Services en el modo de servidor tabular puede ejecutar modelos tabulares en cualquier nivel de compatibilidad (1100, 1103 y 1200). La última versión de SQL Server Management Studio se ha actualizado para mostrar las propiedades y proporcionar la administración del modelo de base de datos para los modelos tabulares en el nivel de compatibilidad 1200.
Esta versión incluye una nueva funcionalidad para el procesamiento en paralelo de las tablas con dos o más particiones, lo que aumenta el rendimiento del procesamiento. No hay valores de configuración para esta característica. Para obtener más información sobre cómo configurar particiones y tablas de procesamiento, vea Particiones de modelo tabulares.
SQL Server Analysis Services administradores ahora pueden usar SQL Server Management Studio para configurar cuentas de equipo para que sean miembros del grupo de administradores de SQL Server Analysis Services. En el cuadro de diálogo Seleccionar usuarios o grupos, establezca Ubicaciones para el dominio de equipos y, a continuación, agregue el tipo de objeto Equipos. Para más información, consulte Concesión de derechos de administrador de servidor a una instancia de Analysis Services.
DBCC (Database Consistency Checker, comprobador de coherencia de base de datos) se ejecuta internamente para detectar posibles problemas de errores de datos en la base de datos de carga, pero también se puede ejecutar a petición si sospecha que hay problemas en los datos o el modelo. DBCC ejecuta comprobaciones diferentes dependiendo de si el modelo es tabular o multidimensional. Consulte Comprobador de coherencia de base de datos (DBCC) para bases de datos tabulares y multidimensionales de Analysis Services para obtener más información.
Esta versión agrega una interfaz gráfica de usuario para SQL Server Management Studio configurar y administrar eventos extendidos SQL Server Analysis Services. Puede configurar los flujos de datos en directo para supervisar la actividad del servidor en tiempo real, mantener los datos de sesión cargados en memoria para un análisis más rápido o guardar flujos de datos en un archivo para un análisis sin conexión. Para más información, vea Supervisar Analysis Services con SQL Server Extended Events.
En esta versión se han incluido mejoras de PowerShell para los modelos tabulares en el nivel de compatibilidad 1200. Puede usar todos los cmdlets aplicables y, además, cmdlets específicos del modo tabular, como Invoke ProcessASDatabase y el cmdlet Invoke-ProcessTable.
En la última versión de SQL Server Management Studio (SSMS), el script está ahora habilitado para los comandos de base de datos, que incluyen Create, Alter, Delete, Backup, Restore, Attach y Detach. El resultado es TMSL (Tabular Model Scripting Language, lenguaje de scripting del modelo tabular) en JSON. Consulte Tabular Model Scripting Language (TMSL) Reference (Referencia del lenguaje de scripting de modelos tabulares [TMSL]) para obtener más información.
Latarea Ejecutar DDL de Analysis Services ahora acepta también los comandos de Tabular Model Scripting Language (TMSL).
El cmdlet de PowerShell de SSAS Invoke-ASCmd ahora acepta comandos de Tabular Model Scripting Language (TMSL). Los demás cmdlets de PowerShell de SSAS podrían actualizarse en una versión futura para usar los nuevos metadatos tabulares (las excepciones se indicarán en las notas de la versión). Para obtener información detallada, vea Analysis Services PowerShell Reference .
Con la versión más reciente de SSMS, ahora puede crear scripts para automatizar la mayoría de las tareas administrativas para los modelos tabulares 1200. Actualmente, se pueden crear scripts de las siguientes tareas: proceso en cualquier nivel, además de los comandos CREATE, ALTER y DELETE en el nivel de base de datos.
Funcionalmente, TMSL es equivalente a la extensión ASSL de XMLA que proporciona las definiciones de objetos multidimensionales, salvo que TMSL usa descriptores como model, tabley relationship para describir los metadatos tabulares. Consulte Tabular Model Scripting Language (TMSL) Reference (Referencia del lenguaje de scripting de modelos tabulares [TMSL]) para obtener más información sobre el esquema.
Un script basado en JSON generado para un modelo tabular podría ser similar al siguiente:
{
"create": {
"database": {
"name": "AdventureWorksTabular1200",
"id": "AdventureWorksTabular1200",
"compatibilityLevel": 1200,
"readWriteMode": "readWrite",
"model": {}
}
}
}
La carga es un documento JSON que puede ser tan mínimo como el ejemplo anterior o muy embellecido con el conjunto completo de definiciones de objeto. La referencia del lenguaje de scripting de modelos tabulares (TMSL) describe la sintaxis.
En el nivel de base de datos, los comandos CREATE, ALTER y DELETE darán como resultado un script de TMSL en la ventana de XMLA familiar. Otros comandos, como PROCESS, también pueden incluirse en scripts en esta versión. En una versión futura podría agregarse compatibilidad con scripts para muchas otras acciones.
| Comandos con scripts | Descripción |
|---|---|
| create | Permite agregar una base de datos, conexión o partición. El equivalente de ASSL es CREATE. |
| createOrReplace | Permite actualizar una definición de objeto existente (base de datos, conexión o partición) sobrescribiendo una versión anterior. El equivalente de ASSL es ALTER con AllowOverwrite establecido en true y ObjectDefinition en ExpandFull. |
| eliminar | Permite quitar una definición de objeto. El equivalente de ASSL es DELETE. |
| actualizar | Procesa el objeto. El equivalente de ASSL es PROCESS. |
Novedades a la barra de fórmulas le ayudará a escribir fórmulas con más facilidad mediante la diferenciación de funciones, campos y medidas mediante el color de sintaxis, proporciona sugerencias inteligentes de función y campo y le indica si las partes de la expresión DAX están mal usando subrayados ondulados de error. También permite usar varias líneas (Alt + Entrar) y sangría (Tabulador). La barra de fórmulas ahora también le permite escribir comentarios como parte de las medidas, solo tiene que escribir "//" y todo después de estos caracteres en la misma línea se considerará un comentario.
En esta versión se incluye compatibilidad con variables en DAX. Ahora, las variables pueden almacenar el resultado de una expresión como una variable con nombre, que se pasa después como argumento a otras expresiones de medida. Una vez que se han calculado los valores resultantes de una expresión variable, esos valores no cambian, aunque se haga referencia a la variable en otra expresión. Para obtener más información, vea Función VAR.
Con esta versión, DAX presenta más de cincuenta funciones nuevas para admitir cálculos más rápidos y visualizaciones mejoradas en Power BI. Para obtener más información, vea New DAX Functions(Funciones DAX nuevas).
Ahora puede guardar las medidas DAX incompletas directamente en un proyecto del modelo tabular 1200 y seleccionarlo de nuevo cuando esté listo para continuar.
Los objetos de administración de Analysis Services (AMO) se actualizan para incluir un nuevo espacio de nombres tabular para administrar una instancia del modo tabular de SQL Server 2016 Analysis Services y para proporcionar el lenguaje de definición de datos para la creación o la modificación de modelos tabulares 1200 mediante programación. Visite Microsoft.AnalysisServices.Tabular para obtener información sobre la API.
Analysis Services Management Objects (AMO) se ha vuelto a factorizar para incluir un segundo ensamblado, Microsoft.AnalysisServices.Core.dll. El nuevo ensamblado separa las clases comunes como el servidor, la base de datos y la función que tienen una amplia aplicación en Analysis Services, independientemente del modo de servidor. Anteriormente, estas clases formaban parte del ensamblado Microsoft.AnalysisServices original. Moverlos a un nuevo ensamblado prepara el terreno para futuras ampliaciones a AMO, con una división clara entre las API genéricas y específicas del contexto. Las aplicaciones existentes no se ven afectadas por los nuevos ensamblados. Sin embargo, si decide volver a generar aplicaciones con el nuevo ensamblado AMO por cualquier motivo, asegúrese de agregar una referencia a Microsoft.AnalysisServices.Core. De forma similar, los scripts de PowerShell que cargan y llaman a AMO deben cargar ahora Microsoft.AnalysisServices.Core.dll. Asegúrese de actualizar los scripts.
La vista Código en Visual Studio 2015 ahora representa el archivo BIM en formato JSON para los modelos tabulares 1200. La versión de Visual Studio determina si el archivo BIM se representa en JSON a través del editor JSON integrado o como texto simple.
Para usar el editor JSON, con la capacidad de expandir y contraer secciones del modelo, necesitará la versión más reciente de SQL Server Data Tools y Visual Studio 2015 (cualquier edición, incluida la edición Community gratis). Para las demás versiones de SSDT o Visual Studio, el archivo BIM se representa en JSON como texto simple. Como mínimo, un modelo vacío contendrá el siguiente código JSON:
{
"name": "SemanticModel",
"id": "SemanticModel",
"compatibilityLevel": 1200,
"readWriteMode": "readWrite",
"model": {}
}
Advertencia
Evite la edición directa de JSON. Esto puede dañar el modelo.
Se han agregado los siguientes elementos al tipo complejo TProperty definido en el esquema de [MS-CSDLBI] 2.0:
| Elemento | Definición |
|---|---|
| DefaultValue | Una propiedad que especifica el valor usado al evaluar la consulta. La propiedad DefaultValue es opcional, pero se selecciona automáticamente si no se pueden agregar los valores del miembro. |
| Estadísticas | Un conjunto de estadísticas de los datos subyacentes que está asociado a la columna. Estas estadísticas se definen mediante el tipo complejo de TPropertyStatistics y se proporcionan solo si su generación no es cara a nivel computacional, como se describe en la sección 2.1.13.5 del formato de archivo de definición del esquema conceptual con el documento de anotaciones de Business Intelligence. |
En esta versión se incluyen mejoras considerables en DirectQuery para los modelos tabulares 1200. A continuación, se muestra un resumen:
Los orígenes de datos admitidos para los modelos tabulares 1200 en modo DirectQuery ahora incluyen Oracle, Teradata y Microsoft Analytics Platform (anteriormente conocido como Parallel Data Warehouse). Para más información, consulte Modo DirectQuery.
Las siguientes características están en desuso en esta versión:
| Modo/Categoría | Característica |
|---|---|
| Multidimensional | Particiones remotas |
| Multidimensional | Grupos de medida vinculados remotos |
| Multidimensional | Reescritura de dimensiones |
| Multidimensional | Dimensiones vinculadas |
| Multidimensional | Notificaciones de tabla de SQL Server para almacenamiento en caché automático. Lo que se va a sustituir es el uso del sondeo por el almacenamiento en caché automático. Consulte Almacenamiento en caché automático (dimensiones) y Almacenamiento en caché automático (particiones). |
| Multidimensional | Cubos de sesión. No hay ningún sustituto. |
| Multidimensional | Cubos locales. No hay ningún sustituto. |
| Tabular | Los niveles de compatibilidad 1100 y 1103 del modelo tabular no se admitirán en futuras versiones. El reemplazo consiste en establecer modelos en el nivel de compatibilidad 1200 o superior, convirtiendo las definiciones de modelo en metadatos tabulares. Consulte Compatibility Level for Tabular models in Analysis Services. |
| Herramientas | SQL Server Profiler para captura de seguimiento La sustitución es usar el Generador de perfiles de eventos extendidos integrado en SQL Server Management Studio. Consulte Monitor Analysis Services with SQL Server Extended Events. |
| Herramientas | Server Profiler para reproducción de seguimiento Sustitución. No hay ningún sustituto. |
| Objetos de administración de seguimiento y API de seguimiento | Objetos de Microsoft.AnalysisServices.Trace (contiene las API para los objetos Trace y Replay de Analysis Services). La sustitución abarca varias partes: - Configuración de seguimiento: Microsoft.SqlServer.Management.XEvent - Lectura de seguimiento: Microsoft.SqlServer.XEvent.Linq - Reproducción de seguimiento: Ninguno |
En esta versión se descontinuan las siguientes características:
| Característica | Sustitución o solución alternativa |
|---|---|
| CalculationPassValue (MDX) | Ninguno. Esta característica ha quedado obsoleta en SQL Server 2005. |
| CalculationCurrentPass (MDX) | Ninguno. Esta característica ha quedado obsoleta en SQL Server 2005. |
| Sugerencia del optimizador de consultas NON_EMPTY_BEHAVIOR | Ninguno. Esta característica ha quedado obsoleta en SQL Server 2008. |
| Ensamblados COM | Ninguno. Esta característica ha quedado obsoleta en SQL Server 2008. |
| Propiedad de celda intrínseca CELL_EVALUATION_LIST | Ninguno. Esta característica ha quedado obsoleta en SQL Server 2005. |
Los objetos de administración de Analysis Services (AMO), ADOMD.NET y las bibliotecas cliente del modelo de objetos tabulares (TOM) ahora tienen como destino el entorno de ejecución de .NET 4.0. Esto puede ser un cambio importante para las aplicaciones que tienen como destino .NET 3.5. Las aplicaciones que usan versiones más recientes de estos ensamblados ahora deben tener como destino .NET 4.0 o versiones posteriores.
Esta versión es una actualización de versión para Objetos de administración de Analysis Services (AMO) y es un cambio importante en determinadas circunstancias. Los scripts y el código existentes que llaman a AMO seguirán ejecutándose como antes si actualiza desde una versión anterior. Sin embargo, si necesita volver a compilar la aplicación y tiene como destino una instancia de SQL Server 2016 Analysis Services, debe agregar el siguiente espacio de nombres para que el código o el script estén operativos:
using Microsoft.AnalysisServices;
using Microsoft.AnalysisServices.Core;
El espacio de nombres Microsoft.AnalysisServices.Core ahora es necesario cada vez que se hace referencia al ensamblado Microsoft.AnalysisServices en el código. Los objetos que anteriormente solo se encontraban en el espacio de nombres Microsoft.AnalysisServices se mueven al espacio de nombres principal en esta versión si el objeto se usa de la misma forma en los escenarios tabulares y multidimensionales. Por ejemplo, las API relacionadas con el servidor se reubican en el espacio de nombres principal.
Aunque ahora hay varios espacios de nombres, ambos existen en el mismo ensamblado (Microsoft.AnalysisServices.dll).
Para admitir mejor el streaming XEvent DISCOVER en SSMS para SQL Server 2016 Analysis Services, DISCOVER_XEVENT_TRACE_DEFINITION se reemplaza por los seguimientos XEvent siguientes:
DISCOVER_XEVENT_PACKAGES
DISCOVER_XEVENT_OBJECT
DISCOVER_XEVENT_OBJECT_COLUMNS
DISCOVER_XEVENT_SESSION_TARGETS
Ya no se requiere la ejecución del Asistente para configuración de PowerPivot como tarea posterior a la instalación. Esto es cierto para todas las versiones compatibles de SharePoint que cargan modelos del SQL Server 2016 Analysis Services actual.
DirectQuery es un modo de acceso a datos para los modelos tabulares, donde se realiza la ejecución de la consulta en una base de datos relacional de back-end y se recupera un conjunto de resultados en tiempo real. A menudo se usa para grandes conjuntos de datos que no caben en la memoria o cuando los datos son volátiles y quiere que los datos más recientes se devuelvan en las consultas en un modelo tabular.
DirectQuery ha existido como un modo de acceso a datos en las últimas versiones. En SQL Server 2016 Analysis Services, la implementación se ha revisado ligeramente, suponiendo que el modelo tabular está en el nivel de compatibilidad 1200 o superior. DirectQuery tiene menos restricciones que antes. También tiene propiedades de base de datos diferentes.
Si usa DirectQuery en un modelo tabular existente, puede mantener el modelo en su nivel actual de compatibilidad de 1100 o 1103 y seguir usando DirectQuery implementado para esos niveles. Como alternativa, puede actualizar a 1200 o superior para beneficiarse de las mejoras realizadas en DirectQuery.
No hay ninguna actualización local de un modelo de DirectQuery porque la configuración de los niveles de compatibilidad anteriores no tiene equivalentes exactos en los niveles de compatibilidad más recientes de 1200 y superiores. Si tiene un modelo tabular existente que se ejecuta en modo DirectQuery, debe abrir el modelo en SQL Server Data Tools, desactivar DirectQuery, establecer la propiedad Nivel de compatibilidad en 1200 o superior y, a continuación, volver a configurar las propiedades de DirectQuery. Consulte DirectQuery Mode (Modo DirectQuery ) para obtener más información.
Una característica en desuso se interrumpirá del producto en una versión futura, pero todavía se admite e incluye en la versión actual para mantener la compatibilidad con versiones anteriores. Se recomienda dejar de usar características en desuso en proyectos nuevos y existentes para mantener la compatibilidad con versiones futuras. La documentación no se actualiza para las características en desuso.
Una característica descontinuada ha quedado en desuso en una versión anterior. Puede seguir incluyendo en la versión actual, pero ya no se admite. Las características descontinuadas se pueden quitar completamente en la versión indicada o futura.
Un cambio importante hace que una característica, el modelo de datos, el código de aplicación o el script ya no funcionen después de actualizar a la versión actual.
Un cambio de comportamiento afecta al funcionamiento de la misma característica en la versión actual en comparación con la versión anterior. Solo se describen cambios de comportamiento significativos. No se incluyen los cambios en la interfaz de usuario. Los cambios en los valores predeterminados, la configuración manual necesaria para completar una funcionalidad de actualización o restauración, o una nueva implementación de una característica existente son ejemplos de un cambio de comportamiento.
Eventos
31 mar, 23 - 2 abr, 23
Evento de aprendizaje de Fabric, Power BI y SQL más grande. 31 de marzo – 2 de abril. Use el código FABINSIDER para ahorrar $400.
Regístrate hoyCursos
Ruta de aprendizaje
Use advance techniques in canvas apps to perform custom updates and optimization - Training
Use advance techniques in canvas apps to perform custom updates and optimization
Certificación
Microsoft Certified: Power BI Data Analyst Associate - Certifications
Demostrar métodos y procedimientos recomendados que se alinean con los requisitos empresariales y técnicos para modelar, visualizar y analizar datos con Microsoft Power BI.
Documentación
Describe las tres plataformas de Analysis Services.
Comparación de modelos tabulares y multidimensionales de Analysis Services
Describe las diferencias entre las soluciones de modelos tabulares y multidimensionales de Analysis Services.
Características de Analysis Services compatibles con SQL Server edición
Obtenga información sobre las características compatibles con diferentes ediciones de SQL Server 2016, 2017, 2019 Analysis Services.