[Visual C++ 2010][Concurrency Runtime]Introduction au Concurrency Runtime
Les deux offres parallèles de Visual Studio 2010, native et .NET, reposent sur des socles techniques permettant de tirer parti des processeurs/cœurs avec une grande efficacité: un Concurrency runtime. J'ai préféré l'illustration de l'offre native car elle dispose d'une architecture extensible que ne propose pas l’actuelle offre .NET. Cependant sur le plan des concepts les deux offres partagent de nombreux points communs.
Introduction
Une nouvelle offre parallèle pour les développeurs C++ arrive avec Visual Studio 2010. Contrairement à l'offre .NET, celle-ci n'avait jamais été dévoilée auparavant. Néanmoins, à l'instar de la version .NET, celle-ci expose aussi un ensemble de librairies de haut niveau permettant de paralléliser des applications très facilement avec d'excellentes performances.

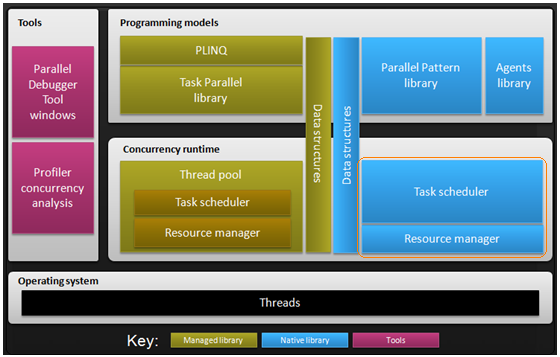
Figure 1: Plateforme d’exécution parallèle, librairies et outils de Visual Studio 2010: en bleu l'offre C++
Sur la figure 1, dans les éléments en bleu on distingue essentiellement deux librairies (Parallele Pattern Library et Asynchronous Agents Library), et un ensemble de structures de données (Data structures) dédié à la synchronisation et enfin l'outillage en mauve permettant de gérer plus facilement les problèmes de synchronisation inter-threads (débogueur et profileur mutualisés avec l'offre .NET):
Parallele Pattern Library (PPL)
PPL permet de simplifier le développement d’applications parallèles en élevant le niveau d’abstraction et en fournissant des alternatives aux partages d’états. Par exemple on ne parle plus de threads, mais de tâches (task_handle) afin de gagner un pouvoir sémantique sur les traitements. L'exécution des tâches passe pas un groupe de tâches (task_group) permettant de les exécuter, de les attendre ou de les abandonner:
· task_handle
· task_group
Elle offre aussi des algorithmes permettant de paralléliser des données très facilement sans avoir besoin de manipuler des tâches (cependant les tâches sont toujours présentes):
· parallel_for
· parallel_for_each
· parallel_invoke
· parallel_accumulate
Data Structure (DS)
DS permet de gérer le partage d'états plus facilement en offrant des collections adaptées pour résister aux problèmes de concurrences:
· concurrent_queue
· concurrent_vector
· concurrent_unordered _map
· combinable
Elle apporte des nouveaux verrous et outils de synchronisation plus économiques sur le plan des ressources système que ceux de la plateforme Win32:
- reader_writer_lock
- critical_section
- Event
Asynchronous Agents Library
La librairie Agent offre une alternative pour des applications ayants des difficultés maitriser leurs états internes vis à vis d'un passage au mode parallèle. La classe agent (agent) permet d'isoler son code du monde extérieur en communiquant exclusivement en asynchrone via des messages de type queue (unbounded_buffer<T> ) ou bien valeurs (overwrite_buffer<T>) où la donnée transmise est clonée lorsqu'elle est consommée :
· unbounded_buffer<T>
· overwrite_buffer<T>
· la prochaine CTP de VS2010 apportera d’autres types.
De plus cette librairie permet de construire des réseaux de communications asynchrones en combinant des bloques prédéfinis ou personnalisés par vos soins. Par exemple on peut souhaiter adapter les données au vol via des transformations (transform<T1, T2>) ou bien appeler directement une fonction call<T>
:
· transform<T1, T2>
· call<T>
· la prochaine CTP de VS2010 apportera d’autres bloques asynchrones.
Aux extrémités des réseaux, on trouve des primitives pour envoyer (send) et recevoir (receive) des messages:
· send
· receive
Pour que la magie de ces librairies s'exerce, un moteur d'exécution chargé de gérer les soubassements de l'infrastructure de l'offre parallèle (la partie bleue cerclée en orange sur la figure 1) permet de répondre aux besoins les plus courants dans la mise en place de codes parallèles dans une application C++. En d'autres termes, le moteur d'exécution de l'offre parallèle C++ constitue un élément clef de cette offre.
Motivation
Pourquoi un Concurrency Runtime ? Sans doute pour éviter que chacun ait besoin de réinventer la roue. En d'autres mots, il serait envisageable de laisser les développeurs implémenter une solution d'abstraction permettant de s'affranchir de créer des threads directement ou gérer la politique d'ordonnancement par eux-mêmes, mais ceci ne permettrait pas de tirer le marché des développeurs C++ vers du code parallèle rapidement. Néanmoins, il est légitime d'imaginer qu'une société puisse apporter sa propre politique de threading pour des raisons parfaitement justifiées. L'objectif du Concurrency runtime est de fournir une infrastructure de base solide, performante et ouverte afin de rendre accessible la programmation parallèle depuis de nombreuses librairies: comme par exemple s'assurer que l'occupation des processeurs est maximisée. Mais on peut aussi souhaiter que le nombre d'aller-retour soit minimalisé entre le mode noyau et le mode utilisateur. La révolution matérielle est déjà en marche, et les prochaines années seront marquées par une croissance importante du nombre de processeurs sur des machines bon marché et le Concurrency Runtime permettra à de nombreux développeurs d'en tirer avantage.

Figure 2: L'offre Intel Parallel Studio tirant avantage du Concurrency runtime
Ce moteur d'exécution est donc une pièce maitresse pour garantir le succès de cette nouvelle offre qui a déjà séduit Intel en tant que partenaire Microsoft. Dans ce cadre, Intel a en Aout 2008, prévu l'adaptation de son offre parallèle C++ , Intel Parallel Studio tools, sur le Concurrency Runtime Microsoft. Les librairies Threading Building Blocks (TBB) et OpenMP Intel viendront s'intégrer au Concurrency Runtime côte à côte avec les librairies parallèles Microsoft. Cependant cette démarche n'est pas limitée aux sociétés du rang d'Intel. Cette personnalisation est parfaitement éligible pour toute société où les développeurs ont des besoins spécifiques justifiant d'une adaptation du Concurrency runtime. A l'instar du Runtime-C à son époque, le Concurrency runtime permet de réutiliser une infrastructure unifiée permettant des gains de productivité tout en étant personnalisable en fonction des cas d'utilisation. Sur la figure 2 ci-dessus, on note que les librairies Microsoft et celles d'Intel reposent sur une infrastructure commune. Le Concurrency Runtime est en réalité la composition de deux briques : Task Scheduler (ordonnanceur de tâches) et Resource Manager (gestionnaire dynamique des ressources cœurs /processeurs) qui assure à travers une collaboration efficace de bonnes performances vis à vis des librairies l'utilisant, laissant peu de place au hasard.
Comparatif des offres parallèles .NET & C++
L'offre parallèle C++ à l'instar de l'offre parallèle .NET repose aussi sur Concurrency runtime prenant en charge les politiques d'ordonnancement, l'implémentation d'une gestion de threads en accord avec le nombre de processeurs disponibles. Peut être êtes vous en train de vous demander pourquoi les deux offres n'ont pas mutualisé leur moteur d’exécution concurrent ? Même si toutes les deux offrent des partages des besoins communs, les deux technologies sont radicalement différentes sur le plan de l'exécution. Imaginons que l'offre .NET repose sur la version native du moteur d'exécution parallèle, nous serions sans doute déçu par les performances générales des codes parallélisés, conséquence directe des aller-retour entre le code géré et le code natif (coût d'un marshalling excessif). Néanmoins, les équipes concernées sont parfaitement conscientes des mutualisations envisageables à plus ou moins long terme, mais pour l'instant les moteurs d'exécution parallèle resteront distincts.
Resource Manager
Le Resource Manager est un gestionnaire dynamique des ressources de cœurs/processeurs. En réalité il porte une intention extrêmement simple: servir l'accès aux processeurs aux différentes instances de l’ordonnanceur de tâches (Task Scheduler) tout en optimisant la répartition physique en fonction des processeurs disponibles afin de favoriser et d’assurer l'occupation effective des processeurs tout en favorisant l'optimisation des caches. Le principe est le suivant : une instance de l’ordonnanceur réclame un certains critères d’exécution (via la classe SchedulerPolicy) comme le nombre de processeurs au Resource Manager (cette demande provient indirectement d'une librairie PPL, TBB ...), de son côté, en fonction des processeurs/cœurs disponibles, le Resource Manager va tenter de satisfaire la demande de l'ordonnanceur sans connaitre la nature de l'ordonnanceur. Sur une architecture massivement parallèle, on peut imaginer une collection d'instances ordonnanceur sollicitant le Resource Manager pour satisfaire des demandes provenant de diverses librairies (il y a un Ressource Manager par processus système). Dans le cas où le Resource Manager ne peut complètement satisfaire la demande d'un ordonnanceur (le nombre de cœurs/processeurs disponibles est inférieur à la demande), la demande est conservée et une future réévaluation des ressources disponibles pourra le cas échéant compléter la demande initiale partiellement couverte.
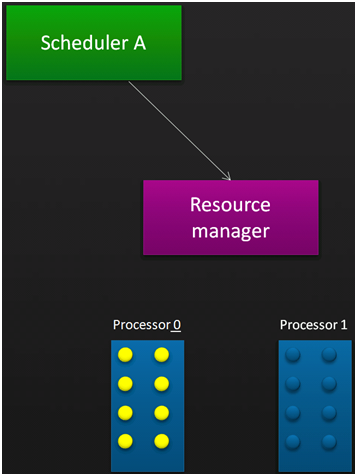
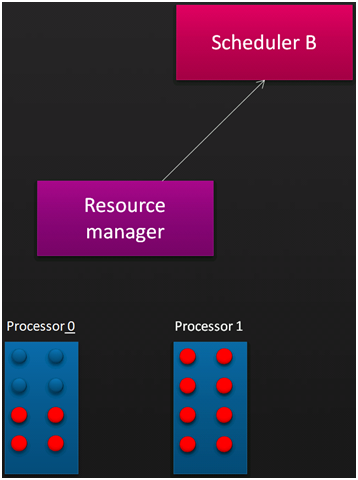
Pour comprendre le fonctionnement du Resource Manager reportez-vous aux images ci-dessous qui illustrent ce fonctionnement. Vous devez lire les schémas de gauche à droite, de haut en bas. Figure 3, un ordonnanceur A (SA) réclame 8 cœurs au Resource Manager qui lui attribue les 8 cœurs disponibles sur le processeur 0. Ainsi les traitements de SA pourront profiter du cache associé. Sur la figure 4, un deuxième ordonnanceur, SB, arrive et réclame 12 processeurs, mais seulement 8 cœurs sont disponibles. Le Resource Manager affecte les 8 cœurs restants à SB, mais mémorise la requête initiale. Sur la figure 5, après avoir évalué l'usage des cœurs par SA, le Resource Manager décide de réaffecter deux cœurs du processeur 0 à SB. Sur la figure 6, SA à disparu et le Resource Manager peut affecter à SB deux processeurs supplémentaires afin de compléter la demande initiale de SB.


Figure 3: SA réclame 8 cœurs Figure 4: SB réclame 12 cœurs


Figure 5: RM décide que SA est trop gourmand Figure 6: SB obtient 12 cœurs
Avec cette petite animation on comprend le rôle de médiateur du Resource Manager vis à vis des ordonnanceurs, apportant une répartition dynamique favorable à l'utilisation maximale des ressources et à d’excellentes performances.
Task Scheduler
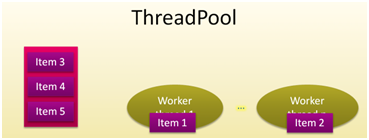
Au dessus du Resource Manager on trouve le Task Scheduler en charge des instances des ordonnanceurs. Son rôle est d'ordonnancer les tâches en assurant un équilibrage de charge optimisé. Contrairement au Resource Manager qui est unique par processus, nous pouvons disposer de plusieurs ordonnanceurs de tâches. Dans un premier temps, on peut résumer le rôle d'un ordonnanceur à celui d'un pool de threads. il prend les demandes de traitement puis les exécute via les threads de travail disponibles, sachant qu'en fonction des politiques d'ordonnancement déterminées à sa création il peut modifier son comportement par défaut. Par exemple un processus peut posséder plusieurs instances ordonnanceur de tâches afin d'adhérer au mieux aux stratégies de parallélisme des traitements en cours (nombre de cœurs réclamés, taille des piles, priorités des threads). Cependant, lorsqu’Intel intègre les librairies Open MP ou TBB via Intel Parallel Studio c'est à travers des ordonnanceurs personnalisés (et non une stratégie personnalisée) que l'intégration fonctionne. L'ordonnanceur de tâches assure une virtualisation des processeurs, mariant un thread de travail par cœur disponible. Dans un pool threads classique nous disposons d'une file d'attente globale qui réceptionne les items de demande de travail et les distribue aux threads de travail disponibles. Dans le schéma ci-dessous, figure 7, cinq items ont été insérés dans le pool de threads dont deux sont en cours d'exécution.

Figure 7: l'architecture classique du pool de threads
Pool de Threads revisité
Cette architecture (figure 7) n'est malheureusement pas optimale pour assurer des performances accrues face à la croissance du nombre de cœurs dans nos prochaines machines. L'unique file d'attente globale permet de réceptionner les demandes de traitement. Mais pour être traité chaque élément contenu dans la file doit être extrait pour être affecté à un thread de travail. Comme le pool de threads est utilisable depuis un environnement multithreads, chaque insertion ou retrait dans la file d'attente, gérée par un verrou global, créant du même coup un goulot d'étranglement. Dans cette architecture, on note deux problèmes sous-jacents:
· En cas d'affluence importante de nouvelles demandes dont la granularité serait très fine, le verrou global deviendrait rapidement un frein, car le nombre d’appels au verrou augmenterait de manière significative.
· L'évolution significative du nombre de cœurs dans les prochains ordinateurs entrainerait une distribution plus accrue pour la boucle de ventilation des items de travail (méthode Dispatch de l'ordonnanceur). L'appel systématique au verrou de la file globale, ralentirait la distribution des traitements sur les cœurs et pénaliserait l'utilisation effective de tous les cœurs.
Pour améliorer les performances du pool de threads standards quelques suggestions ont été proposées, comme la décentralisation des techniques de distribution des items de file d'attente globale afin de soulager l'usage du verrou. En associant chaque thread de travail à une file d'attente locale (sans verrou car confiné dans l'ordonnanceur donc inaccessible depuis les librairies), nous modifions significativement la technique de répartition des items tout en corrigeant le problème de goulot d'étranglement de la file d'attente globale. Un autre point d'amélioration proposé est le changement de la notion d’item de travail en la notion de tâche de travail, offrant une sémantique plus riche et permettant de corréler les tâches entre elles via leurs liens de filiation afin de les regrouper si possible dans la même file. Comme dans le pool de threads, les éléments entrants (ici des tâches) sont insérés dans la file d'attente globale, et ventilés dans l'ensemble des files d'attente associées aux threads de travail. Chaque thread de travail dépile (sans verrouiller de ressource) sa file d'attente au fur et à mesure que les traitements sont exécutés. Dans ce modèle, la fréquence de l'usage du verrou de file global n'est plus complètement corrélée avec la vitesse de traitement des threads de travail.
Comparatif des offres parallèles .NET & C++
Depuis l'annonce de la disponibilité de la première CTP de Visual Studio 2010, il n'y à plus de nouvelles librairies PFX compatibles avec Visual Studio 2008. Les raisons qui ont motivé ce choix sont relatives aux modifications apportées à la CLR 4.0 afin de rendre la gestion du pool thread compatible avec une architecture de file d'attente type « vol de travail » (work stealing queue) ce qui n'est pas le cas de le CLR 2.0.
Ordonnancement type vol de travail
En fonctionnement nominal la ventilation des traitements dans les files d'attentes se fait en fonction des affinités de filiation entre les tâches, afin que les caches des processeurs puissent éventuellement satisfaire plusieurs tâches successives. Le point essentiel qu'apporte cette nouvelle architecture est dans la capacité de rediriger une tâche d'une file locale à une autre file locale en fonction des taux d'occupation sans aucun verrouillage. En d'autres termes, lorsque la boucle de ventilation (méthode Dispatch) constate que la file d'attente courante n'a plus de travail en cours ou que sa file est vide, elle "vole du travail" à une autre file contentant des tâches en attente. Le retrait de la tâche se fait par le haut de la file concernée, puis elle est réaffectée au contexte de la file couramment analysée (la réalité est légèrement différente mais est sans influence pour la compréhension).
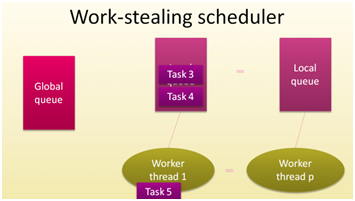
Pour illustrer l'orchestration du work-stealing, imaginons trois tâches dans la file de Worker Thread 1, les tâches 3 et 4 sont en attente alors que la 5 est en cours d'exécution (Figure 8 - 10). Le méthode de ventilation constate qu'il n'y plus rien à dépiler dans la file globale, mais pour améliorer les performances de l'ensemble, la tâche 3 est déplacée, ou "volée" de sa file d'origine, pour être distribuée au thread de travail disponible (Figure 3: image 3).

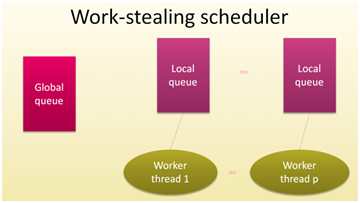
Figure 8: WT1 .. WTp sont disponibles

Figure 9: WP1 traite t5, WTp ne fait rien

Figure 10: Vole la tâche t3 de WT1 au profit de WTp
Ainsi l'élimination de l'usage intensif du verrou de la file globale accompagné de l'exploitation maximum des cœurs et des caches, apporte une réduction significative du temps d'exécution global des librairies clientes du Concurrency Runtime.
Structure de données du Scheduler Manager
Les structures de données du Scheduler Manager permettent de mieux appréhender le fonctionnement du Concurrency Runtime en action. La liste des contextes en haut de la figure 11, correspond à des contextes d'exécution disponibles (pile d'exécution ...). Plus bas, la liste des groupes d'ordonnanceurs (scheduler group) représentant une collection de regroupements de files d'attente de travail "volable". Ce regroupement est en réalité conditionné par le contexte applicatif et non par les librairies. L'objectif est de rapprocher les traitements communs dans un jeu de files d'attente dédié. Chaque groupe possède un contexte d'exécution. Chaque contexte est lié à un processeur virtuel retourné par le Ressource Manager.

Figure 11: Structures de données du Schéduler Manager
Supposons qu'un contexte d'exécution bloque en mode noyau (latence d'un périphérique système par exemple) au détriment de l'exécution globale, celui-ci est désaffecté à la fois de son groupe d'ordonnancement et de son processeur virtuel respectif au profit du contexte d'exécution et retiré de la liste des contextes disponibles; dans ce cas une nouvelle boucle de ventilation des unités de travail (méthode Dispatch) débute pour traiter ce nouveau contexte. Le Sheduler Manager adhère automatiquement aux éventuelles attentes passives des contextes, favorisant l'exécution des traitements. Lorsque la ventilation des unités de travail est terminée au sein d'un groupe d'ordonnancement, la ventilation passe au groupe suivant et ainsi de suite.
Structure de données d'un groupe d'ordonnancement
Au sein d'un groupe d'ordonnancement nous retrouvons des éléments déjà connus comme les contextes d'exécution, ici nous avons une liste de contextes revenus du mode noyau et à nouveau disponibles, c'est à dire prêt à être exécutés. Pour des raisons d'optimisation, le Task Scheduler laisse toujours se terminer les contextes courants avant de réélire les contextes débloqués en attente, ainsi on évite des changements ou des recopies mémoire souvent sources de ralentissements et de consommation mémoire excessive. Une file logique des tâches à traiter mais concrètement ces tâches sont ventilées dans les files d'attente du groupe. Ici nous avons trois files d'attentes de type "vol de travail".
Windows 7 et l'offre parallèle C++
Dans le cadre de l'implémentation d'un Ressource Manager natif efficace, l'équipe Windows travaille conjointement avec les équipes « parallèle » afin de fournir un prochain système d'exploitation parfaitement en adhérence avec les besoins des offres parallèles. C'est dans ce cadre que le coût de va et vient d'un bloc d'exécution entre le noyau et le mode utilisateur à été optimisé dans le noyau Windows 7.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 12: Structures de données interne d'un groupe d'ordonnancement
Boucle de Ventilation
Nous avons souvent évoqué la boucle de ventilation dans les paragraphes précédents sans jamais la détailler. Pour illustrer sont fonctionnent vous trouverez à la figure 13 un pseudo code naïf de la boucle de ventilation. La boucle de ventilation est en réalité l'agrégation d'une composition de sous boucles. Depuis la super boucle où l'on tourne indéfiniment tant que l'ordonnanceur respectif est présent. Dans la boucle sous-jacente où l'on itère sur la liste des groupes d'ordonnancement (figure 11). Chaque groupe contient une suite de files d'attente qui est unitairement itérée via une boucle associée:
- File des contextes disponibles (GetUnblockedWork()) qui apparait sur la figure 12 (unblocked contexts). En d'autres termes, on termine tous les travaux en cours avant de passer à la suite afin de faire des économies de mémoire et d'éviter d'introduire des latences inutiles.
- File des tâches en attente des nouveaux travaux (GetNewWork()), qui apparait dans sur la figure 12 (FIFO tasks),
HRESULT Dispatch(IThreadProxy *pProxy) {
bool stop = false;
while( !stop ) {
for each (group in groups) {
bool foundSomething = false;
do {
while (Task *tsk = group->GetUnblockedWork() != NULL)
{ tsk->Run(); foundSomething = true; }
while (Task *tsk = group->GetNewWork())
{ tsk->Run(); foundSomething = true; }
while (Chore *chre = group->Steal() != NULL)
{ chre->Run(); foundSomething = true; }
} while (foundSomething);
}
stop = WaitForMoreWork();
}
}
Figure 13: pseudo code naïf de la boucle de ventilation
Notons que ce code n'adhère pas complètement à la réalité du code source de la méthode Dispatch(), mais il permet de mieux appréhender le principe d'un pool thread orienté "vol de travail" que l'on retrouve dans l'offre .NET.
Conclusion
Les offres parallèles de Visual C++ 2010 proposent des performances souvent impressionnantes, le Concurency Runtime est sans aucun doute responsable d'une bonne partie de ces bons résultats. Arrivé à ce stade, vous devriez avoir une meilleure compréhension des fonctionnements internes du Concurency Runtime C++. Le Resource Manager Gestionnaire est à la fois souple et dynamique offrant un comportement collaboratif vis à vis des ordonnanceurs. L’ordonnanceur gagne en efficacité avec le concept de file d'attente "orientée vol de travail", qui est un élément essentiel partagé par les offres parallèles .NET et C++. On retiendra le capacité de mettre en attente un bloque d’exécution ayant des latences en mode noya au profit d’une tâche en attente afin de maximiser l’usage des processeurs. Enfin, les capacités d'extension du Concurrency Runtime C++ pour intégrer des librairies parallèles provenant de tiers est un élément essentiel de l'offre. Après Intel et son Parallel Studio Tools, d'autres éditeurs de logiciels ou de simples programmeurs viendront sans doute en tirer parti car nous savons qu'il n'existe pas de solution unique répondant à tous les scénarios dans tous les domaines. Dans le cadre plus restreint des librairies parallèles offertes dans Visual Studio 2010, les deux librairies "Parallel Pattern Library" et "Asynchronous Agents Library" où les philosophies parallèles sont complètement différentes (bien que complémentaires) reposent sur le Concurency Runtime tout en respectant leurs propres paradigmes.
Pour aller plus loin, je vous invite à regarder la session PDC08, TL22 Concurrency Runtime Deep Dive How to Harvest Multicore Computing Resources, dont je me suis largement inspiré pour préparer ce long billet.
A bientôt,
Bruno
Bruno Boucard (boucard.bruno@free.fr)
Comments
- Anonymous
April 22, 2009
9H00 - 9H30 Introduction Christian Staudinger présentant le programme de la journée La journée débute