Self-Tracking Entities in the Entity Framework
Background
One of the biggest pieces of feedback we received from the N-Tier Improvements for Entity Framework post as well as other sources was: “low level APIs are great, but where is the end-to-end architecture for N-tier and the Entity Framework?”. This post outlines some of the additional feedback we’ve received and describes the self-tracking entities architecture that will ship along side of VisualStudio 2010 and .NET Framework 4.0.
When an application goes multi-tier, there are important architectural decisions that the application developer makes around how to communicate between tiers. There are a lot of choices, and the choice depends on a variety of conditions. How rapidly is each tier expected to change? How much control is there over each tier? Are their specific protocol, security, or business policy concerns? The answers to these questions often drive the selection of whether to use data transfer objects (DTOs) or DataSets or something different altogether.
Self-Tracking Entities
Self-tracking entities know how to do their own change tracking regardless of which tier those changes are made on. As an architecture, self-tracking entities falls between DTOs and DataSets and includes some of the benefits of each.
Drawing from DataSet
DataSet on the client tier is very easy to use because there is no need to track changes separately or maintain any extra data structures that include change tracking information. DataSet takes care of serializing state information for each row of data. On the mid tier, applying the changes stored within a DataSet is straightforward. DataSets have also gained popularity because of the number of tools that work with DataSets, and because they are easily bound to many UI/presentation controls. Since it works in so many scenarios, for many applications there is never a need to transform data outside of a DataSet allowing a single paradigm to be used up and down the stack.
However, there are disadvantages to DataSets when used as the communication payload between tiers. The first is the cost of getting the data into a serializable format, and the second is that the DataSet serialization format is generally not very interoperable with other languages that are used to expose services. Another disadvantage of using a DataSet is that you can quickly lose the intent of your service call because so many kinds of things can be included in a DataSet. For example, if the service method is declared as:
DataSet GetCustomer(string id);
It is extra work to ensure that the DataSet that is returned contains only rows of data that pertain to “customers”. It is also more difficult to specify a service contract that says the DataSet is also supposed to return data for each customer’s orders and their order details.
Self-tracking entities share many advantages with DataSet. They also encapsulate change tracking information, which is serialized along with the data contained in the entity. On the mid-tier applying changes from a graph of self-tracking entities to a persistent context is equally straightforward. The Entity Framework will also provide tools for generating self-tracking entities and because these entities are just objects, they can be easily made to work with UI/presentation controls.
Drawing from DTOs
DTOs and SOA are used to give the developer more control over the service contract and payload for tier to tier communication. DTOs themselves do not have behavior, so they are typically very simple classes designed just to provide the needed information to perform a specific service operation. Not only does this provide the opportunity to optimize the wire format (some believe a DTO is all about the wire format), but it makes it possible and easy to capture the intent of each service method. The data contract used with DTOs is typically interoperable which makes it easy to use services that run on different platforms. DTOs also provide a way to separate messaging contracts from the presentation layer, the business logic, and the persistence layer which in many cases creates a maintainable architecture.
There are disadvantages to using DTOs and the primary one is complexity. DTOs are often hand-crafted to include only the specific information that is needed for an operation. When there is a common pattern for mapping DTOs to entity classes, there are some tools available that will do DTO generation and mapping but it is not always possible. With DTOs, it is up to the developer to decide how to do change tracking on each tier (especially the client) which increases the complexity of the presentation layer. The complexity of the service implementation also increases because the developer is responsible for translating the DTO into entities for doing business logic validation, as well as being able to report changes stored in the DTO to the persistence framework.
Not only do self-tracking entities share advantages with DataSets as mentioned above, they also share many advantages with DTOs. Self-tracking entities expose a simple and interoperable wire format and it is clear what kinds of data a service method requires or returns. You can also use a self-tracking entity as part of a message. However, self-tracking entities don’t give quite as much architectural separation as using pure DTOs, but you do gain a less complex solution that requires fewer data transformations. It is important to note that self-tracking entities can be made to be ignorant of any particular persistence framework making them essentially POCO objects. Particular persistence frameworks such as the Entity Framework will have the capabilities to create these entities and interpret the change tracking information when saving changes.
.NET Framework 3.5SP1 Challenge
With the .NET Framework 3.5SP1, this sort of solution was very hard to implement using the Entity Framework because change tracking was always done by a centralized ObjectContext which contains an ObjectStateManager. In particular, “reattaching” to report changes back to the ObjectStateManager was all but impossible without completely shredding your entity graph and applying changes one entity and one relationship at a time. The new API changes that are being added to the Entity Framework in .NET Framework 4.0 are enablers for an easier experience of reporting changes back to the ObjectStateManager, making self-tracking entities (as well as other architectures) easier to build.
Mid-tier experience
Using self-tracking entities on the mid-tier is about working with entity graphs and the Entity Framework. The service contract that is used in the following examples contains two simple methods for retrieving a Customer entity graph and applying updates to that entity graph:
interface ICustomerService
{
Customer GetCustomer(string customerID);
bool UpdateCustomer(Customer customer);
}
The implementation of the GetCustomer service method can be done using an Entity Framework ObjectContext and using LINQ or query builder methods to retrieve the entity you want. In the example below, a query is issued for a particular customer entity and all of the Orders and OrderDetails are included.
public Customer GetCustomer(string customerID)
{
using (NorthwindEFContext context = new NorthwindEFContext())
{
var result = context.Customers.
Include("Orders.OrderDetails").
Single(c => c.CustomerID == customerID);
return result;
}
}
UpdateCustomer is example of how to save the changes that are made to a graph of self-tracking entities. Similar to DataSet, applying these changes to the persistence layer and saving them should be simple. In the below example, a new Entity Framework API, “ApplyChanges” is used which understands how to interpret the change tracking information that is stored by each entity and how to tell the ObjectContext’s ObjectStateManager about those changes.
public void UpdateCustomer(Customer customer)
{
using (NorthwindEFContext context = new NorthwindEFContext())
{
context.Customers.ApplyChanges(customer);
context.SaveChanges();
}
}
Client Experience
The client experience when working with self-tracking entities is similar to how you would manipulate any object graph. You can make changes to scalar or complex properties, add or remove references, and add or remove from collections of related entities. The key part of the experience is that tracking changes is hidden from the client because it is done internally on each entity. There is no ObjectContext and there is no extra state that has to be maintained or passed from client to the tier that does persistence.
In this example, the test first queries for a customer, then deletes one of the orders. The resulting entity graph is sent back to the service tier using the UpdateCustomer method.
public void DeleteObjectsTest()
{
using (CustomerServiceClient client = new CustomerServiceClient())
{
var customer = client.GetCustomer("ALFKI");
customer.Orders.First().Delete();
client.UpdateCustomer(customer);
}
}
The next test shows how to add a new Order with two OrderDetails to an existing customer. By default, the constructor of a self-tracking entity puts the entity in the “Added” state. There are conveience methods on each self-tracking entity to change this state if needed (Delete() and SetUnchanged()).
public void AddObjectsTest()
{
using (CustomerServiceClient client = new CustomerServiceClient())
{
var customer = client.GetCustomer("ALFKI");
customer.Orders.Add(new Order() {
OrderID = 100,
OrderDetails = {
new OrderDetail{
ProductID = 3,
Quantity = 7
},
new OrderDetail{
ProductID = 4,
Quantity = 8
},
}
});
client.UpdateCustomer(customer);
}
}
The final example shows that a self-tracking entity graph can contain any number of changes and those changes can be any combination of adds, modifications, and deletes.
public void ComplexModificationsTest ()
{
using (CustomerServiceClient client = new CustomerServiceClient())
{
var cust = client.GetCustomer("ALFKI");
// remove first order - will do cascade in the database
cust.Orders.Remove(cust.Orders.First());
// modify one of the orders
var order = cust.Orders.Last();
order.RequiredDate = DateTime.Now;
order.OrderDetails.Add(
new OrderDetail{
ProductID = 7,
Quantity = 3
});
// add new order
cust.Orders.Add(new Order()
{
OrderID = 100,
OrderDate = DateTime.Now,
ShipCity = "Redmond",
ShipAddress = "One Microsoft Way",
ShipRegion = "WA",
ShipPostalCode = "98052",
OrderDetails = {
new OrderDetail{
ProductID = 3,
Quantity = 7
},
new OrderDetail{
ProductID = 4,
Quantity = 8
},
}
});
client.UpdateCustomer(cust);
}
}
Generating Self-Tracking Entities Building self-tracking entities should be as easy as using them. We plan to ship a T4 template that will do the code generation for creating self-tracking entities from your EDM. This template will show up in the list of available templates when you right click on your model and choose Add New Artifact Generation Item.
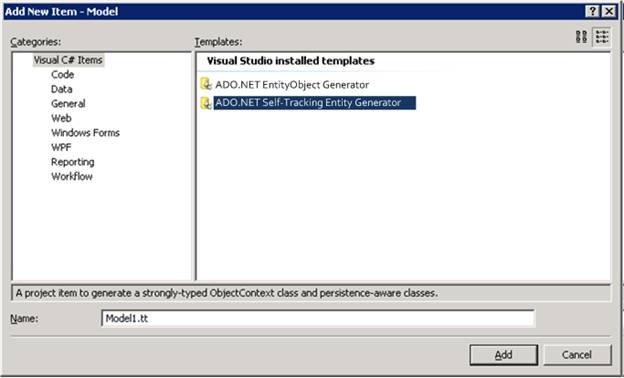
Design Notes
Inside a Self-Tracking Entity
There have not been final decisions about what exactly will be included inside of a self-tracking entity, but it is important to track:
- The state of the entity, Added, Deleted, Modified, or Unchanged
- The original value from reference relationship properties
- Adds and removes from collection relationship properties
This information will be included with the data contract of the entity. As part of the code generation of each self-tracking entity, scalar and complex property changes will mark the entity as “dirty” meaning that its state will change from Unchanged to Modified.
Inside ApplyChanges
ApplyChanges is a new API on the ObjectContext and ObjectSet classes that attaches an entity graph and interprets the change tracking information stored in each entity. The design for discovering the change tracking information has not yet been finalized, but there are a couple of options available. One would be to code generate an interface as part of the T4 template for self-tracking entities as well as a version of ApplyChanges that knew about the interface. Another option would be fall back to runtime discovery of the particular properties using a convension and some of the new dynamic capabilities of the framework. The thing we want to avoid is causing the self-tracking entity implementation to have a dependency on any of the Entity Framework assemblies.
The algorithm that ApplyChanges uses is:
1. Attaching the entity graph to the ObjectContext
2. Changing the state of each entity using the ChangeObjectState API.
3. For any reference relationship property, if there is an original value changing the state of the original reference relationship to Deleted and change the state of the current reference relationship to Added. This is done using the ChangeRelationshipState API.
4. For any collection relationship property, use the ChangeRelationshipState API to mark any removed relationships as Deleted and to mark any added relationships as Added.
Summary
We’ve received a lot of feedback and suggestions on how to make developing multi-tier applications easier using the Entity Framework. One of the components of improving this experience is the introduction of an end-to-end architecture around self-tracking entities. We’d like to hear your feedback on this addition to the Entity Framework, and any other comments you have on the matter of multi-tier development using domain models and entities.
Jeff Derstadt,
Dev Lead, Entity Framework Team, Microsoft
This post is part of the transparent design exercise in the Entity Framework Team. To understand how it works and how your feedback will be used please look at this post .
Comments
Anonymous
March 23, 2009
Lots of the feedback we got on the EF design blog about our early N-Tier plans , highlighted that lotsAnonymous
March 23, 2009
I’d like to turn your attention to two blog posts on EF Design Blog about exciting new features plannedAnonymous
March 23, 2009
Sounds great! Any plans for a beta/ctp?Anonymous
March 23, 2009
Sounds great to me too. This is the most important feature to me since working with the entityBag or any other solution led to a big BIG mess... although i didnt understand how the "self-track-entities" will integrate with poco :(Anonymous
March 23, 2009
@onemenny , @jaroslaw how about making "self-tracking" an inheritable base class (for poco). e.g.: [Entity] public class MyEntity : ChangeTrackedEntity { [Member("ID")] public int id { get;set;} }Anonymous
March 24, 2009
Thank you for submitting this cool story - Trackback from DotNetShoutoutAnonymous
March 24, 2009
Kristofer - i think it better be an interface of some kind or a wrapper class (injection), since it can mess with your domain model...Anonymous
March 24, 2009
Fantastic news! It seems to me that this would be best implemented in an interface. In that way it could be used more generally and even by other ORMs. It could be really handy for generic change logging?Anonymous
March 24, 2009
This DTO's with self tracking are not inherited by a special base class? This DTO's for the client should know nothing about the framework they will persisted with. What is about a kind of client side-tracking collection? Kind of EntityBag? This collection knows all entities and tracks all changes client side. For updating the entities, this collection calls serveral service-functions for updating, saving and deleting. Also see http://msdn.microsoft.com/en-us/magazine/dd263098.aspx. Thank you, MarcoAnonymous
March 24, 2009
Jeff, the scenario-based overview sounds great but I think a bit of elaboration is needed on how this would work with POCO. Based on what I have seen for the vNext release I would like to
- poco entities that are self-tracking
- shared library of these poco objects across tiers
- use the new "agile" method of creating an object context using attributes instead of .edmx How would self-tracking entities work in this scenario?
Anonymous
March 24, 2009
This is exactly what we need. Looking forward to seeing this.Anonymous
March 24, 2009
The comment has been removedAnonymous
March 24, 2009
@James Hancock James, I think a "ChangeInterceptor" similar to what is in ado.net data services would work for this.Anonymous
March 24, 2009
A couple of years ago I was involved in a couple of threads about doing change-tracking in client-sideAnonymous
March 25, 2009
@onemenny, @kristofera We want self-tracking entities to be POCO entities in that they have no special dependency on the Entity Framework or any of its base classes. In .NET 3.5SP1 the only options you had were to derive your entities from our EntityObject class or to implement interfaces that are specific to the Entity Framework (IEntityWithRelationships, for example). That is decided not POCO because you are forced to have a dependency between your domain classes and the EF, which depending on your scenario may not be desirable. So having self-tracking entities require a base class or an interface that is part of the Entity Framework assembly would fall into the “not very POCO” category, and we want to avoid that. It is likely that we will have an interface for self-tracking entities, but the interface would exist as part of your code-generated template for self-tracking entities so the interface would be specific to the assembly containing your domain classes, not the EF assembly. However, that may not be POCO enough so we are exploring other options as well, including using some dynamic way of “discovering” certain properties on your entity that contain change tracking information. We could also look at different dependency injection techniques (such as dynamically generated proxies), but those can be very hard to deal with in serialization scenarios. I will follow-up with a post on what we can expect the entities to look like, but for now the important point is that we will not require an interface or base class that is part of the Entity Framework to use self-tracking entities.Anonymous
March 25, 2009
@lynn Our hope is that you’ll be able to accomplish those three things. Self-tracking entities do not have a dependency on the Entity Framework, so they are POCO in that way. However, there still needs to be logic in that class that can do the self-tracking bit. Our goal would be that this is simple enough to write and could be used with agile approaches, even ones where you may not have a model (or database) yet. If you already have a model, then you can use the T4 template that will generate self-tracking entities to get started.Anonymous
March 25, 2009
@James In the next release, the ObjectContext's SaveChanges method will be virtual so you'll be able to do this kind of validation in your ObjectContext class.Anonymous
March 25, 2009
@Jeff Jeff, looking forward to your follow on. For my two cents, anything you can make happen with the use of attributes is a plus.Anonymous
March 26, 2009
@lynn, One dilemma with using attributes is that the attribute classes need to be defined somewhere which causes a dependency issue...
- Danny
Anonymous
March 26, 2009
I'd like to second James' request for entity-specific partial methods or events when saving an entity. Having "OnSaving" and "OnSaved" hooks to tie in logic when a single specific type of entity is saved and you want to take some additional action (like saving an audit record or recalculating a cached value) would be really useful. Having the ability to hook in to this type of event for each entity class could be preferable to overriding the ObjectContext's catch-all SaveChanges method to implement this type of entity-specific logic. We've used the OnValidate method in Linq2Sql quite a bit and wish we had something similar for OnSaving and OnSaved to help complete the validation picture. Speaking of which, it could also be handy to be able to somehow get access to the current ObjectContext from within an entity. So for example: OnValidate(EventArgs e) { // validate that the email isn't already in use var existingCustomer = this.CurrentObjectContext.Customers.SingleOrDefault(o => o.Email == this.Email); if (existingCustomer != null) throw new ValidationException("A customer with that email already exists!"); } OR OnSaving(EventArgs e) { // add a log of this transaction e.ObjectContext.AuditLogs.Add(new blah); } Perhaps if it isn't possible from anywhere within an entity, it could at least be made accessible from the event/method arguments for certain things like validation. This would allow you full access to the database when an entity is validated or saved, which would be extremely useful in certain architectures.Anonymous
March 26, 2009
I need to do more reading to understand the new EF. Thanks MS for making the process more transparent. But as a LINQ 2 SQL guy, things like this scare me Include("Orders.OrderDetails") Why are there strings in Data Tier like this? this seems like a C#3 fail to me. Surely you can use lambda expressions to capture these includes and memoize them for speed.Anonymous
March 26, 2009
@ Danny Understood about attributes. Since this is a major release release might it be possible to get a set of generic enough attributes for your purposes somewhere in the system dll, perhaps under System.ComponentModel or sub namespace?Anonymous
March 26, 2009
Vijay, we agree that lambda expressions could provide a nicer syntax for Include (although for multi-level paths, the lambda-based syntax becomes more complicated than the string version). In any case, at this point it doesn’t look like this improvement will make it in.NET 4.0. We appreciate your feedback.Anonymous
March 26, 2009
@Diego That's too bad, it would be really nice to have lambda-based syntax for Include. I thought getting rid of "magic strings" and having compile-time checking of queries was one of the main purposes behind LINQ. :( I'm definitely another person who would love to see strongly typed Include statements make it in sooner rather than later. It has always seemed out of place using strings there.Anonymous
March 26, 2009
A change tracking mechanism would be very nice in Entity Framework but I venture to doubt that the solution of self tracking entities can solve the problem. Tracking properties on entities would be a good start, but who is responsible to set this properties? Self tracking entities must have behavior to track its change state. Can you tell me how this can work without shared library of these poco/self tracking entity objects across tiers when using a modern technology like webservices or wcf over metadata contracts. And whats about interoperability? How can a java client consuming a webservice and track the change state of the entities?Anonymous
March 28, 2009
I think you should change name of the Delete method to MarkAsDeleted.Anonymous
March 29, 2009
The comment has been removedAnonymous
March 29, 2009
Команда ADO.NET продолжает свой эксперимент по публичному проектированию следующей версии Entity FrameworkAnonymous
March 29, 2009
The comment has been removedAnonymous
March 30, 2009
Interesting - I have a large project implemented using self tracking entities. These entities travel between tiers using web services. While its a viable solution, one pitfall that always comes up is that after doing an update, a new object comes down from server. All references now need to be updated. This becomes really challenging with data binding and events. Events have to be non serialized, and you have to have compensating code to reconfigure events. I am intrigued by the RIA services solution to some of these problems. I am sure there are some new pitfalls in that solution, but have you guys considered looking at it for ideas? Especially since its a MSFT technology?Anonymous
March 30, 2009
The comment has been removedAnonymous
March 30, 2009
@Eugene The problem you describe is something that is not baked into the self-tracking entities pattern directly. The issue boils down to being able to effectively do identity resolution on your client for round tripping. This is needed for many operations and is especially important when “bulk refreshing” your data binding is not possible (or, as you said hooking p events). There are some other solutions we are thinking about, such as an evolution of EntityBag that give you this sort of capability. If you are interested I can give you more details here. We are also working with the RIA Services teams to make sure that entities work well with their client side change tracker.Anonymous
March 30, 2009
The comment has been removedAnonymous
March 30, 2009
@Jeff > Are you asking about doing lazy load on the client? Not actually. It's clear that it's impossible to get the lazy loading work on the client when you don't have the ObjectContext at all (except additional query to the server). I was asking about the server-side solution. I thought when you create the self-tracking entity it is automatically detached from the ObjectContext it was created with to avoid any side-effects and be a POCO object. Is it correct assumption? If it's correct then it might be difficult to work with this entity using entity.Collection.Load() if you haven't load it's navigation collections when you get this entity from the context. That's why I asked about the possibility to inject the different ObjectContext to the entity so it can be used to retrieve this data afterwords or some other solution you came up for this situation. Could you please tell me whether my assumption is correct and what would you suggest for such scenario? Thank you and keep up a great work!Anonymous
March 31, 2009
The comment has been removedAnonymous
April 08, 2009
Today I was looking at a post in the forums where someone asked a very natural and common question aboutAnonymous
April 20, 2009
One quick question, while I'm wrapping my mind around this post... What is the distinction between "ApplyChanges" and "SaveChanges"? Is it the difference between persisting to the model and persisting to the database?Anonymous
April 20, 2009
@Remi, Yes, the distinction between ApplyChanges and SaveChanges is something like that. The context has an ObjectStateManager which keeps track of changes that need persisted to the database and provides that information to the rest of the EF. Since the context and state manager don't serialize with the entities, we need a way to push changes from the self-tracking entities into the context so that when you call SaveChanges the database will be updated.
- Danny
Anonymous
April 23, 2009
I agree that it looks like an other approach to ntiers solution than the one of RIA services team. I hope it's not going to be like EntityFramework/LINQToSql competition ! Questions : Is the RejectChanges() scenario will be supported by your SelfTrackableEntities ? Is the validation messages will be also supported. TrackableEntities implementing IDataErrorInfo that read messages in the inherited tracking info datamember (filled by the server that has the business logic to apply the validation rules ) ? By the way, we really need a IDataErrorInfoEx that includes the notion of severity of the message (error/warning/info)Anonymous
April 23, 2009
For the include statement that should be in strongly typed Include statements instead of "string" we use the following solution : http://blogs.msdn.com/stuartleeks/archive/2008/08/27/improving-objectquery-t-include.aspxAnonymous
April 30, 2009
O último post do time do Entity Framework é bem interessante no contexto dos assuntos discutidos nesteAnonymous
April 30, 2009
I'd love a mix of DTOs and tracking. It can be one more option for the next version. DTO's can protect us against errors at the client side, like updating a field that should be not reacheable in that context. That's what OO is all about. regardsAnonymous
May 14, 2009
Building applications that work across tiers is a core part of many application architectures. In .NETAnonymous
May 16, 2009
I received a mission to explore entity framework as a DAL for a new project, this project is intendedAnonymous
May 20, 2009
This framework sounds very similar to the CSLA.NET. Is this true?Anonymous
May 23, 2009
While I can see the usefulness of self-tracking entities in a pure Microsoft stack, what options to we have for managing change tracking in a true SOA environment with a hybrid of different technologies, including .NET, Java, AJAX calls from web clients, etc? Self-tracking entities are great when your always working with .NET on both sides of the wire...but more and more, the client tends to be something else...Java or Javascript/AJAX most frequently in my experience. Is our only option to attach the entity as fully changed, and save the whole thing? Or is there a more efficient option?Anonymous
May 23, 2009
@Jon, While self-tracking entities are aimed at making especially easy scenarios where .Net is available on the client, we have also been giving some thought to interop. The intention is that the serialization XML for the entities (including the tracking information) will be very clear and easy to work with in other platforms. You will have to write client code which does tracking and supplies the tracking info ina compatible format, but that should be possible. We have been debating about just how much change tracking information to include. Certainly we will include information about the state of each entity and about the relationships between them, but we originally thought we would avoid tracking exactly which properties of an entity were modified and instead just plan to send the whole entity to the database each time (very reasonable in many situations but not for some). This is what you are likely to see in the first CTP of self-tracking entities, but we're now leaning toward the idea that the long-term plan will be to include original values for properties in the change-tracking info so that only the modified properties would be sent to the database on a save.
- Danny
Anonymous
May 25, 2009
This post runs through a simple demo of the new N-Tier focused APIs in the in ADO.Net Entity Framework bits (EF4) that are included in Beta 1 of Visual Studio 2010 / .Net Framework 4.0. For this d ...Anonymous
May 25, 2009
This post runs through a simple demo of the new N-Tier focused APIs in the in ADO.Net Entity Framework bits (EF4) that are included in Beta 1 of Visual Studio 2010 / .Net Framework 4.0. For this d ...Anonymous
May 25, 2009
@Dan Simmons, Thanks for the reply Dan. Good to know your trying to keep change tracking open. While I personally prefer to work in an entirely .NET stack, other individuals at a higher pay grade often take that decision out of my hands. I've been both lucky (expanding my horizons), and unlucky (having to deal with cross-platform implementation issues and complexity), enough to be working in a hybrid .NET/Java environment these days. So an open, simple format is good news. In response to something you mentioned in your reply, I am curious if you could expand upon it a bit more. If the intention with self-tracking is to provide a simple and open format that any client could use to transfer state-change details back to a service with...then the following statement confuses me a little: "This is what you are likely to see in the first CTP of self-tracking entities, but we're now leaning toward the idea that the long-term plan will be to --> include original values for properties in the change-tracking info so that only the modified properties would be sent to the database on a save. <--" When it comes to...disconnected change tracking, is the concept of "original value" really useful, or is it just a waste of space and bandwidth? We have a full entity, and it will be tracking its own changes. I don't think that knowing the original value as well as the current value matters as much as knowing that the value changed. Differentiating between the current value and a value that is being set, and not flipping that "changed" bit in the event the two values are equal, should be the responsibility of the self-tracking entity its elf (regardless of platform). Correct? We can bloat the self-tracking entity message schema to track original values, but it seems more logical to simply track a map of which values have changed. The end goal is to overwrite whatever value is in the database anyway, so the original value has no meaning. A change conflict could be detected by a database-level version (i.e. SQL Server rowversion/timestamp), thus preventing last-in-wins, correct? Is there something I am missing that would make original values useful in the self-tracking context?Anonymous
May 25, 2009
To expound a bit more on why I think tracking original values could be wasteful (because I'm sure some will say it wouldn't be that much space/bandwidth.) I am thinking in the context of strings mostly. For example, if I have a Blog entity, which contains an author id, date posted, a list of tags (string, but generally small), and the contents of the blog post itself. Tracking original values for the author id, date, and tags really isn't a huge deal. However, tracking the original value for the contents means I am likely doubling the size of my self-tracking entity message, when all I really need is to know that the contents did, indeed, change. A simple boolean along the lines of: <changes><property name="Body"/><changes> would do the job, and keep things compact. This goes for pretty much any large string value, which occur a lot in things like forum posts, product descriptions, email messages, blogs, digital newspapers (pretty much all text), etc. Sorry for not clarifying in my previous post.Anonymous
May 25, 2009
@Jon, Well, you are right that sometimes keeping around the original value is not nearly so interesting as just knowing that the column has changed. It turns out that this is a rather tricky topic. Sometimes we just want to know a column has changed (like your scenarios above where the original value isn't interesting and the values are large so keeping the original value is wasteful), while other times we really do need to know the original value, and still other times we need the original value, but it's very likely that anyone would change the value since it's a server-generated rowversion or something so keeping the original value is a waste and we can just treat the current value as the original value. The tricky ones are the middle case (where we really need the original value), and they come up in two scenarios. The first one is when you have a concurrency value that is determined on the client rather than the server. In this case you need the original value to check for concurrency conflicts, but you also need the current value to set the property to if there isn't a conflict. This is unusual because it's hard to do this correctly, usually you want the concurrency value to be automatically generated by the server. The second case is a bit more obscure, but it is possible to create certain mappings where the value of a property can change how the entity is persisted to the database, and in these cases we need the original values so we know how to undo the old persistence and then do the new one--imagine for instance that depending on a value an entity might be persisted in part to one table or to another table. If the value changed, then we would need to remove a row from the old location and add a row to the new one. It is possible for us to determine most if not all of this information at code generation time from the metadata, so we could generate classes that are more precise in the way that they handle original values to sometimes store them and other times just store a bit indicating that something has changed, but then we start getting into cases where interoperability becomes harder because the wire format becomes more complex. Until now we have favored either going the route of never storing original values which makes for a simple, efficient wire format and simple client classes but rules out some mapping scenarious and can produce less efficient database updates, or always toring original values which still keeps the wire format and client classes relatively simple, and allows for efficient database updates, but makes the wire format less efficient. Neither of the options seems perfect, but it may be that one or the other is best in light of trying to keep the wire format simple. It's always possible to take our self-tracking template and modify it for more specific needs or to avoid code gen altogether and write DTO classes by hand to handle n-tier for those cases where you need the most flexibility and efficiency for a particular sceanrio.
- Danny
Anonymous
May 25, 2009
  Building applications that work across tiers is a core part of many application architecturesAnonymous
May 26, 2009
@Dan, Thanks for the clarification. It definitely sounds like a more complex issue that it appears at first glance. I think message efficiency is a very critical factor, especially considering some of the scenarios I mentioned (which, if the "always use original values" route is taken, could effectively halve the overall message throughput in those scenarios.) I think flexibility is key here...and if there is anything we have all learned from EF v1.0, its that the community needs a great breadth of flexibility to accommodate existing needs. It may make the wire format a bit more complex, but I think neither option 1 (never use original values) nor option 2 (always use original values) is going to be sufficient to meet the needs of everyone involved (including the EF team, who needs to support as many mapping scenarios as possible.) While I love to use simple formats whenever possible, if a little added complexity will give me the ability to tune my efficiency, I'll take that complexity every time. Limiting my options and not giving me the ability to tweak and tune (i.e. go from just using simple flags to a hybrid of flags and original values where required) is a sure-fire way to make me abandon the rigid, inflexible framework in favor of a more flexible one, or build something in-house that meets my needs.Anonymous
May 26, 2009
Code generation has been mentioned several times. I'm wondering if it is still expected that you are generating your data model from an existing database, or, is model first supported? i.e. I want to define my database by defining classes and then generating the database from that, a la Hibernate. Is this something that can be done in a pain free way, or, will I be going against the grain and having to implement a lot of methods needed by EF manually?Anonymous
May 26, 2009
@Jon: I think the following entry from this blog will answer your questions: http://blogs.msdn.com/efdesign/archive/2008/09/10/model-first.aspxAnonymous
June 05, 2009
Introduction My blog has been feeling very neglected after my move to the US and I thought with the recentAnonymous
June 08, 2009
Hi! Is there any release date for the self tracking entities T4 template, or any preview of it? ThanksAnonymous
June 08, 2009
@Ben, We don't yet have an official release date, but I can help you narrow it down a bit. It's getting close, but it won't be for a few weeks yet.
- Danny
Anonymous
June 10, 2009
  Entity Framework 4.0 Beta 1(又称EF V2)与 .NET 4.0 Beta 1 一起发布,包含了一系列的重要改进:自定义代码生成、延迟加载、N层支持、POCO支持Anonymous
July 07, 2009
This looks like it should solve one of the issues that I have had to handle in my code, but there are a couple of points that I would like to clarify. As these are self-tracking entities, am I right in thinking that the query in GetCustomer should be a MergeOption.NoTracking query or alternatively that the entity graph needs to be detached manually ? If I recall correctly (I don't use NoTracking myself), NoTracking queries do not perform identity resolution (and hence there is a possibility of duplicate entities) and also they do not populate EntityReference EntityKey values that are not Included. Also, am I right that Detaching an entity detaches only that entity and drops all the navigation properties ?Anonymous
July 07, 2009
Graham, Your recollection of the behavior of NoTracking queries and Detach is correct. Self Tracking Entities, in fact, do not make use of either, at least in mainline scenarios. Instead, it is the work of serialization to create a snapshot of the full graph of tracked entities. Hope this answers your question, DiegoAnonymous
July 07, 2009
Thanks Diego, just to confirm, are you saying that entities can be both self-tracking and attached to an object context ?Anonymous
July 17, 2009
awesome, I'm just in the middle of the artcile but so excited :) so I have just one question... why woudn't I want to use self-tracking entities, when it is so coool? no more UOW problems and referencing it via many tiers with problems where to store it (session) for entities to be reatached later and many other problems than other mappers face... here, I can code as Conan the Barbarian style, "opening the connection", e.g. "using" Context just when I want to store final entity, and that's it. I don't need to have it opened all the time, e.g. without "using ctx = ..." I can't do any work right now. Unless I am missing something this sounds too easy to be real :) must be some drawbacksAnonymous
July 21, 2009
Storing the original values also allows you to handle concurrency issues. So if two users update the same Contact record, the last should fail with something like a RecordChangedByAnotherUser exception. It would be nice if EF allowed you to specify the WHERE clause for the update. So for example, typically UPDATE contact SET name=:name WHERE id=:id what is really needed for concurrency is: UPDATE contact SET name=:name WHERE id=:id AND lastModified=:lastModified The Borland ClientDataSet had an option for this:
- UpdateWhereKey - only use the Pk
- UpdateWhereAll - put all the old values in the where
- UpdateWhereChanged - only put changed fields in the where. I don't particularly like this, because two simultaneous updates could occur producing a result that actually violates business rules.
- UpdateSpecify - specify the set of fields to include in the where.
Anonymous
August 24, 2009
I am with cowgaR. Am I missing something? Also, what is wrong with IEditableObject as the interface?Anonymous
September 10, 2009
I agree with Vijay Santhanam and ManojR. Support for filtering when doing Load or Include is one of the things we really missed in EF v1. How do you recommend one solves such filtering problems?Anonymous
August 08, 2010
Thanks for writing this article. I must admit, overall I am quite disappointed with Microsoft and in particular the EF group within Microsoft for not releasing more documentation that demonstrates how to use the EF in common ntier development models. I have been searching Google and Bing for months now, since the release of VS2010, and almost all of the articles I find are for old versions of the entity framework. Why are no articles being written? Are too few people adopting the EF? I stick with ADO.NET for my projects simply because it is well documented and proven. EF?? Even the team behind it doesn't seem to do a good job promoting it! What kind of a future can it have?? All of my excitement over the EF has been turned into disappointment.Anonymous
September 01, 2010
please fix broken links in this rather fundamental blog (e.g. 3rd and 4th link)... cheersAnonymous
July 28, 2011
How to handle IEditable Interace for Reference data typeAnonymous
September 11, 2011
@acesdesign I think the following entry from this blog will answer your questions http://acesdesign.com.br/Anonymous
November 09, 2012
Nice tutorial on Self-Tracking Entities. It help me to understand it how it works. Thanks a lot for useful info. Waqas webdesignpluscode.blogspot.comAnonymous
December 29, 2014
Great article, you can also check this 2 parts article on SQL Server Change tracking , Part 1 - sqlturbo.com/practical-intro-sql-server-table-change-tracking and Part 2 sqlturbo.com/practical-intro-sql-server-table-change-tracking-part-2-column-tracking