Traiter et visualiser les données avec Power BI
Après un billet sur les annonces de la conférence Build 2017 (#Build2017), conférence qui s'est tenue en mai dernier, l'offre de service Microsoft Power BI à l'honneur lors la conférence Microsoft Data Insights Summit 2017 hier et avant-hier, avec notamment la disponibilité générale de Power BI Premium, nous nous sommes dits qu'un peu d'exercices (pratiques) ne « ferait pas de mal » !
Nous allons donc l'espace de ce billet nous confronter à un problème d'apprentissage automatique (Machine Learning) en le traitant de A à Z, c'est-à-dire du nettoyage des données à leur traitement, en passant par leur visualisation.
Le jeu de données choisi concerne Adventure Works Cycles, une entreprise de commerce en ligne fictive fabriquant et vendant des vélos. Nous avons accès à la liste des clients et la liste des ventes.
Compte tenu des lignes précédentes, nous avons fait ici le choix d'utiliser Microsoft Power BI pour le nettoyage et la visualisation des données. C'est en effet une approche ergonomique permettant de traiter rapidement et facilement des données, puis de partager ses résultats de manière dynamique et compréhensible par tous. Pour les besoins de notre cas pratique de prévision des achats clients, le service Azure Machine Learning (Azure ML) (qui a fait l'objet de nombreux billets sur ce même blog) est sans surprise ensuite utilisé pour la partie prédiction à proprement parlé.
J'en profite pour remercier très sincèrement Anaig Maréchal actuellement en stage au sein de l'équipe pour cette contribution :-)
Un mot sur le curriculum Microsoft Professional Program Data Science
Ce billet s'inspire du projet final proposé dans le cadre du curriculum Microsoft Professional Program for Data Science. Ce curriculum complet s'appuie sur 10 cours en ligne traitant 8 compétences différentes, essentielles au profil de « Data Scientist ».
Les technologies Microsoft, comme Azure ML, Power BI, Excel ou SQL Server sont principalement utilisées dans les cours.

Le projet final permet de mettre en application les connaissances acquises tout au long du programme. Débutants comme professionnels peuvent se prêter au jeu pour acquérir, renforcer ou attester leurs compétences fonctionnelles et techniques. Nous n'en dévoilerons pas plus ici mais cette source d'inspiration permet de revenir sur un certain nombre de considérations essentielles.
De l'importance d'un jeu de donnée propre et compris
Lors d'un travail d'analyse de données, il ne faut pas sous-estimer la phase préliminaire à l'application des algorithmes d'apprentissage automatique (Machine Learning).
Suivant la qualité du jeu de données fourni, l'étape de nettoyage peut prendre peu de temps tout comme elle peut prendre plus de temps que l'analyse en elle-même ! (sic)
Quelle que soit la situation, il est important d'y accorder (toute) l'attention nécessaire, car c'est sur cette étape que va reposer la qualité du rendu. Elle va en effet permettre d'éviter :
- De se confronter à des erreurs lors du traitement à cause de données manquantes ou de caractères spéciaux.
- D'avoir un jeu biaisé dû à la présence de doublons ou de lignes incomplètes.
L'étape de visualisation va permettre de mieux se représenter les données et ainsi mieux les comprendre. Il est intéressant en particulier de déchiffrer les relations entre les différentes variables, car cela va permettre de juger de l'importance de leur rôle dans la phase de prédiction. De cette façon, on peut donner plus de poids à certains prédicteurs (feature) présentant une forte corrélation avec la colonne à prédire et on peut également écarter certaines variables qui ne semblent pas avoir d'influence dans le cadre de la prédiction.
Une bonne visualisation va se jouer sur :
- Un choix pertinent des formules et graphiques employés.
- Une bonne intuition par rapport aux données : en effet, la compréhension repose parfois seulement sur du bon sens ou une connaissance du métier.
Les données
Les données se trouvent dans 2 fichiers : « AWCustomers.csv » et « AWSales.csv ». Ces fichiers sont téléchargeables ici.
Le premier fichier « AWCustomers.csv » est une liste d'informations personnelles relatives à chaque client. Ceux-ci sont identifiés de manière unique par un ID qui les lie à des données telles que leur nom, leur adresse, leur numéro de téléphone, leur date de naissance, leur revenu annuel, leur nombre d'enfants… 23 colonnes décrivent ainsi les clients, en plus de leur identificateur client ou « Customer ID ».
Le deuxième fichier « AWSales.csv » correspond à une liste des ventes, indiquant si les clients ont précédemment acheté un vélo (1 si oui, 0 sinon) et la hauteur de leurs dépenses mensuelles chez Adventure Works Cycles. De la même façon, chaque ligne est associée à un Customer ID, reliant les achats à un client.
Importation des données
Dans un premier temps, nous allons importer les données dans l'application Power BI Desktop. Power BI Desktop facilite la découverte des données et vous permet pour cela de créer des connexions de données et de créer une collection de requêtes. Vos travaux peuvent être sauvegardés sous forme de rapports qui peuvent ensuite être aisément partagés avec d'autres utilisateurs. Power BI Desktop fonctionne pour cela de façon transparente avec le service Power BI en ligne qui permet de publier vos rapports. Le Guide de prise en de Power BI Desktop peut vous « accompagner dans vos premiers pas » si besoin.
Téléchargez et installez l'application Power BI Desktop si ce n'est pas déjà le cas depuis le portail Power BI ici.
Exécutez l'application. A l'ouverture de l'application, sélectionner Get Data, puis Text/CSV pour sélectionner un fichier CSV depuis les fichiers locaux.
En fonction du format du fichier, le séparateur des colonnes peut être modifié. Dans notre cas, ce sont des virgules. Charger ensuite le deuxième fichier, de la même manière.

Les deux fichiers se présentent alors comme des fichiers Excel dans l'application Power BI Desktop.
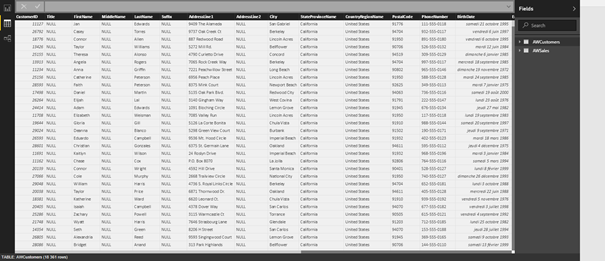
Nettoyage des données
Pour manipuler les données insérées, cliquer sur Edit Queries (modifier une requête). De nombreux outils sont alors disponibles pour manipuler les données.
Type des variables
On peut tout d'abord s'assurer que les différents types automatiquement attribués aux variables sont bien corrects pour les deux fichiers. Nous sommes en présence de littéraux, d'entiers, d'une colonne de type date et d'une colonne de type décimal.
Pour modifier un type, il faut sélectionner la colonne en question, puis se rendre dans l'onglet Transform dans le menu du haut et modifier la valeur grâce au bouton Data type.

Paramètres régionaux
Des erreurs de conversion peuvent survenir si les paramètres régionaux ne sont pas adaptés. Le paramétrage français prend ainsi la virgule comme séparateur décimal. Or ici, nos données sont au format américain. La colonne des dépenses moyennes mensuelles, avec un point en guise de séparateur décimal, apparaît donc comme une donnée texte et affiche une erreur lors de la conversion.
Il faut alors se rendre dans File, Options and settings, Options, puis dans Regional Settings sélectionner English (United States) par exemple.

Une fois ce changement effectué, on peut modifier le type de la colonne des dépenses sans provoquer d'erreur.
Suppression des doublons
L'identifiant des clients est supposé être unique. On peut donc commencer par vérifier que cette règle est respectée. Pour cela, faites un clic droit sur la colonne « CustomerId » puis sélectionnezRemove Duplicates.

On peut également penser que le même client a pu être entré plusieurs fois dans la base sous un ID différent. Pour vérifier cela, on peut identifier arbitrairement des colonnes qui nous paraissent définir une identité unique (sélectionner toutes les colonnes ne serait pas pertinent).
Par exemple, plusieurs personnes peuvent avoir le même nom et prénom. En revanche, le numéro de téléphone, dans le cadre d'un foyer, est unique. On peut donc définir les colonnes nom, prénom, date de naissance et téléphone comme définissant une personne unique. On sélectionne ces 3 colonnes grâce à la touche Ctrl et, comme pour la colonne CustomerID, on applique la commande Remove Duplicates .
Nettoyage des données manquantes
On remarque au premier coup d'œil que le jeu de données personnelles des clients comporte beaucoup de valeurs nulles. Or cela concerne des colonnes telles que le 2ème prénom ou la 2ème ligne d'adresse, des données que tout le monde n'a pas, ce qui est donc normal. Supprimer les lignes concernées ne serait pas conséquent pas utile.
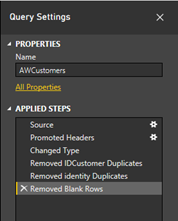
Pour supprimer les lignes vides, on peut se rendre dans Remove rows et cliquer sur Remove blank rows.

Toutes les opérations effectuées sur les données sont affichées dans le menu de droite. Il est possible de revenir en arrière, annuler des actions ou encore changer leur ordre.
Ajout d'une colonne personnalisée
L'application Power BI Desktop permet aussi d'ajouter ses propres colonnes, à partir de règles personnalisées par une requête Power Query ou grâce aux fonctionnalités déjà proposées. Par exemple, l'âge d'un client peut-être une donnée plus facilement manipulable que sa date de naissance. L'application Power BI Desktop propose un outil pour calculer directement l'âge depuis une date.

La nouvelle colonne apparaissant se présente sous la forme d'une durée en timestamp. Par un clic droit, on peut ainsi transformer la donnée en année puis arrondir le chiffre obtenu pour obtenir un âge entier.


Une fois les modifications sur les données terminées, on peut cliquer sur Close & Apply pour quitter l'éditeur de requêtes et retrouver les modifications dans le projet.

Jointure des données
Dans le cas de notre illustration, nous avons deux fichiers de données, chacun apportant des informations différentes sur les clients. Pour mettre en relation ces deux tables, on peut s'appuyer sur le Customer ID qui est à chaque fois présent.
Quand deux colonnes ont le même nom, PowerBI fait en général automatiquement le lien entre les deux tables. C'est ce qu'on constate ici en se rendant dans l'onglet Relationships.
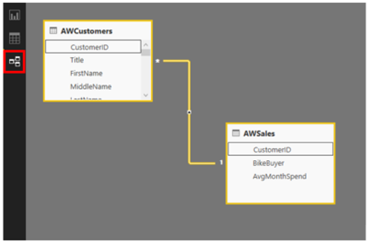
Dans le menu du haut, l'onglet Manage relationships permet de gérer les relations entre les tables : supprimer, créer, éditer.
La création d'une nouvelle relation s'effectue sur le même principe que pour les relations UML. On sélectionne les colonnes concernées et on leur affecte une cardinalité. Ici par exemple, on modifie la relation automatiquement créée pour la transformer en une cardinalité 1 à 1.

Visualisation des données
Un problème de classification possible serait de mettre en place un système permettant de prédire si un nouveau client achètera ou non un vélo, c'est-à-dire la variable booléenne BikeBuyer.
Comme nous l'avons vu, nous sommes initialement en présence de 23 variables différentes décrivant la situation personnelle d'un client. Une première sélection peut se faire par bon sens : des colonnes comme le nom de l'acheteur ou son numéro de téléphone ne seront certainement pas déterminantes pour un modèle général. Pour choisir ensuite les variables les plus significatives pour la prédiction, on peut s'aider de la visualisation.

Ajout d'un filtre
Afin de comparer le comportement des acheteurs et celui des autres, on peut ajouter un filtre : cette opération est possible soit à l'échelle de la page, soit à l'échelle d'un graphique.
Nous avons ici créé un graphique représentant la répartition des personnes selon leur genre et leur situation maritale. Pour comparer ces informations en fonction de la valeur de BikeBuyer, on copie ce graphique, et pour chacun des duplicatas on ajoute un filtre soit à 1, soit à 0.

Concernant les acheteurs de vélo, on observe qu'ils se trouvent en majorité aux Etats-Unis et en Australie grâce à un pie plot, qui permet de visualiser rapidement des proportions. Néanmoins, il n'y a pas de différence de répartition géographique en fonction de la valeur de BikeBuyer.
Création de catégories de valeurs
Pour regrouper des valeurs par catégories, il faut se rendre dans le menu et cliquer sur les trois points face à la variable d'intérêt pour sélectionner New Group.
Il est alors possible grâce au menu déroulant Group type de créer automatiquement des bins de taille définie ou bien de grouper par liste manuellement. De cette façon, on constate que la tranche d'âge entre 30 et 50 ans est la plus disposée à acheter un vélo.
Ajout d'un graphique personnalisé
De nombreux graphiques sont disponibles avec l'application Power BI Desktop. Cependant, il est possible que l'effet recherché ne puisse pas être représenté par les visualisations basiques. Des solutions existent alors pour personnaliser sa présentation.


Tout d'abord, on peut ajouter visuel directement depuis un script R. En appuyant sur ce symbole, un éditeur s'ouvre directement au sein de l'application Power BI Desktop.
De cette manière, on constate que les acheteurs de vélos ont une médiane de salaire annuelle plus élevée que les autres.
Une autre façon de personnaliser ses rapports est d'importer des visuels personnalisés. La galerie Power BI propose de nombreux modèles (templates) originaux en libre téléchargement.

Pour les besoins de notre illustration, nous choisissons ici le visuel « Mekki Chart », publié par Microsoft. La taille des bandes de couleur représente le nombre d'enfants au foyer par acheteurs de vélo ou non et la largeur des colonnes est proportionnelle au nombre moyen de voiture pour BikeBuyer=1 et BikeBuyer=0.
Les acheteurs de vélo ont en moyenne plus de voitures que les autres, et ils ont aussi en moyenne plus d'enfants à la maison, 0.52 contre 0.11.

Pour partager la visualisation créée avec des collaborateurs, on peut ensuite la publier.

Prédiction sur les achats de vélo
A partir des observations faites sur les données, nous sommes à présent en mesure d'établir un modèle de prédiction ; la suite logique à ce que nous souhaitions aborder dans ce billet.
On effectue en premier lieu une sélection de variables (feature selection) pour ne garder que les colonnes nous intéressant. D'après notre exploration des données, l'âge, le genre, le statut marital, le nombre de voitures, le nombre d'enfants au foyer et le revenu annuel sont discriminatoires.
Nous choisissons le modèle « Two-class Boosted Decision Tree » pour cette classification, et nous le paramétron grâce au module « Tune Model Hyperparameters ».
Pour de plus amples informations, vous pouvez consulter l'article Machine learning algorithm cheat sheet for Microsoft Azure Machine Learning Studio.
Le meilleur paramétrage a été sélectionné et son taux d'erreur a été calculé par cross validation, ce qui permet de réduire la variance du résultat. On obtient une précision de 0.8.
Nous illustrons ci-après le modèle complet et le résultat associé.


En guise de conclusion
Le travail d'un « Data Scientist » ne se résume pas à l'application de modèles de Machine Learning ou de Deep Learning.
Les phases préliminaires représentent une part importante du travail. C'est ce que nous avons souhaité illustrer dans ce billet.
La visualisation des données permet notamment de bien appréhender le problème de prédiction. Les plots R et Python sont les méthodes les plus classiques pour cette exploration. L'alternative ou complément que peut représenter l'application Power BI Desktop présentée ici est intéressante dans une optique de simplicité, de partage et de visualisation dynamique.
Ceci conclut ce billet.