COLUMN STORE INDEXES (ÍNDICES ALMACENADOS POR COLUMNAS)
COLUMN STORE INDEXES (ÍNDICES ALMACENADOS POR COLUMNAS)
Hace unos días visite un cliente en Puerto Rico que tenía problemas de rendimiento en una aplicación transaccional y entre las opciones que quería considerar era el uso de índices almacenados por columnas. Este tipo de índice es una de las nuevas funcionalidades que tiene SQL 2012 pero como veremos a continuación sus características lo hacen idóneo para ciertos escenarios no para todos. Las versiones de SQL 2012 donde está disponible la funcionalidad de índices almacenados por columnas son: SQL Server 2012 Enterprise, Evaluation, y Developer.
Los índices tradicionales son almacenados por filas en vez de columnas. Esta forma de almacenamiento es extremadamente eficiente cuando se requiere acceder una fila o un rango compuesto de un grupo pequeño de filas. Sin embargo cuando se solicitan todas las filas o un rango grande, este método se vuelve ineficiente.

Los índices almacenados por columnas permiten presentar un rango amplio de filas a través del almacenamiento de los datos organizados por columnas. Cuando se crea un índice almacenado por columnas típicamente se incluyen todas las columnas de la tabla. Esto asegura que todas las columnas se beneficiaran de la mejora en rendimiento.

En un índice almacenado por columnas, en vez de almacenar juntas todas las columnas de un registro, cada columna es almacenada de forma separada con todas las demás filas en el índice. El beneficio de este tipo de índice consiste en que solo las columnas y las filas requeridas para contestar una consulta serán leídas. En escenarios de Datawarehouse, a menudo se utiliza menos de un 15% de las columnas de un índice para obtener el resultado de una consulta.
Hay dos restricciones principales a considerar cuando se trabaja con índices almacenados por columnas. En primer lugar un índice almacenado por columna es de solo lectura. Una vez se ha creado, no se pueden realizar modificaciones a los datos en la tabla. Es decir las operaciones: INSERT, UPDATE y DELETE no están permitidas. Por esta razón a menudo se utiliza el particionamiento de tablas para reducir la cantidad de datos que necesitan ser almacenados en un índice almacenado por columnas y para permitir el reconstruir un índice cuando se insertan nuevos datos a la tabla. Debido a esta restricción, los índices almacenados por columnas son idóneos en situaciones donde los datos no cambian con frecuencia como es el caso de los datawarehouse. La segunda restricción limita a uno el número de índices almacenados por columnas que pueden existir en una tabla. Esta restricción no se considera un problema ya que se acostumbra a incluir todas las columnas de la tabla en el índice almacenado por columnas.
Otra limitación está relacionada con el tiempo que toma la creación de un índice en comparación con un índice nonclustered. El tiempo promedio podría ser de dos a tres veces más. Sin embargo, a pesar de las restricciones antes mencionadas, los índices almacenados por columnas pueden proveer un valor significativo en términos de rendimiento si se considera que el índice solo cargará las columnas que sean requeridas por la consulta. Además de la mejora en compresión que se puede obtener por contar con data similar en la misma página.
Los siguientes tipos de datos no pueden ser utilizados en índices almacenados por columnas: binary, varbinary, ntext, text, image, nvarchar(max), varchar(max), uniqueidentifier, rowversion, sql_variant, decimal (mayor de 18 dígitos), datetimeoffset, xml, y tipos basados en CLR. Además el número de columnas está limitado a 1,024. Finalmente por la naturaleza del índice no puede ser UNIQUE, CLUSTERED, contener columnas incluidas o tener definido un orden (ascendente o descendente).
Los índices almacenados por columnas utilizan su propia tecnología de compresión por lo cual no se pueden combinar con la opción de compresión a nivel de fila o página. Tampoco pueden ser utilizados en esquemas de replicación, change tracking o Change data capture, filestream. Estas tecnologías trabajan en escenarios de lectura/escritura lo cual no es compatible con la naturaleza de solo lectura de los índices almacenados por columnas.
Como crear un índice almacenado por columnas
La creación de un índice almacenado por columnas puede ser realizada a través de T-SQL o utilizando SQL Server Management Studio.
T-SQL
CREATE NONCLUSTERED COLUMNSTORE INDEX <ColumnStoreIndexName> ON<Table> (col1, col2, col3);
-- Create the columnstore index
CREATE NONCLUSTERED COLUMNSTORE INDEX [csindx_FactResellerSalesPtnd]
ON [FactResellerSalesPtnd]
(
[ProductKey], [OrderDateKey], [DueDateKey], [ShipDateKey], [CustomerKey], [EmployeeKey],
[PromotionKey], [CurrencyKey], [SalesTerritoryKey], [SalesOrderNumber], [SalesOrderLineNumber],
[RevisionNumber], [OrderQuantity], [UnitPrice], [ExtendedAmount], [UnitPriceDiscountPct],
[DiscountAmount], [ProductStandardCost], [TotalProductCost], [SalesAmount], [TaxAmt], [Freight],
[CarrierTrackingNumber], [CustomerPONumber], [OrderDate], [DueDate], [ShipDate]
);
Management Studio
- A través del Management Studio, utilice el Object Explorer para conectarse a la instancia de SQL Server.
- En el Object Explorer, expanda la instancia de SQL Server, la base de datos y la tabla donde desea crear el índice.
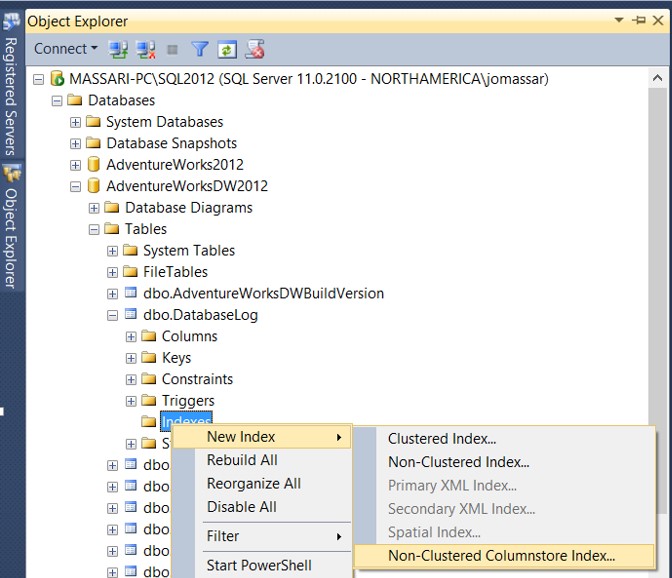
- Presione el botón de la derecha del mouse y seleccione Non-Clustered Columnstore Index dentro de la opción New Index ubicada en la carpeta Indexes.
- Ingrese el nombre y seleccione las columnas que participarán en el índice almacenado por columnas. Presione OK dos veces para crear el índice.
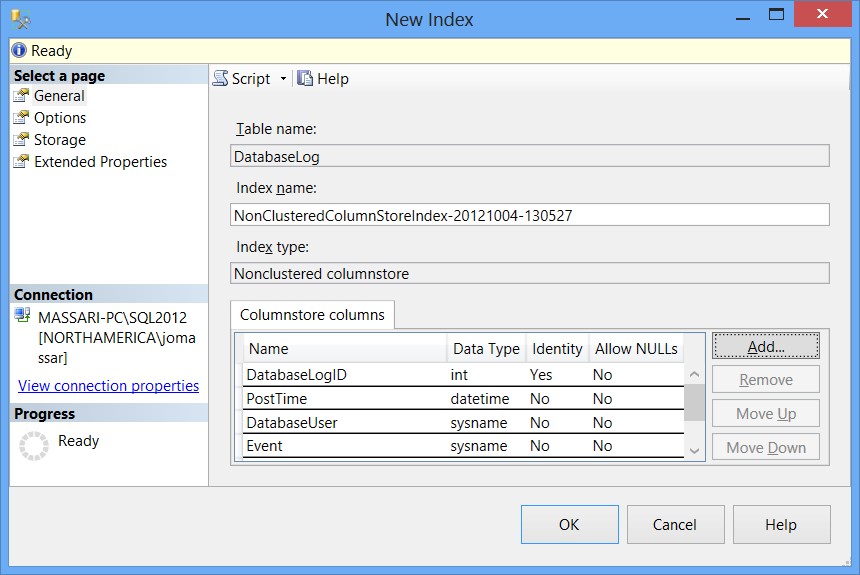
Índices almacenados por columnas con tablas particionadas
Crearemos una tabla particionada llamada FactResellerSalesPtnd utilizando el siguiente código de MSDN (https://msdn.microsoft.com/en-us/library/gg492088.aspx).
Paso #1: Crear la tabla FactResellerSalesPtnd(Versión particionada de la tabla: FactResellerSales)
USE AdventureWorksDW2012;
GO
CREATE PARTITION FUNCTION [ByOrderDateMonthPF](int) AS RANGE RIGHT
FOR VALUES (
20050701, 20050801, 20050901, 20051001, 20051101, 20051201,
20060101, 20060201, 20060301, 20060401, 20060501, 20060601,
20060701, 20060801, 20060901, 20061001, 20061101, 20061201,
20070101, 20070201, 20070301, 20070401, 20070501, 20070601,
20070701, 20070801, 20070901, 20071001, 20071101, 20071201,
20080101, 20080201, 20080301, 20080401, 20080501, 20080601,
20080701, 20080801, 20080901, 20081001, 20081101, 20081201
)
GO
CREATE PARTITION SCHEME [ByOrderDateMonthRange]
AS PARTITION [ByOrderDateMonthPF]
ALL TO ([PRIMARY])
GO
-- Create a partitioned version of the FactResellerSales table
CREATE TABLE [dbo].[FactResellerSalesPtnd](
[ProductKey] [int] NOT NULL,
[OrderDateKey] [int] NOT NULL,
[DueDateKey] [int] NOT NULL,
[ShipDateKey] [int] NOT NULL,
[CustomerKey] [int] NOT NULL,
[EmployeeKey] [int] NOT NULL,
[PromotionKey] [int] NOT NULL,
[CurrencyKey] [int] NOT NULL,
[SalesTerritoryKey] [int] NOT NULL,
[SalesOrderNumber] [nvarchar](20) NOT NULL,
[SalesOrderLineNumber] [tinyint] NOT NULL,
[RevisionNumber] [tinyint] NULL,
[OrderQuantity] [smallint] NULL,
[UnitPrice] [money] NULL,
[ExtendedAmount] [money] NULL,
[UnitPriceDiscountPct] [float] NULL,
[DiscountAmount] [float] NULL,
[ProductStandardCost] [money] NULL,
[TotalProductCost] [money] NULL,
[SalesAmount] [money] NULL,
[TaxAmt] [money] NULL,
[Freight] [money] NULL,
[CarrierTrackingNumber] [nvarchar](25) NULL,
[CustomerPONumber] [nvarchar](25) NULL,
OrderDate [datetime] NULL,
DueDate [datetime] NULL,
ShipDate [datetime] NULL
) ON ByOrderDateMonthRange(OrderDateKey);
GO
-- Using simple or bulk logged recovery mode, and then the TABLOCK
-- hint on the target table of the INSERT…SELECT is a best practice
-- because it causes minimal logging and is therefore much faster.
ALTER DATABASE AdventureWorksDW2012 SET RECOVERY SIMPLE;
GO
-- Copy the data from the FactResellerSales into the new table
INSERT INTO dbo.FactResellerSalesPtnd WITH(TABLOCK)
SELECT * FROM dbo.FactResellerSales;
GO
-- Create the columnstore index
CREATE NONCLUSTERED COLUMNSTORE INDEX [csindx_FactResellerSalesPtnd]
ON [FactResellerSalesPtnd]
(
[ProductKey],
[OrderDateKey],
[DueDateKey],
[ShipDateKey],
[CustomerKey],
[EmployeeKey],
[PromotionKey],
[CurrencyKey],
[SalesTerritoryKey],
[SalesOrderNumber],
[SalesOrderLineNumber],
[RevisionNumber],
[OrderQuantity],
[UnitPrice],
[ExtendedAmount],
[UnitPriceDiscountPct],
[DiscountAmount],
[ProductStandardCost],
[TotalProductCost],
[SalesAmount],
[TaxAmt],
[Freight],
[CarrierTrackingNumber],
[CustomerPONumber],
[OrderDate],
[DueDate],
[ShipDate]
);
Paso #2: Vamos a correr una consulta y confirmaremos que se utilizó el índice almacenado por columnas.
- a. Presione Ctrl+M, o seleccione Include Actual Execution Plan desde el menú Query enSQL Server Management Studio para activar una representación gráfica del plan actual de ejecución.
- b. En el Query Editor corra la siguiente consulta:
SELECT SalesTerritoryKey, SUM(ExtendedAmount) AS SalesByTerritory
FROM FactResellerSalesPtnd
GROUP BY SalesTerritoryKey;

Beneficios en términos de rendimiento de los índices almacenados por columnas
Costo
SELECT SalesTerritoryKey, SUM(ExtendedAmount) AS SalesByTerritory
FROM FactResellerSales
GROUP BY SalesTerritoryKey;
-- Índice almacenado por columnas
SELECT SalesTerritoryKey, SUM (ExtendedAmount) AS SalesByTerritory
FROM FactResellerSalesPtnd
GROUP BY SalesTerritoryKey;
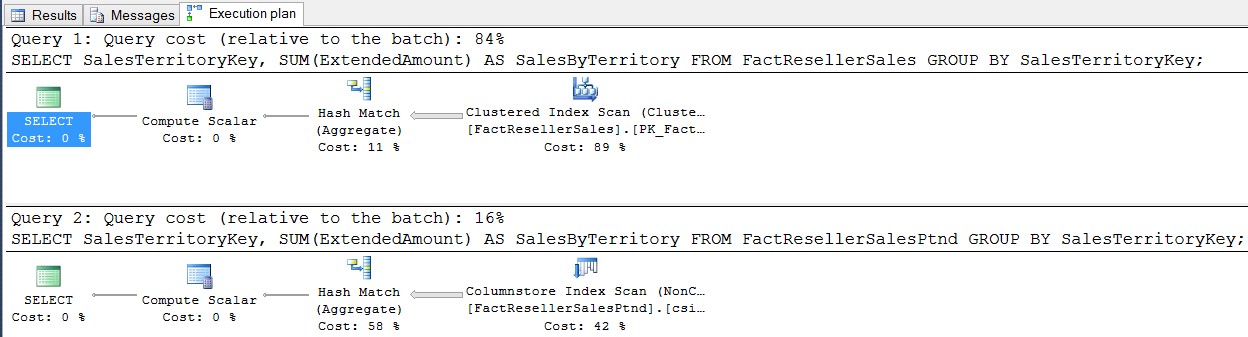
El costo relativo de la segunda consulta (utilizando un índice almacenado por columnas) es de 16% en comparación con el costo relativo de la primera consulta que es de 84% y utiliza un índice regular.
Actividad de disco
Al correr las consultas con STATISTICS IO ON (Muestra información relacionada con la cantidad de actividad de disco generada por las instrucciones Transact-SQL) se observa una mejora en rendimiento en la segunda consulta relacionada principalmente con las lecturas lógicas y read-ahead.
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
SET STATISTICS IO ON
SELECT SalesTerritoryKey, SUM(ExtendedAmount) AS SalesByTerritory
FROM FactResellerSales
GROUP BY SalesTerritoryKey;
SELECT SalesTerritoryKey, SUM(ExtendedAmount) AS SalesByTerritory
FROM FactResellerSalesPtnd
GROUP BY SalesTerritoryKey;
SET STATISTICS IO OFF
(10 row(s) affected)
Table 'FactResellerSales'. Scan count 1, logical reads 2982, physical reads 2, read-ahead reads 2972, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
(10 row(s) affected)
Table 'FactResellerSalesPtnd'. Scan count 1, logical reads 599, physical reads 4, read-ahead reads 235, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Tiempo
Al correr las consultas con STATISTICS TIME ON (Muestra el número de milisegundos necesarios para analizar, compilar y ejecutar cada instrucción) se observa una reducción de tiempo en la segunda consulta relacionada con el tiempo transcurrido y tiempo de CPU.
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
SET STATISTICS TIME ON
SELECT SalesTerritoryKey, SUM(ExtendedAmount) AS SalesByTerritory
FROM FactResellerSales
GROUP BY SalesTerritoryKey;
SELECT SalesTerritoryKey, SUM(ExtendedAmount) AS SalesByTerritory
FROM FactResellerSalesPtnd
GROUP BY SalesTerritoryKey;
SET STATISTICS TIME OFF
SQL Server Execution Times:
CPU time = 46 ms, elapsed time = 109 ms.
SQL Server Execution Times:
CPU time = 32 ms, elapsed time = 85 ms.
Conclusión
Expertos coinciden que la mejora en rendimiento obtenida al utilizar índices almacenados en columnas fluctúa entre un 10% a un 100%. Sin embargo como hemos mencionado en este artículo las aplicaciones que se benefician más son las relacionadas con altos volúmenes de lectura y no en sistemas altamente transaccionales. Los esquemas de estrella y copo de nieve usualmente forman parte de los datawarehouse y datamarts donde la velocidad de la extracción de los datos es más importante que la eficiencia en la manipulación de los datos. La tecnología de índices almacenados en columnas puede detectar y agilizar las consultas dirigidas a estos esquemas por lo cual son los escenarios típicos idóneos para su aplicación.