Comportamiento de Linked Servers cuando se utilizan en Joins
Recientemente trabajé en un caso donde un cliente presentaba problemas de desempeño con un query que realizaba un join con una tabla remota a través de un linked server. El cliente preguntó porque queries similares, que aplican condiciones sobre las tablas locales y retornaban pocos registros, generaban en algunas oportunidades consultas pesadas sobre el servidor remoto.
Es importante conocer como SQL Server maneja las consultas con tablas remotas ya que esto nos permite entonar nuestros queries y tener buenos tiempos de respuesta, ya que al usar la menor cantidad de IO y transmitir la menor cantidad de datos a través de la red obtendremos un mejor rendimiento.
Al trabajar con linked servers es muy importante estar consciente de que SQL Server debe enviar información desde el servidor remoto al servidor que hace la llamada para evaluar y aplicar la condición de JOIN.
Al usar Linked Servers en la cláusula JOIN, SQL Server compilará el mejor plan para ejecutar la consulta, evitando transmitir información innecesaria a través de la red y de esa forma disminuir el tiempo requerido para satisfacer el query. Vamos a revisar paso a paso algunos escenarios para observar las diferentes acciones que SQL Server ejecuta en una instancia remota de acuerdo al tipo de query que se esté ejecutando:
CASO 1: En el siguiente ejemplo se utiliza un JOIN con una tabla remota y sin filtros adicionales. Podemos observar en el servidor remoto que la sentencia ejecutada retorna todos los registros de la tabla, ya que al no existir ningún filtro todos los registros son necesarios para poder ejecutar el JOIN en el servidor local.
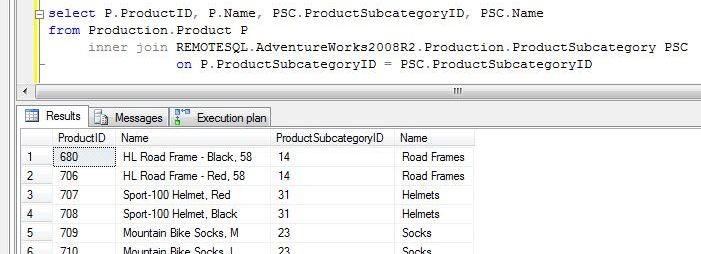
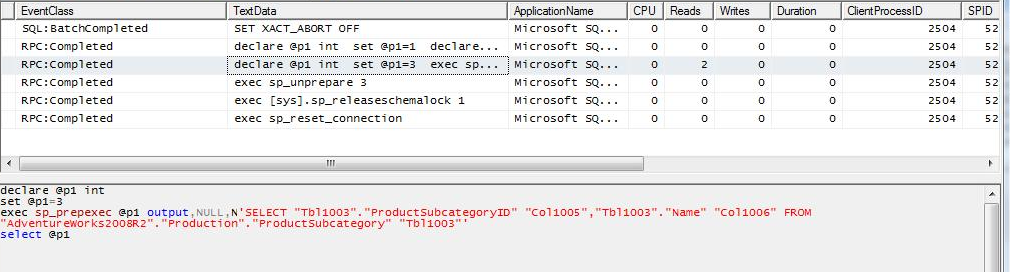
CASO 2: Al query del caso 1 aplicamos un filtro sobre una columna de la tabla remota. Se observa que SQL Server consulta las estadísticas de la tabla remota para construir el query más adecuado, y efectivamente se observa que la sentencia enviada filtra la tabla remota por el campo indicado en el query.
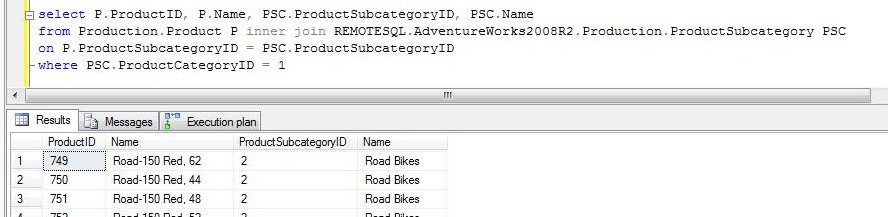
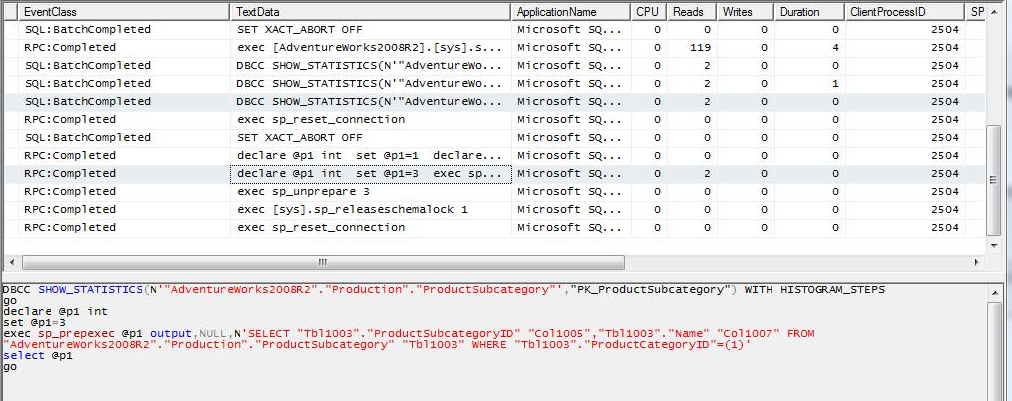
CASO 3a: Al query del caso 1 aplicamos un filtro sobre una columna de la tabla local. Se observa que SQL Server aplica primero el filtro local, y al obtener un número bajo (relativo para cada query) de valores diferentes para el filtro, construye un query para obtener sólo la información necesaria de la tabla remota usando la condición sobre el campo correspondiente, y lo ejecuta tantas veces como valores diferentes retorne el filtro sobre la tabla local
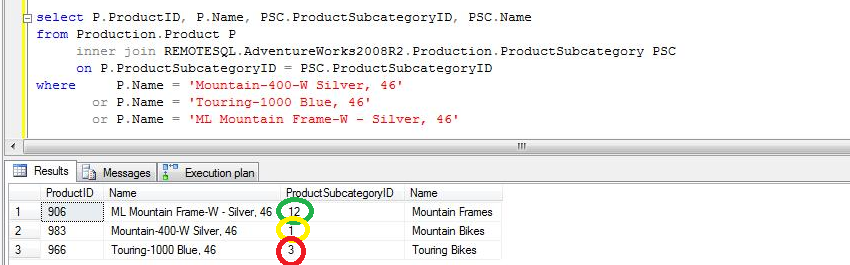
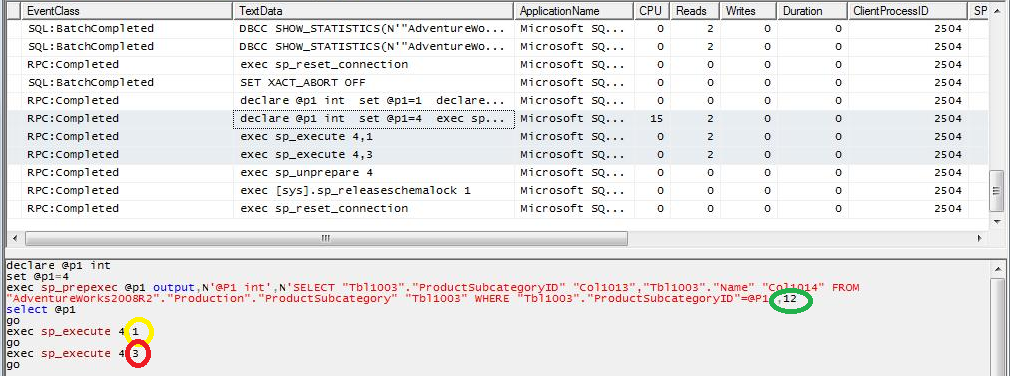
CASO 3b: Al query del caso 1 aplicamos un filtro sobre una columna de la tabla local, y se observa que SQL Server aplica primero el filtro local y al obtener un número alto (relativo para cada query) de valores diferentes para el filtro, SQL Server envía al servidor remoto un único query que no tiene filtros definidos y sólo indica los campos requeridos aunque ordenado por el campo de condición del JOIN para facilitar la operación, ya que requiere ejecutar un Merge Join en vez de un Nested Loop como el ejemplo anterior.
NOTA: esto se observa existiendo o no un índice por el campo del JOIN.
CASE 4a: Al query del caso 1 aplicamos un filtro sobre una columna de la tabla local que causa que ningún registro sea retornado para la tabla y por lo tanto para todo el query. Se puede observar que SQL Server no ejecuta en el servidor remoto ningún query para recuperar valores de la tabla remota (ya que no los necesita), sin embargo, si establece sesión a la instancia remota y ejecuta una serie de operaciones para consultar estadísticas y bloquear el esquema de la tabla remota.
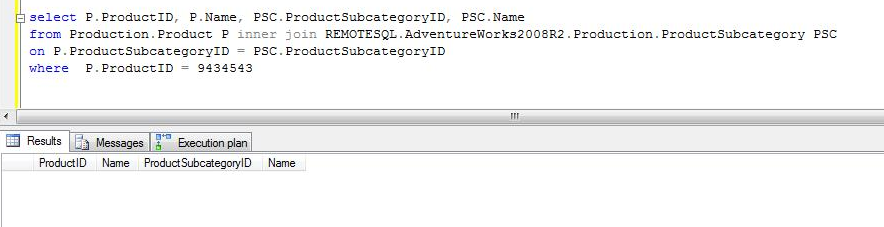
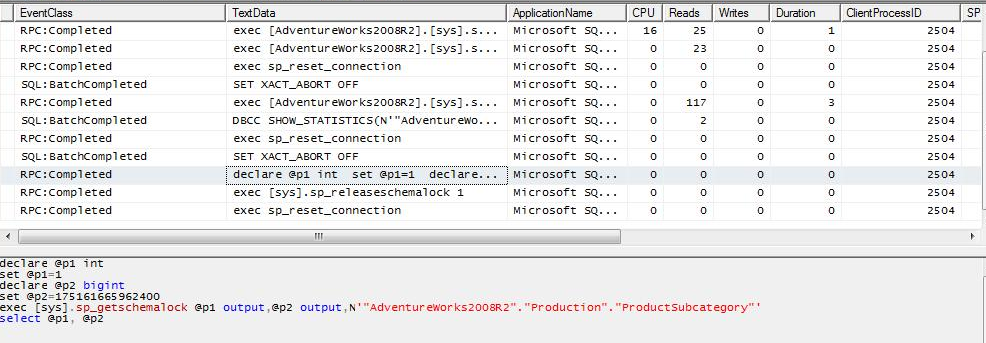
Lo mismo sucede al ejecutar el mismo query del caso 1, pero con una condición que causa que ningún valor sea retornado al aplicarlo sobre la tabla remota: ninguna consulta es ejecutada contra el servidor remoto luego de que se validan las estadísticas de la tabla remota.

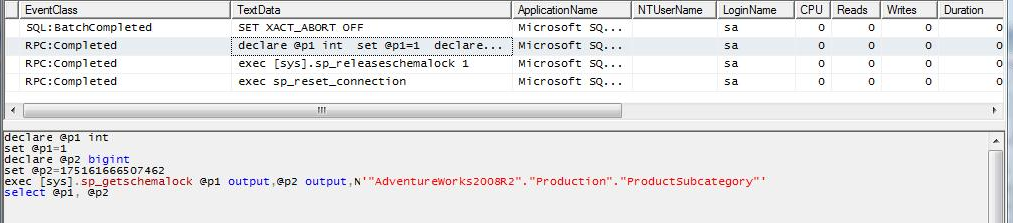
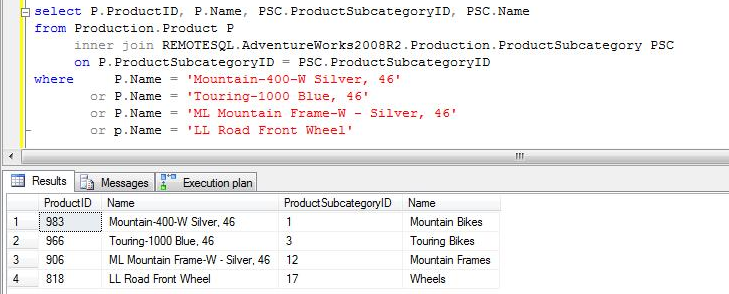
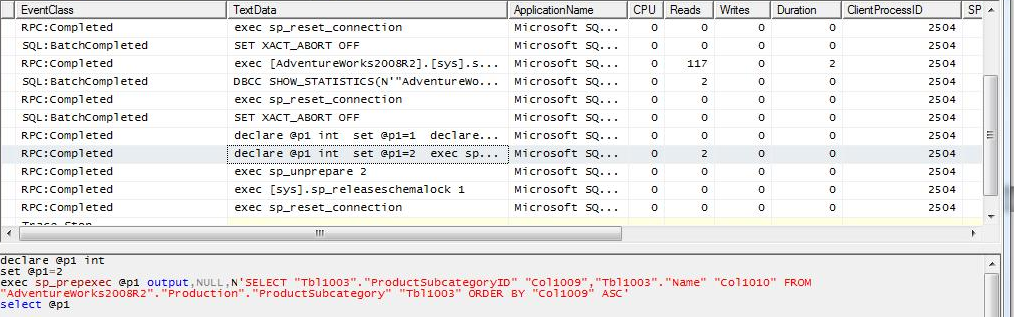
Caso 4b: Al query del caso 1 aplicamos un filtro sobre una columna de la tabla local que causa que ningún registro sea retornado para la tabla y por lo tanto para todo el query, y adicionalmente incluimos un filtro para la tabla remota sobre un campo que tiene definido una índice UNIQUE, se puede observar que a diferencia del caso 4a, SQL Server ejecuta una consulta en la instancia remota filtrando la tabla por el campo indicado
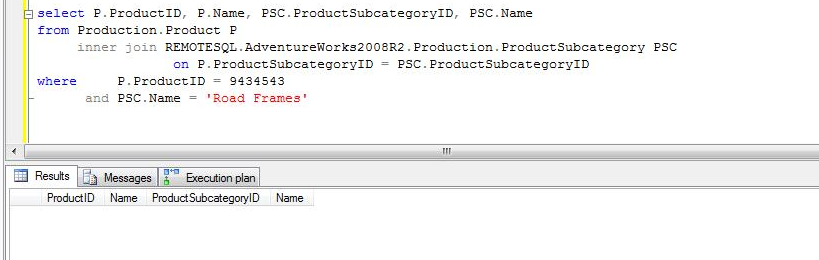
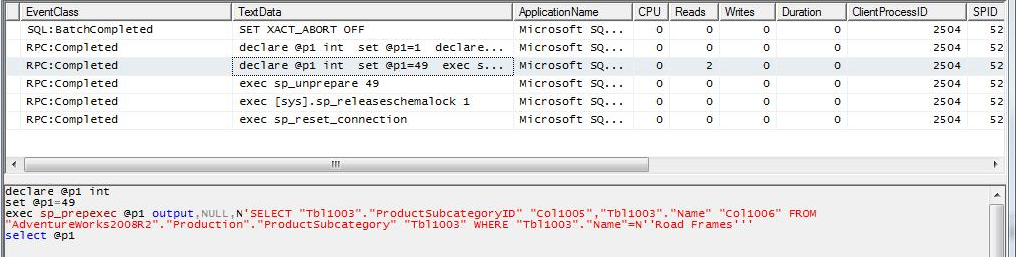
NOTA: Los LEFT JOINs y RIGTH JOINs se comportan exactamente de la misma manera que el EQUAL JOIN. Las sentencias enviadas al servidor remoto serán construidas dependiendo del volumen de datos, índices y estadísticas disponibles.
En el caso puntual del cliente que tenía el problema, la diferencia en la ejecución estaba dada por que a pesar de ser queries similares al agregar una o dos condiciones adicionales, y empeorado por las estadísticas desactualizadas tanto en la base de datos local como en la base de datos remoto, SQL Server no era capaz de generar el mejor query para ser ejecutado en el servidor remoto.
Luego de revisar el comportamiento de SQL Server al utilizar linked servers en clausulas JOIN, podemos concluir lo siguiente:
- Mantener estadísticas actualizadas no sólo es importante para que SQL Server genere planes de ejecución óptimos en operaciones locales, sino que son de gran utilidad al utilizar linked servers para definir si es necesario ejecutar alguna consulta contra la instancia remota y de ser necesario construir el mejor query posible para retornar la menor cantidad de registros posible.
- Aunque se determine que no es necesario ejecutar consultas contra el servidor remoto para satisfacer un query, SQL Server se conecta al servidor remoto, consulta estadísticas y aplica locks de esquema sobre el objeto remoto, por lo que puede existir aún retrasos para la ejecución del query por factores en la instancia remota, por ejemplo, un lock de esquema previo sobre el objeto utilizado generaría un bloqueo.
- Durante las fases de desarrollo y troubleshooting, analizar las consultas que SQL Server ejecuta en el servidor remoto es de gran utilidad para identificar la causa de lo que parece ser un comportamiento errático de SQL Server. Los casos 3a y 3b son ejemplos de casos en los que la distribución, volúmenes de datos y estadísticas puede causar diferencias de performance significativas. Los casos 4a y 4b son ejemplos de cómo al utilizar ciertas condiciones en determinadas estructuras puede modificar la forma en que SQL Server diseña los queries remotos.
“Las opiniones e ideas expresadas en este blog son las de los Autores y no necesariamente declaran o reflejan la opinión de Microsoft”