Tablas Particionadas
Durante una plática con todos los PFE’s de SQL Server, empezamos a platicar de los objetos que tienen millones y millones de registros, el acceso a este es muy lento y por consiguiente su administración. Con este preludio empezamos a tocar el tema de Tablas Particionadas, que en simples palabras es partir en múltiples pedacitos la tabla de millones de registros.
Esta característica se encuentra en SQL Server 2005, SQL Server 2008 y SQL Server 2008 R2. Para poder generar tablas particionadas es necesario identificar la columna mediante la cual va a ser realizar dicha partición. Para la creación de la tabla particionada es necesario realizar los siguientes pasos:
- Crear una función de partición (PARTITION FUNCTION), en esta se definirá el rango que cada partición va a almacenar. Para este caso existen dos métodos de Rangos, Izquierda (left) o Derecha (right), la diferencia del uso de este método, es la manera de realizar el análisis de rangos. Un ejemplo de la sentencia para cada método serían los siguiente
CREATE PARTITION FUNCTION pfAnualR(int) AS RANGE RIGHT FOR VALUES(2008,2009,2010,2011) |
CREATE PARTITION FUNCTION pfAnualL(int) AS RANGE LEFT FOR VALUES(2008,2009,2010,2011) |
Primera Partición < 2008 |
Primera Partición <= 2008 |
Segunda Partición >= 2008 |
Segunda Partición > 2008 |
Tercera Partición >= 2009 |
Tercera Particion > 2009 |
Cuarta Partición >= 2010 |
Cuarta Particion > 2010 |
Quinta Partición >= 2011 |
Quinta Particion > 2011 |
- Crear un esquema para la partición (PARTITION SCHEME) , en esta se definirán los FileGroupsdonde se almacenara cada partición, un ejemplo es el siguiente (para la ejecución correcta de este script, es necesario que se creen o existan 5 FileGroups llamados FG01, FG02, FG03, FG04, FG05):
CREATE PARTITION SCHEME psAnualR AS PARTITION pfAnualR TO ([FG01], [FG02], [FG03], [FG04], [FG05]) |
CREATE PARTITION SCHEME psAnualL AS PARTITION pfAnualL TO ([FG01], [FG02], [FG03], [FG04], [FG05]) |
- En la creación de la Tabla, la diferencia es que en lugar de definir un FileGroup donde se guardara el objeto, se define la Función de partición y la columna eje. Ejemplo
CREATE TABLE tblEstadosR (Ano int, Mes int, Dia int, Tipo varchar(30), Importe float) ON psAnualR(Ano) |
CREATE TABLE tblEstadosL (Ano int, Mes int, Dia int, Tipo varchar(30), Importe float) ON psanualL(Ano) |
- Una vez realizados estos pasos, se procede a realizar el llenado de las tablas particionadas
INSERT INTO tblEstadosR (Ano, Mes, Dia, Tipo, Importe) VALUES (2007,08,22,'Cargo',13.00) INSERT INTO tblEstadosR (Ano, Mes, Dia, Tipo, Importe) VALUES (2008,08,22,'Cargo',34.00)INSERT INTO tblEstadosR (Ano, Mes, Dia, Tipo, Importe) VALUES (2009,08,22,'Cargo',23.00)INSERT INTO tblEstadosR (Ano, Mes, Dia, Tipo, Importe) VALUES (2010,08,22,'Cargo',78.00)INSERT INTO tblEstadosR (Ano, Mes, Dia, Tipo, Importe) VALUES (2011,08,22,'Cargo',98.00)INSERT INTO tblEstadosR (Ano, Mes, Dia, Tipo, Importe) VALUES (2012,08,22,'Cargo',14.00) GO |
INSERT INTO tblEstadosL (Ano, Mes, Dia, Tipo, Importe) VALUES (2007,08,22,'Cargo',13.00)INSERT INTO tblEstadosL (Ano, Mes, Dia, Tipo, Importe) VALUES (2008,08,22,'Cargo',34.00)INSERT INTO tblEstadosL (Ano, Mes, Dia, Tipo, Importe) VALUES (2009,08,22,'Cargo',23.00)INSERT INTO tblEstadosL (Ano, Mes, Dia, Tipo, Importe) VALUES (2010,08,22,'Cargo',78.00)INSERT INTO tblEstadosL (Ano, Mes, Dia, Tipo, Importe) VALUES (2011,08,22,'Cargo',98.00)INSERT INTO tblEstadosL (Ano, Mes, Dia, Tipo, Importe) VALUES (2012,08,22,'Cargo',14.00) GO |
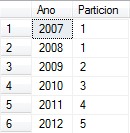
Para saber en qué partición se encuentra la data se utilizara el siguiente comando Transac-SQL $PARTITION, este regresa el número de partición en el cual se encuentra la data. Para el ejemplo que estamos realizando, el nombre de la Base de Datos utilizada es BDPrueba
SELECT Ano, BDPrueba.$Partition.pfAnualR(Ano) FROM tblEstadosR
SELECT Ano, BDPrueba.$Partition.pfAnualL(Ano) FROM tblEstadosL
El resultado de estos querys, explicaran el tipo de Rango RIGHT o LEFT de una manera más clara.
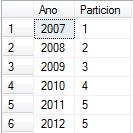
Primera Partición < 2008 Segunda Partición >= 2008 Tercera Partición >= 2009 Cuarta Partición >= 2010 Quinta Partición >= 2011 Quita Particion >= 2011 |
Primera Partición <= 2008 Primera Partición > 2008 Segunda Partición > 2009 Tercera Partición > 2010 Cuarta Partición > 2011 Quinta Particion > 2011 |
Con lo anterior, se ha aprendido los conceptos básicos de particionamiento de tablas, las ventajas principales al manejar esta característica son:
- Sliding Windows escenarios
- Mejora de actividades administrativas, como:
- Mantenimiento de Índices
- Compresión de particiones
- Manejo de Storage
Debido al manejo de paralelismo algunos queries se pueden comportar más lentos con tabla particionadas que sin tabla particionadas.
Posteriormente en el siguiente blog discutiremos temas como:
- Cuáles son las ventajas y desventajas de particionar una tabla
- Consideraciones cuando se implementa Sliding Windows.
“Las opiniones e ideas expresadas en este blog son las de los Autores y no necesariamente declaran o reflejan la opinión de Microsoft”