Temas de .NET
Pedido de ejecución con ThreadPool
Stephen Toub
Pmuchos componentes de mi sistema necesita ejecutar trabajo de forma asincrónica, lo que hace me pensar que la ThreadPool de Microsoft .NET Framework se la solución correcta. Sin embargo, tiene lo que CREO que es un requisito único: cada componente es necesario asegurarse de que sus elementos de trabajo se procesan en orden y que, como resultado, no dos de sus elementos de trabajo se ejecutan al mismo tiempo. Es correcto, sin embargo, para que varios componentes ejecutar simultáneamente con otros; de hecho, que se desea. ¿Dispone de las recomendaciones?
A este no es único como un problema como es posible que piensa, ya que se produce en una variedad de escenarios importantes, los basado en el mensaje pasa incluyendo. Considere una implementación de canalización que obtiene las ventajas de paralelismo al tener varias etapas de la canalización activa en cualquier momento.
Por ejemplo, podría tener una canalización de lee de datos de un archivo, se comprime, lo cifra y lo escribe a un nuevo archivo. La compresión puede realizarse simultáneamente con el cifrado, pero no en los mismos datos al mismo tiempo, desde la salida de uno debe ser la entrada a la otra. En su lugar, la rutina de compresión puede comprimir algunos datos y enviarla fuera a la rutina de cifrado que se va a procesar, en ese momento, la rutina de compresión puede trabajar en el siguiente fragmento de datos.
Dado que muchos algoritmos de compresión y cifrado mantener un estado que afecta a cómo futuros datos es comprimido y cifrado, es importante que se mantiene el orden. (Never mind que en este ejemplo, se trata con archivos, y podría ser interesante si se pudo descifrar y descomprimir los resultados para obtener el original con todos los datos en el orden correcto.)
Existen varias soluciones posibles. La primera solución es simplemente dedicar un subproceso a cada componente. Este DedicatedThread tendría una cola de (FIFO) primero en primer lugar fuera de elementos de trabajo que se va a ejecutar y un único subproceso que servicios de dicha cola. Cuando el componente tiene trabajo para ejecutarse, vuelca ese trabajo en la cola y finalmente el subproceso se obtenga alrededor recoge el trabajo y ejecutarla. Puesto que hay sólo un subproceso, se ejecutará sólo un elemento a la vez. Y como se se utiliza una cola FIFO, los elementos de trabajo se procesará en el orden que se han generado.
Según los con el ejemplo proporciona en la columna enero de 2008 .NET Matters Una clase de elementos de trabajo simple, se usará para representar el trabajo que se ejecuta, se muestra en la figura 1 . Una implementación de DedicatedThread que utiliza este tipo de elementos de trabajo se muestra en la figura 2 . La mayor parte de la implementación está en una libreta BlockingQueue <T> implementación (el 4.0 de .NET Framework incluye un BlockingCollection <T> tipo que sería un mejor ajuste para una implementación así). El constructor de DedicatedThread simplemente crea una BlockingQueue <t>, a continuación, deriva hasta un subproceso que espera continuamente otro elemento llegue a la cola y, a continuación, se ejecuta la instancia.
Figura 1, capturas de un elemento de trabajo
internal class WorkItem {
public WaitCallback Callback;
public object State;
public ExecutionContext Context;
private static ContextCallback _contextCallback = s => {
var item = (WorkItem)s;
item.Callback(item.State);
};
public void Execute() {
if (Context != null)
ExecutionContext.Run(Context, _contextCallback, this);
else Callback(State);
}
}
La Figura 2 DedicatedThread implementación
public class DedicatedThread {
private BlockingQueue<WorkItem> _workItems =
new BlockingQueue<WorkItem>();
public DedicatedThread() {
new Thread(() => {
while (true) { workItems.Dequeue().Execute(); }
}) { IsBackground = true }.Start();
}
public void QueueUserWorkItem(WaitCallback callback, object state) {
_workItems.Enqueue(new WorkItem {
Callback = callback, State = state,
Context = ExecutionContext.Capture() });
}
private class BlockingQueue<T> {
private Queue<T> _queue = new Queue<T>();
private Semaphore _gate = new Semaphore(0, Int32.MaxValue);
public void Enqueue(T item) {
lock (_queue) _queue.Enqueue(item);
_gate.Release();
}
public T Dequeue() {
_gate.WaitOne();
lock (_queue) return _queue.Dequeue();
}
}
}
Esto proporciona la funcionalidad básica para el escenario y pueden satisfacer sus necesidades, pero hay algunas desventajas importantes. En primer lugar, un subproceso que se está reservado para cada componente. Con uno o dos componentes, que no puede ser un problema. Pero para un lote de componentes, esto podría generar una expansión grave en el número de subprocesos. Que puede conducir a rendimiento incorrecto.
Esta implementación particular no es muy eficaz también. Por ejemplo, ¿qué sucede si desea destruya hacia abajo de un componente, ¿cómo saber el subproceso para detener el bloqueo? Y ¿qué sucede si se produce una excepción desde un elemento de trabajo?
Como un margen, resulta interesante tener en cuenta que esta solución es similar a lo que Windows usa en un surtidor de mensajes típico. El suministro de mensajes es un bucle en espera de los mensajes llegan a, despachando ellos (procesamiento ellos), a continuación, volver y que esperan para obtener más información. Los mensajes de una ventana determinada se procesan mediante un único subproceso. Las similitudes son demuestra el código de la figura 3 , que debe presentar comportamiento mucho como el código en la figura 2 . Un subproceso nuevo se marcha que crea un control, se garantiza que se ha inicializado su identificador y utiliza Application.Run para ejecutar un bucle de mensajes. A la cola un elemento de trabajo a este subproceso, simplemente método se utiliza el control BeginInvoke. Tenga en cuenta que no me recomendar este método, pero en su lugar sólo señalador que, en un nivel alto, es el mismo concepto básico como la solución DedicatedThread que ya se muestra.
Figura 3 similitudes con un bucle de mensajes de interfaz de usuario
public class WindowsFormsDedicatedThread {
private Control _control;
public WindowsFormsDedicatedThread() {
using (var mre = new ManualResetEvent(false)) {
new Thread(() => {
_control = new Control();
var forceHandleCreation = _control.Handle;
mre.Set();
Application.Run();
}) { IsBackground = true }.Start();
mre.WaitOne();
}
}
public void QueueUserWorkItem(WaitCallback callback, object state) {
_control.BeginInvoke(callback, state);
}
}
Una segunda solución implica el uso del ThreadPool para su ejecución. En vez de movimiento hasta un subproceso nuevo, personalizado por cada componente que servicios de una cola privada, se le mantener sólo la cola por componente, tal que no dos elementos de la misma cola nunca se atenderá al mismo tiempo. Esto tiene las ventajas de permitir la ThreadPool controlar cómo muchos subprocesos se necesitan, para controlar su inserción y retirada, para controlar los problemas de confiabilidad y para que fuera de la empresa de movimiento hasta nuevos subprocesos, que con poca frecuencia es lo correcto para realizar.
Una implementación de esta solución se muestra en la figura 4 . La clase fifoExecution mantiene sólo dos campos: una cola de elementos de trabajo que se va a procesar y un valor booleano que indica si se ha emitido una solicitud a la ThreadPool para procesar los elementos de trabajo. Ambos estos campos están protegidos por un bloqueo en la lista de elementos de trabajo. El resto de la implementación es simplemente dos métodos.
La figura 4 implementación FifoExecution
public class FifoExecution {
private Queue<WorkItem> _workItems = new Queue<WorkItem>();
private bool _delegateQueuedOrRunning = false;
public void QueueUserWorkItem(WaitCallback callback, object state) {
var item = new WorkItem {
Callback = callback, State = state,
Context = ExecutionContext.Capture() };
lock (_workItems) {
_workItems.Enqueue(item);
if (!_delegateQueuedOrRunning) {
_delegateQueuedOrRunning = true;
ThreadPool.UnsafeQueueUserWorkItem(ProcessQueuedItems, null);
}
}
}
private void ProcessQueuedItems(object ignored) {
while (true) {
WorkItem item;
lock (_workItems) {
if (_workItems.Count == 0) {
_delegateQueuedOrRunning = false;
break;
}
item = _workItems.Dequeue();
}
try { item.Execute(); }
catch {
ThreadPool.UnsafeQueueUserWorkItem(ProcessQueuedItems,
null);
throw;
}
}
}
}
El primer método es QueueUserWorkItem, con una firma que coincide con que expone el ThreadPool (el ThreadPool también proporciona una sobrecarga de comodidad que acepta sólo un WaitCallback, una sobrecarga podría optar por agregar). El método crea primero un elementos de trabajo para almacenarlo y, a continuación, toma el bloqueo. (No hay ningún estado compartido se obtiene acceso al crear los elementos de trabajo. Por lo tanto, para mantener el bloqueo tan pequeño como sea posible, esta captura del elemento se realiza antes de realizar el bloqueo.) Una vez que se mantiene el bloqueo, el elemento de trabajo creado está en cola en la cola de elemento de trabajo.
El método, a continuación, comprueba si una solicitud se realizó la ThreadPool para procesar los elementos de trabajo en cola y, si no ha realizado una, realiza tal una solicitud (y las notas para el futuro). Esta solicitud a la ThreadPool es simplemente usar uno de subprocesos los ThreadPool para ejecutar el método ProcessQueuedItems.
Cuando se invoca por un subproceso ThreadPool, ProcessQueuedItems entra en un bucle. En este bucle, toma el bloqueo y, mientras mantiene el bloqueo, comprueba si existen más los elementos de trabajo que se va a procesar. Si no hay ninguna, restablece el indicador de solicitud (, que futuros elementos en cola se solicitar procesamiento del fondo de nuevo) y termina. Si no hay elementos de trabajo que se va a procesar, toma el siguiente, libera el bloqueo, ejecuta el procesamiento y inicia todos los más de nuevo, ejecutando hasta que no hay ningún más elementos en la cola.
Ésta es una implementación sencilla pero eficaz. Un componente ahora puede crear una instancia de FifoExecution y utilizarla para programar elementos de trabajo. Por cada instancia de FifoExecution, sólo un elemento de trabajo en cola podrán ejecutar en un tiempo, y los elementos de trabajo en cola se ejecutarán en el orden que se ponen en cola. Además, los elementos de distinto FifoExecution instancias será capaz de ejecutar simultáneamente de trabajo. Y lo mejor es que se está ahora fuera de la empresa de administración de subprocesos, dejando todo el trabajo difícil (pero muy importante) de administración de subprocesos a la ThreadPool.
En el peor caso, donde cada componente es mantener el grupo saturado con el trabajo, la rampa probable de se ThreadPool hasta tener un subproceso por cada componente, igual que en la implementación de DedicatedThread original. Pero que sólo sucederá si se considera apropiada por la ThreadPool. Si los componentes no conserva el fondo saturado, muchos subprocesos menos será necesarios.
Hay ventajas adicionales, como permitir que el ThreadPool hacer lo correcto con respecto a excepciones. En la implementación DedicatedThread, ¿qué ocurre si el procesamiento de un elemento produce una excepción? El subproceso se vienen bloquea hacia abajo, pero dependiendo de la configuración de la aplicación, el proceso puede no ser destruido. En ese caso, los elementos de trabajo iniciará queueing hasta el DedicatedThread pero ninguno nunca obtener procesarán. FifoExecution, la ThreadPool sólo terminará hasta agregar más subprocesos para compensar los que se ha desplazado fuera.
Figura 5 muestra una aplicación de demostración sencilla que utiliza la clase FifoExecution. Esta aplicación tiene tres fases en una canalización. Cada fase escribe el ID del fragmento de datos actual que está trabajando (que es simplemente la iteración del bucle). A continuación, hace algún trabajo (representado aquí por un Thread.SpinWait) y pasa datos (de nuevo, sólo la iteración del bucle) junto a la siguiente fase. Cada paso envía su información con un número diferente de fichas para que sea muy fácil ver los resultados separados fuera. Como puede observar en el resultado que se muestra en la figura 6 , cada fase (una columna) es mantener el trabajo correctamente ordenado.
Demostración de la figura 5 de FifoExecution
static void Main(string[] args) {
var stage1 = new FifoExecution();
var stage2 = new FifoExecution();
var stage3 = new FifoExecution();
for (int i = 0; i < 100; i++) {
stage1.QueueUserWorkItem(one => {
Console.WriteLine("" + one);
Thread.SpinWait(100000000);
stage2.QueueUserWorkItem(two => {
Console.WriteLine("\t\t" + two);
Thread.SpinWait(100000000);
stage3.QueueUserWorkItem(three => {
Console.WriteLine("\t\t\t\t" + three);
Thread.SpinWait(100000000);
}, two);
}, one);
}, i);
}
Console.ReadLine();
}
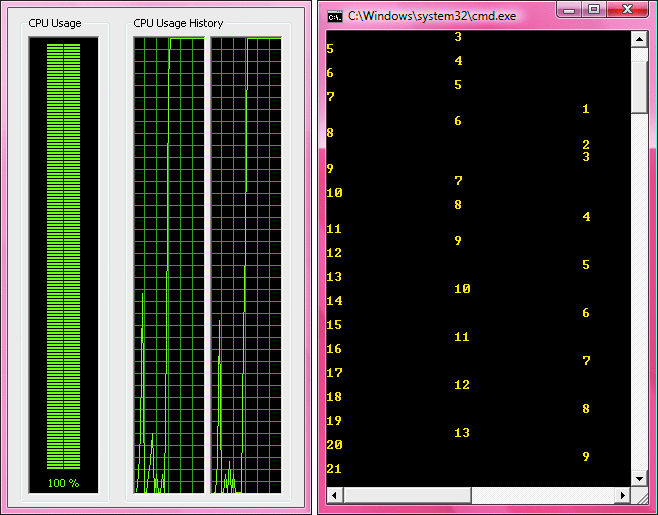
La figura 6 la salida de aplicaciones de demostración
También resulta interesante observar que hay una falta de fairness entre las fases de la canalización. Puede ver, por ejemplo, que stage1 en la figura 6 es ya hasta 21, iteración mientras stage2 está aún en 13 y stage3 está en 9. Esto se en gran parte debido a mi implementación de ProcessQueuedItems. La aplicación de ejemplo inserta muy rápidamente 100 trabajo elementos en stage1 y, por tanto, el subproceso del grupo que stage1 los servicios de se es probable que sentarse en el bucle ProcessQueuedItems y no devolverá hasta que hay trabajo stage1 no más. Esto proporciona, una diferencia desleal a través de las demás fases. Si ve un comportamiento similar en su aplicación, y es un problema, puede aumentar fairness entre las fases modificando la implementación de ProcessQueuedItems a uno más similares a las siguientes:
private void ProcessQueuedItems(object ignored) {
WorkItem item;
lock (_workItems) {
if (_workItems.Count == 0) {
_delegateQueuedOrRunning = false;
return;
}
item = _workItems.Dequeue();
}
try { item.Execute(); }
finally {
ThreadPool.UnsafeQueueUserWorkItem(ProcessQueuedItems,
null);
}
}
Ahora, incluso si hay más elementos que se va a procesar, ProcessQueuedItems no bucle pero en su lugar se recursivamente cola propia para la ThreadPool, por lo tanto asignar prioridades a sí mismo detrás de los elementos de otras fases. Con esta modificación, el resultado de la aplicación en la figura 5 ahora será como se muestra en figura 7 . Puede ver en este nuevo resultado que programación es en realidad tratar stage2 y stage3 con más fairness que antes (aún hay algunos posposición entre las fases, pero eso es que se espera dado que se trata de una canalización).
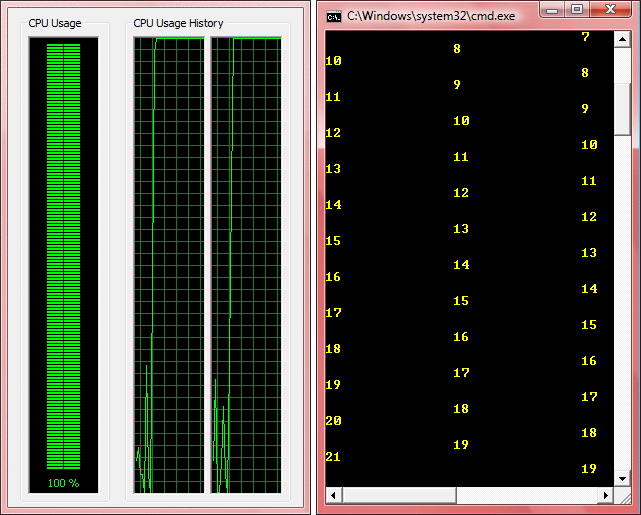
La figura 7 nuevo resultado con programación Fairer
Por supuesto, este aumento fairness no incluye de forma gratuita. Cada elemento de trabajo ahora implica un viaje adicional mediante el programador, que agrega algunos costos. Deberá decidir si éste es un equilibrio que puede realizar para la aplicación; por ejemplo, si es considerable en todo el trabajo que está realizando en los elementos de trabajo, esta sobrecarga debe ser insignificante y inadvertido.
Esto es sólo un ejemplo más de cómo es posible crear sistemas encima de la ThreadPool que agregan funciones sin tener que crear grupos de subprocesos personalizado. Para obtener otros ejemplos, vea las ediciones anteriores de la importante de .NET columna en MSDN Magazine .
Envíe sus preguntas y comentarios a netqa@Microsoft.com.
Stephen Toub es un administrador de programas jefe en el equipo de plataforma informática paralela en Microsoft. También es un editor colaborador de MSDN Magazine.