Este artículo proviene de un motor de traducción automática.
Ejecución de prueba
Analizar la exposición del proyecto Y riesgos con PERIL
Dr. James McCaffrey
Descarga de código de la Galería de código de MSDN
Examinar el código en línea
Contenido
META-los riesgos
Identificación de riesgos
Análisis de riesgos
Ajustar hacia arriba
Todos los proyectos de software enfrentan los riesgos. Un riesgo es un evento, que puede o no puede producirse y que provoca algún tipo de pérdida. La relación entre los riesgos y pruebas de software es sencilla. Porque, excepto en situaciones excepcionales, no puede exhaustively probar un sistema de software, el análisis de riesgos revelan problemas que pueden provocar la pérdida de la mayoría. Puede utilizar esta información para ayudarle a dar prioridad a los esfuerzos de comprobación. En la columna de este mes, presentan prácticas las técnicas que puede utilizar para identificar y analizar los riesgos que implica con un proyecto de software. Vamos a empezar.
Imagine una situación hipotética en la que se está desarrollando una aplicación basada en Web de ASP.NET de algún tipo. la figura 1 muestra algunas de las ideas clave y problemas asociados con el análisis de riesgos de software. El proceso general de análisis de riesgos implica la identificación de los riesgos, estimar cómo es probable que cada uno de los riesgos es, determinación de la pérdida asociada con cada uno de los riesgos y combinación de probabilidad y pérdida de información en un valor denominada exposición al riesgo.
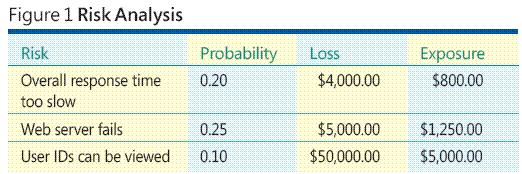
Según los datos de ejemplo en la figura 1 , el riesgo de que "ID de usuario se pueden ver" tiene la mayor exposición, por lo que otros factores que igual, es probable que se desea ponerla a una prioridad superior para probar esta opción para evitar que el riesgo de convertirse en una realidad. ¿Pero cómo puede identificar los riesgos?¿Puede cómo calcular la probabilidad del riesgo y pérdida?¿Puede seguir realiza análisis de riesgos si no puede calcular la probabilidad del riesgo y pérdida?
Aunque ha habido varios esfuerzos para formalizar y estandarizar la terminología de análisis de riesgos, en la práctica términos diferentes suelen utilizarse en dominios con distintos problemas. VOY a utilizar el término de análisis de riesgos" para significar calcular la exposición al riesgo multiplicando la probabilidad de riesgo o probabilidad por la pérdida de riesgo, o para significa el proceso general de identificación, análisis y administración de riesgos de proyecto de software.
En pesar de que el análisis de riesgos es una parte vital importancia del desarrollo de software, según mi experiencia, muchas técnicas de análisis de riesgos no se conocen ampliamente en el software prueba comunidad. Si busca en el Web, encontrará decenas de miles de referencias en análisis de riesgos de software. Sin embargo, la mayoría de estos hace referencia a cualquier dirección riesgos análisis en un nivel muy alto y no representen técnicas prácticas o presente sólo una técnica de análisis de riesgo específicos y no explique cómo se adapta la técnica en un marco de análisis de riesgo general. Le presentan tanto una introducción a análisis de riesgos y técnicas útiles que puede emplear inmediatamente en su entorno de desarrollo de software.
En las secciones de esta columna, describen dos metadatos de los riesgos que son comunes a todos los proyectos de software. A continuación, presente tres formas, que puede identificar riesgos específicos asociados con el proyecto de software y tres formas de analizar el riesgo. En concreto, se presentan una interesante nuevo riesgo análisis técnica denominada exposición del proyecto con clasificación consecuencias y probabilidad (PERIL) que es especialmente útil en un entorno de desarrollo de software. Concluir con una explicación breve de la administración de riesgos. Creo que las técnicas presentadas aquí se convertirá en una adición muy valiosa a su kit de herramientas software de prueba, desarrollo y administración.
META-los riesgos
Dos tipos especiales de análisis de riesgos de proyecto de software son lo que llame al tiempo y costos de análisis de riesgos de metadatos. Administración de proyectos tradicional define un concepto que tiene diferentes nombres incluidos "del proyecto de administración triple restricción" y "el triángulo de administración de proyecto." La idea es, en resumen, que prácticamente todos los proyectos tiene tres factores limitación: costo, programación y ámbito. Costo es ¿cuánto dinero tiene que emplee en el proyecto, plan es ¿cuánto tiempo tiene que completar el proyecto y ámbito es el conjunto de características del proyecto requerido y su calidad.
Las restricciones del proyecto de tres tener una variedad de alias. Por ejemplo, Costo también se denomina presupuesto o dinero. A menudo se denomina programación hora o duración. Y ámbito se denomina a veces, las características, o calidad o incluso características y calidad. Tenga en cuenta que esta restricción de las características y calidad última puede estar (y a menudo es, de hecho) se considera que dos restricciones distintas.
Una noción clave es que un cambio en cualquiera de las restricciones es probable que hará que un cambio en una o ambas de las otras dos restricciones. Por ejemplo, si está desarrollando una aplicación de software y es de repente necesario para finalizar el proyecto en un período de tiempo más corto que el planeado originalmente, probablemente se debe gastar más dinero (por ejemplo, para comprar recursos adicionales o subcontratar parte del proyecto) o cortar algunas características o de calidad. Si el presupuesto para el proyecto se cortan, probablemente deberá que ampliar el tiempo para finalizar el proyecto, quitar algunas características o reducir la calidad de su proyecto. Mediante el paradigma de triángulo de administración de proyecto, como pruebas de software está diseñada para mejorar la calidad de un sistema, se deduce que el dos niveles de más altos de riesgo en un proyecto de software son que el proyecto no finaliza a tiempo y que se ejecuta el proyecto por encima del presupuesto.
Hay una forma relativamente sencilla pero eficaz para calcular los riesgos de programación y el costo generales para un proyecto de software. Echemos un vistazo sólo a la hora y programación de metadatos riesgo (análisis funciona de riesgo de presupuesto y costo de la misma manera). El primer paso en un análisis de metadatos de alto nivel de riesgo es para dividir el proyecto en general en fragmentos más pequeños, más fáciles de administrar de actividades.
Por ejemplo, supongamos está trabajando en un pequeño proyecto de aplicación Web, y el proyecto debe completarse en 30 días de trabajo. Para iniciar el análisis de riesgos de metadatos, lista de todas las actividades implicadas en el proyecto. Aquí, el enfoque más común consiste en crear lo que se denomina una estructura detallada del trabajo (EDT), que puede ver en la figura 2 . Crea una tarea nivel superior que consta de todo el proyecto. A continuación, se dividen esa tarea en un número de subtareas más pequeños, normalmente sobre tres a las tareas de siete. Repita el proceso, descomponer cada subtarea en subtareas más pequeños hasta que alcance el nivel de detalle adecuado para su entorno.
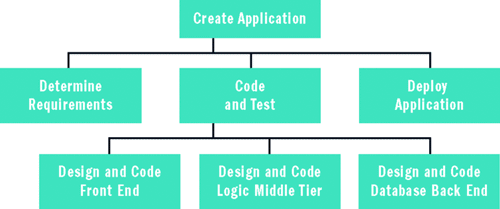
La Figura 2 estructura detallada de trabajo
El nivel inferior, las tareas de nodo de hoja se denominan los paquetes de trabajo. Exactamente cómo descomponer las tareas y cómo granular que realice la WBS depende de una serie de factores. Por ejemplo, en un entorno de desarrollo ágil, se puede bien decidir que una estructura de desglose de trabajo de profundidad de dos niveles simple satisface sus necesidades. O, si está trabajando en un proyecto de software muy grandes y complejos mediante una metodología de ciclo de vida de desarrollo software tradicionales, puede que tenga decenas de miles de paquetes de trabajo.
Puede crear manualmente una WBS pequeña, utilizar herramientas de productividad genérico tal como Microsoft Office Excel o utilizar herramientas sofisticadas tal como Microsoft Office Project. Una estructura de descomposición de trabajo no contiene información secuenciación, tiempo y costo. En otras palabras, una estructura de descomposición de trabajo le indica qué debe hacerse, pero no en qué orden y no indica cómo tendrá tiempo para cada tarea o cuánto cada costará. Después de crear la estructura de descomposición del trabajo, normalmente, el paso siguiente es utilizar los paquetes de trabajo para crear lo que se denomina un diagrama de prioridad.

La figura 3 diagrama de prioridad
El diagrama de prioridad agrega información de secuencia. El diagrama que se muestra en la figura 3 indica que la tarea de los requisitos de debe se completado antes de la tarea final atrás de base de datos, que a su vez debe realizarse antes de pueden comenzar en tanto la tarea de nivel medio y la tarea solicitudes de cliente. Estas últimos dos tareas se pueden realizar en paralelo según en el diagrama de prioridad. Por último, tanto la tarea de nivel medio y la tarea solicitudes de cliente deben realizarse antes de la tarea de implementación de aplicaciones puede comenzar.
Después de crear un diagrama de prioridad con su información de secuencia, el paso siguiente en un análisis de riesgos de metadatos de tiempo es estimar el tiempo necesario para cada paquete de trabajo individuales. Aunque puede calcular cada vez como un punto de datos única, un enfoque mejor consiste en proporcionar estimaciones de tres, una estimación optimista, una estimación de la mejor estimación y una estimación pesimista.
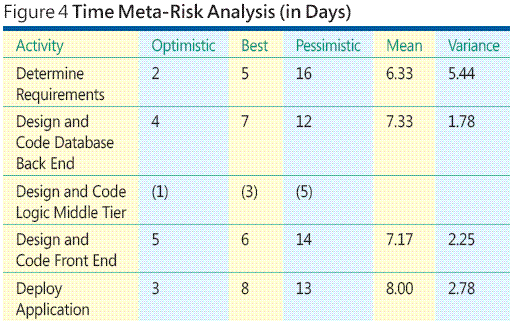
ACEPTAR, pero sólo ¿de donde estos cálculos proceden?Determinar las estimaciones de tiempo y costos forma parte el por mucho más difícil de análisis de riesgo de metadatos de proyecto de software. Hay muchas formas para estimar el tiempo de actividad y el costo. Puede utilizar experiencia histórico, esos intentos, modelos de matemáticas sofisticadas y así sucesivamente. Las técnicas que utiliza dependerá de su situación en particular. Con independencia del método se utiliza, estimar el tiempo y costo de un conjunto de actividades más pequeñas es mucho más fácil que estimar el tiempo y el costo de una actividad monolítica. La tabla en la figura 4 muestra un ejemplo tiempo riesgo meta análisis.
Al que se analiza " optimista ", datos de tiempo mejor estimación y pesimista, normalmente se utiliza una distribución matemática simple denominada la distribución beta. La media o promedio, de una distribución beta se calcula como esto:
(optimistic + (4 * best-guess) + pessimistic) / 6
Por lo que para la tarea de implementación de aplicaciones, el tiempo estimado promedio para finalización es:
mean = (3 + 4*8 + 13) / 6
= 48 / 6
= 8.0 days.
Observe que una media de la versión beta es un promedio ponderado con pesos 1, 4 y 1.Por lo tanto, la varianza de una distribución beta viene dado por esta fórmula:
((pessimistic - optimistic)/6)²
Por lo que para la tarea de implementación de aplicaciones la variación es:
variance = ((13 - 3) / 6)²
= (10/6)²
= (1.6667)²
= 2.78 days²
La desviación estándar total para el proyecto es la raíz cuadrada de la suma de las variaciones de actividad. Por lo tanto, en este ejemplo, la ecuación el siguiente aspecto:
std. deviation = sqrt(5.44 + 1.78 + 2.25 + 2.78)
= sqrt(12.25)
= 3.50 days
Observe que los cálculos no utilizan los datos de la actividad de diseño y código de lógica de medio de nivel. Debido a la actividad de lógica de medio de nivel puede realizarse en paralelo con la actividad de la base de datos back-end y la actividad de aplicaciones para usuario no puede comenzar hasta que han terminado ambas actividades paralelas, la actividad paralela más corta (lógica intermedio-nivel) no explícitamente contribuye a la hora general para completar el proyecto.
Este tipo de análisis se denomina el método de ruta crítica (CPM) y es una técnica de administración estándar del proyecto. Con las programación Media y la variación de datos calculados, ahora puede calcular la probabilidad de que todo el proyecto tardar más de 30 días para completar:
z = (30.00 - 28.83) / 3.50 = 0.33
p(0.33) = 0.6293
p(late) = 1.0000 - 0.6293 = 0.3707
En primer lugar, se calcula el denominado valor de z, que es igual a la cantidad de tiempo que se ha programado para finalizar el proyecto (en este caso, 30 días) menos el tiempo estimado para finalización (28.83 días), dividido por la desviación estándar de tarea (3.50 días). A continuación, se toma el valor de z (0.33) y buscar el valor p correspondiente en una tabla de la distribución normal estándar o utilizar la Excel NORMSDIST función (0.6293). Por último, si se restan del valor p de 1.0000 para obtener la probabilidad de que su proyecto pasará a través de programación.
Va a realizar un análisis de una cola aquí porque sólo ocupa si tarda más que programado y no importa si lleva menos tiempo. Con esta datos de ejemplo, es la probabilidad de que la aplicación Web tarda más de 30 días para completar 0.3707 o casi el 40 %, una situación de riesgo en su lugar. Si piensa sobre ella por un momento, el resultado debe sentido. La programación planeada de 26 días de desarrollo es demasiado cercanos al límite de proyecto de 30 días y lo que es posible que no tenga suficiente espacio de wiggle para cuenta para las variaciones de programación.
Obviamente, los resultados de metadatos de riesgos son sólo tan buenos como los datos de entrada, el tiempo de estimaciones en este caso. Si las estimaciones de entrada son incorrectas, cantidad de análisis estadístico no puede generar resultados significativos. Puede calcular la probabilidad de riesgo de metadatos que el proyecto se pasan por encima del presupuesto mediante tal como se ha sólo muestra la misma técnica para plan. Una vez que la probabilidad de que su proyecto pasará a través de programación, puede calcular la exposición al riesgo de los metadatos de riesgo si se puede calcular la pérdida del monetario por haber se en tiempo de ejecución.
En algunas situaciones, puede ser en un contrato para crear un sistema de software y el contrato puede tener bien definidos y importantes reducciones en tiempo de ejecución. Por ejemplo, suponga que los estados de contrato que hay una penalización $10,000.00 para la entrega en tiempo de ejecución. La exposición de metadatos de riesgos es $ 10,000.00 * 0.3707 = $3,707. En otros casos, el costo de un proyecto de software en tiempo de ejecución es demasiado difícil de calcular más allá de "muy, muy caro."
Pero observe que incluso sin calcular una exposición al riesgo, el análisis de riesgos de metadatos de tiempo proporciona información útil. Si examina los datos en la figura 4 , puede ver que la tarea de determinar los requisitos tiene la variación de programación mayor. Por lo tanto, simplemente aplicar recursos adicionales desde el principio del proyecto puede reducir la variación de tarea, que a su vez reducirá la probabilidad de que va a través de programación.
Identificación de riesgos
A diferencia de tiempo y costos metadatos de los riesgos, donde se pueden determinar los eventos de riesgo en un poco paso a paso (aunque no en absoluto sencilla) forma por manera iterativa descomponer las tareas en subtareas más pequeñas, la identificación de riesgos en el caso general es mucho menos mecánica. En un entorno de pruebas y desarrollo de software, hay tres métodos principales para la identificación de riesgos: en función de taxonomía, basada en escenarios y en función de la especificación.
Una taxonomía es simplemente una lista de clasificación. Tenga en cuenta la analogía siguiente. Va a realizar un viaje en un avión, por tanto, utilizar una lista de aviso estándar que se utiliza antes cada viaje. La lista contiene instrucciones o preguntas como "pendientes tengo mi ID?" y "tiene comprobar para ver si el vuelo de tiempo?"
En los años, muchas personas y organizaciones creado Taxonomías de riesgos de software. Una dicha lista se creó por Barry Boehm, un pioneer anticipado y de un investigador conocido en el área de riesgos del proyecto de software. En 1989 Boehm identifica una taxonomía de riesgos de software 10 superior y actualiza la lista en 1995. La versión de 1995 de la taxonomía de riesgos de proyecto de software 10 superior se muestra aquí:
- Déficits personal
- Planes, presupuestos, de proceso
- Software comercial comercial, los componentes externos
- No coinciden los requisitos
- No coincide de interfaz de usuario
- Arquitectura, rendimiento, calidad
- Los cambios de requisitos
- Software heredado
- Externamente realiza las tareas
- Straining informática
Debería ser evidente que lista de riesgos del Boehm 10 no inmediatamente identifica los riesgos. En su lugar, la taxonomía simplemente proporciona punto de partida para comenzar a pensar en riesgos aplicables a su proyecto de software. Por ejemplo, incluya el riesgo de primero, "déficits personal," tener muchos riesgos posibles diferentes relacionados con la asignación de personal. El proyecto simplemente puede no tener suficiente ingenieros para crear la aplicación o sistema. O un ingeniero de clave puede dejar el proyecto a medio camino mediante programación del proyecto. O el personal de ingeniería no es posible que tenga los conocimientos técnicos necesarios para el proyecto. Y así sucesivamente.
La mayoría de las categorías de riesgo 10 superior debe estar familiarizada, excepto para quizás la décima riesgo categoría, "straining informática". Se trata de un poco de una categoría de todos los catch- y cubre las tareas relacionadas con cosas tales como análisis técnicos, análisis de costos y beneficios y prototipos.
Otra lista de taxonomía de riesgos de software utilizados se creó por Software Engineering Institute (SEI). El SEI es uno de 36 federally funded investigación y desarrollo de centros de en los EE.UU. Estos centros de referencia son organizaciones de híbrido bastante extraño que son financiadas por dinero pública, pero venden productos y servicios. La taxonomía de riesgos SEI software creada en 1993 y consta de las preguntas aproximadamente 200. ¿Por ejemplo, la pregunta 1 es, "son estables los requisitos?Si no, lo que es el efecto en el sistema (calidad, funcionalidad, programación, integración, diseñar, probar)? " Pregunta #16 es, cómo que determinar la viabilidad de algoritmos y diseños (prototipos, modelos, análisis, simulación)?" Puede encontrar elTaxonomía de riesgos SEIen un apéndice al documento.
En identificación de riesgos de software basada en escenarios, imagine usted mismo en distintas funciones, crear escenarios para dichas funciones y, identificar lo que puede ir mal en cada escenario. Utiliza la analogía de viaje de avión descrito anteriormente, mentally se pueden trazar los pasos que se tarda en tu viaje. Por ejemplo, "primero unidad en el aeropuerto. A continuación, park mi automóvil. A continuación, proteja en el contador de la compañía aérea." Este proceso de escenario podría revelar muchos riesgos incluidos los retrasos tráfico debido a la construcción de carretera o un accidente, falta de disponibilidad, olvidarse de tu ID de estacionamiento y así sucesivamente.
En un entorno de proyecto de software, algunas funciones comunes que utiliza para la identificación de riesgos basada en escenarios son los usuarios, los desarrolladores, evaluadores, vendedores, los arquitectos de software y los jefes de proyecto. Un escenario de usuario podría ser algo las líneas de "primero, se instalar la aplicación. A continuación, inicie la aplicación." En muchos casos un escenario de identificación de riesgos se asigna directamente a un caso de prueba.
Las funciones de identificación de riesgos basada en escenarios no son necesariamente las personas. Las funciones pueden ser módulos de software o subsistemas demasiado. Por ejemplo, supongamos que tiene algún objeto de C# que realiza el cifrado y descifrado. Puede imaginar que el objeto es la función y crea escenarios tales como, "primero aceptan algunas entradas y crear una instancia de yo mismo. A continuación aceptan algunas entradas y pasarla a mi método de cifrar. " Ha habido menos investigación en la identificación software basada en escenarios de riesgo que en la identificación de en función de taxonomía. Las notas de investigación enPatrones de identificación de riesgos para proyectos de softwareofrece una buena introducción a la del campo y propone un interesante, teórico basado en patrones enfoque para la identificación de riesgos.
Además de estrategias de identificación de riesgos en función de taxonomía y basada en escenarios, un tercer enfoque es una estrategia en función de la especificación. En este enfoque estrechamente examine cada característica y procesar en el producto o documentos de especificaciones del sistema y se intenta identificar lo que pueden ir mal. Con la analogía de viaje de avión, cuidadosamente se puede examinar un itinerario de viaje detallada que se creó por un agente de viaje. Imagine que uno de los documentos de especificaciones para una Web aplicación indica que desea utilizar un contratista externo para generar los diversos archivos de ayuda de la aplicación. Una dependencia de proyecto externo puede dar lugar a una lista larga de riesgos. ¿Qué ocurre si el contratista no entregar a tiempo?¿Qué ocurre si trabajo calidad el contratista no cumple los estándares subjetivos?
No es estrategia de identificación única y óptimo riesgos, ya que cada uno tiene ventajas y desventajas. Taxonomías de riesgos son una manera excelente para comenzar el proceso de identificar los riesgos en el proyecto de software. Proporcionan una forma algo mecánica para empezar en el sentido de que simplemente inicie examinar cada pregunta o una instrucción de la taxonomía. Taxonomías también ayudarle a distribuir el proceso de identificación de riesgos entre varias personas asignando diferentes personas a las preguntas de taxonomía diferentes. En el lado negativo, el uso de Taxonomías para la identificación de riesgos puede ser muy prolongado. Además, Taxonomías son, por su naturaleza, genérica y por lo tanto no pueden identificar los riesgos que son específicos de su sistema de software a menos que se coloca en el esfuerzo para detectar estos riesgos específicos.
En comparación con la identificación de riesgos en función de taxonomía, una ventaja de una solución basada en escenarios es que tiende a ser menos genérico y obliga a desde el principio que más definitiva. En la otra parte, basada en escenarios la identificación de riesgos es algo más arte que ciencia y puede fácilmente perder un escenario clave. Identificación de riesgos en función de especificación es normalmente el enfoque menos genérico, más específico. Sin embargo, un enfoque en función de la especificación producirá resultados sólo tan buenos como los documentos de especificaciones. Cuando se utiliza conjuntamente, los tres métodos ofrecen una buena oportunidad de identificar con exactitud los riesgos de software.
Análisis de riesgos
Análisis de riesgos es el proceso de combinación de la probabilidad (o probabilidad) de un evento de riesgo con las pérdidas monetarias (o un efecto negativo) que se produce si el evento ocurre, para generar un valor que puede utilizarse para comparar y asignar prioridades a los riesgos frente a otros riesgos. En esta sección, presente dos métodos anteriores para el análisis de riesgos (la técnica de valor esperado y la técnica de categoría) y un enfoque nuevo denominado PERIL. Echemos un vistazo a la técnica de valor esperado en primer lugar.
Eche un vistazo al ejemplo mostrado en la figura 5 . Supongamos que ha identificado cuatro eventos de riesgo. Llamar vamos a los riesgos A, B de riesgos, C de riesgos y D. riesgosPuede asignar las probabilidades a cada evento de riesgo. Una probabilidad es un número entre 0,00 (es decir imposible) y la 1.00 (significado certeza) que indica cómo es probable que el evento es. A continuación, se asigna un valor de pérdidas monetarias a cada evento de riesgo, que es el coste que si se produce el evento de riesgo. Ahora para cada evento de riesgo simplemente multiplique probabilidad del riesgo y pérdida del riesgo para obtener la exposición al riesgo.
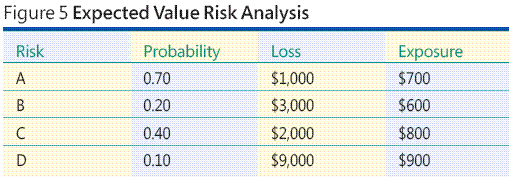
Con este método, exposición al riesgo es sólo una forma de valor esperado. Obviamente, hay varios problemas principales con el método de valor esperado. ¿Pueden cómo se estimar probabilidades de riesgo?Cómo puede que se calcula una pérdida de riesgo? queEn algunas situaciones puede tener buena datos históricos o experiencia para basar las estimaciones en, pero esto generalmente es una situación excepcional durante la creación de software. Según mi experiencia, el enfoque de valor esperado para el análisis de riesgos a menudo no es factible en un entorno de desarrollo de software.
Porque es difícil o imposible incluso en muchos entornos de desarrollo software para calcular la probabilidad de un evento de riesgo o su pérdida asociada, una comunes alternativa es utilizar escalas de categoría para la probabilidad del riesgo y pérdida de riesgo. Ésta es la técnica de categoría. Un ejemplo hará que la idea borrar. Supongamos que haya identificado riesgos cuatro, A, B, C y D. Ahora en lugar de adivinar en una probabilidad y una pérdida de cada riesgo, se genere una tabla exposición de categoría de riesgo como el que se muestra en la parte superior de la figura 6 .
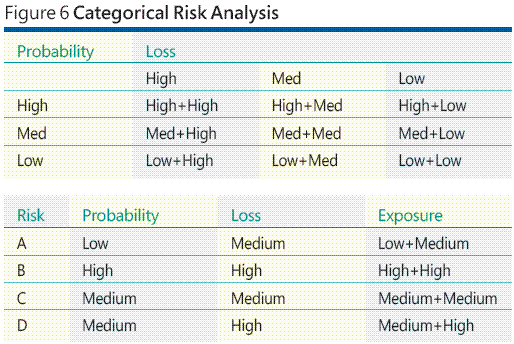
Como puede ver, tengo un total de nueve categorías de exposición al riesgo. Hay tres categorías de probabilidad de riesgo, bajo, medio y alto. Hay tres categorías de pérdida, también bajo, medio y alto. El producto cruzado de categoría de probabilidad y categoría de pérdida genera nueve categorías de exposición de riesgos, de baja baja (baja probabilidad de pérdida baja) a través de máximos, High (alta probabilidad de pérdida alto). Ahora pueden ser en cada uno de mis eventos de riesgo cuatro, asignar un bajo, medio, o probabilidad alta y, a continuación, un bajo, medio o alto pérdida, para producir un riesgo de nueve puntos que se expone. La idea es que resulta a menudo más razonable asignar un valor de probabilidad de "bajo" en lugar de un valor numérico exacto como 0,05, por ejemplo.
Los datos hipotéticos de la tabla en la parte inferior de la figura 6 sugieren que riesgos B tiene la mayor exposición y es posible que garantizan más atención o los recursos (incluidas las pruebas) de A, que tiene la más baja exposición del riesgo. Aunque un enfoque de análisis de riesgos categoría facilita un poco el problema de asignación de probabilidades difíciles o imposibles determinar y pérdida de información, la técnica presenta nuevos problemas.
Observe que arbitrariamente utilizan tres categorías de probabilidad y pérdidas. Éste es un enfoque muy grueso. Pero supongamos que decide mejorar mi análisis de riesgos al utilizar cinco categorías para el factor de probabilidad y el factor de pérdida: muy bajo, bajo, medio, alto y muy alto. Ahora podría acabar teniendo un total de riesgo 25 exposición categorías —(Very Low + Very Low) a través (muy alta + muy alto). ¿Podría cómo PUEDO clasificar o comparar estos valores de exposición 25?¿Cómo un (muy baja + alto) riesgo exposición exposición de comparación en un (alto + medio)?¿Si varias personas evaluación de los datos de exposición riesgo categoría, tendría interpretar los datos de exposición de la misma manera?
Para solucionar los problemas con un enfoque de análisis de riesgos puramente categoría, hace varios años que he desarrollado una técnica que LLAMO a exposición del proyecto con clasificación consecuencias y probabilidad (PERIL). La esencia de la idea es usar categorías (como en el enfoque de categoría) pero convertirlos en una escala cuantitativa por lo que éstos se pueden fácilmente combinar (como en el método de valor esperado) para generar métricas de exposición numérico.
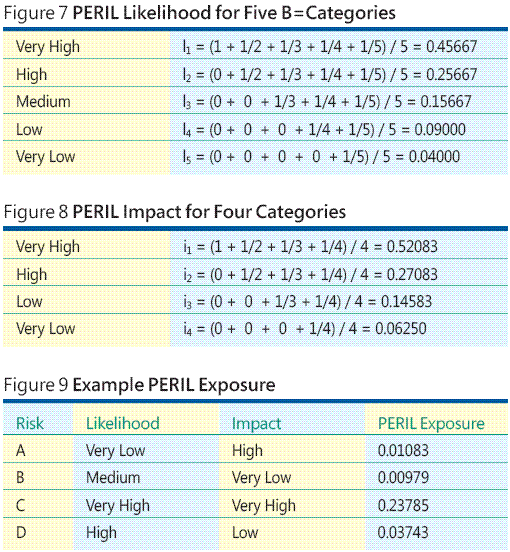
Voy a mostrarle un ejemplo. Supongamos que haya identificado riesgos cuatro: A, B, C y D. Ahora suponga que decide que intenta asignar valores numéricos significativo a cada riesgo probabilidad y pérdida no es factible. Además, decide que en su entorno concreto sentido clasificar la probabilidad de riesgo en cinco categorías: muy bajo, bajo, medio, alto y muy alto. A continuación, se determina que se clasifica pérdidas/impacto en una escala de cuatro puntas: muy bajo, bajo, alto y muy alto. La técnica PERIL asigna datos de categoría en una escala cuantitativa mediante una simple matemática denominado centroids de orden de clasificación de. La técnica de asignación se explica mejor por ejemplo. Para la escala de probabilidad de cinco categorías Mis cinco asignaciones de centroid de orden de clasificación se muestran en la figura 7 .
De forma similar, se calculan Mis asignaciones de impacto de cuatro categorías, tal como se muestra en la figura 8 . Ahora pueden combinar la probabilidad de cada riesgo y valor de centroid de impacto para calcular se expone el riesgo mediante la multiplicación. Por ejemplo, buscar en la figura 9 . Aquí, D riesgos tiene probabilidad alta, que asigna a 0.25667, e impacto bajo, que asigna a 0.14583, por lo que la exposición es 0.25667 * 0.14583 = 0.03743. A partir de estos datos concluir el C de riesgos tiene claramente la mayor exposición y tendría el aspecto formas para evitar que se produzca el riesgo y crear un plan de contingencia, si se produce el evento de riesgo.
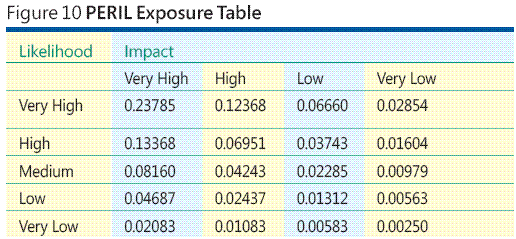
En lugar de la informática individualmente se expone cada riesgo, puede construir una tabla búsqueda exposición PERIL completa para cinco niveles de probabilidad y consecuencias cuatro niveles y que se, a continuación, simplemente lea PERIL los valores de exposición de la tabla, como se ilustra en la figura 10 . La técnica PERIL generalizes a cualquier número de categorías de probabilidad e impacto.
Clasificar orden centroids asignar jerarquía (como primer, segundo, tercer) en valores numéricos (como 0.61111, 0.27778, 0.11111). Observe que el orden de clasificación centroid valores se normalizan en el sentido que sumar a 1,0 (sujeto a errores de redondeo). Expresar en notación de sigma, si N es el número de categorías, a continuación, el valor numérico correspondiente a la categoría kth es:
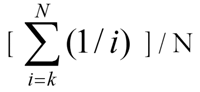
Existen muchas otras asignaciones matemáticas entre categorías y valores numéricos, pero no hay alguna referencia que sugiere que una manera muy buena para asignar las clasificaciones como las utilizadas en el análisis de riesgos consiste en utilizar centroids de orden de clasificación. Es una explicación completa de la orden de clasificación centroids fuera del ámbito de esta columna, pero tener en cuenta este argumento informal. Supongamos que está trabajando con tan sólo dos categorías de probabilidad de eventos de riesgo: máximos y mínimos. Posiblemente la probabilidad de evento High-risk tiene una probabilidad de que se produzca que sea mayor que 0,5 y, por tanto, la probabilidad de evento de bajo riesgo tiene una probabilidad de menos de 0,5. Sin información adicional, puede suponga que la probabilidad de eventos alto es a medio camino entre 0,5 y 1.0 y por lo que es igual a 0,75. Del modo mismo, la probabilidad de eventos bajo es a medio camino entre 0,0 y 0,5 que es 0,25. Estos dos valores, 0,75 y 0,25, son centroids de orden de clasificación para N = 2 categorías (como se muestra en la figura 11 ).
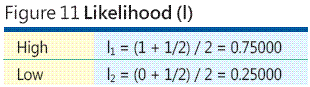
Observe que cuando se utiliza PERIL, utiliza la probabilidad de las condiciones y impacto en vez de probabilidad y pérdida. PERIL probabilidad e impacto son relativos, normalizan los valores. Aunque los valores de probabilidad PERIL suman a 1,0 al igual que cuando un conjunto de probabilidad, permítanme haga hincapié en que los valores de probabilidad PERIL no son las probabilidades. De forma similar, en valores de impacto PERIL se tienen significado sólo cuando se compara con entre sí y no se son los valores de pérdidas monetarias.
Las tres técnicas para determinar la exposición al riesgo, la técnica de valor esperado, la técnica de categoría y la técnica PERIL, puntos fuertes y débiles. Si tiene datos históricos sólidos que permite estimar las probabilidades de eventos de riesgo y la pérdida de moneda asociado con cada evento, a continuación, la técnica de valor esperado es normalmente el mejor método. Sin embargo, en un entorno de pruebas y desarrollo de software rara vez tiene suficientes datos para realizar estimaciones de probabilidad y pérdida significativas.
En el otro extremo, si tiene prácticamente no hay datos riesgo históricos, a continuación, la técnica de categoría, con dos o tres categorías de probabilidad del riesgo y pérdida de riesgo asociado, es una solución razonable. En situaciones donde es posible clasificar la probabilidad de eventos de riesgo e impacto de riesgo asociado (que puede ser monetario o no monetario pérdida como efecto de estado de ánimo) en aproximadamente cinco categorías, a continuación, la técnica PERIL es a menudo una excelente opción.
Independientemente de que las técnicas de análisis de riesgos que decida utilizar en su entorno, debe procurar para interpretar los resultados con precaución. Tenga en cuenta que casi siempre análisis de riesgos tiene grandes cantidades de variabilidad en las estimaciones de entrada. En otras palabras, riesgos análisis le ofrece instrucciones, no reglas, para dar prioridad a los esfuerzos de pruebas de software.
Recursos de riesgos
Para obtener más de riesgo, consulte estosMSDN Magazinecolumnas:
| "Ejecución de prueba: análisis competitivo con MAGIQ" |
| "Ejecución de prueba: proceso de jerarquía de analítica" |
Ajustar hacia arriba
Una parte del proceso general de análisis de riesgos que no tratan en esta columna es la administración de riesgos. Administración de riesgos implica actividades, como establecer un sistema para escribir y almacenar los datos de riesgo además de información de riesgos a lo largo del tiempo medida que avanza el proyecto de software de supervisión. Sistemas de administración de riesgos pueden abarcar desde un sistema informal basado en el correo electrónico, mediante un enfoque ligero basado en hojas de cálculo de Excel, copia a un enfoque sofisticado según con elementos de riesgo en un sistema de Microsoft Team Foundation Server.
Es importante comprender que el análisis de riesgos debe ser un proceso continuo, iterativo, independientemente de cómo decide administrar los esfuerzos de riesgo. Dado que desarrollo del proyecto de software es una actividad tan dinámica, debe revisar los datos de riesgos y resultados que el proyecto evolucione.
Sentido común sugiere que el análisis de riesgos de software debe formar parte de todos los proyectos de software. Proyectos desde muy pequeño, un desarrollador, una semana esfuerzos hacia arriba para proyectos grandes y varios años con cientos o incluso miles de desarrolladores deberían tener algún tipo de análisis de riesgos. Sin embargo, es bastante un poco de investigación de encuesta que muestra que el análisis de riesgos a menudo no se realizan, especialmente en proyectos de software pequeñas y medianas.
Hay varias explicaciones es probable que. Sospecha que una razón rara vez se realizan análisis de riesgos es que necesitan técnicas y aptitudes que son casi lo contrario de los conocimientos y aptitudes necesarios para la codificación. Voy a explicar. Desarrollo de software más actividades son relativamente bien definidas, basándose en un sistema de cerrado, son micro-objetivo orientado a y generalmente proporcionan información inmediata. Por ejemplo, cuando se escribe algún código como desarrollador, puede obtener comentarios instantáneo cuando se compila y, a continuación, ejecutar el código. Si el código se ejecuta como se esperaba, normalmente, obtendrá un cierto grado de satisfacción del. Realizar análisis de riesgos de software es un tipo cantidad diferente de la actividad. No obtendrá cualquiera de los tipos de comentarios o satisfacción de los que está acostumbrado a obtener.
Mi punto es que el análisis de riesgos de software es muy diferente de codificación. Espero que esta columna tiene convencido de la importancia de realizar el análisis de riesgos y muestra algunas técnicas nueva para crear software mejor y más confiable.
Envíe sus preguntas y comentarios para James a testrun@Microsoft.com.
Dr. James McCaffrey funciona para información biológicas volt, Inc., que administra el formación técnica para ingenieros de software trabaja en Microsoft en Redmond, Washington. Ha trabajado en varios productos de Microsoft, incluidos Internet Explorer y MSN Search y es autor de .NET Test Automation: A Problem-Solution Approach (Apress, 2006). Juan puede ponerse en jmccaffrey@volt.com o v-jammc@microsoft.com.