Este artículo proviene de un motor de traducción automática.
Escala fuera
Distribuye la caché en la ruta de acceso a la escalabilidad
Iqbal Khan
En este artículo se describe:
|
En este artículo usa las tecnologías siguientes: ASP.NET, servicios Web, aplicaciones HPC |
Contenido
Distribuye la caché
Características de debe tener en caché distribuida
Caducidad
Expulsiones
Almacenamiento en caché datos relacionales
Sincronizar una caché con otros entornos
Sincronización de la base de datos
Read-Through
Escribir A, escribir detrás
Consultas de caché
Propagación de eventos
Caché de rendimiento y escalabilidad
Alta disponibilidad
Rendimiento
Ganando popularidad
Si está desarrollando un ASP.NET de aplicaciones, servicios Web o una aplicación informática de alto rendimiento (HPC), es probable que problemas de escalabilidad principal como intenta escala y poner más carga en la aplicación. Con una aplicación ASP.NET, los cuellos de botella se producen en almacenes de datos de dos. El primero es los datos de aplicación residen en la base de datos y la otra es datos de estado de sesión ASP.NET que normalmente se almacenan en uno de los tres modos (InProc, SqlServer o StateServer) proporcionados por Microsoft. Las tres tienen problemas de escalabilidad principal.
Servicios Web, normalmente, no utilizan el estado de sesión, pero tendrán cuellos de botella de escalabilidad cuando se trata los datos de aplicación. Al igual que aplicaciones de ASP.NET, servicios Web pueden ser alojados en IIS y implementados en una comunidad Web de escalabilidad.
Las aplicaciones de HPC diseñados para realizar gran paralelo también el procesamiento tienen problemas de escalabilidad porque no se escala el almacén de datos de la misma manera. HPC (también denominado cuadrícula informática) ha utilizado tradicionalmente Java, pero como .NET ganancias mercado está ganando adeptos para así las aplicaciones HPC. Se implementan aplicaciones HPC en cientos y a veces miles de equipos para el procesamiento paralelo y a menudo necesitan para funcionar en grandes cantidades de datos y compartir los resultados intermedios con otros equipos. Aplicaciones HPC utilizan una base de datos o un sistema de archivo compartido como un almacén de datos, y ambas no escala muy bien.
Distribuye la caché
Almacenamiento en caché es un concepto conocido en el hardware y software mundos. Tradicionalmente, almacenamiento en caché se ha un mecanismo independiente, pero que no es factible ya en la mayoría de los entornos porque las aplicaciones ahora se ejecutan en varios servidores y en varios procesos dentro de cada servidor.
En la memoria caché distribuida es una forma de almacenamiento en caché que permite la caché para abarcar varios servidores, por lo que puede aumentar en tamaño y capacidad transaccional. Caché distribuida ha convertido en factible ahora por una serie de razones. En primer lugar, memoria se convierten en muy barato y puede material variado equipos con muchas gigabytes a precios throwaway. En segundo lugar, tarjetas de red se han vuelto muy rápidas, con 1Gbit ahora en todas partes estándar y 10Gbit traction obtener. Por último, a diferencia de un servidor de base de datos, que normalmente requiere un equipo de gama alta, distribuye de almacenamiento en caché funciona bien en equipos de costo inferiores (como los utilizados para los servidores Web), que permite agregar fácilmente más equipos.
Caché distribuida es escalable debido a la arquitectura que emplea. Se distribuye su trabajo en varios servidores, pero todavía ofrece una vista lógica de una caché única. Para los datos de aplicación, una caché distribuida mantiene una copia de un subconjunto de los datos en la base de datos. Esto supone que un almacén temporal, que puede significar horas, días o semanas. En muchas situaciones, los datos se utilizados en una aplicación no necesita almacenarse de forma permanente. En ASP.NET, por ejemplo, datos de sesión son temporal y es necesario para quizás unos minutos a unas horas como máximo.
De forma similar, en HPC, gran parte del procesamiento requiere almacenar datos intermedios en un almacén de datos, y esto también es temporal en la naturaleza. El resultado final de HPC puede almacenarse en una base de datos, sin embargo. la figura 1 muestra una configuración típica de una caché distribuida en una empresa.
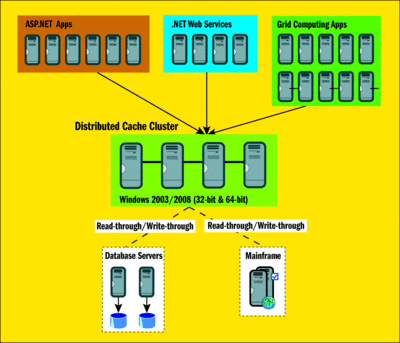
Figura 1 Distribuidas caché compartida por varias aplicaciones en una empresa (haga clic en la imagen para ampliarla)
Características de debe tener en caché distribuida
Tradicionalmente, los desarrolladores han considerado almacenar en caché sólo datos estáticos, los datos de significado que nunca cambia durante la vida de la aplicación. Pero que datos normalmente son un subconjunto muy pequeño, quizás 10 %, de los datos que procesa una aplicación. Aunque puede conservar datos estáticos en la caché, el valor real viene si puede almacenar en caché datos dinámicos o transaccionales, datos que mantiene cambiar cada pocos minutos. Todavía caché ya dentro de ese intervalo de tiempo, puede recuperar en decenas de veces y guardar ese número de viajes en la base de datos. Si se multiplican por miles de usuarios que intenten realizar operaciones simultáneamente, puede imaginar cuántos lecturas menos que se tiene en la base de datos.
Pero si caché dinámico de datos, la caché para que determinadas características diseñadas para evitar problemas de integridad de datos. Una caché típica debería tener características para caducar y expulsar los elementos, así como otras funciones. Explicaré estas características en las secciones siguientes.
Caducidad
Caducidad está en la parte superior de la lista. Permiten especificar cuánto tiempo los datos deben permanecer en la caché antes de que la memoria caché quita automáticamente. Puede especificar dos tipos de caducidad: tiempo absoluto caducidad de caducidad y tiempo deslizante (o tiempo de inactividad).
Si los datos de la caché también existen en un origen de datos master, sabrá que se pueden cambiar estos datos en la base de datos por usuarios o aplicaciones que no pueden tener acceso a la caché. Cuando esto ocurre, los datos de la caché se convierte en obsoletos. Si puede estimar cuánto estos datos pueden segura mantenerse en la caché, puede especificar la caducidad de tiempo absoluto, algo como, "Caducar este elemento 10 minutos a partir de ahora" o "Caducar este elemento esta noche a medianoche."
Una variación interesante caducidad absoluta es si la caché puede volver a cargar una copia actualizada del elemento en caché directamente desde su origen de datos. Esto es posible sólo si la caché proporciona un read-through característica (consulte secciones posteriores) y le permite registrar un controlador de read-through vuelve a cargar los elementos almacenados en caché cuando se produce una caducidad absoluta. Excepto para unas cachés comerciales, las cachés de la mayoría no admiten esta característica.
Puede utilizar la caducidad de tiempo de inactividad (tiempo deslizante) para un elemento caduca si no se utiliza durante un período de tiempo determinado. Puede especificar algo como "Caducar este elemento." Si nadie lee o actualiza durante 10 minutos Este enfoque resulta útil cuando la aplicación necesita los datos temporalmente, pero una vez finalizada la aplicación lo utiliza, desea automáticamente la caducidad de la caché. El estado de sesión de ASP.NET es un buen candidato para la caducidad de tiempo de inactividad.
Caducidad absoluta tiempo le ayuda a evitar situaciones en las que la memoria caché tiene una copia de los datos obsoleta o una copia anterior a la copia maestra de la base de datos. Caducidad de tiempo de inactividad está diseñado para limpiar la caché después de la aplicación ya no necesita determinados datos. En lugar de la aplicación de seguimiento de limpieza necesarias, permiten la caché de encargarse de él.
Expulsiones
Más distribuidas cachés están en memoria y no conservan la caché de disco. Esto significa que en la mayoría de los casos, la memoria es limitada y el tamaño de la caché no puede crecer más allá de un límite determinado, que podría ser la memoria total disponible o mucho menor que si tiene otras aplicaciones que se ejecutan en el mismo equipo.
En ambos casos, una caché distribuida debe permitirle especificar un tamaño máximo de caché (lo ideal es que en términos de tamaño de memoria). Cuando la caché alcanza este tamaño, debe empezar quitar elementos almacenados en caché para dejar espacio para nuevos, un proceso que se suele denominar Expulsiones.
Expulsiones se realizan basándose en diversos algoritmos. El más popular es menos usados recientemente (LRU), que se quitan los elementos almacenados en caché que no se toca para el tiempo más largo. Otro algoritmo es menos frecuente (LFU). Aquí, los elementos que han sido toca el menor número de veces que se quitan. Hay unos otras variaciones, pero estos dos son más populares.
Almacenamiento en caché datos relacionales
La mayoría de los datos proceden de una base de datos relacional, pero incluso si no lo hace, es relacional en naturaleza, lo que significa que diferentes partes de datos están relacionadas entre sí, por ejemplo, un objeto de cliente y un objeto de orden.
Cuando tiene estas relaciones, deberá controlar en una memoria caché. Esto significa que la caché debe conocer la relación entre un cliente y un pedido. Si actualizar o quitar a un cliente de la caché, quizás desee también automáticamente actualizar o quitar objetos de pedido relacionado de la caché de la caché. Esto ayuda a mantener la integridad de los datos en muchas situaciones.
Pero nuevamente, si una caché no puede mantener un seguimiento de estas relaciones, tiene que hacerlo y hace su aplicación mucho más complicado y complejos. Es mucho más fácil si le sólo que se agrega la caché de los datos de tiempo que un pedido está asociado con un cliente, y la caché entonces sabe que si se actualiza o se quita ese cliente, pedidos relacionados también tengan que actualizarse o quita de la caché.
Caché de ASP.NET tiene una característica interesante denominada CacheDependency, que permite realizar un seguimiento de relaciones entre distintos elementos en caché. Algunos cachés comerciales también tienen esta característica. la figura 2 muestra un ejemplo de cómo funciona la caché de ASP.NET.
Figura 2 mantener un seguimiento de relaciones entre elementos en caché
using System.Web.Caching;
...
public void CreateKeyDependency()
{
Cache["key1"] = "Value 1";
// Make key2 dependent on key1.
String[] dependencyKey = new String[1];
dependencyKey[0] = "key1";
CacheDependency dep1 = new CacheDependency(null, dependencyKey);
Cache.Insert("key2", "Value 2", dep2);
}
Se trata de una dependencia multinivel, puede depender de significado que A puede depender de B y C. Por lo tanto, si la aplicación quita C, la A y B deben quitarse de la caché así.
Sincronizar una caché con otros entornos
Características de dependencia de caché y los vencimientos están pensadas para ayudarle a mantener la caché reciente y correcta. También deberá sincronizar la caché con orígenes de datos que usted y la caché no tienen acceso a para que los cambios en dichos orígenes de datos se reflejen en su caché para mantener actualizada.
Por ejemplo, supongamos que la memoria caché se escribe mediante Microsoft .NET Framework, pero tiene aplicaciones de Java o C++ modificar datos en el origen de datos principal. Desea que estas aplicaciones para notificar a la caché cuando cambian de determinados datos en los orígenes de datos principal para que la caché puede invalidar un elemento correspondiente de la caché.
Lo ideal es que la caché debe admitir esta capacidad. Si no es así, esta carga se cae en la aplicación. Caché de ASP.NET proporciona esta característica a través de CacheDependency, como algunas soluciones de almacenamiento en caché comerciales. Permite especificar que un determinado elemento en caché depende de un archivo y que, siempre que se actualiza o quita este archivo, la caché descubre este y invalida el elemento en caché. Invalidar las fuerzas de elemento de la aplicación para obtener la última copia de este objeto en la siguiente vez la aplicación, necesita y no la encuentra en la caché.
Si tenía 100.000 elementos en la caché, 10.000 de ellos puede tener dependencias de archivo y para que tenga 10.000 archivos en una carpeta especial. Cada archivo tiene un nombre especial asociado con ese elemento en caché. Cuando otra aplicación, si escribe en NET o no, cambia los datos de origen de datos principal, que puede comunicarse aplicación a la caché a través de una actualización de la marca de hora de archivo.
Sincronización de la base de datos
La necesidad de sincronización de la base de datos se produce porque la base de datos está compartida entre varias aplicaciones y no todas las aplicaciones tienen acceso a la caché. Si la aplicación es la única aplicación actualizar la base de datos y también fácilmente puede actualizar la caché, probablemente no necesita la capacidad de sincronización de la base de datos. Pero en un entorno real, no siempre el caso. Siempre que un tercero o cualquier otra aplicación cambia los datos de la base de datos, desea la caché para reflejar dicho cambio. La caché refleja cambios volviendo a los datos, o al menos por no tener datos más antiguos en la caché.
Si la caché tiene una copia antigua y la base de datos de una copia nueva, ahora tiene un problema de integridad de datos como no sabe qué copia es el adecuado. Por supuesto, la base de datos siempre es correcto, pero siempre no vaya a la base de datos. Obtener datos de la caché porque la aplicación confía en que la caché siempre será correcta o que la caché será correcta para sus necesidades.
Sincronizar con la base de datos puede significar invalidar el elemento relacionado en la caché de modo que la próxima vez que necesita la aplicación, recuperará, desde la base de datos. Una variante interesante a este proceso es cuando vuelve a la caché de cargar automáticamente una copia actualizada del objeto cuando cambian los datos en la base de datos. Sin embargo, esto es posible sólo si la caché le permite proporcionar un controlador read-through (consulte la sección siguiente) y, a continuación, lo utiliza para volver a cargar el elemento en caché de la base de datos. Sin embargo, sólo algunas de las cachés comerciales admiten esta característica, y ninguno de los libres pendientes.
Caché de ASP.NET tiene una característica de SqlCacheDependency (consulte la figura 3 ) que permite sincronizar la caché con un SQL Server 2005 y 2008, Oracle 10 g R2 o base de datos de versión posterior, básicamente cualquier base de datos tiene CLR de .NET integrado. Algunas de las cachés comerciales también proporcionan esta capacidad.
Figura 3 uso de SqlDependency para sincronizar con una base de datos relacional
using System.Web.Caching;
using System.Data.SqlClient;
...
public void CreateSqlDependency(Customers cust, SqlConnection conn)
{
// Make cust dependent on a corresponding row in the
// Customers table in Northwind database
string sql = "SELECT CustomerID FROM Customers WHERE ";
sql += "CustomerID = @ID";
SqlCommand cmd = new SqlCommand(sql, conn);
cmd.Parameters.Add("@ID", System.Data.SqlDbType.VarChar);
cmd.Parameters["@ID"].Value = cust.CustomerID;
SqlCacheDependency dep = new SqlCacheDependency(cmd);
string key = "Customers:CustomerID:" + cust.CustomerID;
Cache.Insert(key, cust, dep);
}
SqlCacheDependency de caché de ASP.NET le permite especificar una cadena SQL para hacer coincidir uno o más filas de una tabla en la base de datos. Si nunca se actualiza esta fila, el DBMS desencadena un evento de .NET que captura la caché. A continuación, se sabe qué elemento en caché está relacionado con esta fila de la base de datos y ese elemento en caché invalida.
Una capacidad caché de ASP.NET no proporciona pero que realizar algunas soluciones comerciales es sincronización de bases de datos basadas en sondeo. Esta capacidad resulta útil en dos situaciones. En primer lugar, si el DBMS no dispone de CLR de .NET integrado, no puede beneficiarse de SqlCacheDependency. En ese caso, sería interesante si la caché no se pudo sondear la base de datos en intervalos configurables y detectar cambios en algunas filas de una tabla. Si han cambiado las filas, la caché invalida sus elementos en caché correspondientes.
La segunda situación es cuando se cambian frecuentemente datos en la base de datos y eventos de .NET están convirtiéndose en demasiado conversadoras. Esto ocurre porque se desencadena un evento de .NET independiente para cada cambio SqlCacheDependency, y si tiene miles de filas que se actualizan frecuentemente, fácilmente se llena la caché. En tales casos, resulta mucho más eficaz que depender de sondeo, donde con una base de datos de consulta se pueden recuperar cientos o miles de filas que han cambiado y, a continuación, invalidarán elementos almacenados en caché correspondientes. Por supuesto, sondeo crea un ligero retardo en la sincronización (quizás 15 a 30 segundos), pero esto es aceptable en muchos casos.
Read-Through
En pocas palabras, read-through es una característica que permite la caché leer directamente los datos de origen de datos que sea. Escribir un controlador read-through y registrarlo con la caché y, a continuación, la caché llama a este controlador en momentos adecuados. figura 4 muestra un ejemplo.
Figura 4 ejemplo de un controlador Read-Through para SQL Server
using System.Web.Caching;
using System.Data.SqlClient;
using Company.MyDistributedCache;
...
public class SqlReadThruProvider : IReadhThruProvider
{
private SqlConnection _connection;
// Called upon startup to initialize connection
public void Start(IDictionary parameters)
{
_connection = new SqlConnection(parameters["connstring"]);
_connection.Open();
}
// Called at the end to close connection
public void Stop() { _connection.Close(); }
// Responsible for loading object from external data source
public object Load(string key, ref CacheDependency dep)
{
string sql = "SELECT * FROM Customers WHERE ";
sql += "CustomerID = @ID";
SqlCommand cmd = new SqlCommand(sql, _connection);
cmd.Parameters.Add("@ID", System.Data.SqlDbType.VarChar);
// Let's extract actual customerID from "key"
int keyFormatLen = "Customers:CustomerID:".Length;
string custId = key.Substring(keyFormatLen,
key.Length - keyFormatLen);
cmd.Parameters["@ID"].Value = custId;
// fetch the row in the table
SqlDataReader reader = cmd.ExecuteReader();
// copy data from "reader" to "cust" object
Customers cust = new Customers();
FillCustomers(reader, cust);
// specify a SqlCacheDependency for this object
dep = new SqlCacheDependency(cmd);
return cust;
}
}
Debido a una caché distribuida normalmente reside fuera de la aplicación, se comparte entre varias instancias de la aplicación o incluso varias aplicaciones. Una capacidad importante de un controlador read-through es que la que almacena en caché se recuperan por la caché directamente desde la base de datos. Por lo tanto, las aplicaciones no necesita tener código de la base de datos. Sólo pueden recuperar datos de la caché y, si la caché no tiene, la caché de va y toma de la base de datos.
Obtendrá beneficios incluso más importantes si combina las capacidades de read-through con caducidad. Siempre que un elemento en la caché caduca, la caché cargarla automáticamente llamando a su controlador read-through. Ahorrar mucho tráfico en la base de datos con este mecanismo. La caché usa sólo un subproceso, un viaje de base de datos, para volver a cargar esos datos de la base de datos, mientras que podría tener miles de usuarios intentando obtener acceso a esos mismos datos. Si no tenía capacidad read-through, todos esos usuarios se podrían va directamente a la base de datos, inundating la base de datos con miles de solicitudes paralelas.
Read-through permite establecer una cuadrícula de datos de nivel empresarial, lo que significa que un almacén de datos que no sólo es muy escalable, pero puede actualizar también propio de orígenes de datos principal. Esto proporciona sus aplicaciones con un origen de datos alternativo desde el que se va a leer datos y evita mucha presión en las bases de datos.
Como se mencionó anteriormente, las bases de datos siempre están el cuello de botella en entornos de alta transacción y se convierten en cuellos de botella debido principalmente a excesivas operaciones de lectura, también ralentizar las operaciones de escritura. Tener una caché que sirve como una cuadrícula de datos de empresa nivel por encima de la base de datos proporciona las aplicaciones un aumento de rendimiento y escalabilidad principal.
Sin embargo, tenga en cuenta que read-through no es un sustituto para realizar algunas consultas combinadas complejos en la base de datos. Una caché típica no permite realizar estos tipos de consultas. Una capacidad read-through funciona bien para las operaciones de lectura de objeto individual, pero no en operaciones que implican consultas combinadas complejas, que siempre es necesario realizar en la base de datos.
Escribir A, escribir detrás
Escritura simultánea es igual read-through: proporcionar un controlador y la caché se llama al controlador, que escribe los datos en la base de datos siempre que actualice la caché. Una ventaja importante es que la aplicación no tiene escribir directamente en la base de datos porque la caché la hace por usted. Esto simplifica el código de aplicación, puesto que la caché, en lugar de la aplicación, tiene el código de acceso de datos.
Normalmente, la aplicación emite una actualización a la caché (por ejemplo, agregar, insertar o quitar). La caché actualiza en primer lugar y, a continuación, emite una llamada de actualización a la base de datos a través de su controlador de escritura. La aplicación espera hasta que la caché y la base de datos se actualizan.
¿Qué ocurre si desea esperar a la caché para actualizarse, pero no desea esperar a la base de datos puede actualizar porque ralentiza el rendimiento de la aplicación? Es donde entra la escritura en segundo plano en, que utiliza el mismo controlador de escritura simultánea pero actualiza la caché de forma sincrónica y la base de datos asincrónicamente. Esto significa que la aplicación espera a que la caché para actualizarse, pero no espere a la base de datos para actualizarse.
Sabe que está en la cola la actualización de base de datos y que la base de datos se actualiza bastante rápidamente por la caché. Ésta es otra forma de mejorar el rendimiento de aplicación. Debe escribir en la base de datos de todos modos, pero ¿por qué espera? Si la caché tiene los datos, incluso no sufrir las consecuencias de otras instancias de la aplicación no encuentra los datos en la base de datos ya que acaba de actualizar la caché y las otras instancias de la aplicación buscará los datos en la caché y no necesita ir a la base de datos.
Consultas de caché
Normalmente, la aplicación busca objetos en la caché basada en una clave, como una tabla hash, como ha visto en ejemplos de código de origen anteriores. Tiene la clave y el valor es el objeto. Pero a veces necesitará buscar objetos basados en atributos distinta de la clave. Por lo tanto, la caché debe proporcionar la capacidad para para buscar o consulta la caché.
Hay un par de formas que puede hacer esto. Uno consiste en Buscar en los atributos del objeto. El otro implica situaciones en que ha asignado etiquetas arbitrarias a objetos en caché y desea buscar basándose en las etiquetas. Búsqueda basada en atributos actualmente está disponible sólo en algunas soluciones comerciales a través de lenguajes de consulta de objeto, pero basado en etiquetas buscar está disponible en cachés comerciales y velocidad de Microsoft.
Supongamos que ha guardado un objeto de cliente. Se puede decir "Conceder me todos los clientes donde la población es San Francisco" cuando desee objetos de sólo cliente, incluso aunque tenga la caché de los empleados, clientes, pedidos, artículos de pedido y más. Cuando se emite una consulta similar a SQL como las que se muestra en la figura 5 , busca los objetos que coinciden con los criterios.
Figura 5 mediante una consulta LINQ para buscar elementos en la caché
using Company.MyDistributedCache;
...
public List<Customers> FindCustomersByCity(Cache cache, string city)
{
// Search cache with a LINQ query
List<Customers> custs = from cust in cache.Customers
where cust.City == city
select cust;
return custs;
}
Etiquetado permite adjuntar varias etiquetas arbitrarias a un objeto específico, y la misma etiqueta puede asociarse con múltiples objetos. Las etiquetas son normalmente basados en cadenas y etiquetado también le permite clasificar objetos en grupos y, a continuación, buscar los objetos más adelante a través de estas etiquetas o grupos.
Propagación de eventos
Puede que no siempre necesite propagación de eventos en la caché, pero es una característica importante que debe conocer. Es una buena característica para tiene si ya ha distribuido aplicaciones, aplicaciones HPC o varias aplicaciones compartir datos a través de una caché. Qué propagación de eventos hace es pedir la caché para desencadenar eventos cuando ocurren ciertas cosas en la caché. Las aplicaciones pueden capturar estos eventos y acciones adecuadas en respuesta.
Supongamos que la aplicación recuperado algún objeto de la caché y muestre al usuario. Podría estar interesado saber si alguien actualiza o quita este objeto de la caché mientras se muestra. En este caso, se notificará la aplicación y puede actualizar la interfaz de usuario.
Esto es, por supuesto, es un ejemplo muy sencillo. En otros casos, puede tener una aplicación distribuida donde algunas instancias de la aplicación producen datos y otras instancias es necesario consumen. Los productores pueden informar a los consumidores cuando datos están preparados activando un evento a través de la caché que reciben los consumidores. Hay muchos ejemplos de este tipo, donde pueden realizarse colaboración o de uso compartido a través de la caché de datos a través de propagación de eventos.
Caché de rendimiento y escalabilidad
Al considerar las características de almacenamiento en caché descritas en las secciones anteriores, debe no olvide que el principal razones que estás thinking del uso de una caché distribuida, que son mejorar el rendimiento y más importante, para mejorar la escalabilidad de la aplicación. Además, puesto que la memoria caché se ejecuta en un entorno de producción como un servidor, también debe proporcionar alta disponibilidad.
La escalabilidad es el problema fundamental que se trata de una caché distribuida. Una caché escalable es aquella que puede mantener un rendimiento incluso cuando aumenta la carga de transacciones. Por lo tanto, si tiene una aplicación ASP.NET en una batería de servidores Web y aumentar el conjunto de Web de cinco servidores Web 15 o incluso 50 servidores Web, podrá aumentar el número de servidores de caché proporcionalmente y mantener la misma hora de respuesta. Esto es algo que no se puede hacer con una base de datos.
Una caché distribuida evita los problemas de escalabilidad que se enfrenta normalmente una base de datos porque es mucho más sencillo de naturaleza que un sistema de administración de bases de datos y también porque utiliza mecanismos de almacenamiento diferentes (también conocido como topologías de almacenamiento en caché) de un sistema de administración de bases de datos. Estos incluyen replicado, particiones y topologías de caché de cliente.
En situaciones de caché más distribuidas, tiene dos o más servidores de caché que aloja la caché. Usaré el término "caché de clúster" para indicar dos o más servidores de caché une para un caché de formulario lógico. Una caché replicada copia toda la memoria caché en cada servidor de caché en el clúster de caché. Esto significa que una caché replicada proporciona alta disponibilidad. Si se interrumpe cualquier un servidor de caché, no perderá los datos en la caché porque otra copia está inmediatamente disponible para la aplicación. También es una topología extremadamente eficaz y proporciona gran escalabilidad si su aplicación necesita para realizar muchas operaciones de lectura intensivo. Cuando se agregan más servidores de caché, agregue esa capacidad mucho más en transacciones de lectura a su clúster de caché. Pero una caché replicada no es la topología ideal para las operaciones de escritura intensivo. Si está actualizando la caché con la frecuencia que estás leyendo, no utilice la topología replicada.
Una caché de particiones saltos de la caché en particiones y, a continuación, almacena una partición en cada servidor de caché en el clúster. Esta topología es más escalable para la caché datos transaccionales (cuando están tan frecuentes como lecturas escrituras en la caché). A medida que agregar más servidores de caché al clúster, aumentan no sólo la capacidad de transacción, sino también la capacidad de almacenamiento de la caché, puesto que todas esas particiones juntos forman toda la memoria caché.
Muchas cachés distribuidas proporcionan una variante de una caché con particiones para alta disponibilidad, donde cada partición también se replica para que ese servidor de una memoria caché contiene una partición y una copia o una copia de seguridad de partición de otro servidor. De este modo, no perderá ningún dato si se interrumpe cualquier servidor. Algunas soluciones de almacenamiento en caché permiten crear más de una copia de cada partición para la confiabilidad agregado.
Otra topología muy eficaz de almacenamiento en caché es caché de cliente (también llamada cerca de la caché), que es muy útil si la caché reside en un nivel de almacenamiento en caché dedicado remoto. La idea detrás de una caché del cliente es que cada cliente mantiene un conjunto de trabajo de la caché cerrar (incluso dentro de proceso de la aplicación) en el equipo cliente. Sin embargo, al igual que una caché distribuida tiene esté sincronizado con la base de datos a través de diferentes medios (como se explicó anteriormente), caché de un cliente necesita estar sincronizada con la caché distribuida. Algunas soluciones de almacenamiento en caché comerciales proporcionan este mecanismo de sincronización, pero más proporcionan sólo una memoria de caché cliente independiente sin ninguna sincronización.
Del mismo modo que una caché distribuida reduce el tráfico a la base de datos, una caché de cliente reduce el tráfico a la caché distribuida. No es sólo más rápido que la caché distribuida porque está más cerca de la aplicación (y también puede ser InProc), también mejora la escalabilidad de la caché distribuida reduciendo viajes a la caché distribuida. Por supuesto, una caché de cliente es un buen enfoque sólo cuando esté realizando muchas más lecturas que escrituras. Si el número de lecturas y escrituras es igual, no utilice una caché del cliente. Escrituras será más lentos debido a que ahora tiene que actualizar la caché del cliente y la caché distribuida.
Alta disponibilidad
Dado que una caché distribuida se ejecuta como un servidor en el entorno de producción y en muchos casos sirve como almacén de datos sólo para la aplicación (por ejemplo, estado de sesión ASP.NET), la caché debe proporcionar alta disponibilidad. Esto significa que la caché debe ser muy estable para que nunca se bloquea y ofrece la posibilidad de realizar los cambios de configuración sin detener la caché.
La mayoría de los usuarios de una caché distribuida requieren que se ejecute sin cualquier interrupciones para los meses en un momento la caché. Siempre que tienen que detener la caché, es normalmente durante una hora programada hacia abajo. Esta es la razón por alta disponibilidad es tan importante para una caché distribuida. Le ofrecemos algunas preguntas que tener en cuenta al evaluar si una solución de almacenamiento en caché proporciona una alta disponibilidad.
- ¿Puede desconecte uno de los servidores de caché sin detener toda la memoria caché?
- ¿Puede agregar un nuevo servidor de caché sin detener la caché?
- ¿Puede agregar a nuevos clientes sin detener la caché?
En la mayoría de los cachés, se utiliza un tamaño de caché máximo especificado para que la caché no superen la cantidad de datos. El tamaño de caché se basa en cuánta memoria tiene disponible en ese sistema. ¿Puede cambiar esa capacidad? Supongamos que inicialmente establezca el tamaño de caché que 1 GB pero ahora desea que sea 2 GB. ¿Puede hacer sin detener la caché?
Éstos son los tipos de preguntas que desee considerar la posibilidad de. ¿Cuántos de estos cambios de configuración necesitan realmente la caché para reiniciarse? Menos, mejor. Aparte de las características de almacenamiento en caché, el primer criterio para tener una caché que se puede ejecutar en un entorno de producción es la caché se va a proporcionarle cuánto tiempo de actividad.
Rendimiento
Simplemente colocar, si no es más rápido que tener acceso a la base de datos tener acceso a la caché, no es necesario disponer de ella. Dicho esto, ¿qué debe espera en términos de rendimiento de una buena caché distribuida?
Lo primero que debe recordar es que una caché distribuida es normalmente OutProc o remoto, por lo que nunca será tan rápido como una caché de InProc independiente (por ejemplo, la caché de ASP.NET) de tiempo de acceso. En una caché independiente de InProc, probablemente se pueden leer elementos de 150.000 a 200.000 por segundo (tamaño de objeto de 1 KB). Con un OutProc o una caché remota, este número disminuye notablemente. En términos de rendimiento, debe esperar 20.000 a 30.000 lecturas por segundo (tamaño de objeto de 1 KB) como el rendimiento de un servidor de caché individuales (desde todos los clientes golpear en él). Puede conseguir algunos este rendimiento InProc utilizando una caché de cliente (en el modo InProc), pero que es sólo para las operaciones de lectura y no para las operaciones de escritura. Sacrificar parte el rendimiento para obtener la escalabilidad, pero el rendimiento más lento es aún mucho más rápido que el acceso a la base de datos.
Ganando popularidad
Una caché distribuida como un concepto y como una práctica recomendada está ganando popularidad más. Sólo unos años, muy pocas personas en el espacio de .NET sabían sobre él, aunque la comunidad de Java ha sido adelantado de .NET en esta área. Con el crecimiento explosivo en transacciones de la aplicación, las bases de datos admiten una carga más allá de sus límites y ahora se acepta la caché distribuida como una parte vital de cualquier arquitectura de aplicación escalable.
Iqbal kan es presidente y tecnología evangelista en Alachisoft. Alachisoft proporciona que NCache, .NET un líder del sector distribuyen caché para aumentar el rendimiento y escalabilidad en aplicaciones empresariales. Iqbal tiene una Microsoft en informática de Indiana University, Bloomington. Puede ponerse en iqbal@alachisoft.com.