Estrategias de creación de particiones de datos (Creación de aplicaciones reales en la nube con Azure)
por Rick Anderson y Tom Dykstra
Descargar proyecto Fix It o Descargar libro electrónico
El libro electrónico Creación de aplicaciones reales en la nube con Azure se basa en una presentación desarrollada por Scott Guthrie. Explica 13 patrones y prácticas que pueden ayudarle a tener éxito en el desarrollo de aplicaciones web para la nube. Para obtener información sobre la serie, consulte el primer capítulo.
Anteriormente vimos lo fácil que es modificar la escala del nivel web de una aplicación en la nube mediante la adición y eliminación de servidores web. Pero, si todos visitan el mismo almacén de datos, el cuello de botella de la aplicación se mueve del front-end al back-end y la capa de datos es la más difícil para modificar la escala. En este capítulo veremos cómo puede hacer que la capa de datos sea escalable mediante la creación de particiones de datos en varias bases de datos relacionales o mediante la combinación de almacenamiento de bases de datos relacionales con otras opciones de almacenamiento de datos.
Es mejor si se realiza por adelantado la configuración de un esquema de creación de particiones por la misma razón mencionada anteriormente: es muy difícil cambiar la estrategia de almacenamiento de datos después de que una aplicación esté en producción. Si piensa mucho por adelantado sobre diferentes enfoques, puede evitar tener un "momento de Twitter" cuando la aplicación se bloquea o deja de funcionar durante mucho tiempo mientras reorganiza el código de acceso a datos y datos de la aplicación.
Las tres V del almacenamiento de datos
Para determinar si necesita una estrategia de creación de particiones y cuál debe ser, tenga en cuenta tres preguntas sobre los datos:
- Volumen: ¿Cuánto datos almacenará en última instancia? ¿Un par de gigabytes? ¿Un par de cientos de gigabytes? ¿Terabytes? ¿Petabytes?
- Velocidad: ¿Cuál es la velocidad a la que aumentarán los datos? ¿Es una aplicación interna que no genera muchos datos? ¿Una aplicación externa en la que los clientes cargarán imágenes y vídeos?
- Variedad: ¿Qué tipo de datos almacenará? ¿Relacionales, imágenes, pares clave-valor, gráficos sociales?
Si cree que va a tener una gran cantidad de volumen, velocidad o variedad, tiene que considerar cuidadosamente qué tipo de esquema de creación de particiones permitirá que la aplicación modifique la escala de forma eficaz y eficiente a medida que crezca y para asegurarse de que no encuentre ningún cuello de botella.
Básicamente hay tres enfoques para crear particiones:
- Particiones verticales
- Creación de particiones horizontal
- Particionamiento híbrido
Particiones verticales
Crear porciones verticales es como dividir una tabla por columnas: un conjunto de columnas entra en un almacén de datos y otro conjunto de columnas entra en un almacén de datos diferente.
Por ejemplo, supongamos que mi aplicación almacena datos sobre personas, incluidas las imágenes:
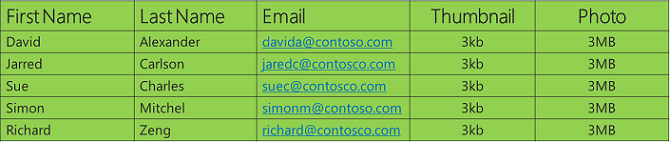
Al representar estos datos como una tabla y examinar las diferentes variedades de datos, puede ver que las tres columnas de la izquierda tienen datos de cadena que una base de datos relacional puede almacenar eficazmente, mientras que las dos columnas de la derecha son básicamente matrices de bytes que proceden de archivos de imagen. Es posible almacenar datos de archivos de imagen en una base de datos relacional y muchas personas lo hacen porque no quieren guardar los datos en el sistema de archivos. Es posible que no tengan un sistema de archivos capaz de almacenar los volúmenes de datos necesarios o que no quieran administrar un sistema de copia de seguridad y restauración independiente. Este enfoque funciona bien para las bases de datos locales y para pequeñas cantidades de datos en bases de datos en la nube. En el entorno local, es posible que sea más fácil dejar que el DBA se ocupe de todo.
Pero, en una base de datos en la nube, el almacenamiento es relativamente caro y un gran volumen de imágenes podría hacer que el tamaño de la base de datos crezca más allá de los límites en los que puede funcionar de forma eficiente. Puede solucionar estos problemas mediante la creación de particiones de los datos verticales, lo que significa que elige el almacén de datos más adecuado para cada columna de la tabla de datos. Lo que podría funcionar mejor para este ejemplo es colocar los datos de cadena en una base de datos relacional y las imágenes de Blob Storage.
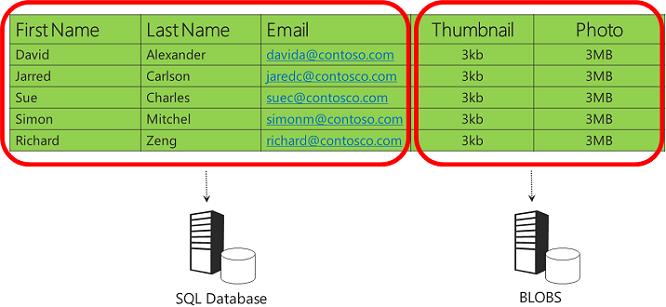
El almacenamiento de imágenes en Blob Storage en lugar de una base de datos es más práctico en la nube que en un entorno local porque no tiene que preocuparse por configurar servidores de archivos o administrar la copia de seguridad y restauración de datos almacenados fuera de la base de datos relacional: todo se controla automáticamente mediante el servicio Blob Storage.
Este es el enfoque de creación de particiones que implementamos en la aplicación Fix It y veremos el código para ello en el capítulo Blob Storage. Sin este esquema de partición y suponiendo un tamaño medio de imagen de 3 megabytes, la aplicación Fix It solo podría almacenar aproximadamente 40 000 tareas antes de alcanzar el tamaño máximo de la base de datos de 150 gigabytes. Después de quitar las imágenes, la base de datos puede almacenar 10 veces esa cantidad de tareas; puede continuar mucho más tiempo antes de tener que pensar en la implementación de un esquema de partición horizontal. Y, a medida que la aplicación modifica la escala, los gastos crecen más lentamente porque la mayor parte de las necesidades de almacenamiento van a caber en Blobs Storage que es muy económico.
Creación de particiones horizontales (particionamiento)
Crear porciones horizontales es como dividir una tabla por filas: un conjunto de filas entra en un almacén de datos y otro conjunto de filas entra en un almacén de datos diferente.
Dado el mismo conjunto de datos, otra opción sería almacenar diferentes rangos de nombres de cliente en distintas bases de datos.
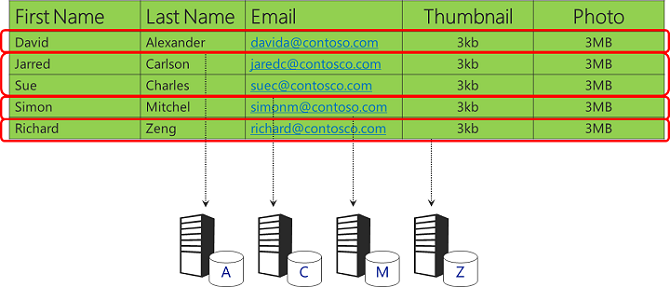
Querrá tener mucho cuidado con el esquema de particionamiento y asegurarse de que los datos se distribuyen uniformemente para evitar puntos calientes. Este ejemplo sencillo que usa la primera letra del apellido no cumple ese requisito, ya que muchas personas tienen apellidos que comienzan con determinadas letras comunes. Alcanzaría las limitaciones de tamaño de tabla antes de lo esperado, ya que algunas bases de datos obtendrían un tamaño muy grande, mientras que la mayoría seguiría siendo pequeña.
Un inconveniente de la creación de particiones horizontales es que es posible que sea difícil realizar consultas entre todos los datos. En este ejemplo, una consulta tendría que extraer entre 26 bases de datos diferentes para obtener todos los datos almacenados por la aplicación.
Particionamiento híbrido
Puede combinar particionamiento vertical y horizontal. Por ejemplo, en los datos de ejemplo podría almacenar las imágenes en Blob Storage y particionar horizontalmente los datos de cadena.
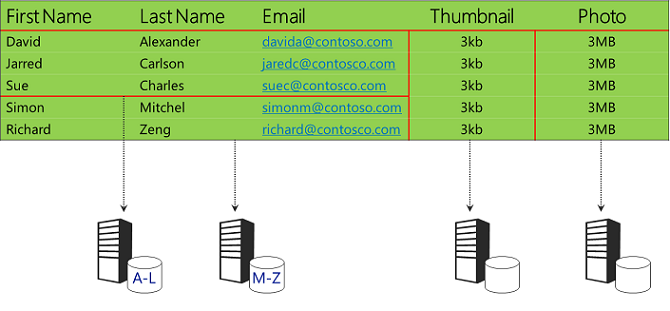
Creación de particiones de una aplicación de producción
Conceptualmente, es fácil ver cómo funcionaría un esquema de partición, pero cualquier esquema de partición aumenta la complejidad del código e introduce muchas complicaciones nuevas con las que tiene que lidiar. Si va a mover imágenes a Blob Storage, ¿qué haría cuando el servicio de almacenamiento está inactivo? ¿Cómo controla la seguridad de Blob? ¿Qué ocurre si la base de datos y Blob Storage salen de sincronía? Si va a particionar, ¿cómo controlará las consultas entre todas las bases de datos?
Las complicaciones son manejables siempre que haya planeando para ellas antes de ir a producción. Muchas personas que no hicieron esto más tarde desearon haberlo hecho. En promedio, nuestro Equipo de asesoramiento al cliente (CAT, por sus siglas en inglés) recibe llamadas telefónicas de pánico, aproximadamente una vez al mes de los clientes cuyas aplicaciones se están teniendo éxito de una manera muy sustancial y no lo hicieron. Y dicen algo así: "¡Ayuda! ¡Lo puse todo en un único almacén de datos y en 45 días me voy a quedar sin espacio en él!" Y, si tiene una gran cantidad de lógica de negocios integrada en cómo accede al almacén de datos y tiene clientes que usan la aplicación, no hay buen momento para quedar inactivo durante un día mientras migra. Terminamos pasando por los esfuerzos hercúleos para ayudar al cliente a crear particiones de sus datos sobre la marcha sin tiempo inactivo. ¡Es muy emocionante y asusta mucho, y no es algo en lo que quiere estar involucrado si puede evitarlo! Pensar en esto por adelantado e integrarlo en la aplicación hará que su vida sea mucho más fácil si la aplicación crece más adelante.
Resumen
Un esquema de partición eficaz puede permitir que la aplicación en la nube aumente la escala a petabytes de datos en la nube sin cuellos de botella. Y, no tiene que pagar por adelantado por máquinas masivas ni una infraestructura extensa, como podría ser si estuviera ejecutando la aplicación en un centro de datos local. En la nube, puede agregar capacidad que se incrementa según la necesite y solo paga por la cantidad que esté usando cuando la use.
En el siguiente capítulo, veremos cómo la aplicación Fix It implementa la creación de particiones verticales mediante el almacenamiento de imágenes en Blob Storage.
Recursos
Para obtener más información acerca de las estrategias de creación de particiones, vea los siguientes recursos.
Documentación:
- Prácticas recomendadas para el diseño de servicios a gran escala en Azure Cloud Services de Windows. Notas del producto por Mark Simms y Michael Thomassy.
- Patrones y prácticas de Microsoft: patrones de diseño en la nube. Consulte Guía de creación de particiones de datos, Patrón de particionamiento.
Videos:
- FailSafe: creación de servicios en la nube escalables y resistentes. Serie de vídeos de nueve partes por Ulrich Homann, Marc Mercuri y Mark Simms. Presenta conceptos de alto nivel y principios arquitectónicos de una manera muy accesible e interesante, con historias extraídas de la experiencia del Equipo de asesoramiento al cliente (CAT) de Microsoft con clientes reales. Vea la discusión de creación de particiones en el episodio 7.
- Crear en grande: lecciones aprendidas de clientes de Windows Azure: parte I. Mark Simms describe esquemas de partición, estrategias de particionamiento, cómo implementar particionamiento y federaciones de SQL Database a partir del minuto 19:49. Similar a la serie Failsafe, pero se incluyen más detalles de procedimientos.
Ejemplo de código:
- Aspectos básicos del servicio en la nube en Windows Azure. Aplicación de ejemplo que incluye una base de datos particionada. Para obtener una descripción del esquema de particionamiento implementado, consulte DAL : particionamiento de RDBMS en el blog de Windows Azure.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de