Manejo de errores transitorios (Creación de aplicaciones en la nube reales con Azure)
por Rick Anderson y Tom Dykstra
Descargar el proyecto Fix It o descargar el libro electrónico
El libro electrónico Building Real World Cloud Apps with Azure (Creación de aplicaciones reales en la nube con Azure) se basa en una presentación desarrollada por Scott Guthrie. En él se explican 13 patrones y procedimientos que pueden ayudarle a desarrollar correctamente aplicaciones web para la nube. Para obtener información sobre el libro electrónico, consulte el primer capítulo.
Al diseñar una aplicación en la nube para el mundo real, una de las cosas que tiene que pensar es cómo manejar las interrupciones temporales del servicio. Este problema es muy importante en las aplicaciones en la nube porque se depende mucho de las conexiones de red y los servicios externos. Con frecuencia puede obtener pequeños problemas que normalmente son de recuperación automática y, si no está preparado para manejarlos de forma inteligente, darán lugar a una mala experiencia para sus clientes.
Causas de errores transitorios
En el entorno de nube verá que las conexiones de base de datos con errores y anuladas se producen periódicamente. Esto se debe en parte a que está pasando por más equilibradores de carga en comparación con el entorno local, en el que el servidor web y el servidor de bases de datos tienen una conexión física directa. Además, a veces cuando dependa de un servicio multiinquilino, verá que las llamadas al servicio tardan más o se agota el tiempo de espera porque otra persona que usa el servicio lo está usando con fuerza. En otros casos, podría ser el usuario que está visitando el servicio con demasiada frecuencia y el servicio lo limita deliberadamente (deniega las conexiones) para evitar que afecte negativamente a otros inquilinos del servicio.
Usar una lógica inteligente de reintentos y retrocesos para mitigar el efecto de los errores transitorios
En lugar de producir una excepción y mostrar una página de error o no disponible para el cliente, puede reconocer errores que suelen ser transitorios y reintentar automáticamente la operación que produjo el error, con la esperanza de que se realice correctamente en no demasiado tiempo. La mayoría de las veces la operación se realizará correctamente en el segundo intento, y se recuperará del error sin que el cliente haya sido consciente de que hubo un problema.
Hay varias maneras de implementar la lógica de reintento inteligente.
El grupo Patrones y prácticas de Microsoft tiene un bloque de aplicaciones de control de errores transitorios (TFH) que se encarga de todo si usa ADO.NET para el acceso a SQL Database (no a través de Entity Framework). Simplemente se establece una directiva para los reintentos (cuántas veces se reintenta una consulta o un comando y cuánto tiempo se espera entre intentos) y se ajusta el código SQL en un bloque using.
public void HandleTransients() { var connStr = "some database"; var _policy = RetryPolicy.Create < SqlAzureTransientErrorDetectionStrategy( retryCount: 3, retryInterval: TimeSpan.FromSeconds(5)); using (var conn = new ReliableSqlConnection(connStr, _policy)) { // Do SQL stuff here. } }TFH también admite In-Role Cache para Azure y Service Bus.
Cuando se usa Entity Framework, normalmente no se trabaja directamente con conexiones SQL, por lo que no se puede usar este paquete de patrones y prácticas, pero Entity Framework 6 compila este tipo de lógica de reintento directamente en el marco. De forma similar, usted especifica la estrategia de reintento y, a continuación, EF usa esa estrategia cada vez que accede a la base de datos.
Para usar esta característica en la aplicación Fix It, todo lo que tenemos que hacer es agregar una clase que derive de DbConfiguration y active la lógica de reintento.
// EF follows a Code based Configuration model and will look for a class that // derives from DbConfiguration for executing any Connection Resiliency strategies public class EFConfiguration : DbConfiguration { public EFConfiguration() { AddExecutionStrategy(() => new SqlAzureExecutionStrategy()); } }En el caso de las excepciones de SQL Database que el marco identifica como errores transitorios habituales, el código que se muestra indica a EF que vuelva a intentar la operación hasta tres veces, con un retraso de retroceso exponencial entre reintentos y un retraso máximo de cinco segundos. El retroceso exponencial significa que después de cada reintento con error, esperará un período de tiempo más largo antes de volver a intentarlo. Si se produce un error en tres intentos seguidos se producirá una excepción. En la siguiente sección sobre los interruptores de circuito se explica por qué es deseable que el retroceso exponencial y un número limitado de reintentos.
Puede tener problemas similares al usar el servicio Azure Storage, como hace la aplicación Fix It hace para Blobs, y la API de cliente de almacenamiento de .NET ya implementa el mismo tipo de lógica. Simplemente especifique la directiva de reintento, o ni siquiera tiene que hacerlo si está satisfecho con la configuración predeterminada.
Interruptores
Hay varias razones por las que no es deseable reintentar demasiadas veces durante demasiado tiempo:
- Demasiados usuarios reintentando de forma persistente solicitudes con error pueden degradar la experiencia de otros usuarios. Si millones de personas están realizando solicitudes de reintento repetidamente, podría estar pasando a la máquina las colas de envío de IIS y evitando que la aplicación realice solicitudes de mantenimiento que, de lo contrario, podría controlar correctamente.
- Si todos el mundo está reintentando debido a un error de servicio, podría haber tantas solicitudes en cola que el servicio se sature cuando empiece a recuperarse.
- Si el error se debe a la limitación y hay un marco de tiempo que el servicio usa para la limitación, los reintentos continuos podrían mover ese marco y hacer que la limitación continúe.
- Es posible que tenga un usuario esperando a que se represente una página web. Hacer que las personas esperen demasiado tiempo puede ser más molesto que aconsejarles de forma relativamente rápida que vuelvan a intentarlo más tarde.
El retroceso exponencial soluciona algunos de estos problemas limitando la frecuencia de reintentos que un servicio puede obtener de la aplicación. Pero también debe tener interruptores de circuito: esto significa que, en un umbral de reintento determinado, la aplicación detiene los reintentos y realiza alguna otra acción, como una de las siguientes:
- Reserva personalizada. Si no puede obtener un precio de acciones de Reuters, tal vez puedas obtenerlo de Bloomberg; o si no puede obtener datos de la base de datos, quizás pueda obtenerlos de la memoria caché.
- Error silencioso. Si lo que necesita de un servicio para la aplicación no es todo o nada, solo tiene que devolver null cuando no pueda obtener los datos. Si muestra una tarea de Fix It y Blob service no está respondiendo, podría mostrar los detalles de la tarea sin la imagen.
- Error rápido. Genere un error al usuario para evitar saturar el servicio con solicitudes de reintento que podrían provocar interrupciones del servicio para otros usuarios o ampliar un marco de tiempo de limitación. Puede mostrar un mensaje descriptivo "inténtelo de nuevo más tarde".
No hay ninguna directiva de reintento para todos los casos. Puede reintentar más veces y esperar más tiempo en un proceso de trabajo en segundo plano asincrónico que en una aplicación web sincrónica en la que un usuario está esperando una respuesta. Puede esperar más tiempo entre reintentos para un servicio de base de datos relacional que para un servicio en caché. Estas son algunas directivas de reintento recomendadas de ejemplo para darle una idea de cómo pueden variar los números. ("Fast First" significa que no hay ningún retraso antes del primer reintento).
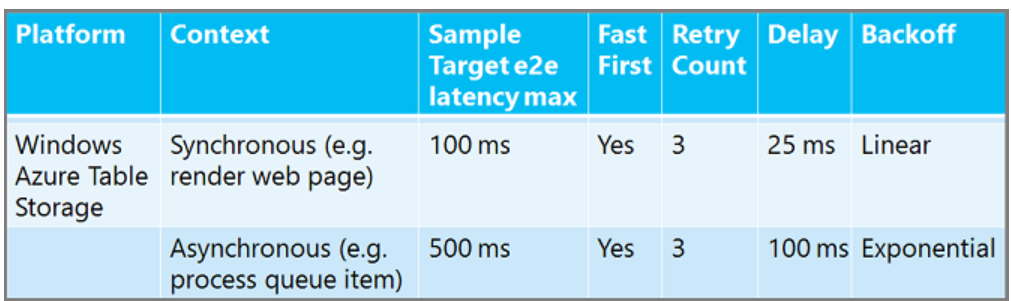
Para obtener instrucciones sobre la directiva de reintento de SQL Database, consulte Solución de errores transitorios y errores de conexión a SQL Database.
Resumen
Una estrategia de reintento o retroceso puede ayudar a hacer que los errores temporales sean invisibles para el cliente la mayor parte de las veces, y Microsoft proporciona marcos que puede usar para minimizar el trabajo implementando una estrategia tanto si usa ADO.NET, Entity Framework o el servicio Azure Storage.
En el siguiente capítulo veremos cómo mejorar el rendimiento y la confiabilidad mediante el almacenamiento en caché distribuido.
Recursos
Para obtener más información, consulte los siguientes recursos:
Documentación
- Procedimientos recomendados para el diseño de servicios a gran escala en Azure Cloud Services. Notas del producto de Mark Simms y Michael Thomassy. Similar a la serie Seguridad en caso de fallo, pero entra en más detalles prácticos. Consulte la sección Telemetría y diagnósticos.
- Seguridad en caso de fallo: instrucciones para crear arquitecturas de nube resistentes. Notas del producto de Marc Mercuri, Ulrich Homann y Andrew Townhill. Versión de página web de la serie de vídeos Seguridad en caso de fallo.
- Patrones y procedimientos de Microsoft: guía de Azure. Consulte Patrón de reintento, Patrón supervisor del agente Scheduler.
- Entity Framework: resistencia de conexión o lógicade reintento. Uso y personalización de la característica de control de errores transitorios de Entity Framework 6.
- Resistencia de conexión e interceptación de comandos con Entity Framework en una aplicación MVC de ASP.NET. El cuarto en una serie de nueve partes de tutoriales, muestra cómo configurar la característica de resistencia de conexión de EF 6 para SQL Database.
Vídeos
- Seguridad en caso de fallo: creación de servicios en la nube escalables y resistentes. Serie de nueve partes de Ulrich Homann, Marc Mercuri y Mark Simms. Presenta conceptos de alto nivel y principios arquitectónicos de una manera muy accesible e interesante, con historias extraídas de la experiencia del equipo de asesoramiento al cliente (CAT) de Microsoft con clientes reales. Vea la discusión de los interruptores de circuito en el episodio 3 a partir de 40:55.
- Construyendo a lo grande: lecciones de los clientes de Azure - Parte II. Mark Simms habla sobre el diseño para errores, el manejo de errores transitorios y la instrumentación de todo.
Código de ejemplo
- Aspectos básicos del servicio en la nube en Azure. Aplicación de ejemplo creada por el equipo de asesoramiento al cliente de Microsoft Azure que muestra cómo usar el Bloque de control de errores transitorios (TFH) de la biblioteca empresarial. Para obtener más información, consulte Capa de acceso a datos de fundamentos del servicio de nube: tratamiento de errores transitorios. Se recomienda TFH para el acceso a bases de datos mediante ADO.NET directamente (sin usar Entity Framework).
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de