Replicación de recursos mediante el replicador de suscripciones de Azure Stack Hub
Puede usar el script de PowerShell del replicador de suscripciones de Azure Stack Hub para copiar recursos entre suscripciones de Azure Stack Hub, entre marcas de Azure Stack Hub o entre Azure Stack Hub y Azure. El script del replicador lee y vuelve a generar los recursos de Azure Resource Manager de distintas suscripciones de Azure y Azure Stack Hub. En este artículo se describe cómo funciona el script y cómo se puede usar, y se proporciona una referencia para las operaciones del script.
Puede encontrar los scripts que se usaron en este artículo en el repositorio de GitHub Azure Intelligent Edge Patterns. Los scripts se encuentran en la carpeta del replicador de suscripciones.
Introducción al replicador de suscripciones
El replicador de suscripciones de Azure se diseñó para ser modular. Esta herramienta usa un procesador principal que organiza la replicación de recursos. Además, la herramienta admite procesadores personalizables que actúan como plantillas para copiar distintos tipos de recursos.
El procesador principal se compone de los tres scripts siguientes:
resource_retriever.ps1
Genera carpetas para almacenar los archivos de salida.
Establece el contexto para la suscripción de origen.
Recupera los recursos y los pasa a resource_processor.ps1.
resource_processor.ps1
Procesa el recurso pasado por resource_retriever.ps1.
Determina qué procesador personalizado hay que usar y pasa los recursos.
post_process.ps1
Realiza el posprocesamiento de la salida generada por el procesador personalizado para prepararla para su implementación en la suscripción de destino.
Genera código de implementación para implementar los recursos en la suscripción de destino.
Los tres scripts controlan el flujo de información de una manera estándar para permitir una mayor flexibilidad. Al agregar compatibilidad con recursos adicionales, por ejemplo, no es necesario cambiar el código del procesador principal.
Los procesadores personalizados, que se han mencionado anteriormente, son archivos ps1 que determinan cómo debe procesarse un determinado tipo de recurso. El nombre de un procesador personalizado siempre se denomina con los datos de tipo de un recurso. Por ejemplo, suponiendo que $vm contiene un objeto de máquina virtual, al ejecutar $vm, el tipo produciría Microsoft.Compute/virtualMachines. Esto significa que un procesador de una máquina virtual se podría denominar virtualMachines_processor.ps1; el nombre debe ser exactamente como aparece en los metadatos de recursos, ya que es la forma en que el procesador principal determina el procesador personalizado que se va a usar.
Un procesador personalizado determina cómo se debe replicar un recurso al determinar qué información es importante y dictar cómo se debe extraer la información de los metadatos de recursos. A continuación, el procesador personalizado toma todos los datos extraídos y los utiliza para generar un archivo de parámetros que se utilizará junto con una plantilla de Azure Resource Manager para implementar el recurso en la suscripción de destino. Este archivo de parámetros se almacena en Parameter_Files después de que el script post_process.ps1 lo procese.
Hay una carpeta en la estructura de archivos del replicador denominada Standardized_ARM_Templates. En función del entorno de origen, las implementaciones utilizarán una de estas plantillas de Azure Resource Manager normalizadas, o habrá que generar una plantilla de Azure Resource Manager personalizada. En este caso, el procesador personalizado debe llamar a un generador de plantillas de Azure Resource Manager. En el ejemplo iniciado anteriormente, el nombre de un generador de plantillas de Azure Resource Manager para máquinas virtuales se denominará virtualMachines_ARM_Template_Generator.ps1. El generador de plantillas de Azure Resource Manager es responsable de crear una plantilla de Azure Resource Manager personalizada basada en la información que se encuentra en los metadatos de un recurso. Por ejemplo, si el recurso de máquina virtual tiene metadatos que especifican que es miembro de un conjunto de disponibilidad, el generador de plantillas de Azure Resource Manager creará una plantilla de Azure Resource Manager con código que especifique el identificador del conjunto de disponibilidad del que forma parte la máquina virtual. De este modo, cuando la máquina virtual se implementa en la nueva suscripción, se agrega automáticamente al conjunto de disponibilidad en el momento de la implementación. Estas plantillas de Azure Resource Manager personalizadas se almacenan en la carpeta Custom_ARM_Templates, que se encuentra en la carpeta Standardized_ARM_Templates. El script post_processor.ps1 es responsable de determinar si una implementación debe utilizar una plantilla de Azure Resource Manager normalizada o una personalizada, así como de generar el código de implementación correspondiente.
El script post-orocess.ps1 es responsable de limpiar los archivos de parámetros y de crear los scripts que usará el usuario para implementar los nuevos recursos. Durante la fase de limpieza, el script reemplaza todas las referencias al identificador de la suscripción de origen, al identificador de inquilino y a la ubicación con los valores de destino correspondientes. Después, genera el archivo de parámetros en la carpeta Parameter_Files. A continuación, determina si el recurso que se está procesando usa o no una plantilla de Azure Resource Manager personalizada y genera el código de implementación correspondiente, que utiliza el cmdlet New-AzResourceGroupDeployment. Después, el código de implementación se agrega al archivo denominado DeployResources.ps1 almacenado en la carpeta Deployment_Files. Por último, el script determina el grupo de recursos al que pertenece el recurso y comprueba el script DeployResourceGroups.ps1 para ver si el código de implementación que implementa ese grupo de recursos ya existe. Si no es así, agregará código a ese script para implementar el grupo de recursos, en caso de que no haga nada.
Recuperación de API dinámica
La herramienta tiene una recuperación de API dinámica integrada, de modo que la versión más reciente de la API del proveedor de recursos disponible en la suscripción de origen se usa para implementar los recursos en la suscripción de destino:

Figura de la recuperación de la API en resource_processor.ps1
Sin embargo, existe la posibilidad de que la versión de la API del proveedor de recursos de la suscripción de destino sea anterior a la de la suscripción de origen y no admita la versión que se proporciona desde la suscripción de origen. En este caso, se producirá un error cuando se ejecute la implementación. Para resolver esto, actualice los proveedores de recursos de la suscripción de destino para que coincidan con los de la suscripción de origen.
Implementaciones paralelas
La herramienta requiere un parámetro denominado parallel. Este parámetro toma un valor booleano que especifica si los recursos recuperados se deben implementar en paralelo o no. Si el valor se establece en true, cada llamada a New-AzResourceGroupDeployment tendrá la marca -asJob y se agregarán bloques de código para esperar a que finalicen los trabajos paralelos en los conjuntos de implementaciones de recursos basados en los tipos de recursos. Garantiza que todos los recursos de un tipo se hayan implementado antes de implementar el siguiente tipo de recurso. Si el valor del parámetro parallel se establece en false, todos los recursos se implementarán en serie.
Incorporación de tipos de recursos adicionales
Agregar nuevos tipos de recursos es sencillo. El desarrollador debe crear un procesador personalizado y una plantilla de Azure Resource Manager o un generador de plantillas de Azure Resource Manager. Cuando haya finalizado, el desarrollador debe agregar el tipo de recurso a ValidateSet para el parámetro $resourceType y la matriz $resourceTypes en resource_retriever.ps1. Al agregar el tipo de recurso a la matriz $resourceTypes, debe hacerse en el orden correcto. El orden de la matriz determina el orden en que se implementarán los recursos, por lo que debe tener en cuenta las dependencias. Por último, si el procesador personalizado emplea un generador de plantillas de Azure Resource Manager, debe agregar el nombre del tipo de recurso a la matriz $customTypes en post_process.ps1.
Ejecución del replicador de suscripciones de Azure
Para ejecutar la herramienta del replicador de suscripciones de Azure (v3), deberá iniciar el script resource_retriever.ps1 y proporcionar todos los parámetros. En el parámetro resourceType, hay una opción para elegir todos en lugar de un tipo de recurso. Si se selecciona All (Todos), el script resource_retriever.ps1 procesará todos los recursos en un orden determinado de forma que, cuando se ejecute la implementación, los recursos dependientes se implementen en primer lugar. Por ejemplo, las redes virtuales se implementan antes que las máquinas virtuales, ya que las máquinas virtuales requieren una red virtual para que se implementen correctamente.
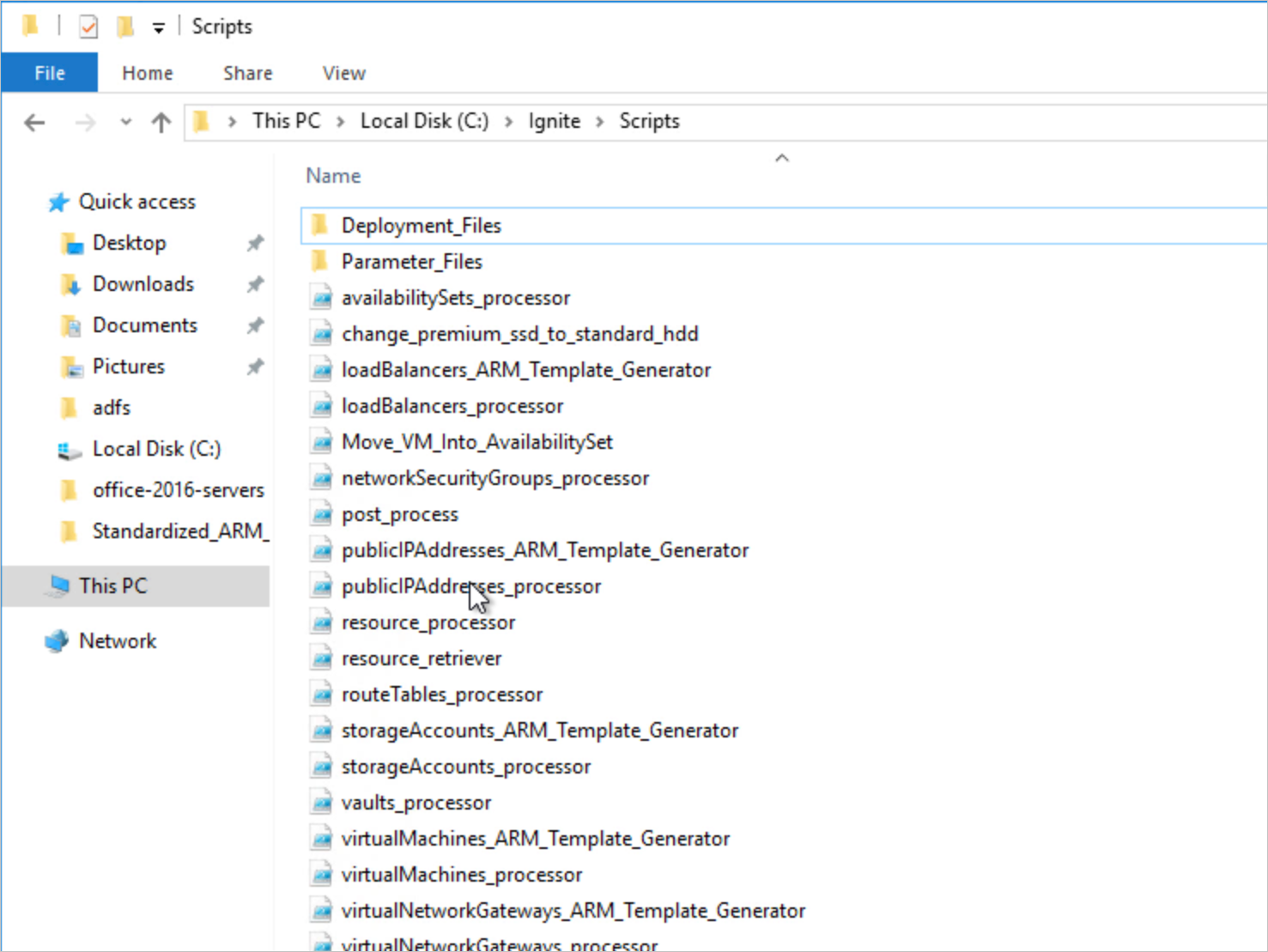
Cuando el script termine de ejecutarse, habrá tres nuevas carpetas, Deployment_Files, Parameter_Files y Custom_ARM_Templates.
Nota
Antes de ejecutar cualquiera de los scripts generados debe establecer el entorno correcto e iniciar sesión en la suscripción de destino (en la nueva instancia de Azure Stack Hub, por ejemplo) y establecer el directorio de trabajo en la carpeta Deployment_Files.
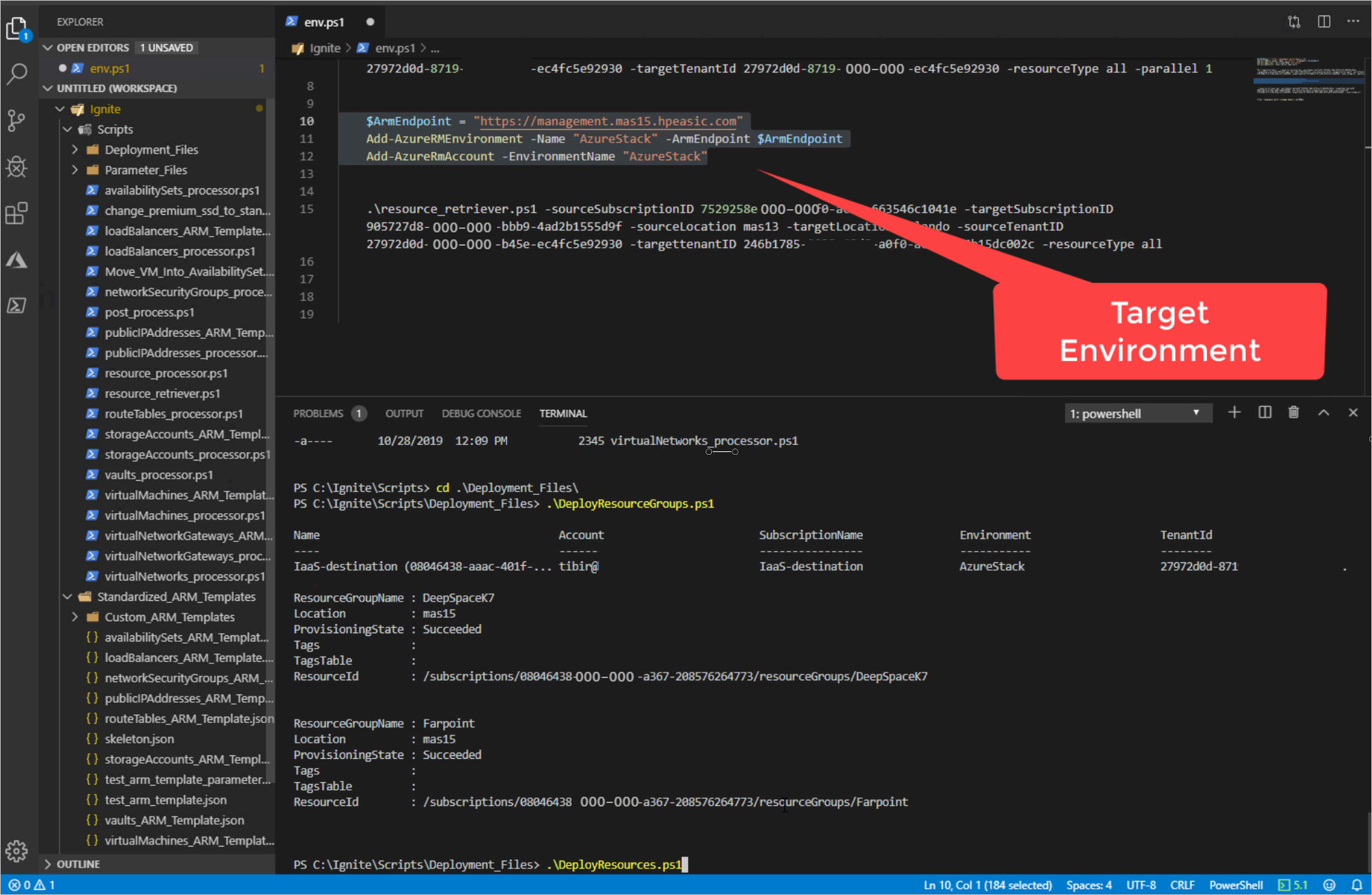
Deployment_Files contendrá dos archivos DeployResourceGroups.ps1 y DeployResources.ps1. Al ejecutar DeployResourceGroups.ps1, se implementarán los grupos de recursos. Al ejecutar DeployResources.ps1, se implementarán todos los recursos que se procesaron. En el caso de que la herramienta se ejecute con All (Todos) o Microsoft.Compute/virtualMachines como tipo de recurso, DeployResources.ps1 solicitará al usuario que escriba una contraseña de administrador de máquina virtual que se usará para crear todas las máquinas virtuales.
Ejemplo
Ejecute el script.
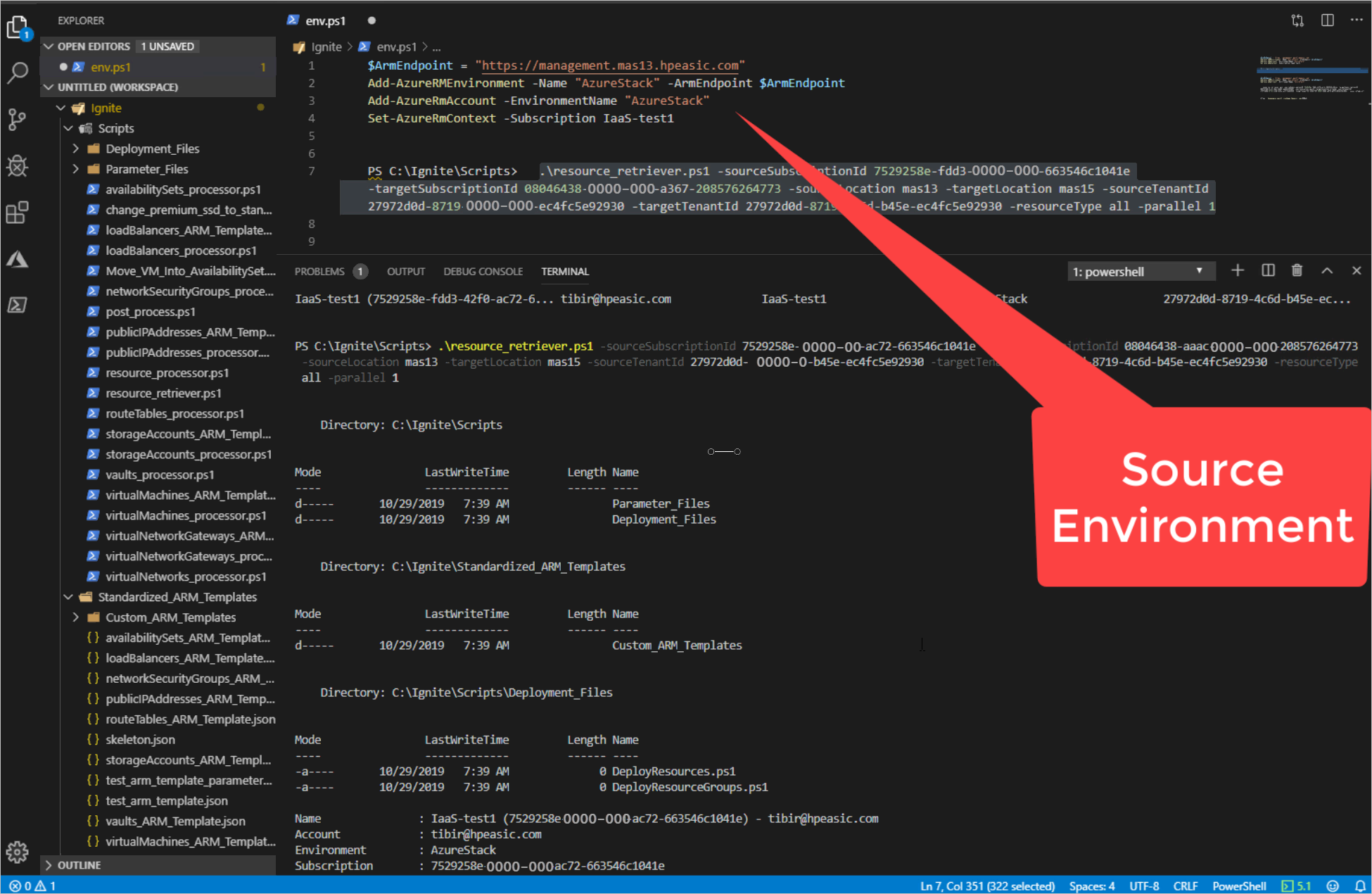
Nota
No olvide configurar el entorno de origen y el contexto de la suscripción para la instancia de PS.
Revise las carpetas recién creadas:
Establezca el contexto en la suscripción de destino, cambie la carpeta a Deployment_Files, implemente los grupos de recursos (ejecute el script DeployResourceGroups.ps1) e inicie la implementación de los recursos (ejecute el script DeployResources.ps1).
Ejecute
Get-Jobpara comprobar el estado. Get-Job | Receive-Job devolverá los resultados.
Limpieza
Dentro de la carpeta replicatorV3, el archivo denominado cleanup_generated_items.ps1 quitará las carpetas Deployment_Files, Parameter_Files y Custom_ARM_Templates y todo su contenido.
Operaciones del replicador de suscripciones
El replicador de suscripciones de Azure (v3) puede replicar actualmente los siguientes tipos de recursos:
Microsoft.Compute/availabilitySets
Microsoft.Compute/virtualMachines
Microsoft.Network/loadBalancers
Microsoft.Network/networkSecurityGroups
Microsoft.Network/publicIPAddresses
Microsoft.Network/routeTables
Microsoft.Network/virtualNetworks
Microsoft.Network/virtualNetworkGateways
Microsoft.Storage/storageAccounts
Al ejecutar la herramienta con All (Todos) como tipo de recurso, se seguirá el siguiente orden al realizar la replicación e implementación (en el ejemplo siguiente, todos los recursos tienen su configuración replicada, es decir, SKU, oferta, etc.):
Microsoft.Network/virtualNetworks
- Replica: todos los espacios de direcciones, todas las subredes
Microsoft.Network/virtualNetworkGateways
- Replica: configuración de IP pública, configuración de subred, tipo de VPN, tipo de puerta de enlace
Microsoft.Network/routeTables
Microsoft.Network/networkSecurityGroups
- Replica: todas las reglas de seguridad entrantes y salientes
Microsoft.Network/publicIPAddresses
Microsoft.Network/loadBalancers
- Replica: direcciones IP privadas, configuración de dirección IP pública, configuración de subred
Microsoft.Compute/availabilitySets
- Replica: número de dominios de error, número de dominios de actualización
Microsoft.Storage/storageAccounts
Microsoft.Compute/virtualMachines
- Replica:
- Discos de datos (sin datos)
- Tamaño de la máquina virtual
- Sistema operativo
- Configuración de la cuenta de almacenamiento de diagnósticos
- Configuración de IP pública
- Interfaz de red
- Dirección IP privada de interfaz de red
- Configuración de grupos de seguridad de red
- Configuración del conjunto de disponibilidad
- Replica:
Nota
Solo crea discos administrados para discos del sistema operativo y discos de datos. Actualmente, no se admite el uso de cuentas de almacenamiento.
Limitaciones
La herramienta puede replicar recursos de una suscripción a otra siempre que los proveedores de recursos de la suscripción de destino admitan todos los recursos y las opciones que se están replicando desde la suscripción de origen.
Para asegurarse de que la replicación se realiza correctamente, asegúrese de que las versiones del proveedor de recursos de la suscripción de destino coinciden con las de la suscripción de origen.
Al replicar desde un servicio de Azure comercial a otro o desde una suscripción de Azure Stack Hub a otra en la misma instancia de Azure Stack Hub, habrá problemas al replicar cuentas de almacenamiento. Esto se debe a que el requisito de nomenclatura de la cuenta de almacenamiento es que todos los nombres de las cuentas de almacenamiento sean únicos en todos los servicios de Azure comerciales o en todas las suscripciones de una región o instancia de Azure Stack Hub. La replicación de las cuentas de almacenamiento en distintas instancias de Azure Stack Hub se realizará correctamente, ya que las pilas son regiones o instancias independientes.
Pasos siguientes
Diferencias y consideraciones para las redes de Azure Stack Hub
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de