Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios para las versiones preliminares de Microsoft Azure.
En este artículo se explica cómo usar la API de finalizaciones de chat con modelos multimodales implementados en Azure AI Foundry Models. Además de la entrada de texto, los modelos multimodales pueden aceptar otros tipos de entrada, como imágenes o entrada de audio.
Prerrequisitos
Para usar los modelos de finalización de chat en la aplicación, necesita:
Una suscripción de Azure. Si usa modelos de GitHub, puede actualizar su experiencia y crear una suscripción de Azure en el proceso. Lea Actualización de modelos de GitHub a modelos de Azure AI Foundry si es su caso.
Un recurso de Azure AI Foundry (anteriormente conocido como Azure AI Services). Para más información, consulte Creación de un recurso de Azure AI Foundry.
Dirección URL y clave del punto de conexión.


Instale el paquete de inferencia de Azure AI para Python con el siguiente comando:
pip install -U azure-ai-inference
Implementación de modelos de finalizaciones de chat con compatibilidad con audio e imágenes. Si no tiene uno, consulte Agregar y configurar modelos de Fundición para agregar un modelo de finalizaciones de chat al recurso.
- En este artículo se usa
Phi-4-multimodal-instruct.
- En este artículo se usa
Uso de las finalizaciones de chat
En primer lugar, cree el cliente para consumir el modelo. El código siguiente usa una dirección URL de punto de conexión y una clave que se almacenan en variables de entorno.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint="https://<resource>.services.ai.azure.com/api/models",
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="Phi-4-multimodal-instruct"
)
Si ha configurado el recurso con compatibilidad con el identificador de Entra de Microsoft , puede usar el siguiente fragmento de código para crear un cliente.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint="https://<resource>.services.ai.azure.com/api/models",
credential=DefaultAzureCredential(),
model="Phi-4-multimodal-instruct"
)
Uso de finalizaciones de chat con imágenes
Algunos modelos pueden razonar entre texto e imágenes y generar finalizaciones de texto basadas en ambos tipos de entrada. En esta sección, exploras las funcionalidades de algunos modelos para la visión en un formato de chat.
Las imágenes se pueden pasar a los modelos mediante direcciones URL e incluyéndolas dentro de los mensajes con el rol de usuario. También puede usar direcciones URL de datos que le permiten insertar el contenido real del archivo dentro de una dirección URL codificada en base64 cadenas.
Consideremos la siguiente imagen que se puede descargar desde este origen:
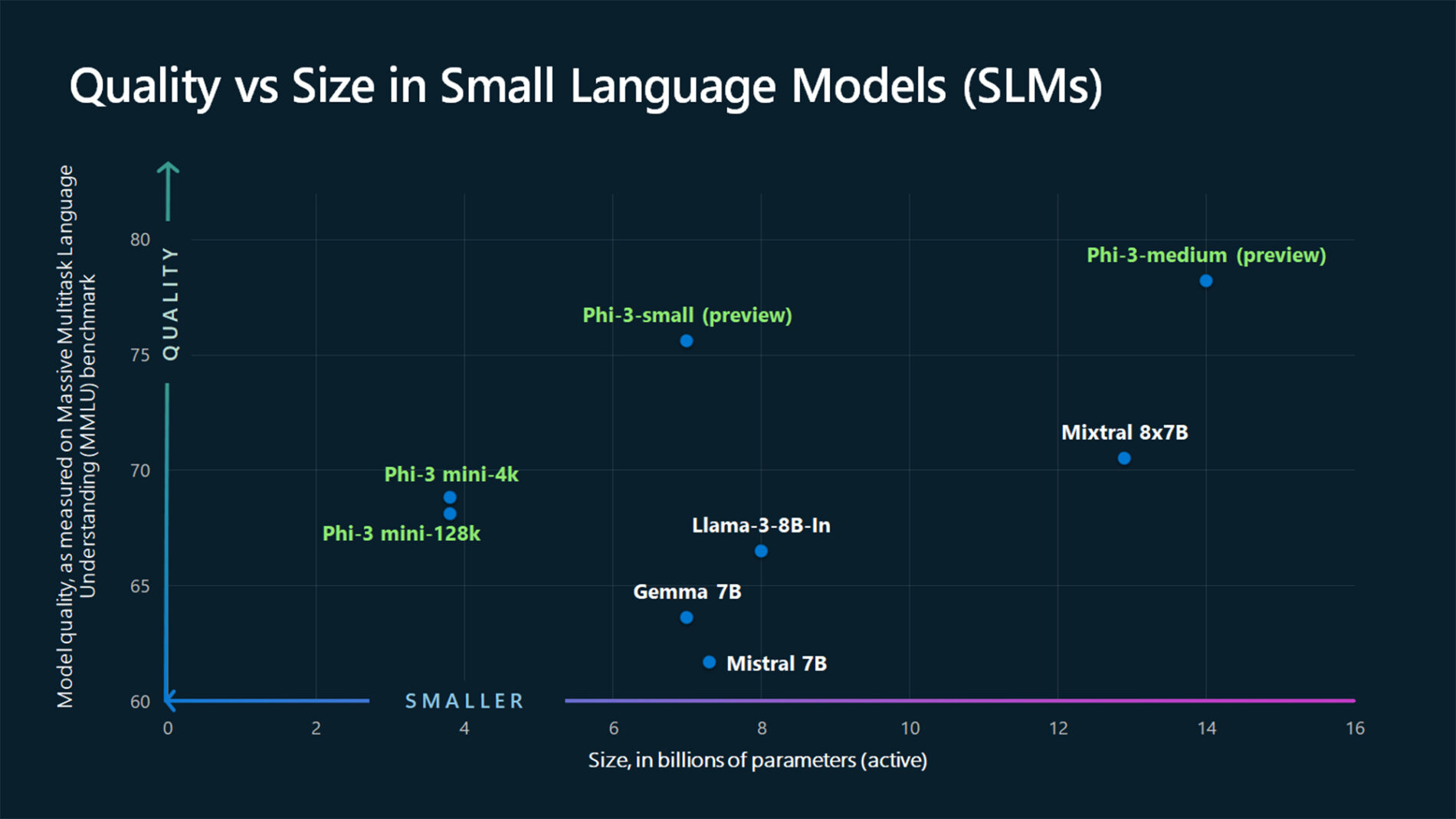{kind=link}

Puede cargar la imagen en una dirección URL de datos de la siguiente manera:
from azure.ai.inference.models import ImageContentItem, ImageUrl
data_url = ImageUrl.load(
image_file="The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg",
image_format="jpeg"
)
Las direcciones URL de datos tienen el formato data:image/{image_format};base64,{image_data_base64}.
Ahora, cree una solicitud de finalización de chat con la imagen:
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image_url=data_url)
]),
],
temperature=1,
max_tokens=2048,
)
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
print(f"{response.choices[0].message.role}: {response.choices[0].message.content}")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: phi-4-omni
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Uso
Las imágenes se dividen en tokens y se envían al modelo para su procesamiento. Al hacer referencia a imágenes, cada uno de esos tokens se conoce normalmente como revisiones. Cada modelo puede desglosar una imagen determinada en un número diferente de revisiones. Lea la tarjeta de modelo para obtener información sobre los detalles.
Conversaciones multiturno
Hay modelos que solo admiten una imagen para cada turno en la conversación de chat y solo se conserva la última imagen en contexto. Si agrega varias imágenes, se producirá un error. Lea la tarjeta de modelo para comprender el caso de cada modelo.
Direcciones URL de imagen
El modelo puede leer el contenido desde una ubicación de nube accesible pasando la dirección URL como entrada. Este enfoque requiere que la dirección URL sea pública y no requiera un control específico.
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg"
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image_url=ImageUrl(image_url))
]),
],
temperature=1,
max_tokens=2048,
)
Uso de finalizaciones de chat con audio
Algunos modelos pueden razonar entre entradas de texto y audio. En el ejemplo siguiente se muestra cómo puede enviar contexto de audio a modelos de finalizaciones de chat que también admiten audio. Use InputAudio para cargar el contenido del archivo de audio en la carga útil. El contenido se codifica en los datos base64 y se envía a través de la carga.
from azure.ai.inference.models import (
TextContentItem,
AudioContentItem,
InputAudio,
AudioContentFormat,
)
response = client.complete(
messages=[
SystemMessage("You are an AI assistant for translating and transcribing audio clips."),
UserMessage(
[
TextContentItem(text="Please translate this audio snippet to spanish."),
AudioContentItem(
input_audio=InputAudio.load(
audio_file="hello_how_are_you.mp3", audio_format=AudioContentFormat.MP3
)
),
],
),
],
)
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
print(f"{response.choices[0].message.role}: {response.choices[0].message.content}")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: Hola. ¿Cómo estás?
Model: speech
Usage:
Prompt tokens: 77
Completion tokens: 7
Total tokens: 84
El modelo puede leer el contenido desde una ubicación de nube accesible pasando la dirección URL como entrada. El SDK de Python no proporciona una manera directa de hacerlo, pero puede indicar la carga como se indica a continuación:
response = client.complete(
{
"messages": [
{
"role": "system",
"content": "You are an AI assistant for translating and transcribing audio clips.",
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please translate this audio snippet to spanish."
},
{
"type": "audio_url",
"audio_url": {
"url": "https://.../hello_how_are_you.mp3"
}
}
]
},
],
}
)
Uso
El audio se divide en tokens y se envía al modelo para su procesamiento. Algunos modelos pueden funcionar directamente sobre tokens de audio, mientras que otros pueden usar módulos internos para realizar conversión de voz en texto, lo que da lugar a diferentes estrategias para calcular tokens. Lea la tarjeta de modelo para obtener más información sobre cómo funciona cada modelo.
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios para las versiones preliminares de Microsoft Azure.
En este artículo se explica cómo usar la API de finalizaciones de chat con modelos multimodales implementados en Azure AI Foundry Models. Además de la entrada de texto, los modelos multimodales pueden aceptar otros tipos de entrada, como imágenes o entrada de audio.
Prerrequisitos
Para usar los modelos de finalización de chat en la aplicación, necesita:
Una suscripción de Azure. Si usa modelos de GitHub, puede actualizar su experiencia y crear una suscripción de Azure en el proceso. Lea Actualización de modelos de GitHub a modelos de Azure AI Foundry si es su caso.
Un recurso de Azure AI Foundry (anteriormente conocido como Azure AI Services). Para más información, consulte Creación de un recurso de Azure AI Foundry.
Dirección URL y clave del punto de conexión.
Instale la biblioteca de inferencia de Azure para JavaScript con el siguiente comando:
npm install @azure-rest/ai-inference npm install @azure/core-auth npm install @azure/identitySi usa Node.js, puede configurar las dependencias en package.json:
package.json
{ "name": "main_app", "version": "1.0.0", "description": "", "main": "app.js", "type": "module", "dependencies": { "@azure-rest/ai-inference": "1.0.0-beta.6", "@azure/core-auth": "1.9.0", "@azure/core-sse": "2.2.0", "@azure/identity": "4.8.0" } }Importe lo siguiente:
import ModelClient from "@azure-rest/ai-inference"; import { isUnexpected } from "@azure-rest/ai-inference"; import { createSseStream } from "@azure/core-sse"; import { AzureKeyCredential } from "@azure/core-auth"; import { DefaultAzureCredential } from "@azure/identity";
Implementación de modelos de finalizaciones de chat con compatibilidad con audio e imágenes. Si no tiene uno, consulte Agregar y configurar modelos de Fundición para agregar un modelo de finalizaciones de chat al recurso.
- En este artículo se usa
Phi-4-multimodal-instruct.
- En este artículo se usa
Uso de las finalizaciones de chat
En primer lugar, cree el cliente para consumir el modelo. El código siguiente usa una dirección URL de punto de conexión y una clave que se almacenan en variables de entorno.
const client = ModelClient(
"https://<resource>.services.ai.azure.com/api/models",
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
Si ha configurado el recurso con compatibilidad con el identificador de Entra de Microsoft , puede usar el siguiente fragmento de código para crear un cliente.
const clientOptions = { credentials: { "https://cognitiveservices.azure.com" } };
const client = ModelClient(
"https://<resource>.services.ai.azure.com/api/models",
new DefaultAzureCredential()
clientOptions,
);
Uso de finalizaciones de chat con imágenes
Algunos modelos pueden razonar entre texto e imágenes y generar finalizaciones de texto basadas en ambos tipos de entrada. En esta sección, exploras las funcionalidades de algunos modelos para la visión en un formato de chat.
Importante
Hay modelos que solo admiten una imagen para cada turno en la conversación de chat y solo se conserva la última imagen en contexto. Si agrega varias imágenes, se producirá un error.
Para ver esta funcionalidad, descargue una imagen y codifique la información como base64 cadena. Los datos resultantes deben estar dentro de una Dirección URL de datos:
const image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
const image_format = "jpeg";
const response = await fetch(image_url, { headers: { "User-Agent": "Mozilla/5.0" } });
const image_data = await response.arrayBuffer();
const image_data_base64 = Buffer.from(image_data).toString("base64");
const data_url = `data:image/${image_format};base64,${image_data_base64}`;
Visualizar la imagen:
const img = document.createElement("img");
img.src = data_url;
document.body.appendChild(img);
Ahora, cree una solicitud de finalización de chat con la imagen:
var messages = [
{ role: "system", content: "You are a helpful assistant that can generate responses based on images." },
{ role: "user", content:
[
{ type: "text", text: "Which conclusion can be extracted from the following chart?" },
{ type: "image_url", image:
{
url: data_url
}
}
]
}
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
model: "Phi-4-multimodal-instruct",
}
});
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
console.log(response.body.choices[0].message.role + ": " + response.body.choices[0].message.content);
console.log("Model:", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: Phi-4-multimodal-instruct
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Uso
Las imágenes se dividen en tokens y se envían al modelo para su procesamiento. Al hacer referencia a imágenes, cada uno de esos tokens se conoce normalmente como revisiones. Cada modelo puede desglosar una imagen determinada en un número diferente de revisiones. Lea la tarjeta de modelo para obtener información sobre los detalles.
Conversaciones multiturno
Hay modelos que solo admiten una imagen para cada turno en la conversación de chat y solo se conserva la última imagen en contexto. Si agrega varias imágenes, se producirá un error. Lea la tarjeta de modelo para comprender el caso de cada modelo.
Direcciones URL de imagen
El modelo puede leer el contenido desde una ubicación de nube accesible pasando la dirección URL como entrada. Este enfoque requiere que la dirección URL sea pública y no requiera un control específico.
Uso de finalizaciones de chat con audio
Algunos modelos pueden razonar entre entradas de texto y audio. En el ejemplo siguiente se muestra cómo puede enviar contexto de audio a modelos de finalizaciones de chat que también admiten audio.
En este ejemplo, creamos una función getAudioData para cargar el contenido del archivo de audio codificado como datos en base64, tal y como el modelo lo espera.
import fs from "node:fs";
/**
* Get the Base 64 data of an audio file.
* @param {string} audioFile - The path to the image file.
* @returns {string} Base64 data of the audio.
*/
function getAudioData(audioFile: string): string {
try {
const audioBuffer = fs.readFileSync(audioFile);
return audioBuffer.toString("base64");
} catch (error) {
console.error(`Could not read '${audioFile}'.`);
console.error("Set the correct path to the audio file before running this sample.");
process.exit(1);
}
}
Ahora vamos a usar esta función para cargar el contenido de un archivo de audio almacenado en el disco. Enviamos el contenido del archivo de audio en un mensaje de usuario. Observe que en la solicitud también indicamos el formato del contenido de audio:
const audioFilePath = "hello_how_are_you.mp3"
const audioFormat = "mp3"
const audioData = getAudioData(audioFilePath);
const systemMessage = { role: "system", content: "You are an AI assistant for translating and transcribing audio clips." };
const audioMessage = {
role: "user",
content: [
{ type: "text", text: "Translate this audio snippet to spanish."},
{ type: "input_audio",
input_audio: {
audioData,
audioFormat,
},
},
]
};
const response = await client.path("/chat/completions").post({
body: {
messages: [
systemMessage,
audioMessage
],
model: "Phi-4-multimodal-instruct",
},
});
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log("Response: ", response.body.choices[0].message.content);
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
ASSISTANT: Hola. ¿Cómo estás?
Model: speech
Usage:
Prompt tokens: 77
Completion tokens: 7
Total tokens: 84
El modelo puede leer el contenido desde una ubicación de nube accesible pasando la dirección URL como entrada. El SDK de Python no proporciona una manera directa de hacerlo, pero puede indicar la carga como se indica a continuación:
const systemMessage = { role: "system", content: "You are a helpful assistant." };
const audioMessage = {
role: "user",
content: [
{ type: "text", text: "Transcribe this audio."},
{ type: "audio_url",
audio_url: {
url: "https://example.com/audio.mp3",
},
},
]
};
const response = await client.path("/chat/completions").post({
body: {
messages: [
systemMessage,
audioMessage
],
model: "Phi-4-multimodal-instruct",
},
});
Uso
El audio se divide en tokens y se envía al modelo para su procesamiento. Algunos modelos pueden funcionar directamente sobre tokens de audio, mientras que otros pueden usar módulos internos para realizar conversión de voz en texto, lo que da lugar a diferentes estrategias para calcular tokens. Lea la tarjeta de modelo para obtener más información sobre cómo funciona cada modelo.
En este artículo se explica cómo usar la API de finalizaciones de chat con modelos multimodales implementados en Azure AI Foundry Models. Además de la entrada de texto, los modelos multimodales pueden aceptar otros tipos de entrada, como imágenes o entrada de audio.
Prerrequisitos
Para usar los modelos de finalización de chat en la aplicación, necesita:
Una suscripción de Azure. Si usa modelos de GitHub, puede actualizar su experiencia y crear una suscripción de Azure en el proceso. Lea Actualización de modelos de GitHub a modelos de Azure AI Foundry si es su caso.
Un recurso de Azure AI Foundry (anteriormente conocido como Azure AI Services). Para más información, consulte Creación de un recurso de Azure AI Foundry.
Dirección URL y clave del punto de conexión.
Agregue el paquete de inferencia de Azure AI al proyecto:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.4</version> </dependency>Si usa Entra ID, también necesita el siguiente paquete:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.15.3</version> </dependency>Importe los siguientes espacios de nombres:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.ChatCompletionsClient; import com.azure.ai.inference.ChatCompletionsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.ai.inference.models.ChatCompletions; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Una implementación de un modelo para completar conversaciones de chat. Si no tienes uno, lee Agregar y configurar modelos de Foundry para añadir un modelo de finalizaciones de chat a tu recurso.
- En este ejemplo se usa
phi-4-multimodal-instruct.
- En este ejemplo se usa
Uso de las finalizaciones de chat
En primer lugar, cree el cliente para consumir el modelo. El código siguiente usa una dirección URL de punto de conexión y una clave que se almacenan en variables de entorno.
ChatCompletionsClient client = new ChatCompletionsClientBuilder()
.credential(new AzureKeyCredential("{key}"))
.endpoint("https://<resource>.services.ai.azure.com/api/models")
.buildClient();
Si ha configurado el recurso con compatibilidad con el identificador de Entra de Microsoft , puede usar el siguiente fragmento de código para crear un cliente.
TokenCredential defaultCredential = new DefaultAzureCredentialBuilder().build();
ChatCompletionsClient client = new ChatCompletionsClientBuilder()
.credential(defaultCredential)
.endpoint("https://<resource>.services.ai.azure.com/api/models")
.buildClient();
Uso de finalizaciones de chat con imágenes
Algunos modelos pueden razonar entre texto e imágenes y generar finalizaciones de texto basadas en ambos tipos de entrada. En esta sección, explorará las funcionalidades de algunos modelos para la visión en forma de chat:
Para ver esta funcionalidad, descargue una imagen y codifique la información como base64 cadena. Los datos resultantes deben estar dentro de una Dirección URL de datos:
Path testFilePath = Paths.get("small-language-models-chart-example.jpg");
String imageFormat = "jpg";
Visualizar la imagen:
Ahora, cree una solicitud de finalización de chat con la imagen:
List<ChatMessageContentItem> contentItems = new ArrayList<>();
contentItems.add(new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"));
contentItems.add(new ChatMessageImageContentItem(testFilePath, imageFormat));
List<ChatRequestMessage> chatMessages = new ArrayList<>();
chatMessages.add(new ChatRequestSystemMessage("You are an AI assistant that helps people find information."));
chatMessages.add(ChatRequestUserMessage.fromContentItems(contentItems));
ChatCompletionsOptions options = new ChatCompletionsOptions(chatMessages);
options.setModel("phi-4-multimodal-instruct")
ChatCompletions response = client.complete(options);
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
System.out.println("Response: " + response.getValue().getChoices().get(0).getMessage().getContent());
System.out.println("Model: " + response.getValue().getModel());
System.out.println("Usage:");
System.out.println("\tPrompt tokens: " + response.getValue().getUsage().getPromptTokens());
System.out.println("\tTotal tokens: " + response.getValue().getUsage().getTotalTokens());
System.out.println("\tCompletion tokens: " + response.getValue().getUsage().getCompletionTokens());
Uso
Las imágenes se dividen en tokens y se envían al modelo para su procesamiento. Al hacer referencia a imágenes, cada uno de esos tokens se conoce normalmente como revisiones. Cada modelo puede desglosar una imagen determinada en un número diferente de revisiones. Lea la tarjeta de modelo para obtener información sobre los detalles.
Conversaciones multiturno
Hay modelos que solo admiten una imagen para cada turno en la conversación de chat y solo se conserva la última imagen en contexto. Si agrega varias imágenes, se producirá un error. Lea la tarjeta de modelo para comprender el caso de cada modelo.
Direcciones URL de imagen
El modelo puede leer el contenido desde una ubicación de nube accesible pasando la dirección URL como entrada. Este enfoque requiere que la dirección URL sea pública y no requiera un control específico.
Path testFilePath = Paths.get("https://.../small-language-models-chart-example.jpg");
List<ChatMessageContentItem> contentItems = new ArrayList<>();
contentItems.add(new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"));
contentItems.add(new ChatMessageImageContentItem(
new ChatMessageImageUrl(testFilePath)));
List<ChatRequestMessage> chatMessages = new ArrayList<>();
chatMessages.add(new ChatRequestSystemMessage("You are an AI assistant that helps people find information."));
chatMessages.add(ChatRequestUserMessage.fromContentItems(contentItems));
ChatCompletionsOptions options = new ChatCompletionsOptions(chatMessages);
options.setModel("phi-4-multimodal-instruct")
ChatCompletions response = client.complete(options);
Uso de finalizaciones de chat con audio
Algunos modelos pueden razonar entre entradas de texto y audio. Esta funcionalidad no está disponible en el paquete de inferencia de Azure AI para Java.
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios para las versiones preliminares de Microsoft Azure.
En este artículo se explica cómo usar la API de finalizaciones de chat con modelos multimodales implementados en Azure AI Foundry Models. Además de la entrada de texto, los modelos multimodales pueden aceptar otros tipos de entrada, como imágenes o entrada de audio.
Prerrequisitos
Para usar los modelos de finalización de chat en la aplicación, necesita:
Una suscripción de Azure. Si usa modelos de GitHub, puede actualizar su experiencia y crear una suscripción de Azure en el proceso. Lea Actualización de modelos de GitHub a modelos de Azure AI Foundry si es su caso.
Un recurso de Azure AI Foundry (anteriormente conocido como Azure AI Services). Para más información, consulte Creación de un recurso de Azure AI Foundry.
Dirección URL y clave del punto de conexión.
Instale el paquete de inferencia de Azure AI con el siguiente comando:
dotnet add package Azure.AI.Inference --prereleaseSi usa Entra ID, también necesita el siguiente paquete:
dotnet add package Azure.Identity
Una implementación de un modelo para completar conversaciones de chat. Si no tiene uno, lea Agregar y configurar modelos de Foundry para agregar un modelo de finalizaciones de chat al recurso.
- En este ejemplo se usa
phi-4-multimodal-instruct.
- En este ejemplo se usa
Uso de las finalizaciones de chat
En primer lugar, cree el cliente para consumir el modelo. El código siguiente usa una dirección URL de punto de conexión y una clave que se almacenan en variables de entorno.
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri("https://<resource>.services.ai.azure.com/api/models"),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
);
Si ha configurado el recurso con compatibilidad con el identificador de Entra de Microsoft , puede usar el siguiente fragmento de código para crear un cliente.
client = new ChatCompletionsClient(
new Uri("https://<resource>.services.ai.azure.com/api/models"),
new DefaultAzureCredential(),
);
Uso de finalizaciones de chat con imágenes
Algunos modelos pueden razonar entre texto e imágenes y generar finalizaciones de texto basadas en ambos tipos de entrada. En esta sección, explorará las funcionalidades de algunos modelos para la visión en forma de chat:
Importante
Hay modelos que solo admiten una imagen para cada turno en la conversación de chat y solo se conserva la última imagen en contexto. Si agrega varias imágenes, se producirá un error.
Para ver esta funcionalidad, descargue una imagen y codifique la información como base64 cadena. Los datos resultantes deben estar dentro de una Dirección URL de datos:
string imageUrl = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
string imageFormat = "jpeg";
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0");
byte[] imageBytes = httpClient.GetByteArrayAsync(imageUrl).Result;
string imageBase64 = Convert.ToBase64String(imageBytes);
string dataUrl = $"data:image/{imageFormat};base64,{imageBase64}";
Visualizar la imagen:
Ahora, cree una solicitud de finalización de chat con la imagen:
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage([
new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"),
new ChatMessageImageContentItem(new Uri(dataUrl))
]),
},
MaxTokens=2048,
Model = "Phi-4-multimodal-instruct",
};
var response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: Phi-4-multimodal-instruct
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Uso
Las imágenes se dividen en tokens y se envían al modelo para su procesamiento. Al hacer referencia a imágenes, cada uno de esos tokens se conoce normalmente como revisiones. Cada modelo puede desglosar una imagen determinada en un número diferente de revisiones. Lea la tarjeta de modelo para obtener información sobre los detalles.
Conversaciones multiturno
Hay modelos que solo admiten una imagen para cada turno en la conversación de chat y solo se conserva la última imagen en contexto. Si agrega varias imágenes, se producirá un error. Lea la tarjeta de modelo para comprender el caso de cada modelo.
Direcciones URL de imagen
El modelo puede leer el contenido desde una ubicación de nube accesible pasando la dirección URL como entrada. Este enfoque requiere que la dirección URL sea pública y no requiera un control específico.
Uso de finalizaciones de chat con audio
Algunos modelos pueden razonar entre entradas de texto y audio. En el ejemplo siguiente se muestra cómo puede enviar contexto de audio a modelos de finalizaciones de chat que también admiten audio. Use InputAudio para cargar el contenido del archivo de audio en la carga útil. El contenido se codifica en los datos base64 y se envía a través de la carga.
var requestOptions = new ChatCompletionsOptions()
{
Messages =
{
new ChatRequestSystemMessage("You are an AI assistant for translating and transcribing audio clips."),
new ChatRequestUserMessage(
new ChatMessageTextContentItem("Please translate this audio snippet to spanish."),
new ChatMessageAudioContentItem("hello_how_are_you.mp3", AudioContentFormat.Mp3),
},
};
Response<ChatCompletions> response = client.Complete(requestOptions);
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: Hola. ¿Cómo estás?
Model: speech
Usage:
Prompt tokens: 77
Completion tokens: 7
Total tokens: 84
El modelo puede leer el contenido desde una ubicación de nube accesible pasando la dirección URL como entrada. El SDK de Python no proporciona una manera directa de hacerlo, pero puede indicar la carga como se indica a continuación:
var requestOptions = new ChatCompletionsOptions()
{
Messages =
{
new ChatRequestSystemMessage("You are an AI assistant for translating and transcribing audio clips."),
new ChatRequestUserMessage(
new ChatMessageTextContentItem("Please translate this audio snippet to spanish."),
new ChatMessageAudioContentItem(new Uri("https://.../hello_how_are_you.mp3"))),
},
};
Response<ChatCompletions> response = client.Complete(requestOptions);
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: Hola. ¿Cómo estás?
Model: speech
Usage:
Prompt tokens: 77
Completion tokens: 7
Total tokens: 84
Uso
El audio se divide en tokens y se envía al modelo para su procesamiento. Algunos modelos pueden funcionar directamente sobre tokens de audio, mientras que otros pueden usar módulos internos para realizar conversión de voz en texto, lo que da lugar a diferentes estrategias para calcular tokens. Lea la tarjeta de modelo para obtener más información sobre cómo funciona cada modelo.
Importante
Los elementos marcados (versión preliminar) en este artículo se encuentran actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin acuerdo de nivel de servicio y no se recomienda para las cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios para las versiones preliminares de Microsoft Azure.
En este artículo se explica cómo usar la API de finalizaciones de chat con modelos multimodales implementados en Azure AI Foundry Models. Además de la entrada de texto, los modelos multimodales pueden aceptar otros tipos de entrada, como imágenes o entrada de audio.
Prerrequisitos
Para usar los modelos de finalización de chat en la aplicación, necesita:
Una suscripción de Azure. Si usa modelos de GitHub, puede actualizar su experiencia y crear una suscripción de Azure en el proceso. Lea Actualización de modelos de GitHub a modelos de Azure AI Foundry si es su caso.
Un recurso de Azure AI Foundry (anteriormente conocido como Azure AI Services). Para más información, consulte Creación de un recurso de Azure AI Foundry.
Dirección URL y clave del punto de conexión.
Una implementación de un modelo para completar conversaciones de chat. Si no tiene uno, consulte Agregar y configurar modelos de Fundición para agregar un modelo de finalizaciones de chat al recurso.
- En este artículo se usa
Phi-4-multimodal-instruct.
- En este artículo se usa
Uso de las finalizaciones de chat
Para usar la API de finalizaciones de chat, use la ruta /chat/completions añadida a la URL base, junto con la credencial indicada en api-key. El encabezado Authorization también se admite con el formato Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Si ha configurado el recurso con compatibilidad con Microsoft Entra ID, pase el token en el encabezado Authorization con el formato Bearer <token>. Use el ámbito https://cognitiveservices.azure.com/.default.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
El uso de Microsoft Entra ID puede requerir una configuración adicional en el recurso para conceder acceso. Obtenga información sobre cómo configurar la autenticación sin claves con el identificador de Microsoft Entra.
Uso de finalizaciones de chat con imágenes
Algunos modelos pueden razonar entre texto e imágenes y generar finalizaciones de texto basadas en ambos tipos de entrada. En esta sección, explorará las funcionalidades de algunos modelos para la visión en forma de chat:
Importante
Hay modelos que solo admiten una imagen para cada turno en la conversación de chat y solo se conserva la última imagen en contexto. Si agrega varias imágenes, se producirá un error.
Para ver esta funcionalidad, descargue una imagen y codifique la información como base64 cadena. Los datos resultantes deben estar dentro de una Dirección URL de datos:
Sugerencia
Debe construir la dirección URL de datos mediante un scripting o lenguaje de programación. En este artículo se usa esta imagen de ejemplo en formato JPEG. Una dirección URL de datos tiene un formato como sigue: data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ....
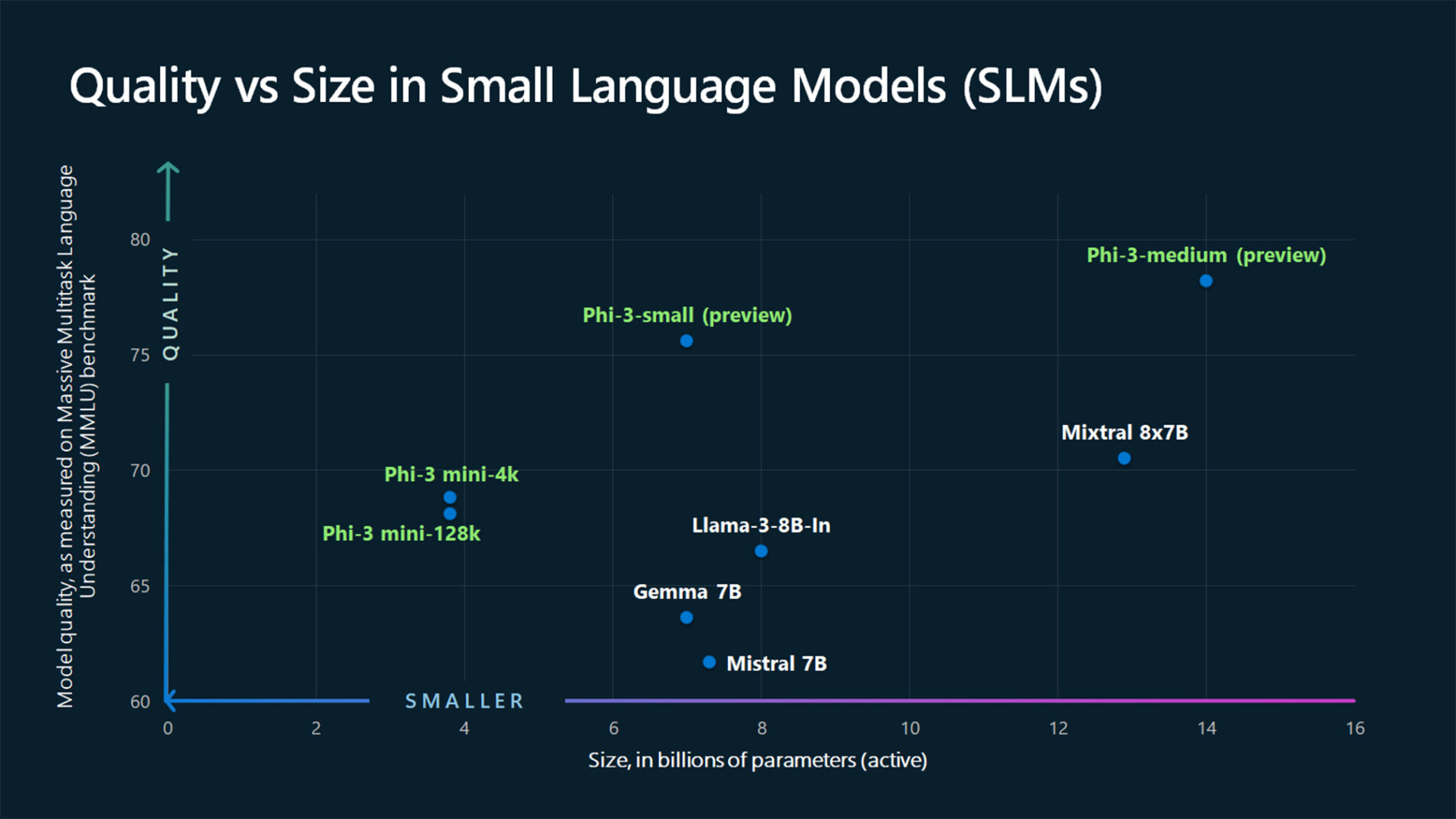{kind=link}
Visualizar la imagen:
Ahora, cree una solicitud de finalización de chat con la imagen:
{
"model": "Phi-4-multimodal-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which peculiar conclusion about LLMs and SLMs can be extracted from the following chart?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ..."
}
}
]
}
],
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "Phi-4-multimodal-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 2380,
"completion_tokens": 126,
"total_tokens": 2506
}
}
Las imágenes se dividen en tokens y se envían al modelo para su procesamiento. Al hacer referencia a imágenes, cada uno de esos tokens se conoce normalmente como revisiones. Cada modelo puede desglosar una imagen determinada en un número diferente de revisiones. Lea la tarjeta de modelo para obtener información sobre los detalles.
Uso de finalizaciones de chat con audio
Algunos modelos pueden razonar entre entradas de texto y audio. En el ejemplo siguiente se muestra cómo puede enviar contexto de audio a modelos de finalizaciones de chat que también admiten audio.
En el ejemplo siguiente se envía contenido de audio codificado en los datos base64 del historial de chat.
{
"model": "Phi-4-multimodal-instruct",
"messages": [
{
"role": "system",
"content": "You are an AI assistant for translating and transcribing audio clips."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please translate this audio snippet to spanish."
},
{
"type": "input_audio",
"input_audio": {
"data": "0xABCDFGHIJKLMNOPQRSTUVWXYZ...",
"format": "mp3"
}
}
]
}
],
}
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "Phi-4-multimodal-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hola. ¿Cómo estás?",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 77,
"completion_tokens": 7,
"total_tokens": 84
}
}
El modelo puede leer el contenido desde una ubicación de nube accesible pasando la dirección URL como entrada. Puede indicar la carga de la siguiente manera:
{
"model": "Phi-4-multimodal-instruct",
"messages": [
{
"role": "system",
"content": "You are an AI assistant for translating and transcribing audio clips."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Please translate this audio snippet to spanish."
},
{
"type": "audio_url",
"audio_url": {
"url": "https://.../hello_how_are_you.mp3",
}
}
]
}
],
}
La respuesta es la siguiente, donde se pueden ver las estadísticas de uso del modelo:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "Phi-4-multimodal-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hola. ¿Cómo estás?",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 77,
"completion_tokens": 7,
"total_tokens": 84
}
}
El audio se divide en tokens y se envía al modelo para su procesamiento. Algunos modelos pueden funcionar directamente sobre tokens de audio, mientras que otros pueden usar módulos internos para realizar conversión de voz en texto, lo que da lugar a diferentes estrategias para calcular tokens. Lea la tarjeta de modelo para obtener más información sobre cómo funciona cada modelo.