Entrenamiento de un modelo de detección de anomalías de multivariante
Importante
A partir del 20 de septiembre de 2023, no podrá crear nuevos recursos de Anomaly Detector. El servicio Anomaly Detector se va a retirar el 1 de octubre de 2026.
Para probar la detección de anomalías multivariante rápidamente, pruebe el código de ejemplo. Para obtener más instrucciones sobre cómo ejecutar una instancia de Jupyter Notebook, consulte Instalación y ejecución de Jupyter Notebook.
Información general acerca de la API
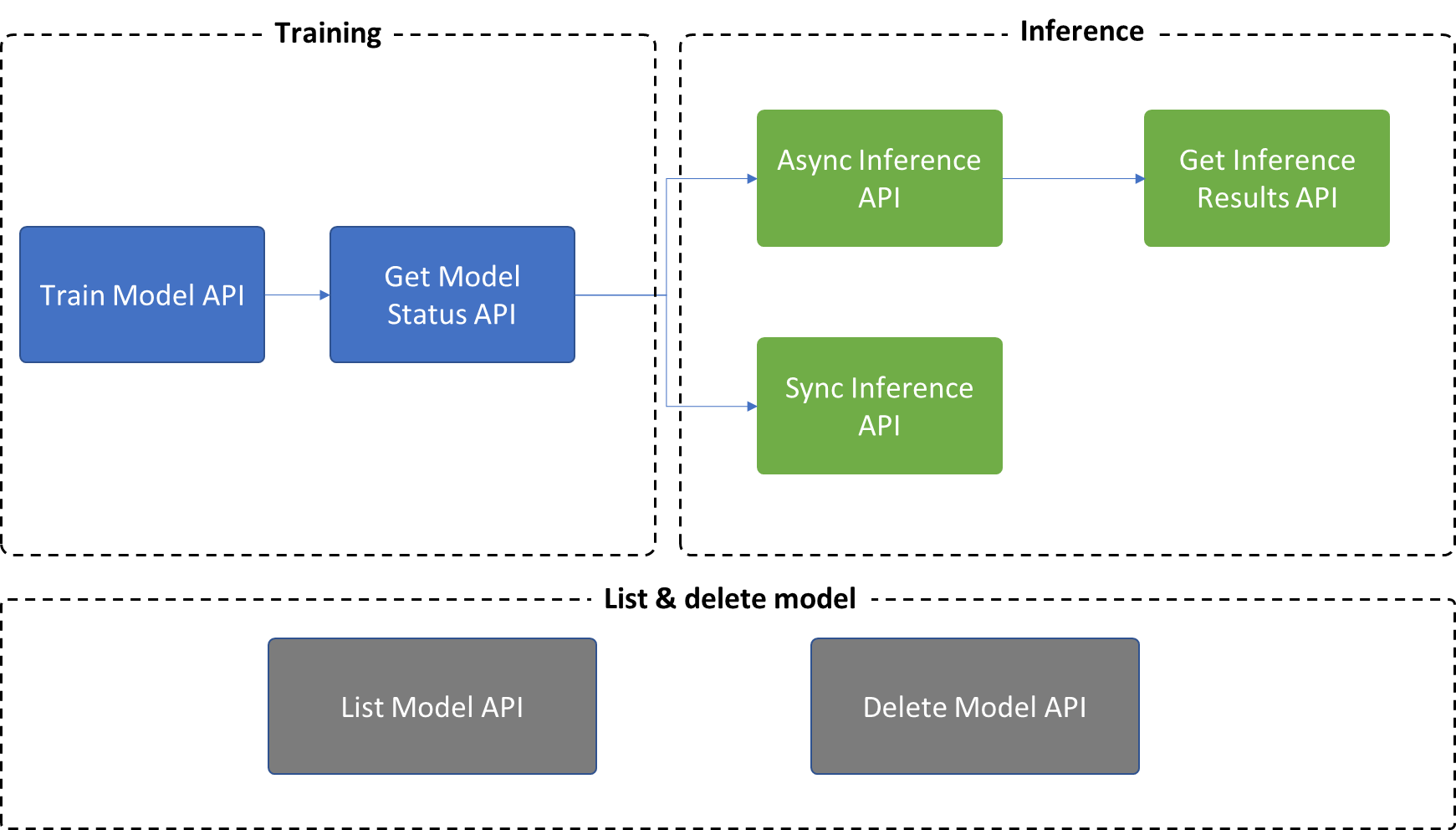
La detección de anomalías multivariante ofrece siete API:
- Training: use
Train Model APIpara crear y entrenar un modelo y, a continuación, useGet Model Status APIpara obtener los metadatos de estado y modelo. - Inference:
- use
Async Inference APIpara desencadenar un proceso de inferencia asincrónica y useGet Inference results APIpara obtener los resultados de la detección de un lote de datos. - También puede usar
Sync Inference APIpara desencadenar una detección en una marca de tiempo cada vez.
- use
- Otras operaciones:
List Model APIyDelete Model APIse admiten en el modelo de detección de anomalías multivariante para la administración de modelos.
| Nombre de la API | Método | Ruta de acceso | Descripción |
|---|---|---|---|
| Train Model (entrenar modelo) | POST | {endpoint}/anomalydetector/v1.1/multivariate/models |
Crear y entrenar un modelo |
| Obtener estado del modelo | GET | {endpoint}anomalydetector/v1.1/multivariate/models/{modelId} |
Obtener metadatos y estado del modelo con modelId |
| Inferencia por lotes | POST | {endpoint}/anomalydetector/v1.1/multivariate/models/{modelId}: detect-batch |
Desencadenar una inferencia asincrónica con modelId, que funciona en un escenario por lotes |
| Obtener resultados de la inferencia por lotes | GET | {endpoint}/anomalydetector/v1.1/multivariate/detect-batch/{resultId} |
Obtener resultados de la inferencia por lotes con resultId |
| Inferencia de streaming | POST | {endpoint}/anomalydetector/v1.1/multivariate/models/{modelId}: detect-last |
Desencadenar una inferencia sincrónica con modelId, que funciona en un escenario de streaming |
| Enumerar modelos | GET | {endpoint}/anomalydetector/v1.1/multivariate/models |
Enumerar todos los modelos |
| Eliminar modelo | DELET | {endpoint}/anomalydetector/v1.1/multivariate/models/{modelId} |
Eliminar modelo con modelId |
Entrenamiento de un modelo
En este proceso, usará la siguiente información que creó anteriormente:
- Clave del recurso de Anomaly Detector
- Punto de conexión del recurso de Anomaly Detector
- Dirección URL del blob de los datos de la cuenta de almacenamiento
Para el tamaño de los datos de entrenamiento, el número máximo de marcas de tiempo es 1 000 000 y el número mínimo recomendado es 5000 marcas de tiempo.
Solicitud
Este es el cuerpo de una solicitud de ejemplo para entrenar un modelo de detección de anomalías multivariante.
{
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0
},
"dataSource": "{{dataSource}}", //Example: https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest"
}
Parámetros obligatorios
Estos tres parámetros son necesarios en las solicitudes de API de entrenamiento e inferencia:
- dataSource: se trata de la dirección URL del blob vinculada a la carpeta o al archivo CSV que se encuentra en Azure Blob Storage.
- dataSchema: indica el esquema que está usando:
OneTableoMultiTable. - startTime: hora de inicio de los datos usados para el entrenamiento o la inferencia. Si es anterior a la marca de tiempo más temprana real de los datos, se usará la marca de tiempo más temprana real como punto de partida.
- endTime: hora final de los datos usados para el entrenamiento o la inferencia, que debe ser posterior o igual a
startTime. SiendTimees posterior a la marca de tiempo más reciente real de los datos, se usará la marca de tiempo más reciente real como punto final. SiendTimees igual astartTime, indica la inferencia de un único punto de datos, que se suele usar en escenarios de streaming.
Parámetros opcionales
Otros parámetros de la API de entrenamiento son opcionales:
slidingWindow: cuántos puntos de datos se usan para determinar las anomalías. Número entero entre 28 y 2880. El valor predeterminado es 300. Si
slidingWindoweskpara el entrenamiento del modelo, deben ser accesibles al menoskpuntos desde el archivo de origen durante la inferencia para obtener resultados válidos.La detección de anomalías multivariante toma un segmento de puntos de datos para decidir si el punto de datos siguiente es una anomalía. La longitud del segmento es
slidingWindow. Tenga en cuenta dos cosas al elegir el valor deslidingWindow:- Las propiedades de los datos: si son periódicos y la frecuencia de muestreo. Cuando los datos son periódicos, puede establecer una longitud de 1 a 3 ciclos como valor de
slidingWindow. Cuando los datos tienen una frecuencia alta (granularidad pequeña), como en el nivel de minutos o segundos, podría establecer un valor relativamente superior paraslidingWindow. - El equilibrio entre el tiempo de entrenamiento o inferencia y el posible impacto en el rendimiento. Un valor mayor de
slidingWindowpuede provocar un tiempo de entrenamiento o inferencia más largo. No hay ninguna garantía de que valores mayores queslidingWindowvayan a provocar mejoras de precisión. Un valor pequeño deslidingWindowpuede dificultar que el modelo converja en una solución óptima. Por ejemplo, es difícil detectar anomalías cuandoslidingWindowsolo tiene dos puntos.
- Las propiedades de los datos: si son periódicos y la frecuencia de muestreo. Cuando los datos son periódicos, puede establecer una longitud de 1 a 3 ciclos como valor de
alignMode: cómo alinear varias variables (series temporales) en las marcas de tiempo. Hay dos opciones para este parámetro,
InneryOuter, y el valor predeterminado esOuter.Este parámetro es fundamental cuando hay una incoherencia entre las secuencias de marcas de tiempo de las variables. El modelo debe alinear las variables en la misma secuencia de marcas de tiempo antes de continuar el procesamiento.
Innersignifica que el modelo solo mostrará los resultados de la detección en las marcas de tiempo en las que todas las variables tienen un valor, por ejemplo, la intersección de todas las variables.Outersignifica que el modelo solo mostrará los resultados de la detección en las marcas de tiempo en las que alguna variable tiene un valor, por ejemplo, la unión de todas las variables.Este es un ejemplo para explicar los distintos valores de
alignModel.Variable-1
timestamp value 2020-11-01 1 2020-11-02 2 2020-11-04 4 05-11-2020 5 Variable-2
timestamp value 2020-11-01 1 2020-11-02 2 2020-11-03 3 2020-11-04 4 Combinación
Innerde dos variablestimestamp Variable-1 Variable-2 2020-11-01 1 1 2020-11-02 2 2 2020-11-04 4 4 Combinación
Outerde dos variablestimestamp Variable-1 Variable-2 2020-11-01 1 1 2020-11-02 2 2 2020-11-03 nan3 2020-11-04 4 4 05-11-2020 5 nanfillNAMethod: cómo rellenar
nanen la tabla combinada. Es posible que falten valores en la tabla combinada y se deben controlar adecuadamente. Proporcionamos varios métodos para rellenarlos. Las opciones sonLinear,Previous,Subsequent,ZeroyFixed, y el valor predeterminado esLinear.Opción Método LinearRellenar los valores nanpor interpolación linealPreviousPropagar el último valor válido para rellenar los espacios. Ejemplo: [1, 2, nan, 3, nan, 4]->[1, 2, 2, 3, 3, 4]SubsequentUsar el siguiente valor válido para rellenar los espacios. Ejemplo: [1, 2, nan, 3, nan, 4]->[1, 2, 3, 3, 4, 4]ZeroRellenar los valores nancon 0.FixedRellenar los valores nancon un valor válido especificado que se debe proporcionar enpaddingValue.paddingValue: el valor de relleno se usa para rellenar los valores
nancuandofillNAMethodesFixedy se debe proporcionar en ese caso. En otros casos, es opcional.displayName: parámetro opcional que se usa para identificar los modelos. Por ejemplo, puede usarlo para marcar parámetros, orígenes de datos y cualquier otro metadato sobre el modelo y sus datos de entrada. El valor predeterminado es una cadena vacía.
Response
Dentro de la respuesta, lo más importante es modelId, que usará para desencadenar Get Model Status API.
Ejemplo de respuesta:
{
"modelId": "09c01f3e-5558-11ed-bd35-36f8cdfb3365",
"createdTime": "2022-11-01T00:00:00Z",
"lastUpdatedTime": "2022-11-01T00:00:00Z",
"modelInfo": {
"dataSource": "https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv",
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest",
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0.0
},
"status": "CREATED",
"errors": [],
"diagnosticsInfo": {
"modelState": {
"epochIds": [],
"trainLosses": [],
"validationLosses": [],
"latenciesInSeconds": []
},
"variableStates": []
}
}
}
Obtención del estado del modelo
Puede usar la API anterior para desencadenar un entrenamiento y usar Get model status API para saber si el modelo está entrenado correctamente o no.
Solicitud
No hay contenido en el cuerpo de la solicitud; lo único que se requiere es colocar modelId en la ruta de acceso de la API, que tendrá un formato: {{endpoint}}anomalydetector/v1.1/multivariate/models/{{modelId}}
Response
- status:
statusen el cuerpo de la respuesta indica el estado del modelo con esta categoría: CREATED, RUNNING, READY, FAILED. - trainLosses y validationLosses: estos son dos conceptos de aprendizaje automático que indican el rendimiento del modelo. Si los números están disminuyendo y terminan en un número relativamente pequeño, como 0,2 o 0,3, significa que el rendimiento del modelo es bueno en cierta medida. Sin embargo, el rendimiento del modelo todavía debe validarse a través de la inferencia y la comparación con las etiquetas, si las hay.
- epochIds: indica cuántas épocas se ha entrenado el modelo en un total de 100 épocas. Por ejemplo, si el modelo sigue en estado de entrenamiento,
epochIdpodría ser[10, 20, 30, 40, 50], lo que significa que ha completado su 50 ª época de entrenamiento y, por consiguiente, está completado a la mitad. - latenciesInSeconds: contiene el costo de tiempo de cada época y se registra cada 10 épocas. En este ejemplo, la 10 ª época tarda aproximadamente 0,34 segundos. Esto sería útil para calcular el tiempo de finalización del entrenamiento.
- variableStates: resume información sobre cada variable. Es una lista clasificada por
filledNARatioen orden descendente. Indica cuántos puntos de datos se usan para cada variable yfilledNARatioindica cuántos puntos faltan. Normalmente es necesario reducirfilledNARatiotanto como sea posible. Si faltan demasiados puntos de datos, se degradará la precisión del modelo. - errors: los errores durante el procesamiento de datos se incluirán en el campo
errors.
Ejemplo de respuesta:
{
"modelId": "09c01f3e-5558-11ed-bd35-36f8cdfb3365",
"createdTime": "2022-11-01T00:00:12Z",
"lastUpdatedTime": "2022-11-01T00:00:12Z",
"modelInfo": {
"dataSource": "https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv",
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest",
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0.0
},
"status": "READY",
"errors": [],
"diagnosticsInfo": {
"modelState": {
"epochIds": [
10,
20,
30,
40,
50,
60,
70,
80,
90,
100
],
"trainLosses": [
0.30325182933699,
0.24335388161919333,
0.22876543213020673,
0.2439815090461211,
0.22489577260884372,
0.22305156764659015,
0.22466289590705524,
0.22133831883018668,
0.2214335961775346,
0.22268397090109912
],
"validationLosses": [
0.29047123109451445,
0.263965221366497,
0.2510373182971068,
0.27116744686858824,
0.2518718700216274,
0.24802495975687047,
0.24790137705176768,
0.24640804830223623,
0.2463938973166726,
0.24831805566344597
],
"latenciesInSeconds": [
2.1662967205047607,
2.0658926963806152,
2.112030029296875,
2.130472183227539,
2.183091640472412,
2.1442034244537354,
2.117824077606201,
2.1345198154449463,
2.0993552207946777,
2.1198465824127197
]
},
"variableStates": [
{
"variable": "series_0",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_1",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_2",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_3",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_4",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
}
]
}
}
}
Enumeración de modelos
Puede consultar esta página para obtener información sobre la dirección URL de solicitud y los encabezados de solicitud. Tenga en cuenta que solo se devuelven 10 modelos ordenados por tiempo de actualización, pero puede visitar otros modelos estableciendo los parámetros $skip y $top en la dirección URL de la solicitud. Por ejemplo, si la dirección URL de la solicitud es https://{endpoint}/anomalydetector/v1.1/multivariate/models?$skip=10&$top=20, omitiremos los últimos 10 modelos y devolveremos los 20 modelos siguientes.
Una respuesta de ejemplo es:
{
"models": [
{
"modelId": "09c01f3e-5558-11ed-bd35-36f8cdfb3365",
"createdTime": "2022-10-26T18:00:12Z",
"lastUpdatedTime": "2022-10-26T18:03:53Z",
"modelInfo": {
"dataSource": "https://mvaddataset.blob.core.windows.net/sample-onetable/sample_data_5_3000.csv",
"dataSchema": "OneTable",
"startTime": "2021-01-01T00:00:00Z",
"endTime": "2021-01-02T09:19:00Z",
"displayName": "SampleRequest",
"slidingWindow": 200,
"alignPolicy": {
"alignMode": "Outer",
"fillNAMethod": "Linear",
"paddingValue": 0.0
},
"status": "READY",
"errors": [],
"diagnosticsInfo": {
"modelState": {
"epochIds": [
10,
20,
30,
40,
50,
60,
70,
80,
90,
100
],
"trainLosses": [
0.30325182933699,
0.24335388161919333,
0.22876543213020673,
0.2439815090461211,
0.22489577260884372,
0.22305156764659015,
0.22466289590705524,
0.22133831883018668,
0.2214335961775346,
0.22268397090109912
],
"validationLosses": [
0.29047123109451445,
0.263965221366497,
0.2510373182971068,
0.27116744686858824,
0.2518718700216274,
0.24802495975687047,
0.24790137705176768,
0.24640804830223623,
0.2463938973166726,
0.24831805566344597
],
"latenciesInSeconds": [
2.1662967205047607,
2.0658926963806152,
2.112030029296875,
2.130472183227539,
2.183091640472412,
2.1442034244537354,
2.117824077606201,
2.1345198154449463,
2.0993552207946777,
2.1198465824127197
]
},
"variableStates": [
{
"variable": "series_0",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_1",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_2",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_3",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
},
{
"variable": "series_4",
"filledNARatio": 0.0004999999999999449,
"effectiveCount": 1999,
"firstTimestamp": "2021-01-01T00:01:00Z",
"lastTimestamp": "2021-01-02T09:19:00Z"
}
]
}
}
}
],
"currentCount": 42,
"maxCount": 1000,
"nextLink": ""
}
La respuesta contiene cuatro campos: models, currentCount, maxCount y nextLink.
- models: contiene la hora de creación, la hora de la última actualización, el identificador del modelo, el nombre para mostrar, los recuentos de variables y el estado de cada modelo.
- currentCount: contiene el número de modelos multivariante entrenados en el recurso de Anomaly Detector.
- maxCount: el número máximo de modelos admitidos por el recurso de Anomaly Detector, que se diferenciará por el plan de tarifa que elija.
- nextLink: podría usarse para capturar más modelos, ya que el número máximo de modelos que se mostrarán en esta respuesta de API es 10.