Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El proceso de etiquetado es una parte importante de la preparación del conjunto de datos. Dado que este proceso requiere mucho tiempo y esfuerzo, puede usar la característica de etiquetado automático para etiquetar automáticamente los documentos con las clases en las que desea clasificarlos. Actualmente puede iniciar trabajos de etiquetado automático basados en un modelo mediante modelos GPT en los que puede desencadenar inmediatamente un trabajo de etiquetado automático sin ningún entrenamiento previo del modelo. Esta característica puede ahorrarle el tiempo y el esfuerzo, ya que no tiene que etiquetar manualmente los documentos.
Requisitos previos
Para poder usar la etiqueta automática con GPT, necesita:
- Un proyecto creado correctamente con una cuenta de Azure Blob Storage configurada.
- Datos del texto que se ha cargado en la cuenta de almacenamiento.
- Nombres de clase que son significativos. Los modelos GPT etiquetan documentos basados en los nombres de las clases que ha proporcionado.
- No se requieren datos etiquetados.
- Un recurso y una implementación de Azure OpenAI.
Desencadenamiento de un trabajo de etiquetado automático
Al desencadenar un trabajo de etiquetado automático con GPT, se le cobrará al recurso de Azure OpenAI según el consumo. Se le cobrará una estimación del número de tokens de cada documento que se va a etiquetar automáticamente. Consulte la página de precios de Azure OpenAI para obtener un desglose detallado de los precios por token de diferentes modelos.
En el panel izquierdo, seleccione Etiquetado de datos.
Seleccione el botón Etiqueta automática en el panel Actividad situado a la derecha de la página.
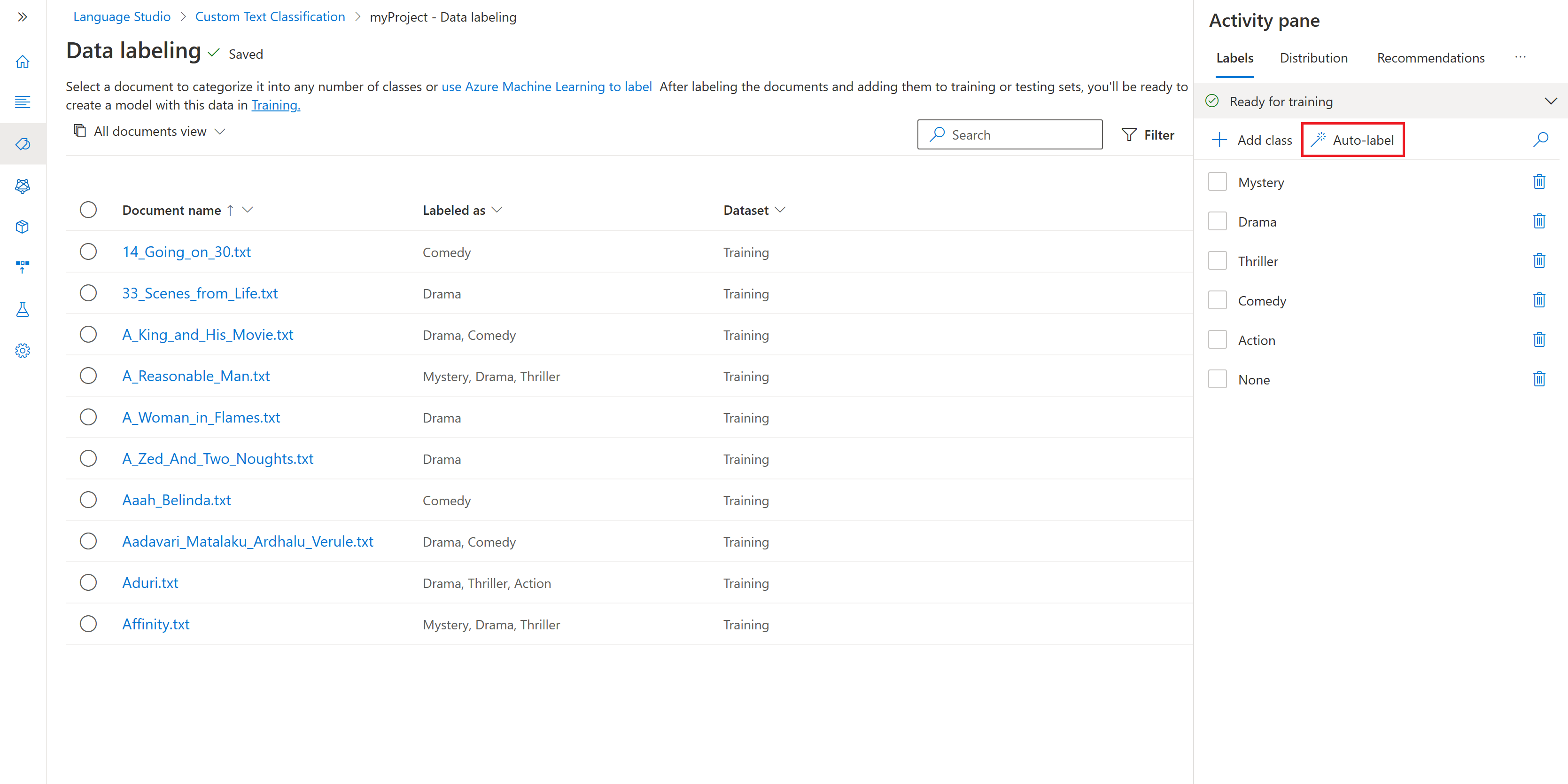
Elija Autoetiquetar con GPT y seleccione Siguiente.
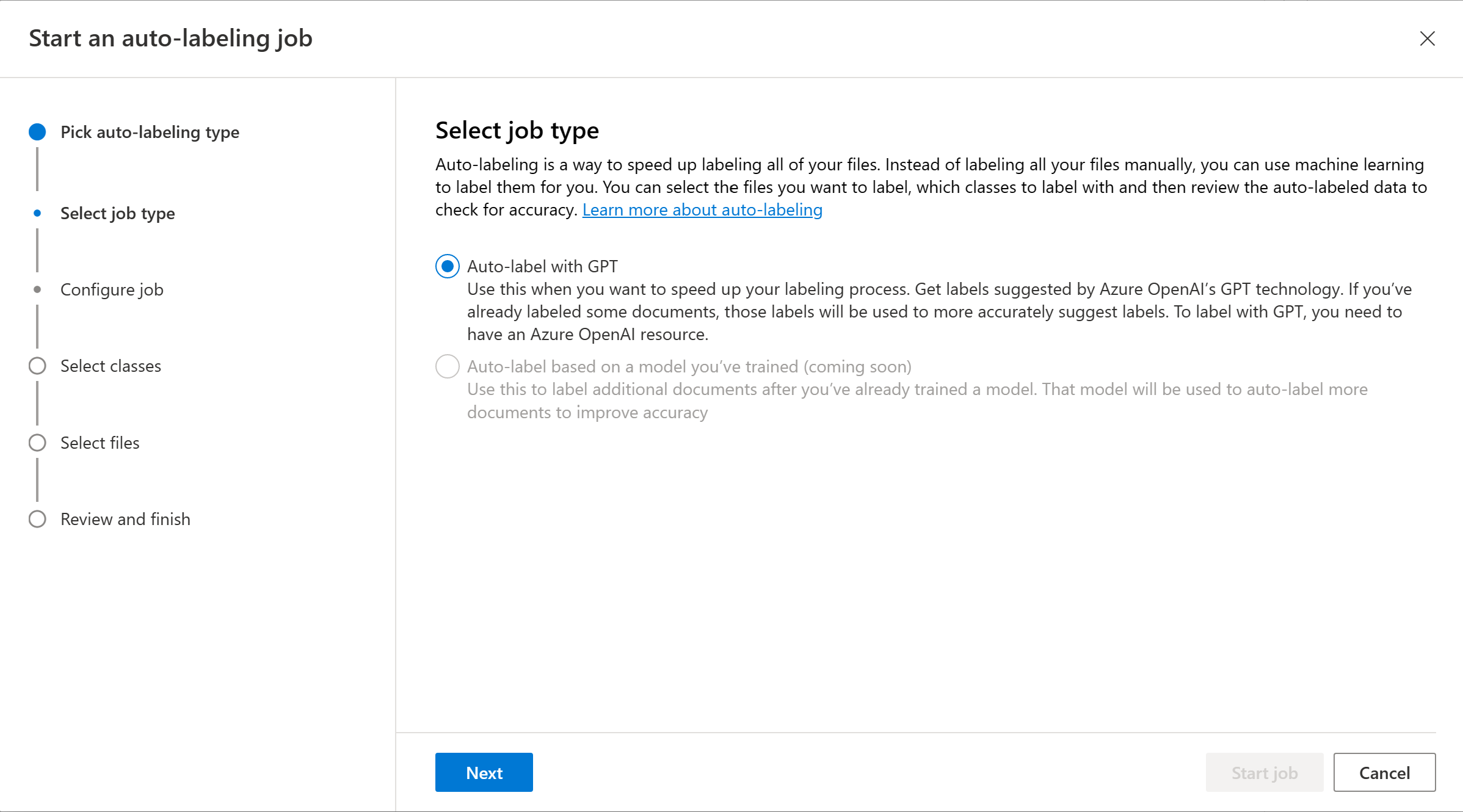
Elija el recurso y la implementación de Azure OpenAI. Debe crear un recurso de Azure OpenAI e implementar un modelo para continuar.
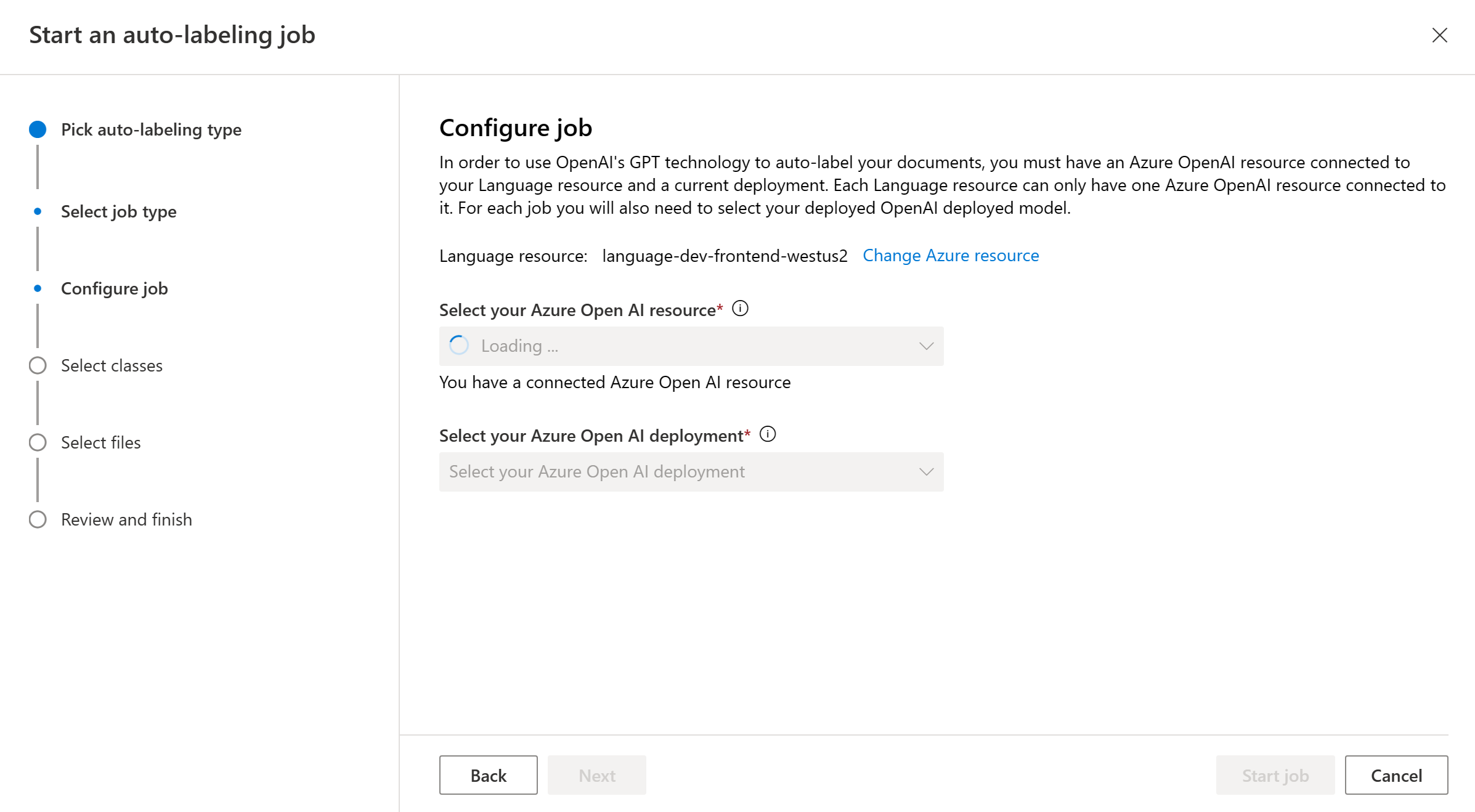
Seleccione las clases que desea incluir en el trabajo de etiquetado automático. De forma predeterminada, se seleccionan todas las clases. Se recomienda asignar nombres descriptivos a las clases e incluir ejemplos para cada una de ellas a fin de lograr un etiquetado de buena calidad con GPT.
Elija los documentos que quiera etiquetar automáticamente. Se recomienda elegir los documentos sin etiquetar del filtro.
Nota
- Si un documento se etiquetó automáticamente, pero el usuario ya había definido esta etiqueta, solo se utilizará la etiqueta que definió el usuario.
- Para ver los documentos, haga clic en el nombre de un documento.
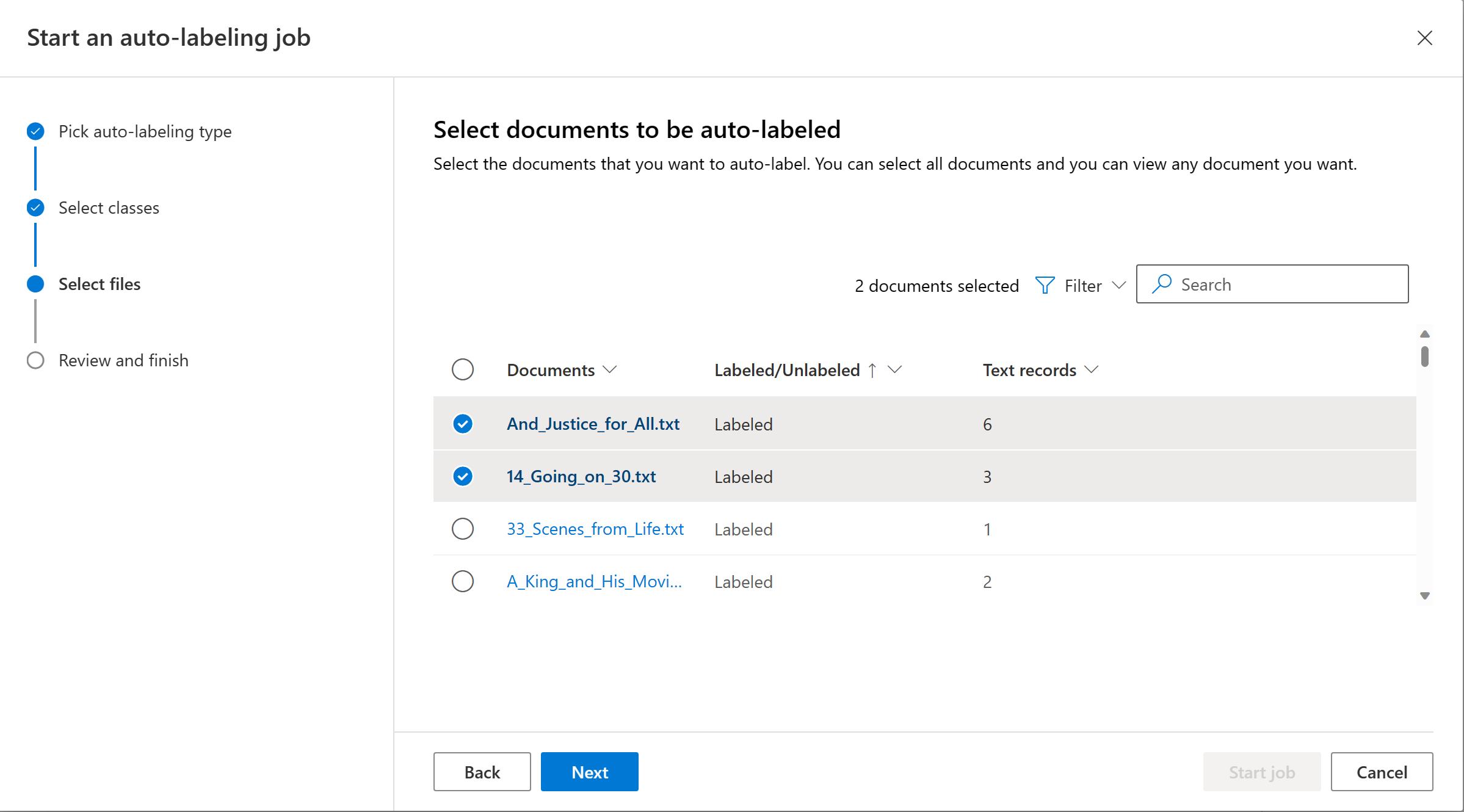
Seleccione Iniciar trabajo para desencadenar el trabajo de etiquetado automático. Debe dirigirse a la página de etiquetado automático que muestra los trabajos de etiquetado automático iniciados. Los trabajos de etiquetado automático pueden tardar unos segundos o unos minutos, en función del número de documentos que incluya.
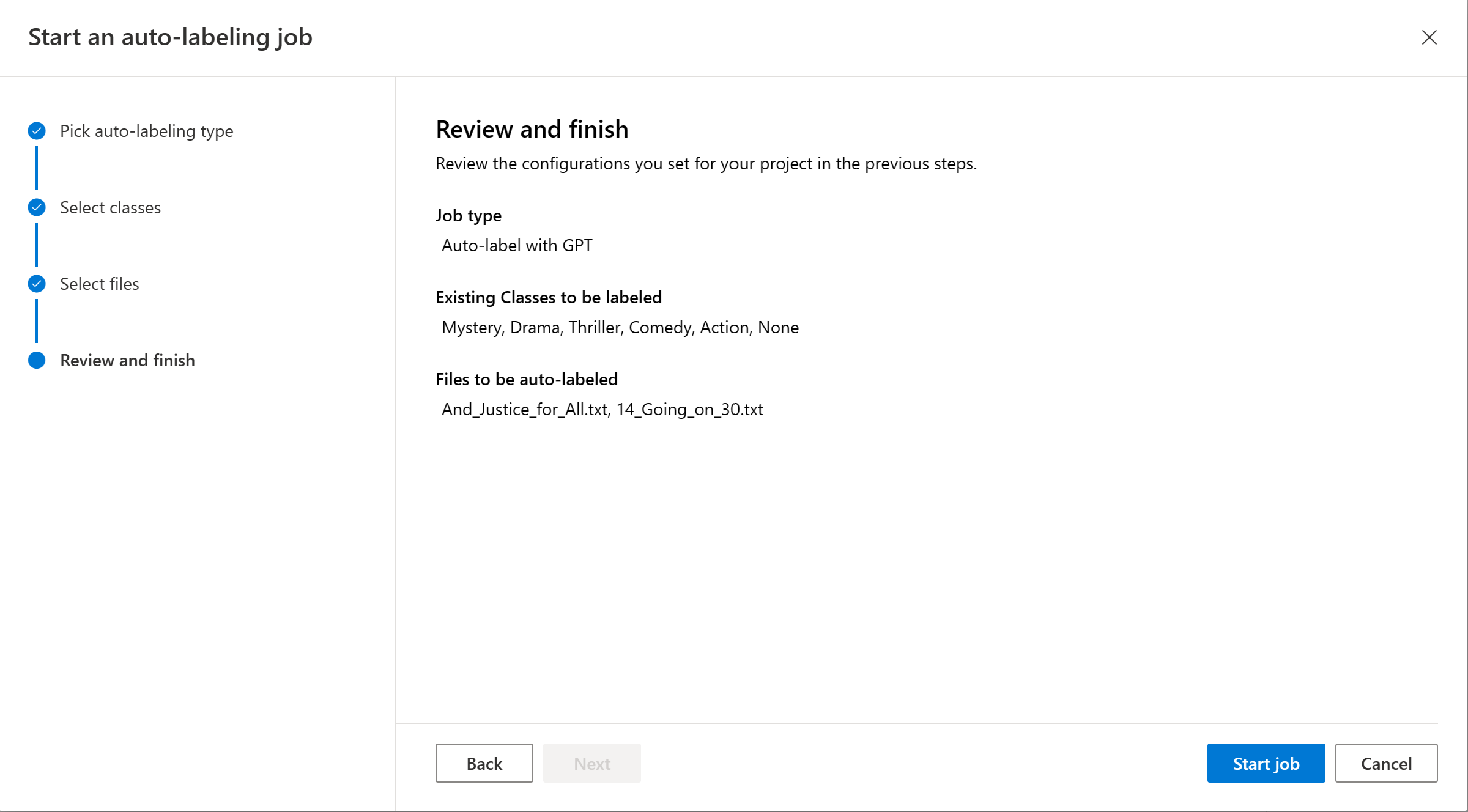






Revisión de los documentos etiquetados automáticamente
Una vez completado el trabajo de etiquetado automático, puede ver los documentos de salida en la página Etiquetado de datos de Language Studio. Seleccione Revisar documentos con etiquetas automáticas para ver los documentos con el filtro Etiquetado automático aplicado.

Los documentos que se han clasificado automáticamente han sugerido etiquetas en el panel de actividad resaltado en púrpura. Cada etiqueta sugerida tiene dos selectores (una marca de verificación y un icono de cancelación) que permiten aceptar o rechazar la etiqueta automática.
Una vez aceptada una etiqueta, el color púrpura cambia al azul predeterminado y la etiqueta se incluye en cualquier entrenamiento de modelo adicional,convirtiéndose en una etiqueta definida por el usuario.
Después de aceptar o rechazar las etiquetas de los documentos etiquetados automáticamente, seleccione Guardar etiquetas para aplicar los cambios.
Nota
- Se recomienda validar automáticamente los documentos etiquetados antes de aceptarlos.
- Todas las etiquetas que no se aceptaron se eliminan al entrenar el modelo.

Pasos siguientes
- Obtenga más información sobre el etiquetado de sus datos.