Conceptos básicos
¿Cuándo quedará en desuso Metrics Advisor?
A partir del 20 de septiembre de 2023, no podrá crear nuevos recursos de Metrics Advisor. El servicio Metrics Advisor se va a retirar el 1 de octubre de 2026.
¿Qué son los datos de serie temporal multidimensional?
Consulte la definición de métrica multidimensional en el glosario.
¿Cuántos datos se necesitan para que Metrics Advisor inicie la detección de anomalías?
Como mínimo, un punto de datos puede desencadenar la detección de anomalías. Sin embargo, esto no aporta la mejor precisión. Durante la creación de la fuente de distribución de datos, el servicio asumirá una ventana de puntos de datos anteriores utilizando el valor especificado como regla de "espacio de relleno".
Se recomienda tener algunos datos antes de la marca de tiempo en la que desea realizar la detección. Según la granularidad de los datos, la cantidad de datos recomendada varía como se indica a continuación.
| Granularidad | Importe de datos recomendado para la detección |
|---|---|
| Menos de 5 minutos | 4 días de datos |
| 5 minutos a 1 día | 28 días de datos |
| Más de 1 día, hasta 31 días | 4 años de datos |
| Superior a 31 días | 48 años de datos |
¿Qué datos procesa Metrics Advisor y cómo se conservan los datos?
- Metrics Advisor procesa datos de series temporal que se recopilan del origen de datos de un cliente, los datos históricos se usan para la selección del modelo y determinan el límite de datos esperado.
- Los datos de las series temporales del cliente y los resultados de la inferencia se almacenarán en el servicio. Metrics Advisor no almacena ni procesa los datos del cliente fuera de la región donde el cliente implementa la instancia de servicio.
¿Por qué Metrics Advisor no detecta las anomalías de los datos históricos?
Metrics Advisor está diseñado para detectar datos de streaming en vivo. Existe una limitación de la duración máxima de los datos históricos que el servicio analizará y en la que ejecutará la detección de anomalías. Esto significa que solo los puntos de datos después de una marca de tiempo más temprana determinada tendrán resultados de detección de anomalías. La marca de tiempo más temprana depende de la granularidad de los datos.
En función de la granularidad de los datos, las duraciones de los datos históricos que tendrán resultados de detección de anomalías son las siguientes.
| Granularidad | Duración máxima de los datos históricos para la detección de anomalías |
|---|---|
| Menos de 5 minutos | Tiempo de incorporación: 13 horas |
| De 5 minutos a menos de 1 hora | Tiempo de incorporación: 4 días |
| De 1 hora a menos de 1 día | Tiempo de incorporación: 14 días |
| 1 día | Tiempo de incorporación: 28 días |
| Mayor de 1 día, menos de 31 días | Tiempo de incorporación: 2 años |
| Superior a 31 días | Tiempo de incorporación: 24 años |
¿Cuáles son la retención de datos y las limitaciones de Metrics Advisor?
- Retención de datos. Metrics Advisor mantendrá como máximo 10 000 intervalos de tiempo ¿qué es un intervalo? contando hacia delante desde la marca de tiempo actual, con independencia de que haya datos disponibles o no. Se eliminarán los datos fuera del intervalo. Asignación de retención de datos para el recuento de días para una granularidad de métricas diferente.
| Grranularidad (min) | Retención (día) |
|---|---|
| 1 | 6,94 |
| 5 | 34,72 |
| 15 | 104,1 |
| 60(=hourly) | 416,67 |
| 1440(=daily) | 10000,00 |
- Limitación del número máximo de series temporales dentro de una métrica.
Pueden tener varias dimensiones dentro de una métrica y cada dimensión puede tener varios valores. La combinación de dimensiones máxima para una métrica no debe superar los 100 000.
- Los administradores de recursos y propietarios de fuentes de distribución de datos de Metrics Advisor recibirán una notificación cuando se alcance la limitación del 80 % en la página de detalles de la fuente de distribución de datos.
- Si la métrica ha superado la limitación, la fuente de distribución de datos se pausará y esperará a que los clientes realicen acciones de seguimiento. Se recomienda dividir la fuente de distribución de datos en varias fuentes de distribución de datos mediante el filtrado.
- Limitación de los puntos de datos máximos almacenados en una instancia de Metrics Advisor
Metrics Advisor cuenta el total de puntos de datos de todas las fuentes de distribución de datos que se incorporaron a la instancia a partir de la primera fecha de ingesta. El número máximo de puntos de datos que se almacenarán en una instancia de Metrics Advisor es de 2 mil millones.
- Los administradores de recursos y todos los usuarios de Metrics Advisor recibirán una notificación cuando se alcance la limitación del 80 % en la página de la lista de fuente de distribución de datos y a través de la página de fuente de distribución de datos nueva.
- Si el total de puntos de datos ha superado la limitación, todas las fuentes de distribución de datos se pausarán y también se bloqueará la incorporación de nuevas fuentes. Se recomienda eliminar las fuentes de distribución de datos no utilizadas o crear un nuevo recurso de Metrics Advisor dentro de la suscripción.
¿Por qué no puedo iniciar sesión en Metrics Advisor? El mensaje de error indica que el recurso se retira por inactividad transcurridos 90 días
Hay dos casos en los que se retira un recurso:
- Se crea un recurso de Metrics Advisor, pero no se ha incorporado ninguna fuente de distribución de datos en un período de 90 días. El recurso se retirará transcurridos 90 días debido a la inactividad.
- Si se han creado una o varias fuentes de distribución de datos, pero no se ingieren datos nuevos en Metrics Advisor, el servicio entrará en modo inactivo sin que se procesen datos. El sistema seguirá intentando obtener datos periódicamente del origen según la granularidad de las métricas. Sin embargo, si sigue sin tener datos disponibles o ninguna serie temporal única que se procese durante un período de 90 días consecutivos, se retirará el recurso. Todos los datos históricos asociados al recurso se perderán cuando se retire.
Se recomienda crear un nuevo recurso y eliminar el anterior si desea reiniciar el uso.
¿Cómo detecto picos y caídas como anomalías?
Si tiene umbrales estrictos predefinidos, puede establecer de forma manual el "umbral estricto" en las configuraciones de detección de anomalías. Si no hay umbrales, puede usar la "detección inteligente", que se basa en IA. Consulte la optimización de la configuración de detección para obtener detalles.
¿Cómo detecto el incumplimiento con patrones normales (estacionales) como anomalías?
La "detección inteligente" es capaz de aprender el patrón de los datos, incluidos los patrones estacionales. Después, detecta los puntos de datos que no se ajustan a los patrones regulares como anomalías. Consulte la optimización de la configuración de detección para obtener detalles.
¿Admite Metrics Advisor orígenes de datos que están detrás de una red virtual?
No, Metrics Advisor no admite actualmente orígenes de datos que estén detrás de una red virtual.
¿Cómo detecto líneas planas como anomalías?
Si los datos suelen ser bastante inestables y fluctúan mucho, y desea recibir una alerta cuando pasen a ser demasiado estables o incluso se conviertan en una línea plana, el "umbral de cambio" puede configurarse para detectar dichos puntos de datos cuando el cambio sea demasiado pequeño. Consulte las configuraciones de detección de anomalías para obtener detalles.
¿Cómo se efectúa la configuración de correo electrónico y se habilitan las alertas por correo electrónico?
Un usuario con privilegios de administrador de la suscripción o de administrador del grupo de recursos debe ir al recurso de Metrics Advisor que creó en Azure Portal y seleccionar la pestaña Control de acceso (IAM) .
Seleccione Agregar asignación de roles.
Elija un rol de administrador de Cognitive Services Metrics Advisor y seleccione su cuenta como en la imagen siguiente.
Seleccione el botón Guardar y se le agregará como administrador del recurso de Metrics Advisor. Todas las acciones anteriores las debe realizar el administrador de la suscripción o el administrador del grupo de recursos.
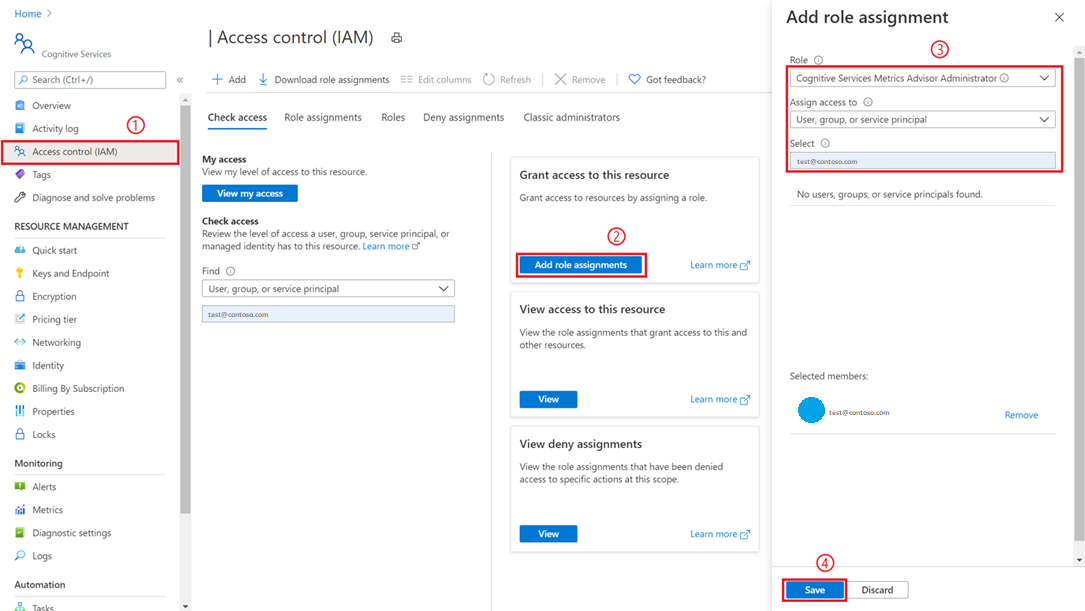
Los permisos pueden tardar hasta un minuto en propagarse. A continuación, seleccione el área de trabajo de Metrics Advisor y seleccione la opción Configuración de correo electrónico en el panel izquierdo. Rellene los elementos necesarios, en particular la información relacionada con SMTP.
Seleccione Guardar y, después, habrá completado la configuración de correo electrónico. Puede crear nuevos enlaces y suscribirse a anomalías de métricas para alertas casi en tiempo real.

Conceptos avanzados
¿Cómo crea Metric Advisor un árbol de diagnóstico para métricas multidimensionales?
Una métrica se puede dividir en varias series temporales mediante dimensiones. Por ejemplo, la métrica Response latency se supervisa en todos los servicios que posee el equipo. La categoría Service se podría usar como dimensión para enriquecer la métrica, por lo que se obtiene Response latency dividido por Service1, Service2, y así sucesivamente. Cada servicio se puede implementar en distintas máquinas de varios centros de datos, por lo que la métrica se podría dividir aún más por Machine y Data center.
| Servicio | Centro de datos | Máquina |
|---|---|---|
| S1 | DC1 | M1 |
| S1 | DC1 | M2 |
| S1 | DC2 | M3 |
| S1 | DC2 | M4 |
| S2 | DC1 | M1 |
| S2 | DC1 | M2 |
| S2 | DC2 | M5 |
| S2 | DC2 | M6 |
| ... |
A partir del valor total de Response latency, se puede explorar en profundidad la métrica por Service, Data center y Machine. Sin embargo, puede que para los propietarios de servicios tenga más sentido usar la ruta Service ->Data center ->Machine, o para los ingenieros de infraestructura la ruta Data Center ->Machine ->Service. Todo depende de los requisitos empresariales individuales de los usuarios.
En Metrics Advisor, los usuarios pueden especificar cualquier ruta que quieran explorar en profundidad o consolidar de un nodo de la topología jerárquica. Más concretamente, la topología jerárquica es un grafo acíclico dirigido en lugar de una estructura de árbol. Hay una topología jerárquica completa que consta de todas las combinaciones posibles de dimensiones, como esta:

En teoría, si la dimensión Service tiene Ls valores distintos, la dimensión Data center tiene Ldc valores distintos y la dimensión Machine tiene Lm valores distintos, podría haber entonces combinaciones de las dimensiones (Ls + 1) * (Ldc + 1) * (Lm + 1) en la topología jerárquica.
Sin embargo, normalmente no todas las combinaciones de dimensiones son válidas, lo que puede reducir de forma considerable la complejidad. Actualmente, si los usuarios agregan la métrica por su cuenta, no se limita el número de dimensiones. Si necesita usar la funcionalidad de consolidación que ofrece Metrics Advisor, el número de dimensiones no debería ser superior a 6. Sin embargo, se limita el número de series temporales expandidas por las dimensiones de una métrica a menos de 10 000.
La herramienta de árbol de diagnóstico de la página de diagnósticos solo muestra los nodos en los que se ha detectado una anomalía, no toda la topología. De esta manera, puede centrarse en el problema actual. También puede que no se muestren todas las anomalías dentro de la métrica, sino aquellas más importantes en función de la contribución. Así, se puede averiguar rápidamente el efecto, el ámbito y la ruta de propagación de los datos anómalos. Esto reduce de forma considerable el número de anomalías en las que debemos centrarnos y ayuda a los usuarios a comprender y localizar sus problemas principales.
Por ejemplo, cuando se produce una anomalía en Service = S2 | Data Center = DC2 | Machine = M5, la desviación de esta afecta al nodo primario Service= S2, que también la ha detectado, pero no afecta a todo el centro de datos en DC2 ni a todos los servicios de M5. El árbol de incidentes se crearía como en la siguiente captura de pantalla: la anomalía principal se captura en Service = S2 y la causa principal podría analizarse en dos rutas que conducen a Service = S2 | Data Center = DC2 | Machine = M5.
