¿Qué es la voz personal (versión preliminar) para el texto a voz?
Nota:
La voz personal para texto a voz se encuentra actualmente en versión preliminar pública. Esta versión preliminar se ofrece sin contrato de nivel de servicio y no es aconsejable usarla para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan sus funcionalidades limitadas. Para más información, consulte Términos de uso complementarios de las Versiones Preliminares de Microsoft Azure.
Con la voz personal, puede obtener la replicación generada por IA de la voz (o los usuarios de la aplicación) en unos segundos. Proporcione un ejemplo de voz de un minuto como símbolo del sistema de audio y después úselo para generar voz en cualquiera de los más de 90 idiomas admitidos en más de 100 configuraciones regionales.
Nota:
La voz personal está disponible en estas regiones: Oeste de Europa, Este de EE. UU. y Sudeste de Asia. Para conocer las configuraciones regionales admitidas, consulte Compatibilidad con idiomas de voz personales.
En la tabla siguiente se resume la diferencia entre la voz personal y la voz neuronal personalizada profesional.
| De comparación | Voz personal (versión preliminar) | Voz profesional |
|---|---|---|
| Escenarios de destino | Los clientes empresariales crean una aplicación para permitir a sus usuarios crear y usar su propia voz personal en la aplicación. | Escenarios profesionales como voces de marca y caracteres para bots de chat o lectura de contenido de audio. |
| Casos de uso | Restringido a casos de uso limitados. Vea la nota de transparencia . Los clientes aprobados deben tener un plan para admitir más de 1000 voces personales. | Restringido a casos de uso limitados. Vea la nota de transparencia. |
| Datos de aprendizaje. | Asegúrese de seguir el código de conducta. | Traiga sus propios datos. Se recomienda grabar en un estudio profesional. |
| Tamaño de datos requerido | Un minuto de discurso humano. | 300-2000 expresiones (aproximadamente de 30 minutos a 3 horas de voz humana). |
| Tiempo de entrenamiento | Menos de 5 segundos | Aproximadamente 20-40 horas de proceso. |
| Calidad de voz | Natural | Altamente natural |
| Compatibilidad con varios idiomas | Sí. La voz puede hablar unos 100 idiomas, con la detección automática de idioma habilitada. | Sí. Debe seleccionar la característica "Neuronal – entre idiomas" para entrenar un modelo que habla un idioma diferente de los datos de entrenamiento. |
| Disponibilidad | La demostración de Speech Studio está disponible al registrarse. El acceso a la API está restringido a los clientes aptos y a los casos de uso aprobados. Solicitar acceso a través del formulario de admisión. | Puede entrenar e implementar un modelo de CNV Pro después de que se apruebe el acceso. El acceso CNV Pro está limitado en función de los criterios de idoneidad y uso. Solicitar acceso a través del formulario de admisión. |
| Precios | “Los precios oficiales de la versión preliminar pública para la voz personal se anunciarán en enero de 2024. Antes del anuncio adicional, el uso de voz personal se cobrará con el mismo precio que el texto neuronal predeterminado a voz. | Consulte aquí los detalles de precios. |
| Requisitos de inteligencia artificial responsable | Se requiere la declaración verbal del orador. No se permite ningún caso de uso no aprobado. | Se requiere la declaración verbal del orador. No se permite ningún caso de uso no aprobado. |
Prueba de la demostración
Si tiene un recurso S0, puede acceder a la demostración de voz personal en Speech Studio. Para usar la API de voz personal, puede solicitar acceso aquí.
Vaya a Speech Studio
Seleccione la tarjeta voz personal.
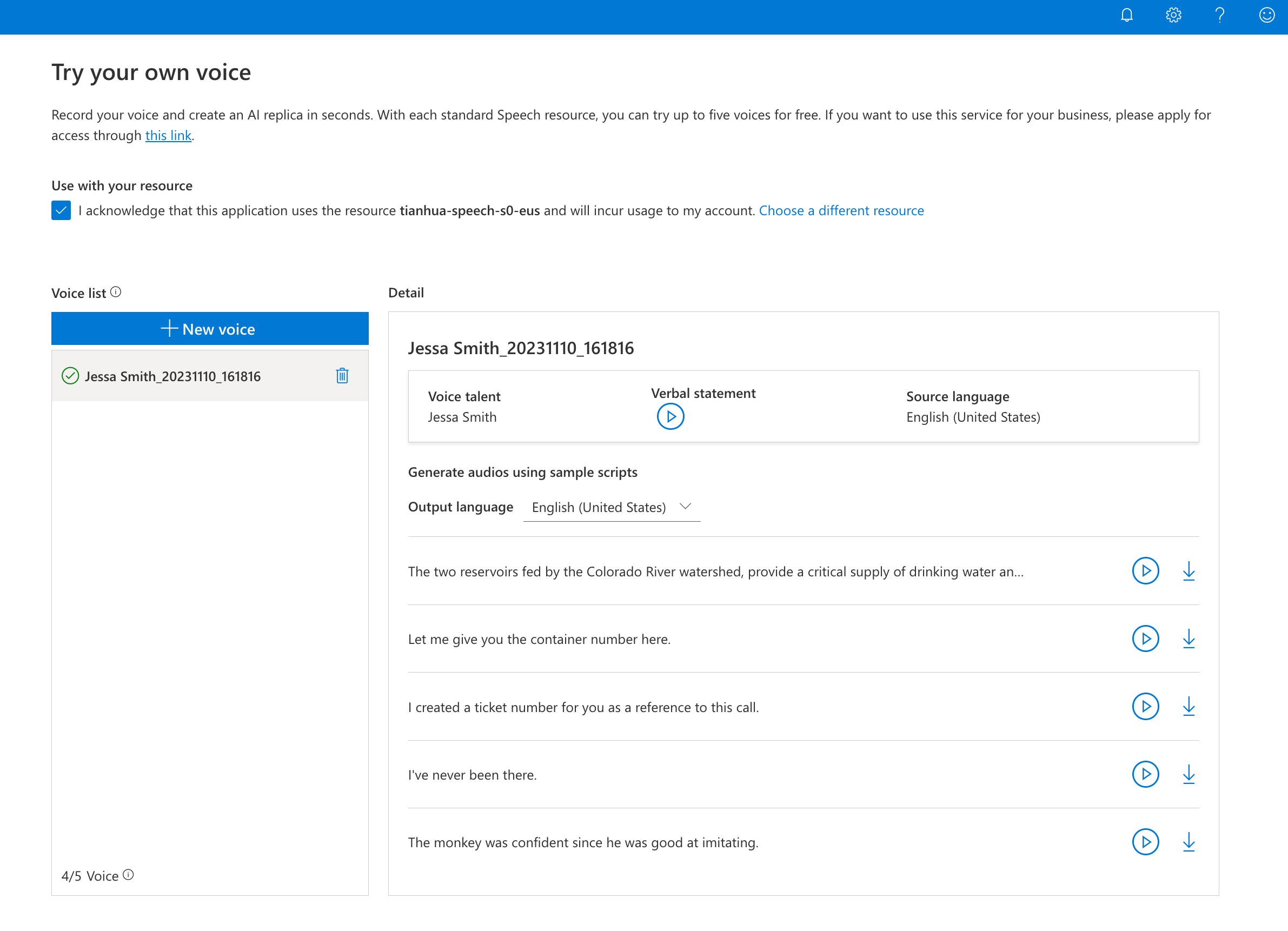
Puede grabar su propia voz y probar los ejemplos de salida de voz en diferentes idiomas. La demostración incluye un subconjunto de los idiomas admitidos por voz personal.


Cómo crear una voz personal
Para empezar, este es un resumen de los pasos para crear una voz personal:
- Cree un proyecto.
- Cargue el archivo de consentimiento. Con la característica de voz personal, es necesario que cada voz se cree con consentimiento explícito del usuario. Se requiere una instrucción grabada del usuario que reconozca que el cliente (propietario del recurso de Voz de Azure AI) creará y usará su voz.
- Obtener un identificador de perfil de hablante para la voz personal. Obtiene un identificador de perfil de hablante en función de la declaración de consentimiento verbal del hablante y un aviso de audio. Las características de voz del usuario se codifican en la propiedad
speakerProfileIdque se usa para el texto a voz.
Una vez que tenga una voz personal, puede usarla para sintetizar la voz en cualquiera de los 91 idiomas admitidos en más de 100 configuraciones regionales. No se requiere una etiqueta de configuración regional. La voz personal usa la detección automática de idioma en el nivel de oración. Para obtener más información, vea usar voz personal en la aplicación.
Sugerencia
Modifique los ejemplos de código del repositorio del SDK de Voz en GitHub para ver cómo usar la voz personal en la aplicación.
Documentación de referencia
IA responsable
Nos preocupamos por las personas que usan inteligencia artificial y las personas que se verán afectadas por ella tanto como nos preocupamos por la tecnología. Para más información, consulte las notas sobre transparencia de la IA responsable.
Pasos siguientes
- Cree un proyecto.
- Obtenga más información acerca de la voz neuronal personalizada en la información general.
- Obtenga más información sobre Speech Studio en la información general .