Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
LangChain es un ecosistema de desarrollo que permite a los desarrolladores compilar de forma sencilla aplicaciones con capacidad de razonamiento. El ecosistema se compone de varios elementos. La mayoría de ellos se pueden usar por sí solos, lo que le permite elegir el que más le guste.
Los modelos implementados en Azure AI Foundry se pueden usar con LangChain de dos maneras:
Usar la API de inferencia de modelos de Azure AI: todos los modelos implementados en Azure AI Foundry de la API de inferencia del modelo de Azure AI, que ofrece un conjunto común de funcionalidades que se pueden usar para la mayoría de los modelos del catálogo. La ventaja de esta API es que, puesto que es la misma para todos los modelos, cambiar de uno a otro es tan sencillo como cambiar la implementación de modelo que se está usando. No se requieren más cambios en el código. Al trabajar con LangChain, instale las extensiones
langchain-azure-ai.Usar la API específica del proveedor del modelo: algunos modelos, como OpenAI, Cohere o Mistral, ofrecen su propio conjunto de API y extensiones para LlamaIndex. Estas extensiones pueden incluir funcionalidades específicas que admiten el modelo y, por tanto, son adecuadas si desea aprovecharlas. Al trabajar con LangChain, instale la extensión específica para el modelo que quiere usar, como
langchain-openaiolangchain-cohere.
En este tutorial, aprenderá a usar los paquetes langchain-azure-ai para compilar aplicaciones con LangChain.
Requisitos previos
Para ejecutar este tutorial, necesitará:
Una suscripción de Azure.
Una implementación de modelo que admite la API de inferencia del modelo de Azure AI implementada. En este ejemplo, se usa una implementación de
Mistral-Large-2407en la Inferencia del modelo de Azure AI.Python 3.9 o una versión posterior instalada, incluido pip.
Tener instalado LangChain. Puede hacerlo con:
pip install langchain-coreEn este ejemplo, estamos trabajando con la API de inferencia del modelo de Azure AI, por lo que se instalan los siguientes paquetes:
pip install -U langchain-azure-ai
Configuración del entorno
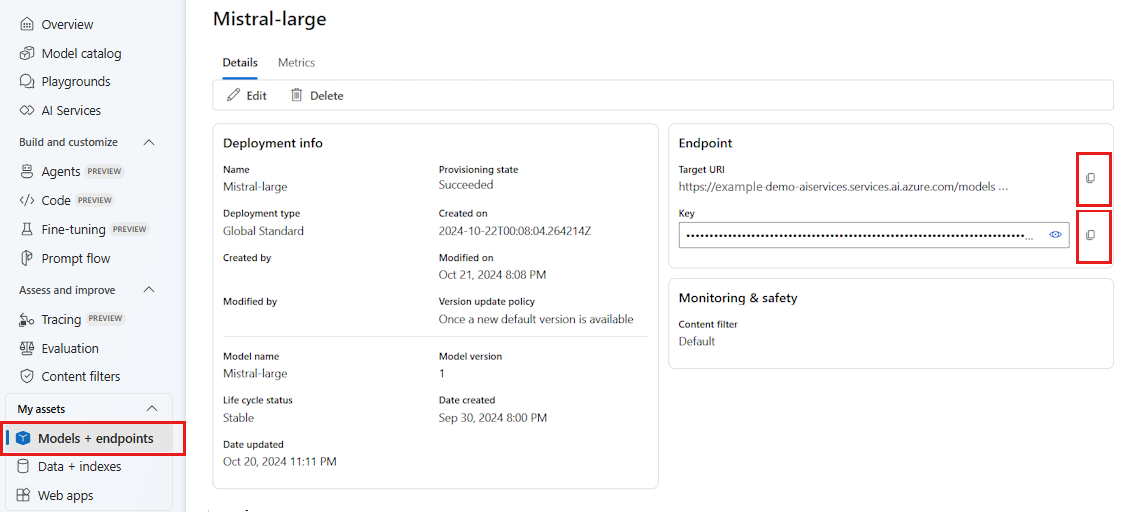
Para usar las VM implementadas en el portal de Azure AI Foundry, necesita el punto de conexión y las credenciales para conectarse a él. Siga estos pasos para obtener la información que necesita del modelo que desea usar:
Vaya al Azure AI Foundry.
Abra el proyecto donde está implementado el modelo, si aún no está abierto.
Vaya a Modelos y puntos de conexión y seleccione el modelo implementado como se indica en los requisitos previos.
Copie la dirección URL del punto de conexión y la clave.
Sugerencia
Si el modelo se implementó con compatibilidad con Microsoft Entra ID, no necesita una clave.

En este escenario, colocamos la dirección URL del punto de conexión y la clave en las siguientes variables de entorno:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
Una vez configurado, cree un cliente para conectarse al punto de conexión. En este caso, estamos trabajando con un modelo de finalizaciones de chat, por lo que importamos la clase AzureAIChatCompletionsModel.
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model="mistral-large-2407",
)
Sugerencia
Para los modelos de Azure OpenAI, configure el cliente como se indica en Uso de modelos de Azure OpenAI.
Puede usar el siguiente código para crear el cliente si el punto de conexión es compatible con Microsoft Entra ID:
import os
from azure.identity import DefaultAzureCredential
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model_name="mistral-large-2407",
)
Nota:
Al usar Microsoft Entra ID, asegúrese de que el punto de conexión se implementó con ese método de autenticación y que tiene los permisos necesarios para invocarlo.
Si planea usar llamadas asincrónicas, se recomienda usar la versión asincrónica para las credenciales:
from azure.identity.aio import (
DefaultAzureCredential as DefaultAzureCredentialAsync,
)
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredentialAsync(),
model_name="mistral-large-2407",
)
Si el punto de conexión atiende un modelo, como con los puntos de conexión de API sin servidor, no tiene que indicar el parámetro model_name:
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
)
Uso de modelos de finalizaciones de chat
Vamos a usar el modelo directamente.
ChatModels son instancias de LangChain Runnable, lo que significa que exponen una interfaz estándar para interactuar con ellas. Para llamar simplemente al modelo, podemos pasar una lista de mensajes al método invoke.
from langchain_core.messages import HumanMessage, SystemMessage
messages = [
SystemMessage(content="Translate the following from English into Italian"),
HumanMessage(content="hi!"),
]
model.invoke(messages)
También puede crear operaciones según sea necesario en lo que se denomina cadenas. Ahora vamos a usar una plantilla de indicación para traducir oraciones:
from langchain_core.output_parsers import StrOutputParser
system_template = "Translate the following into {language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
Como puede ver en la plantilla de indicación, esta cadena tiene una entrada language y text. Ahora, vamos a crear un analizador de salida:
from langchain_core.prompts import ChatPromptTemplate
parser = StrOutputParser()
Ahora podemos combinar la plantilla, el modelo y el analizador de salida anteriores mediante el operador de barra vertical (|):
chain = prompt_template | model | parser
Para invocar la cadena, identifique las entradas necesarias y proporcione valores mediante el método invoke:
chain.invoke({"language": "italian", "text": "hi"})
'ciao'
Encadenamiento de varios modelos LLM juntos
Los modelos implementados en Azure AI Foundry admiten la API de inferencia de modelos de Azure AI, que es estándar en todos los modelos. Encadene varias operaciones de LLM según las funcionalidades de cada modelo para que pueda optimizar el modelo adecuado de acuerdo con dichas funcionalidades.
En el ejemplo siguiente, creamos dos clientes de modelo, uno es un productor y otro es un comprobador. Para aclarar la distinción, estamos usando un punto de conexión de múltiples modelos, como el servicio Azure AI Model Inference, de ahí que pasemos el parámetro model_name para usar un modelo Mistral-Large y Mistral-Small, citando el hecho de que producir contenido es más complejo que comprobarlo.
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
producer = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
)
verifier = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-small",
)
Sugerencia
Explore la tarjeta de modelo de cada uno de los modelos para comprender los mejores casos de uso de cada uno.
En el ejemplo siguiente se genera un poema escrito por un poeta urbano:
from langchain_core.prompts import PromptTemplate
producer_template = PromptTemplate(
template="You are an urban poet, your job is to come up \
verses based on a given topic.\n\
Here is the topic you have been asked to generate a verse on:\n\
{topic}",
input_variables=["topic"],
)
verifier_template = PromptTemplate(
template="You are a verifier of poems, you are tasked\
to inspect the verses of poem. If they consist of violence and abusive language\
report it. Your response should be only one word either True or False.\n \
Here is the lyrics submitted to you:\n\
{input}",
input_variables=["input"],
)
Ahora encadenemos las partes:
chain = producer_template | producer | parser | verifier_template | verifier | parser
La cadena anterior devuelve la salida del paso verifier solo. Dado que queremos tener acceso al resultado intermedio generado por el producer, en LangChain debe usar un objeto RunnablePassthrough para generar también ese paso intermedio. El código siguiente muestra cómo hacerlo:
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
generate_poem = producer_template | producer | parser
verify_poem = verifier_template | verifier | parser
chain = generate_poem | RunnableParallel(poem=RunnablePassthrough(), verification=RunnablePassthrough() | verify_poem)
Para invocar la cadena, identifique las entradas necesarias y proporcione valores mediante el método invoke:
chain.invoke({"topic": "living in a foreign country"})
{
"peom": "...",
"verification: "false"
}
Uso de modelos de inserción
De la misma manera que crea un cliente LLM, puede conectarse a un modelo de inserciones. En el siguiente ejemplo, vamos a establecer la variable de entorno para que apunte ahora a un modelo de inserciones:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
A continuación, cree el cliente:
from langchain_azure_ai.embeddings import AzureAIEmbeddingsModel
embed_model = AzureAIEmbeddingsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ['AZURE_INFERENCE_CREDENTIAL'],
model_name="text-embedding-3-large",
)
En el ejemplo siguiente se muestra un ejemplo sencillo mediante un almacén de vectores en memoria:
from langchain_core.vectorstores import InMemoryVectorStore
vector_store = InMemoryVectorStore(embed_model)
Vamos a agregar algunos documentos:
from langchain_core.documents import Document
document_1 = Document(id="1", page_content="foo", metadata={"baz": "bar"})
document_2 = Document(id="2", page_content="thud", metadata={"bar": "baz"})
documents = [document_1, document_2]
vector_store.add_documents(documents=documents)
Vamos a buscar por similitud:
results = vector_store.similarity_search(query="thud",k=1)
for doc in results:
print(f"* {doc.page_content} [{doc.metadata}]")
Uso de modelos de Azure OpenAI
Si usa Azure OpenAI Service o el servicio Azure AI Model Inference con modelos de OpenAI con el paquete langchain-azure-ai, es posible que tenga que usar el parámetro api_version para seleccionar una versión de API específica. En el ejemplo siguiente se muestra cómo conectarse a una implementación de modelo de Azure OpenAI en Azure OpenAI Service:
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
llm = AzureAIChatCompletionsModel(
endpoint="https://<resource>.openai.azure.com/openai/deployments/<deployment-name>",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
api_version="2024-05-01-preview",
)
Importante
Compruebe cuál es la versión de la API que usa la implementación. Si se utiliza un api_version incorrecto o no compatible con el modelo, se produce una excepción ResourceNotFound.
Si la implementación se hospeda en Servicios de Azure AI, puede usar el servicio Azure AI Model Inference:
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
llm = AzureAIChatCompletionsModel(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="<model-name>",
api_version="2024-05-01-preview",
)
Depuración y solución de problemas
Si necesita depurar la aplicación y comprender las solicitudes enviadas a los modelos de Azure AI Foundry, puede usar las funcionalidades de depuración de la integración de la siguiente manera:
En primer lugar, configure el registro en el nivel que le interese:
import sys
import logging
# Acquire the logger for this client library. Use 'azure' to affect both
# 'azure.core` and `azure.ai.inference' libraries.
logger = logging.getLogger("azure")
# Set the desired logging level. logging.INFO or logging.DEBUG are good options.
logger.setLevel(logging.DEBUG)
# Direct logging output to stdout:
handler = logging.StreamHandler(stream=sys.stdout)
# Or direct logging output to a file:
# handler = logging.FileHandler(filename="sample.log")
logger.addHandler(handler)
# Optional: change the default logging format. Here we add a timestamp.
formatter = logging.Formatter("%(asctime)s:%(levelname)s:%(name)s:%(message)s")
handler.setFormatter(formatter)
Para ver las cargas de las solicitudes, al instalar el cliente, pase el argumento logging_enable=True al client_kwargs:
import os
from langchain_azure_ai.chat_models import AzureAIChatCompletionsModel
model = AzureAIChatCompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2407",
client_kwargs={"logging_enable": True},
)
Use el cliente como de costumbre en el código.
Seguimiento
Puede usar las funcionalidades de seguimiento en Azure AI Foundry mediante la creación de un seguimiento. Los registros se almacenan en Azure Application Insights y se pueden consultar en cualquier momento mediante el portal de Azure Monitor o Azure AI Foundry. Cada Centro de IA tiene una instancia de Azure Application Insights asociada.
Obtener la cadena de conexión de instrumentación
Puede configurar la aplicación para enviar telemetría a Azure Application Insights mediante:
Uso de la cadena de conexión para Azure Application Insights directamente:
Vaya al portal de Azure AI Foundry y seleccione Seguimiento.
Seleccione Administrar origen de datos. En esta pantalla puede ver la instancia asociada al proyecto.
Copie el valor en cadena de conexión y establézcalo en la variable siguiente:
import os application_insights_connection_string = "instrumentation...."
Uso del SDK de Azure AI Foundry y la cadena de conexión del proyecto.
Asegúrese de tener instalado el paquete
azure-ai-projectsen el entorno.Visite el portal de Azure AI Foundry.
Copie la cadena de conexión del proyecto y establézcala en el código siguiente:
from azure.ai.projects import AIProjectClient from azure.identity import DefaultAzureCredential project_client = AIProjectClient.from_connection_string( credential=DefaultAzureCredential(), conn_str="<your-project-connection-string>", ) application_insights_connection_string = project_client.telemetry.get_connection_string()
Configuración del seguimiento para Azure AI Foundry
El código siguiente crea un seguimiento conectado a Azure Application Insights detrás de un proyecto en Azure AI Foundry. Observe que el parámetro enable_content_recording está establecido en True. Esto permite capturar las entradas y salidas de toda la aplicación, así como los pasos intermedios. Esto resulta útil al depurar y compilar aplicaciones, pero es posible que desee deshabilitarlo en entornos de producción. El valor predeterminado es la variable de entorno AZURE_TRACING_GEN_AI_CONTENT_RECORDING_ENABLED:
from langchain_azure_ai.callbacks.tracers import AzureAIInferenceTracer
tracer = AzureAIInferenceTracer(
connection_string=application_insights_connection_string,
enable_content_recording=True,
)
Para configurar el seguimiento con la cadena, indique la configuración de valor en la operación de invoke como devolución de llamada:
chain.invoke({"topic": "living in a foreign country"}, config={"callbacks": [tracer]})
Para configurar la propia cadena para el seguimiento, use el método .with_config():
chain = chain.with_config({"callbacks": [tracer]})
A continuación, use el método invoke() como de costumbre:
chain.invoke({"topic": "living in a foreign country"})
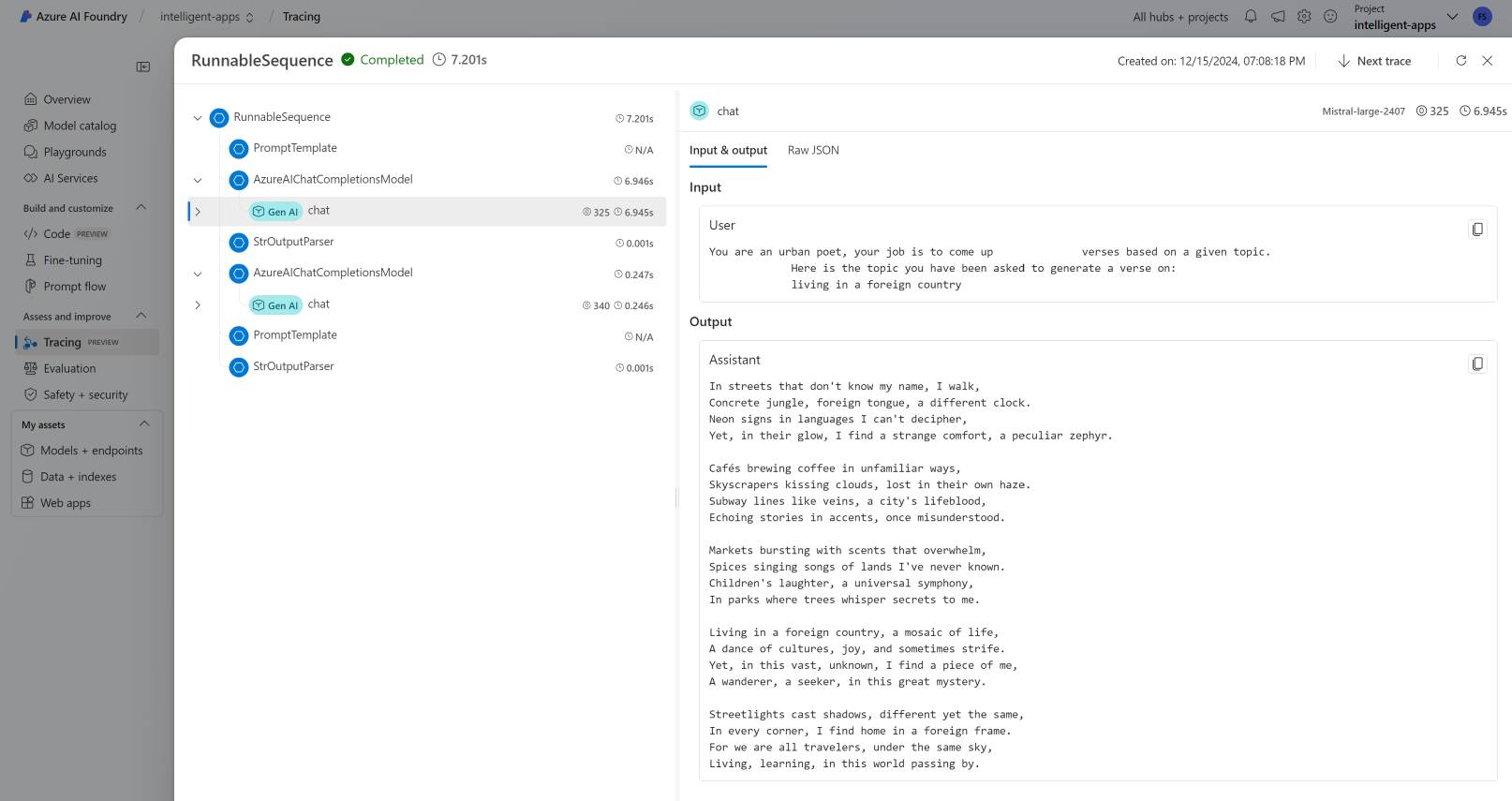
Visualización de seguimientos
Para ver los seguimientos:
Visite el portal de Azure AI Foundry.
Vaya a la sección Seguimiento.
Identifique el seguimiento que ha creado. El seguimiento puede tardar un par de segundos en mostrarse.

Obtenga más información sobre cómo visualizar y administrar seguimientos.