Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo, obtendrá información sobre cómo usar LlamaIndex con modelos implementados desde el catálogo de modelos de Azure AI en el portal de la Fundición de IA de Azure.
Los modelos implementados en Azure AI Foundry se pueden usar con LlamaIndex de dos maneras:
Uso de la API de inferencia de modelos de Azure AI: Todos los modelos implementados en Azure AI Foundry admiten la API de Inferencia de Modelos, que ofrece un conjunto común de funcionalidades que se pueden usar para la mayoría de los modelos del catálogo. La ventaja de esta API es que, puesto que es la misma para todos los modelos, cambiar de uno a otro es tan sencillo como cambiar la implementación de modelo que se está usando. No se requieren más cambios en el código. Al trabajar con LlamaIndex, instale las extensiones
llama-index-llms-azure-inferenceyllama-index-embeddings-azure-inference.Usar la API específica del proveedor del modelo: algunos modelos, como OpenAI, Cohere o Mistral, ofrecen su propio conjunto de API y extensiones para LlamaIndex. Estas extensiones pueden incluir funcionalidades específicas que admiten el modelo y, por tanto, son adecuadas si desea aprovecharlas. Al trabajar con
llama-index, instale la extensión específica para el modelo que quiere usar, comollama-index-llms-openaiollama-index-llms-cohere.
En este ejemplo, estamos trabajando con la API de inferencia de modelos.
Prerrequisitos
Para ejecutar este tutorial, necesitará:
Una suscripción de Azure.
Un proyecto de Azure AI como se explica en Creación de un proyecto en el portal de la Fundición de IA de Azure.
Modelo que admite la API de inferencia de modelos implementada. En este ejemplo, usamos una implementación de
Mistral-Large, pero use cualquier modelo de su preferencia. Para usar funcionalidades de inserción en LlamaIndex, necesita un modelo de inserción comocohere-embed-v3-multilingual.- Puede seguir las instrucciones de Implementación de modelos como implementaciones de API sin servidor.
Python 3.8 o posterior instalado, incluido pip.
LlamaIndex instalado. Puede hacerlo con:
pip install llama-indexEn este ejemplo, estamos trabajando con la API de inferencia de modelos, por lo que instalamos los siguientes paquetes:
pip install -U llama-index-llms-azure-inference pip install -U llama-index-embeddings-azure-inferenceImportante
El uso del servicio Foundry Models requiere una versión
0.2.4parallama-index-llms-azure-inferenceollama-index-embeddings-azure-inference.
Configuración del entorno
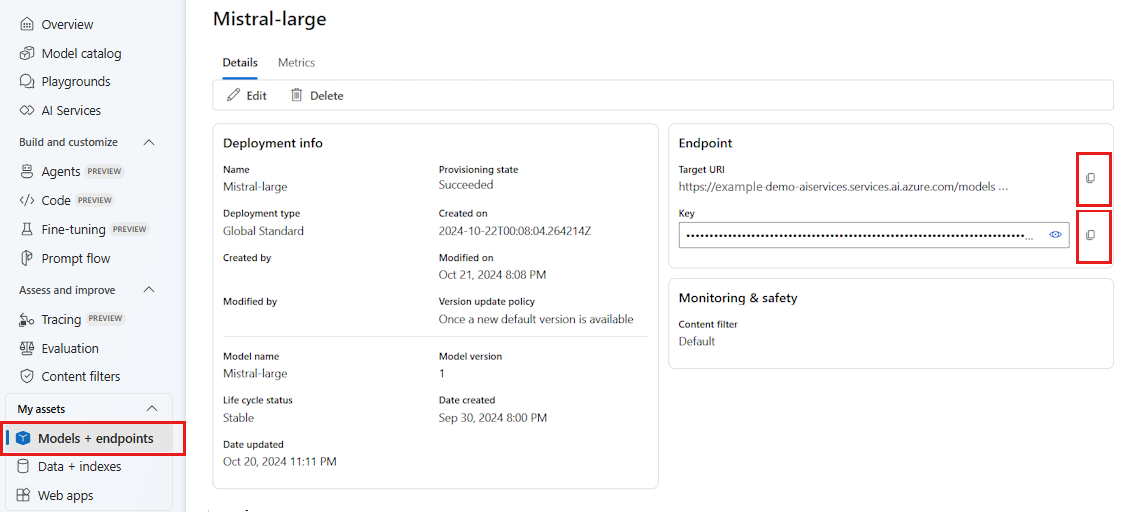
Para usar los LLM implementados en el portal de la Fundición de IA de Azure, necesita el punto de conexión y las credenciales para conectarse a él. Siga estos pasos para obtener la información que necesita del modelo que desea usar:
Sugerencia
Dado que puede personalizar el panel izquierdo en el portal de Azure AI Foundry, es posible que vea elementos diferentes de los que se muestran en estos pasos. Si no ve lo que busca, seleccione ... Más en la parte inferior del panel izquierdo.
Vaya a la Fundición de IA de Azure.
Abra el proyecto donde está implementado el modelo, si aún no está abierto.
Vaya a Modelos y puntos de conexión y seleccione el modelo implementado como se indica en los requisitos previos.
Copie la dirección URL del punto de conexión y la clave.
Sugerencia
Si el modelo se implementó con compatibilidad con Microsoft Entra ID, no necesita una clave.

En este escenario, establezca la dirección URL del punto de conexión y la clave como variables de entorno. (Si el punto de conexión que copió incluye texto adicional después de /models, quítelo para que la dirección URL finalice en /models como se muestra a continuación).
export AZURE_INFERENCE_ENDPOINT="https://<resource>.services.ai.azure.com/models"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
Una vez configurado, cree un cliente para conectarse al punto de conexión.
import os
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
)
Sugerencia
Si la implementación del modelo se hospeda en Azure OpenAI en los recursos de Foundry Models o Azure AI Services, configure el cliente como se indica en modelos de Azure OpenAI y servicio Foundry Models.
Si el punto de conexión atiende más de un modelo, como con el servicio Foundry Models o Los modelos de GitHub, debe indicar model_name el parámetro :
import os
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2411",
)
Como alternativa, si el punto de conexión es compatible con Microsoft Entra ID, puede usar el siguiente código para crear el cliente:
import os
from azure.identity import DefaultAzureCredential
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
)
Nota:
Al usar Microsoft Entra ID, asegúrese de que el punto de conexión se implementó con ese método de autenticación y que tiene los permisos necesarios para invocarlo.
Si planea usar llamadas asincrónicas, se recomienda usar la versión asincrónica para las credenciales:
from azure.identity.aio import (
DefaultAzureCredential as DefaultAzureCredentialAsync,
)
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredentialAsync(),
)
Modelos de Azure OpenAI y servicio de Modelos Foundry
Si usa el servicio Azure OpenAI o Foundry Models, asegúrese de que tiene al menos la versión 0.2.4 de la integración de LlamaIndex. Use el parámetro api_version en caso de que necesite seleccionar un elemento específico api_version.
Para el servicio Foundry Models, debe pasar el model_name parámetro:
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint="https://<resource>.services.ai.azure.com/models",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
model_name="mistral-large-2411",
)
Para los modelos de Azure OpenAI en Fundición de IA de Azure:
from llama_index.llms.azure_inference import AzureAICompletionsModel
llm = AzureAICompletionsModel(
endpoint="https://<resource>.openai.azure.com/openai/deployments/<deployment-name>",
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
api_version="2024-05-01-preview",
)
Sugerencia
Compruebe cuál es la versión de la API que usa la implementación. Si se utiliza un api_version incorrecto o no compatible con el modelo, se produce una excepción ResourceNotFound.
Parámetros de inferencia
Puede configurar cómo se realiza la inferencia para todas las operaciones que usan este cliente estableciendo parámetros adicionales. Esto ayuda a evitar indicarlos en cada llamada que realice al modelo.
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
temperature=0.0,
model_kwargs={"top_p": 1.0},
)
Parámetros que no están admitidos en la API de inferencia de modelos (referencia) pero que están disponibles en el modelo subyacente; en tal caso, se puede utilizar el argumento model_extras. En el siguiente ejemplo, se pasa el parámetro safe_prompt, solo disponible para los modelos Mistral.
llm = AzureAICompletionsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ["AZURE_INFERENCE_CREDENTIAL"],
temperature=0.0,
model_kwargs={"model_extras": {"safe_prompt": True}},
)
Uso de modelos de LLM
Puede usar el cliente directamente o Configurar los modelos usados por el código en LlamaIndex. Para usar el modelo directamente, utilice el método chat para modelos de instrucción por chat:
from llama_index.core.llms import ChatMessage
messages = [
ChatMessage(
role="system", content="You are a pirate with colorful personality."
),
ChatMessage(role="user", content="Hello"),
]
response = llm.chat(messages)
print(response)
También puede transmitir las salidas:
response = llm.stream_chat(messages)
for r in response:
print(r.delta, end="")
El método complete sigue estando disponible para el modelo de tipo chat-completions. En esos casos, el texto de entrada se convierte en un mensaje con role="user".
Uso de modelos de inserción
De la misma manera que crea un cliente LLM, puede conectarse a un modelo de inserción. En el ejemplo siguiente, vamos a establecer la variable de entorno para que apunte ahora a un modelo de inserción:
export AZURE_INFERENCE_ENDPOINT="<your-model-endpoint-goes-here>"
export AZURE_INFERENCE_CREDENTIAL="<your-key-goes-here>"
A continuación, cree el cliente:
from llama_index.embeddings.azure_inference import AzureAIEmbeddingsModel
embed_model = AzureAIEmbeddingsModel(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=os.environ['AZURE_INFERENCE_CREDENTIAL'],
)
En el ejemplo siguiente se muestra una prueba sencilla para comprobar que funciona:
from llama_index.core.schema import TextNode
nodes = [
TextNode(
text="Before college the two main things I worked on, "
"outside of school, were writing and programming."
)
]
response = embed_model(nodes=nodes)
print(response[0].embedding)
Configuración de los modelos usados por el código
Puede usar el cliente de modelo LLM o inserciones individualmente en el código que desarrolle con LlamaIndex o puede configurar toda la sesión mediante las opciones de Settings. Configurar la sesión tiene la ventaja de que todo el código usará los mismos modelos para todas las operaciones.
from llama_index.core import Settings
Settings.llm = llm
Settings.embed_model = embed_model
Sin embargo, hay escenarios en los que quiere usar un modelo general para la mayoría de las operaciones, pero uno específico para una tarea determinada. En esos casos, resulta útil establecer el modelo de inserción o LLM que se usa para cada construcción LlamaIndex. En el siguiente ejemplo, se establece un modelo específico:
from llama_index.core.evaluation import RelevancyEvaluator
relevancy_evaluator = RelevancyEvaluator(llm=llm)
En general, se usa una combinación de ambas estrategias.