Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Para satisfacer las necesidades de la aplicación en Azure Kubernetes Service (AKS), es posible que deba ajustar el número de nodos que ejecutan las cargas de trabajo. El componente de escalador automático del clúster supervisa los pods del clúster que no se pueden programar debido a restricciones de recursos. Cuando el escalador automático del clúster detecta pods no programados, escala verticalmente el número de nodos del grupo de nodos para satisfacer la demanda de la aplicación. También comprueba periódicamente los nodos que no tienen pods programados y reduce verticalmente el número de nodos según sea necesario.
Este artículo le ayuda a comprender cómo funciona el escalador automático de clústeres en AKS. También proporciona instrucciones, procedimientos recomendados y consideraciones al configurar el escalador automático del clúster para las cargas de trabajo de AKS. Si desea habilitar, deshabilitar o actualizar el escalador automático del clúster para las cargas de trabajo de AKS, consulte Uso del escalador automático de clústeres en AKS.
Acerca del escalado automático de clústeres
Para adaptarse a las cambiantes necesidades de las aplicaciones, como en las jornadas laborales y las noches o los fines de semana, los clústeres a menudo necesitan una forma de escalado automático. Los clústeres de AKS se pueden escalar de las siguientes maneras:
- El escalador automático de clústeres comprueba periódicamente los pods que no se pueden programar en los nodos debido a restricciones de recursos. Luego, el clúster aumenta automáticamente la cantidad de nodos. El escalado manual está deshabilitado cuando se usa el escalado automático de clústeres. Para obtener más información, consulte ¿Cómo funciona el escalado vertical?.
- El Horizontal Pod Autoscaler utiliza el servidor de métricas en un clúster de Kubernetes para supervisar la demanda de recursos de los pods. Si una aplicación necesita más recursos, el número de pods aumenta automáticamente para satisfacer la demanda.
- El Vertical Pod Autoscaler establece automáticamente las solicitudes de recursos y los límites de los contenedores por carga de trabajo, basándose en el uso histórico, para asegurar que los pods se programen en nodos que dispongan de los recursos necesarios de CPU y memoria.
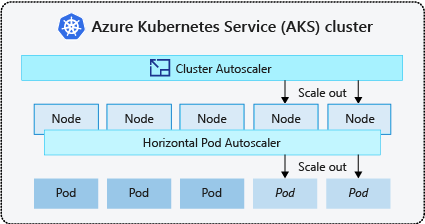
Es una práctica habitual habilitar el escalador automático de clústeres para los nodos y el escalador automático de pods verticales o horizontal para pods. Al habilitar el escalador automático del clúster, aplica las reglas de escalado especificadas cuando el tamaño del grupo de nodos es inferior al número mínimo de nodos, hasta el número máximo de nodos. A continuación, el escalador automático del clúster espera a activarse hasta que se necesita un nuevo nodo en el grupo de nodos o hasta que el nodo se puede eliminar de forma segura del grupo de nodos actual. Para obtener más información, consulte ¿Cómo funciona la reducción de escala?
Procedimientos recomendados y consideraciones
- Al implementar zonas de disponibilidad con el escalador automático del clúster, se recomienda usar un único grupo de nodos para cada zona. Puede establecer el parámetro
--balance-similar-node-groupsenTruepara mantener una distribución equilibrada de nodos entre zonas para las cargas de trabajo durante las operaciones de escalado vertical. Cuando este enfoque no se implementa, la reducción de operaciones puede interrumpir el equilibrio de nodos entre zonas. - En el caso de los clústeres con más de 400 nodos, se recomienda usar Azure CNI o la superposición de Azure CNI.
- Para ejecutar de forma eficaz las cargas de trabajo simultáneamente en grupos de nodos fijos y puntuales, considere la posibilidad de usar los ampliadores de prioridad. Este enfoque permite programar pods de acuerdo con la prioridad del grupo de nodos.
- Tenga cuidado cuando asignar solicitudes de CPU o memoria en pods. El escalador automático del clúster se escala verticalmente en función de los pods pendientes en lugar de la presión de CPU/memoria en los nodos.
- En el caso de los clústeres que hospedan simultáneamente cargas de trabajo de ejecución prolongada, como las aplicaciones web y las cargas de trabajo de corta duración o de ráfaga, se recomienda separarlas en grupos de nodos distintos con Reglas de afinidad/expanders o usar PodDisruptionBudget para ayudar a evitar las operaciones innecesarias de purga o escalado de nodos. Especificar la anotación cluster-autoscaler.kubernetes.io/safe-to-evict: "false" en la especificación pod también impedirá que los pods se expulsen. Use esta anotación con precaución, ya que puede provocar que el Cluster Autoscaler encuentre problemas al vaciar un nodo con un Pod activo que tiene esta anotación.
- En un grupo de nodos habilitado para el escalado automático, reduzca verticalmente los nodos mediante la eliminación de cargas de trabajo, en lugar de reducir manualmente el número mínimo o máximo del grupo de nodos. Esto puede ser problemático si el grupo de nodos ya está en capacidad máxima o si hay cargas de trabajo activas que se ejecutan en los nodos, lo que puede provocar un comportamiento inesperado por el escalador automático del clúster.
- Los nodos no se escalan verticalmente si los pods tienen un valor PriorityClass por debajo de -10. Priority -10 está reservado para pods de sobreaprovisionamiento. Para obtener más información, consulte Uso del escalador automático de clústeres con prioridad de pod y adelantamiento.
- No combine otros mecanismos de escalado automático de nodos, como los escaladores automáticos del conjunto de escalado de máquinas virtuales, con el escalador automático del clúster.
- Es posible que el escalador automático del clúster no pueda reducir verticalmente si los pods no se pueden mover, como en las siguientes situaciones:
- Un pod que se crea directamente y no está respaldado por un objeto controlador, como un Deployment o un ReplicaSet.
- Un presupuesto de interrupción del pod (PDB) demasiado restrictivo y que no permite que el número de pods caiga por debajo de un umbral determinado.
- Un pod usa selectores de nodo o antiafinidad que no se pueden respetar si se programan en un nodo diferente. Para obtener más información, consulte ¿Qué tipos de pods pueden impedir que el escalador automático del clúster quite un nodo?.
Importante
No realizar cambios en nodos individuales dentro de los grupos de nodos de escalado automático. Todos los nodos del mismo grupo de nodos deben tener capacidad uniforme, etiquetas, taints y pods del sistema que se ejecutan en ellos.
- El escalador automático del clúster no es responsable de aplicar un "número máximo de nodos" en un grupo de nodos de clúster independientemente de las consideraciones de programación de pods. Si algún actor que no es de escalado automático de clústeres establece el recuento del grupo de nodos en un número más allá del máximo configurado del escalador automático del clúster, el escalador automático del clúster no quita automáticamente los nodos. Los comportamientos de reducción de escala del escalador automático del clúster se limitan a quitar nodos infrautilizados. El único propósito de la configuración de recuento máximo de nodos del escalador automático del clúster es aplicar un límite superior para las operaciones de escalado vertical. No tiene ningún efecto en las consideraciones de reducción vertical.
Perfil del escalador automático de clústeres
El perfil del escalador automático del clúster es un conjunto de parámetros que controlan el comportamiento del escalador automático del clúster. Puede configurar el perfil del escalador automático del clúster al crear un clúster o actualizar un clúster existente.
Optimización del perfil del escalador automático del clúster
Debe ajustar la configuración del perfil del escalador automático del clúster según los escenarios de carga de trabajo específicos, a la vez que tiene en cuenta los inconvenientes entre el rendimiento y el costo. En esta sección se proporcionan ejemplos que muestran esas contrapartidas.
Es importante tener en cuenta que la configuración del perfil del escalador automático del clúster es en todo el clúster y se aplica a todos los grupos de nodos habilitados para escalabilidad automática. Las acciones de escalado que se realizan en un grupo de nodos pueden afectar al comportamiento de escalado automático de otros grupos de nodos, lo que puede provocar resultados inesperados. Asegúrese de aplicar configuraciones de perfil coherentes y sincronizadas en todos los grupos de nodos pertinentes para asegurarse de obtener los resultados deseados.
Ejemplo 1: Optimización del rendimiento
En el caso de los clústeres que manejan cargas de trabajo sustanciales y con picos repentinos, con un enfoque principal en el rendimiento, se recomienda aumentar el scan-interval y reducir el scale-down-utilization-threshold. Esta configuración ayuda a procesar por lotes varias operaciones de escalado en una sola llamada, optimizando el tiempo de escalado y el uso de cuotas de lectura y escritura de proceso. También ayuda a mitigar el riesgo de reducir rápidamente las operaciones en nodos infrautilizados, mejorando la eficiencia de la programación de pods. Aumente también ok-total-unready-count y max-total-unready-percentage.
En el caso de los clústeres con pods daemonset, se recomienda establecer ignore-daemonsets-utilization en true, que omite eficazmente el uso del nodo por los pods de daemonset y minimiza las operaciones de reducción vertical innecesarias. Consulte el perfil para cargas de trabajo intermitentes
Ejemplo 2: Optimización del costo
Si desea una perfil optimizado para costos, se recomienda establecer las siguientes configuraciones de parámetros:
- Reduzca
scale-down-unneeded-time, que es la cantidad de tiempo que un nodo debe ser innecesario antes de que sea apto para la reducción vertical. - Reduzca
scale-down-delay-after-add, que es la cantidad de tiempo que se debe esperar después de agregar un nodo antes de considerarlo para reducir verticalmente. - Aumente
scale-down-utilization-threshold, que es el umbral de uso para quitar nodos. - Aumente
max-empty-bulk-delete, que es el número máximo de nodos que se pueden eliminar en una sola llamada. - Establezca
skip-nodes-with-local-storageen false. - Aumente
ok-total-unready-countymax-total-unready-percentage.
Problemas comunes y recomendaciones de mitigación
Vea los errores de escalado y los eventos de escalado vertical no desencadenados a través de CLI o Portal.
No desencadenar operaciones de escalado vertical
| Causas comunes | Recomendaciones de mitigación |
|---|---|
| Conflictos de afinidad de nodo PersistentVolume, que pueden surgir al usar el escalador automático del clúster con varias zonas de disponibilidad o cuando la zona de un pod o volumen persistente difiere de la zona del nodo. | Use un grupo de nodos por zona de disponibilidad y habilite --balance-similar-node-groups. También puede establecer el campo volumeBindingMode en WaitForFirstConsumer en la especificación del pod para evitar que el volumen se enlace a un nodo hasta que se cree un pod que utiliza el volumen. |
| Conflictos de afinidad entre intolerancias y tolerancias/nodo | Evalúe las intolerancias asignadas a los nodos y revise las tolerancias definidas en los pods. Si es necesario, realice ajustes en las intolerancias y tolerancias para asegurarse de que los pods se pueden programar de forma eficaz en los nodos. |
Errores de operación de escalado vertical
| Causas comunes | Recomendaciones de mitigación |
|---|---|
| Agotamiento de direcciones IP en la subred | Agregue otra subred en la misma red virtual y agregue otro grupo de nodos a la nueva subred. |
| Agotamiento de cuotas principales | Se ha agotado la cuota de núcleos aprobada. Solicite un aumento de cuota. El escalador automático del clúster entra en un estado de retroceso exponencial dentro del grupo de nodos específico cuando experimenta varios intentos de escalado vertical erróneos. |
| Tamaño máximo del grupo de nodos | Aumente el número máximo de nodos del grupo de nodos o cree un nuevo grupo de nodos. |
| Solicitudes o llamadas que superan el límite de velocidad | Consulte Errores 429: Demasiadas solicitudes. |
Errores de operación de reducción vertical
| Causas comunes | Recomendaciones de mitigación |
|---|---|
| Pod que impide la purga de nodos o no se puede expulsar el pod | • Vea qué tipos de pods pueden evitar la reducción vertical. • En el caso de los pods que usan almacenamiento local, como hostPath y emptyDir, establezca la marca de perfil del escalador automático del clúster skip-nodes-with-local-storage en false. • En la especificación del pod, establezca la anotación cluster-autoscaler.kubernetes.io/safe-to-evict en true. • Compruebe su PDB, ya que podría ser restrictivo. |
| Tamaño mínimo del grupo de nodos | Reduzca el tamaño mínimo del grupo de nodos. |
| Solicitudes o llamadas que superan el límite de velocidad | Consulte Errores 429: Demasiadas solicitudes. |
| Operaciones de escritura bloqueadas | No realice ningún cambio en el grupo de recursos de AKS totalmente administrado (consulte Directivas de soporte técnico de AKS). Quite o restablezca los bloqueos de recursos que haya aplicado anteriormente al grupo de recursos. |
Otros problemas
| Causas comunes | Recomendaciones de mitigación |
|---|---|
| PriorityConfigMapNotMatchedGroup | Asegúrese de agregar todos los grupos de nodos que requieren el escalado automático al archivo de configuración del ampliador. |
Grupo de nodos en retroceso
El grupo de nodos en el retroceso se introdujo en la versión 0.6.2 y hace que el escalador automático del clúster se desactive del escalado de un grupo de nodos después de un error.
Dependiendo de cuánto tiempo se hayan producido errores en las operaciones de escalado, puede tardar hasta 30 minutos antes de realizar otro intento. Para restablecer el estado de retroceso del grupo de nodos, deshabilite y vuelva a habilitar el escalado automático.
Colaborar con nosotros en GitHub
El origen de este contenido se puede encontrar en GitHub, donde también puede crear y revisar problemas y solicitudes de incorporación de cambios. Para más información, consulte nuestra guía para colaboradores.

Azure Kubernetes Service