Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Este tutorial le guía a través de la implementación de una aplicación de bot de chat basada en Spring Boot integrada con la extensión sidecar Phi-4 en Azure App Service. Siguiendo los pasos, aprenderá a configurar una aplicación web escalable, agregar un sidecar con tecnología de IA para mejorar las funcionalidades de conversación y probar la funcionalidad del bot de chat.
Hospedar su propio modelo de lenguaje pequeño (SLM) ofrece varias ventajas:
- Control total sobre los datos. La información confidencial no se expone a servicios externos, lo que es fundamental para los sectores con requisitos de cumplimiento estrictos.
- Los modelos autohospedados se pueden ajustar para satisfacer casos de uso específicos o requisitos específicos del dominio.
- Latencia de red minimizada y tiempos de respuesta más rápidos para mejorar la experiencia del usuario.
- Control total sobre la asignación de recursos, lo que garantiza un rendimiento óptimo para la aplicación.
Prerrequisitos
- Una cuenta de Azure con una suscripción activa.
- Una cuenta de GitHub.
Implementación de la aplicación de ejemplo
En el explorador, vaya al repositorio de aplicaciones de ejemplo.
Inicie un nuevo Codespace desde el repositorio.
Inicie sesión con su cuenta de Azure:
az loginAbra el terminal en Codespace y ejecute los comandos siguientes:
cd use_sidecar_extension/springapp ./mvnw clean package az webapp up --sku P3MV3 --runtime "JAVA:21-java21" --os-type linux
Adición de la extensión de sidecar Phi-4
En esta sección, agregará la extensión de sidecar Phi-4 a la aplicación ASP.NET Core hospedada en Azure App Service.
- Vaya a Azure Portal y vaya a la página de administración de la aplicación.
- En el menú de la izquierda, seleccione Centro>.
- En la pestaña Contenedores, seleccione Añadir>extensión Sidecar.
- En las opciones de extensión de sidecar, seleccione AI: phi-4-q4-gguf (Experimental).
- Proporcione un nombre para la extensión sidecar.
- Seleccione Guardar para aplicar los cambios.
- Espere unos minutos a que la extensión se implemente. Mantenga la selección de Actualizar hasta que la columna Estado muestre En ejecución.
Esta extensión de sidecar Phi-4 usa una API de finalización de chat como OpenAI que puede responder a respuestas de finalización de chat en http://localhost:11434/v1/chat/completions. Para obtener más información sobre cómo interactuar con la API, consulte:
Prueba del bot de chat
En la página de administración de la aplicación, en el menú izquierdo, seleccione Información general.
En Dominio predeterminado, seleccione la dirección URL para abrir la aplicación web en un explorador.
Compruebe que la aplicación de bot de chat se está ejecutando y respondiendo a las entradas del usuario.
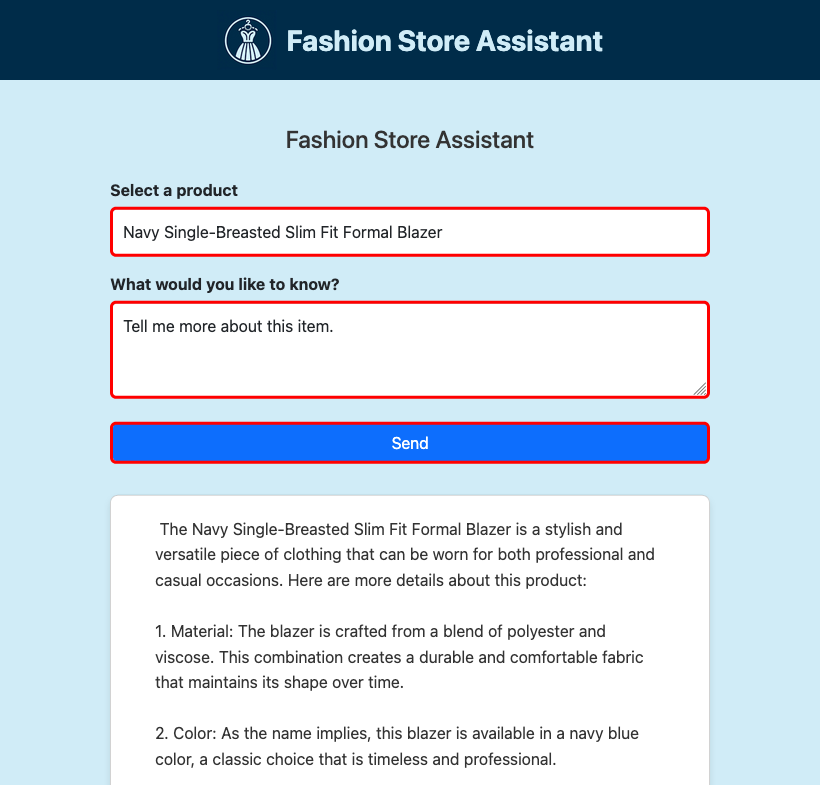
Funcionamiento de la aplicación de ejemplo
La aplicación de ejemplo muestra cómo integrar un servicio de Java con la extensión sidecar de SLM. La ReactiveSLMService clase encapsula la lógica para enviar solicitudes a la API de SLM y procesar las respuestas transmitidas. Esta integración permite a la aplicación generar respuestas conversacionales dinámicamente.
Al mirar en use_sidecar_extension/springapp/src/main/java/com/example/springapp/service/ReactiveSLMService.java, observas que:
El servicio lee la dirección URL de
fashion.assistant.api.url, que se establece en application.properties y tiene el valor dehttp://localhost:11434/v1/chat/completions.public ReactiveSLMService(@Value("${fashion.assistant.api.url}") String apiUrl) { this.webClient = WebClient.builder() .baseUrl(apiUrl) .build(); }La carga POST incluye el mensaje del sistema y la solicitud generada a partir del producto seleccionado y de la consulta del usuario.
JSONObject requestJson = new JSONObject(); JSONArray messages = new JSONArray(); JSONObject systemMessage = new JSONObject(); systemMessage.put("role", "system"); systemMessage.put("content", "You are a helpful assistant."); messages.put(systemMessage); JSONObject userMessage = new JSONObject(); userMessage.put("role", "user"); userMessage.put("content", prompt); messages.put(userMessage); requestJson.put("messages", messages); requestJson.put("stream", true); requestJson.put("cache_prompt", false); requestJson.put("n_predict", 2048); String requestBody = requestJson.toString();La solicitud POST reactiva transmite la respuesta línea por línea. Cada línea se analiza para extraer el contenido generado (o token).
return webClient.post() .contentType(MediaType.APPLICATION_JSON) .body(BodyInserters.fromValue(requestBody)) .accept(MediaType.TEXT_EVENT_STREAM) .retrieve() .bodyToFlux(String.class) .filter(line -> !line.equals("[DONE]")) .map(this::extractContentFromResponse) .filter(content -> content != null && !content.isEmpty()) .map(content -> content.replace(" ", "\u00A0"));
Preguntas más frecuentes
¿Cómo afecta el nivel de precios al rendimiento de sidecar para SLM?
Dado que los modelos de IA consumen recursos considerables, elija el plan de tarifa que proporciona suficientes vCPU y memoria para ejecutar el modelo específico. Por este motivo, las extensiones sidecar integradas de IA solo aparecen cuando la aplicación está en un plan de tarifa adecuado. Si construye su propio contenedor sidecar para SLM, debería utilizar un modelo optimizado para CPU, ya que los planes de tarifas de App Service están basados exclusivamente en CPU.
Por ejemplo, el modelo mini Phi-3 con una longitud de contexto de 4K de Hugging Face está diseñado para ejecutarse con recursos limitados y proporciona un fuerte razonamiento matemático y lógico para muchos escenarios comunes. También incluye una versión optimizada para CPU. En App Service, probamos el modelo en todos los niveles Premium y lo encontramos para funcionar bien en el nivel P2mv3 o superior. Si los requisitos lo permiten, puede ejecutarlo en un nivel inferior.
¿Cómo usar mi propio sidecar SLM?
El repositorio de ejemplo contiene un contenedor SLM de ejemplo que puede usar como sidecar. Ejecuta una aplicación fastAPI que escucha en el puerto 8000, tal como se especifica en su Dockerfile. La aplicación usa ONNX Runtime para cargar el modelo Phi-3 y, a continuación, reenvía los datos HTTP POST al modelo y transmite la respuesta del modelo de vuelta al cliente. Para obtener más información, vea model_api.py.
Para compilar la imagen sidecar usted mismo, debe instalar Docker Desktop localmente en el equipo.
Clone el repositorio localmente.
git clone https://github.com/Azure-Samples/ai-slm-in-app-service-sidecar cd ai-slm-in-app-service-sidecarCambie al directorio de origen de la imagen phi-3 y descargue el modelo localmente mediante la CLI de Huggingface.
cd bring_your_own_slm/src/phi-3-sidecar huggingface-cli download microsoft/Phi-3-mini-4k-instruct-onnx --local-dir ./Phi-3-mini-4k-instruct-onnxEl Dockerfile está configurado para copiar el modelo desde ./Phi-3-mini-4k-instruct-onnx.
Compile la imagen de Docker. Por ejemplo:
docker build --tag phi-3 .Cargue la imagen compilada en Azure Container Registry con Inserción de la primera imagen en Azure Container Registry mediante la CLI de Docker.
En la pestaña Contenedores del Centro> de implementación(nuevo), seleccione Agregar>contenedor personalizado y configure el nuevo contenedor de la siguiente manera:
- Nombre: phi-3
- Origen de la imagen: Azure Container Registry
- Registro: el registro
- Imagen: la imagen cargada
- Etiqueta: la etiqueta de imagen que desea
- Puerto: 8000
Selecciona Aplicar.
Consulte bring_your_own_slm/src/webapp para obtener una aplicación de ejemplo que interactúe con este contenedor sidecar personalizado.
Pasos siguientes
Tutorial: Configuración de un contenedor sidecar para una aplicación Linux en Azure App Service