Diagnóstico de un incidente mediante Metrics Advisor
Importante
A partir del 20 de septiembre de 2023, no podrá crear nuevos recursos de Metrics Advisor. El servicio Metrics Advisor se va a retirar el 1 de octubre de 2026.
¿Qué es un incidente?
Cuando se detectan anomalías en varias series temporales dentro de una métrica en una marca de tiempo determinada, Metrics Advisor agrupa automáticamente las anomalías que comparten la misma causa principal en un incidente. Normalmente, un incidente indica un problema real; Metrics Advisor realiza un análisis sobre él y proporciona información de análisis automática de la causa principal.
Esto reducirá en gran medida la necesidad del cliente de consultar cada anomalía y detectará rápidamente el factor más importante que contribuye a un problema.
Una alerta de Metrics Advisor puede incluir varios incidentes, y cada uno de ellos puede contener varias anomalías capturadas en series temporales diferentes con la misma marca de tiempo.
Rutas de acceso para diagnosticar un incidente
Diagnóstico a partir de una notificación de alerta
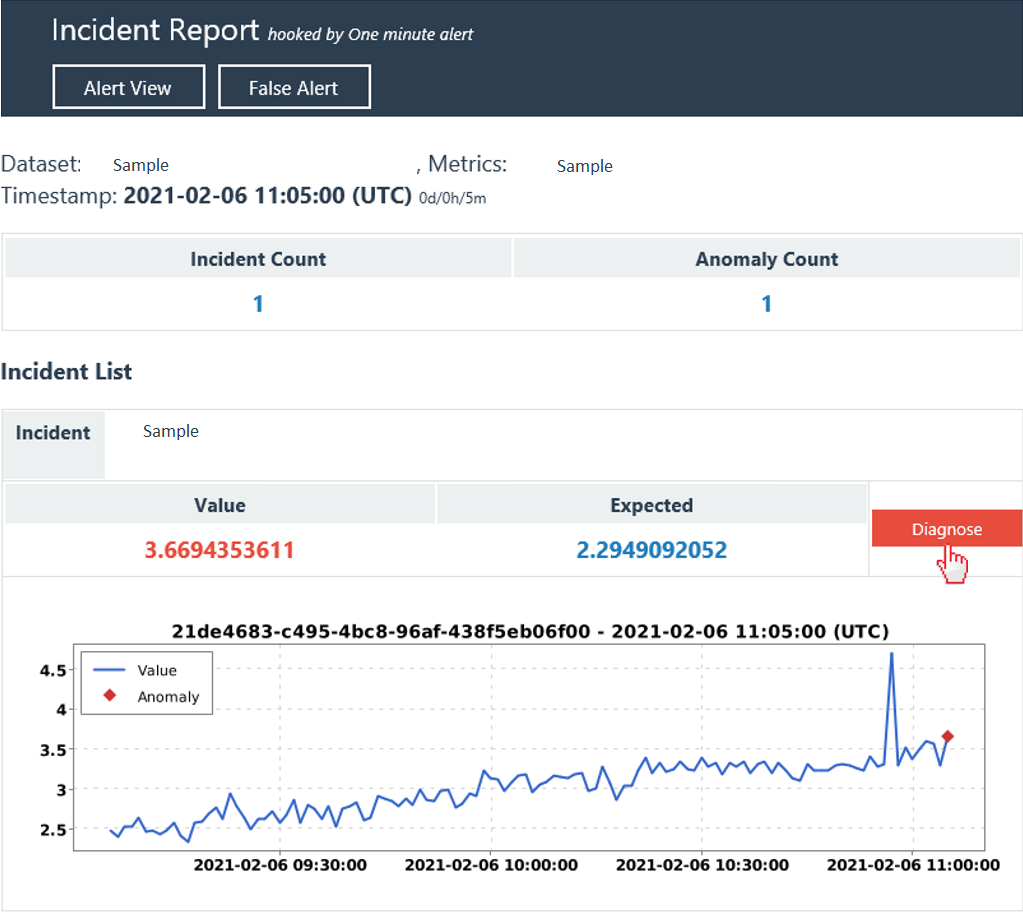
Si ha configurado un enlace de tipo correo electrónico o Teams y ha aplicado al menos una configuración de alertas, recibirá notificaciones de alerta continuas en las que se escalan los incidentes que analiza Metrics Advisor. La notificación contiene una lista de incidentes y una breve descripción. Cada incidente incluye un botón "Diagnosticar" . Si lo selecciona, se le dirigirá a la página de detalles del incidente para ver información de diagnóstico.
Diagnóstico a partir de un incidente en el "Centro de incidentes"
Hay un lugar central en Metrics Advisor que recopila todos los incidentes que se han capturado y facilita el seguimiento de los problemas en curso. Al seleccionar la pestaña Incident Hub (Centro de incidentes) en la barra de navegación de la izquierda, se mostrarán todos los incidentes de las métricas seleccionadas. En la lista de incidentes, seleccione uno para ver información de diagnóstico detallada.
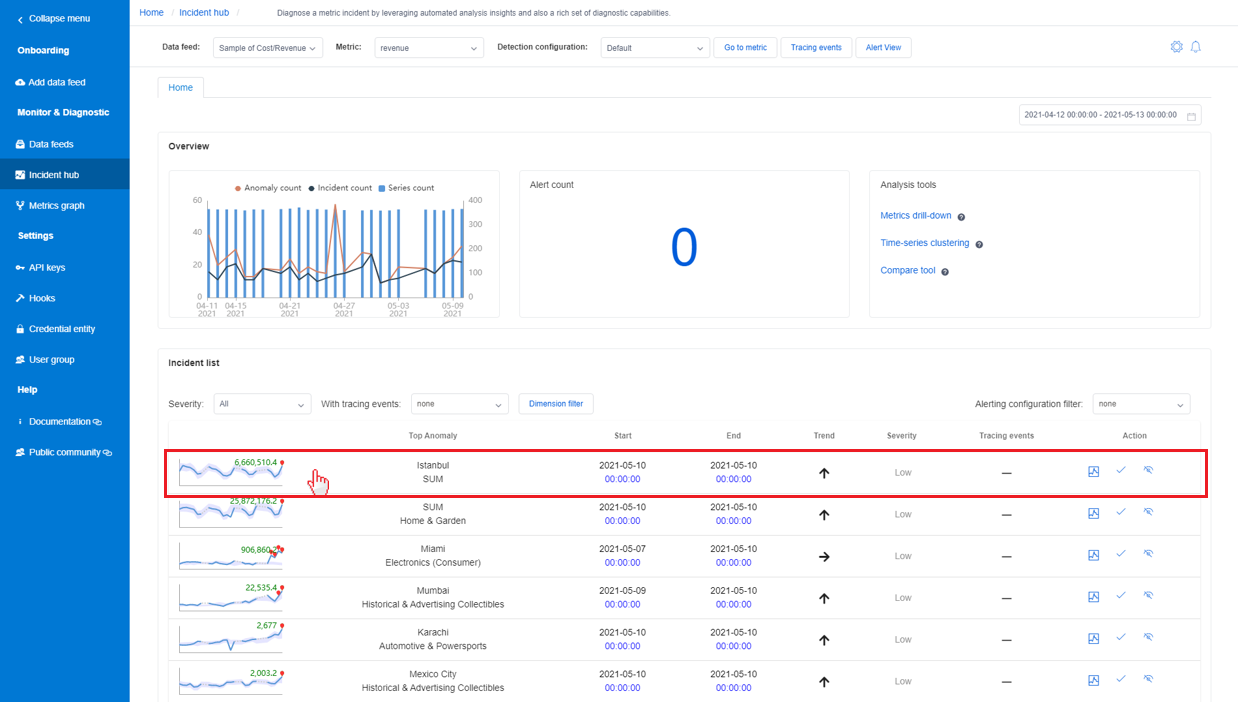
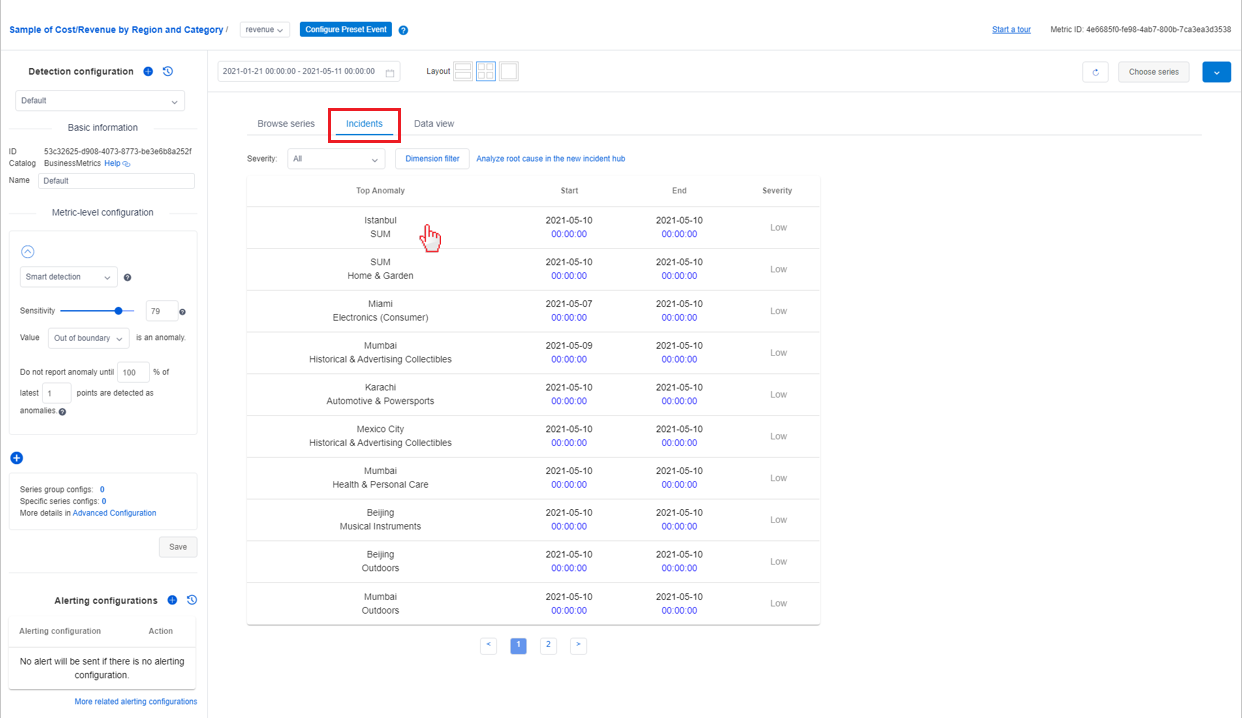
Diagnóstico a partir de un incidente enumerado en la página de métricas
En la página de detalles de las métricas, hay una pestaña denominada Incidentes donde se que muestran los incidentes más recientes capturados para esta métrica. La lista se puede filtrar por la gravedad de los incidentes o por el valor de dimensión de las métricas.
Al seleccionar un incidente de la lista, se le dirigirá a la página de detalles del incidente para ver la información de diagnóstico.
Flujo de diagnóstico típico
Cuando se le dirija a la página de detalles del incidente, puede aprovechar la información que analiza automáticamente Metrics Advisor para localizar rápidamente la causa principal de un problema o usar la herramienta de análisis para evaluar en profundidad el impacto del problema. Hay tres secciones en la página de detalles del incidente que corresponden a tres pasos principales para diagnosticar un incidente.
Paso 1: Comprobar el resumen del incidente actual
En la primera sección se muestra un resumen del incidente actual, incluida información básica, acciones y seguimientos, así como una causa principal analizada.
La información básica incluye la serie más afectada con un diagrama, la hora de inicio y finalización del impacto, la gravedad del incidente y el número total de anomalías incluidas. Al leer estos detalles, podrá hacerse una idea de un problema en curso y su impacto.
Las acciones y los seguimientos se usan para facilitar la colaboración de varios equipos con motivo de un incidente en curso. A veces, un incidente puede requerir el esfuerzo conjunto de los miembros de diferentes equipos para analizarlo y resolverlo. Todos los usuarios que tengan permiso para ver el incidente podrán agregar una acción o un evento de seguimiento.
Por ejemplo, después de diagnosticar el incidente e identificar la causa principal, un ingeniero puede agregar un elemento de seguimiento con el tipo "personalizado" e indicar la causa principal en la sección de comentarios. Deje el estado como "Activo". Así, otros compañeros del equipo podrán compartir la información y sabrán que hay alguien trabajando para corregirlo. También puede agregar un elemento "Azure DevOps" para llevar el seguimiento de un incidente con una tarea o un error específicos.
La causa principal analizada es un resultado que se analiza automáticamente. Metrics Advisor analiza todas las anomalías que se capturan en series temporales dentro de una métrica con valores de dimensión diferentes en la misma marca de tiempo. Luego, realiza la correlación, para lo que agrupa las anomalías relacionadas, y genera un aviso de causa principal.
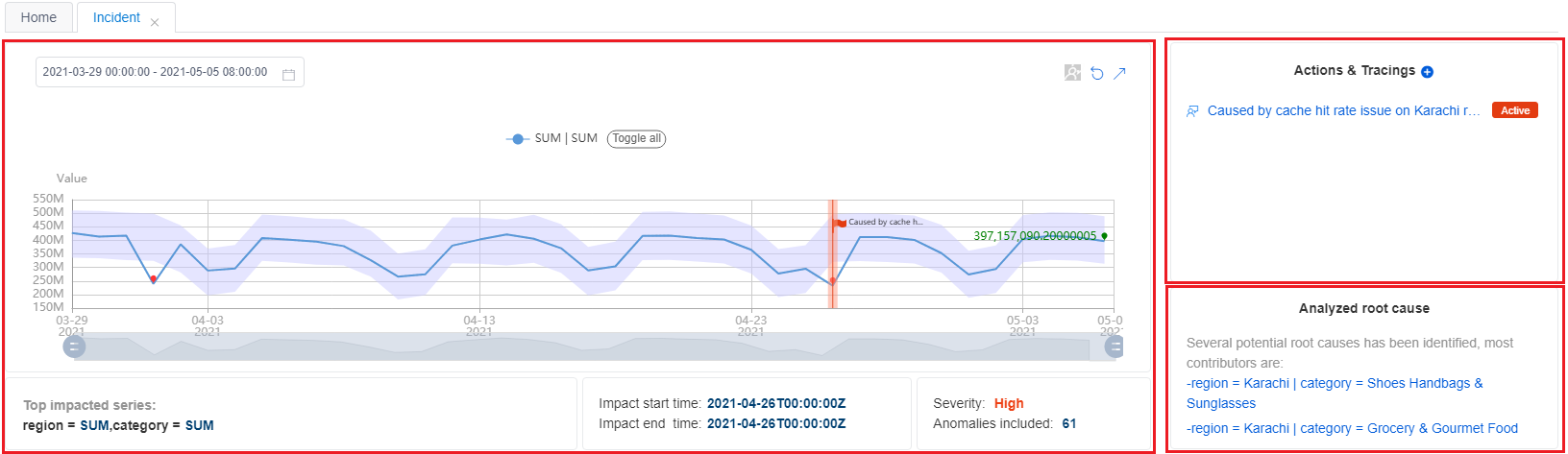
En el caso de las métricas con varias dimensiones, es habitual que se detecten varias anomalías al mismo tiempo, pero podrían compartir la misma causa principal. En lugar de analizar todas las anomalías una a una, la manera más eficaz de diagnosticar el incidente actual consiste en centrarse en la causa principal analizada.
Paso 2: Ver la información del diagnóstico entre dimensiones
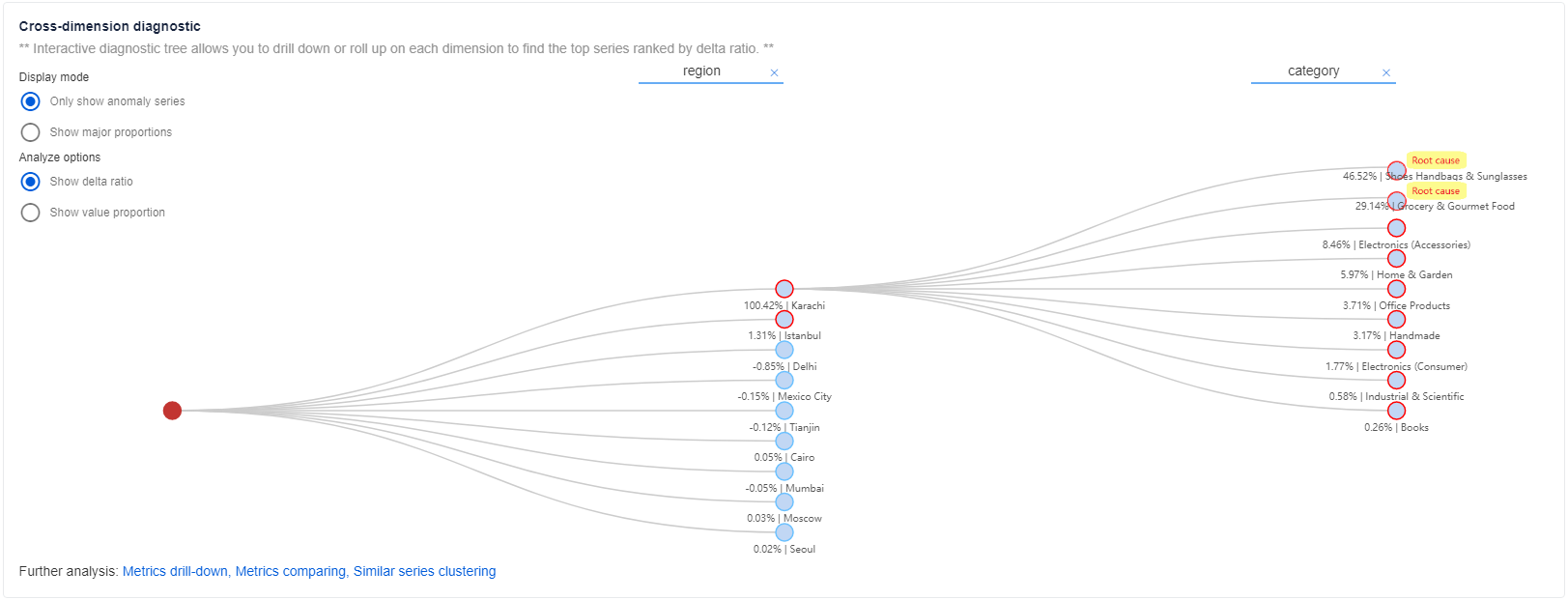
Después de obtener información básica y una conclusión del análisis automático, puede obtener detalles más específicos sobre el estado anómalo en otras dimensiones de la misma métrica de forma holística mediante el "Árbol de diagnóstico" .
En el caso de las métricas con varias dimensiones, Metrics Advisor clasifica la serie temporal en una jerarquía, que se denomina Árbol de diagnóstico. Por ejemplo, dos dimensiones supervisan una métrica "revenue": "region" y "category". A pesar de los valores de dimensión concretos, es preciso tener un valor de dimensión agregado, como "SUM" . Luego, la serie temporal de "region" = "SUM" y de "category" = "SUM" se clasificará como el nodo principal dentro del árbol. Cada vez que se captura una anomalía en la dimensión "SUM" , se puede explorar en profundidad y analizar para localizar qué valor de dimensión específico ha sido el que más ha contribuido a la anomalía del nodo primario. Seleccione cada nodo para expandirlo y ver información detallada.
Procedimiento para habilitar un valor de dimensión "agregado" en las métricas
Metrics Advisor permite realizar una "acumulación" en las dimensiones para calcular un valor de dimensión "agregado". El árbol de diagnóstico admite el diagnóstico en agregaciones "SUM", "AVG", "MAX", "MIN" y "COUNT" . Para habilitar un valor de dimensión "agregado", puede habilitar la función de "acumulación" durante la incorporación de datos. Asegúrese de que las métricas sean matemáticamente computables y de que la dimensión agregada tenga un valor empresarial real.

Si las métricas no tienen un valor de dimensión "agregado"
Si no hay ningún valor de dimensión "agregado" en las métricas y la función de "acumulación" no está habilitada durante la incorporación de datos, no se calculará ningún valor de métrica para la dimensión "agregada". Se mostrará como un nodo gris en el árbol que puede expandirse para ver sus nodos secundarios.
Leyenda del árbol de diagnóstico
Hay tres tipos de nodos en el árbol de diagnóstico:
- Nodo azul, que corresponde a una serie temporal con un valor de métrica real.
- Nodo gris, que corresponde a una serie temporal virtual sin ningún valor de métrica. Es un nodo lógico.
- Nodo rojo, que corresponde a la serie temporal más afectada del incidente actual.
El color del borde del nodo indica el estado anómalo de cada nodo.
- Un borde rojo significa que hay una anomalía capturada en la serie temporal correspondiente a la marca de tiempo del incidente.
- Un borde que no es rojo significa que no hay ninguna anomalía capturada en la serie temporal correspondiente a la marca de tiempo del incidente.
Modo de pantalla
Hay dos modos de presentación del árbol de diagnóstico: el que muestra solo series de anomalías y el que muestra las proporciones principales.
- El modo para mostrar solo series de anomalías permite al cliente centrarse en las anomalías actuales capturadas en diferentes series y diagnosticar la causa principal de las series más afectadas.
- El modo para mostrar las proporciones principales permite al cliente comprobar el estado anómalo de las proporciones principales de las series más afectadas. En este modo, el árbol mostraría tanto las series con anomalías detectadas como las series sin anomalías, pero centrándose más en las series importantes.
Opciones de análisis
Mostrar la relación de delta
La relación de delta es el porcentaje de delta del nodo actual en comparación con el delta del nodo primario. Esta es la fórmula:
(valor real del nodo actual - valor esperado del nodo actual) / (valor real del nodo primario - valor esperado del nodo primario) * 100 %
Se usa para analizar la contribución principal del delta del nodo primario.
Mostrar la proporción de valores
La proporción de valores es el porcentaje del valor del nodo actual en comparación con el valor del nodo primario. Esta es la fórmula:
(valor real del nodo actual / valor real del nodo primario) * 100 %
Se usa para evaluar la proporción del nodo actual en el conjunto.
Mediante el uso del árbol de diagnóstico, los clientes pueden localizar la causa principal del incidente actual en una dimensión específica. Esto reducirá en gran medida la necesidad del cliente de consultar cada anomalía o de pasar por diferentes dimensiones para encontrar la principal contribución a las anomalías.
Paso 3: Visualizar la información de diagnóstico entre métricas mediante un "gráfico de métricas"
A veces, es difícil analizar un problema mediante la comprobación del estado anómalo de una sola métrica, pero necesita poner en correlación varias métricas. Los clientes pueden configurar un gráfico de métricas que indica la relación entre las métricas. Consulte Procedimiento: Creación de un gráfico de métricas para empezar a trabajar.
Comprobación del estado de anomalía en la dimensión de causa principal en un "gráfico de métricas"
Cuando usa el resultado de diagnóstico entre dimensiones anterior, la causa principal se limita a un valor de dimensión concreto. Después, use el "gráfico de métricas" y filtre por la dimensión de causa principal analizada para comprobar el estado de anomalía de otras métricas.
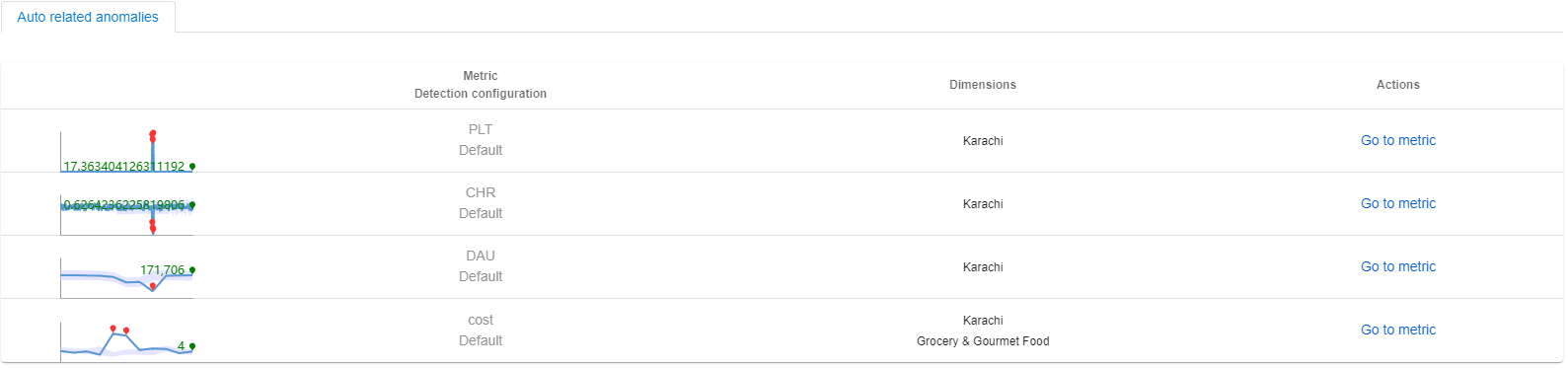
Por ejemplo, supongamos que se ha capturado un incidente en la métrica "revenue". La serie más afectada se encuentra en la región global con "region" = "SUM". Al usar el diagnóstico entre dimensiones, la causa principal se ha ubicado en "region" = "Karachi". Hay un gráfico de métricas preconfigurado, que incluye las métricas "revenue" (ingresos), "cost" (costos), "DAU" (usuarios activos diariamente), "PLT" (tiempo de carga de la página) y "CHR" (tasa de aciertos de caché).
Metrics Advisor filtrará automáticamente el gráfico de métricas por la dimensión de causa principal de "region" = "Karachi" y mostrará el estado de anomalía de cada métrica. Al analizar la relación entre las métricas y el estado de anomalía, los clientes pueden obtener más información sobre cuál es la causa principal final.

Anomalías relacionadas automáticamente
Al aplicar el filtro de dimensión de causa principal en el gráfico de métricas, las anomalías de cada métrica en la marca de tiempo del incidente actual se relacionarán automáticamente. Estas anomalías deben estar relacionadas con la causa principal identificada del incidente actual.