Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Azure Managed Redis
El almacenamiento en caché es una técnica que tiene como objetivo mejorar el rendimiento y la escalabilidad de un sistema. Almacena en caché los datos copiando temporalmente los datos a los que se accede con frecuencia a un almacenamiento rápido que se encuentra cerca de la aplicación. Si este almacenamiento de datos rápido se encuentra más cerca de la aplicación que el primer origen, el almacenamiento en caché puede mejorar considerablemente los tiempos de respuesta de las aplicaciones cliente dado que los datos se sirven con mayor rapidez.
El almacenamiento en caché es más eficaz cuando una instancia de cliente lee repetidamente los mismos datos, especialmente si todas las condiciones siguientes se aplican al almacén de datos original:
- Sigue siendo relativamente estático.
- Es lento en comparación con la velocidad de la caché.
- Está sujeto a un alto nivel de contención.
- Es lo suficientemente lejos de los clientes que la latencia de red es significativa.
Almacenamiento en caché en aplicaciones distribuidas
Normalmente, las aplicaciones distribuidas implementan o ambas de las estrategias siguientes al almacenar datos en caché:
- Usan una caché privada, donde los datos se mantienen localmente en el equipo que ejecuta una instancia de una aplicación o servicio.
- Usan una caché compartida, que actúa como un origen común al que pueden acceder varios procesos y máquinas.
En ambos casos, el almacenamiento en caché se puede realizar en el lado cliente y en el lado servidor. El almacenamiento en caché del lado cliente se realiza mediante el proceso que proporciona la interfaz de usuario para un sistema, como un explorador web o una aplicación de escritorio. El proceso que proporciona los servicios empresariales que se ejecutan de forma remota realiza el almacenamiento en caché del lado servidor.
Almacenamiento en caché privado
El tipo de caché más básico es un almacén en memoria. Se mantiene en el espacio de direcciones de un único proceso y es accedido directamente por el código que se ejecuta en ese proceso. Este tipo de caché es rápido de acceder. También puede proporcionar un medio eficaz para almacenar cantidades modestas de datos estáticos. El tamaño de una memoria caché suele estar restringido por la cantidad de memoria disponible en el equipo que hospeda el proceso.
Si necesita almacenar más información de la que es físicamente posible en la memoria, puede escribir datos almacenados en caché en el sistema de archivos local. Este proceso es más lento para acceder a los datos que se conservan en la memoria, pero aún debe ser más rápido y confiable que recuperar datos a través de una red.
Si tiene varias instancias de una aplicación que usa este modelo que se ejecuta simultáneamente, cada instancia de aplicación tiene su propia caché independiente que contiene su propia copia de los datos.
Piense en una memoria caché como una instantánea de los datos originales en algún momento del pasado. Si estos datos no son estáticos, es probable que diferentes instancias de aplicación contengan versiones diferentes de los datos en sus memorias caché. Por lo tanto, la misma consulta realizada por estas instancias puede devolver resultados diferentes, como se muestra en la figura 1.
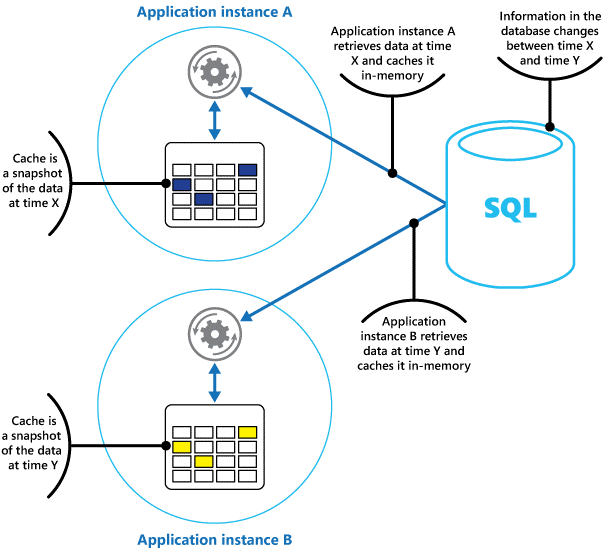
Figura 1: Uso de una caché en memoria en instancias diferentes de una aplicación.
Almacenamiento en caché compartido
Si utiliza una caché compartida, puede ayudar a aliviar las preocupaciones sobre la posible inconsistencia de los datos entre cada caché, lo cual puede ocurrir con el almacenamiento en caché en memoria. El almacenamiento en caché compartido garantiza que las distintas instancias de aplicación vean la misma vista de los datos almacenados en caché. Localiza la memoria caché en una ubicación independiente, que normalmente se hospeda como parte de un servicio independiente, como se muestra en la figura 2.
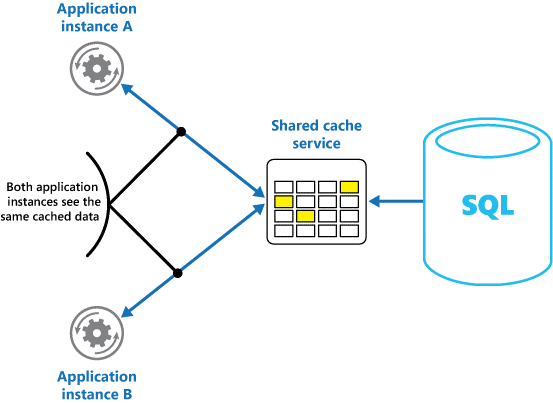
Figura 2: Uso de una caché compartida.
Una ventaja importante del enfoque de almacenamiento en caché compartido es la escalabilidad que proporciona. Muchos servicios de caché compartida se implementan mediante un clúster de servidores y usan software para distribuir los datos en el clúster de forma transparente. Una instancia de aplicación envía una solicitud al servicio de caché. La infraestructura subyacente determina la ubicación de los datos almacenados en caché en el clúster. Puede escalar fácilmente la memoria caché agregando más servidores.
Hay dos desventajas principales del enfoque de almacenamiento en caché compartido:
- La memoria caché es más lenta para acceder porque ya no se mantiene localmente en cada instancia de aplicación.
- El requisito de implementar un servicio de caché independiente podría agregar complejidad a la solución.
Consideraciones para usar el almacenamiento en caché
En las secciones siguientes se describen con más detalle las consideraciones para diseñar y usar una memoria caché.
Decidir cuándo almacenar en caché los datos
El almacenamiento en caché puede mejorar considerablemente el rendimiento, la escalabilidad y la disponibilidad. Cuantos más datos tenga y mayor sea el número de usuarios que necesitan acceder a estos datos, mayores serán las ventajas del almacenamiento en caché. El almacenamiento en caché reduce la latencia y la contención asociadas al control de grandes volúmenes de solicitudes simultáneas en el almacén de datos original.
Por ejemplo, una base de datos podría admitir un número limitado de conexiones simultáneas. Sin embargo, recuperar datos de una caché compartida, en lugar de la base de datos subyacente, permite que una aplicación cliente acceda a estos datos incluso si el número de conexiones disponibles se agota actualmente. Además, si la base de datos deja de estar disponible, es posible que las aplicaciones cliente puedan continuar usando los datos que se mantienen en la memoria caché.
Considere la posibilidad de almacenar en caché los datos que se leen con frecuencia pero que se modifican con poca frecuencia (por ejemplo, datos que tienen una proporción mayor de operaciones de lectura que las operaciones de escritura). Sin embargo, no se recomienda usar la memoria caché como almacén autoritativo de información crítica. En su lugar, asegúrese de que todos los cambios que la aplicación no pueda permitirse perder siempre se guardan en un almacén de datos persistente. Si la memoria caché no está disponible, la aplicación todavía puede seguir funcionando mediante el almacén de datos y no perderá información importante.
Determinación de cómo almacenar en caché los datos de forma eficaz
La clave para usar una memoria caché reside eficazmente en determinar los datos más adecuados para almacenarlos en caché y almacenarlos en caché en el momento adecuado. Los datos se pueden agregar a la memoria caché a petición la primera vez que una aplicación la recupera. La aplicación solo debe capturar los datos una vez desde el almacén de datos y, a continuación, se puede satisfacer el acceso posterior mediante la memoria caché.
Como alternativa, una memoria caché puede rellenarse parcialmente o completamente con datos de antemano, normalmente cuando se inicia la aplicación (un enfoque conocido como propagación). Sin embargo, es posible que no sea aconsejable implementar la propagación para una caché grande, ya que este enfoque puede imponer una carga repentina y alta en el almacén de datos original cuando la aplicación comienza a ejecutarse.
A menudo, un análisis de patrones de uso puede ayudarle a decidir si rellenar previamente una memoria caché completa o parcialmente y elegir los datos que se van a almacenar en caché. Por ejemplo, puede inicializar la memoria caché con los datos de perfil de usuario estáticos para los clientes que usan la aplicación periódicamente (quizás todos los días), pero no para los clientes que usan la aplicación solo una vez a la semana.
El almacenamiento en caché normalmente funciona bien con datos inmutables o que cambian con poca frecuencia. Algunos ejemplos incluyen información de referencia, como información de productos y precios en una aplicación de comercio electrónico, o recursos estáticos compartidos que son costosos de construir. Algunos o todos estos datos se pueden cargar en la memoria caché al iniciar la aplicación para minimizar la demanda de recursos y mejorar el rendimiento. También puede que desee tener un proceso en segundo plano que actualice periódicamente los datos de referencia en la memoria caché para asegurarse de que es up-to-date. O bien, el proceso en segundo plano puede actualizar la memoria caché cuando cambian los datos de referencia.
El almacenamiento en caché es menos útil para los datos dinámicos, aunque hay algunas excepciones a esta consideración. Para obtener más información, consulte la sección Caché de datos altamente dinámicos más adelante en este artículo. Cuando los datos originales cambian periódicamente, la información almacenada en caché se vuelve obsoleta rápidamente o la sobrecarga de sincronizar la memoria caché con el almacén de datos original reduce la eficacia del almacenamiento en caché.
Una caché no tiene que incluir los datos completos de una entidad. Por ejemplo, si un elemento de datos representa un objeto multivalor, como un cliente bancario con un nombre, una dirección y un saldo de cuenta, algunos de estos elementos pueden permanecer estáticos, como el nombre y la dirección. Otros elementos, como el saldo de la cuenta, pueden ser más dinámicos. En estas situaciones, puede ser útil almacenar en caché las partes estáticas de los datos y recuperar (o calcular) solo la información restante cuando sea necesario.
Se recomienda llevar a cabo pruebas de rendimiento y análisis de uso para determinar si la carga previa o a petición de la memoria caché, o bien una combinación de ambas, es adecuada. La decisión debe basarse en el patrón de volatilidad y uso de los datos. El uso de caché y el análisis de rendimiento son importantes en las aplicaciones que encuentran cargas pesadas y deben ser altamente escalables. Por ejemplo, en escenarios altamente escalables, puede inicializar la memoria caché para reducir la carga en el almacén de datos en horas punta.
El almacenamiento en caché también se puede usar para evitar cálculos repetidos mientras se ejecuta la aplicación. Si una operación transforma los datos o realiza un cálculo complicado, puede guardar los resultados de la operación en la memoria caché. Si se requiere el mismo cálculo después, la aplicación puede recuperar los resultados de la memoria caché.
Una aplicación puede modificar los datos que se mantienen en una memoria caché. Sin embargo, se recomienda pensar en la memoria caché como un almacén de datos transitorio que podría desaparecer en cualquier momento. No almacene datos valiosos solo en la memoria caché; Asegúrese de mantener también la información en el almacén de datos original. Esto significa que si la memoria caché deja de estar disponible, se minimiza la posibilidad de perder datos.
Almacenar en caché datos altamente dinámicos
Cuando se almacena información que cambia rápidamente en un almacén de datos persistente, puede imponer una sobrecarga en el sistema. Por ejemplo, considere un dispositivo que informa continuamente del estado o de alguna otra medida. Si una aplicación decide no almacenar en caché estos datos basándose en que la información almacenada en caché suele estar obsoleta, la misma consideración podría ser cierta al almacenar y recuperar esta información del almacén de datos. En el tiempo necesario para guardar y capturar estos datos, puede cambiar.
En una situación como esta, tenga en cuenta las ventajas de almacenar la información dinámica directamente en la memoria caché en lugar de en el almacén de datos persistente. Si los datos no son críticos y no requieren auditoría, no importa si se pierde el cambio ocasional.
Administrar la expiración de datos en una caché
En la mayoría de los casos, los datos que se mantienen en una memoria caché son una copia de los datos que se mantienen en el almacén de datos original. Los datos del almacén de datos original pueden cambiar después de almacenarse en caché, lo que hace que los datos almacenados en caché se vuelvan obsoletos. Muchos sistemas de almacenamiento en caché permiten configurar la memoria caché para que expiren los datos y reducir el período durante el que los datos podrían estar obsoletos.
Los datos almacenados en caché expirados se quitan de la memoria caché y la aplicación debe recuperar los datos del almacén de datos original (puede devolver la información recién capturada a la memoria caché). Puede establecer una directiva de expiración predeterminada al configurar la memoria caché. En muchos servicios de caché, también puede estipular el período de expiración de objetos individuales cuando los almacena mediante programación en la memoria caché. Algunas memorias caché permiten especificar el período de expiración como un valor absoluto o como un valor deslizante que hace que el elemento se quite de la memoria caché si no se tiene acceso dentro del tiempo especificado. Esta configuración invalida cualquier directiva de expiración de toda la memoria caché, pero solo para los objetos especificados.
Note
Tenga en cuenta el período de expiración de la memoria caché y los objetos que contiene cuidadosamente. Si lo hace demasiado corto, los objetos expiran demasiado rápido y reduce las ventajas de usar la memoria caché. Si hace que el período sea demasiado largo, corre el riesgo de que los datos se vuelvan obsoletos.
También es posible que la memoria caché se rellene si los datos pueden permanecer residentes durante mucho tiempo. En este caso, las solicitudes para agregar nuevos elementos a la memoria caché pueden provocar que algunos elementos se quiten forzosamente en un proceso conocido como expulsión. Usualmente, los servicios de caché expulsan los datos según el criterio de menos recientemente usados (LRU), pero normalmente puede anular esta directiva e impedir que los elementos se expulsen. Sin embargo, si adopta este enfoque, corre el riesgo de superar la memoria que está disponible en la memoria caché. Una aplicación que intente agregar un elemento a la memoria caché fallará provocando una excepción.
Algunas implementaciones de almacenamiento en caché pueden proporcionar otras directivas de expulsión. Hay varios tipos de directivas de expulsión. Estos incluyen:
- Una directiva usada más recientemente (en la expectativa de que los datos no se vuelvan a requerir).
- Una política de primero en entrar, primero en salir (los datos más antiguos se eliminan primero).
- Una directiva de eliminación explícita basada en un evento desencadenado (como los datos que se están modificando).
Invalidar datos en una caché del lado cliente
Los datos que se mantienen en una caché del lado cliente se consideran generalmente fuera de los auspicios del servicio que proporciona los datos al cliente. Un servicio no puede forzar directamente a un cliente a agregar o quitar información de una caché del lado cliente.
Esto significa que es posible que un cliente que use una memoria caché mal configurada para seguir usando información obsoleta. Por ejemplo, si las directivas de expiración de la memoria caché no se implementan correctamente, un cliente podría usar información obsoleta almacenada en caché localmente cuando cambia la información del origen de datos original.
Si crea una aplicación web que sirve datos a través de una conexión HTTP, puede forzar implícitamente a un cliente web (como un explorador o proxy web) para capturar la información más reciente. Puede hacerlo si un recurso se actualiza mediante un cambio en el URI de ese recurso. Los clientes web suelen usar el URI de un recurso como clave en la memoria caché del lado cliente, por lo que si cambia el URI, el cliente web omite las versiones almacenadas anteriormente en caché de un recurso y captura la nueva versión en su lugar.
Administración de la simultaneidad en una memoria caché
A menudo, las memorias caché están diseñadas para compartirse mediante varias instancias de una aplicación. Cada instancia de aplicación puede leer y modificar datos en la memoria caché, por lo que los mismos problemas de simultaneidad que surgen con cualquier almacén de datos compartidos también se aplican a una memoria caché. En una situación en la que una aplicación necesita modificar los datos contenidos en la memoria caché, es posible que tenga que asegurarse de que las actualizaciones realizadas por una instancia de la aplicación no sobrescriben los cambios realizados por otra instancia.
En función de la naturaleza de los datos y de la probabilidad de colisiones, puede adoptar uno de estos dos enfoques para la simultaneidad:
- Optimistic. Antes de que la aplicación actualice los datos, comprueba si los datos de la memoria caché han cambiado desde que se recuperó. Si los datos siguen siendo los mismos, se puede realizar el cambio. De lo contrario, la aplicación tiene que decidir si se va a actualizar. (La lógica de negocios que impulsa esta decisión es específica de la aplicación). Este enfoque es adecuado para situaciones en las que las actualizaciones son poco frecuentes o donde es poco probable que se produzcan colisiones.
- Pessimistic. Cuando recupera los datos, la aplicación la bloquea en la memoria caché para evitar que otra instancia lo cambie. Este proceso garantiza que no se puedan producir colisiones, pero también pueden bloquear otras instancias que necesiten procesar los mismos datos. La concurrencia pesimista puede afectar la escalabilidad de una solución y solo se recomienda para operaciones de corta duración. Este enfoque puede ser adecuado para situaciones en las que las colisiones son más probables, especialmente si una aplicación actualiza varios elementos en la memoria caché y debe asegurarse de que estos cambios se aplican de forma coherente.
Implementación de alta disponibilidad y escalabilidad, y mejora del rendimiento
Evite usar una memoria caché como repositorio principal de datos; este es el rol del almacén de datos original desde el que se rellena la memoria caché. El almacén de datos original es responsable de garantizar la persistencia de los datos.
Tenga cuidado de no introducir dependencias críticas sobre la disponibilidad de un servicio de caché compartido en las soluciones. Una aplicación debe poder seguir funcionando si el servicio que proporciona la memoria caché compartida no está disponible. La aplicación no debe dejar de responder ni producir un error mientras espera a que se reanude el servicio de caché.
Por lo tanto, la aplicación debe estar preparada para detectar la disponibilidad del servicio de caché y revertir al almacén de datos original si no se puede acceder a la memoria caché. El patrón Circuit-Breaker es útil para manejar este escenario. El servicio que proporciona la memoria caché se puede recuperar y, una vez que esté disponible, la memoria caché se puede repoblar a medida que se leen los datos del almacén de datos original, siguiendo una estrategia como el patrón Cache-aside.
Sin embargo, la escalabilidad del sistema podría verse afectada si la aplicación vuelve al almacén de datos original cuando la memoria caché no está disponible temporalmente. Aunque el almacén de datos se está recuperando, el almacén de datos original podría estar desbordado con solicitudes de datos, lo que da lugar a tiempos de espera y conexiones con errores.
Considere la posibilidad de implementar una caché privada local en cada instancia de una aplicación, junto con la caché compartida a la que acceden todas las instancias de aplicación. Cuando la aplicación recupera un elemento, puede comprobar primero en su caché local, después en la caché compartida y, por último, en el almacén de datos original. La caché local se puede rellenar mediante los datos de la caché compartida o en la base de datos si la caché compartida no está disponible.
Este enfoque requiere una configuración cuidadosa para evitar que la caché local se vuelva demasiado obsoleta con respecto a la caché compartida. Sin embargo, la caché local actúa como un búfer si no se puede acceder a la caché compartida. En la figura 3 se muestra esta estructura.
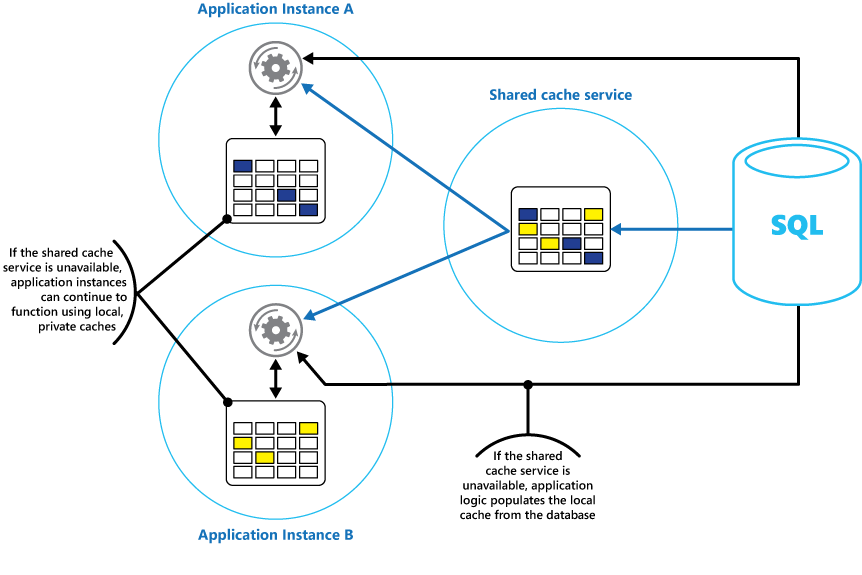
Figura 3: Uso de una caché privada local con una caché compartida.
Para admitir cachés de gran tamaño que contienen datos de larga vida útil, algunos servicios de caché proporcionan una opción de alta disponibilidad que implementa la conmutación por error automática si la caché deja de estar disponible. Este enfoque suele implicar la replicación de los datos almacenados en caché almacenados en un servidor de caché principal en un servidor de caché secundario y cambiar al servidor secundario si se produce un error en el servidor principal o se pierde la conectividad.
Para reducir la latencia asociada a la escritura en varios destinos, la replicación en el servidor secundario puede producirse de forma asincrónica cuando los datos se escriben en la memoria caché del servidor principal. Este enfoque conduce a la posibilidad de que se pierda información almacenada en caché si se produce un error, pero la proporción de estos datos debe ser pequeña, en comparación con el tamaño general de la memoria caché.
Si una memoria caché compartida es grande, puede resultar útil crear particiones de los datos almacenados en caché entre nodos para reducir las posibilidades de contención y mejorar la escalabilidad. Muchas cachés compartidas admiten la capacidad de agregar (y quitar) de forma dinámica los nodos y reequilibrar los datos entre particiones. Este enfoque podría implicar la agrupación en clústeres, en la que la colección de nodos se presenta a las aplicaciones cliente como una sola caché. Sin embargo, internamente, los datos se dispersan entre nodos después de una estrategia de distribución predefinida que equilibra la carga uniformemente. Para obtener más información, consulte el patrón de particionamiento.
La agrupación en clústeres también puede aumentar la disponibilidad de la memoria caché. Si se produce un error en un nodo, el resto de la memoria caché sigue siendo accesible. La agrupación en clústeres se usa con frecuencia con la replicación y la conmutación por error. Cada nodo se puede replicar y la réplica se puede conectar rápidamente si se produce un error en el nodo.
Es probable que muchas operaciones de lectura y escritura impliquen valores o objetos de datos únicos. Sin embargo, en ocasiones podría ser necesario almacenar o recuperar grandes volúmenes de datos rápidamente. Por ejemplo, la propagación de una memoria caché podría implicar la escritura de cientos o miles de elementos en la memoria caché. Es posible que una aplicación también necesite recuperar un gran número de elementos relacionados de la memoria caché como parte de la misma solicitud.
Muchas cachés a gran escala proporcionan operaciones por lotes para estos fines. Esto permite a una aplicación cliente empaquetar un gran volumen de elementos en una sola solicitud y reduce la sobrecarga asociada a realizar un gran número de solicitudes pequeñas.
Almacenamiento en caché y coherencia final
Para que el patrón cache-aside funcione, la instancia de la aplicación que rellena la caché debe tener acceso a la versión más reciente y coherente de los datos. En un sistema que implementa la coherencia final (por ejemplo, un almacén de datos replicado), esto podría no ser el caso.
Una instancia de una aplicación podría modificar un elemento de datos e invalidar la versión almacenada en caché de ese elemento. Otra instancia de la aplicación podría intentar leer este elemento de una memoria caché, lo que provoca un error en la memoria caché, por lo que lee los datos del almacén de datos y lo agrega a la memoria caché. Sin embargo, si el almacén de datos no está totalmente sincronizado con las otras réplicas, la instancia de la aplicación podría leer y rellenar la memoria caché con el valor anterior.
Una caché distribuida presenta otra capa a este problema. El teorema CAP indica que un sistema distribuido puede proporcionar como máximo dos de tres garantías: coherencia, disponibilidad y tolerancia a particiones. Dado que las particiones de red son inevitables en entornos en la nube, debe elegir entre coherencia y disponibilidad. La mayoría de las cachés distribuidas, incluidas Redis, priorizan la disponibilidad y la tolerancia a particiones sobre la coherencia fuerte. Esto significa que las lecturas de una réplica de caché pueden devolver datos obsoletos durante una partición de red o inmediatamente después de una escritura en un nodo diferente. Al diseñar la estrategia de almacenamiento en caché, decida cuánto nivel de desactualización puede tolerar su aplicación y establecer TTLs consiguientemente. Para los datos que deben ser actuales, use TTL más cortos o omita la memoria caché por completo y lea del almacén de datos de origen.
Para obtener más información sobre cómo controlar la coherencia de los datos en sistemas distribuidos, consulte Consideraciones de datos para microservicios.
Protección de datos almacenados en caché
Independientemente del servicio de caché que use, considere cómo proteger los datos que se mantienen en la memoria caché frente al acceso no autorizado. Hay dos preocupaciones principales:
- Privacidad de los datos en la memoria caché.
- La privacidad de los datos a medida que fluye entre la memoria caché y la aplicación que usa la memoria caché.
Para proteger los datos de la memoria caché, el servicio de caché podría implementar un mecanismo de autenticación que requiera que las aplicaciones especifiquen los detalles siguientes:
- Qué identidades pueden acceder a los datos de la memoria caché.
- Qué operaciones (lectura y escritura) que estas identidades pueden realizar.
Para reducir la sobrecarga asociada a la lectura y escritura de datos, después de conceder a una identidad acceso de escritura o lectura a la memoria caché, esa identidad puede usar cualquier dato de la memoria caché.
Si necesita restringir el acceso a subconjuntos de los datos almacenados en caché, puede realizar uno de los métodos siguientes:
- Divida la memoria caché en particiones (mediante diferentes servidores de caché) y conceda acceso solo a identidades para las particiones que deben poder usar.
- Cifre los datos de cada subconjunto mediante claves diferentes y proporcione las claves de cifrado solo a las identidades que deben tener acceso a cada subconjunto. Es posible que una aplicación cliente todavía pueda recuperar todos los datos de la memoria caché, pero solo podrá descifrar los datos para los que tiene las claves.
También debe proteger los datos a medida que fluyen dentro y fuera de la memoria caché. Para ello, depende de las características de seguridad proporcionadas por la infraestructura de red que usan las aplicaciones cliente para conectarse a la memoria caché. Si la memoria caché se implementa mediante un servidor local dentro de la misma organización que hospeda las aplicaciones cliente, es posible que el aislamiento de la propia red no requiera que realice más pasos. Si la memoria caché se encuentra de forma remota y requiere una conexión TCP o HTTP a través de una red pública (como Internet), considere la posibilidad de implementar SSL.
Implementación del almacenamiento en caché con Azure Managed Redis
En las secciones restantes de este artículo se describe cómo implementar los patrones de almacenamiento en caché descritos anteriormente mediante Azure Managed Redis. Azure Managed Redis es un servicio administrado de Redis que puede usar como caché compartida entre instancias de aplicación. Admite el almacenamiento en caché de clave-valor, estructuras de datos como conjuntos, conjuntos ordenados y listas, y persistencia opcional para mantener la durabilidad durante los reinicios.
Para obtener información sobre los niveles disponibles, el planeamiento de la capacidad, las redes y los detalles de las características, consulte la documentación de Azure Managed Redis.
Conexión y configuración de aplicaciones cliente
Redis admite aplicaciones cliente en muchos lenguajes de programación. En el caso de las aplicaciones .NET, hay varias bibliotecas cliente disponibles, cada una adecuada para diferentes cargas de trabajo de Redis. Elegir la biblioteca adecuada depende de si Redis se usa estrictamente como una memoria caché o como una plataforma de datos de varios modelos.
Para conectarse a un servidor de Redis, use el método estático Connect de la ConnectionMultiplexer clase . La conexión que crea este método se crea para su uso durante toda la vigencia de la aplicación cliente. Varios subprocesos simultáneos pueden usar la misma conexión. No vuelva a conectarse y desconecte cada vez que realice una operación de Redis porque esto puede degradar el rendimiento.
Para ver ejemplos de conexiones específicas del lenguaje, consulte Conexión a Azure Managed Redis.
Elección de una biblioteca cliente de .NET
Al usar Azure Managed Redis para el almacenamiento en caché, las bibliotecas de .NET recomendadas son:
- StackExchange.Redis: un cliente de Redis de bajo nivel con alto rendimiento. Úselo cuando necesite acceso directo a comandos de Redis, operaciones atómicas, transacciones, canalización o scripting de Lua.
-
Microsoft.Extensions.Caching.StackExchangeRedis: proporciona una
IDistributedCacheintegración para ASP.NET Core. Úselo para el almacenamiento en caché sencillo de clave-valor donde los valores se almacenan como matrices de bytes opacas. Esta abstracción no expone estructuras de datos avanzadas de Redis.
Estas bibliotecas proporcionan los primitivos necesarios para crear patrones comunes de almacenamiento en caché, pero la aplicación debe implementar la propia lógica de almacenamiento en caché.
Implementación de patrones de almacenamiento en caché
La manera más sencilla de usar Redis para el almacenamiento en caché es almacenar valores en claves mediante el modelo de clave-valor. Los valores pueden ser cadenas o datos binarios de longitud arbitraria, lo que hace que Redis sea adecuado para almacenar en caché objetos serializados, datos de configuración, estado de sesión o resultados predefinidos.
Diseñe cuidadosamente su keyspace y use claves significativas (pero no demasiado extensas). Por ejemplo, use claves estructuradas como customer:100 (en lugar de simplemente 100) para representar la clave para el cliente con el identificador 100. Este esquema permite distinguir entre valores que almacenan distintos tipos de datos. Por ejemplo, también puede usar la clave orders:100 para representar la clave del pedido con el identificador 100.
Aunque las cadenas son el enfoque de almacenamiento en caché más común, Redis admite un amplio conjunto de tipos de datos nativos, como hashes, listas, conjuntos, conjuntos ordenados y flujos, lo que permite patrones de almacenamiento en caché más flexibles. Para más información sobre los tipos de datos de Redis, consulte la documentación de Redis sobre los tipos de datos.
Implementación del patrón cache-aside
Como se describe en Determinar cómo almacenar en caché los datos de forma eficaz, un enfoque común consiste en cargar datos en la memoria caché a petición. En el ejemplo siguiente se comprueba primero la memoria caché, se captura del origen de datos en caso de error y se almacena el resultado para las solicitudes posteriores:
var config = new ConfigurationOptions();
// ... configure endpoint, credentials, SSL, etc.
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase db = redisHostConnection.GetDatabase();
async Task<string> RetrieveItemAsync(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await db.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue is null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await db.StringSetAsync(itemKey, itemValue);
}
return itemValue;
}
Realización de operaciones atómicas y por lotes
Cuando varios clientes o instancias de aplicación comparten una memoria caché, debe evitar que las actualizaciones simultáneas dañen los datos. Las estrategias generales de simultaneidad se describen en Administración de la simultaneidad en una memoria caché anterior en este artículo. Redis proporciona varios mecanismos que implementan esas estrategias.
Operaciones atómicas de clave única. Los comandos como INCR, INCRBY, DECR, DECRBYy GETSET actualizan un valor en un solo paso, lo que elimina las condiciones de carrera que se producen cuando GET y SET se emiten por separado. Ejemplos:
INCR,INCRBY,DECR,DECRBYincrementa o disminuye de forma atómica un valor numérico. En StackExchange.Redis, utilizaIDatabase.StringIncrementAsyncyIDatabase.StringDecrementAsync. Son útiles para contadores, limitadores de velocidad y seguimiento de cuotas en los que varios clientes actualizan la misma clave simultáneamente.GETSET, que establece de forma atómica una clave en un nuevo valor y devuelve el valor anterior. En StackExchange.Redis, useIDatabase.StringGetSetAsync:string oldValue = await cache.StringGetSetAsync("data:counter", 0);
Operaciones de múltiples claves.
MGET y MSET leen o escriben múltiples valores de texto en una sola operación, lo que reduce la sobrecarga de red cuando se necesita trabajar con varias claves a la vez. Los métodos IDatabase.StringGetAsync y IDatabase.StringSetAsync se sobrecargan para admitir esta funcionalidad.
// Create a list of key-value pairs
var keysAndValues =
new KeyValuePair<RedisKey, RedisValue>[]
{
new("data:key1", "value1"),
new("data:key99", "value2"),
new("data:key322", "value3")
};
// Store the list of key-value pairs in the cache
await cache.StringSetAsync(keysAndValues);
...
// Find all values that match a list of keys
RedisKey[] keys = ["data:key1", "data:key99", "data:key322"];
// values should contain { "value1", "value2", "value3" }
RedisValue[] values = await cache.StringGetAsync(keys);
Transacciones (concurrencia optimista) Puede usar el WATCH comando para supervisar una o varias claves antes de iniciar una transacción con MULTI/EXEC. Si alguna clave inspeccionada cambia antes de que se inicie la transacción, Redis descarta la transacción y el cliente puede reintentar. La biblioteca StackExchange proporciona compatibilidad con transacciones a través de la ITransaction interfaz .
Se crea un ITransaction objeto mediante el IDatabase.CreateTransaction método . Se invocan comandos a la transacción mediante los métodos proporcionados por el ITransaction objeto .
La ITransaction interfaz proporciona acceso a un conjunto de métodos similares a los a los a los que accede la IDatabase interfaz, excepto que todos los métodos son asincrónicos. Esto significa que solo se realizan cuando se invoca el ITransaction.Execute método . El valor devuelto por el ITransaction.Execute método indica si la transacción se creó correctamente (true) o si se produjo un error (false).
El siguiente fragmento de código muestra un ejemplo que incrementa y disminuye dos contadores como parte de la misma transacción:
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = await transaction.ExecuteAsync();
Console.WriteLine($"Transaction {(result ? "succeeded" : "failed")}");
if (result)
{
long increment = await tx1;
long decrement = await tx2;
Console.WriteLine($"Result of increment: {increment}");
Console.WriteLine($"Result of decrement: {decrement}");
}
Las transacciones de Redis son diferentes a las transacciones en bases de datos relacionales. El Execute método pone en cola todos los comandos que componen la transacción que se va a ejecutar y, si algún comando no es válido, la transacción se detiene. Si todos los comandos se han puesto en cola correctamente, cada comando se ejecuta de forma asincrónica. Si se produce un error en algún comando, los demás siguen procesando. Si necesita comprobar que un comando se completó correctamente, capture los resultados mediante la propiedad Result de la tarea correspondiente, como se muestra en el ejemplo anterior.
Programación en Lua Para las actualizaciones de varios pasos que deben ser atómicas en varias claves, puede ejecutar un script Lua en el servidor. Redis ejecuta todo el script como una sola operación sin intercalar otros comandos.
Note
En las implementaciones en clúster, todas las claves implicadas en una transacción o script lua deben residir en la misma ranura hash. Use etiquetas hash (por ejemplo, customer:{123}:name y customer:{123}:email) para colocar claves relacionadas.
Realizar operaciones de desencadenación y olvidar caché
Cuando una actualización de caché no afecta a la corrección de la aplicación, como incrementar un contador de vista o actualizar una estadística no crítica, puede omitir la espera de la respuesta del servidor. Redis admite operaciones fire-and-forget a través de marcas de comandos, que reducen la latencia de ida y vuelta para el cliente:
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
Especificar claves que expiran automáticamente
Las estrategias de expiración descritas en Administración de la expiración de datos en una caché se implementan en Redis a través de TTLs por clave. Al almacenar un elemento en una caché de Redis, puede especificar un tiempo de espera después del cual el elemento se quita automáticamente. También puede consultar cuánto tiempo tiene una clave antes de que expire mediante el TTL comando . Este comando está disponible para las aplicaciones stackExchange mediante el IDatabase.KeyTimeToLive método .
El siguiente fragmento de código muestra cómo establecer un tiempo de expiración de 20 segundos en una clave y consultar la duración restante de la clave:
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
También puede establecer la expiración en una fecha y hora específicas mediante el EXPIREAT comando , que está disponible en la biblioteca StackExchange como método KeyExpireAsync con un DateTime parámetro :
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2026, 6, 1, 0, 0, 0, DateTimeKind.Utc));
Tip
Puede quitar manualmente un elemento de la memoria caché mediante el comando DEL, que está disponible a través de la biblioteca StackExchange como método IDatabase.KeyDeleteAsync .
Cuando Redis alcanza su límite de memoria, expulsa las claves según una directiva de expulsión configurada. La directiva predeterminada es volatile-lru, que expulsa la clave usada menos recientemente que tiene un TTL establecido. Otras directivas incluyen allkeys-lru, volatile-randomy noeviction (lo que hace que las operaciones de escritura produzcan un error cuando la memoria está llena). Elija una directiva de expulsión en función de si la aplicación usa TTL de forma coherente y si prefiere proteger las claves que no tienen expiración. Para obtener más información, consulte Administración de memoria.
Correlacionar elementos almacenados en caché.
Al almacenar en caché los elementos relacionados, a menudo es necesario encontrarlos por relación en lugar de por clave principal. Por ejemplo, puede almacenar en caché las entradas de blog y debe responder a consultas como "¿qué publicaciones comparten la etiqueta Y?" o "¿qué etiquetas pertenecen a la publicación X?"
En Azure Managed Redis, el enfoque recomendado es usar RedisJSON y RediSearch. Almacene cada elemento almacenado en caché como un documento JSON con sus metadatos y, a continuación, cree un índice de RediSearch en los campos que necesita consultar. RediSearch controla las búsquedas inversas, el filtrado basado en etiquetas, las consultas de intervalo y la búsqueda de texto completo sin necesidad de que la aplicación mantenga estructuras de índice independientes.
Para escenarios más sencillos, también puede usar Conjuntos de Redis para construir índices directos e inversos manualmente. Almacene un conjunto por publicación (que contenga sus etiquetas) y un conjunto por etiqueta (que contenga los IDs de las publicaciones):
foreach (BlogPost post in posts)
{
string postTagsKey = $"blog:posts:{post.Id}:tags";
await cache.SetAddAsync(
postTagsKey, post.Tags.Select(s => (RedisValue)s).ToArray());
foreach (var tag in post.Tags)
{
await cache.SetAddAsync($"tag:{tag}:blog:posts", post.Id);
}
}
A continuación, puede consultar etiquetas para una publicación con SetMembersAsync, buscar etiquetas comunes entre publicaciones con SetCombineAsync(SetOperation.Intersect, ...)o buscar todas las publicaciones de una etiqueta determinada. El inconveniente es que la aplicación debe mantener tanto los conjuntos directos como los inversos, lo que aumenta la complejidad a medida que crece el número de relaciones.
Buscar elementos a los que se ha accedido recientemente
Muchas aplicaciones necesitan realizar un seguimiento de los elementos a los que se ha accedido o visto más recientemente. Por ejemplo, un sitio de blogs podría mostrar las publicaciones recientemente leídas a un visitante que vuelve. Las listas de Redis proporcionan una manera eficaz de implementar patrones de caché basados en la recencia. Los elementos se pueden insertar al final de la lista mediante LPUSH o RPUSH, y se pueden quitar mediante LPOP o RPOP. Utilice LTRIM para limitar la longitud de la lista y evitar el crecimiento descontrolado de la memoria.
Implementación de una tabla de clasificación
Los conjuntos ordenados (ZSET) de Redis mantienen clasificaciones ordenadas asociando cada elemento con una puntuación numérica. Redis mantiene la ordenación automáticamente.
ZADD es O(log N) y consultas de intervalo como ZRANGE y ZREVRANGE son O(log N + M) donde M es el número de elementos devueltos, por lo que los conjuntos ordenados siguen siendo eficaces incluso con recuentos de elementos grandes.
Agregar elementos a una tabla de clasificación
En el siguiente ejemplo se muestra cómo agregar una entrada de blog y su puntuación a una tabla de clasificación mediante el comando ZADD a través de SortedSetAddAsync:
var db = connection.GetDatabase();
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // The blog post being ranked
await db.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
Recuperar elementos clasificados
Puede recuperar elementos en orden de puntuación ascendente mediante SortedSetRangeByRankWithScoresAsync:
var entries = await db.SortedSetRangeByRankWithScoresAsync(redisKey);
foreach (var entry in entries)
{
Console.WriteLine($"{entry.Element}: {entry.Score}");
}
Note
SortedSetRangeByRankAsync devuelve solo valores de miembro, no puntuaciones.
Recuperar los N elementos principales
Para obtener los elementos de puntuación más alta, como las 10 publicaciones principales, use el orden descendente:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
Recuperar elementos por intervalo de puntuación
También puede consultar elementos en función de los límites de puntuación en lugar de clasificar:
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
Para evitar que una tabla de clasificación crezca indefinidamente, quite las entradas antiguas mediante SortedSetRemoveRangeByRankAsync o use claves con ámbito de tiempo (por ejemplo, tablas de clasificación diarias o semanales). Puede actualizar las puntuaciones de forma atómica mediante SortedSetIncrementAsync (ZINCRBY).
Almacenamiento en caché del estado de sesión y salida HTML
Las aplicaciones ASP.NET Core y ASP.NET pueden usar Azure Managed Redis para almacenar el estado de sesión y los datos de caché de salida. Al mantener los datos de sesión y la salida representada en una caché compartida basada en Redis, las aplicaciones que se ejecutan en varias instancias, como en Azure App Service, Azure Kubernetes Service (AKS), Azure Container Apps o conjuntos de escalado de máquinas virtuales, pueden mantener experiencias de usuario coherentes sin necesidad de afinidad de servidor.
Tip
Para obtener el mejor rendimiento, implemente la aplicación y la instancia de Azure Managed Redis en la misma región de Azure.
ASP.NET Core
Las aplicaciones de ASP.NET Core utilizan la abstracción IDistributedCache y el middleware de sesión. Azure Managed Redis se integra con IDistributedCache a través del Microsoft.Extensions.Caching.StackExchangeRedis paquete.
builder.Services.AddStackExchangeRedisCache(options =>
{
options.Configuration = "<your-cache-name>.<region>.redis.azure.net:10000";
options.InstanceName = "app-cache:";
});
builder.Services.AddSession();
El middleware de almacenamiento en caché de salida de ASP.NET Core también puede usar Redis como almacén de respaldo distribuido, lo que permite a las aplicaciones compartir fragmentos o páginas renderizados en todas las instancias. Para obtener más información, consulte ASP.NET proveedor de caché de salida principal para Redis.
Integración de .NET Aspire
Las aplicaciones de .NET Aspire pueden usar el Aspire.Hosting.Azure.Redis paquete para declarar un recurso de Redis administrado de Azure en el host de la aplicación. Los proyectos consumidores reciben automáticamente la configuración de conexión a través de la inyección de dependencias, lo que elimina la administración manual de cadenas de conexión a través de los servicios.
// App host: declare the Azure Managed Redis resource
var cache = builder.AddAzureManagedRedis("cache");
builder.AddProject<Projects.ProductService>()
.WithReference(cache);
Los servicios consumidores registran la caché distribuida de la misma manera que cualquier otro IDistributedCache proveedor. Para más información, consulte Introducción a la integración de Redis.
Alta disponibilidad, escalabilidad y creación de particiones
Cada instancia de Azure Managed Redis usa la replicación principal o de réplica. El servicio supervisa el estado del nodo y promueve automáticamente una réplica si se produce un error en la principal. Dado que la replicación es asincrónica, se puede perder una pequeña cantidad de datos escritos recientemente durante una conmutación por error inesperada. Para conocer las estrategias generales detrás de la replicación, la conmutación por error y el almacenamiento en caché en capas, consulte Implementación de alta disponibilidad y escalabilidad, y mejorar el rendimiento anteriormente en este artículo.
Puede combinar una caché local en memoria con Azure Managed Redis para reducir la latencia y proporcionar una reserva si la caché compartida es inaccesible temporalmente. El patrónCircuit-Breaker y el patrón Cache-aside ayudan a administrar este enfoque en capas.
En el caso de las cargas de trabajo que superan la capacidad de un solo nodo, Azure Managed Redis admite la creación de particiones (particionamiento) en varios nodos de Redis. Con ambas directivas de clúster, los datos se fragmentan automáticamente entre nodos usando hash de clave a shard, conmutación automática por error y resincronización, y refragmentación en línea (escalado horizontal y escalado vertical). Azure Managed Redis admite dos directivas de agrupación en clústeres:
Directiva de agrupación en clústeres de OSS (valor predeterminado): Los clientes se comunican directamente con la partición adecuada y siguen la semántica del clúster de OSS Redis, incluidas las redirecciones MOVED y ASK. Los clientes compatibles con clústeres, como StackExchange.Redis, controlan estas redirecciones automáticamente. Esta directiva proporciona la sobrecarga de enrutamiento más baja.
Directiva de agrupación en clústeres de Redis Enterprise: Un proxy proporciona enrutamiento transparente a través de un único punto de conexión. Los clientes no necesitan implementar la lógica compatible con clústeres ni controlar las respuestas MOVED/ASK. Esta directiva ofrece una integración de cliente más sencilla, pero presenta una pequeña sobrecarga de enrutamiento.
Azure Managed Redis también admite el modo no agrupado, que usa un único par principal o réplica sin particionamiento. Este modo es adecuado para cargas de trabajo más pequeñas que no requieren escalabilidad horizontal.
Note
Los modelos de creación de particiones personalizados (como el hash del lado cliente o servidores proxy de terceros) normalmente solo se necesitan en implementaciones de Redis autoadministradas en máquinas virtuales o Kubernetes. La agrupación en clústeres de Azure Managed Redis controla automáticamente el enrutamiento, la conmutación por error y la reasignación de particiones.
Replicación geográfica activa
Para la disponibilidad en varias regiones, Azure Managed Redis admite la replicación geográfica activa, que vincula instancias entre regiones de Azure a un único grupo de replicación. Cada instancia puede controlar las lecturas y escrituras, y los cambios se sincronizan automáticamente. La aplicación es responsable de redirigir el tráfico a una instancia en buen estado durante un fallo regional. Para más información, consulte Replicación geográfica activa.
Persistencia de los datos
De forma predeterminada, los datos almacenados en caché en Azure Managed Redis se mantienen en memoria y se pueden perder si un nodo se reinicia o conmuta por error. En el caso de las cargas de trabajo en las que la recompilación de la caché desde el almacén de datos de origen sería lenta o costosa, Azure Managed Redis admite la persistencia de datos opcional:
- Las instantáneas RDB toman capturas periódicas en un momento específico y se guardan en un disco administrado. RDB tiene un impacto mínimo en el rendimiento durante las operaciones normales, pero los datos escritos desde la última instantánea se pueden perder.
- AOF (Append-Only File) registra cada operación de escritura en el disco. AOF reduce la posible pérdida de datos a aproximadamente un segundo de escrituras, pero genera archivos más grandes y puede reducir el rendimiento de escritura.
Puede habilitar RDB y AOF juntos. Redis carga la instantánea RDB en el inicio y, a continuación, reproduce el registro de AOF para una recuperación casi completa.
Importante
La persistencia mejora la durabilidad frente a errores de nodo, pero no es un mecanismo de copia de seguridad o recuperación ante desastres. Para los datos críticos, mantenga siempre la copia autoritativa en el almacén de datos de origen y use el patrón cache-aside para volver a rellenar la memoria caché.
Para obtener más información sobre la configuración, consulte Configuración de la persistencia de datos.
Protección de datos almacenados en caché en Azure Managed Redis
Las instrucciones de Protección de datos almacenados en caché describen los problemas de control de acceso y datos en tránsito. Azure Managed Redis aborda estas direcciones:
- Use la autenticación de Microsoft Entra ID como mecanismo de control de acceso principal y siga el principio de privilegios mínimos al conceder acceso.
- Use puntos de conexión privados para restringir el acceso a la red para que el tráfico no recorra la red pública de Internet.
- Azure Managed Redis cifra los datos en tránsito con TLS y cifra los datos en reposo.
Consideraciones sobre la serialización
Al almacenar objetos .NET en Redis como valores de cadena, debe serializarlos. Al elegir un formato de serialización, considere los inconvenientes entre el rendimiento, la interoperabilidad, el control de versiones y el tamaño de carga. No hay ningún serializador único más rápido para todos los escenarios. Las pruebas comparativas dependen mucho del contexto y es posible que no reflejen la carga de trabajo real.
Si el nivel Redis administrado de Azure admite RedisJSON, puede almacenar objetos como documentos JSON nativos y consultar campos individuales sin deserializar todo el valor:
public static class RedisJsonExtensions
{
public static async Task<T?> GetAsync<T>(
this IDatabase cache,
string key,
string path = "$")
{
var result = await cache.ExecuteAsync("JSON.GET", key, path);
if (result.IsNull)
return default;
return JsonSerializer.Deserialize<T>(result!);
}
public static async Task SetAsync<T>(
this IDatabase cache,
string key,
T value,
TimeSpan? expiry = null,
string path = "$")
{
var json = JsonSerializer.Serialize(value);
// Store JSON document
await cache.ExecuteAsync("JSON.SET", key, path, json);
// Apply TTL if provided
if (expiry.HasValue)
{
await cache.KeyExpireAsync(key, expiry);
}
}
public static async Task<bool> ExpireAsync(
this IDatabase cache,
string key,
TimeSpan expiry)
{
return await cache.KeyExpireAsync(key, expiry);
}
}
Al serializar valores como cadenas de Redis en su lugar, las opciones de formato comunes incluyen:
JSON - legible por humanos, compatibilidad amplia multiplataforma. No el formato más compacto, sino una buena opción cuando los elementos almacenados en caché se devuelven directamente a los clientes HTTP, ya que evita un paso de deserialización adicional y re serialización.
MessagePack : formato binario compacto sin requisitos de esquema. Genera cargas más pequeñas que JSON con una sobrecarga de serialización inferior.
Búferes de protocolo (protobuf): formato binario basado en esquemas que genera cargas compactas. Requiere
.protoarchivos de definición y un paso de compilación para generar código específico del lenguaje.BSON : formato binario que extiende JSON con tipos adicionales, como fechas y datos binarios sin procesar. Las cargas son comparables en tamaño a JSON. Una opción práctica cuando la aplicación ya usa BSON en otro lugar, como con MongoDB.
Pasos siguientes
- Documentación de Azure Managed Redis
- Preguntas más frecuentes sobre Azure Managed Redis
- Documentación de Redis
- StackExchange.Redis
Recursos relacionados
Los siguientes patrones también pueden ser relevantes para su escenario al implementar el almacenamiento en caché en las aplicaciones:
Patrón cache-aside: este patrón describe cómo cargar datos a petición en una memoria caché desde un almacén de datos. Este patrón también ayuda a mantener la coherencia entre los datos que se mantienen en la memoria caché y los datos del almacén de datos original.
El patrón de particionamiento proporciona información sobre la implementación de particiones horizontales para ayudar a mejorar la escalabilidad al almacenar y acceder a grandes volúmenes de datos.