Guía de creación de particiones de datos
En muchas soluciones a gran escala, los datos se dividen en particiones que se pueden administrar y acceder a ellas por separado. La creación de particiones puede mejorar la escalabilidad, reducir la contención y optimizar el rendimiento. También puede proporcionar un mecanismo para dividir los datos mediante un patrón de uso. Por ejemplo, puede archivar los datos más antiguos en un nivel de almacenamiento de datos más barato.
Sin embargo, la estrategia de creación de particiones debe elegirse cuidadosamente para maximizar las ventajas, a la vez que se minimizan los efectos adversos.
Nota:
En este artículo, el término creación de particiones significa el proceso de dividir físicamente los datos en almacenes de datos independientes. No es lo mismo que la creación de particiones de tablas de SQL Server.
¿Por qué crear particiones de datos?
Mejorar la escalabilidad. Al escalar verticalmente un único sistema de base de datos, finalmente alcanzará un límite de hardware físico. Si divide los datos entre varias particiones, cada uno hospedado en un servidor independiente, puede escalar horizontalmente el sistema casi indefinidamente.
Mejorar el rendimiento. Las operaciones de acceso a datos en cada partición tienen lugar en un volumen menor de datos. Correctamente hecho, la creación de particiones puede hacer que el sistema sea más eficaz. Las operaciones que afectan a más de una partición se pueden ejecutar en paralelo.
Mejorar la seguridad. En algunos casos, puede separar los datos confidenciales y no sensibles en distintas particiones y aplicar controles de seguridad diferentes a los datos confidenciales.
Proporcionar flexibilidad operativa. La creación de particiones ofrece muchas oportunidades para realizar operaciones de ajuste, maximizar la eficiencia administrativa y minimizar el costo. Por ejemplo, puede definir diferentes estrategias para la administración, supervisión, copia de seguridad y restauración, y otras tareas administrativas en función de la importancia de los datos de cada partición.
Coincide con el almacén de datos con el patrón de uso. La creación de particiones permite implementar cada partición en un tipo diferente de almacén de datos, en función del costo y de las características integradas que ofrece el almacén de datos. Por ejemplo, los datos binarios grandes se pueden almacenar en Blob Storage, mientras que los datos más estructurados se pueden almacenar en una base de datos de documentos. Para obtener más información, consulte Elegir el almacén de datos correcto.
Mejorar la disponibilidad. La separación de datos entre varios servidores evita un único punto de error. Si se produce un error en una instancia, solo los datos de esa partición no están disponibles. Las operaciones en otras particiones pueden continuar. En el caso de los almacenes de datos de plataforma como servicio (PaaS) administrados, esta consideración es menos relevante, ya que estos servicios están diseñados con redundancia integrada.
Diseño de particiones
Hay tres estrategias típicas para crear particiones de datos:
Particionamiento horizontal (a menudo denominado particionamiento). En esta estrategia, cada partición es un almacén de datos independiente, pero todas las particiones tienen el mismo esquema. Cada partición se conoce como partición y contiene un subconjunto específico de los datos, como todos los pedidos de un conjunto específico de clientes.
Creación de particiones verticales. En esta estrategia, cada partición contiene un subconjunto de los campos de los elementos del almacén de datos. Los campos se dividen según su patrón de uso. Por ejemplo, los campos a los que se accede con frecuencia se pueden colocar en una partición vertical y campos a los que se accede con menos frecuencia en otro.
Creación de particiones funcionales. En esta estrategia, los datos se agregan según cómo se usa en cada contexto enlazado del sistema. Por ejemplo, un sistema de comercio electrónico podría almacenar datos de factura en una partición y datos de inventario de productos en otro.
Estas estrategias se pueden combinar y se recomienda considerarlas todas al diseñar un esquema de partición. Por ejemplo, puede dividir los datos en particiones y, a continuación, usar particiones verticales para subdividir aún más los datos de cada partición.
Particionamiento horizontal (particionamiento)
En la figura 1 se muestran particiones horizontales o particionamiento. En este ejemplo, los datos de inventario de productos se dividen en particiones basadas en la clave de producto. Cada partición contiene los datos de un intervalo contiguo de claves de partición (A-G y H-Z), organizados alfabéticamente. El particionamiento distribuye la carga en más equipos, lo que reduce la contención y mejora el rendimiento.
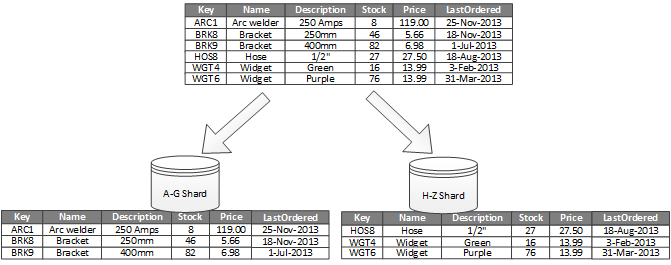
Figura 1: Particionamiento horizontal (particionamiento) de datos basados en una clave de partición.
El factor más importante es la elección de una clave de particionamiento. Puede ser difícil cambiar la clave después de que el sistema esté en funcionamiento. La clave debe asegurarse de que los datos se particionen para distribuir la carga de trabajo lo más uniformemente posible entre las particiones.
Las particiones no tienen que tener el mismo tamaño. Es más importante equilibrar el número de solicitudes. Algunas particiones pueden ser muy grandes, pero cada elemento tiene un número bajo de operaciones de acceso. Otras particiones pueden ser más pequeñas, pero se accede a cada elemento con mucha más frecuencia. También es importante asegurarse de que una sola partición no supere los límites de escala (en términos de capacidad y recursos de procesamiento) del almacén de datos.
Evite crear particiones "activas" que puedan afectar al rendimiento y la disponibilidad. Por ejemplo, el uso de la primera letra del nombre de un cliente provoca una distribución desequilibrada, ya que algunas letras son más comunes. En su lugar, use un hash de un identificador de cliente para distribuir datos de forma más uniforme entre particiones.
Elija una clave de particionamiento que minimice los requisitos futuros para dividir particiones grandes, fusionar particiones pequeñas en particiones más grandes o cambiar el esquema. Estas operaciones pueden llevar mucho tiempo y pueden requerir desconectar una o varias particiones mientras se realizan.
Si se replican particiones, es posible mantener algunas de las réplicas en línea, mientras que otras se dividen, combinan o reconfiguran. Sin embargo, es posible que el sistema tenga que limitar las operaciones que se pueden realizar durante la reconfiguración. Por ejemplo, los datos de las réplicas pueden marcarse como de solo lectura para evitar incoherencias de datos.
Para obtener más información sobre la creación de particiones horizontales, consulte Patrón de particionamiento.
Creación de particiones verticales
El uso más común para la creación de particiones verticales es reducir los costos de E/S y rendimiento asociados a la captura de elementos a los que se accede con frecuencia. En la figura 2 se muestra un ejemplo de creación de particiones verticales. En este ejemplo, las distintas propiedades de un elemento se almacenan en particiones diferentes. Una partición contiene datos a los que se accede con más frecuencia, incluido el nombre del producto, la descripción y el precio. Otra partición contiene datos de inventario: el recuento de existencias y la fecha de última orden.
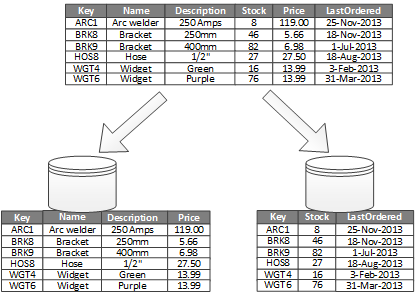
Figura 2: Creación de particiones verticales de datos por su patrón de uso.
En este ejemplo, la aplicación consulta periódicamente el nombre, la descripción y el precio del producto al mostrar los detalles del producto a los clientes. El recuento de existencias y la fecha de último pedido se mantienen en una partición independiente porque estos dos elementos se usan normalmente juntos.
Otras ventajas de la creación de particiones verticales:
Los datos relativamente lentos (nombre del producto, descripción y precio) se pueden separar de los datos más dinámicos (nivel de existencias y fecha de última pedido). Los datos de movimiento lento son un buen candidato para que una aplicación se almacene en caché en memoria.
Los datos confidenciales se pueden almacenar en una partición independiente con controles de seguridad adicionales.
La creación de particiones verticales puede reducir la cantidad de acceso simultáneo necesario.
La creación de particiones verticales funciona en el nivel de entidad dentro de un almacén de datos, normalizando parcialmente una entidad para dividirla de un elemento ancho a un conjunto de elementos estrechos . Es ideal para almacenes de datos orientados a columnas, como HBase y Cassandra. Si es poco probable que cambien los datos de una colección de columnas, también puede considerar el uso de almacenes de columnas en SQL Server.
Creación de particiones funcional
Cuando es posible identificar un contexto limitado para cada área empresarial distinta de una aplicación, la creación de particiones funcionales es una manera de mejorar el aislamiento y el rendimiento del acceso a datos. Otro uso común para la creación de particiones funcionales es separar los datos de lectura y escritura de los datos de solo lectura. En la figura 3 se muestra información general sobre la creación de particiones funcionales en la que los datos de inventario están separados de los datos de los clientes.
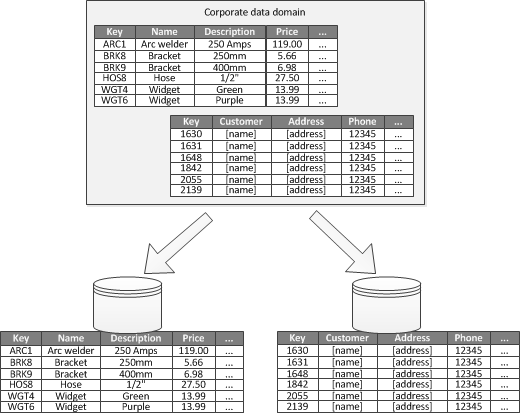
Figura 3: Creación de particiones funcionales de datos por contexto o subdominio enlazados.
Esta estrategia de creación de particiones puede ayudar a reducir la contención de acceso a datos en diferentes partes de un sistema.
Diseño de particiones para escalabilidad
Es fundamental tener en cuenta el tamaño y la carga de trabajo de cada partición y equilibrarlos para que los datos se distribuyan para lograr la máxima escalabilidad. Sin embargo, también debe particionar los datos para que no supere los límites de escalado de un único almacén de particiones.
Siga estos pasos al diseñar particiones para la escalabilidad:
- Analice la aplicación para comprender los patrones de acceso a datos, como el tamaño del conjunto de resultados devuelto por cada consulta, la frecuencia de acceso, la latencia inherente y los requisitos de procesamiento de proceso del lado servidor. En muchos casos, algunas entidades principales demandarán la mayoría de los recursos de procesamiento.
- Use este análisis para determinar los objetivos de escalabilidad actuales y futuros, como el tamaño de los datos y la carga de trabajo. A continuación, distribuya los datos entre las particiones para cumplir el objetivo de escalabilidad. Para la creación de particiones horizontales, es importante elegir la clave de partición correcta para asegurarse de que la distribución sea uniforme. Para obtener más información, consulte el patrón de particionamiento.
- Asegúrese de que cada partición tiene suficientes recursos para controlar los requisitos de escalabilidad, en términos de tamaño y rendimiento de los datos. Según el almacén de datos, puede haber un límite en la cantidad de espacio de almacenamiento, potencia de procesamiento o ancho de banda de red por partición. Si es probable que los requisitos superen estos límites, es posible que tenga que refinar la estrategia de creación de particiones o dividir los datos aún más, posiblemente combinando dos o más estrategias.
- Supervise el sistema para comprobar que los datos se distribuyen según lo previsto y que las particiones pueden controlar la carga. El uso real no siempre coincide con lo que predice un análisis. Si es así, puede ser posible reequilibrar las particiones o volver a diseñar algunas partes del sistema para obtener el equilibrio necesario.
Algunos entornos de nube asignan recursos en términos de límites de infraestructura. Asegúrese de que los límites del límite seleccionado proporcionan suficiente espacio para cualquier crecimiento previsto en el volumen de datos, en términos de almacenamiento de datos, potencia de procesamiento y ancho de banda.
Por ejemplo, si usa Azure Table Storage, hay un límite para el volumen de solicitudes que puede controlar una sola partición en un período de tiempo determinado. (Para más información, consulte Objetivos de escalabilidad y rendimiento de Azure Storage). Una partición ocupada puede requerir más recursos que una sola partición. Si es así, es posible que la partición tenga que volver a particionarse para distribuir la carga. Si el tamaño total o el rendimiento de estas tablas supera la capacidad de una cuenta de almacenamiento, es posible que tenga que crear cuentas de almacenamiento adicionales y distribuir las tablas entre estas cuentas.
Diseño de particiones para el rendimiento de las consultas
El rendimiento de las consultas se puede aumentar a menudo mediante conjuntos de datos más pequeños y mediante la ejecución de consultas paralelas. Cada partición debe contener una pequeña proporción de todo el conjunto de datos. Esta reducción del volumen puede mejorar el rendimiento de las consultas. Sin embargo, la creación de particiones no es una alternativa para diseñar y configurar una base de datos correctamente. Por ejemplo, asegúrese de que tiene los índices necesarios en su lugar.
Siga estos pasos al diseñar particiones para el rendimiento de las consultas:
Examine los requisitos y el rendimiento de la aplicación:
- Use los requisitos empresariales para determinar las consultas críticas que siempre deben realizarse rápidamente.
- Supervise el sistema para identificar las consultas que se realizan lentamente.
- Busque las consultas que se realizan con más frecuencia. Incluso si una sola consulta tiene un costo mínimo, el consumo acumulativo de recursos podría ser significativo.
Particione los datos que están causando un rendimiento lento:
- Limite el tamaño de cada partición para que el tiempo de respuesta de la consulta esté dentro del destino.
- Si usa particiones horizontales, diseñe la clave de partición para que la aplicación pueda seleccionar fácilmente la partición correcta. Esto evita que la consulta tenga que examinar todas las particiones.
- Considere la ubicación de una partición. Si es posible, intente mantener los datos en particiones que están geográficamente cerca de las aplicaciones y los usuarios que acceden a ellos.
Si una entidad tiene requisitos de rendimiento y rendimiento de consultas, use la creación de particiones funcionales en función de esa entidad. Si esto sigue sin cumplir los requisitos, aplique también particiones horizontales. En la mayoría de los casos, bastará una sola estrategia de partición, pero en algunos casos es más eficaz combinar ambas estrategias.
Considere la posibilidad de ejecutar consultas en paralelo entre particiones para mejorar el rendimiento.
Diseño de particiones para disponibilidad
Los datos de creación de particiones pueden mejorar la disponibilidad de las aplicaciones asegurándose de que todo el conjunto de datos no constituye un único punto de error y que los subconjuntos individuales del conjunto de datos se pueden administrar de forma independiente.
Tenga en cuenta los siguientes factores que afectan a la disponibilidad:
La importancia de los datos es para las operaciones empresariales. Identifique qué datos son información empresarial crítica, como transacciones, y qué datos son datos operativos menos críticos, como archivos de registro.
Considere la posibilidad de almacenar datos críticos en particiones de alta disponibilidad con un plan de copia de seguridad adecuado.
Establezca procedimientos de administración y supervisión independientes para los distintos conjuntos de datos.
Coloque los datos que tengan el mismo nivel de importancia crítica en la misma partición para que se pueda realizar una copia de seguridad juntas con una frecuencia adecuada. Por ejemplo, es posible que las particiones que contengan datos de transacción deban realizar copias de seguridad con más frecuencia que las particiones que contienen información de registro o seguimiento.
Cómo se pueden administrar las particiones individuales. El diseño de particiones para admitir la administración y el mantenimiento independientes proporciona varias ventajas. Por ejemplo:
Si se produce un error en una partición, se puede recuperar de forma independiente sin aplicaciones que accedan a los datos de otras particiones.
La creación de particiones de datos por área geográfica permite que las tareas de mantenimiento programadas se produzcan fuera de las horas punta de cada ubicación. Asegúrese de que las particiones no sean demasiado grandes para evitar que se complete ningún mantenimiento planeado durante este período.
Si se van a replicar datos críticos entre particiones. Esta estrategia puede mejorar la disponibilidad y el rendimiento, pero también puede presentar problemas de coherencia. Se tarda tiempo en sincronizar los cambios con cada réplica. Durante este período, diferentes particiones contendrán valores de datos diferentes.
Consideraciones sobre el diseño de aplicaciones
La creación de particiones agrega complejidad al diseño y desarrollo del sistema. Considere la posibilidad de crear particiones como parte fundamental del diseño del sistema incluso si el sistema solo contiene inicialmente una sola partición. Si direcciona la creación de particiones como una idea posterior, será más difícil porque ya tiene un sistema activo para mantener:
- Será necesario modificar la lógica de acceso a datos.
- Es posible que sea necesario migrar grandes cantidades de datos existentes para distribuirlos entre particiones.
- Los usuarios esperan poder seguir usando el sistema durante la migración.
En algunos casos, la creación de particiones no se considera importante porque el conjunto de datos inicial es pequeño y se puede controlar fácilmente mediante un único servidor. Esto puede ser cierto para algunas cargas de trabajo, pero muchos sistemas comerciales deben expandirse a medida que aumenta el número de usuarios.
Además, no solo es grandes almacenes de datos que se benefician de la creación de particiones. Por ejemplo, es posible que cientos de clientes simultáneos tengan acceso a un pequeño almacén de datos. La creación de particiones de los datos en esta situación puede ayudar a reducir la contención y mejorar el rendimiento.
Tenga en cuenta los siguientes puntos al diseñar un esquema de partición de datos:
Minimice las operaciones de acceso a datos entre particiones. Siempre que sea posible, mantenga los datos de las operaciones de base de datos más comunes en cada partición para minimizar las operaciones de acceso a datos entre particiones. La consulta entre particiones puede ser más lenta que la consulta dentro de una sola partición, pero la optimización de particiones para un conjunto de consultas podría afectar negativamente a otros conjuntos de consultas. Si debe consultar entre particiones, minimice el tiempo de consulta ejecutando consultas paralelas y agregando los resultados dentro de la aplicación. (Es posible que este enfoque no sea posible en algunos casos, como cuando se usa el resultado de una consulta en la consulta siguiente).
Considere la posibilidad de replicar datos de referencia estáticos. Si las consultas usan datos de referencia relativamente estáticos, como tablas de código postal o listas de productos, considere la posibilidad de replicar estos datos en todas las particiones para reducir las operaciones de búsqueda independientes en distintas particiones. Este enfoque también puede reducir la probabilidad de que los datos de referencia se conviertan en un conjunto de datos "frecuente", con un tráfico intensivo desde todo el sistema. Sin embargo, hay un costo adicional asociado a la sincronización de los cambios en los datos de referencia.
Minimice las combinaciones entre particiones. Siempre que sea posible, minimice los requisitos para la integridad referencial en particiones verticales y funcionales. En estos esquemas, la aplicación es responsable de mantener la integridad referencial entre particiones. Las consultas que unen datos entre varias particiones son ineficazs porque la aplicación normalmente necesita realizar consultas consecutivas basadas en una clave y, a continuación, una clave externa. En su lugar, considere la posibilidad de replicar o des normalizar los datos pertinentes. Si se necesitan combinaciones entre particiones, ejecute consultas paralelas en las particiones y una los datos dentro de la aplicación.
Adopte la coherencia final. Evalúe si la coherencia fuerte es realmente un requisito. Un enfoque común en los sistemas distribuidos es implementar la coherencia final. Los datos de cada partición se actualizan por separado y la lógica de la aplicación garantiza que todas las actualizaciones se completen correctamente. También controla las incoherencias que pueden surgir de consultar datos mientras se ejecuta una operación coherente con el tiempo.
Considere cómo las consultas buscan la partición correcta. Si una consulta debe examinar todas las particiones para localizar los datos necesarios, hay un impacto significativo en el rendimiento, incluso cuando se ejecutan varias consultas paralelas. Con la creación de particiones verticales y funcionales, las consultas pueden especificar de forma natural la partición. La creación de particiones horizontales, por otro lado, puede dificultar la localización de un elemento, ya que cada partición tiene el mismo esquema. Una solución típica para mantener un mapa que se usa para buscar la ubicación de partición de elementos específicos. Este mapa se puede implementar en la lógica de particionamiento de la aplicación o mantenerla en el almacén de datos si admite particionamiento transparente.
Considere la posibilidad de reequilibrar periódicamente las particiones. Con la creación de particiones horizontales, las particiones de reequilibrio pueden ayudar a distribuir los datos uniformemente por tamaño y por carga de trabajo para minimizar las zonas activas, maximizar el rendimiento de las consultas y solucionar las limitaciones de almacenamiento físico. Sin embargo, se trata de una tarea compleja que a menudo requiere el uso de una herramienta o proceso personalizados.
Replicar particiones. Si replica cada partición, proporciona protección adicional contra errores. Si se produce un error en una sola réplica, las consultas se pueden dirigir a una copia en funcionamiento.
Si alcanza los límites físicos de una estrategia de creación de particiones, es posible que tenga que ampliar la escalabilidad a un nivel diferente. Por ejemplo, si la creación de particiones está en el nivel de base de datos, es posible que tenga que buscar o replicar particiones en varias bases de datos. Si la creación de particiones ya está en el nivel de base de datos y las limitaciones físicas son un problema, es posible que tenga que buscar o replicar particiones en varias cuentas de hospedaje.
Evite transacciones que accedan a datos en varias particiones. Algunos almacenes de datos implementan coherencia y integridad transaccional para las operaciones que modifican los datos, pero solo cuando los datos se encuentran en una sola partición. Si necesita compatibilidad transaccional en varias particiones, es probable que tenga que implementarlo como parte de la lógica de la aplicación, ya que la mayoría de los sistemas de creación de particiones no proporcionan compatibilidad nativa.
Todos los almacenes de datos requieren cierta actividad de supervisión y administración operativa. Las tareas pueden variar desde la carga de datos, la copia de seguridad y la restauración de datos, la reorganización de los datos y la garantía de que el sistema funciona correctamente y de forma eficaz.
Tenga en cuenta los siguientes factores que afectan a la administración operativa:
Cómo implementar las tareas operativas y de administración adecuadas cuando se crean particiones de los datos. Estas tareas pueden incluir copias de seguridad y restauración, archivar datos, supervisar el sistema y otras tareas administrativas. Por ejemplo, mantener la coherencia lógica durante las operaciones de copia de seguridad y restauración puede ser un desafío.
Cómo cargar los datos en varias particiones y agregar nuevos datos que llegan desde otros orígenes. Es posible que algunas herramientas y utilidades no admitan operaciones de datos particionadas, como cargar datos en la partición correcta.
Cómo archivar y eliminar los datos de forma periódica. Para evitar el crecimiento excesivo de las particiones, debe archivar y eliminar datos periódicamente (por ejemplo, mensualmente). Es posible que sea necesario transformar los datos para que coincidan con un esquema de archivo diferente.
Cómo localizar problemas de integridad de datos. Considere la posibilidad de ejecutar un proceso periódico para localizar cualquier problema de integridad de datos, como los datos de una partición que hace referencia a la información que falta en otra. El proceso puede intentar corregir estos problemas automáticamente o generar un informe para su revisión manual.
Reequilibrar particiones
A medida que un sistema madura, es posible que tenga que ajustar el esquema de creación de particiones. Por ejemplo, las particiones individuales pueden empezar a obtener un volumen desproporcionada de tráfico y convertirse en frecuente, lo que conduce a una contención excesiva. O bien, es posible que haya subestimado el volumen de datos en algunas particiones, lo que hace que algunas particiones se acerquen a los límites de capacidad.
Algunos almacenes de datos, como Azure Cosmos DB, pueden reequilibrar automáticamente las particiones. En otros casos, el reequilibrio es una tarea administrativa que consta de dos fases:
Determine una nueva estrategia de creación de particiones.
- ¿Qué particiones deben dividirse (o posiblemente combinarse)?
- ¿Cuál es la nueva clave de partición?
Migre datos del esquema de partición anterior al nuevo conjunto de particiones.
En función del almacén de datos, es posible que pueda migrar datos entre particiones mientras están en uso. Esto se denomina migración en línea. Si no es posible, es posible que tenga que hacer que las particiones no estén disponibles mientras se reubican los datos (migración sin conexión).
Migración sin conexión
La migración sin conexión suele ser más sencilla porque reduce las posibilidades de contención. Conceptualmente, la migración sin conexión funciona de la siguiente manera:
- Marque la partición sin conexión.
- Dividir y mover los datos a las nuevas particiones.
- Comprobar los datos.
- Ponga las nuevas particiones en línea.
- Quite la partición antigua.
Opcionalmente, puede marcar una partición como de solo lectura en el paso 1 para que las aplicaciones puedan seguir leyendo los datos mientras se mueve.
Migración en línea
La migración en línea es más compleja para realizar, pero menos perjudicial. El proceso es similar a la migración sin conexión, excepto que la partición original no está marcada como sin conexión. Según la granularidad del proceso de migración (por ejemplo, elemento por elemento frente a partición por partición), es posible que el código de acceso a datos de las aplicaciones cliente tenga que controlar la lectura y escritura de datos que se mantienen en dos ubicaciones, la partición original y la nueva partición.
Pasos siguientes
- Obtenga información sobre las estrategias de creación de particiones para servicios específicos de Azure. Para más información, consulte Estrategias de creación de particiones de datos.
- Objetivos de escalabilidad y rendimiento de Azure Storage
Recursos relacionados
Los siguientes patrones de diseño pueden ser relevantes para su escenario:
El patrón de particionamiento describe algunas estrategias comunes para particionar datos.
El patrón de tabla de índice muestra cómo crear índices secundarios a través de datos. Una aplicación puede recuperar rápidamente datos con este enfoque mediante consultas que no hacen referencia a la clave principal de una colección.
El patrón de vista materializado describe cómo generar vistas rellenadas previamente que resumen los datos para admitir operaciones de consulta rápidas. Este enfoque puede ser útil en un almacén de datos con particiones si las particiones que contienen los datos que se resumen se distribuyen entre varios sitios.