Las aplicaciones distribuidas y los servicios que se ejecutan en la nube son, por naturaleza, complejos fragmentos de software que se componen de muchas partes móviles. En un entorno de producción, es importante poder controlar la forma en que los usuarios usan el sistema, realizan un seguimiento del uso de recursos, y supervisan en general el estado y el rendimiento del sistema. Esta información se puede usar como herramienta de diagnóstico para detectar y corregir problemas y para ayudar a detectarlos antes de que se produzcan.
Escenarios de supervisión y diagnósticos
Puede usar la supervisión para obtener información detallada sobre cómo funciona un sistema. La supervisión es una parte fundamental en el mantenimiento de los objetivos de calidad de servicio. La recopilación de datos de supervisión puede usarse en las siguientes situaciones:
- Garantizar que el sistema esté en buen estado.
- Realizar un seguimiento de la disponibilidad del sistema y sus elementos componentes.
- Mantener el rendimiento para garantizar que el procesamiento del sistema no se degrada inesperadamente a medida que el volumen de trabajo aumenta.
- Garantizar que el sistema satisface los contratos de nivel de servicio (SLA) establecidos con los clientes.
- Proteger la privacidad y la seguridad del sistema, los usuarios y sus datos.
- Realizar un seguimiento de las operaciones que se llevan a cabo como auditoría para fines normativos.
- Supervisar el uso diario del sistema e identificar las tendencias que podrían conducir a problemas a fin de actuar con anticipación.
- Realizar un seguimiento de los problemas que se producen, desde el informe inicial al análisis de las causas posibles, su rectificación, las actualizaciones de software pertinentes y la implementación.
- Realizar un seguimiento de las operaciones y depurar las versiones de software.
Nota
Esta lista no pretende ser exhaustiva. Este documento se centra en estos escenarios, en cuanto que son las situaciones más comunes para la ejecución de la supervisión. Puede haber otros menos comunes o que sean específicos de su entorno.
En las siguientes secciones se describen estas configuraciones con más detalle. La información para cada escenario se describe en el siguiente formato:
- Una breve descripción del escenario.
- Los requisitos típicos de este escenario.
- Los datos de instrumentación sin procesar necesarios para permitir el escenario y los posibles orígenes de esta información.
- Cómo pueden analizarse y combinarse estos datos sin procesar para generar información de diagnóstico significativa.
Supervisión del estado
Un sistema es correcto si está en funcionamiento y es capaz de procesar solicitudes. El propósito del seguimiento de estado es generar una instantánea del estado actual del sistema que le permita comprobar que todos los componentes del sistema funcionan según lo previsto.
Requisitos para la supervisión del estado
Un operador debe recibir una alerta rápidamente (en cuestión de segundos) si se considera que cualquier parte del sistema tiene un estado incorrecto. El operador debe ser capaz de determinar las partes del sistema que funcionan con normalidad y las partes que tienen problemas. El mantenimiento del sistema se puede señalizar mediante el uso de un semáforo:
- Rojo para incorrecto (se ha detenido el sistema)
- Amarillo para parcialmente correcto (el sistema se ejecuta con funcionalidad reducida)
- Verde para completamente correcto
Un completo sistema de supervisión del estado permite que un operador explore en profundidad el sistema para ver el estado de los subsistemas y componentes. Por ejemplo, si el sistema global se representa como parcialmente correcto, el operador debe ser capaz de profundizar y determinar la funcionalidad que no está disponible actualmente.
Requisitos de recopilación de datos, instrumentación y orígenes de datos
Los datos sin procesar necesarios para permitir el seguimiento de estado pueden generarse como resultado de:
- El seguimiento de la ejecución de las solicitudes de los usuarios. Esta información puede usarse para determinar las solicitudes que se realizaron correctamente, las que produjeron un error y cuánto tiempo tarda cada solicitud.
- Supervisión de usuarios sintéticos. Este proceso simula los pasos que realiza un usuario y sigue una serie predefinida de pasos. Se deben capturar los resultados de cada paso.
- El registro de excepciones, errores y advertencias. Esta información se puede capturar como resultado de las instrucciones de seguimiento insertadas en el código de la aplicación, o mediante la recuperación de información de los registros de eventos de cualquier servicio al que el sistema haga referencia.
- Seguimiento del estado de los servicios de terceros que usa el sistema. Este seguimiento podría requerir la supervisión y el análisis de los datos de mantenimiento que suministran estos servicios. Esta información puede adoptar diversos formatos.
- Supervisión de extremos. Este mecanismo se describe con más detalle en la sección Supervisión de la disponibilidad.
- Recopilación de la información de rendimiento del ambiente, como el uso de la CPU en segundo plano o la actividad de E/S (incluida la red).
Análisis de los datos de estado
El objetivo principal de la supervisión del estado es indicar rápidamente si el sistema está en ejecución. El análisis en caliente de los datos inmediatos puede desencadenar una alerta si un componente crítico se detecta como incorrecto. (Por ejemplo, no puede responder a una serie consecutiva de pings). El operador puede entonces tomar la acción correctiva apropiada.
Un sistema más avanzado podría incluir un elemento predictivo que realiza un análisis en frío de las cargas de trabajo actuales y recientes. Un análisis en frío puede detectar tendencias y determinar la probabilidad de que el sistema se mantenga en buen estado o de que necesite recursos adicionales. Este elemento predictivo debe basarse en métricas de rendimiento críticas, como por ejemplo:
- La tasa de solicitudes dirigidas en cada servicio o subsistema.
- Los tiempos de respuesta de estas solicitudes.
- El volumen de datos que fluyen dentro y fuera de cada servicio.
Si el valor de cualquier métrica supera un umbral definido, el sistema puede generar una alerta para avisar a un operador o escalarse automáticamente (si esta opción está disponible) con el fin de realizar las acciones preventivas necesarias para mantener el estado del sistema. Estas acciones pueden implicar que se agreguen recursos, se reinicie uno o varios servicios que no funcionen correctamente o se aplique una limitación a las solicitudes de menor prioridad.
Supervisión de la disponibilidad
Un sistema con un estado verdaderamente correcto requiere que los componentes y los subsistemas que lo constituyen estén disponibles. La supervisión de la disponibilidad está estrechamente relacionada con el seguimiento de estado. Mientras que el seguimiento de estado proporciona una vista inmediata del estado actual del sistema, la supervisión de la disponibilidad se ocupa de realizar un seguimiento de la disponibilidad del sistema y sus componentes para generar estadísticas sobre el tiempo de actividad del sistema.
En muchos sistemas, algunos componentes (por ejemplo, una base de datos) se configuran con redundancia integrada para permitir una rápida conmutación por error si se produce un error grave o una pérdida de conectividad. Lo ideal es que los usuarios no sean conscientes de que se ha producido un error de este tipo. Pero desde una perspectiva de la supervisión de disponibilidad, es necesario recopilar toda la información posible sobre estos errores para determinar la causa y adoptar las medidas necesarias para evitar que se repita.
Los datos que se necesitan para realizar un seguimiento de la disponibilidad podrían depender de una serie de factores de nivel inferior. Muchos de estos factores podrían ser específicos de la aplicación, el sistema y el entorno. Un sistema de supervisión eficaz captura los datos de disponibilidad que corresponden a esos factores de bajo nivel y, después, los agrupa para ofrecer una visión general del sistema. Por ejemplo, en un sistema de comercio electrónico, la funcionalidad empresarial que permite que un cliente realice pedidos puede depender del repositorio en que se almacenan los detalles del pedido y del sistema de pago que controla las transacciones monetarias para pagar dichos pedidos. La disponibilidad de la parte de realización de pedidos del sistema es, por tanto, una función de la disponibilidad del repositorio y del subsistema de pago.
Requisitos para la supervisión de la disponibilidad
Un operador también debería poder ver el histórico de disponibilidad de cada sistema y subsistema y usar esta información para identificar las tendencias que podrían ocasionar errores periódicos en uno o varios subsistemas. (¿Los servicios comienzan a dar problemas a una determinada hora del día que corresponde a las horas de procesamiento máximo?)
Una solución de supervisión debe proporcionar una vista inmediata e histórica de la disponibilidad o no disponibilidad de cada subsistema. También debe ser capaz de alertar rápidamente a un operador cuando uno o más servicios produzcan errores o cuando los usuarios no pueden conectarse a los servicios. No es solo cuestión de supervisar cada servicio, sino también de examinar las acciones que los usuarios realizan si estas acciones producen un error al intentar comunicarse con un servicio. En cierta medida, un cierto grado de error en la conectividad es normal y podría deberse a errores transitorios. Pero podría ser útil permitir que el sistema genere una alerta por el número de errores de conectividad en un subsistema especificado que se produzcan durante un período determinado.
Requisitos de recopilación de datos, instrumentación y orígenes de datos
Al igual que con el seguimiento de estado, los datos sin procesar necesarios para permitir la supervisión de la disponibilidad pueden generarse como resultado de la supervisión de usuarios sintéticos y el registro de las excepciones, los errores y las advertencias que puedan producirse. Además, los datos de la disponibilidad se pueden obtener de la supervisión de los extremos. La aplicación puede exponer uno o más extremos de estado, cada uno de los cuales realiza pruebas de acceso a un área funcional dentro del sistema. El sistema de supervisión puede hacer ping a cada punto de conexión siguiendo una programación definida y recopilar los resultados (acierto o error).
Se deben registrar todos los tiempos de espera, los errores de conectividad de red y los reintentos de conexión. Todos los datos deben tener marca de tiempo.
Análisis de los datos de disponibilidad
Los datos de instrumentación se deben agregar y realizarse una correlación para admitir los siguientes tipos de análisis:
- La disponibilidad inmediata del sistema y los subsistemas.
- Las tasas de error de disponibilidad del sistema y los subsistemas. Lo ideal sería que el operador pudiera correlacionar los errores con actividades específicas; ¿qué ocurría cuando se produjo el error en el sistema?
- Una vista histórica de las frecuencias de errores del sistema o los subsistemas en cualquier período de tiempo especificado y la carga del sistema (por ejemplo, el número de solicitudes de usuario) cuando se produjo un error.
- Las razones de falta de disponibilidad del sistema o los subsistemas. Por ejemplo, el servicio no se está ejecutando, se ha perdido la conectividad, el servicio está conectado pero se ha agotado el tiempo de espera y el servicio está conectado pero se devuelven errores.
Puede calcular el porcentaje de disponibilidad de un servicio en un período de tiempo con la siguiente fórmula:
%Availability = ((Total Time – Total Downtime) / Total Time ) * 100
Esto resulta de utilidad de cara al SLA. (La supervisión del SLA se describe con más detalle más adelante en esta guía). La definición de tiempo de inactividad depende del servicio. Por ejemplo, el servicio de compilación de Visual Studio Team Services define el tiempo de inactividad como el período (minutos acumulados totales) durante el cual el servicio de compilación está disponible. Se considera que no hay disponibilidad durante un minuto si todas las solicitudes HTTP continuas que recibe el servicio de compilación para realizar operaciones iniciadas por el cliente a lo largo del minuto dan lugar a un código de error o no devuelven ninguna respuesta.
Supervisión de rendimiento
A medida que el sistema se somete a condiciones de carga cada vez mayores (a medida que el volumen de usuarios incrementa) y el tamaño de los conjuntos de datos a los que tienen acceso estos usuarios crece, la probabilidad de error de uno o varios componentes es cada vez mayor. Con frecuencia, el error de componentes está precedido por una disminución del rendimiento. Si puede detectar esa disminución, puede tomar medidas proactivas para remediar la situación.
El rendimiento del sistema depende de varios factores. Cada factor se mide normalmente mediante indicadores clave de rendimiento (KPI), como el número de transacciones de la base de datos por segundo o el volumen de solicitudes de red que se atienden correctamente en un período de tiempo determinado. Algunos de estos KPI pueden estar disponibles como medidas de rendimiento específicas, mientras que otros pueden derivarse de una combinación de métricas.
Nota
La determinación de un buen o mal rendimiento requiere que comprenda el nivel de rendimiento al que el sistema debería ser capaz de funcionar. Para ello es necesario observar el sistema mientras está funcionando bajo una carga típica y capturar los datos de cada KPI durante un período de tiempo. Esto puede implicar tener que ejecutar el sistema bajo una carga simulada en un entorno de pruebas y recopilar los datos apropiados antes de implementar el sistema en un entorno de producción.
También debe asegurarse de que la supervisión del rendimiento no se convierta en una carga injustificada para el sistema. Es posible que pueda ajustar dinámicamente el nivel de detalle de los datos que recopila el proceso de supervisión del rendimiento.
Requisitos de la supervisión del rendimiento
Para examinar el rendimiento del sistema, un operador normalmente necesitaría ver cierta información, entre la que se incluye:
- Las tasas de respuesta de las solicitudes de usuario.
- El número de solicitudes de usuario simultáneas.
- El volumen de tráfico de la red.
- Las tasas a las que se completan las transacciones de negocios.
- El tiempo medio de procesamiento de solicitudes.
También puede ser útil ofrecer herramientas que permitan que un operador ayude a identificar correlaciones, como por ejemplo:
- El número de usuarios simultáneos frente a los tiempos de latencia de las solicitudes (cuánto se tarda en iniciar el procesamiento de una solicitud después de que el usuario la haya enviado).
- El número de usuarios simultáneos frente al tiempo de respuesta medio (cuánto se tarda en completar una solicitud después de que haya comenzado a procesarse).
- El volumen de solicitudes frente al número de errores de procesamiento.
Además de esta información funcional de alto nivel, un operador también debería poder obtener una vista detallada del rendimiento de cada componente del sistema. Estos datos normalmente se suministran mediante el uso de información de seguimiento de contadores de rendimiento de bajo nivel, como:
- El uso de memoria;
- el número de subprocesos;
- el tiempo de procesamiento de la CPU;
- la longitud de la cola de solicitudes;
- los errores y las tasas de E/S de las redes y los discos;
- el número de bytes escritos o leídos;
- los indicadores de software intermedio, como la longitud de la cola.
Todas las visualizaciones deben permitir que un operador especifique un período de tiempo. Los datos mostrados pueden ser una instantánea de la situación actual o una vista histórica del rendimiento.
Un operador debe ser capaz de generar una alerta en función de una medida de rendimiento de un valor especificado durante un intervalo de tiempo especificado.
Requisitos de recopilación de datos, instrumentación y orígenes de datos
Puede recopilar datos de rendimiento de alto nivel (capacidad de proceso, número de usuarios simultáneos, número de transacciones de negocio, tasas de error, etc.) mediante la supervisión del progreso de las solicitudes de los usuarios cuando llegan y pasan por el sistema. Esto implica la incorporación de instrucciones de seguimiento en puntos clave del código de la aplicación junto con información de tiempo. Todos los errores, excepciones y advertencias deben capturarse con datos suficientes para que puedan correlacionarse con las solicitudes que los provocaron. El registro de Internet Information Services (IIS) es otro origen útil.
Si es posible, también debería capturar datos de rendimiento de los sistemas externos que use la aplicación. Estos sistemas externos podrían proporcionar sus propios contadores de rendimiento u otras características para solicitar datos de rendimiento. Si esto no es posible, registre la información como la horas de inicio y finalización de cada solicitud realizada a un sistema externo, junto con el estado (correcto, error o advertencia) de la operación. Por ejemplo, puede aplicar un enfoque de cronómetro a las solicitudes de tiempo; inicie un temporizador cuando se inicie la solicitud y deténgalo cuando la solicitud se complete.
Los datos de rendimiento de bajo nivel de los componentes individuales en un sistema pueden estar disponibles mediante características y servicios, por ejemplo, contadores de rendimiento de Windows y Diagnósticos de Azure.
Análisis de los datos de rendimiento
Gran parte del trabajo de análisis consiste en agregar los datos de rendimiento por el tipo de solicitud de usuario o el subsistema o servicio al que se envía cada solicitud. Un ejemplo de una solicitud de usuario es agregar un artículo al carro de la compra o realizar el proceso de pago en un sistema de comercio electrónico.
Otro requisito común es resumir los datos de rendimiento en percentiles seleccionados. Por ejemplo, un operador puede determinar los tiempos de respuesta del 99, el 95 y el 70 por ciento de las solicitudes. Puede que haya objetivos de SLA o de otro tipo establecidos para cada percentil. Los resultados en curso se deben notificar casi en tiempo real para ayudar a detectar problemas inmediatos. Los resultados también deben juntarse durante períodos más largos con fines estadísticos.
En caso de que el rendimiento se vea afectado por problemas de latencia, un operador debería ser capaz de identificar rápidamente la causa del cuello de botella mediante el examen de la latencia de cada paso que cada solicitud realiza. Por tanto, los datos de rendimiento deben ofrecer una forma de realizar una correlación de las medidas de rendimiento de cada paso para vincularlas a una solicitud concreta.
Según los requisitos de visualización, podría ser útil generar y almacenar un cubo de datos que contenga vistas de los datos sin procesar. Este cubo de datos puede permitir consultas ad hoc complejas y análisis de la información del rendimiento.
Supervisión de la seguridad
Todos los sistemas comerciales que incluyen datos confidenciales deben implementar una estructura de seguridad. Normalmente, la complejidad del mecanismo de seguridad depende de la confidencialidad de los datos. En un sistema que requiere que los usuarios se autentiquen, debe registrar:
- Todos los intentos de inicio de sesión, tanto si han tenido éxito como si no.
- Todas las operaciones que realiza un usuario autenticado, así como los detalles de todos los recursos a los que este accede.
- Cuando un usuario finaliza una sesión y la cierra.
La supervisión podría ayudar a detectar ataques en el sistema. Por ejemplo, un gran número de intentos de inicio de sesión erróneos puede indicar un ataque por fuerza bruta. Un aumento inesperado de las solicitudes podría ser el resultado de un ataque de denegación de servicio (DDoS) distribuido. Debe estar preparado para supervisar todas las solicitudes a todos los recursos con independencia del origen de estas solicitudes. Un sistema que tenga una vulnerabilidad en el inicio de sesión podría exponer por accidente recursos al mundo exterior sin necesidad de que un usuario inicie sesión realmente.
Requisitos para la supervisión de la seguridad
Los aspectos más críticos de la supervisión de la seguridad deberían permitir que un operador realizara las siguientes operaciones con rapidez:
- Detectar intentos de intrusión de una entidad no autenticada.
- Identificar intentos de entidades que quieren realizar operaciones en datos a los que no se les ha concedido acceso.
- Determinar si el sistema, o alguna de sus partes, está sufriendo un ataque desde fuera o dentro. (Por ejemplo, un usuario autenticado malintencionado podría estar intentando acabar con el sistema).
Para admitir estos requisitos, se debe notificar a un operador:
- Si una cuenta realiza repetidamente intentos de inicio de sesión erróneos dentro de un período especificado.
- Si una cuenta autenticada intenta repetidamente acceder a un recurso prohibido durante un período de tiempo especificado.
- Si se produce un gran número de solicitudes no autenticadas o no autorizadas durante un período de tiempo especificado.
La información facilitada a un operador debe incluir la dirección del host del origen de cada solicitud. Si las infracciones de seguridad provienen con regularidad de un determinado intervalo de direcciones, podrían bloquearse estos hosts.
Una parte clave del mantenimiento de la seguridad de un sistema es poder detectar rápidamente las acciones que se desvíen del patrón habitual. La información, como el número de solicitudes de inicio de sesión aceptadas o rechazadas, se puede mostrar de forma visual para detectar si se ha producido un pico de actividad a una hora inusual. (Por ejemplo, los usuarios que inician sesión a las 3 a.m. y que realizan un gran número de operaciones cuando su día laborable comienza a las 9 a.m.). Esta información también puede utilizarse para ayudar a configurar el escalado automático basado en el tiempo. Por ejemplo, si un operador observa que un gran número de usuarios normalmente inician sesión en un momento determinado del día, el operador puede organizarse para iniciar servicios de autenticación adicionales y así controlar el volumen de trabajo y, más tarde, reducir esos servicios adicionales cuando haya pasado el pico.
Requisitos de recopilación de datos, instrumentación y orígenes de datos
La seguridad es un aspecto global de la mayoría de los sistemas distribuidos. Es posible que los datos pertinentes se generen en varios puntos de un sistema. Considere la posibilidad de adoptar un enfoque de administración de eventos e información de seguridad (SIEM) para recopilar la información relacionada con la seguridad resultante de los eventos que han generado la aplicación, el equipo de red, los servidores, los firewalls, el software antivirus y otros elementos de prevención de intrusiones.
La supervisión de la seguridad puede incorporar datos de herramientas que no forman parte de la aplicación. Por ejemplo, herramientas que identifican actividades de exploración de puertos por organismos externos o filtros de red que detectan intentos de acceso no autenticado a la aplicación y los datos.
En todos los casos, los datos recopilados deben permitir que un administrador determine la naturaleza de cualquier ataque y adopte las medidas adecuadas.
Análisis de los datos de seguridad
Una característica de la supervisión de seguridad es la variedad de orígenes desde los que se generan los datos. Los distintos formatos y el nivel de detalle requieren a menudo un análisis complejo de los datos capturados para unirlos en una cadena de información coherente. Aparte del más sencillo de los casos (por ejemplo, la detección de un gran número de inicios de sesión erróneos o los intentos repetidos de obtener acceso no autorizado a recursos críticos), podría no ser posible realizar ningún procesamiento automatizado complejo de los datos de seguridad. En su lugar, podría ser preferible escribir estos datos, con marca de tiempo, pero en su formato original, en un repositorio seguro para permitir un análisis manual experto.
supervisión del SLA
Muchos sistemas comerciales que admiten a los clientes de pago ofrecen garantías sobre el rendimiento del sistema en forma de SLA. Básicamente, los SLA especifican que el sistema puede controlar un volumen de trabajo definido en un período de tiempo acordado sin perder la información crítica. La supervisión del SLA se encarga de garantizar que el sistema puede cumplir los SLA medibles.
Nota
La supervisión del SLA está estrechamente relacionada con la supervisión de rendimiento. Pero mientras que la supervisión del rendimiento se encarga de garantizar que el sistema funciona de manera óptima, la supervisión del SLA se rige por una obligación contractual que define lo que significa realmente óptimamente.
A menudo, los SLA se definen en términos de:
- Disponibilidad general del sistema. Por ejemplo, una organización puede garantizar que el sistema estará disponible el 99,9 por ciento del tiempo. Esto equivale a no más de 9 horas de tiempo de inactividad por año, o aproximadamente 10 minutos a la semana.
- Rendimiento operativo. Este aspecto se expresa a menudo como una o más marcas de límite superior, por ejemplo, la garantía de que el sistema tenga cabida para hasta 100 000 solicitudes de usuario simultáneas o controlar 10 000 transacciones de negocio simultáneas.
- Tiempo de respuesta operativa. El sistema también podría garantizar la velocidad a la que se procesan las solicitudes. Por ejemplo: el 99 por ciento de todas las transacciones de negocio finalizarán dentro de 2 segundos y ninguna transacción única tardará más de 10 segundos.
Nota
Algunos contratos de los sistemas comerciales pueden incluir también SLA para el soporte al cliente. Por ejemplo: todas las solicitudes de asistencia tendrán una respuesta en 5 minutos, y el 99 por ciento de todos los problemas se tratarán totalmente en un plazo de 1 día laborable. Un seguimiento de problemas eficaz (que se describe más adelante en esta sección) es crucial para cumplir SLA como estos.
Requisitos de la supervisión del estado
En el nivel más alto, un operador debe ser capaz de determinar de un vistazo si el sistema está cumpliendo los SLA acordados o no. Y si no, el operador debe ser capaz de explorar en profundidad y examinar los factores subyacentes para determinar las razones del rendimiento incorrecto.
Entre los indicadores de alto nivel más habituales que se pueden representar visualmente, se incluyen:
- El porcentaje de tiempo de actividad de servicio.
- El rendimiento de la aplicación (medido en cuanto a transacciones correctas u operaciones por segundo).
- El número de solicitudes correctas y erróneas de la aplicación.
- El número de errores, excepciones y advertencias de la aplicación y del sistema.
Todos estos indicadores deben poder filtrarse para un período de tiempo especificado.
Una aplicación en la nube probablemente constará de un número de componentes y subsistemas. Un operador debe ser capaz de seleccionar un indicador de alto nivel y ver cómo está compuesto por el estado de los elementos subyacentes. Por ejemplo, si el tiempo de inactividad del sistema global cae por debajo de un valor aceptable, un operador debe poder ver en profundidad y determinar qué elementos están contribuyendo a dicho error.
Nota
El tiempo de actividad del sistema debe definirse con cuidado. En un sistema que usa redundancia para garantizar la máxima disponibilidad, las instancias individuales de los elementos pueden producir un error, pero el sistema puede seguir siendo funcional. El tiempo de actividad del sistema tal y como lo presenta la supervisión del estado debe indicar el tiempo de actividad agregado de cada elemento y no necesariamente si el sistema realmente se detuvo. Además, los errores podrían aislarse. Por lo que incluso si un sistema concreto no está disponible, el resto del sistema puede permanecer disponible, aunque con funcionalidad reducida. (En un sistema de comercio electrónico, un error en el sistema podría impedir que un cliente realice pedidos, pero no que pueda examinar el catálogo de productos).
Para fines de alertas, el sistema debe ser capaz de generar un evento si cualquiera de los indicadores de alto nivel supera un umbral especificado. Los detalles de nivel inferior de los distintos factores que componen el indicador de alto nivel deben estar disponibles como datos contextuales para el sistema de alertas.
Requisitos de recopilación de datos, instrumentación y orígenes de datos
Los datos sin procesar necesarios para permitir la supervisión del SLA son similares a los que se necesitan para supervisar el rendimiento, junto con algunos aspectos de seguimiento de estado y supervisión de la disponibilidad. (Consulte esas secciones para obtener más detalles). Puede capturar estos datos mediante:
- La realización de supervisión de los extremos
- El registro de excepciones, errores y advertencias.
- El seguimiento de la ejecución de las solicitudes de usuario.
- La supervisión de la disponibilidad de los servicios de terceros que usa el sistema.
- El uso de contadores y métricas de rendimiento.
Todos los datos deben medirse en tiempo y disponer de una marca de tiempo.
Análisis de los datos de SLA
Los datos de instrumentación se deben agregar para generar una imagen del rendimiento general del sistema. Los datos agregados también deben permitir la exploración en profundidad para hacer posible el examen del rendimiento de los subsistemas subyacentes. Por ejemplo, debe ser capaz de:
- Calcular el número total de solicitudes de usuario durante un período determinado y determinar la tasa de solicitudes correctas y erróneas.
- Combinar los tiempos de respuesta de las solicitudes de usuario para generar una vista general de los tiempos de respuesta del sistema.
- Analizar el progreso de la interrupción de las solicitudes de usuario cuando se descompone el tiempo de respuesta de una solicitud en los tiempos de respuesta de los elementos de trabajo individuales de esa solicitud.
- Determinar la disponibilidad general del sistema como un porcentaje del tiempo de actividad durante un período concreto.
- Analizar el porcentaje del tiempo de disponibilidad de cada uno de los servicios y componentes individuales en el sistema. Esto podría implicar tener que analizar los registros que han generado servicios de terceros.
En muchos sistemas comerciales es necesario informar de las cifras de rendimiento reales con respecto a los SLA acordados durante un período especificado, normalmente un mes. Esta información se puede usar para calcular créditos u otras formas de compensación para los clientes si no se cumplen los SLA durante ese período. Puede calcular la disponibilidad de un servicio mediante la técnica descrita en la sección Analyzing availability data(Análisis de los datos de disponibilidad).
Para fines internos, una organización también podría realizar un seguimiento del número y la naturaleza de los incidentes que produjeron un error en los servicios. Aprender a resolver estos problemas rápidamente o a eliminarlos por completo le ayudará a reducir el tiempo de inactividad y a cumplir los SLA.
Auditoría
Según la naturaleza de la aplicación, puede haber normativas legales o reglamentarias que especifiquen los requisitos para la auditoría de las operaciones de los usuarios y el registro de todos los accesos a los datos. La auditoría puede proporcionar evidencia que vincule a los clientes con las solicitudes específicas. La ausencia de rechazo es un factor importante en muchos sistemas de comercio electrónico para ayudar a mantener la confianza entre un cliente y la organización responsable de la aplicación o el servicio.
Requisitos de la auditoría
Un analista debe poder realizar un seguimiento de la secuencia de operaciones de negocios que han llevado a cabo los usuarios, de forma que se puedan reconstruir las acciones de estos. Esto podría ser necesario simplemente como una cuestión de registro, o como parte de una investigación forense.
La información de auditoría es sumamente delicada. Probablemente incluya datos que identifiquen a los usuarios del sistema, junto con las tareas que realizan. Por este motivo, lo más habitual es que la información de auditoría adopte la forma de informes que solo están disponibles para los analistas de confianza en lugar de mediante un sistema interactivo que admita la exploración en profundidad de operaciones gráficas. Un analista debe ser capaz de generar una variedad de informes. Por ejemplo, informes que muestren las actividades de todos los usuarios que se producen durante un período de tiempo especificado, que detallen la cronología de actividad de un solo usuario o que indiquen la secuencia de operaciones realizadas en relación con uno o más recursos.
Requisitos de recopilación de datos, instrumentación y orígenes de datos
Los principales orígenes de información de auditoría pueden incluir:
- El sistema de seguridad que administra la autenticación de usuario.
- Los registros de seguimiento que registran la actividad del usuario.
- Los registros de seguridad que realizan el seguimiento de todas las solicitudes de red identificables y no identificables.
El formato de los datos de auditoría y la forma en que se almacenan pueden estar controlados por requisitos normativos. Por ejemplo, podría no ser posible limpiar los datos de ninguna manera. (Deben registrarse en su formato original). El acceso al repositorio donde se mantienen debe estar protegido para evitar alteraciones.
Análisis de los datos de auditoría
Un analista debe tener acceso a los datos sin procesar en su totalidad y en su forma original. Además del requisito de generar informes de auditoría comunes, es probable que las herramientas usadas para analizar estos datos sean especializadas y se mantengan de forma externa al sistema.
Supervisión del uso
La supervisión del uso realiza un seguimiento de cómo se utilizan las características y los componentes de una aplicación. Un operador puede usar los datos recopilados para:
Determinar las características que se utilizan mucho y las posibles zonas activas del sistema. Los elementos de tráfico elevado podrían beneficiarse del particionamiento funcional o incluso de la replicación para distribuir la carga de forma más uniforme. Un operador puede también usar esta información para determinar las características que se utilizan con poca frecuencia y que son posibles candidatas para retirarlas o sustituirlas en una versión futura del sistema.
Obtenga información sobre los eventos operativos del sistema con un uso normal. Por ejemplo, en un sitio de comercio electrónico podría registrar información estadística sobre el número de transacciones y el volumen de clientes que son responsables de las mismas. Esta información podría usarse para el planeamiento de la capacidad a medida que el número de clientes aumenta.
Detecte (posiblemente indirectamente) la satisfacción de los usuarios con el rendimiento o la funcionalidad del sistema. Por ejemplo, si un gran número de clientes de un sistema de comercio electrónico abandona con frecuencia sus carros de la compra, podría tratarse de un problema con la funcionalidad de finalización de la compra.
Genere información de facturación. Una aplicación comercial o un servicio multiempresa podrían cobrar a los clientes por los recursos que usan.
Aplique cuotas. Si un usuario de un sistema multiempresa supera la cuota de pago sobre el uso de recursos o el tiempo de procesamiento durante un período concreto, se puede limitar su acceso o el procesamiento.
Requisitos de la supervisión del uso
Para examinar el uso del sistema, un operador normalmente necesita ver cierta información, entre la que se incluye:
- El número de solicitudes que procesa cada subsistema y que se dirige a cada recurso.
- El trabajo que realiza cada usuario.
- El volumen de almacenamiento de datos que ocupa cada usuario.
- Los recursos a los que tiene acceso cada usuario.
Un operador también debe ser capaz de generar gráficos. Por ejemplo, un gráfico podría mostrar los usuarios que necesitan más recursos o los recursos o las características del sistema a los que se accede con mayor frecuencia.
Requisitos de recopilación de datos, instrumentación y orígenes de datos
El seguimiento del uso se puede realizar en un nivel relativamente alto. Se pueden anotar los tiempos de inicio y finalización de cada solicitud y la naturaleza de la solicitud (lectura, escritura, etc., según el recurso en cuestión). Puede obtener esta información mediante:
- El seguimiento de la actividad de usuario.
- La captura de los contadores de rendimiento que miden la utilización de cada recurso.
- La supervisión del consumo de recursos por cada usuario.
Con fines de medición, también debe ser capaz de identificar qué usuarios son responsables de realizar qué operaciones y los recursos que estas utilizan. La información recopilada debe ser lo suficientemente detallada para permitir una facturación precisa.
seguimiento de problemas
Los clientes y otros usuarios podrían informar de problemas si se producen eventos o comportamientos inesperados en el sistema. El seguimiento de problemas se ocupa de administrar estos problemas, los asocia a esfuerzos para resolver cualquier problema subyacente del sistema e informa a los clientes de las posibles soluciones.
Requisitos para el seguimiento de problemas
Los operadores realizan a menudo el seguimiento de problemas mediante un sistema independiente que les permite registrar e informar de los detalles de los problemas que los usuarios notifican. Estos detalles pueden incluir las tareas que el usuario estaba intentando llevar a cabo, los síntomas del problema, la secuencia de eventos y los mensajes de error o advertencia que se emitieron.
Requisitos de recopilación de datos, instrumentación y orígenes de datos
El origen inicial de los datos de seguimiento de problemas es el usuario que informa del problema en primer lugar. El usuario podría proporcionar datos adicionales, como:
- Un archivo de volcado (si la aplicación incluye un componente que se ejecuta en el escritorio del usuario).
- Una instantánea de la pantalla.
- La fecha y hora en que se produjo el error, junto con cualquier otra información del entorno, como la ubicación del usuario.
Esta información se puede utilizar para facilitar el esfuerzo de depuración y ayudar a construir un trabajo pendiente para versiones futuras del software.
Análisis de los datos de seguimiento de problemas
Es posible que diferentes usuarios notifiquen el mismo problema. El sistema de seguimiento de problemas debe asociar los informes comunes.
El progreso del esfuerzo de depuración se debe registrar en cada informe de problemas. Cuando se resuelva el problema, se puede informar al cliente de la solución.
Si un usuario informa de un problema que tiene una solución conocida en el sistema de seguimiento de problemas, el operador debería poder informar al usuario de la solución inmediatamente.
Seguimiento de las operaciones y depuración de las versiones de software
Cuando un usuario informa de un problema, a menudo solo es consciente del efecto inmediato que tiene en sus operaciones. El usuario solo puede notificar los resultados de su propia experiencia a un operador que es responsable de mantener el sistema. Estas experiencias normalmente son simplemente un síntoma visible de uno o más problemas fundamentales. En muchos casos, será necesario que un analista indague en la cronología de las operaciones subyacentes para establecer la causa raíz del problema. Este proceso se conoce como análisis de causa raíz.
Nota
El análisis de causa raíz podría revelar las ineficacias en el diseño de una aplicación. En estas situaciones, quizá sea posible modificar los elementos afectados e implementarlos como parte de una versión posterior. Este proceso requiere un control cuidadoso y los componentes actualizados deben supervisarse atentamente.
Requisitos para el seguimiento y la depuración
Para el seguimiento de eventos inesperados y otros problemas, es fundamental que los datos de supervisión proporcionen información suficiente para permitir que un analista haga un seguimiento hasta los orígenes de estos problemas y reconstruya la secuencia de eventos que se produjeron. Esta información debe ser suficiente para permitir que un analista diagnostique la causa raíz de los problemas. Luego, un programador puede realizar las modificaciones necesarias para evitar que se repitan.
Requisitos de recopilación de datos, instrumentación y orígenes de datos
La solución de problemas puede implicar tener que realizar un seguimiento de todos los métodos (y sus parámetros) que se invocan como parte de una operación, para crear un árbol que represente el flujo lógico a través del sistema cuando un cliente realiza una solicitud concreta. Se deben capturar y registrar las excepciones y advertencias que genera el sistema como resultado de este flujo.
Para hacer posible la depuración, el sistema puede proporcionar enlaces que permitan a un operador capturar información de estado en los puntos esenciales del sistema. O bien, el sistema puede ofrecer información detallada paso a paso a medida que progresan las operaciones seleccionadas. La captura de datos a este nivel de detalle puede imponer una carga adicional en el sistema y debería ser un proceso temporal. Un operador utiliza este proceso principalmente cuando se produce una serie de eventos muy poco habituales y es difícil de replicar, o cuando una nueva versión de uno o más elementos de un sistema requiere una cuidadosa supervisión para asegurarse de que los elementos funcionan según lo esperado.
La canalización de supervisión y diagnósticos
La supervisión de un sistema distribuido a gran escala plantea un desafío importante. Cada uno de los escenarios descritos en la sección anterior no se deben considerar necesariamente de forma aislada. Es probable que sea una superposición significativa en los datos de supervisión y diagnóstico necesarios para cada situación, aunque es posible que estos datos deban procesarse y presentarse de maneras distintas. Por estas razones, debe tener una vista holística de la supervisión y los diagnósticos.
Puede prever el proceso completo de diagnósticos y supervisión como una canalización que comprende las fases que se muestran en la Ilustración 1.
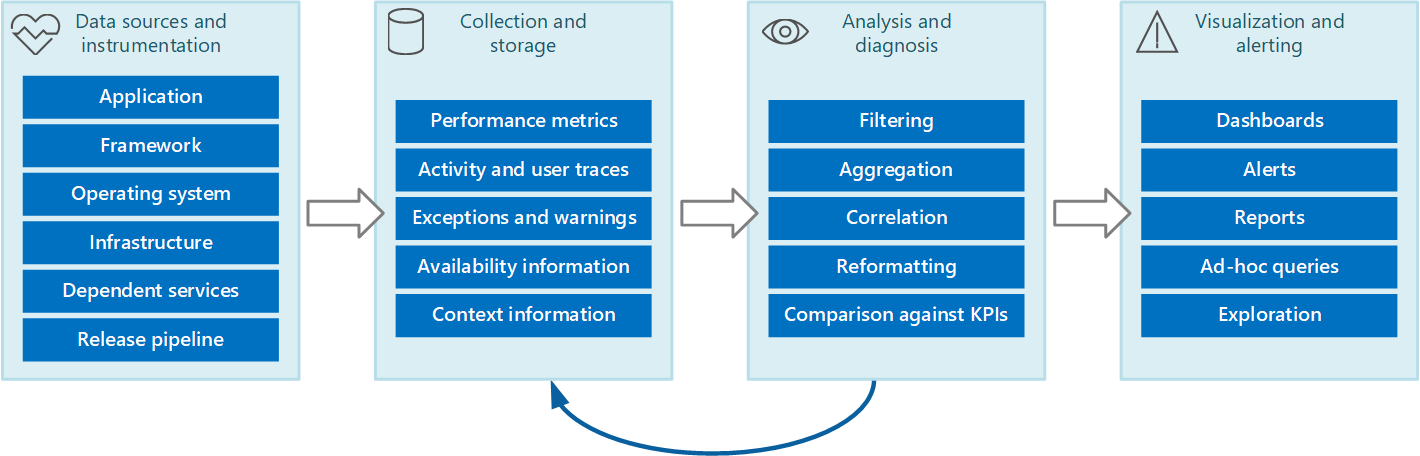
Ilustración 1: Las etapas de la canalización de supervisión y diagnóstico.
En la Ilustración 1 se muestra cómo los datos de supervisión y diagnósticos pueden proceder de diversos orígenes de datos. Las fases de instrumentación y recopilación tienen que ver con la identificación de los orígenes desde los que se deben capturar los datos, la determinación de qué datos capturar, cómo hacerlo y cómo dar formato a estos datos para que puedan examinarse fácilmente. La fase de análisis y diagnóstico toma los datos sin procesar y los usa para generar información significativa que un operador puede utilizar para determinar el estado del sistema. El operador puede utilizar esta información para tomar decisiones sobre las posibles acciones que se deben realizar y luego transmitir los resultados en las fases de instrumentación y recopilación. La fase de visualización y alerta presenta una vista consumible del estado del sistema. Se puede mostrar información casi en tiempo real mediante una serie de paneles. Y se pueden generar informes y gráficos para ofrecer una vista histórica de los datos que puede ayudar a identificar tendencias a largo plazo. Si la información indica la probabilidad de que un KPI no supere los límites aceptables, esta fase también puede desencadenar una alerta en un operador. En algunos casos, una alerta también puede usarse para desencadenar un proceso automatizado que intenta realizar acciones correctivas, como el escalado automático.
Tenga en cuenta que estos pasos constituyen un proceso de flujo continuo en el que las fases se producen en paralelo. Lo ideal sería que todas las fases se pudieran configurar de forma dinámica. En algunos puntos, especialmente cuando un sistema se ha implementado recientemente o está experimentando problemas, puede ser necesario recopilar datos extendidos con más frecuencia. En otras ocasiones, se debería poder volver a capturar un nivel básico de información esencial para comprobar que el sistema funciona correctamente.
Además, todo el proceso de supervisión debe considerarse una solución continuada dinámica, que está sujeta a mejoras y ajustes como resultado de los comentarios. Por ejemplo, puede comenzar con la medición de muchos factores para determinar el estado del sistema. Los análisis con el paso del tiempo podrían dar lugar a un refinamiento, dado que se descartan las medidas que no son pertinentes, lo que le permite centrarse con una mayor precisión en los datos que necesita y reducir el ruido de fondo.
Orígenes de los datos de supervisión y diagnóstico
La información que usa el proceso de supervisión puede proceder de varios orígenes, como se ilustra en la Figura 1. En el nivel de aplicación, información procede de los registros de seguimiento incorporados en el código del sistema. Los desarrolladores deben seguir un enfoque estándar hacia el seguimiento del flujo de control a través de su código. Por ejemplo, una entrada a un método puede emitir un mensaje de seguimiento que especifica el nombre del método, la hora actual, el valor de cada parámetro y cualquier otra información pertinente. El registro de las horas de entrada y salida también puede resultar útil.
Debe registrar todas las excepciones y advertencias y asegurarse de mantener un seguimiento completo de las advertencias y excepciones anidadas. Lo ideal sería también capturar la información que identifica al usuario que ejecuta el código, junto con la información de correlación de actividad (para realizar un seguimiento de las solicitudes a medida que pasan por el sistema). Y se deben registrar los intentos de acceso a todos los recursos, como colas de mensajes, bases de datos, archivos y otros servicios dependientes. Esta información puede utilizarse con fines de medición y auditoría.
Muchas aplicaciones usan bibliotecas y marcos para realizar tareas comunes como acceder a un almacén de datos o comunicarse a través de una red. Estos marcos pueden ser configurables para proporcionar sus propios mensajes de seguimiento e información de diagnóstico sin procesar, como las tasas de transacciones y las transmisiones de datos aceptadas y rechazadas.
Nota
Muchos marcos modernos publican automáticamente eventos de rendimiento y seguimiento. Capturar esta información es simplemente cuestión de ofrecer un medio para recuperarla y almacenarla donde se pueda procesar y analizar.
El sistema operativo donde se ejecuta la aplicación puede ser un origen de información de bajo nivel aplicable a todo el sistema, como los contadores de rendimiento que indican las tasas de E/S, la utilización de memoria y el uso de CPU. También se pueden notificar los errores del sistema operativo (por ejemplo, el error al abrir un archivo).
También debe considerar la infraestructura y los componentes subyacentes en los que se ejecuta el sistema. Las máquinas virtuales, las redes virtuales y los servicios de almacenamiento pueden ser orígenes de importantes contadores de rendimiento de nivel de infraestructura y otros datos de diagnóstico.
Si la aplicación usa otros servicios externos, como un servidor web o un sistema de administración de bases de datos, estos servicios pueden publicar sus propios registros, contadores de rendimiento e información de seguimiento. Algunos ejemplos son las vistas de administración dinámica de SQL Server para realizar un seguimiento de las operaciones llevadas a cabo en una base de datos SQL Server y los registros de seguimiento de Internet Information Server para registrar las solicitudes realizadas en un servidor web.
Como los componentes de un sistema se modifican y se implementan nuevas versiones, es importante poder atribuir problemas, eventos y métricas a cada versión. Esta información debe asociarse a la canalización de la versión para que se pueda hacer un rápido seguimiento de los problemas con una versión concreta de un componente y se rectifiquen.
Los problemas de seguridad pueden producirse en cualquier punto del sistema. Por ejemplo, un usuario podría intentar iniciar sesión con un id. de usuario o una contraseña no válidos. Un usuario autenticado podría intentar obtener acceso no autorizado a un recurso. O bien, un usuario podría proporcionar una clave no válida o caducada para tener acceso a información cifrada. Siempre se debe registrar la información relacionada con la seguridad de las solicitudes correctas y erróneas.
La sección Instrumentación de una aplicación contiene más indicaciones sobre la información que se debe capturar. Pero puede usar una gran variedad de estrategias para recopilar esta información:
Supervisión del sistema y la aplicación. Esta estrategia usa orígenes internos dentro de la aplicación, marcos de aplicaciones, el sistema operativo y la infraestructura. El código de la aplicación en sí mismo puede generar sus propios datos de supervisión en puntos notables durante el ciclo de vida de una solicitud de cliente. La aplicación puede incluir instrucciones de seguimiento que pueden habilitarse o deshabilitarse de forma selectiva, según las circunstancias. También es posible insertar diagnósticos dinámicamente mediante el uso de un marco de diagnósticos. Normalmente, estos marcos ofrecen complementos que pueden adjuntarse a varios puntos de instrumentación en el código y capturar los datos de seguimiento en dichos puntos.
Además, el código y la infraestructura subyacente pueden generar eventos en puntos críticos. La supervisión de los agentes que están configurados para detectar estos eventos puede registrar la información del evento.
Supervisión de los usuarios reales. Este enfoque registra las interacciones entre un usuario y la aplicación y observa el flujo de cada solicitud y respuesta. Esta información puede tener un objetivo doble: se puede utilizar para medir el uso de cada usuario y para determinar si los usuarios reciben una calidad de servicio adecuada (por ejemplo, tiempos de respuesta rápidos, latencia baja y errores mínimos). Los datos capturados se pueden usar para identificar áreas problemáticas donde se producen errores con más frecuencia. También se pueden utilizar los datos para identificar los elementos en los cuales el sistema se ralentiza, posiblemente debido a zonas activas en la aplicación o alguna otra forma de cuello de botella. Si implementa este enfoque cuidadosamente, quizá sea posible reconstruir los flujos de los usuarios a través de la aplicación con fines de depuración y pruebas.
Importante
Debería tener en cuenta que los datos que se capturan mediante la supervisión de usuarios reales son extremadamente delicados ya que podrían incluir material confidencial. Si guarda los datos capturados, almacénelos de forma segura. Si desea utilizar los datos para la supervisión del rendimiento o con fines de depuración, elimine en primer lugar todos los datos personales.
Supervisión de usuarios sintéticos. En este enfoque, escribe su propio cliente de prueba que simula un usuario y realiza una serie de operaciones configurables pero habituales. Puede realizar un seguimiento del rendimiento del cliente de prueba para ayudar a determinar el estado del sistema. También puede usar varias instancias del cliente de prueba como parte de una operación de prueba de carga para establecer la forma en que el sistema responde en situaciones de estrés y el tipo de resultado de supervisión que se genera en estas condiciones.
Nota
Puede implementar la supervisión de usuarios reales y sintéticos mediante la inclusión de código que realice un seguimiento y controle el tiempo de la ejecución de las llamadas a métodos y otras partes esenciales de una aplicación.
Generación de perfiles. Este enfoque está dirigido principalmente a supervisar y mejorar el rendimiento de la aplicación. En lugar de operar en el nivel funcional de la supervisión de usuarios reales y sintéticos, captura información de nivel inferior mientras se ejecuta la aplicación. Puede implementar perfiles mediante el muestreo periódico del estado de ejecución de una aplicación, y determinar la parte del código que la aplicación ejecuta en un momento dado. También puede utilizar instrumentación para insertar sondeos en el código en momentos importantes (como el inicio y el final de una llamada al método) y registrar qué métodos se invocaron, en qué momento y cuánto tiempo duró cada llamada. Luego estos datos se pueden analizar para determinar las partes de la aplicación que podrían producir problemas de rendimiento.
Supervisión de puntos de conexión. Esta técnica emplea uno o varios puntos de conexión de diagnóstico que la aplicación expone específicamente para permitir la supervisión. Un extremo ofrece un camino al código de la aplicación y puede devolver información sobre el estado del sistema. Distintos puntos de conexión pueden centrarse en diversos aspectos de la funcionalidad. Puede escribir su propio cliente de diagnósticos que envíe solicitudes periódicas a estos extremos y asimile las respuestas. Para más información, consulte el patrón de supervisión del punto de conexión de mantenimiento.
Para obtener la máxima cobertura, debe utilizar una combinación de estas técnicas.
Instrumentación de una aplicación
La instrumentación es una parte fundamental del proceso de supervisión. Puede tomar decisiones significativas sobre el rendimiento y el estado de un sistema solo si primero captura los datos que le permite tomar esas decisiones. La información que se recopila mediante instrumentación debe ser suficiente para que pueda evaluar el rendimiento, diagnosticar los problemas y tomar decisiones sin que tenga que iniciar sesión en un servidor de producción remoto para realizar el seguimiento (y la depuración) manualmente. Los datos de instrumentación contienen normalmente métricas e información que se escribe en los registros de seguimiento.
El contenido de un registro de seguimiento puede ser el resultado de los datos de texto que escribe la aplicación o los datos binarios que se crean como resultado de un evento de seguimiento (si la aplicación usa el Seguimiento de eventos de Windows (ETW)). También se pueden generar a partir de registros del sistema que anotan los eventos resultantes de partes de la infraestructura, como un servidor web. A menudo, los mensajes de registro de texto están diseñados para ser legibles por el ojo humano, pero también se deben escribir en un formato que permita que un sistema automatizado los analice fácilmente.
Además, los registros se deben clasificar. No escriba todos los datos de seguimiento en un registro único, use registros independientes para anotar los resultados de seguimiento de diversos aspectos operativos del sistema. Así puede filtrar rápidamente los mensajes de registro y leerlos desde el registro adecuado, en lugar de tener que procesar un único archivo largo. Nunca escriba información que tenga requisitos de seguridad diferentes (como información de auditoría y datos de depuración) en el mismo registro.
Nota
Un registro puede implementarse como un archivo en el sistema de archivos o puede mantenerse en otro formato, como un blob en un almacenamiento de blobs. La información de registro también se puede mantener en un almacenamiento más estructurado, como las filas de una tabla.
En general, las métricas serán generalmente una medida o un recuento de algún aspecto o recurso del sistema en un momento determinado, con una o varias etiquetas o dimensiones asociadas (a veces denominadas muestra). Una sola instancia de una métrica no suele ser útil de forma aislada. Las métricas deben capturarse con el paso del tiempo. El aspecto fundamental que se debe tener en cuenta es qué métricas se deben registrar y con qué frecuencia. Con demasiada frecuencia, la generación de datos de métricas puede suponer una carga adicional significativa sobre el sistema, mientras que la captura de métricas con poca frecuencia puede provocar que se pierdan las circunstancias que dan lugar a un evento significativo. Las consideraciones variarán de una métrica a otra. Por ejemplo, el uso de CPU en un servidor puede variar considerablemente de un segundo a otro, pero una utilización alta solo se convierte en un problema si persiste un tiempo, durante unos cuantos minutos.
Información para la correlación de datos
Puede supervisar fácilmente los contadores de rendimiento individuales de nivel de sistema, capturar métricas de recursos y obtener información de seguimiento de la aplicación de varios archivos de registro. Pero algunas formas de supervisión requieren la fase de análisis y diagnóstico en la canalización de supervisión para correlacionar los datos recuperados desde varios orígenes. Estos datos podrían adoptar distintas formas en los datos sin procesar, y el proceso de análisis debe contar con suficientes datos de instrumentación para poder asignar estas formas diferentes. Por ejemplo, en el nivel de marco de aplicación, una tarea podría identificarse mediante un id. de subproceso. Dentro de una aplicación, el mismo trabajo podría estar asociado con el id. de usuario del usuario que realiza la tarea.
Además, es poco probable que haya una asignación 1:1 entre los subprocesos y las solicitudes de usuario, dado que las operaciones asincrónicas pueden reutilizar los mismos subprocesos para realizar operaciones en nombre de más de un usuario. Para complicarlo todo aún más, una única solicitud podría controlarse mediante más de un subproceso a medida que la ejecución fluye a través del sistema. Si es posible, asocie cada solicitud a un id. de actividad único que se propague a través del sistema como parte del contexto de la solicitud. (La técnica para generar e incluir identificadores de actividad en la información de seguimiento depende de la tecnología que se utiliza para capturar los datos de seguimiento).
Todos los datos de supervisión deben tener una marca de tiempo del mismo tipo. Para mantener la coherencia, registre todas las fechas y horas según la hora universal coordinada. De esta forma, podrá realizar más fácilmente el seguimiento de las secuencias de eventos.
Nota
Es posible que los equipos que funcionan en diferentes zonas horarias y redes no se puedan sincronizar. No dependa del uso de marcas de tiempo solamente para correlacionar datos de instrumentación que abarquen varias máquinas.
Información que se debe incluir en los datos de instrumentación
A la hora de decidir qué datos de instrumentación necesita recopilar, tenga en cuenta los siguientes puntos:
Asegúrese de que la información que capturan los eventos de seguimiento sea legible por el ojo humano y las máquinas. Adopte esquemas bien definidos para esta información a fin de facilitar el procesamiento automatizado de los datos de registro entre sistemas y ofrecer coherencia para las operaciones y el personal de ingeniería que lee los registros. Incluya información del entorno, por ejemplo, el entorno de implementación, la máquina en la que se ejecuta el proceso, los detalles del proceso y la pila de llamadas.
Habilite la generación de perfiles solo cuando sea necesario, ya que puede suponer una sobrecarga significativa sobre el sistema. La generación de perfiles mediante los registros de instrumentación registra un evento (por ejemplo, una llamada a un método) cada vez que se produce, mientras que el muestreo solo registra los eventos seleccionados. La selección puede basarse en el tiempo (una vez cada n segundos) o en la frecuencia (una vez cada n solicitudes). Si los eventos se producen con mucha frecuencia, la generación de perfiles mediante instrumentación puede provocar un exceso de carga y afectar al rendimiento general. En este caso, puede ser preferible el enfoque de muestreo. Sin embargo, si la frecuencia de eventos es baja, el muestreo podría perderlos. En este caso, la instrumentación podría ser el mejor método.
Facilite suficiente contexto para permitir que un desarrollador o administrador determine el origen de cada solicitud. Por ejemplo, alguna forma de id. de actividad que identifica una instancia específica de una solicitud. O también información que puede usarse para correlacionar esta actividad con el trabajo de cálculo realizado y los recursos usados. Tenga en cuenta que este trabajo podría cruzar los límites de los procesos o las máquinas. Para la medición, el contexto también debe incluir (directa o indirectamente a través de otra información correlacionada) una referencia al cliente que motivó que se realizará la solicitud. Este contexto ofrece valiosa información sobre el estado de la aplicación en el momento en que se capturaron los datos de supervisión.
Registre todas las solicitudes y las ubicaciones o regiones desde las que se realizan estas solicitudes. Esta información puede ayudarle a determinar si hay alguna zona activa específica de la ubicación. También puede ser útil para determinar si se van a volver a crear particiones de la aplicación o de los datos que utiliza.
Registre y capture los detalles de las excepciones con cuidado. Con frecuencia, la información de depuración importante se pierde como resultado de un control de excepciones deficiente. Capture los detalles completos de las excepciones que inicia la aplicación, incluidas las excepciones internas y otra información de contexto. Incluya la pila de llamadas si es posible.
Sea coherente en los datos que capturan los distintos elementos de la aplicación, ya que esto puede ayudarle a analizar los eventos y a correlacionarlos con las solicitudes de usuario. Considere la posibilidad de usar un paquete de registro completo y configurable para recopilar información, en lugar de depender de que los desarrolladores adopten el mismo enfoque para implementar diferentes partes del sistema. Recopile datos de contadores de rendimiento clave, como el volumen de E/S que se procesa, la utilización de la red, el número de solicitudes, el uso de memoria y la utilización de CPU. Algunos servicios de infraestructuras podrían ofrecer sus propios contadores de rendimiento específicos, como el número de conexiones a una base de datos, la velocidad a la que se realizan las transacciones y el número de transacciones que se realizan de forma correcta o errónea. Las aplicaciones también pueden definir sus propios contadores de rendimiento específicos.
Registre todas las llamadas que se realizan a servicios externos, como los sistemas de bases de datos, los servicios web u otros servicios de nivel de sistema que forman parte de la infraestructura. Registre información sobre el tiempo necesario para realizar cada llamada y si se realizó correctamente o de forma errónea. Si es posible, capture información sobre todos los reintentos y errores de los errores transitorios que se produzcan.
Garantizar la compatibilidad con los sistemas de telemetría
En muchos casos, la información que produce la instrumentación se genera como una serie de eventos y pasa a un sistema de telemetría independiente para su procesamiento y análisis. Un sistema de telemetría suele ser independiente de cualquier aplicación o tecnología específicas, pero espera que la información siga un formato determinado que normalmente define un esquema. El esquema especifica eficazmente un contrato que define los campos y tipos de datos que puede recopilar el sistema de telemetría. El esquema debe generalizarse para permitir que los datos procedan de una variedad de plataformas y dispositivos.
Un esquema común debe incluir campos que sean comunes a todos los eventos de instrumentación, como el nombre del evento, la hora del evento, la dirección IP del remitente y los detalles necesarios para realizar una correlación con otros eventos (por ejemplo, un id. de usuario, un id. de dispositivo y un id. de aplicación). Recuerde que cualquier número de dispositivos puede generar eventos, por lo que el esquema no debe depender del tipo de dispositivo. Además, varios dispositivos diferentes pueden generar eventos para la misma aplicación; la aplicación podría admitir movilidad o algún otro tipo de distribución entre dispositivos.
El esquema también podría incluir campos de dominio que sean pertinentes para un determinado escenario común en las distintas aplicaciones. Puede tratarse de información sobre excepciones, eventos de inicio y finalización de la aplicación y llamadas de API de servicios web aceptadas y rechazadas. Todas las aplicaciones que usan el mismo conjunto de campos de dominio deben emitir el mismo conjunto de eventos, lo que permite que se genere un conjunto de informes y análisis comunes.
Por último, un esquema podría contener campos personalizados para capturar los detalles de los eventos específicos de la aplicación.
Prácticas recomendadas para la instrumentación de aplicaciones
En la lista siguiente se resumen las prácticas recomendadas para instrumentar una aplicación distribuida que se ejecuta en la nube.
Haga que los registros sean fáciles de leer y de analizar. Use registros estructurados siempre que sea posible. Sea conciso y descriptivo en los mensajes de registro.
En todos los registros, identifique el origen y ofrezca contexto e información de tiempo conforme se escriba cada entrada del registro.
Use el mismo formato y la misma zona horaria para todas las marcas de tiempo. Esto le ayudará a hacer una correlación de los eventos para las operaciones que abarcan el hardware y los servicios que se ejecutan en regiones geográficas distintas.
Clasifique los registros y escriba mensajes en el archivo de registro adecuado.
No revele información confidencial sobre el sistema o información personal sobre los usuarios. Elimine esta información antes de que se registre, pero asegúrese de que se conservan los detalles pertinentes. Por ejemplo, quite el identificador y la contraseña de las cadenas de conexión de la base de datos, pero escriba la información restante en el registro para que un analista pueda determinar si el sistema está accediendo a la base de datos correcta. Registre todas las excepciones críticas, pero permita que el administrador active y desactive el registro de los niveles inferiores de las excepciones y advertencias. Además, capture y registre toda la información lógica de reintentos. Estos datos pueden ser útiles para supervisar el estado transitorio del sistema.
Realice un seguimiento de las llamadas de proceso, como las solicitudes de bases de datos o servicios web externos.
No mezcle mensajes de registro con distintos requisitos de seguridad en el mismo archivo de registro. Por ejemplo, no escriba información sobre la depuración y la auditoría en el mismo registro.
Con la excepción de los eventos de auditoría, asegúrese de que todas las llamadas de registro sean operaciones que no requieran intervención manual tras su activación y que no bloqueen el progreso de las operaciones de negocio. Los eventos de auditoría son una excepción porque son fundamentales para la empresa y se pueden clasificar como una parte crucial de las operaciones de negocio.
Asegúrese de que el registro sea extensible y no tenga ninguna dependencia directa en un destino concreto. Por ejemplo, en lugar de escribir la información mediante System.Diagnostics.Trace, defina una interfaz abstracta (como ILogger) que exponga métodos de registro y que pueda implementarse por cualquier medio adecuado.
Asegúrese de que todo el registro sea a prueba de errores y nunca genere errores en cascada. El registro no debe producir excepciones.
Trate la instrumentación como un proceso iterativo continuo y revise los registros con regularidad, no solo cuando haya un problema.
Recopilación y almacenamiento de datos
La fase de recopilación del proceso de supervisión se ocupa de recuperar la información que genera la instrumentación, dar formato a estos datos para que resulten más fáciles de usar en la fase de análisis y diagnóstico y guardar los datos transformados en un almacenamiento confiable. Los datos de instrumentación que se recopilan de distintas partes de un sistema distribuido se pueden mantener en una variedad de ubicaciones y con diferentes formatos. Por ejemplo, el código de su aplicación podría generar archivos de registro de seguimiento y datos de registro de eventos de la aplicación, mientras que los contadores de rendimiento que supervisan aspectos clave de la infraestructura que usa su aplicación se pueden capturar mediante otras tecnologías. Los servicios y componentes de terceros que use su aplicación podrían proporcionar información de instrumentación en formatos diferentes, con archivos de seguimiento independientes, almacenamiento de blobs o incluso un almacén de datos personalizado.
La recopilación de datos se realiza a menudo mediante un servicio de recopilación que se puede ejecutar de forma independiente de la aplicación que genera los datos de instrumentación. En la Figura 2 se muestra un ejemplo de esta arquitectura, donde se resalta el subsistema de recopilación de datos de instrumentación.
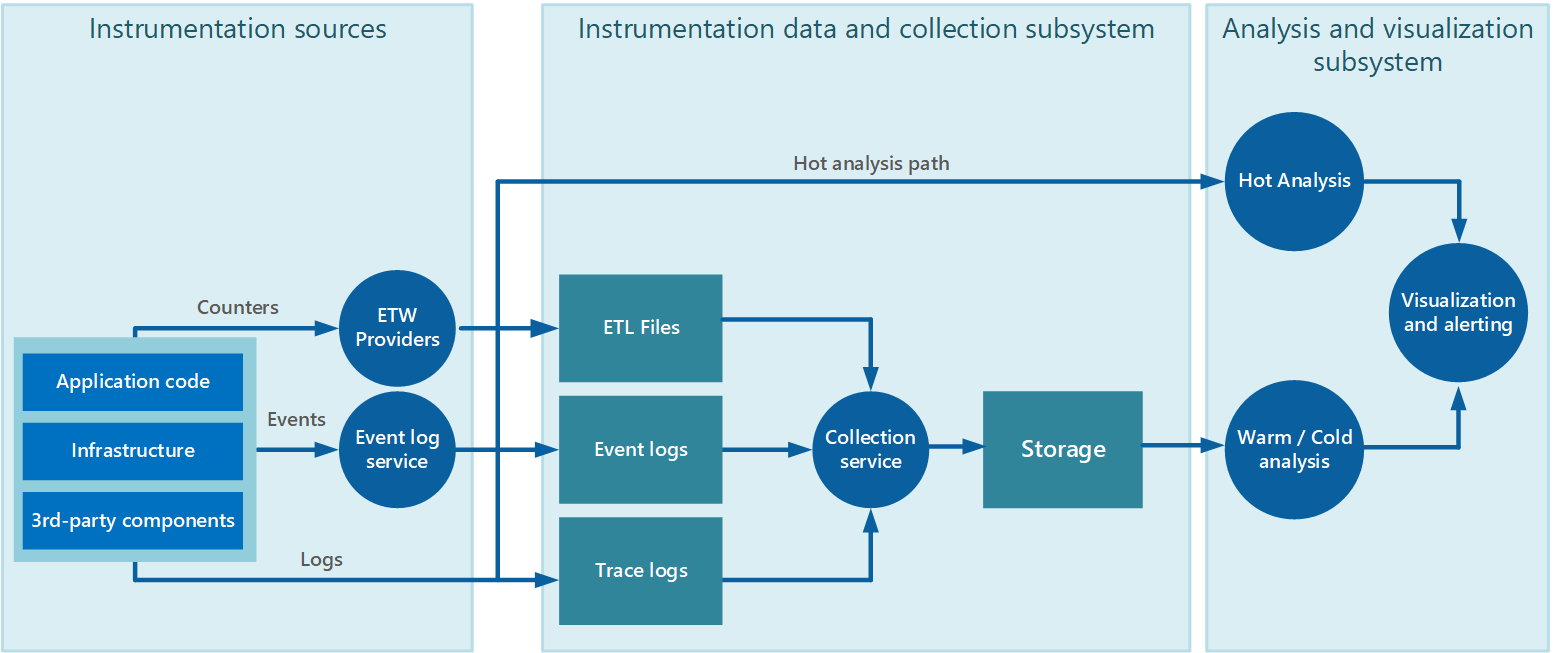
Ilustración 2: Recopilación de datos de instrumentación.
Tenga en cuenta que se trata de una vista simplificada. El servicio de recopilación no es necesariamente un proceso único y puede constar de varias partes que se ejecutan en equipos diferentes, como se describe en las secciones siguientes. Además, si es necesario realizar el análisis de algunos datos de telemetría rápidamente (análisis en vivo, como se describe en la sección Compatibilidad con el análisis en caliente, intermedio y en frío que se encuentra más adelante en este documento), los componentes locales que se encuentren fuera del servicio de recopilación podrían realizar las tareas de análisis inmediatamente. En la Figura 2 se ilustra esta situación para los eventos seleccionados. Después del procesamiento analítico, los resultados pueden enviarse directamente al subsistema de visualización y alertas. Los datos que se someten a análisis en frío o intermedio se mantienen en el almacenamiento mientras esperan el procesamiento.
Para los servicios y aplicaciones de Azure, Diagnósticos de Azure ofrece una solución posible para capturar los datos. Diagnósticos de Azure recopila datos de los siguientes orígenes para cada nodo de ejecución, los agrega y, después, los carga en Azure Storage:
- Registros IIS
- Registros de solicitudes con error de IIS
- Registros de eventos de Windows
- Contadores de rendimiento
- Volcados de memoria
- Registros de infraestructura de diagnóstico de Azure
- Registros de errores personalizados
- .NET EventSource
- ETW basado en manifiesto
Para más información, consulte el artículo Azure: Telemetry Basics and Troubleshooting (Azure: Conceptos básicos sobre telemetría y solución de problemas).
Estrategias para la recopilación de datos de instrumentación
Dada la naturaleza flexible de la nube y para evitar la necesidad de recuperar manualmente los datos de telemetría de todos los nodos del sistema, debe organizar los datos para que se transfieran a una ubicación central y consolidada. En un sistema que abarque varios centros de datos, podría ser útil que en primer lugar se recopilen, consoliden y almacenen los datos región por región y, después, que se agreguen los datos regionales en un solo sistema central.
Para optimizar el uso del ancho de banda, puede elegir transferir datos menos urgentes en fragmentos, como lotes. Sin embargo, los datos no deben retrasarse indefinidamente, especialmente si contienen información confidencial en el tiempo.
Extracción e inserción de datos de instrumentación
El subsistema de recopilación de datos de instrumentación puede recuperar de forma activa datos de instrumentación de los distintos registros y otros orígenes para cada instancia de la aplicación (el modelo de extracción). O bien, puede actuar como receptor pasivo que espera a que se envíen los datos desde los componentes que conforman cada instancia de la aplicación (el modelo de inserción).
Un enfoque para implementar el modelo de extracción es usar agentes de supervisión que se ejecuten localmente con cada instancia de la aplicación. Un agente de supervisión es un proceso independiente que recupera periódicamente (extrae) datos de telemetría recopilados en el nodo local y escribe esta información directamente en un almacenamiento centralizado que comparten todas las instancias de la aplicación. Este es el mecanismo que implementa Diagnósticos de Azure. Cada instancia de un rol web o de trabajo de Azure puede configurarse para que capture información de diagnóstico y otra información de seguimiento, que se almacena localmente. El agente de supervisión que se ejecuta unto con cada instancia copia los datos especificados en Azure Storage. En el artículo Habilitación de diagnósticos de Azure en Azure Cloud Services y Virtual Machines se proporcionan más detalles sobre este proceso. Algunos elementos, como registros, volcados y registros de errores personalizados de IIS se escriben en el almacenamiento de blobs. Los datos del registro de eventos de Windows, los eventos ETW y los contadores de rendimiento se registran en el almacenamiento de tablas. En la Figura 3 se muestra este mecanismo.
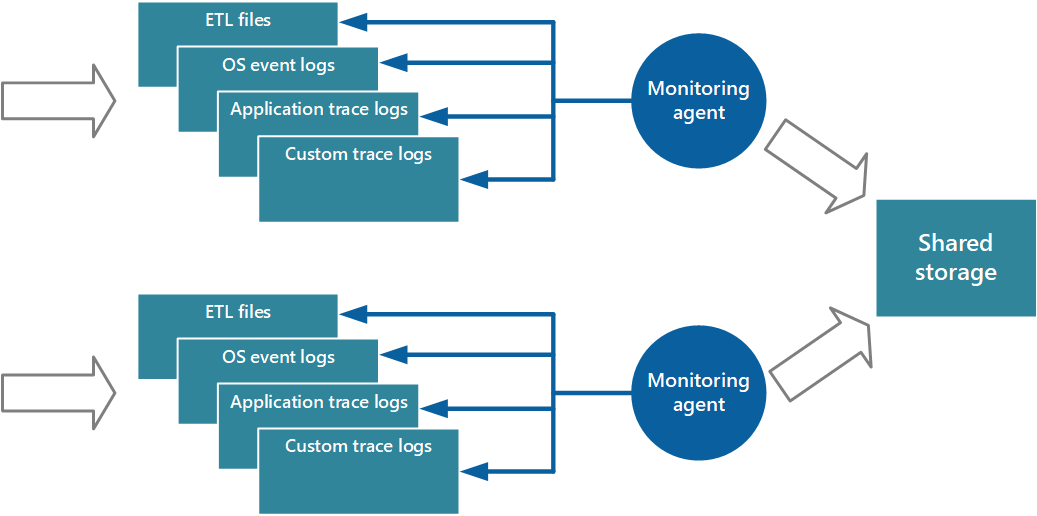
Ilustración 3: Uso de un agente de supervisión para extraer información y escribir en el almacenamiento compartido.
Nota
El uso de un agente de supervisión resulta muy conveniente para capturar datos de instrumentación que se extraen naturalmente de un origen de datos. Por ejemplo, la información de las vistas de administración dinámica de SQL Server o la longitud de una cola de Azure Service Bus.
El enfoque que se acaba de describir resulta factible para almacenar datos de telemetría para aplicaciones a pequeña escala que se ejecutan en un número limitado de nodos en una sola ubicación. Sin embargo, una aplicación de la nube global, compleja y altamente escalable puede generar con facilidad grandes volúmenes de datos de cientos roles web y de trabajo, particiones de base de datos y otros servicios. Esta avalancha de datos puede sobrecargar fácilmente el ancho de banda de E/S disponible en una única ubicación central. Por lo tanto, la solución de telemetría debe ser escalable para impedir que actúe como un cuello de botella que amplía el sistema. Lo ideal es que la solución incorpore un grado de redundancia para reducir el riesgo de perder información de supervisión importante (por ejemplo, los datos de auditoría o de facturación) si se produce un error en alguna parte del sistema.
Para resolver estos problemas, puede implementar la puesta en cola, como se muestra en la Figura 4. En esta arquitectura, el agente de supervisión local (si se puede configurar adecuadamente) o si no el servicio de recopilación de datos personalizado publica datos en una cola. Un proceso independiente que se ejecuta de manera asincrónica (el servicio de escritura en almacenamiento en la Figura 4) toma los datos en esta cola y los escribe en almacenamiento compartido. En este escenario lo adecuado es una cola de mensajes porque proporciona una semántica de "al menos una vez" que ayuda a garantizar que los datos en cola no se perderán después de publicarlos. El servicio de escritura en almacenamiento se puede implementar mediante un rol de trabajo independiente.
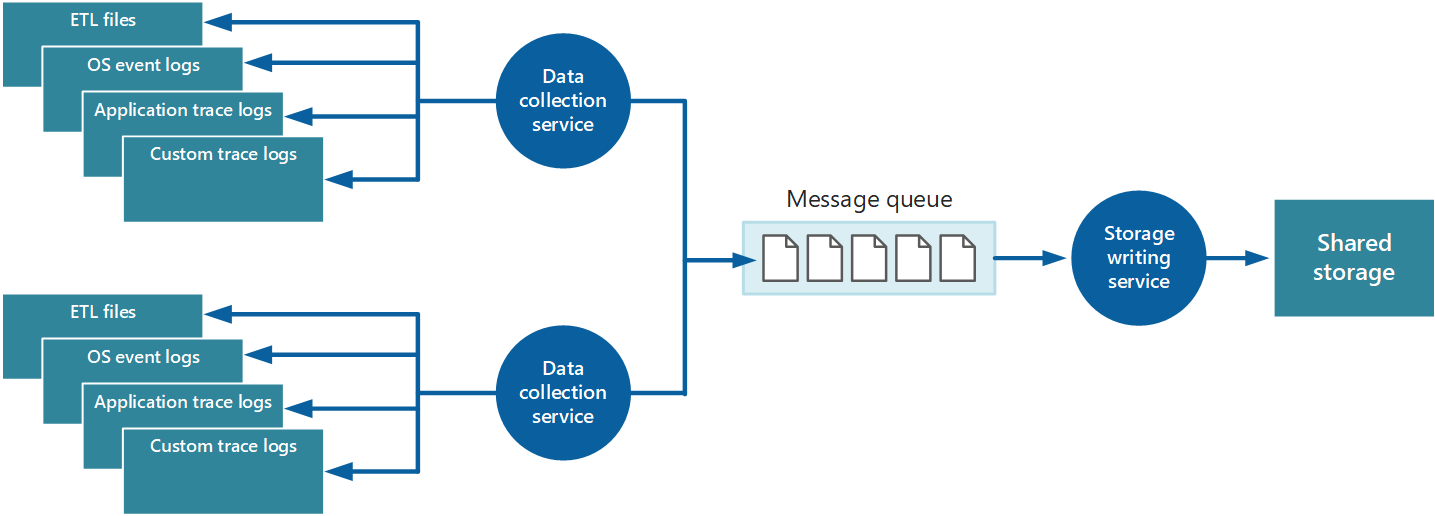
Ilustración 4: Uso de una cola para almacenar en búfer datos de instrumentación.
El servicio de recopilación de datos local puede agregar datos a una cola en cuanto se reciben. La cola actúa como búfer y el servicio de escritura en almacenamiento puede recuperar y escribir los datos a su propio ritmo. De forma predeterminada, una cola funciona según el criterio primero en entrar, primero en salir. Pero puede dar prioridad a los mensajes para acelerarlos en la cola si contienen datos que se deben controlar más rápidamente. Para más información, consulte el patrón de cola de prioridad. Como alternativa, puede usar canales distintos (por ejemplo, los temas de Service Bus) para dirigir datos a destinos diferentes según el tipo de procesamiento analítico necesario.
Para la escalabilidad, puede ejecutar varias instancias del servicio de escritura en almacenamiento. Si hay un gran volumen de eventos, puede usar un centro de eventos para enviar los datos a recursos de procesos diferentes para su procesamiento y almacenamiento.
Consolidación de datos de instrumentación
Los datos de instrumentación que recupera el servicio de recopilación de datos a partir de una única instancia de una aplicación ofrecen una vista localizada del estado y rendimiento de esa instancia. Para evaluar el estado general del sistema, es necesario consolidar algunos aspectos de los datos en las vistas locales. Puede realizar esto después de que se han almacenado los datos, pero en algunos casos, también puede conseguirlo mientras se recopilan. En vez de que los datos de instrumentación se escriban directamente en el almacenamiento compartido, pueden pasar por un servicio de consolidación de datos independiente que combine los datos y actúe como un proceso de filtrado y limpieza. Por ejemplo, se pueden combinar datos de instrumentación que incluyan la misma información de correlación, como un id. de actividad. (Es posible que un usuario comience a realizar una operación de negocio en un nodo y que luego se transfiera a otro nodo en caso de error o en función de cómo esté configurado el equilibrio de carga). Este proceso también puede detectar y quitar los datos duplicados (siempre es una posibilidad, si el servicio de telemetría usa colas de mensajes para insertar datos de instrumentación en el almacenamiento). En la Ilustración 5 se muestra un ejemplo de esta estructura.
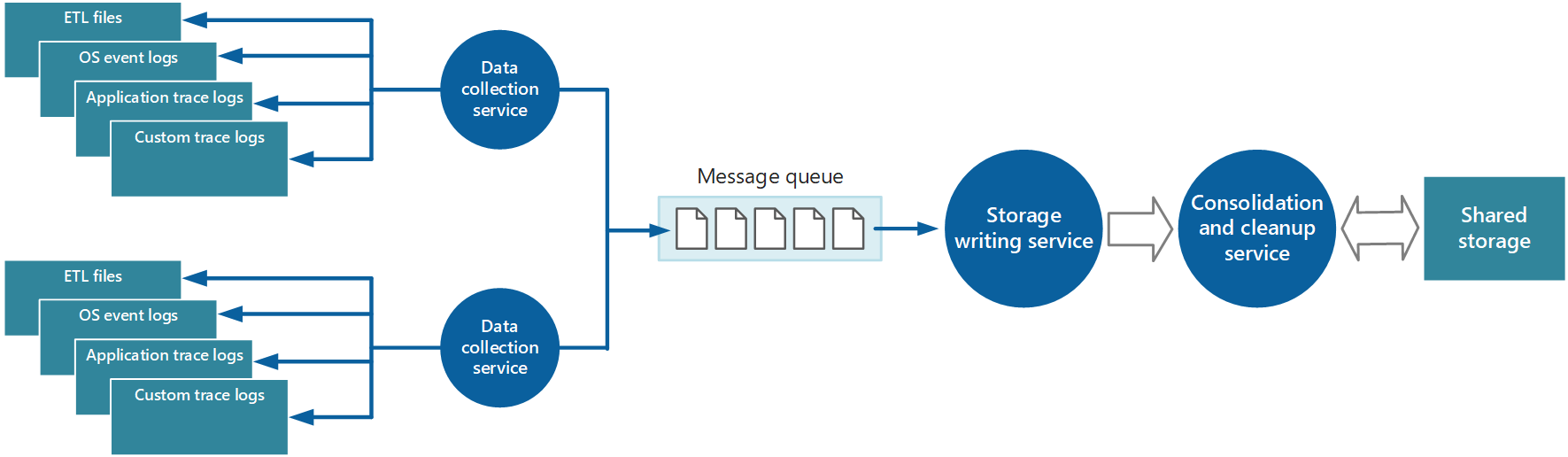
Ilustración 5: Uso de un servicio independiente para consolidar y limpiar los datos de instrumentación.
Almacenamiento de datos de instrumentación
En la información anterior se ha descrito una vista bastante simple de la manera en que se almacenan los datos de instrumentación. En realidad, puede tener sentido almacenar los distintos tipos de información con las tecnologías que sean más adecuadas para la manera en que sea más probable que se use cada tipo.
Por ejemplo, el almacenamiento de blobs y de tablas de Azure guarda algunas similitudes en la forma en la que se tiene acceso a ellos. Sin embargo, tienen limitaciones en las operaciones que se pueden realizar con ellos, y la granularidad de los datos que contienen es bastante diferente. Si necesita realizar más operaciones de análisis o precisa funcionalidades de búsqueda de texto completo en los datos, podría ser más apropiado usar el almacenamiento de datos que ofrezca funcionalidades que estén optimizadas para tipos concretos de accesos a datos y consultas. Por ejemplo:
- Los datos de los contadores de rendimiento se pueden almacenar en una base de datos SQL para permitir el análisis ad hoc.
- Los registros de seguimiento podrían almacenarse mejor en Azure Cosmos DB.
- La información de seguridad se puede escribir en HDFS.
- La información que requiere la búsqueda de texto completo se puede almacenar mediante Elasticsearch (que también puede acelerar las búsquedas mediante la indexación enriquecida).
Puede implementar un servicio adicional que recupere de forma periódica los datos del almacenamiento compartido, cree particiones de los mismos y los filtre según su propósito para, después, escribirlos en un conjunto de almacenes de datos, como se muestra en la Ilustración 6. Un enfoque alternativo es incluir esta funcionalidad en el proceso de consolidación y limpieza y escribir los datos directamente en esos almacenes a medida que se recuperan, en lugar de guardarlos en un área intermedia de almacenamiento compartido. Cada enfoque tiene sus ventajas e inconvenientes. La implementación de un servicio de creación de particiones independiente reduce la carga en el servicio de consolidación y limpieza y permite que al menos algunos de los datos con particiones se vuelvan a generar si es necesario (según la cantidad de datos que se conserven en el almacenamiento compartido). Sin embargo, consume recursos adicionales. Además, podría haber un retraso entre la recepción de los datos de instrumentación de cada instancia de aplicación y la conversión de estos datos en información útil.
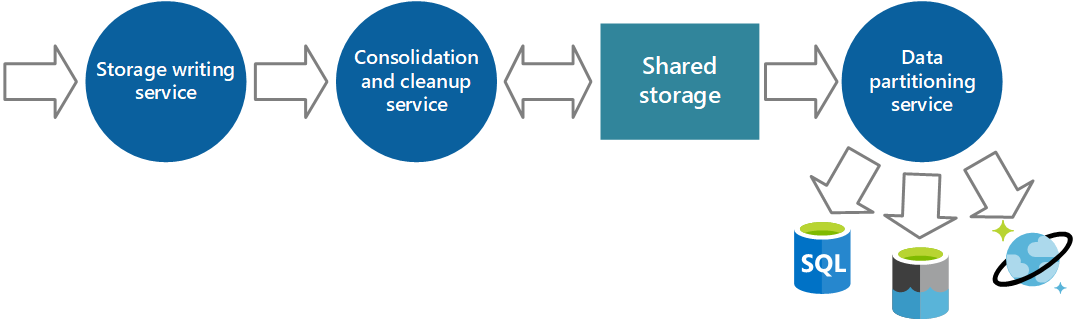
Ilustración 6: Creación de particiones de los datos según los requisitos analíticos y de almacenamiento.
Es posible que se necesiten los mismos datos de instrumentación para más de un fin. Por ejemplo, los contadores de rendimiento se pueden utilizar para proporcionar una vista histórica del rendimiento del sistema con el tiempo. Esta información puede combinarse con otros datos de uso para generar información de facturación del cliente. En estas situaciones, los mismos datos se podrían enviar a más de un destino, como una base de datos documental que pueda actuar como un almacén a largo plazo para mantener información de facturación y un almacén multidimensional para controlar análisis complejos del rendimiento.
También debe considerar la urgencia con que se requieren los datos. Es necesario que el acceso a los datos que proporcionan información de alerta sea rápido, de forma que deben mantenerse en almacenamientos de datos rápido y se deben indexar o estructurar para optimizar las consultas que realiza el sistema de alertas. En algunos casos, puede ser necesario que el servicio de telemetría recopile los datos de cada nodo para dar formato y guardar los datos de forma local, de forma que una instancia local del sistema de alertas pueda notificar rápidamente cualquier problema. Los mismos datos se pueden enviar al servicio de escritura en almacenamiento que se muestra en los diagramas anteriores y se pueden almacenar de forma centralizada si también se necesitan para otros fines.
La información que se usa para análisis más considerados, informes y para detectar las tendencias históricas es menos urgente y se puede almacenar de manera que admita minería de datos y consultas ad hoc. Para más información, consulte la sección Compatibilidad con el análisis en caliente, intermedio y en frío más adelante en este documento.
Rotación de registros y retención de datos
La instrumentación puede generar grandes volúmenes de datos. Estos datos se pueden almacenar en varios lugares, comenzando por los archivos de registro sin procesar, los archivos de seguimiento y otra información capturada en cada nodo para las vistas consolidada, limpia y con particiones de los datos que se mantienen en el almacenamiento compartido. En algunos casos, cuando los datos se han procesado y transferido, los datos originales sin procesar se pueden eliminar de cada nodo. En otros casos, puede ser necesario o simplemente útil guardar la información sin procesar. Por ejemplo, es mejor que los datos generados con fines de depuración queden disponibles en el formato sin procesar, pero luego puedan descartarse bastante rápido cuando se han subsanados los errores.
Los datos de rendimiento a menudo tienen una vida más larga, de modo que pueden usarse para identificar tendencias de rendimiento y para planear la capacidad. La vista consolidada de estos datos normalmente se mantiene en línea durante un período limitado para permitir un acceso rápido. Después, se pueden archivar o descartar. Es posible que los datos recopilados para la medición y facturación de los clientes se guarden de forma indefinida. Además, los requisitos normativos podrían obligar a que la información recopilada con fines de auditoría y seguridad también se deba archivar y guardar. Estos datos también son confidenciales y es necesario cifrarlos o aplicarles otro tipo de protección para evitar su manipulación. Nunca debe registrar las contraseñas de usuario u otra información que pudiera utilizarse para cometer fraudes de identidad. Estos detalles deben eliminarse de los datos antes de almacenarlos.
Reducción de la resolución
Resulta útil almacenar datos históricos, así puede detectar tendencias a largo plazo. En lugar de guardar los datos antiguos en su totalidad, es posible tomar una muestra de los datos para disminuir su resolución y ahorrar en costos de almacenamiento. Por ejemplo, en lugar de guardar indicadores de rendimiento minuto a minuto, puede consolidar los datos con una antigüedad superior a un mes para formar una vista hora a hora.
Prácticas recomendadas para recopilar y almacenar información de registro
En la lista siguiente se resumen las prácticas recomendadas para capturar y almacenar información de registro:
El agente de supervisión o el servicio de recopilación de datos deben ejecutarse como un servicio fuera del proceso y deben ser fáciles de implementar.
Todos los resultados del agente de supervisión o del servicio de recopilación de datos deben tener un formato independiente de la máquina, del sistema operativo y del protocolo de red. Por ejemplo, emita la información en un formato autodescriptivo como JSON, MessagePack o Protobuf, en lugar de ETL/ETW. El uso de un formato estándar permite que el sistema cree canalizaciones de procesamiento; se pueden integrar fácilmente componentes que leen, transforman y envían datos en el formato acordado.
El proceso de supervisión y recopilación de datos debe ser a prueba de errores y no debe desencadenar condiciones de errores en cascada.
Si se produce un error transitorio en el envío de información a un receptor de datos, el agente de supervisión o el servicio de recopilación de datos deben estar preparados para volver a ordenar los datos de telemetría, de forma que la información más reciente se envíe primero. (El servicio de recopilación de datos o el agente de supervisión podrían optar por eliminar los datos más antiguos, o guardarlos localmente y transmitirlos más adelante para ponerse al día, según su propio criterio).
Análisis de los datos y diagnóstico de problemas
Una parte importante del proceso de supervisión y diagnóstico es analizar los datos recopilados para obtener una imagen del estado general del sistema. Debe haber definido sus propios KPI y métricas de rendimiento, y es importante entender cómo se pueden estructurar los datos que se han recopilado para cumplir los requisitos de análisis. También es importante comprender cómo se correlacionan los datos capturados en distintos archivos de registro y métricas, ya que esta información puede ser clave para realizar un seguimiento de una secuencia de eventos y ayudar a diagnosticar los problemas que surjan.
Como se describe en la sección Consolidación de los datos de instrumentación, los datos de cada parte del sistema se suelen capturar de forma local, pero normalmente tienen que combinarse con los datos generados en otros sitios que participen en el sistema. Esta información requiere que se realice una correlación con cuidado para garantizar que los datos se combinan con precisión. Por ejemplo, los datos de uso de una operación pueden abarcar un nodo que hospede un sitio web al que se conecta un usuario, un nodo que ejecuta un servicio independiente al que se accede como parte de esta operación y el almacenamiento de datos que se mantiene en un nodo adicional. Esta información debe unirse para ofrecer una visión general del uso de recursos y procesamiento por parte de la operación. Parte del preprocesamiento y el filtrado de los datos puede tener lugar en el nodo en el que se capturan los datos, mientras que es más probable que la agregación y el formato ocurran en un nodo central.
Compatibilidad con el análisis en caliente, intermedio y en frío
El análisis y la operación de formato de los datos para fines de visualización, informes y alertas puede ser un proceso complejo que consume su propio conjunto de recursos. Algunas formas de supervisión dependen del tiempo y requieren un análisis inmediato de los datos para resultar eficaces. Esto se conoce como análisis en caliente. Algunos ejemplos son los análisis que se requieren para las alertas y algunos aspectos de la supervisión de la seguridad (por ejemplo, la detección de un ataque en el sistema). Los datos necesarios con estos fines deben estar disponibles rápidamente y estar estructurados para un procesamiento eficaz. En algunos casos, podría ser necesario mover el procesamiento del análisis a los nodos individuales donde se mantienen los datos.
Otras formas de análisis dependen menos del tiempo y pueden requerir algunos cálculos y agregaciones cuando se han recibido los datos sin procesar. Esto se conoce como análisis en caliente. El análisis del rendimiento se encuentra con frecuencia en esta categoría. En este caso, un evento de rendimiento individual y aislado es poco probable que sea significativo desde el punto de vista estadístico. (Podría deberse a un problema o un pico repentino). Los datos de una serie de eventos deben proporcionar una imagen más confiable del rendimiento del sistema.
El análisis intermedio también puede usarse para ayudar a diagnosticar problemas de estados. Un evento de estado normalmente se procesa mediante la realización de análisis en caliente y puede generar una alerta inmediatamente. Un operador debe ser capaz de explorar en profundidad las razones del evento de estado mediante el examen de los datos de la ruta de acceso activa. Estos datos deben contener información sobre los eventos que llevan al problema que provocó el evento de estado.
Algunos tipos de supervisión generan datos a más largo plazo. Este análisis puede realizarse en una fecha posterior, posiblemente según una programación predefinida. En algunos casos, es posible que el análisis deba realizar un filtrado complejo de grandes volúmenes de datos capturados durante un período de tiempo. Esto se conoce como análisis en frío. El requisito clave es que los datos estén almacenados de forma segura cuando se han capturado. Por ejemplo, la supervisión del uso y la auditoría requieren una imagen precisa del estado del sistema en puntos regulares en el tiempo, pero esta información de estado no tiene que estar disponible para su procesamiento en cuanto se ha recopilado.
Un operador puede usar también el análisis en frío para proporcionar los datos para el análisis de mantenimiento predictivo. El operador puede recopilar la información histórica durante un período de tiempo especificado y usarla junto con los datos de estado actuales (recuperados de la ruta activa) para identificar las tendencias que podrían producir problemas de mantenimiento en un corto espacio de tiempo. En estos casos, podría ser necesario generar una alerta para que se puedan tomar las medidas adecuadas.
Correlación de datos
Los datos que se capturan en la fase de instrumentación pueden proporcionar una instantánea del estado del sistema, pero el propósito del análisis es que esta información sea procesable. Por ejemplo:
- Por ejemplo, ¿qué ha provocado una carga intensa de E/S en el nivel del sistema en un momento determinado?
- ¿Es el resultado de un gran número de operaciones de base de datos?
- ¿Se refleja eso en los tiempos de respuesta de la base de datos, el número de transacciones por segundo y los tiempos de respuesta de la aplicación en el mismo momento?
En caso afirmativo, una acción correctora que podría reducir la carga podría ser repartir los datos entre más servidores. Además, pueden producirse excepciones a consecuencia de un error en cualquier nivel del sistema. Una excepción en un nivel a menudo desencadena otro error en el nivel superior.
Por estas razones, necesita poder correlacionar los distintos tipos de datos de supervisión de cada nivel para producir una vista general del estado del sistema y las aplicaciones que se ejecutan en él. Puede usar esta información para tomar decisiones sobre si el sistema funciona de forma aceptable o no y determinar lo que se puede hacer para mejorar la calidad del sistema.
Como se describe en la sección Información para la correlación de datos, debe asegurarse de que los datos de instrumentación sin procesar incluyan suficiente información de contexto y del identificador de la actividad para permitir las agregaciones necesarias para correlacionar los eventos. Además, estos datos se pueden mantener en formatos distintos y puede ser necesario analizar esta información para convertirla en un formato estandarizado con fines de análisis.
Solución de problemas y diagnóstico de problemas
Es necesario que con el diagnóstico se pueda determinar la causa de los errores o los comportamientos inesperados, incluida la realización del análisis de causa raíz. La información normalmente necesaria incluye:
- Información detallada de los registros y seguimientos de eventos de todo el sistema o de un subsistema concreto durante un período de tiempo especificado.
- Seguimientos de pila completos resultantes de las excepciones y los errores de cualquier nivel especificado que se produzcan dentro del sistema o de un subsistema concreto durante un período de tiempo especificado.
- Volcados de memoria de los procesos erróneos en cualquier lugar del sistema o de un subsistema concreto durante un período de tiempo especificado.
- Registros de actividad que anotan las operaciones que realizan todos los usuarios o los usuarios seleccionados durante un período de tiempo especificado.
El análisis de los datos para fines de solución de problemas requiere a menudo unos profundos conocimientos técnicos de la arquitectura del sistema y de los distintos componentes que conforman la solución. Como resultado, normalmente se requiere un alto grado de intervención manual para interpretar los datos, establecer la causa de los problemas y recomendar una estrategia adecuada para corregirlos. Puede que lo más adecuado sea sencillamente almacenar una copia de esta información en su formato original que esté disponible para que un experto la analice en frío.
Visualización de los datos y generación de alertas
Un aspecto importante de cualquier sistema de supervisión es la posibilidad de para presentar los datos de tal manera que un operador pueda detectar rápidamente tendencias o problemas. También es importante la posibilidad de informar rápidamente a un operador si se ha producido un evento significativo que pueda requerir atención.
La presentación de los datos puede tener varias formas, incluida la visualización mediante paneles, las alertas y los informes.
Visualización mediante paneles
La manera más común de visualizar los datos es usar paneles que puedan mostrar información como una serie de gráficos o alguna otra ilustración. Estos elementos podrían parametrizarse y un analista podría ser capaz de seleccionar los parámetros importantes (por ejemplo, el período de tiempo) para cualquier situación concreta.
Los paneles pueden organizarse de forma jerárquica. Los paneles de nivel superior pueden dar una visión general de cada aspecto del sistema, pero permiten que un operador explore en profundidad hasta llegar a los detalles. Por ejemplo, un panel que muestre la E/S global del disco del sistema debe permitir que un analista vea las tasas de E/S de cada disco individual para determinar si uno o varios dispositivos concretos tienen un volumen de tráfico desproporcionado. Lo ideal sería que el panel mostrara también información relacionada, como el origen de cada solicitud (el usuario o la actividad) que está generando esa E/S. Esta información podría usarse entonces para determinar si (y cómo) se puede distribuir la carga uniformemente entre los dispositivos y si el sistema funcionaría mejor si se agregaran más dispositivos.
Un panel también puede usar códigos de colores u otro tipo de indicaciones visuales para mostrar los valores que parezcan irregulares o que estén fuera de un intervalo esperado. Usando el ejemplo anterior:
- Un disco con una tasa de E/S que se aproxima a su capacidad máxima durante un período prolongado (un disco caliente) puede aparecer resaltado en rojo.
- Un disco con una tasa de E/S que se ejecute periódicamente con su límite máximo durante breves períodos (un disco templado) puede aparecer resaltado en amarillo.
- Un disco que presenta el uso normal puede mostrarse en verde.
Tenga en cuenta que para que un sistema de paneles funcione de forma eficaz, debe contar con los datos sin procesar con los que trabajar. Si va a crear su propio sistema de paneles o a usar un panel que ha desarrollado otra organización, debe entender qué datos de instrumentación necesita recopilar, con qué niveles de granularidad y cuál debe ser el formato para que el panel pueda usarlos.
Un buen panel no solo muestra información, sino que también permite que un analista plantee preguntas ad hoc sobre esa información. Algunos sistemas ofrecen herramientas de administración que un operador puede usar para realizar estas tareas y explorar los datos subyacentes. Como alternativa, según el repositorio utilizado para almacenar esta información, podría ser posible consultar estos datos directamente o importarlos en herramientas como Microsoft Excel para su posterior análisis y creación de informes.
Nota
El acceso a los paneles se debe limitar al personal autorizado, dado que esta información puede ser confidencial a efectos comerciales. También se deben proteger los datos subyacentes de los paneles para impedir que los usuarios los cambien.
Generación de alertas
Las alertas son el proceso de análisis de los datos de supervisión e instrumentación y la generación de una notificación si se detecta un evento significativo.
Las alertas ayudan a garantizar que el estado del sistema sea correcto, con capacidad de respuesta y seguro. Es una parte importante de cualquier sistema que ofrezca garantías de rendimiento, disponibilidad y privacidad a los usuarios, y es posible que haya que actuar sobre los datos inmediatamente. Es posible que haya que informar a un operador del evento que desencadenó la alerta. Las alertas también pueden usarse para invocar funciones del sistema como el escalado automático.
Normalmente, las alertas dependen de los siguientes datos de instrumentación:
- Eventos de seguridad. Si los registros de eventos indican que se están produciendo errores de autorización o autenticación repetidos, el sistema podría estar sufriendo un ataque y debe informarse a un operador.
- Métricas de rendimiento. El sistema debe responder rápidamente si una métrica de rendimiento determinada supera un umbral especificado.
- Información de disponibilidad. Si se detecta un error, podría ser necesario reiniciar rápidamente uno o varios subsistemas o una conmutación por error a un recurso de copia de seguridad. Los errores repetidos de un subsistema podrían indicar problemas más graves.
Los operadores podrían recibir información de alerta mediante varios canales de entrega como el correo electrónico, un dispositivo buscapersonas o un mensaje de texto SMS. Una alerta también puede incluir una indicación de la gravedad de la situación que se haya producido. Muchos sistemas de alertas admiten grupos de suscriptores y todos los operadores que sean miembros del mismo grupo pueden recibir el mismo grupo de alertas.
Un sistema de alertas debe ser personalizable, y como parámetros se pueden proporcionar los valores adecuados de los datos de instrumentación. Este enfoque permite que un operador filtre los datos y se centre en los umbrales o combinaciones de valores que sean de interés. Tenga en cuenta que, en algunos casos, se pueden proporcionar datos de instrumentación sin procesar al sistema de alertas. En otras situaciones, podría ser más apropiado facilitar datos agregados. (Por ejemplo, una alerta puede activarse si el uso de CPU de un nodo ha superado el 90 por ciento en los últimos 10 minutos). Los detalles proporcionados para el sistema de alertas también deben incluir cualquier información de resumen y contexto adecuada. Estos datos pueden ayudar a reducir la posibilidad de que los eventos falsos positivos disparen una alerta.
Notificación
Los informes se utilizan para generar una vista general del sistema. Pueden incorporar datos históricos, además de información actual. Los propios requisitos de los informes se dividen en dos amplias categorías: los informes operativos y los de seguridad.
Normalmente, los informes operativos incluyen los siguientes aspectos:
- Agregación de estadísticas que puede usar para comprender la utilización de recursos del sistema general o de subsistemas concretos durante un período especificado.
- Identificación de tendencias en el uso de recursos en todo el sistema o en subsistemas concretos durante un período de tiempo determinado.
- Supervisión de las excepciones que se hayan producido en todo el sistema o en subsistemas concretos durante un período determinado.
- Determinación de la eficacia de la aplicación en términos de los recursos implementados y comprensión de si el volumen de recursos (y su costo asociado) se puede reducir sin que afecte al rendimiento de forma innecesaria.
Los informes de seguridad se ocupan del seguimiento del uso del sistema por parte de los clientes. Pueden incluir:
- Auditoría de las operaciones de usuario. Esto requiere el registro de las solicitudes individuales que realiza cada usuario, junto con las fechas y horas. Los datos deben estar estructurados para permitir que un administrador reconstruya rápidamente la secuencia de operaciones que realiza un usuario concreto durante un período de tiempo especificado.
- Seguimiento del uso de recursos por usuario. Esto requiere el registro de la forma en que cada solicitud de un usuario obtiene acceso a los distintos recursos que componen el sistema y durante cuánto tiempo. Un administrador debe ser capaz de usar estos datos para generar un informe de uso por usuario durante un período de tiempo especificado, posiblemente con fines de facturación.
En muchos casos, los procesos por lotes pueden generar informes según una programación definida. (La latencia no es normalmente un problema). Pero también deberán estar disponibles para la generación de forma ad-hoc si es necesario. Por ejemplo, si está almacenando datos en una base de datos relacional como Azure SQL Database, puede usar una herramienta como SQL Server Reporting Services para extraer y dar formato a los datos y presentarlos como un conjunto de informes.
Pasos siguientes
- Introducción a Azure Monitor
- Supervisión, diagnóstico y solución de problemas de Microsoft Azure Storage
- Introducción a las alertas en Microsoft Azure
- Visualización de notificaciones de mantenimiento del servicio mediante Azure Portal
- ¿Qué es Application Insights?
- Diagnóstico de rendimiento para máquinas virtuales de Azure
- Descargar e instala SQL Server Data Tools (SSDT) para Visual Studio
Recursos relacionados
- guía de escalado automático se describe cómo disminuir la sobrecarga de administración reduciendo la necesidad de que un operador tenga que supervisar continuamente el rendimiento de un sistema y tomar decisiones sobre cómo agregar o quitar recursos.
- El patrón de supervisión del punto de conexión de mantenimiento describe cómo se implementan las comprobaciones funcionales dentro de una aplicación a las que herramientas externas puedan tener acceso mediante los puntos de conexión expuestos en intervalos regulares.
- El patrón de cola de prioridad muestra cómo dar prioridad a los mensajes en cola para que las solicitudes urgentes se reciban y se puedan procesar antes que los mensajes menos urgentes.