Recuperación ante desastres para una plataforma de datos de Azure: recomendaciones
Lecciones aprendidas
Asegúrese de que todas las partes implicadas comprendan la diferencia entre la alta disponibilidad (HA) y la recuperación ante desastres (DR). Confundir estos conceptos puede dar lugar a soluciones no coincidedas.
Para definir los objetivos de punto de recuperación (RPO) y los objetivos de tiempo de recuperación (RTO), analice con las partes interesadas de la empresa sus expectativas con respecto a los siguientes factores:
Cantidad de tiempo de inactividad que pueden tolerar. Tenga en cuenta que la recuperación más rápida suele suponer un costo mayor.
Los tipos de incidentes contra los que las partes interesadas necesitan protección y la probabilidad de que se produzcan. Por ejemplo, es más probable que se produzca un error de servidor que un desastre natural que afecte a todos los centros de datos de una región.
Los efectos de la falta de disponibilidad del sistema en su negocio.
Presupuesto de gastos operativos (OPEX) para la solución a largo plazo.
Tenga en cuenta qué opciones de servicio degradadas pueden aceptar los usuarios finales. Estas opciones pueden incluir:
Acceso a los paneles de visualización, incluso si los datos no up-to-date. En este escenario, los usuarios finales pueden ver sus datos, incluso si se produce un error en las canalizaciones de ingesta.
Acceso de lectura sin funcionalidades de escritura.
Las métricas de RTO y RPO de destino determinan la estrategia de recuperación ante desastres que elija implementar. Estas estrategias incluyen active/active, active/passive y active/redeploy en caso de desastre. Considere su propio objetivo de nivel de servicio compuesto para tener en cuenta los tiempos de inactividad tolerables.
Asegúrese de comprender todos los componentes que podrían afectar a la disponibilidad de los sistemas, como:
Administración de identidades.
Topología de red.
Administración de secretos y administración de claves.
Orígenes de datos.
Automatización y programación de trabajos.
Repositorio de origen e canalizaciones de implementación como GitHub y Azure DevOps.
La detección temprana de interrupciones también es una manera de reducir significativamente los valores de RTO y RPO. Incluya los siguientes factores clave:
Defina qué es una interrupción y cómo se asigna a la definición de una interrupción según Microsoft. La definición de Microsoft está disponible en la página Acuerdo de nivel de servicio (SLA) de Azure en el nivel de producto o servicio.
Implemente un sistema de supervisión y alertas eficaz con equipos responsable que revisen las métricas y las alertas rápidamente para admitir el objetivo.
Para el diseño de la suscripción, la infraestructura adicional para la recuperación ante desastres se puede almacenar en la suscripción original. Los servicios de plataforma como servicio, como Azure Data Lake Storage y Azure Data Factory, suelen incluir características de conmutación por error nativas. Estas funcionalidades permiten instancias secundarias en otras regiones mientras permanecen dentro de la suscripción original. Para optimizar los costos, algunas organizaciones pueden optar por asignar un grupo de recursos dedicado exclusivamente para los recursos relacionados con la recuperación ante desastres.
Los límites de suscripción pueden introducir restricciones en este enfoque.
Otras restricciones pueden incluir la complejidad del diseño y los controles de administración para asegurarse de que los grupos de recursos de recuperación ante desastres no se usan para flujos de trabajo empresariales como habituales.
Diseñe el flujo de trabajo de recuperación ante desastres en función de la importancia y las dependencias de una solución. Por ejemplo, no intente volver a generar una instancia de Azure Analysis Services antes de que el almacenamiento de datos esté operativo porque desencadena un error. Deje primero los laboratorios de desarrollo para más adelante en el proceso y recupere las soluciones empresariales principales.
Identifique las tareas de recuperación que se pueden paralelizar entre soluciones. Este enfoque reduce el RTO total.
Si Azure Data Factory se usa en una solución, no olvide incluir entornos de ejecución de integración autohospedados en el ámbito. Azure Site Recovery es ideal para estas máquinas.
Automatice las operaciones manuales tanto como sea posible para evitar errores humanos, especialmente cuando están bajo presión. Le recomendamos que:
Adopte el aprovisionamiento de recursos mediante Bicep, plantillas de Azure Resource Manager o scripts de PowerShell.
Adoptar el control de versiones del código fuente y la configuración de recursos.
Use canalizaciones de versión de entrega continua e integración continua en lugar de select-ops.
Dado que tiene un plan para la conmutación por error, debe tener en cuenta los procedimientos para revertir a las instancias principales.
Defina indicadores claros y métricas para validar que la conmutación por error es correcta y que las soluciones están operativas. Confirme que el rendimiento vuelve a ser normal, también conocido como funcional principal.
Decida si los Acuerdos de Nivel de Servicio deben permanecer sin cambios después de una conmutación por error o si permite una reducción temporal de la calidad del servicio. Esta decisión depende en gran medida del proceso de servicio empresarial que se admita. Por ejemplo, la conmutación por error de un sistema de reserva de habitaciones es muy diferente de un sistema operativo principal.
Base una definición de RTO o RPO en escenarios de usuario específicos en lugar de en el nivel de infraestructura. Este enfoque proporciona mayor granularidad en cómo determinar qué procesos y componentes debe priorizar para la recuperación durante una interrupción o desastre.
Asegúrese de realizar comprobaciones de capacidad en la región de destino antes de continuar con una conmutación por error. En un desastre importante, muchos clientes podrían intentar conmutar por error a la misma región emparejada simultáneamente. Este escenario puede provocar retrasos o contención en el aprovisionamiento de recursos. Si estos riesgos son inaceptables, considere una estrategia de recuperación ante desastres activa/activa o activa/pasiva.
Debe crear y mantener un plan de recuperación ante desastres para documentar el proceso de recuperación y los propietarios de la acción. Tenga en cuenta que algunos miembros del equipo pueden estar de vacaciones y asegurarse de que se incluyen los contactos secundarios.
Realice simulacros de recuperación ante desastres normales para validar el flujo de trabajo del plan de recuperación ante desastres, asegúrese de que cumple los requisitos de RTO y RPO necesarios y entrene a los equipos responsables. Pruebe periódicamente los datos y las copias de seguridad de configuración para asegurarse de que son adecuados para fines, lo que significa que son adecuados y eficaces para su uso previsto. Este proceso garantiza que pueden admitir actividades de recuperación.
La colaboración temprana con los equipos responsables de redes, identidades y aprovisionamiento de recursos facilita el acuerdo sobre la solución más óptima para:
Redirigir usuarios y tráfico desde el sitio principal al sitio secundario. Se pueden evaluar conceptos como el redireccionamiento del sistema de nombres de dominio o el uso de herramientas específicas, como Azure Traffic Manager .
Proporcionar acceso y derechos al sitio secundario de forma oportuna y segura.
Durante un desastre, la comunicación eficaz entre las muchas partes implicadas es clave para la implementación eficaz y rápida del plan. Teams puede incluir:
- Responsables de la toma de decisiones.
- Equipos de respuesta a incidentes.
- Usuarios y equipos internos afectados.
- Equipos externos.
La orquestación de los distintos recursos en el momento adecuado garantiza la eficacia en la implementación del plan de recuperación ante desastres.
Consideraciones
Antipatrones
Copiar y pegar esta serie de artículos
En esta serie de artículos se proporcionan instrucciones para los clientes que buscan una comprensión más profunda de un proceso de recuperación ante desastres específico de Azure. Se basa en la propiedad intelectual genérica de Microsoft y las arquitecturas de referencia en lugar de en cualquier implementación de Azure específica del cliente única.
Este contenido proporciona una sólida comprensión fundamental. Sin embargo, los clientes deben adaptar su enfoque considerando su contexto, implementación y requisitos únicos para desarrollar una estrategia y un proceso de recuperación ante desastres específicos.
Tratar la recuperación ante desastres como un proceso de solo tecnología
Las partes interesadas empresariales son cruciales para definir los requisitos de recuperación ante desastres y completar los pasos de validación empresarial necesarios para confirmar una recuperación del servicio.
Asegurarse de que las partes interesadas de la empresa están comprometidas en todas las actividades de recuperación ante desastres proporciona un proceso de recuperación ante desastres que se ajusta a propósito, representa el valor empresarial y se puede implementar.
Planes de recuperación ante desastres "Establecer y olvidar"
Azure está evolucionando constantemente, ya que es la forma en que los clientes individuales usan varios componentes y servicios. Un proceso de recuperación ante desastres específico debe evolucionar con ellos.
Los clientes deben volver a evaluar periódicamente su plan de recuperación ante desastres a través del ciclo de vida de desarrollo de software o las revisiones periódicas. Esta estrategia mantiene el plan de recuperación del servicio válido y soluciona correctamente los cambios en los componentes, servicios o soluciones.
Evaluaciones basadas en papel
La simulación de un extremo a otro de un evento de recuperación ante desastres es difícil de realizar en un ecosistema de datos moderno. Sin embargo, se deben realizar esfuerzos para acercarse lo más posible a una simulación completa en los componentes afectados.
Los simulacros programados periódicamente ayudan a una organización a desarrollar la capacidad instintiva de implementar con confianza el plan de recuperación ante desastres.
Confiar en Microsoft para hacerlo todo
Dentro de los servicios de Microsoft Azure, hay una división clara de responsabilidad, anclada por el nivel de servicio en la nube usado.
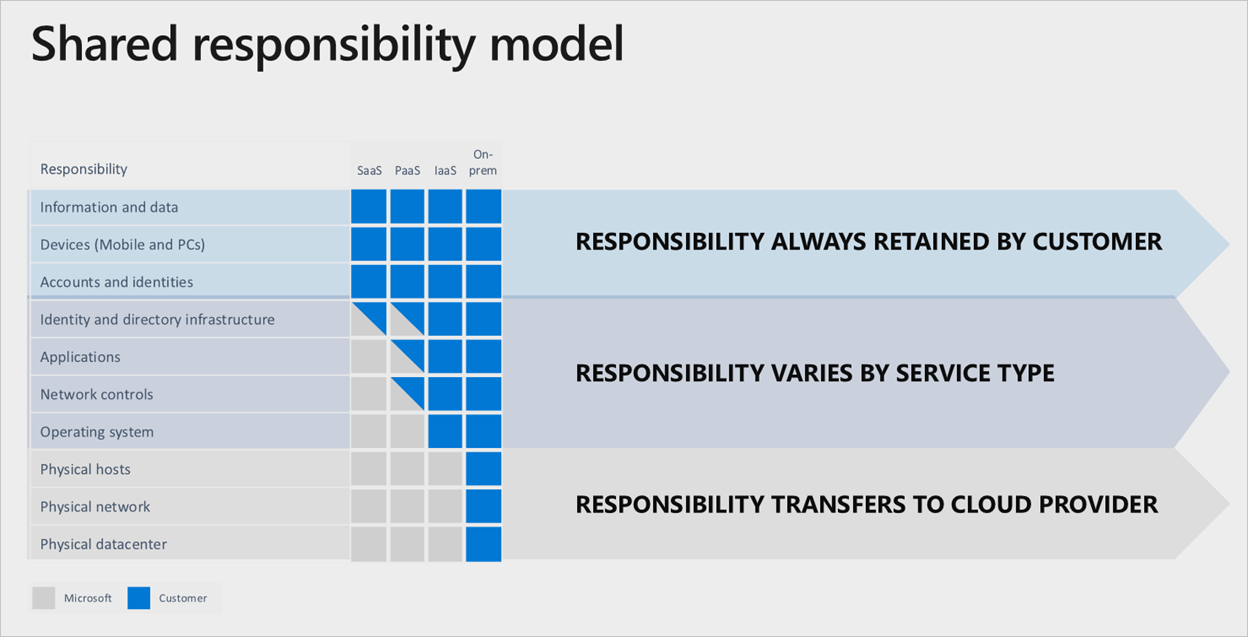
Incluso si se usa una pila de software como servicio completa, el cliente conserva la responsabilidad de asegurarse de que las cuentas, las identidades y los datos son correctos y up-to-date, junto con los dispositivos usados para interactuar con los servicios de Azure.
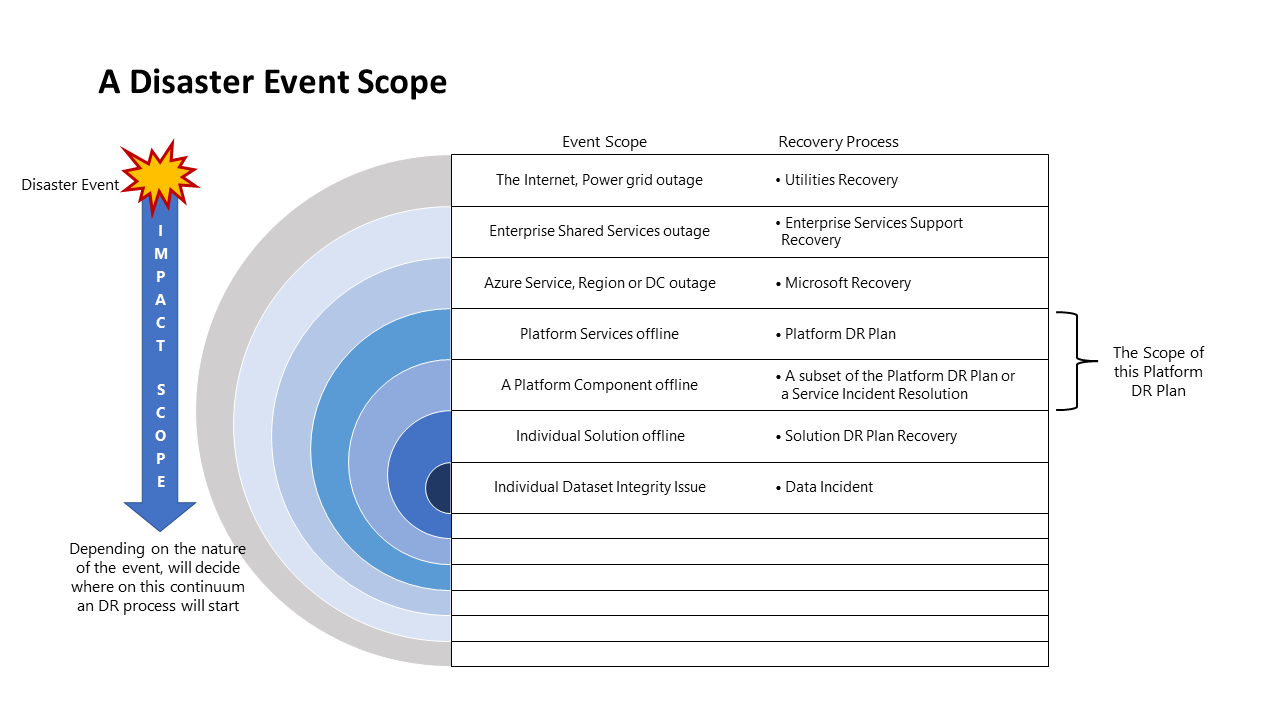
Estrategia y ámbito del evento
Ámbito del evento de desastre
Los distintos eventos tienen distintos ámbitos de impacto que requieren respuestas diferentes. En el diagrama siguiente se muestra el ámbito de impacto y respuesta de un evento de desastre.
Opciones de estrategia ante desastres
Hay cuatro opciones de alto nivel para una estrategia de recuperación ante desastres:
Esperar a Microsoft
Como sugiere el nombre, la solución está sin conexión hasta la recuperación completa de los servicios de la región afectada por Microsoft. Después de la recuperación, el cliente valida la solución y, a continuación, se actualiza para ayudar a garantizar la recuperación del servicio.
Reimplementación en caso de desastre
La solución se vuelve a implementar manualmente como una nueva implementación en una región disponible después de un evento de desastre.
Reserva activa (activa/pasiva)
Se crea una solución hospedada secundaria en una región alternativa y los componentes se implementan para garantizar una capacidad mínima. Sin embargo, los componentes no reciben tráfico de producción.
Los servicios secundarios de la región alternativa pueden desactivarse o ejecutarse en un nivel de rendimiento inferior hasta que se produzca un evento de recuperación ante desastres.
Reserva activa (activa/activa)
La solución se hospeda en una configuración activa o activa en varias regiones. La solución hospedada secundaria recibe, procesa y actúa como parte del sistema más grande.
Efectos de la estrategia de recuperación ante desastres
El costo operativo que se atribuye a los niveles más altos de resistencia del servicio suele desempeñar un papel importante en la decisión clave de diseño de una estrategia de recuperación ante desastres, pero también se deben tener en cuenta otros factores importantes.
Nota:
La optimización de costos es uno de los cinco pilares de excelencia arquitectónica dentro de Azure Well-Architected Framework. Su objetivo es reducir los gastos innecesarios y mejorar las eficiencias operativas.
El escenario de recuperación ante desastres de este ejemplo de trabajo es una interrupción regional completa de Azure que afecta directamente a la región primaria que hospeda la plataforma de datos de Contoso.
La tabla siguiente es una comparación entre las opciones. Una estrategia que tiene un indicador verde es mejor para esa clasificación que una estrategia que tiene un indicador rojo o naranja.
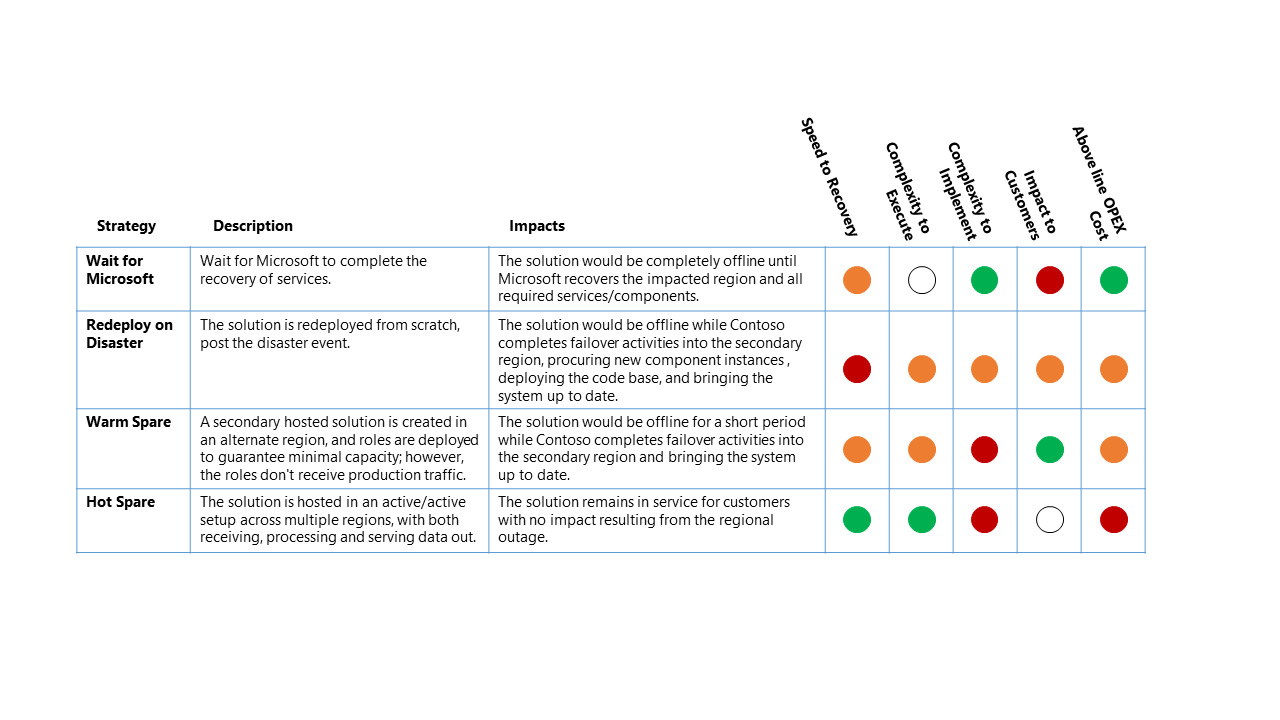
Clave de clasificación
En este escenario de interrupción, el impacto relativo en las cuatro estrategias de recuperación ante desastres de alto nivel se basa en los siguientes factores:
RTO: Tiempo transcurrido esperado desde el evento de desastre hasta la recuperación del servicio de plataforma.
Complejidad que se va a ejecutar: La complejidad de la organización para llevar a cabo las actividades de recuperación.
Complejidad que se va a implementar: la complejidad de la organización para implementar la estrategia de recuperación ante desastres.
Impacto en el cliente: Impacto directo a los clientes del servicio de plataforma de datos de la estrategia de recuperación ante desastres.
Costo de OPEX por encima de la línea: El costo adicional esperado de la implementación de esta estrategia, como el aumento de la facturación mensual de Azure para componentes adicionales y recursos adicionales necesarios para admitir.
Pasos siguientes
- Carga de trabajo crítica
- recomendaciones deWell-Architected Framework para diseñar una estrategia de recuperación ante desastres