Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Microsoft Fabric
Azure Data Factory
Normalmente, las organizaciones necesitan recopilar datos de varios orígenes en varios formatos y moverlos a uno o varios almacenes de datos. Es posible que el destino no sea el mismo tipo de almacén de datos que el origen, y los datos a menudo deben dar forma, limpiarse o transformarse antes de cargarlos.
Varias herramientas, servicios y procesos ayudan a abordar estos desafíos. Independientemente del enfoque, debe coordinar el trabajo y aplicar transformaciones de datos dentro de la canalización de datos. En las secciones siguientes se resaltan los métodos y procedimientos comunes para estas tareas.
Proceso de extracción, transformación y carga (ETL)
Extraer, transformar, cargar (ETL) es un proceso de integración de datos que consolida los datos de diversos orígenes en un almacén de datos unificado. Durante la fase de transformación, los datos se modifican según las reglas de negocios mediante un motor especializado. Esto suele implicar tablas de almacenamiento provisional que contienen temporalmente datos a medida que se procesan y, en última instancia, se cargan en su destino.
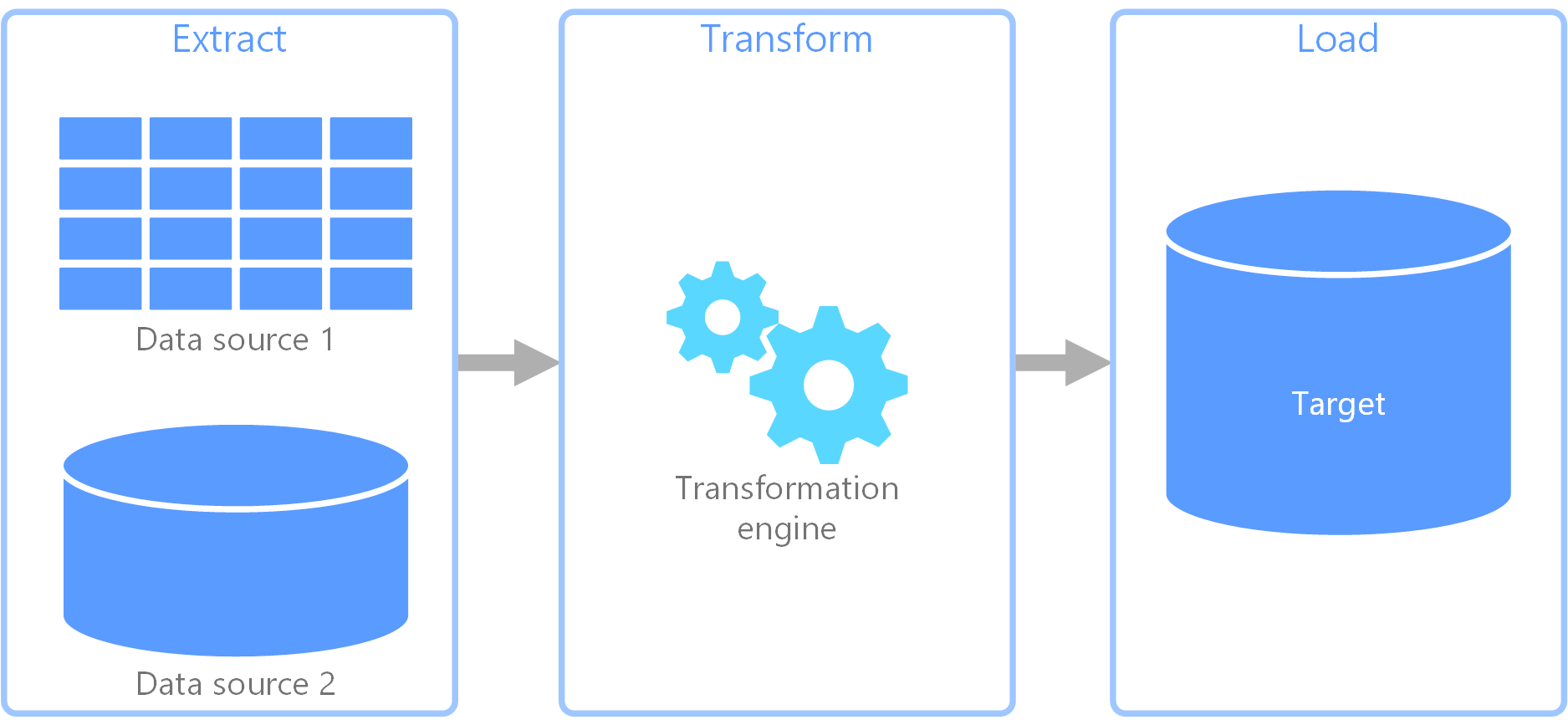
La transformación de datos que tiene lugar a menudo conlleva varias operaciones como filtrado, ordenación, agregación, combinación de datos, limpieza de datos, desduplicación y validación de datos.
A menudo, las tres fases ETL se ejecutan en paralelo para ahorrar tiempo. Por ejemplo, mientras se extraen los datos, un proceso de transformación puede trabajar en los datos ya recibidos y prepararlos para cargarlos, y un proceso de carga puede comenzar a trabajar en los datos preparados, en lugar de esperar a que se complete todo el proceso de extracción. Normalmente, se diseña la paralelización en torno a los límites de la partición de datos (fecha, inquilino, clave de partición) para evitar la contención de escritura y habilitar reintentos idempotentes.
Servicio pertinente:
Otras herramientas:
Extracción, carga y transformación (ELT)
Extracción, carga y transformación (ELT) difiere de ETL solo por la ubicación en la que se realiza la transformación. En la canalización de ELT, la transformación se produce en el almacén de datos de destino. En lugar de usar un motor de transformación independiente, las funcionalidades de procesamiento del almacén de datos de destino se utilizan para transformar los datos. Esto simplifica la arquitectura ya que permite quitar el motor de transformación de la canalización. Otra ventaja de este enfoque es que al escalar el almacén de datos de destino también se escala el rendimiento de la canalización de ELT. No obstante, ELT solo funciona bien si el sistema de destino tiene la suficiente potencia para transformar los datos de forma eficaz.
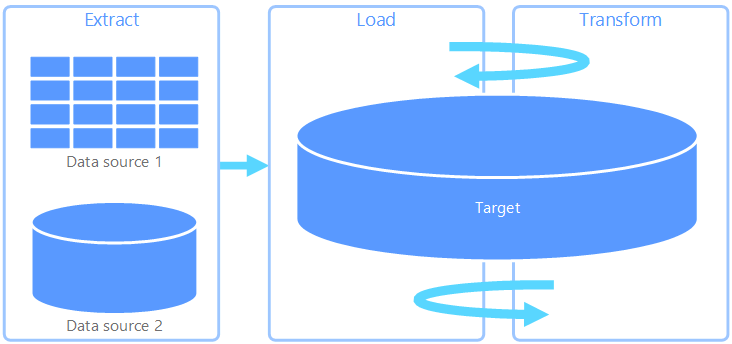
Los casos de uso habituales para ELT están dentro del dominio de los macrodatos. Por ejemplo, puede empezar extrayendo datos de origen a archivos planos en almacenamiento escalable, como un sistema de archivos distribuido de Hadoop (HDFS), Azure Blob Storage o Azure Data Lake Storage Gen2. Después, se pueden usar tecnologías como Spark, Hive o PolyBase para consultar los datos de origen. El punto clave de ELT es que el almacén de datos que se usa para realizar la transformación es el mismo almacén de datos en el que se consumen en última instancia los datos. Este almacén de datos lee directamente desde el almacenamiento escalable, en lugar de cargar los datos en su propio almacenamiento independiente. Este enfoque omite los pasos de copia de datos presentes en ETL, que a menudo pueden llevar mucho tiempo para grandes conjuntos de datos. Algunas cargas de trabajo materializan tablas o vistas transformadas para mejorar el rendimiento de las consultas o aplicar reglas de gobernanza; ELT no siempre implica transformaciones puramente virtualizadas.
La fase final de la canalización ELT normalmente transforma los datos de origen en un formato más eficaz para los tipos de consultas que deben admitirse. Por ejemplo, los datos se pueden particionar mediante claves filtradas normalmente. ELT también puede usar formatos de almacenamiento optimizados como Parquet, que es un formato de almacenamiento en columnas que organiza los datos por columna para habilitar la compresión, la inserción de predicados y exámenes analíticos eficaces.
Servicio de Microsoft pertinente:
- Almacenamiento de datos de Microsoft Fabric
- Microsoft Fabric Lakehouse
- Canalizaciones de datos de Microsoft Fabric
Elección de ETL o ELT
La elección entre estos enfoques depende de sus requisitos.
Elija ETL cuando:
- Debe descargar transformaciones pesadas lejos de un sistema de destino restringido.
- Las reglas de negocio complejas requieren motores de transformación especializados
- Los requisitos normativos o de cumplimiento exigen auditorías de almacenamiento provisional mantenidos antes de cargar
Elija ELT cuando:
- El sistema de destino es un almacenamiento de datos moderno o un lago con escalado de proceso elástico
- Debe conservar los datos sin procesar para el análisis exploratorio o la evolución futura del esquema.
- La lógica de transformación se beneficia de las funcionalidades nativas del sistema de destino
Flujo de datos y flujo de control
En el contexto de las canalizaciones de datos, el flujo de control garantiza el procesamiento ordenado de un conjunto de tareas. Para aplicar el orden de procesamiento correcto de estas tareas, se usan las restricciones de precedencia. Puede considerar estas restricciones como conectores en un diagrama de flujo de trabajo, como se muestra en la siguiente imagen. Cada tarea tiene un resultado como, por ejemplo, correcto, error o conclusión. Cualquier tarea posterior no inicia el procesamiento hasta que su predecesor se haya completado con uno de estos resultados.
Los flujos de control ejecutan flujos de datos como una tarea. En una tarea Flujo de datos, los datos se extraen de un origen, se transforman o se cargan en un almacén de datos. La salida de una tarea Flujo de datos puede ser la entrada de la siguiente tarea, y los flujos de datos se pueden ejecutar en paralelo. A diferencia de los flujos de control, no se pueden agregar restricciones entre las tareas de un flujo de datos. Sin embargo, puede agregar un visor de datos para observar los datos a medida que cada tarea los va procesando.
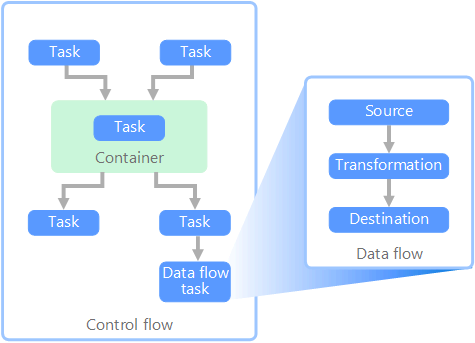
En el diagrama, hay varias tareas dentro del flujo de control, una de las cuales es una tarea de flujo de datos. Una de las tareas se anida dentro de un contenedor. Los contenedores se pueden usar para proporcionar una estructura para las tareas, proporcionando una unidad de trabajo. Un ejemplo es la repetición de elementos en una colección, como los archivos de una carpeta o las instrucciones de una base de datos.
Servicio pertinente:
ETL inverso
ETL inverso es el proceso de mover datos transformados y modelados de sistemas analíticos a herramientas y aplicaciones operativas. A diferencia de ETL tradicional, que fluye datos de sistemas operativos a análisis, ETL inverso activa la información mediante la inserción de datos mantenidos en la ubicación en la que los usuarios empresariales pueden actuar en él. En una canalización ETL inversa, los datos fluyen desde almacenes de datos, lakehouses u otros almacenes analíticos a sistemas operativos como:
- Plataformas de administración de relaciones con clientes (CRM)
- Herramientas de automatización de marketing
- Sistemas de soporte técnico al cliente
- Bases de datos de carga de trabajo
El enfoque sigue un proceso de extracción, transformación y carga. El paso de transformación es donde se convierte desde el formato específico usado por el almacenamiento de datos u otro sistema de análisis para alinearse con el del sistema de destino.
Consulte Extracción inversa, transformación y carga (ETL) con Azure Cosmos DB para NoSQL para obtener un ejemplo.
Arquitecturas de ruta de acceso activa y datos de streaming
Cuando necesite una ruta de acceso activa lambda o arquitecturas kappa, puede suscribirse a orígenes de datos a medida que se generan datos. A diferencia de ETL o ELT, que operan en conjuntos de datos en lotes programados, el streaming en tiempo real procesa los datos a medida que llega, lo que permite información inmediata y acciones.
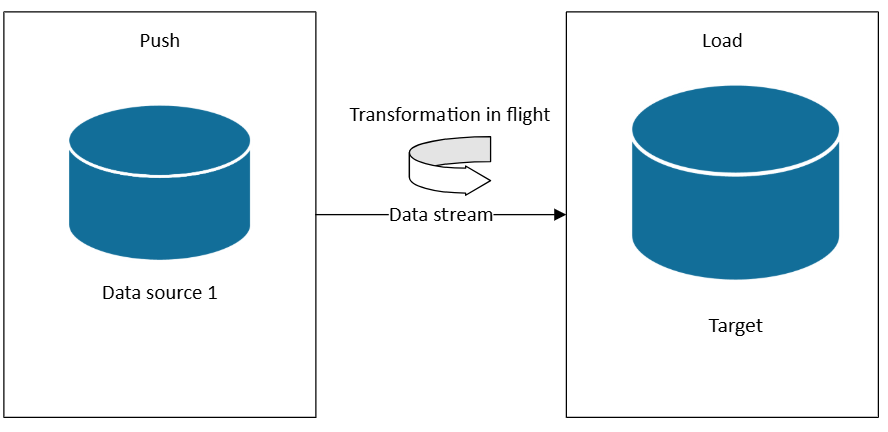
En una arquitectura de streaming, los datos se ingieren desde orígenes de eventos en un agente de mensajes o un centro de eventos (como Azure Event Hubs o Kafka), y luego se procesan mediante un procesador de flujos (como Fabric Real-Time Intelligence, Azure Stream Analytics o Apache Flink). El procesador aplica transformaciones como el filtrado, la agregación, el enriquecimiento o la combinación con datos de referencia (todo en movimiento) antes de enrutar los resultados a sistemas de bajada, como paneles, alertas o bases de datos.
Este enfoque es ideal para escenarios en los que la baja latencia y las actualizaciones continuas son críticas, como:
- Supervisión de equipos de fabricación para detectar anomalías
- Detección de fraudes en transacciones financieras
- Alimentación de paneles en tiempo real para logística o operaciones
- Desencadenar alertas basadas en umbrales de sensor
Consideraciones de confiabilidad para el streaming
- Uso de puntos de comprobación para garantizar el procesamiento al menos una vez y recuperarse de errores
- Transformaciones de diseño que son idempotentes para controlar el posible procesamiento duplicado
- Implementación de marcas de agua para eventos de llegada tardía y procesamiento desordenado
- Usar colas de mensajes fallidos para mensajes que no se pueden procesar
Opciones de tecnología
Almacenes de datos:
- Almacenes de datos de procesamiento de transacciones en línea (OLTP)
- Almacenes de datos de procesamiento analítico en línea (OLAP)
- Almacenamientos de datos
Canalización y orquestación:
- Orquestación de canalizaciones
- Microsoft Fabric Data Factory (orquestación moderna)
- Azure Data Factory (escenarios híbridos y que no son de Fabric)
Lakehouse y análisis modernos: