Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
El procesamiento de lenguaje natural abarca técnicas que analizan, comprenden y generan lenguaje humano a partir de datos de texto. Azure proporciona servicios administrados basados en API y marcos de código abierto distribuidos que abordan cargas de trabajo de procesamiento de lenguaje natural que van desde el análisis de sentimiento y el reconocimiento de entidades hasta la clasificación de documentos y el resumen de texto. Esta guía le ayuda a evaluar y elegir entre las opciones principales de procesamiento de lenguaje natural en Azure para que pueda coincidir con la tecnología adecuada para sus requisitos de carga de trabajo.
Nota:
Esta guía se centra en las funcionalidades de procesamiento de lenguaje natural disponibles a través de Azure Language y Apache Spark con Spark NLP en Azure Databricks o Microsoft Fabric. No proporciona instrucciones sobre cómo seleccionar modelos de lenguaje o diseñar Azure soluciones de OpenAI. Algunas descripciones de la plataforma pueden hacer referencia a integraciones compatibles con el modelo de base o el modelo de voz como detalles de implementación, pero esta guía se centra en la selección del servicio de procesamiento de lenguaje natural. Para más información, consulte Elección de una tecnología de servicios de inteligencia artificial.
Comprender el procesamiento de lenguaje natural y los modelos lingüísticos
Antes de evaluar Azure servicios, comprenda qué es el procesamiento de lenguaje natural, cómo difiere de los modelos de lenguaje y qué tareas aborda.
Distinguir el procesamiento de lenguaje natural de los modelos de lenguaje
En esta sección se aclara el límite entre el procesamiento de lenguaje natural y los modelos de lenguaje, y se analizan las funcionalidades principales que permiten las técnicas de procesamiento de lenguaje natural.
| Dimensión | Procesamiento de lenguaje natural | Modelos de lenguaje |
|---|---|---|
| Ámbito | Un amplio campo que abarca diversas técnicas de procesamiento de texto, como la tokenización, la lematización, el reconocimiento de entidades, el análisis de sentimiento y la clasificación de documentos. | Un subconjunto de aprendizaje profundo del procesamiento de lenguaje natural centrado en tareas de generación y comprensión del lenguaje de alto nivel. |
| Ejemplos | Analizadores basados en reglas, clasificadores de frecuencia de término-inversa de frecuencia de documento (TF-IDF), reconocedores de entidades nombradas, analizadores de sentimiento. | GPT, BERT y modelos similares basados en transformadores que generan texto parecido al humano y consciente del contexto. |
| Salida | Señales estructuradas como etiquetas, puntuaciones, intervalos extraídos y sintaxis analizada. | Lenguaje natural fluido, como texto generado, resúmenes, respuestas y completaciones. |
| Relación | Dominio primario. El procesamiento de lenguaje natural abarca todo el espectro de métodos de procesamiento de texto. | Una herramienta dentro del procesamiento de lenguaje natural. Los modelos de lenguaje mejoran el procesamiento de lenguaje natural sin reemplazarlo. Controlan tareas cognitivas más amplias, pero no son sinónimos de procesamiento de lenguaje natural. |
Funcionalidades de procesamiento de lenguaje natural
Clasifique documentos etiquetandolos como confidenciales o no deseados. El procesamiento de lenguaje natural clasifica automáticamente los documentos en función del contenido para admitir el cumplimiento y el filtrado de flujos de trabajo.
Resumir texto mediante la identificación de entidades en el documento. El procesamiento de lenguaje natural extrae entidades clave para generar resúmenes concisos que capturan la información más importante.
Etiquete documentos con palabras clave mediante entidades identificadas. Después de identificar las entidades, puede generar etiquetas de palabra clave que simplifican la organización del documento. Use estas etiquetas para la búsqueda y recuperación basadas en contenido.
Detectar temas para la navegación y el descubrimiento de documentos relacionados. El procesamiento de lenguaje natural identifica temas clave mediante entidades extraídas, que admite la categorización de documentos y la navegación basada en temas.
Evaluar el sentimiento del texto. El análisis de sentimiento evalúa el tono emocional del texto y clasifica el contenido como positivo, negativo o neutro.
Introducir salidas del procesamiento de lenguaje natural en flujos de trabajo posteriores. Los resultados, como las entidades extraídas, las puntuaciones de opinión y las etiquetas de tema, sirven como entradas para el procesamiento, la indexación de búsqueda y el análisis.
Identificación de posibles casos de uso
Los escenarios empresariales de muchos sectores se benefician de las soluciones de procesamiento de lenguaje natural. Los siguientes casos de uso muestran cómo las técnicas de procesamiento de lenguaje natural abordan los desafíos del mundo real, desde el procesamiento de documentos no estructurados hasta la habilitación de aplicaciones emergentes en ciberseguridad y accesibilidad.
Procesar documentos y texto no estructurado
Extraiga la inteligencia de los documentos creados por la máquina. El procesamiento de lenguaje natural permite el procesamiento de documentos en todo el sector financiero, sanitario, minorista, gubernamental y otros sectores. Puede analizar documentos creados digitalmente para extraer información estructurada de entradas no estructuradas. Para los documentos manuscritos, use Azure Document Intelligence para convertir contenido manuscrito en texto antes de aplicar técnicas de procesamiento de lenguaje natural.
Aplicar tareas de procesamiento de lenguaje natural independientes del sector para el procesamiento de texto. El reconocimiento de entidades con nombre (NER), la clasificación, el resumen y la extracción de relaciones le ayudan a procesar y analizar automáticamente el contenido del documento no estructurado. Estas tareas funcionan entre dominios y no requieren personalización específica del sector.
Cree modelos específicos del dominio para el análisis especializado. Algunos ejemplos de estas tareas son los modelos de estratificación de riesgos para la atención sanitaria, la clasificación de la ontología para la administración de conocimientos y los resúmenes comerciales de los datos de productos y clientes. El entrenamiento del modelo personalizado en Azure Language y NLP de Spark ayuda a mejorar la precisión de estos formatos de documento específicos del dominio.
Genere informes automatizados a partir de entradas de datos estructurados. Puede sintetizar y generar informes textuales completos a partir de datos estructurados. Esta funcionalidad ayuda a sectores como finanzas y cumplimiento que requieren documentación exhaustiva.
Habilitación de la búsqueda, traducción y análisis
Cree gráficos de conocimiento y habilite la búsqueda semántica a través de la recuperación de información. El procesamiento de lenguaje natural admite la creación del grafo de conocimiento y la búsqueda semántica, lo que permite a los sistemas interpretar el significado de la consulta en lugar de confiar solo en la coincidencia de palabras clave.
Apoyar la detección de medicamentos y ensayos clínicos con gráficos de conocimientos médicos. Los sistemas de procesamiento de lenguaje natural analizan el texto clínico. Gráficos de conocimientos médicos creados a partir de ese texto admiten canalizaciones de detección de medicamentos y coincidencias de ensayos clínicos. Estos gráficos conectan entidades como medicamentos, condiciones y resultados para acelerar los flujos de trabajo de investigación. Análisis de texto para salud en Azure Language extrae entidades médicas, relaciones y aseveraciones que puede usar para construir estos gráficos.
Traducir texto para IA de conversación en aplicaciones de cara al cliente. La traducción de texto permite la inteligencia artificial conversacional en varios sectores. Puede crear aplicaciones multilingües orientadas al cliente que procesen y respondan en el idioma preferido del usuario. Spark NLP proporciona funcionalidades de traducción directamente. En Azure, use Azure Translator, que es un servicio independiente del lenguaje Azure.
Analice la opinión y la inteligencia emocional para la percepción de la marca. El análisis de sentimiento le ayuda a supervisar la percepción de la marca y analizar los comentarios de los clientes al exponer señales emocionales positivas, negativas y matizadas a partir del texto.
Ampliación del procesamiento de lenguaje natural a dominios emergentes
Crear interfaces activadas por voz para Internet de las cosas (IoT) y dispositivos inteligentes. El procesamiento de lenguaje natural controla la salida de texto de los sistemas de reconocimiento de voz para comprender la intención del usuario y extraer el significado en escenarios de IoT y dispositivos inteligentes. Los escenarios activados por voz requieren Azure Voz para la conversión de voz a texto antes del procesamiento de lenguaje natural.
Ajuste la salida del lenguaje dinámicamente mediante modelos de lenguaje adaptable. Los modelos de lenguaje adaptable ajustan dinámicamente la salida del idioma para adaptarse a diferentes niveles de comprensión de audiencia, que admiten la entrega de contenido educativo y la accesibilidad.
Detecte la suplantación de identidad (phishing) y la información incorrecta a través del análisis de texto de ciberseguridad. El procesamiento de lenguaje natural analiza los patrones de comunicación y el uso del lenguaje en tiempo real para identificar posibles amenazas de seguridad en la comunicación digital. Este análisis ayuda a detectar intentos de suplantación de identidad y campañas de información incorrecta.
Evaluar Azure Idioma
Azure Language es un servicio basado en la nube que proporciona características de procesamiento de lenguaje natural para comprender y analizar texto. Puede acceder a él a través del portal de Foundry, las API REST y las bibliotecas cliente de Python, C#, Java y JavaScript sin infraestructura para administrar. Para el desarrollo del agente de IA, también puede acceder a estas funcionalidades a través del servidor de protocolo de contexto del modelo de lenguaje (MCP) de Azure. Puede acceder a él como servidor remoto en el catálogo de herramientas de Microsoft Foundry o como un servidor autohospedado local.
Características precompiladas
Las características precompiladas no requieren ningún entrenamiento del modelo y están listos para usarse:
NER: Identifica y clasifica las entidades en texto en tipos predefinidos, como personas, organizaciones, ubicaciones y fechas.
Detección de PII: Identifica y redacta información de identificación personal (PII), incluidos datos personales y de salud confidenciales, en texto y conversaciones transcritas.
Detección de idioma: Detecta el idioma de un documento en una amplia gama de idiomas y dialectos.
Análisis de sentimiento y minería de opiniones: Identifica opiniones positivas, negativas o neutrales en texto y vincula opiniones a elementos específicos, como atributos de producto o aspectos de servicio.
Extracción de frases clave: Evalúa el texto no estructurado y devuelve una lista de conceptos principales y frases clave.
Resumen: Condensa documentos y conversaciones mediante enfoques extractivos o abstractos, que admiten el resumen de texto, chat y centro de llamadas.
Análisis de texto para el estado: Extrae y etiqueta la información sanitaria pertinente del texto clínico no estructurado, incluidas las entidades médicas, las relaciones y las aserciones.
Entrenamiento de modelos personalizados
Puede usar características personalizables para entrenar modelos en los datos para controlar tareas de procesamiento de lenguaje natural específicas del dominio:
- Reconocimiento de entidades con nombre (CNER) personalizado: Cree modelos personalizados para extraer categorías de entidades específicas del dominio a partir de texto no estructurado. Use CNER cuando las categorías NER precompiladas no cubran el vocabulario del dominio.
Azure language MCP server and agents (Servidor MCP de lenguaje de Azure y agentes)
Nota:
El servidor MCP de lenguaje de Azure y los agentes de enrutamiento de intenciones y de respuesta de preguntas exactas están en versión preliminar. Las características en versión preliminar no incluyen un contrato de nivel de servicio (SLA) y no se recomiendan para cargas de trabajo de producción. Es posible que algunas características no sean compatibles o que tengan funcionalidades limitadas. Para obtener más información, vea Supplemental terms of use for Microsoft Azure previews.
Azure Language proporciona agentes precompilados y opciones de implementación flexibles para cargas de trabajo de procesamiento de lenguaje natural de producción:
Agente de enrutamiento de intenciones: Administra los flujos de conversación. Comprende las intenciones y las rutas del usuario a respuestas precisas mediante lógica determinista y auditable. Use este agente cuando necesite enrutamiento conversacional transparente y determinista.
Agente exacto de respuesta a preguntas: Proporciona respuestas confiables palabra por palabra a preguntas cruciales para el negocio, al tiempo que mantiene la supervisión humana y el control de calidad. Use este agente cuando la precisión y la coherencia de la respuesta sean esenciales.
Puede acceder a ambos agentes a través del catálogo de herramientas Foundry. Para obtener más información, consulte servidor MCP de lenguaje de Azure y agentes (versión preliminar).
El servidor MCP de lenguaje Azure admite varias opciones de implementación:
Servidor MCP hospedado en la nube remoto: El catálogo de herramientas Foundry enumera este servidor. El servidor proporciona acceso administrado en la nube a las funcionalidades de lenguaje Azure y no requiere ninguna infraestructura local.
Servidor MCP autohospedado local: Admite implementaciones locales o autoadministrados para los requisitos de cumplimiento, seguridad o residencia de datos.
Implementación en contenedores: Las siguientes características admiten la implementación en contenedores para escenarios que requieren procesamiento local o entornos aislados. Para obtener la lista completa de los contenedores de IA de Azure disponibles y su estado de disponibilidad, consulte soporte para contenedores de Azure IA.
- Análisis de opiniones
- Detección de idioma
- Extracción de frases clave
- NER
- Detección de DCP
- CNER
- Text Analytics para el mantenimiento
- Resumen (versión preliminar)
Evaluación de Apache Spark con NLP de Spark
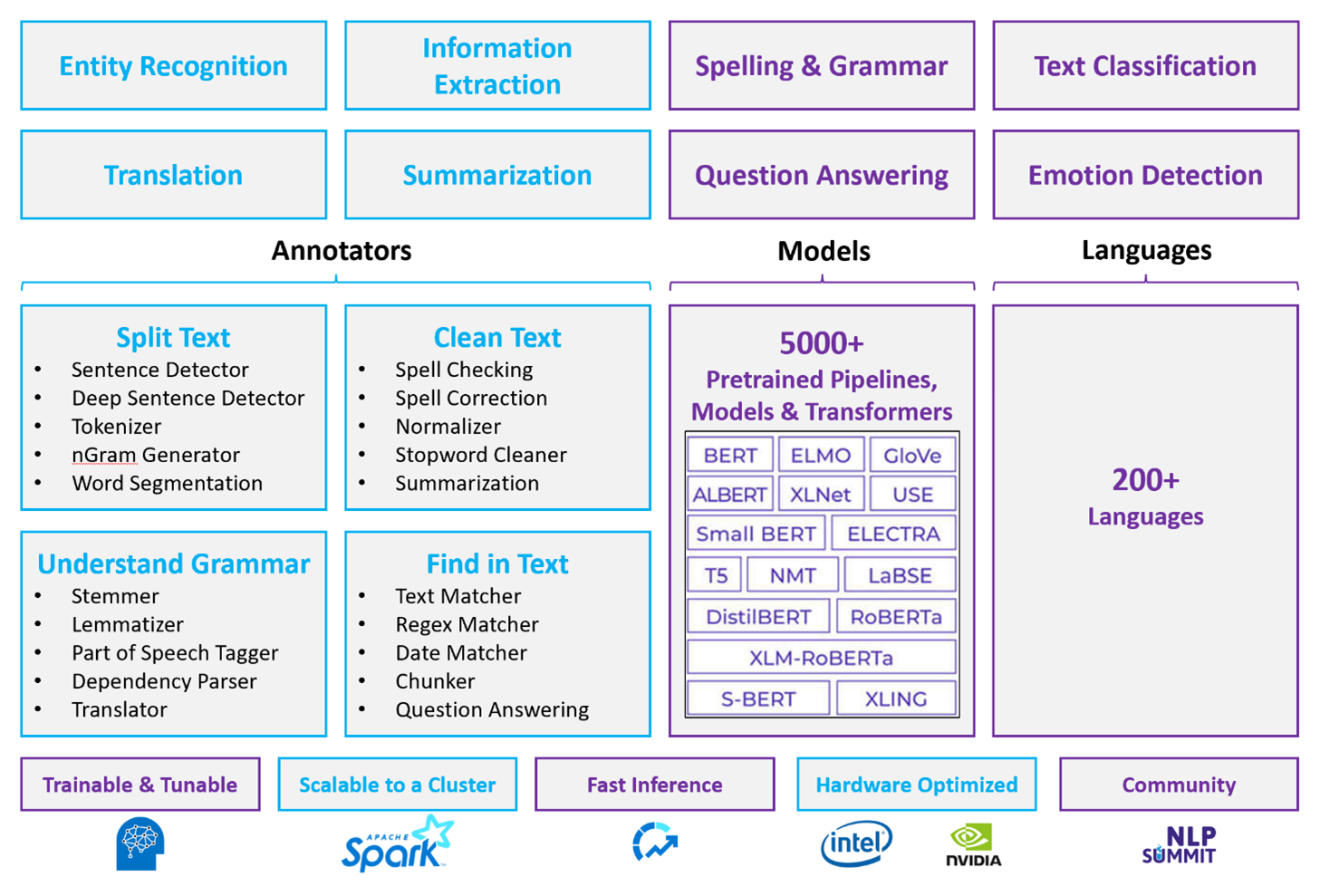
Apache Spark con Spark NLP es un enfoque distribuido y de código abierto para el procesamiento de lenguaje natural que funciona a escala de clústeres. El ecosistema del modelo precompilado, el rendimiento y la arquitectura de la plataforma NLP de Spark lo convierten en una opción segura para cargas de trabajo de procesamiento de lenguaje natural personalizables a gran escala en Azure Databricks o Fabric.
Descripción de la plataforma y la arquitectura
Se recomienda usar Fabric o Azure Databricks para cargas de trabajo de procesamiento de lenguaje natural basadas en Apache Spark.
Apache Spark proporciona procesamiento paralelo en memoria para el análisis de macrodatos. Fabric y Azure Databricks proporcionan acceso a las funcionalidades de procesamiento de Apache Spark para cargas de trabajo de procesamiento de lenguaje natural a gran escala.
Spark NLP funciona como una extensión nativa de Spark ML en tramas de datos. Esta integración permite el procesamiento unificado de lenguaje natural y las canalizaciones de aprendizaje automático con un rendimiento mejorado en clústeres distribuidos.
Spark NLP es una biblioteca de código abierto con compatibilidad con Python, Java y Scala. La biblioteca proporciona funcionalidad comparable a spaCy y Natural Language Toolkit (NLTK), incluida la revisión ortográfica, el análisis de sentimiento y la clasificación de documentos.

Apache®, Apache Spark y el logotipo de llama son marcas comerciales registradas o marcas comerciales de Apache Software Foundation en el United States y/o en otros países. El uso de estas marcas no implica ninguna aprobación de The Apache Software Foundation.
Evaluación del rendimiento y la escalabilidad
Las pruebas comparativas públicas muestran mejoras de velocidad significativas en otras bibliotecas de procesamiento de lenguaje natural. En comparación con marcos como spaCy y NLTK, Spark NLP muestra un entrenamiento e inferencia más rápidos en clústeres distribuidos. Los modelos personalizados que spark NLP entrena alcanzan niveles de precisión que coinciden con los de otros marcos de procesamiento de lenguaje natural, lo que hace que sea adecuado para cargas de trabajo de producción que requieren velocidad y precisión.
Las compilaciones optimizadas para CPU, GPU e chips Intel Xeon usan completamente clústeres de Apache Spark. Estas compilaciones permiten que el entrenamiento y la inferencia se escalen eficazmente entre los nodos del clúster.
Las incrustaciones de MPNet y ONNX admiten el procesamiento preciso y compatible con el contexto. MPNet genera representaciones de vector densos que capturan el significado semántico y la compatibilidad con ONNX le permite importar y ejecutar modelos optimizados para la inferencia.
Uso de modelos y canalizaciones creados previamente
Los modelos de aprendizaje profundo creados previamente controlan NER, clasificación de documentos y detección de sentimiento. La biblioteca incluye modelos de aprendizaje profundo precompilados.
Los modelos de lenguaje previamente entrenados admiten incrustaciones de palabras, fragmentos, oraciones y documentos. La biblioteca incluye modelos de lenguaje previamente entrenados que admiten niveles de inserción de palabras, fragmentos, oraciones y documentos. Estas incrustaciones proporcionan representaciones de vector densos que permiten tareas descendentes, como la búsqueda y clasificación de similitud.
El procesamiento unificado de lenguaje natural y las canalizaciones de aprendizaje automático admiten la clasificación de documentos y la predicción de riesgos. La integración con Spark ML admite el procesamiento unificado de lenguaje natural y las canalizaciones de aprendizaje automático para tareas como la clasificación de documentos y la predicción de riesgos. Con este enfoque unificado, puede combinar el procesamiento de texto con modelos de aprendizaje automático tradicionales en una sola canalización, lo que reduce la complejidad de la arquitectura.
Abordar los desafíos comunes de procesamiento de lenguaje natural
Tanto Azure Language y Apache Spark con Spark NLP enfrentan desafíos comunes en el procesamiento de lenguaje natural a escala. Si comprende estos desafíos, puede planear recursos, diseñar canalizaciones y establecer expectativas de precisión antes de confirmar cualquier opción.
Procesamiento de recursos
El procesamiento de texto de forma libre requiere importantes recursos computacionales y tiempo. Los documentos de texto de forma libre son costosos de cálculo y requieren mucho tiempo para analizarlos. Cada documento requiere tokenización, normalización e inferencia del modelo antes de generar resultados utilizables.
Las cargas de trabajo de NLP de Spark suelen requerir la implementación de proceso de GPU. En el caso de las canalizaciones NLP de Spark a gran escala, los clústeres acelerados por GPU en Azure Databricks o Fabric proporcionan la potencia de procesamiento paralela necesaria para el entrenamiento y la inferencia. Las optimizaciones como la cuantificación de modelos llama 3.x ayudan a reducir la superficie de memoria y a mejorar el rendimiento de estas tareas intensivas.
Azure Language requiere el planeamiento del rendimiento y la administración de cuotas. El servicio controla la administración de recursos, pero las llamadas API de gran volumen requieren un planeamiento cuidadoso del rendimiento. Supervise las tasas de solicitud con respecto a los límites de servicio y los límites de velocidad para evitar la limitación y garantizar un rendimiento de procesamiento coherente.
Normalización de documentos
Los documentos reales rara vez siguen una estructura coherente. Esta incoherencia crea desafíos para las canalizaciones de extracción y requiere estrategias deliberadas para mantener la precisión entre orígenes.
Formatos incoherentes: Sin un formato de documento estandarizado, extraer hechos específicos del texto de forma libre puede ser difícil. Por ejemplo, puede ser un desafío extraer números de factura y fechas de distintos proveedores, ya que los diseños de campo, las etiquetas y el formato varían entre orígenes.
Entrenamiento del modelo personalizado: Al entrenar modelos personalizados en Spark NLP y Azure Language, puede adaptarse a formatos de documento específicos del dominio. Al entrenar en ejemplos representativos de sus documentos reales, puede mejorar la precisión de la extracción de campos, entidades y patrones que los modelos preconstruidos no manejan bien.
Variedad y complejidad de los datos
Las diversas estructuras de documentos y los matices lingüísticos agregan complejidad. Los datos de texto del mundo real vienen en muchos formatos, estilos de escritura e idiomas. Abordar estas variaciones requiere modelos que puedan controlar la ambigüedad, la jerga, las abreviaturas y la terminología específica del dominio, a la vez que se mantiene la precisión.
Las incrustaciones de MPNet en NLP de Spark proporcionan una comprensión contextual mejorada. Las incrustaciones de MPNet capturan relaciones contextuales entre palabras y frases, lo que ayuda a las canalizaciones de NLP de Spark a controlar el texto matizado de forma más eficaz. Estas incrustaciones producen representaciones de vector densos que conservan el significado semántico en diferentes formatos de documento.
Los modelos personalizados en Azure Language se adaptan a patrones de texto específicos del dominio. Con CNER puede entrenar modelos en sus propios datos etiquetados para reconocer patrones específicos de su dominio. Este enfoque mejora la confiabilidad mediante la enseñanza del modelo para reconocer entidades y categorías que se pierden en los modelos creados previamente.
Aplicar criterios de selección de claves
Use los criterios siguientes para determinar qué opción de procesamiento de lenguaje natural Azure mejor se ajusta a sus requisitos. Cada criterio describe una característica de carga de trabajo e identifica el servicio que lo aborda.
Funcionalidades de procesamiento de lenguaje natural administrado: Use Azure Language API para el reconocimiento de entidades, la identificación de intenciones, la detección de temas o el análisis de sentimiento. Estas funcionalidades están disponibles como servicios administrados con una configuración mínima y no es necesario aprovisionar ni administrar ninguna infraestructura.
Modelos precompilados o entrenados previamente: Use Azure Language si planea usar modelos precompilados o entrenados previamente sin administrar la infraestructura. Este enfoque se adapta a conjuntos de datos pequeños a medianos y tareas estándar de procesamiento de lenguaje natural donde los modelos precompilados proporcionan una precisión suficiente. Proporciona escalado automático, seguridad integrada y precios de pago por llamada sin sobrecarga de administración de clústeres.
Entrenamiento del modelo personalizado en conjuntos de datos de texto grandes: Use Azure Databricks o Fabric con Spark NLP. Estas plataformas proporcionan la potencia computacional y la flexibilidad que necesita para un entrenamiento extenso del modelo en conjuntos de datos de texto grandes. También puede descargar modelos a través de Spark NLP, como Llama 3.x y MPNet.
Primitivos de procesamiento de lenguaje natural de nivel bajo: Use Azure Databricks o Fabric con Spark NLP para tokenización, lematización y TF-IDF. Como alternativa, use una biblioteca de código abierto como spaCy o NLTK. Azure Language in Foundry Tools usa la tokenización internamente como parte de su canalización de modelos, pero no expone estos pasos como API independientes y controlables.
Creación de canalizaciones de procesamiento de lenguaje natural mediante Spark NLP
Spark NLP sigue el mismo patrón de desarrollo que los modelos tradicionales de Spark ML al ejecutar una canalización de procesamiento de lenguaje natural. Los modelos entrenados se administran mediante MLflow para el seguimiento de experimentos y la implementación de producción.

Ensamblar componentes principales de canalización
Una canalización NLP de Spark encadena anotadores en secuencia. Cada anotador transforma la salida de la fase anterior y se compila a partir de texto sin formato a vectores semánticos.
DocumentAssembler es el punto de entrada de cada canalización de NLP de Spark. Use
setCleanupModepara aplicar preprocesamiento de texto opcional, como eliminación de etiquetas HTML o normalización de espacios en blanco, antes de que se ejecuten los anotadores de bajada.SentenceDetector identifica los límites de las oraciones en el documento ensamblado. Devuelve las oraciones detectadas como un
Arraydentro de una sola fila o como filas independientes, según la configuración de la canalización. La detección precisa de oraciones es importante porque muchos anotadores descendentes funcionan en el nivel de oración.Tokenizer divide el texto sin formato en tokens discretos, como palabras, números y símbolos. Si las reglas predeterminadas no son suficientes para el dominio, agregue reglas personalizadas para controlar vocabulario especializado, términos guionados o patrones específicos del dominio.
Normalizador refina los tokens aplicando expresiones regulares y transformaciones de diccionario. Limpia el texto para reducir el ruido antes de insertar. Por ejemplo, puede quitar acentos, convertir en minúsculas o aplicar asignaciones de diccionario personalizadas para estandarizar la terminología.
WordEmbeddings asigna tokens a vectores semánticos para el procesamiento contextual. Cada token se representa como un vector denso que captura su significado en relación con otros tokens. Los tokens sin resolver que no aparecen en el vocabulario de incrustaciones tienen como valor predeterminado cero vectores.
Administración de modelos mediante MLflow
Spark NLP usa canalizaciones de Spark MLlib con compatibilidad nativa con MLflow . No es necesario escribir código de integración ni serialización personalizado.
MLflow administra el seguimiento de experimentos, el control de versiones del modelo y la implementación. Puede registrar parámetros de canalización, métricas y artefactos durante las sesiones de entrenamiento. MLflow realiza un seguimiento de cada experimento, por lo que puede comparar los resultados entre iteraciones y reproducir configuraciones correctas.
MLflow se integra directamente con Azure Databricks y Fabric. En Azure Databricks, MLflow viene preinstalado e se integra estrechamente con el área de trabajo. Fabric también proporciona una experiencia de MLflow integrada con el seguimiento y el registro automático de experimentos nativos, por lo que no es necesario instalar MLflow por separado. Si ejecuta Spark NLP en otro entorno basado en Apache Spark, puede instalar MLflow por separado y configurarlo para realizar un seguimiento de los experimentos en un servidor de seguimiento remoto.
Use el Registro de modelos de MLflow para promover modelos a producción y mantener la gobernanza. El Registro de modelos proporciona un repositorio central para administrar las versiones del modelo en las canalizaciones de procesamiento de lenguaje natural. En las implementaciones clásicas, realice la transición de modelos a través de fases como almacenamiento provisional, producción y archivado. En Azure Databricks, las implementaciones más recientes usan Models en el catálogo de Unity, que reemplaza las fases fijas por alias y etiquetas personalizados para la administración del ciclo de vida más flexible. En Fabric, el área de trabajo proporciona su propio registro de modelos basado en MLflow.
Matriz de funcionalidades
En las tablas siguientes se resumen las diferencias clave en las funcionalidades entre Spark NLP en Azure Databricks o Fabric y Azure Language.
Funcionalidades generales
| Capacidad | Spark NLP (Azure Databricks o Fabric) | idioma de Azure |
|---|---|---|
| Modelos preentrenados como servicio | Sí | Sí |
| REST API | Sí | Sí |
| Programabilidad | Pitón, Scala | Consulte Lenguajes de programación admitidos. |
| Admite el procesamiento de grandes conjuntos de datos y documentos grandes | Sí | Limitado 1 |
1.Azure Language tiene límites de tamaño de documento por solicitud que varían según el modo. Las solicitudes sincrónicas admiten hasta 5120 caracteres por documento y las solicitudes asincrónicas admiten hasta 125 000 caracteres por documento. Ambos modos admiten hasta 25 documentos por llamada API. Puede procesar grandes volúmenes de conjuntos de datos a través del procesamiento por lotes y la paginación, pero los documentos individuales que superan el límite de caracteres para el modo elegido requieren fragmentación. Para obtener más información, consulte Data y límites de velocidad para Azure Language.
Funcionalidades del anotador
| Capacidad | Spark NLP (Azure Databricks o Fabric) | idioma de Azure |
|---|---|---|
| Detector de frases | Sí | No |
| Detector de frases profundas | Sí | No |
| Tokenizador | Sí | Solo interna (no expuesta como una API independiente) |
| Generador de N-gramas | Sí | No |
| segmentación de Word | Sí | Sí |
| Lematizador | Sí | No |
| Lematizador | Sí | No |
| Etiquetado de partes del discurso | Sí | No |
| Analizador de dependencias | Sí | No |
| Traducción | Sí | No |
| Limpiador de palabras irrelevantes | Sí | No |
| Corrección ortográfica | Sí | No |
| Normalizador | Sí | Sí |
| Buscador de coincidencias de texto | Sí | No |
| TF-IDF | Sí | No |
| Comparador de expresiones regulares | Sí | Limitado |
| Comparador de fechas | Sí | Limitado |
| Fragmentador | Sí | No |
Funcionalidades de procesamiento de lenguaje natural de alto nivel
| Capacidad | Spark NLP (Azure Databricks o Fabric) | idioma de Azure |
|---|---|---|
| Corrector ortográfico | Sí | No |
| Resumen | Sí | Sí |
| Respuesta a preguntas | Sí | Sí |
| Detección de sentimientos | Sí | Sí |
| Detección de emociones | Sí | Limitado 2 |
| Clasificación de tokens | Sí | Limitado 3 |
| Clasificación de texto | Sí | Limitado 3 |
| Representación de texto | Sí | No |
| NER | Sí | Sí (precompilado). CNER está disponible a través de modelos personalizados. 3 |
| Detección de idioma | Sí | Sí |
| Admite idiomas distintos del inglés | Sí. Consulte Lenguajes compatibles con NLP de Spark. | Sí. Consulte Lenguajes soportados de Azure. |
2.Azure Language admite la minería de opiniones, que identifica sentimientos vinculados a aspectos específicos del texto, pero no proporciona detección de emociones dedicada (como alegría, ira o clasificación de tristeza).
3. Disponible a través de modelos personalizados. Entrena modelos de reconocimiento de entidades personalizados o CNER en tus propios datos etiquetados.
Colaboradores
Microsoft mantiene este artículo. Los colaboradores siguientes escribieron este artículo.
Autores principales:
- Ananya Ghosh Chowdhury | Arquitecto principal de soluciones en la nube
- Kranthi Manchikanti | Ingeniero sénior de soluciones de IA
Otros colaboradores:
- Freddy Ayala | Arquitecto de soluciones en la nube
- Tincy Elias | Arquitecto sénior de soluciones en la nube
- Moritz Steller | Arquitecto sénior de soluciones en la nube
Para ver perfiles de LinkedIn no públicos, inicie sesión en LinkedIn.
Pasos siguientes
- Introducción a la inteligencia artificial en Azure
- Desarrollo de soluciones de procesamiento de lenguaje natural mediante Las herramientas de Foundry
Recursos relacionados
documentación de Azure Language:
Documentación de Spark NLP:
componentes de Azure:
Recursos de Learn: