En este artículo se presenta una solución e instrucciones para desarrollar operaciones de datos sin conexión y administración de datos (DataOps) para un sistema de conducción automatizado. La solución DataOps se basa en el marco que se describe en la guía de diseño de operaciones de vehículos autónomos (AVOps). DataOps es uno de los bloques de creación de AVOps. Otros bloques de creación incluyen operaciones de aprendizaje automático (MLOps), operaciones de validación (ValOps), DevOps y funciones de AVOps centralizadas.
Apache®, Apache Spark y Apache Parquet son marcas registradas o marcas comerciales de Apache Software Foundation en los Estados Unidos u otros países. El uso de estas marcas no implica la aprobación de Apache Software Foundation.
Architecture

Descargue un archivo de Visio que contiene los diagramas de arquitectura de este artículo.
Flujo de datos
Los datos de medida se originan en los flujos de datos de un vehículo. Las fuentes incluyen cámaras, telemetría de vehículos y sensores de radar, ultrasónicos y lidar. Los registradores de datos del vehículo almacenan los datos de medida en los dispositivos de almacenamiento del registrador. Los datos de almacenamiento del registrador se cargan en un lago de datos de aterrizaje. Un servicio como Azure Data Box o Azure Stack Edge, o una conexión dedicada como Azure ExpressRoute, ingiere los datos en Azure. Los datos de medida en los siguientes formatos llegan a Azure Data Lake Storage: formato de datos de medida versión 4 (MDF4), sistemas de administración de datos técnicos (TDMS) y rosbag. Los datos cargados escriben una cuenta de almacenamiento dedicada denominada Aterrizaje que se designa para recibir y validar los datos.
Una canalización de Azure Data Factory se desencadena a intervalos programados para procesar los datos en la cuenta de almacenamiento de aterrizaje. La canalización controla los pasos siguientes:
- Realiza una comprobación de calidad de datos, como una suma de comprobación. En este paso se quitan los datos de baja calidad para que solo los datos de alta calidad pasen a la siguiente fase. Azure App Service se usa para ejecutar el código de comprobación de calidad. Los datos que se consideran incompletos se archivan para su procesamiento futuro.
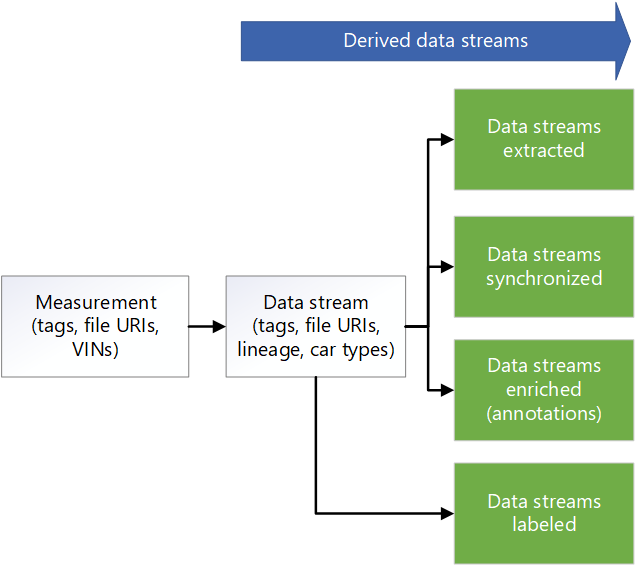
- Para el seguimiento de linaje, llama a una API de metadatos mediante App Service. En este paso se actualizan los metadatos almacenados en Azure Cosmos DB para crear un flujo de datos. Para cada medida, hay un flujo de datos sin formato.
- Copia los datos en una cuenta de almacenamiento denominada Sin formato en Data Lake Storage.
- Llama a la API de metadatos para marcar el flujo de datos como completo para que otros componentes y servicios puedan consumir el flujo de datos.
- Archiva las medidas y las quita de la cuenta de almacenamiento de aterrizaje.
Data Factory y Azure Batch procesan los datos de la zona sin formato para extraer información que los sistemas de bajada pueden consumir:
- Batch lee los datos de los temas en el archivo sin formato y genera los datos en los temas seleccionados en las carpetas respectivas.
- Dado que los archivos de la zona sin formato pueden tener más de 2 GB de tamaño, las funciones de extracción de procesamiento paralelo se ejecutan en cada archivo. Estas funciones extraen el procesamiento de imágenes, lidar, radar y datos GPS. También realizan el procesamiento de metadatos. Data Factory y Batch proporcionan una manera de realizar el paralelismo de forma escalable.
- Los datos se reducen para reducir la cantidad de datos que se deben etiquetar y anotar.
Si los datos del registrador del vehículo no se sincronizan entre los distintos sensores, se desencadena una canalización de Data Factory que sincroniza los datos para crear un conjunto de datos válido. El algoritmo de sincronización se ejecuta en Batch.
Una canalización de Data Factory se ejecuta para enriquecer los datos. Algunos ejemplos de mejoras son la telemetría, los datos del registrador de vehículos y otros datos, como el tiempo, el mapa o los datos de objetos. Los datos enriquecidos ayudan a proporcionar a los científicos de datos información que pueden usar, por ejemplo, en el desarrollo de algoritmos. Los datos generados se mantienen en archivos Apache Parquet que son compatibles con los datos sincronizados. Los metadatos sobre los datos enriquecidos se almacenan en un almacén de metadatos de Azure Cosmos DB.
Los partners de terceros realizan el etiquetado manual o automático. Los datos se comparten con los partners de terceros a través de Azure Data Share y se integran en Microsoft Purview. Data Share usa una cuenta de almacenamiento dedicada denominada Etiquetada en Data Lake Storage para devolver los datos etiquetados a la organización.
Una canalización de Data Factory realiza la detección de escenas. Los metadatos de la escena se conservan en el almacén de metadatos. Los datos de la escena se almacenan como objetos en archivos Parquet o Delta.
Además de los metadatos de los datos de enriquecimiento y las escenas detectadas, el almacén de metadatos de Azure Cosmos DB almacena los metadatos de las medidas, como los datos de unidad. Este almacén también contiene metadatos sobre el linaje de los datos a medida que pasan por los procesos de extracción, reducción de muestreo, sincronización, enriquecimiento y detección de escenas. La API de metadatos se usa para acceder a las medidas, el linaje y los datos de la escena y para buscar dónde se almacenan los datos. Como resultado, la API de metadatos actúa como administrador de capas de almacenamiento. Distribuye los datos entre cuentas de almacenamiento. También proporciona a los desarrolladores una manera de usar una búsqueda basada en metadatos para obtener ubicaciones de datos. Por ese motivo, el almacén de metadatos es un componente centralizado que ofrece rastreabilidad y linaje en el flujo de datos de la solución.
Azure Databricks y Azure Synapse Analytics se usan para conectarse con la API de metadatos y acceder a Data Lake Storage y realizar investigaciones sobre los datos.
Componentes
- Data Box proporciona una forma de enviar terabytes de datos hacia y desde Azure de forma rápida, económica y confiable. En esta solución, Data Box se usa para transferir los datos recopilados del vehículo a Azure a través de un operador regional.
- Los dispositivos de Azure Stack Edge proporcionan funcionalidad de Azure en ubicaciones perimetrales. Entre los ejemplos de funcionalidades de Azure se incluyen el proceso, el almacenamiento, las redes y el aprendizaje automático acelerado por hardware.
- ExpressRoute amplía una red local a la nube de Microsoft a través de una conexión privada.
- Data Lake Storage almacena una gran cantidad de datos en su formato nativo y sin procesar. En este caso, Azure Data Lake Storage almacena datos basados en fases, por ejemplo, sin formato o extraídos.
- Data Factory es una solución totalmente administrada y sin servidor para crear y programar flujos de trabajo de extracción, transformación y carga (ETL) y extracción, carga y transformación (ELT). Aquí, Data Factory realiza ETL a través del proceso por lotes y crea flujos de trabajo controlados por datos para orquestar el movimiento y la transformación de datos.
- Batch ejecuta aplicaciones de informática de alto rendimiento (HPC) en paralelo y a gran escala, de manera eficaz en Azure. Esta solución usa Batch para ejecutar aplicaciones a gran escala para tareas como la limpieza y transformación de datos, el filtrado y la preparación de datos, y extracción de metadatos.
- Azure Cosmos DB es una base de datos de varios modelos distribuida globalmente. Aquí, almacena los resultados de metadatos, como las medidas almacenadas.
- Data Share comparte datos con organizaciones de partners con mayor seguridad. Mediante el uso compartido in situ, los proveedores de datos pueden compartir datos donde estos residen sin copiar los datos ni tomar instantáneas. En esta solución, Data Share comparte datos con empresas de etiquetado.
- Azure Databricks proporciona un conjunto de herramientas para mantener soluciones de datos de nivel empresarial a escala. Es necesario para las operaciones de larga duración con grandes cantidades de datos de vehículos. Los ingenieros de datos usan Azure Databricks como área de trabajo de análisis.
- Azure Synapse Analytics acelera el tiempo necesario para obtener información de los sistemas de almacenamiento de datos y de macrodatos.
- Azure Cognitive Search proporciona servicios de búsqueda del catálogo de datos.
- App Service proporciona un servicio de aplicaciones web sin servidor. En este caso, App Service hospeda la API de metadatos.
- Microsoft Purview proporciona gobernanza de datos entre organizaciones.
- Azure Container Registry es un servicio que crea un registro administrado de imágenes de contenedor. Esta solución usa Container Registry para almacenar contenedores para los temas de procesamiento.
- Application Insights es una extensión de Azure Monitor que proporciona APM. En este escenario, Application Insights le ayuda a crear observabilidad en torno a la extracción de medidas: puede usar Application Insights para registrar eventos personalizados, métricas personalizadas y otra información mientras la solución procesa cada medida para la extracción. También puede crear consultas en análisis de registros para obtener información detallada sobre cada medida.
Detalles del escenario
Diseñar un marco sólido de DataOps para vehículos autónomos es crucial para utilizar sus datos, realizar un seguimiento de su linaje y ponerlos a disposición de toda la organización. Sin un proceso de DataOps bien diseñado, la enorme cantidad de datos que generan los vehículos autónomos puede resultar abrumadora y difícil de administrar.
Al implementar una estrategia eficaz de DataOps, ayuda a garantizar que sus datos se almacenen correctamente, sean fácilmente accesibles y tengan un linaje claro. También facilita la administración y el análisis de los datos, lo que permite tomar decisiones más informadas y mejorar el rendimiento del vehículo.
Un proceso eficaz de DataOps permite distribuir fácilmente los datos por toda la organización. A continuación, varios equipos pueden acceder a la información que necesitan para optimizar sus operaciones. DataOps facilita la colaboración y el uso compartido de información, lo que ayuda a mejorar la eficacia general de su organización.
Entre los retos típicos de las operaciones de datos en el contexto de los vehículos autónomos figuran:
- Administración del volumen diario de datos de medida a escala de terabytes o petabytes de los vehículos de investigación y desarrollo.
- Uso compartido de datos y colaboración entre varios equipos y partners, por ejemplo, para el etiquetado, las anotaciones y los controles de calidad.
- Seguimiento y linaje para una pila de percepción de seguridad crítica que captura el control de versiones y el linaje de los datos de medida.
- Metadatos y detección de datos para mejorar la segmentación semántica, la clasificación de imágenes y los modelos de detección de objetos.
Esta solución de AVOps DataOps proporciona instrucciones sobre cómo abordar estos desafíos.
Posibles casos de uso
Esta solución beneficia a los fabricantes de equipos originales (OEM) automotrices, proveedores de nivel 1 y fabricantes independientes de software (ISV) que desarrollan soluciones para la conducción automatizada.
Operaciones de datos federados
En una organización que implementa AVOps, varios equipos contribuyen a DataOps debido a la complejidad que se requiere para AVOps. Por ejemplo, un equipo podría encargarse de la recopilación e ingesta de datos. Otro equipo podría ser responsable de la administración de la calidad de los datos lidar. Por ello, es importante tener en cuenta los siguientes principios de una arquitectura de malla de datos para DataOps:
- Descentralización orientada al dominio de la propiedad y la arquitectura de los datos. Un equipo dedicado es responsable de un dominio de datos que proporciona productos de datos para ese dominio, por ejemplo, conjuntos de datos etiquetados.
- Datos como producto. Cada dominio de datos tiene varias zonas en contenedores de almacenamiento implementados por data-lake. Hay zonas para el uso interno. También hay una zona que contiene productos de datos publicados para otros dominios de datos o uso externo para evitar la duplicación de datos.
- Datos de autoservicio como plataforma para permitir equipos de datos autónomos orientados a un dominio.
- Gobernanza federada para habilitar la interoperabilidad y el acceso entre dominios de datos de AVOps que requieren un almacén de metadatos centralizado y un catálogo de datos. Por ejemplo, un dominio de datos de etiquetado podría necesitar acceso a un dominio de recopilación de datos.
Para obtener más información sobre las implementaciones de malla de datos, consulte Análisis a escala en la nube.
Estructura de ejemplo para dominios de datos de AVOps
En la tabla siguiente se proporcionan algunas ideas para estructurar dominios de datos de AVOps:
| Dominio de datos | Productos de datos publicados | Paso de solución |
|---|---|---|
| datos, recopilación | Archivos de medida cargados y validados | Aterrizaje y sin formato |
| Imágenes extraídas | Imágenes o fotogramas seleccionados y extraídos, datos lidar y radar | Extraído |
| Radar o lidar extraído | Datos lidar y radar seleccionados y extraídos | Extraído |
| Telemetría extraída | Datos de telemetría de automóviles seleccionados y extraídos | Extraído |
| Etiquetado | Conjuntos de datos etiquetados | Etiquetado |
| Recalcular | KPI generados basados en ejecuciones de simulación repetidas | Recalcular |
Cada dominio de datos de AVOps se configura en función de una estructura de plano técnico. Esa estructura incluye Data Factory, Data Lake Storage, bases de datos, Batch y entornos de ejecución de Apache Spark a través de Azure Databricks o Azure Synapse Analytics.
Metadatos y detección de datos
Cada dominio de datos está descentralizado y administra individualmente sus productos de datos de AVOps correspondientes. Para la detección de datos central y saber dónde se encuentran los productos de datos, se requieren dos componentes:
- Un almacén de metadatos que conserva metadatos sobre archivos de medida procesados y flujos de datos, como secuencias de vídeo. Este componente hace que los datos sean detectables y se les pueda realizar un seguimiento con anotaciones que necesitan indexarse, como por ejemplo para buscar en los metadatos de archivos no etiquetados. Por ejemplo, es posible que desee que el almacén de metadatos devuelva todos los fotogramas de números de identificación de vehículos (VIN) específicos o fotogramas con peatones u otros objetos basados en el enriquecimiento.
- Catálogo de datos que muestra el linaje, las dependencias entre dominios de datos de AVOps y qué almacenes de datos participan en el bucle de datos de AVOps. Un ejemplo de catálogo de datos es Microsoft Purview.
Puede usar Azure Data Explorer o Azure Cognitive Search para ampliar un almacén de metadatos basado en Azure Cosmos DB. La selección depende del escenario final que necesite para la detección de datos. Use Azure Cognitive Search para las funcionalidades de búsqueda semántica.
El siguiente diagrama de modelo de metadatos muestra un modelo de metadatos unificado típico que se utiliza en varios pilares del bucle de datos de AVOps:
Uso compartido de datos
El uso compartido de datos es un escenario común en un bucle de datos de AVOps. Los usos incluyen el uso compartido de datos entre dominios de datos y el uso compartido externo, por ejemplo, para integrar partners de etiquetado. Microsoft Purview proporciona las siguientes funcionalidades para el uso compartido eficaz de datos en un bucle de datos:
Los formatos recomendados para el intercambio de datos de etiquetas incluyen objetos comunes en conjuntos de datos de contexto (COCO) y Asociación para la estandarización de conjuntos de datos openLABEL y sistemas de automatización y medida (ASAM).
En esta solución, los conjuntos de datos etiquetados se usan en procesos de MLOps para crear algoritmos especializados, como modelos de percepción y fusión de sensores. Los algoritmos pueden detectar escenas y objetos en un entorno, como el coche que cambia de carril, carreteras bloqueadas, tráfico peatonal, semáforos y señales de tráfico.
Canalización de datos
En esta solución de DataOps, se automatiza el movimiento de datos entre las distintas fases de la canalización de datos. Mediante este enfoque, el proceso ofrece ventajas de eficacia, escalabilidad, coherencia, reproducibilidad, adaptabilidad y control de errores. Mejora el proceso general de desarrollo, acelera el progreso y apoya la implementación segura y eficaz de tecnologías de conducción autónoma.
En las secciones siguientes se describe cómo implementar el movimiento de datos entre fases y cómo se deben estructurar las cuentas de almacenamiento.
Estructura de carpetas jerárquica
Una estructura de carpetas bien organizada es un componente vital de una canalización de datos en el desarrollo de la conducción autónoma. Esta estructura proporciona una organización sistemática y fácilmente navegable de archivos de datos, lo que facilita la administración y recuperación de datos eficientes.
En esta solución, los datos de la carpeta sin formato tienen la siguiente estructura jerárquica:
region/raw/<measurement-ID>/<data-stream-ID>/YYYY/MM/DD
Los datos de la cuenta de almacenamiento de zona extraída usan una estructura jerárquica similar:
region/extracted/<measurement-ID>/<data-stream-ID>/YYYY/MM/DD
Mediante estructuras jerárquicas similares, puede aprovechar la funcionalidad de espacio de nombres jerárquico de Data Lake Storage. Las estructuras jerárquicas ayudan a crear almacenamiento de objetos escalable y rentable. Estas estructuras también mejoran la eficacia de la búsqueda y recuperación de objetos. La creación de particiones por año y VIN facilita la búsqueda de imágenes relevantes de vehículos específicos. En el lago de datos, se crea un contenedor de almacenamiento para cada sensor, como una cámara, un dispositivo GPS o un sensor lidar o radar.
Aterrizaje de la cuenta de almacenamiento en la cuenta de almacenamiento sin formato
Una canalización de Data Factory se desencadena según una programación. Una vez desencadenada la canalización, los datos se copian de la cuenta de almacenamiento de aterrizaje a la cuenta de almacenamiento sin formato.

La canalización recupera todas las carpetas de medidas e itera a través de ellas. Con cada medida, la solución realiza las siguientes actividades:
Una función valida la medida. La función recupera el archivo de manifiesto del manifiesto de medida. A continuación, la función comprueba si todos los archivos de medida MDF4, TDMS y rosbag para la medida actual existen en la carpeta de medida. Si la validación se realiza correctamente, la función continúa con la siguiente actividad. Si se produce un error en la validación, la función omite la medida actual y se mueve a la siguiente carpeta de medida.
Se realiza una llamada API web a una API que crea una medida y la carga JSON del archivo JSON del manifiesto de medida se pasa a la API. Si la llamada se realiza correctamente, se analiza la respuesta para recuperar el id. de medida. Si se produce un error en la llamada, la medida se mueve a la actividad en caso de error para el control de errores.
Nota:
Esta solución de DataOps se basa en el supuesto de que se limita el número de solicitudes al servicio de la aplicación. Si la solución puede realizar un número indeterminado de solicitudes, considere usar un patrón de limitación de velocidad.
Se realiza una llamada API web a una API que crea un flujo de datos mediante la creación de la carga JSON necesaria. Si la llamada se realiza correctamente, la respuesta se analiza para recuperar el id. del flujo de datos y la ubicación del flujo de datos. Si se produce un error en la llamada, la medida se mueve a la actividad en caso de error.
Se realiza una llamada API web para actualizar el estado del flujo de datos a
Start Copy. Si la llamada se realiza correctamente, la actividad de copia copia los archivos de medida en la ubicación del flujo de datos. Si se produce un error en la llamada, la medida se mueve a la actividad en caso de error.Una canalización de Data Factory invoca a Batch para copiar los archivos de medida de la cuenta de almacenamiento de aterrizaje en la cuenta de almacenamiento sin formato. Un módulo de copia de una aplicación de orquestador crea un trabajo con las siguientes tareas para cada medida:
- Copie los archivos de medida en la cuenta de almacenamiento sin formato.
- Copie los archivos de medida en una cuenta de almacenamiento de archivo.
- Quite los archivos de medida de la cuenta de almacenamiento de aterrizaje.
Nota:
En estas tareas, Batch usa un grupo de orquestadores y la herramienta AzCopy para copiar y quitar datos. AzCopy usa tokens de SAS para realizar tareas de copia o eliminación. Los tokens de SAS se almacenan en un almacén de claves y se hace referencia a ellos mediante los términos
landingsaskey,archivesaskeyyrawsaskey.Se realiza una llamada API web para actualizar el estado del flujo de datos a
Copy Complete. Si la llamada se realiza correctamente, la secuencia continúa con la siguiente actividad. Si se produce un error en la llamada, la medida se mueve a la actividad en caso de error.Los archivos de medida se mueven de la cuenta de almacenamiento de aterrizaje a un archivo de aterrizaje. Esta actividad puede volver a ejecutar una medida determinada si la mueve a la cuenta de almacenamiento de aterrizaje a través de una canalización de copia hidratada. La administración del ciclo de vida está activada para esta zona para que las medidas de esta zona se eliminen o archiven automáticamente.
Si se produce un error con una medida, la medida se mueve a una zona de error. Desde allí, se puede mover a la cuenta de almacenamiento de aterrizaje para que se vuelva a ejecutar. Como alternativa, la administración del ciclo de vida puede eliminar o archivar automáticamente la medida.
Tenga en cuenta los siguientes puntos:
- Estas canalizaciones se desencadenan según una programación. Este enfoque ayuda a mejorar la rastreabilidad de las ejecuciones de canalización y a evitar ejecuciones innecesarias.
- Cada canalización se configura con un valor de simultaneidad de uno para asegurarse de que las ejecuciones anteriores finalicen antes de que se inicie la siguiente ejecución programada.
- Cada canalización está configurada para copiar medidas en paralelo. Por ejemplo, si una ejecución programada recoge 10 medidas para copiar, los pasos de canalización se pueden ejecutar simultáneamente para las diez medidas.
- Cada canalización se configura para generar una alerta en Monitor si la canalización tarda más de lo esperado en finalizar.
- La actividad en caso de error se implementa en casos posteriores de observabilidad.
- La administración del ciclo de vida elimina automáticamente medidas parciales, por ejemplo, medidas con archivos rosbag que faltan.
Diseño de Batch
Toda la lógica de extracción se empaqueta en diferentes imágenes de contenedor, con un contenedor para cada proceso de extracción. Batch ejecuta las cargas de trabajo de contenedor en paralelo cuando extrae información de los archivos de medida.

Batch usa un grupo de orquestadores y un grupo de ejecución para procesar cargas de trabajo:
- Un grupo de orquestadores tiene nodos de Linux sin compatibilidad con el entorno de ejecución del contenedor. El grupo ejecuta código Python que utiliza la API de Batch para crear trabajos y tareas para el grupo de ejecución. Este grupo también supervisa esas tareas. Data Factory invoca al grupo de orquestadores, que organiza las cargas de trabajo de contenedores que extraen datos.
- Un grupo de ejecución tiene nodos de Linux con entornos de ejecución de contenedor para admitir la ejecución de cargas de trabajo de contenedor. Para este grupo, los trabajos y las tareas se programan a través del grupo de orquestadores. Todas las imágenes de contenedor necesarias para el procesamiento en el grupo de ejecución se insertan en un registro de contenedor mediante JFrog. El grupo de ejecución está configurado para conectarse a este registro y extraer las imágenes necesarias.
Las cuentas de almacenamiento desde las que se leen y escriben los datos se montan mediante NFS 3.0 en los nodos por lotes y los contenedores que se ejecutan en los nodos. Este enfoque ayuda a los nodos y contenedores por lotes a procesar los datos rápidamente sin necesidad de descargar los archivos de datos localmente en los nodos por lotes.
Nota:
Las cuentas de lotes y almacenamiento deben estar en la misma red virtual para el montaje.
Invocar Batch desde Data Factory
En la canalización de extracción, el desencadenador pasa la ruta de acceso del archivo de metadatos y la ruta de acceso del flujo de datos sin formato en los parámetros de canalización. Data Factory usa una actividad de búsqueda para analizar el JSON del archivo de manifiesto. El id. de flujo de datos sin formato se puede extraer de la ruta de acceso del flujo de datos sin formato mediante el análisis de la variable de canalización.
Data Factory llama a una API para crear un flujo de datos. La API devuelve la ruta de acceso del flujo de datos extraído. La ruta de acceso extraída se añade al objeto actual, y Data Factory invoca a Batch a través de una actividad personalizada pasando el objeto actual, después de añadir la ruta de acceso al flujo de datos extraída:
{
"measurementId":"210b1ba7-9184-4840-a1c8-eb£397b7c686",
"rawDataStreamPath":"raw/2022/09/30/KA123456/210b1ba7-9184-4840-
alc8-ebf39767c68b/57472a44-0886-475-865a-ca32{c851207",
"extractedDatastreamPath":"extracted/2022/09/30/KA123456
/210bIba7-9184-4840-a1c8-ebf39767c68b/87404c9-0549-4a18-93ff-d1cc55£d8b78",
"extractedDataStreamId":"87404bc9-0549-4a18-93ff-d1cc55fd8b78"
}
Proceso de extracción paso a paso

Data Factory programa un trabajo con una tarea para que el grupo de orquestadores procese una medida para la extracción. Data Factory pasa la siguiente información al grupo de orquestadores:
- Id. de medida
- Ubicación de los archivos de medida de tipo MDF4, TDMS o rosbag que se deben extraer
- Ruta de acceso de destino de la ubicación de almacenamiento del contenido extraído
- Id. de flujo de datos extraído
El grupo de orquestadores invoca una API para actualizar el flujo de datos y establecer su estado en
Processing.El grupo de orquestadores crea un trabajo para cada archivo de medida que forma parte de la medida. Cada trabajo contiene las siguientes tareas:
Tarea Propósito Nota: Validación Valida que los datos se pueden extraer del archivo de medida. Todas las demás tareas dependen de esta tarea. Procesar metadatos Deriva metadatos del archivo de medida y enriquece los metadatos del archivo mediante una API para actualizar los metadatos del archivo. Proceso: StructuredTopicsExtrae datos estructurados de un archivo de medida determinado. La lista de temas de los que extraer datos estructurados se pasa como un objeto de configuración. Proceso: CameraTopicsExtrae datos de imagen de un archivo de medida determinado. La lista de temas de los que extraer imágenes se pasa como un objeto de configuración. Proceso: LidarTopicsExtrae datos lidar de un archivo de medida determinado. La lista de temas de los que extraer datos lidar se pasa como un objeto de configuración. Proceso: CANTopicsExtrae datos de red de área de controlador (CAN) de un archivo de medida determinado. La lista de temas de los que extraer datos se pasa como un objeto de configuración. El grupo de orquestadores supervisa el progreso de cada tarea. Una vez finalizados todos los trabajos de todos los archivos de medida, el grupo invoca una API para actualizar el flujo de datos y establecer su estado en
Completed.El orquestador se cierra correctamente.
Nota:
Cada tarea es una imagen de contenedor independiente que tiene una lógica que se define correctamente para su propósito. Las tareas aceptan objetos de configuración como entrada. Por ejemplo, la entrada especifica dónde escribir la salida y el archivo de medida que se va a procesar. Una matriz de tipos de tema, como
sensor_msgs/Image, es otro ejemplo de entrada. Dado que todas las demás tareas dependen de la tarea de validación, se crea una tarea dependiente para ella. Todas las demás tareas se pueden procesar de forma independiente y se pueden ejecutar en paralelo.
Consideraciones
Estas consideraciones implementan los pilares del marco de buena arquitectura de Azure, que es un conjunto de principios guía que se pueden usar para mejorar la calidad de una carga de trabajo. Para más información, consulte Marco de buena arquitectura de Microsoft Azure.
Confiabilidad
La confiabilidad garantiza que la aplicación pueda cumplir los compromisos contraídos con los clientes. Para más información, consulte Resumen del pilar de fiabilidad.
- En la solución, considere usar zonas de disponibilidad de Azure, que son ubicaciones físicas únicas dentro de la misma región de Azure.
- Plan de recuperación ante desastres y conmutación por error de cuentas.
Seguridad
La seguridad proporciona garantías contra ataques deliberados y el abuso de datos y sistemas valiosos. Para más información, consulte Introducción al pilar de seguridad.
Es importante comprender la división de responsabilidad entre un OEM automotriz y Microsoft. En un vehículo, el OEM posee toda la pila, pero a medida que los datos se mueven a la nube, algunas responsabilidades se transfieren a Microsoft. Las capas de la plataforma como servicio (PaaS) de Azure proporcionan seguridad integrada en la pila física, incluido el sistema operativo. Puede agregar las siguientes funcionalidades a los componentes de seguridad de infraestructura existentes:
- Administración de identidades y acceso que usan identidades de Microsoft Entra y directivas de acceso condicional de Microsoft Entra.
- Gobernanza de la infraestructura que usa Azure Policy.
- Gobernanza de datos que usa Microsoft Purview.
- Cifrado de datos en reposo que usa servicios nativos de almacenamiento y bases de datos de Azure. Para obtener más información, consulte Consideraciones de protección de datos.
- Protección de claves criptográficas y secretos. Use Azure Key Vault con este propósito.
Optimización de costos
La optimización de costes busca formas de reducir los gastos innecesarios y mejorar la eficiencia operativa. Para más información, vea Información general del pilar de optimización de costos.
Una de las principales preocupaciones de los fabricantes de OEM y los proveedores de primer nivel que operan con DataOps para vehículos automatizados es el coste del funcionamiento. Esta solución usa los procedimientos siguientes para ayudar a optimizar los costos:
- Aprovechar las distintas opciones que ofrece Azure para hospedar el código de aplicación. Esta solución usa App Service y Batch. Para obtener instrucciones sobre cómo elegir el servicio adecuado para la implementación, consulte Elegir un servicio de proceso de Azure.
- Usar Uso compartido de datos en contexto de Azure Storage.
- Optimización de los costes mediante la administración del ciclo de vida.
- Ahorro de costes en App Service mediante instancias reservadas.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Creadores de entidad de seguridad:
- Ryan Matsumura | Jefe de programas
- Jochen Schroeer | Arquitecto principal (Movilidad de línea de servicio)
- Brij Singh | Ingeniero principal de software
- Ginette Vellera | Directora de ingeniería de software sénior
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.
Pasos siguientes
- ¿Qué es Azure Batch?
- ¿Qué es Azure Data Factory?
- Introducción a Azure Data Lake Storage Gen2
- Bienvenido a Azure Cosmos DB
- Información general de App Service
- ¿Qué es Azure Data Share?
- ¿Qué es Azure Data Box?
- Documentación de Azure Stack Edge
- ¿Qué es Azure ExpressRoute?
- ¿Qué es Azure Machine Learning?
- ¿Qué es Azure Databricks?
- ¿Qué es Azure Synapse Analytics?
- Introducción a Azure Monitor
- Archivos de registro de ROS (rosbags)
- Plataforma de operaciones de datos a gran escala para vehículos autónomos