Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Una arquitectura de microservicios requiere un buen diseño de API porque todo el intercambio de datos entre servicios se produce a través de mensajes o llamadas API. Las APIs eficaces ayudan a evitar la entrada/salida frecuente (E/S). Los equipos independientes diseñan servicios, por lo que debe definir claramente la semántica de API y los esquemas de control de versiones para evitar interrumpir otros servicios al actualizar un servicio.

Debe distinguir entre los dos tipos de API:
- API públicas a las que llaman las aplicaciones cliente
- API de back-end para la comunicación entre servicios
Estos dos tipos tienen requisitos diferentes. Una API pública debe ser compatible con aplicaciones cliente, como aplicaciones de explorador o aplicaciones móviles nativas. La mayoría de las API públicas usan REST a través de HTTP. Pero las API de back-end deben tener en cuenta el rendimiento de la red. En función de la granularidad de los servicios, la comunicación entre servicios puede dar lugar a demasiado tráfico de red. Los servicios se pueden convertir rápidamente en enlazados de E/S, por lo que las consideraciones como la velocidad de serialización y el tamaño de carga se vuelven más importantes. Algunas alternativas populares a REST a través de HTTP incluyen gRPC Remote Procedure Call (gRPC), Apache Avro y Apache Thrift. Estos protocolos admiten la serialización binaria y mejoran la eficacia en comparación con HTTP.
Consideraciones
Tenga en cuenta los siguientes factores al decidir cómo implementar una API:
REST frente a llamada a procedimiento remoto (RPC): Tenga en cuenta las ventajas entre una interfaz de estilo REST frente a una interfaz de estilo RPC.
REST modela recursos, lo que proporciona una manera intuitiva de expresar el modelo de dominio. Define una interfaz uniforme basada en verbos HTTP, lo que fomenta la evolución. Incluye semántica bien definida para la idempotencia, los efectos secundarios y los códigos de respuesta. REST también aplica la comunicación sin estado, lo que mejora la escalabilidad.
RPC se centra en operaciones o comandos. Las interfaces RPC se asemejan a las llamadas a métodos locales, por lo que pueden dar lugar a APIs demasiado verbosas. Pero RPC no requiere comunicación excesiva. Para evitar ese resultado, debe diseñar cuidadosamente la interfaz.
Para una interfaz RESTful, la mayoría de los equipos eligen REST sobre HTTP empleando JSON. Para una interfaz de estilo RPC, los marcos populares incluyen gRPC, Avro y Thrift.
Eficacia: Considere la eficacia en términos de velocidad, memoria y tamaño de carga. Normalmente, una interfaz basada en gRPC es más rápida que REST a través de HTTP.
Lenguaje de definición de interfaz (IDL): Use un IDL para definir los métodos, parámetros y valores devueltos de una API. Un IDL puede generar código de cliente, código de serialización y documentación de API. Las herramientas de prueba de API consumen lenguajes de definición de interfaces (IDLs). Los marcos como gRPC, Avro y Thrift definen sus propias especificaciones IDL. REST a través de HTTP no tiene un formato IDL estándar, pero una opción común es OpenAPI (anteriormente Swagger). También puede crear una API DE REST HTTP sin usar un lenguaje de definición formal, pero perderá las ventajas de la generación y las pruebas de código.
Serialización: Elija cómo serializar objetos a través de la conexión. Entre las opciones se incluyen formatos basados en texto como JSON y formatos binarios como el búfer de protocolos. Los formatos binarios son más rápidos que los formatos basados en texto. Pero JSON proporciona una interoperabilidad más amplia porque la mayoría de los lenguajes y marcos admiten la serialización JSON. Algunos formatos de serialización requieren un esquema fijo o un archivo de definición de esquema compilado. En esos casos, debe incorporar este paso al proceso de construcción. Para obtener más información, consulte Procedimientos recomendados de codificación de mensajes.
Compatibilidad con lenguajes y marcos: Casi todos los marcos y lenguajes admiten HTTP. Avro, gRPC y Thrift proporcionan bibliotecas para C++, C#, Java y Python. Thrift y gRPC también admiten Go.
Compatibilidad e interoperabilidad: Si elige un protocolo como gRPC, es posible que necesite una capa de traducción de protocolos entre la API pública y el back-end. Una puerta de enlace puede realizar esa función. Si usa una malla de servicio, compruebe la compatibilidad del protocolo con la malla de servicio. Por ejemplo, Linkerd tiene compatibilidad integrada con HTTP, Thrift y gRPC.
Use REST a través de HTTP a menos que necesite las ventajas de rendimiento de un protocolo binario. REST a través de HTTP no requiere bibliotecas especiales y crea un acoplamiento mínimo porque los clientes no necesitan un stub de cliente para comunicarse con el servicio. El ecosistema REST incluye herramientas para admitir definiciones de esquema, pruebas y monitorización de puntos de conexión HTTP RESTful. HTTP también funciona con los clientes del explorador, por lo que no necesita una capa de traducción de protocolos entre el cliente y el back-end.
Si elige REST a través de HTTP, realice pruebas de rendimiento y carga al principio del proceso de desarrollo para comprobar si funciona adecuadamente para su escenario.
Diseño de API RESTful
Los siguientes recursos pueden ayudarle a diseñar LAS API de RESTful:
Tenga en cuenta los siguientes factores:
Evite las API que expongan detalles de implementación internos o reflejen un esquema de base de datos interno. La API debe modelar el dominio y actuar como un contrato entre servicios. Idealmente, solo debe cambiar la API al agregar una nueva funcionalidad, no al refactorizar el código ni cambiar el esquema de la base de datos.
Es posible que distintos tipos de cliente, como aplicaciones móviles y exploradores web de escritorio, requieran diferentes tamaños de carga o patrones de interacción. Considere la posibilidad de usar el patrón Backends for Frontends para crear back-ends independientes para cada cliente. Cada back-end expone una interfaz óptima para ese cliente.
En el caso de las operaciones que causan efectos secundarios, considere la posibilidad de hacerlas idempotentes e implementarlas como métodos
PUT. Este enfoque permite reintentos seguros y mejora la resistencia. Para obtener más información, consulte Comunicación entre servicios.Los métodos HTTP pueden tener semántica asincrónica, donde el método devuelve una respuesta inmediatamente, pero el servicio lleva a cabo la operación de forma asincrónica. En ese caso, el método debe devolver un código de respuesta HTTP 202 . Este código indica que la solicitud se aceptó para su procesamiento, pero aún no se ha procesado. Para obtener más información, consulte Patrón de Request-Reply asincrónico.
API de acceso a datos genéricos: Consideraciones sobre OData y GraphQL
Las API REST proporcionan un enfoque estructurado para exponer recursos, pero algunos escenarios requieren patrones de acceso a datos más flexibles. Las API orientadas a consultas como OData y GraphQL proporcionan alternativas que permiten a los clientes especificar exactamente qué datos necesitan. Este enfoque puede reducir potencialmente la sobresolicitud de datos y mejorar el rendimiento. Estos tipos de API priorizan las operaciones de lectura. Las operaciones de mutación, como crear, actualizar y eliminar, pueden ser más complejas de implementar, pero varios marcos pueden administrar estas operaciones de forma eficaz.
Cuándo se deben tener en cuenta las API de acceso a datos genéricos
Use un patrón de acceso a datos genérico en las situaciones siguientes:
Los clientes tienen diversos requisitos de datos que dan lugar a muchos puntos de conexión REST especializados o un comportamiento especializado.
Debe admitir operaciones complejas de consulta, filtrado y ordenación en varias entidades de datos.
La captura excesiva es un problema de rendimiento significativo, especialmente para clientes móviles o restringidos por ancho de banda.
Evite las API de acceso a datos genéricos en las situaciones siguientes:
La arquitectura de los microservicios destaca los límites de servicio estrictos y la encapsulación de dominio.
Necesita un control específico sobre los patrones de acceso a datos y las directivas de seguridad.
Las API admiten principalmente operaciones sencillas de creación, lectura, actualización y eliminación (CRUD) o flujos de trabajo empresariales bien definidos.
REST ya cumple los requisitos de rendimiento y carga de red.
Los requisitos de seguridad exigen definiciones de punto de conexión explícitas para minimizar las superficies expuestas a ataques.
Su equipo carece de experiencia con la implementación y optimización del lenguaje de consulta.
Asignación de REST a patrones DDD
Los patrones como entity, aggregate y value object definen restricciones para los objetos de un modelo de dominio. Muchos debates de diseño controlado por dominio (DDD) describen estos patrones mediante conceptos de lenguaje orientados a objetos (OO), como constructores o captadores de propiedades y establecedores. Por ejemplo, se supone que los objetos de valor son inmutables. En un lenguaje de programación de OO, debe aplicar esta restricción asignando los valores en el constructor y haciendo que las propiedades sean de solo lectura:
export class Location {
readonly latitude: number;
readonly longitude: number;
constructor(latitude: number, longitude: number) {
if (!Number.isFinite(latitude) || latitude < -90 || latitude > 90) {
throw new RangeError('latitude must be between -90 and 90');
}
if (!Number.isFinite(latitude) || longitude < -180 || longitude > 180) {
throw new RangeError('longitude must be between -180 and 180');
}
this.latitude = latitude;
this.longitude = longitude;
}
}
Estas prácticas de codificación desempeñan un papel importante en la creación de una aplicación monolítica tradicional. En una base de código grande, muchos subsistemas pueden usar el Location objeto, por lo que el objeto debe aplicar el comportamiento correcto.
El patrón Repository proporciona otro ejemplo. Este patrón garantiza que otras partes de la aplicación no realicen lecturas directas ni escrituras en el almacén de datos.

En una arquitectura de microservicios, los servicios no comparten la misma base de código ni un almacén de datos. En su lugar, se comunican a través de las API. Por ejemplo, un servicio de programador podría solicitar información sobre un dron de un servicio de drones. El servicio drone define su modelo de dron interno a través del código. Pero el programador no puede acceder directamente a estos detalles. En su lugar, el programador recibe una representación de la entidad drone, como un objeto JSON en una respuesta HTTP.
Este ejemplo se aplica bien a las industrias aeroespaciales y de aeronaves.

El servicio de planificador no puede modificar los modelos internos del servicio de dron ni escribir en el almacén de datos del servicio de dron. Por lo tanto, el código que implementa el servicio dron tiene un área expuesta más pequeña en comparación con el código en un monolito tradicional. Si el servicio dron define una Location clase, el ámbito de esa clase está limitado, ningún otro servicio consume directamente la clase.
Por estas razones, esta guía no se centra mucho en las prácticas de codificación relacionadas con los patrones de DDD tácticos. Pero puede modelar muchos patrones DDD a través de las API REST.
En los ejemplos siguientes se muestra cómo se alinean los conceptos rest con las construcciones comunes de DDD:
Las entidades agregadas corresponden naturalmente a los recursos de REST. Por ejemplo, una API de entrega podría exponer un agregado de entrega como un recurso.
Los agregados definen límites de coherencia. Las operaciones en agregados no deben dejar un agregado en un estado incoherente. Evite crear API que permitan que un cliente manipule el estado interno de un agregado. En su lugar, favorece las APIs de grano grueso que exponen agregados como recursos.
Las entidades tienen identidades únicas. En REST, los recursos tienen identificadores únicos en forma de direcciones URL. Cree direcciones URL de recursos que correspondan a la identidad de dominio de una entidad. El mapeo de la dirección URL a la identidad de dominio puede ser opaco para los clientes.
Desde la entidad raíz se puede acceder a las entidades secundarias de un agregado. Si sigue hipermedia como motor del estado de aplicación (HATEOAS), se puede acceder a las entidades hijas a través de vínculos en la representación de la entidad primaria.
Los objetos value son inmutables. Para realizar actualizaciones, reemplace todo el objeto de valor. En REST, implemente actualizaciones a través de solicitudes
PUToPATCH.Un repositorio permite a los clientes consultar, agregar o quitar objetos en una colección. El repositorio abstrae los detalles del almacén de datos subyacente. En REST, una colección puede ser un recurso distinto que incluya métodos para consultar la colección o agregar nuevas entidades a la colección.
Al diseñar API, piense en cómo expresan el modelo de dominio, no solo los datos dentro del modelo. Tenga en cuenta también las operaciones empresariales y las restricciones de los datos.
| Concepto de DDD | Equivalente de REST | Example |
|---|---|---|
| Aggregate | Resource | { "1":1234, "status":"pending"... } |
| identidad | URL | https://delivery-service/deliveries/1 |
| Entidades hijas | Enlaces | { "href": "/deliveries/1/confirmation" } |
| Actualizar objetos de valor |
PUT o PATCH |
PUT https://delivery-service/deliveries/1/dropoff |
| Repositorio | Collection | https://delivery-service/deliveries?status=pending |
Control de versiones de API
Una API actúa como un contrato entre un servicio y clientes o consumidores de ese servicio. Los cambios de API pueden interrumpir clientes externos o microservicios que dependen de la API. Minimice el número de cambios de API que realice. Los cambios en la implementación subyacente a menudo no requieren cambios en la API. Pero en algún momento, es probable que quiera agregar nuevas características o nuevas funcionalidades que requieran cambiar una API existente.
Realice cambios en la API compatibles con versiones anteriores siempre que sea posible. Por ejemplo, evite quitar un campo de un modelo. Ese cambio puede afectar a los clientes que esperan que el campo exista. Agregar un campo no interrumpe la compatibilidad porque los clientes deben omitir los campos que no reconocen en una respuesta. Pero el servicio debe controlar las solicitudes de clientes anteriores que omiten el nuevo campo.
Compatibilidad con el control de versiones en el contrato de API. Si presenta un cambio importante en la API, introduzca una nueva versión de API. Continúe dando soporte a la versión anterior y deje que los clientes seleccionen la versión que desean utilizar. Una manera de realizar el control de versiones es exponer ambas versiones en el mismo servicio. Otra opción es ejecutar dos versiones del servicio en paralelo y enrutar las solicitudes a una o la otra versión en función de las reglas de enrutamiento HTTP.
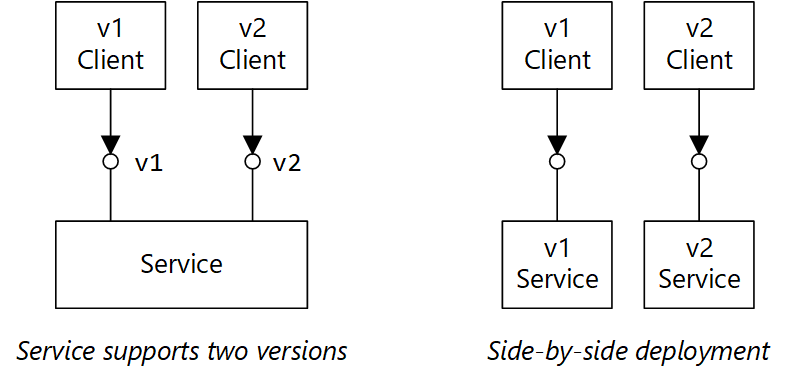
El diagrama tiene dos partes. En el lado izquierdo se muestra un servicio que admite dos versiones. El cliente v1 y el cliente v2 apuntan a un servicio. En el lado derecho se muestra un despliegue en paralelo. El cliente v1 apunta a un servicio v1 y el cliente v2 apunta a un servicio v2.
Varias versiones agregan costos en términos de tiempo de desarrollador, pruebas y sobrecarga operativa. Depreca las versiones anteriores lo antes posible. En el caso de las API internas, el equipo propietario de la API puede trabajar con otros equipos para ayudarles a migrar a la nueva versión. El proceso de gobernanza entre equipos es útil aquí. Las API externas (públicas) pueden ser más difíciles de dejar de usar una versión de API, especialmente si las aplicaciones cliente externas o nativas consumen la API.
Cuando cambia una implementación de servicio, etiquete el cambio con una versión. La versión proporciona información importante para ayudar a solucionar errores. Este enfoque admite el análisis de causa raíz porque se sabe qué versión del servicio se está llamando. Considere usar control de versiones semántico para las versiones del servicio. El versionado semántico utiliza un formato MAJOR.MINOR.PATCH. Sin embargo, los clientes solo deben seleccionar una API por el número de versión principal, o por la versión menor si hay cambios significativos que no rompen la compatibilidad entre versiones menores. Por ejemplo, los clientes pueden elegir entre la versión 1 y la versión 2 de una API, pero no deben elegir la versión 2.1.3. Si permite ese nivel de granularidad, corre el riesgo de tener que admitir demasiadas versiones.
Para obtener más información, consulte Implementación de versiones para una API web RESTful.
Operaciones idempotentes
Una operación es idempotente si se puede llamar varias veces sin producir más efectos secundarios después de la primera llamada. La idempotencia sirve como una estrategia de resiliencia útil porque permite que un servicio anterior invoque de forma segura una operación varias veces. Para obtener más información, consulte Transacciones distribuidas.
La especificación HTTP indica que los métodos GET, PUT y DELETE deben ser idempotentes.
POST No se garantiza que los métodos sean idempotentes. Si un POST método crea un nuevo recurso, generalmente no hay ninguna garantía de que esta operación sea idempotente. La especificación define idempotent de la siguiente manera:
Un método de solicitud se considera idempotent si el efecto previsto en el servidor de varias solicitudes idénticas con ese método es el mismo que el efecto de una sola solicitud de este tipo. (RFC 7231)
Comprenda la diferencia entre la semántica de PUT y POST al crear una nueva entidad. En ambos casos, el cliente envía una representación de una entidad en el cuerpo de la solicitud. Pero el significado del identificador uniforme de recursos (URI) es diferente.
Para un
POSTmétodo, el URI representa un recurso primario de la nueva entidad, como una colección. Por ejemplo, para crear una nueva entrega, el URI podría ser/api/deliveries. El servidor crea la entidad y le asigna un nuevo URI, como/api/deliveries/39660. Este URI se devuelve en elLocationencabezado de la respuesta. Cada vez que el cliente envía una solicitud, el servidor crea una nueva entidad que tiene un nuevo URI.Para un
PUTmétodo, el URI identifica la entidad. Si una entidad existente tiene ese URI, el servidor reemplaza la entidad existente por la versión de la solicitud. Si ninguna entidad usa ese URI, el servidor crea uno. Por ejemplo, supongamos que el cliente envía unaPUTsolicitud aapi/deliveries/39660. Si ningún recurso de entrega usa ese URI, el servidor crea uno nuevo. Si el cliente envía de nuevo la misma solicitud, el servidor reemplaza la entidad existente.
El servicio de entrega usa el código siguiente para implementar el PUT método :
[HttpPut("{id}")]
[ProducesResponseType<Delivery>(StatusCodes.Status201Created)]
[ProducesResponseType(StatusCodes.Status204NoContent)]
public async Task<IActionResult> Put([FromBody]Delivery delivery, string id)
{
logger.LogInformation("In Put action with delivery {Id}: {@DeliveryInfo}", id, delivery.ToLogInfo());
try
{
var internalDelivery = delivery.ToInternal();
// Create the new delivery entity.
await deliveryRepository.CreateAsync(internalDelivery);
// Create a delivery status event.
var deliveryStatusEvent = new DeliveryStatusEvent { DeliveryId = delivery.Id, Stage = DeliveryEventType.Created };
await deliveryStatusEventRepository.AddAsync(deliveryStatusEvent);
// Return HTTP 201 (Created)
return CreatedAtRoute("GetDelivery", new { id= delivery.Id }, delivery);
}
catch (DuplicateResourceException)
{
// This method mainly creates deliveries. If the delivery already exists, update it.
logger.LogInformation("Updating resource with delivery id: {DeliveryId}", id);
var internalDelivery = delivery.ToInternal();
await deliveryRepository.UpdateAsync(id, internalDelivery);
// Return HTTP 204 (No Content)
return NoContent();
}
}
La mayoría de las solicitudes crean una nueva entidad, por lo que el método espera que la creación se realice correctamente y llame CreateAsync al objeto del repositorio. A continuación, el método controla las excepciones de recursos duplicados mediante la actualización del recurso en su lugar.
Paso siguiente
Obtenga información sobre el uso de una puerta de enlace de API en el límite entre las aplicaciones cliente y los microservicios.