Patrón Pipes and Filters
Descompone una tarea que realiza un procesamiento complejo en una serie de elementos independientes que se pueden volver a utilizar. De esta manera se pueden mejorar el rendimiento, la escalabilidad y la capacidad de reutilización de los primeros pasos al permitir que los elementos de tarea que realizan el procesamiento se implementen y escalen por separado. El patrón canalizaciones y filtros admite un alto nivel de modularidad.
Contexto y problema
Tiene una canalización de tareas secuenciales que debe procesar. Realizar este procesamiento en un módulo monolítico es un método sencillo pero inflexible de implementar una aplicación. Sin embargo, este método reducirá probablemente las posibilidades de refactorización del código, su optimización o su reutilización si partes del mismo procesamiento se necesitan en otra ubicación dentro de la aplicación.
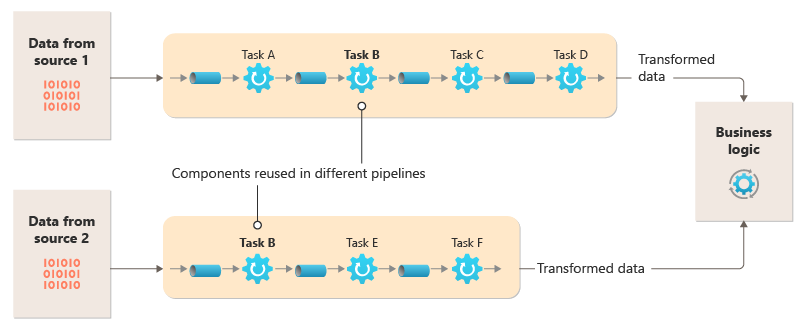
En el diagrama siguiente se muestra uno de los problemas con el procesamiento de datos mediante un enfoque monolítico, la incapacidad de reutilizar el código en varias canalizaciones. En este ejemplo, una aplicación recibe y procesa datos de dos orígenes. Un módulo separado procesa los datos de cada origen realizando una serie de tareas para transformar estos datos antes de transferir el resultado a la lógica de negocios de la aplicación.

Algunas de las tareas que realizan los módulos monolíticos son funcionalmente similares, pero el código debe repetirse en ambos módulos y es probable que esté estrechamente acoplado dentro de su módulo. Además de la incapacidad de reutilizar la lógica, este enfoque presenta un riesgo cuando cambian los requisitos. Debe recordar actualizar el código en ambos lugares.
Una aplicación monolítica plantea otros problemas no relacionados con varias canalizaciones o la reutilización. Con una aplicación monolítica, no tiene la capacidad de ejecutar tareas específicas en diferentes entornos o escalarlas de forma independiente. Algunas tareas pueden requerir una gran cantidad de recursos de proceso y se beneficiarían de un hardware potente o de la ejecución de varias instancias en paralelo. Es posible que otras tareas no tengan los mismos requisitos. Además, con las aplicaciones monolíticas, es difícil reordenar las tareas o insertar otras nuevas en la canalización. Estos cambios requieren volver a probar toda la canalización.
Solución
Desglose el procesamiento que requiere cada flujo en un conjunto de componentes (o filtros) independientes, que realice cada uno una única tarea. Las tareas compuestas deberían usar varios filtros en lugar de uno. Los filtros se componen en canalizaciones mediante la conexión de los filtros con canalizaciones. Los filtros son independientes, autónomos y normalmente sin estado. Los filtros reciben mensajes de una canalización de entrada y publican mensajes en otra canalización de salida. Los filtros pueden transformar el mensaje o probarlo con uno o varios criterios para incluir la lógica condicional. Las canalizaciones no realizan el enrutamiento ni ninguna otra lógica. Solo conectan filtros, transfiriendo el mensaje de salida de un filtro como entrada del siguiente.
Los filtros actúan de forma independiente y desconocen los demás filtros. Solo conocen sus esquemas de entrada y salida. Por lo tanto, los filtros se pueden organizar en cualquier orden siempre que el esquema de entrada de cualquier filtro coincida con el esquema de salida del filtro anterior. El uso de un esquema estandarizado para todos los filtros mejora la capacidad de reordenar filtros. La arquitectura de canalizaciones y filtros fomenta la reutilización composicional.
El acoplamiento flexible de filtros facilita lo siguiente:
- Crear nuevas canalizaciones compuestas de filtros existentes
- Actualizar o reemplazar la lógica en filtros individuales
- Reordenar filtros, cuando sea necesario
- Ejecutar filtros en hardware diferente, cuando sea necesario
- Ejecutar filtros en paralelo
En este diagrama se muestra una solución implementada con canalizaciones y filtros:
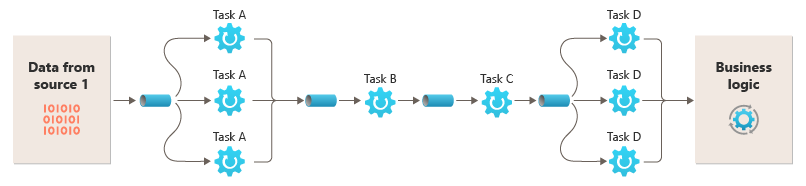
El tiempo que tarda en procesarse una única solicitud depende de la velocidad de los filtros más lentos de la canalización. Uno o más filtros pueden provocar atascos, en especial si un gran número de solicitudes aparece en un flujo de un origen de datos en particular. La capacidad de ejecutar instancias paralelas de filtros lentos permite que el sistema distribuya la carga y mejore el rendimiento.
La capacidad de ejecutar filtros en diferentes instancias de proceso permite escalarlos de manera independiente y aprovechar la elasticidad que proporcionan muchos entornos de nube. Un filtro que consuma muchos recursos informáticos se puede ejecutar en un hardware de alto rendimiento, mientras que los filtros menos exigentes se pueden hospedar en un hardware básico y menos costoso. Los filtros no tienen que estar siquiera en el mismo centro de datos o la misma ubicación geográfica, lo que permite que cada elemento de una canalización se ejecute en un entorno próximo a los recursos que necesita. Estos esfuerzos requieren técnicas de diseño específicas, como mensajería, multiproceso, etc. para maximizar la elasticidad de cada pipeline o filtro. Este diagrama muestra un ejemplo aplicado a la canalización de los datos del Origen 1:
Si la entrada y la salida de un filtro se estructuran como un flujo, se puede realizar el procesamiento de cada filtro en paralelo. El primer filtro de la canalización puede iniciar su trabajo y generar sus resultados, los cuales se traspasan directamente al filtro siguiente de la secuencia antes de que el primero haya completado su trabajo.
El uso del patrón Canalizaciones y filtros en combinación con el patrón Transacción de compensación es una opción alternativa a la implementación de las transacciones distribuidas. Una transacción distribuida se puede dividir en tareas independientes compensables, cada una de los cuales se puede implementar mediante un filtro que a su vez también implementa el patrón de Transacción de compensación. Los filtros de una canalización se pueden implementar como tareas hospedadas diferentes que se ejecutan cerca de los datos que mantienen.
Problemas y consideraciones
Tenga en cuenta los puntos siguientes al decidir cómo implementar este patrón:
Naturaleza monolítica. Este patrón normalmente se implementa como una pipeline monolítica, por lo que, para cualquier cambio, toda la cadena de filtros debe probarse de un extremo a otro. Además, es necesario tener en cuenta la tolerancia a errores para todo el proceso; si se produce un error en un filtro o pipeline, es probable que se produzca un error en toda la pipeline.
Complejidad. La mayor flexibilidad que proporciona este patrón también puede presentar complejidad, especialmente si los filtros de una canalización se distribuyen entre diferentes servidores.
Confiabilidad. Use una infraestructura que garantice que el flujo de datos entre los filtros de una canalización no se pierda.
Idempotencia. Si se produce un error en un filtro de una canalización después de recibir un mensaje y el trabajo se reprograma en otra instancia del filtro, es probable que parte del trabajo ya se haya completado. Si el trabajo actualiza algún aspecto del estado global (por ejemplo, la información almacenada en una base de datos), podría repetirse una única actualización. Un problema similar puede surgir si se produce un error en un filtro después de publicar sus resultados en el filtro siguiente de la canalización, pero antes de que indique que ha completado su trabajo correctamente. En estos casos, otra instancia del filtro podría repetir este trabajo, lo que provoca que los mismos resultados se publiquen dos veces. Esta situación podría dar lugar a que los sucesivos filtros de la canalización procesaran los mismos datos dos veces. Por lo tanto, los filtros de una canalización se deben diseñar para que sean idempotentes. Para más información, consulte los patrones de idempotencia en el blog de Jonathan Oliver.
Mensajes repetidos. Si se produce un error en un filtro de una canalización después de publicarse un mensaje en la siguiente fase de esta, podría ejecutarse otra instancia del filtro y que esta publicase una copia del mismo mensaje en la canalización. Esta situación provocaría que dos instancias del mismo mensaje pasasen al siguiente filtro. Para evitarlo, la canalización debe detectar y eliminar los mensajes duplicados.
Nota
Si va a implementar la canalización mediante colas de mensajes (como las colas de Azure Service Bus), la infraestructura de la puesta en cola de mensajes proporcionará la detección y eliminación automáticas de los mensajes duplicados.
Contexto y estado. En una canalización, cada filtro se ejecuta básicamente de forma aislada y no se debe hacer ninguna suposición sobre cómo se invocó. Esto significa que se debe proporcionar a cada filtro el contexto suficiente para que realice su trabajo. Este contexto puede incluir una gran cantidad de información de estado. Si los filtros usan el estado externo, como los datos de una base de datos o un almacenamiento externo, debe tener en cuenta el impacto en el rendimiento. Cada filtro tiene que cargar, operar y conservar ese estado, lo que agrega sobrecarga a las soluciones que cargan el estado externo una sola vez.
Tolerancia a mensajes. Los filtros deben ser tolerantes con los datos del mensaje entrante contra los que no operan. Operan con los datos que les son pertinentes e ignoran otros datos y los transmiten sin cambios en el mensaje de salida.
Control de errores: cada filtro debe determinar qué hacer en caso de un error de interrupción. El filtro debe determinar si se produce un error en la canalización o propaga la excepción.
Cuándo usar este patrón
Use este patrón en los siguientes supuestos:
El procesamiento que requiera una aplicación se pueda desglosar fácilmente en un conjunto de pasos independientes.
Los pasos de procesamiento que realiza una aplicación tengan requisitos de escalabilidad diferentes.
Nota
Los filtros que se van a escalar juntos se pueden agrupar en el mismo proceso. Para más información, consulte Compute Resource Consolidation pattern (Patrón Compute Resource Consolidation).
Necesita un mínimo de flexibilidad para permitir la reordenación de los pasos de procesamiento que realiza la aplicación o habilitar la funcionalidad para agregar y eliminar pasos.
El sistema puede beneficiarse de la distribución de los pasos de procesamiento entre diferentes servidores.
Se requiere una solución fiable que minimice los efectos de los errores en un paso durante el procesamiento de los datos.
Este modelo podría no ser útil en las situaciones siguientes:
La aplicación sigue un patrón de solicitud-respuesta.
El procesamiento de tareas debe completarse como parte de una solicitud inicial, como un escenario de solicitud o respuesta.
Los pasos de procesamiento que realiza una aplicación no son independientes o se deben realizar conjuntamente como parte de la misma transacción.
La cantidad de información de contexto o estado que requiere un paso convierte a este enfoque en ineficaz. Es posible conservar la información de estado en una base de datos, pero no use esta estrategia si la carga adicional en la base de datos provoca una contención excesiva.
Diseño de cargas de trabajo
Un arquitecto debe evaluar cómo se puede usar el patrón Pipes and Filters en el diseño de su carga de trabajo para abordar los objetivos y principios descritos en los pilares del Marco de buena arquitectura de Azure. Por ejemplo:
| Fundamento | Cómo apoya este patrón los objetivos de los pilares |
|---|---|
| Las decisiones de diseño de la fiabilidad ayudan a que la carga de trabajo sea resistente a los errores y a garantizar que se recupere a un estado de pleno funcionamiento después de que se produzca un error. | La única responsabilidad de cada fase permite la atención centrada y evita la distracción del procesamiento de datos entremezclados. - RE:01 Simplicidad - RE:07 Trabajos en segundo plano |
Al igual que con cualquier decisión de diseño, hay que tener en cuenta las ventajas y desventajas con respecto a los objetivos de los otros pilares que podrían introducirse con este patrón.
Ejemplo
Puede usar una secuencia de colas de mensajes para proporcionar la infraestructura necesaria para implementar una canalización. Una cola de mensajes inicial recibe mensajes sin procesar que se convierten en el inicio de la implementación del patrón de canalizaciones y filtros. Un componente que se implementa como una tarea de filtro escucha un mensaje en esta cola, realiza su trabajo y, a continuación, publica un mensaje nuevo o transformado en la cola siguiente de la secuencia. Otra tarea de filtro puede escuchar mensajes en esta cola, procesarlos, enviar los resultados a otra cola, y así sucesivamente, hasta el paso final que pone fin al proceso de canalizaciones y filtros. En este diagrama se muestra una canalización que usa colas de mensajes:

Una canalización de procesamiento de imágenes podría implementarse con este patrón. Si la carga de trabajo toma una imagen, esta podría pasar por una serie de filtros en gran medida independientes y reordenables para realizar acciones como:
- moderación de contenido
- cambio de tamaño
- aplicación de marcas de agua
- reorientación
- Eliminación de metadatos exif
- Publicación en red de entrega de contenido (CDN)
En este ejemplo, los filtros se podrían implementar como Azure Functions implementadas individualmente o incluso una única aplicación de Azure Function que contenga cada filtro como una implementación aislada. El uso de desencadenadores, enlaces de entrada y enlaces de salida de Azure Functions puede simplificar el código de filtro y funcionar automáticamente con una canalización basada en cola mediante una comprobación de notificaciones para la imagen que se va a procesar.

Este es un ejemplo del aspecto que podría tener un filtro implementado como una Azure Function, desencadenado desde una canalización de Queue Storage con una comprobación de notificación en la imagen y escribiendo una nueva comprobación de notificaciones en otra canalización de Queue Storage. Por motivos de brevedad, hemos sustituido la implementación por pseudocódigo en los comentarios. Puede encontrar más código como este en la demostración del patrón de canalizaciones y filtros disponible en GitHub.
// This is the "Resize" filter. It handles claim checks from input pipe, performs the
// resize work, and places a claim check in the next pipe for anther filter to handle.
[Function(nameof(ResizeFilter))]
[QueueOutput("pipe-fjur", Connection = "pipe")] // Destination pipe claim check
public async Task<string> RunAsync(
[QueueTrigger("pipe-xfty", Connection = "pipe")] string imageFilePath, // Source pipe claim check
[BlobInput("{QueueTrigger}", Connection = "pipe")] BlockBlobClient imageBlob) // Image to process
{
_logger.LogInformation("Processing image {uri} for resizing.", imageBlob.Uri);
// Idempotency checks
// ...
// Download image based on claim check in queue message body
// ...
// Resize the image
// ...
// Write resized image back to storage
// ...
// Create claim check for image and place in the next pipe
// ...
_logger.LogInformation("Image resizing done or not needed. Adding image {filePath} into the next pipe.", imageFilePath);
return imageFilePath;
}
Nota
El marco de integración de Spring tiene una implementación del patrón de canalizaciones y filtros.
Pasos siguientes
Es posible que le resulte útil consultar los siguientes recursos al implementar este patrón:
- Hay disponible una demostración del patrón de canalizaciones y filtros mediante el escenario de procesamiento de imágenes en GitHub.
- Patrones de idempotencia, en el blog de Jonathan Oliver.
Recursos relacionados
Los patrones siguientes también le serán pertinentes cuando implemente este patrón:
- Patrón Claim-Check. Es posible que una canalización implementada mediante una canalización no contenga el elemento real que se envía a través de los filtros, sino un puntero a los datos que se deben procesar. En el ejemplo se usa una comprobación de notificaciones en Azure Queue Storage para las imágenes almacenadas en Azure Blob Storage.
- Patrón de consumidores de la competencia. Una canalización puede contener varias instancias de uno o varios filtros. Este enfoque es útil para ejecutar instancias paralelas de filtros lentos. Permite al sistema distribuir la carga y mejorar el rendimiento. Cada instancia de un filtro competirá por la entrada con las demás instancias. Sin embargo, dos instancias de un mismo filtro nunca deberían procesar los mismos datos. En este artículo se explica dicho enfoque.
- Patrón Compute Resource Consolidation. Es posible agrupar los filtros que deben escalarse juntos en un único proceso. Este artículo proporciona más información sobre las ventajas e inconvenientes de esta estrategia.
- Patrón Compensating Transaction. Un filtro puede implementarse como una operación que se puede invertir o que dispone de una operación de compensación que restaura el estado a una versión anterior en caso de error. En este artículo se explica cómo puede implementar este patrón para mantener o lograr una coherencia finalmente definitiva.
- Canalizaciones y filtros: patrones de integración empresarial.