En este artículo se describe el uso de métricas para encontrar cuellos de botella y mejorar el rendimiento de un sistema distribuido por parte de un equipo de desarrollo. El artículo se basa en la prueba de carga real que se realizó para una aplicación de ejemplo.
Este artículo forma parte de una serie. Puede consultar la primera parte aquí.
Escenario: proceso de un flujo de eventos mediante Azure Functions.

En este escenario, una flota de drones envía datos de posición en tiempo real a Azure IoT Hub. Una aplicación de Functions recibe los eventos, transforma los datos en formato GeoJSON y escribe los datos transformados en Azure Cosmos DB. Azure Cosmos DB tiene compatibilidad nativa con datos geoespaciales y las colecciones de Azure Cosmos DB se pueden indexar para consultas espaciales eficientes. Por ejemplo, una aplicación cliente podría consultar todos los drones que se encuentran a 1 km de una ubicación específica o buscar todos los drones dentro de un área determinada.
Estos requisitos de procesamiento son lo suficientemente simples como para que no necesiten un motor de procesamiento de flujos completo. En particular, el procesamiento no une secuencias, no agrega datos ni procesa en ventanas de tiempo. En función de estos requisitos, Azure Functions es una buena opción para procesar los mensajes. Azure Cosmos DB también se puede escalar para admitir un rendimiento de escritura muy alto.
Supervisión del rendimiento
Este escenario presenta un desafío de rendimiento interesante. Se conoce la velocidad de datos por dispositivo, pero el número de dispositivos puede fluctuar. En este escenario empresarial, los requisitos de latencia no son especialmente rigurosos. La posición notificada de un dron solo debe ser precisa expresada en minutos. Dicho esto, la aplicación de funciones debe mantener la velocidad media de ingesta a lo largo del tiempo.
IoT Hub almacena los mensajes en una secuencia de registro. Los mensajes entrantes se anexan al final de la secuencia. Un lector de la secuencia (en este caso, la aplicación de funciones) controla su propia velocidad de recorrido de la secuencia. Este desacoplamiento de las rutas de lectura y escritura hace que IoT Hub sea muy eficaz, pero también significa que un lector lento puede retrasarse. Para detectar esta situación, el equipo de desarrollo agregó una métrica personalizada para medir el retraso en los mensajes. Esta métrica registra la diferencia entre el momento en el que un mensaje llega a IoT Hub y el momento en el que la función recibe el mensaje para su procesamiento.
var ticksUTCNow = DateTimeOffset.UtcNow;
// Track whether messages are arriving at the function late.
DateTime? firstMsgEnqueuedTicksUtc = messages[0]?.EnqueuedTimeUtc;
if (firstMsgEnqueuedTicksUtc.HasValue)
{
CustomTelemetry.TrackMetric(
context,
"IoTHubMessagesReceivedFreshnessMsec",
(ticksUTCNow - firstMsgEnqueuedTicksUtc.Value).TotalMilliseconds);
}
El método TrackMetric escribe una métrica personalizada en Application Insights. Para obtener información sobre el uso de TrackMetric dentro de una función de Azure, consulte Registrar telemetría personalizada en funciones de C#.
Si la función mantiene el volumen de mensajes, esta métrica debe permanecer en un estado estable bajo. Es inevitable alguna latencia, por lo que el valor nunca será cero. Pero si la función se retrasa, la diferencia entre la hora de puesta en cola y la hora de procesamiento empezará a subir.
Prueba 1: Línea base
La primera prueba de carga mostró un problema inmediato: la aplicación de funciones recibía constantemente errores HTTP 429 de Azure Cosmos DB, lo que indica que Azure Cosmos DB limitaba las solicitudes de escritura.
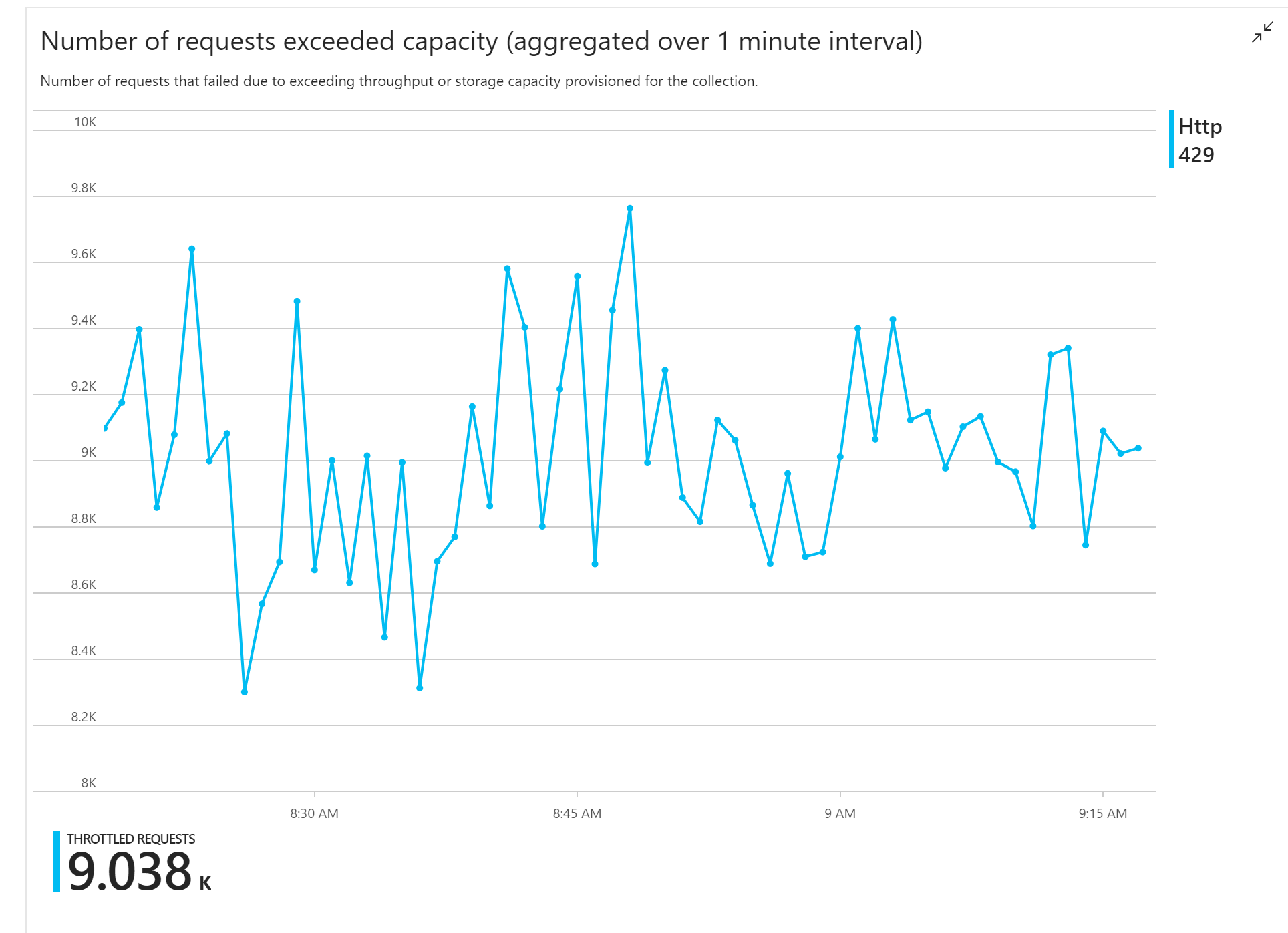
En respuesta, el equipo escaló Azure Cosmos DB mediante el aumento del número de RU asignadas para la colección, pero los errores continuaron. Esto parecía extraño, ya que su cálculo aproximado mostraba que Azure Cosmos DB no debería tener ningún problema para mantener el volumen de solicitudes de escritura.
Más adelante ese día, uno de los desarrolladores envió el siguiente correo electrónico al equipo:
He examinado la ruta de acceso activa de Azure Cosmos DB. Hay una cosa que no entiendo. La clave de partición es deliveryId, pero no se envía deliveryId a Azure Cosmos DB. ¿Hay algo que no he tenido en cuenta?
Esto fue la pista. En el mapa térmico de la partición, se detectó que todos los documentos estaban en la misma partición.
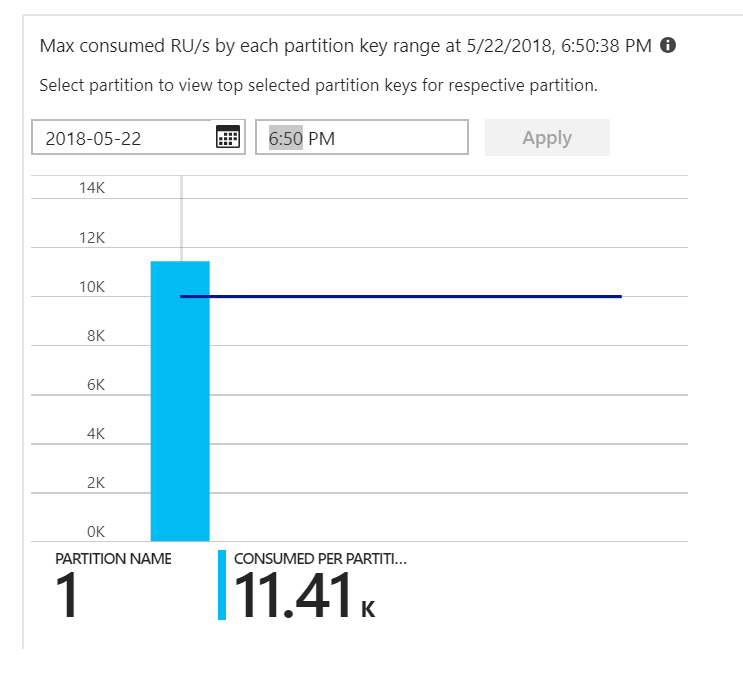
Lo que desearía ver en el mapa térmico es una distribución uniforme entre todas las particiones. En este caso, dado que todos los documentos se han escrito en la misma partición, agregar más RU no resulta de ayuda. El problema resultó ser un error en el código. Aunque la colección de Azure Cosmos DB tenía una clave de partición, la función de Azure no incluía realmente la clave de partición en el documento. Para más información acerca del mapa térmico de particiones, consulte Determinación de la distribución de rendimiento en las particiones.
Prueba 2: corrección del problema de creación de particiones
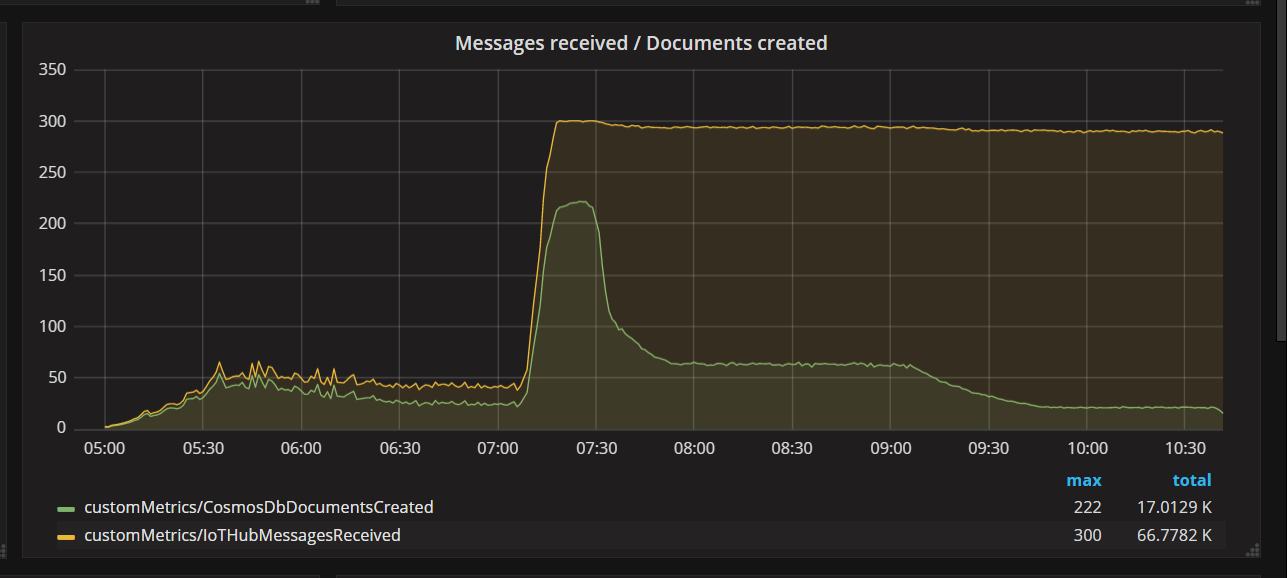
Cuando el equipo implementó una corrección en el código y volvió a ejecutar la prueba, Azure Cosmos DB detuvo la limitación. Durante un tiempo, todo parecía ir bien. Pero en un nivel de carga determinado, la telemetría mostró que la función escribía menos documentos de los que debería. En el siguiente gráfico se muestran los mensajes recibidos desde IoT Hub frente a los documentos escritos en Azure Cosmos DB. La línea amarilla es el número de mensajes recibidos por lote y la verde es el número de documentos escritos por lote. Deberían ser proporcionales. En su lugar, el número de operaciones de escritura en la base de datos por lote cae significativamente aproximadamente a las 07:30.
En el gráfico siguiente se muestra la latencia entre el momento en el que un mensaje llega a IoT Hub desde un dispositivo y el momento en el que la aplicación de funciones procesa dicho mensaje. Puede ver que, en el mismo momento, el retraso crece dramáticamente, se nivela y, a continuación, decrece.
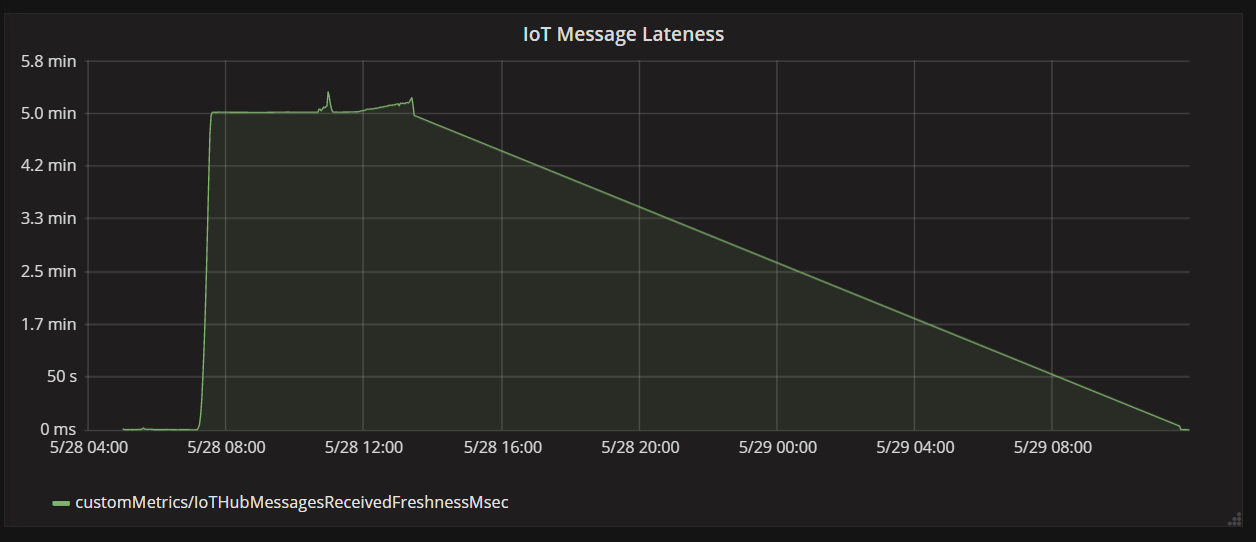
La razón por la que el valor alcanza el máximo en 5 minutos y, a continuación, cae hasta cero, es porque la aplicación de funciones descarta los mensajes que tienen más de 5 minutos de retraso:
foreach (var message in messages)
{
// Drop stale messages,
if (message.EnqueuedTimeUtc < cutoffTime)
{
log.Info($"Dropping late message batch. Enqueued time = {message.EnqueuedTimeUtc}, Cutoff = {cutoffTime}");
droppedMessages++;
continue;
}
}
Puede verlo en el gráfico cuando la métrica del retraso vuelve a cero. Mientras tanto, los datos se han perdido porque la función descartaba los mensajes.
¿Qué ocurría? Para esta prueba de carga en particular, la colección de Azure Cosmos DB tenía RU disponibles, por lo que el cuello de botella no se encontraba en la base de datos. En su lugar, el problema estaba en el bucle de procesamiento de mensajes. Simplemente, la función no escribía los documentos lo suficientemente rápido como para mantenerse al día con el volumen de mensajes entrantes. Con el tiempo, se retrasaba cada vez más.
Prueba 3: escrituras en paralelo
Si el tiempo necesario para procesar un mensaje es el cuello de botella, una solución consiste en procesar más mensajes en paralelo. En este escenario:
- Aumente el número de particiones de IoT Hub. A cada partición de IoT Hub se le asigna una instancia de la función cada vez, por lo que se espera que el rendimiento se escale linealmente con el número de particiones.
- Realice las escrituras de documentos en paralelo dentro de la función.
Para explorar la segunda opción, el equipo modificó la función para admitir escrituras en paralelo. La versión original de la función utilizaba el enlace de salida de Azure Cosmos DB. La versión optimizada llama directamente al cliente de Azure Cosmos DB y realiza las escrituras en paralelo mediante Task.WhenAll:
private async Task<(long documentsUpserted,
long droppedMessages,
long cosmosDbTotalMilliseconds)>
ProcessMessagesFromEventHub(
int taskCount,
int numberOfDocumentsToUpsertPerTask,
EventData[] messages,
TraceWriter log)
{
DateTimeOffset cutoffTime = DateTimeOffset.UtcNow.AddMinutes(-5);
var tasks = new List<Task>();
for (var i = 0; i < taskCount; i++)
{
var docsToUpsert = messages
.Skip(i * numberOfDocumentsToUpsertPerTask)
.Take(numberOfDocumentsToUpsertPerTask);
// client will attempt to create connections to the data
// nodes on Azure Cosmos DB clusters on a range of port numbers
tasks.Add(UpsertDocuments(i, docsToUpsert, cutoffTime, log));
}
await Task.WhenAll(tasks);
return (this.UpsertedDocuments,
this.DroppedMessages,
this.CosmosDbTotalMilliseconds);
}
Tenga en cuenta que se pueden dar condiciones de carrera con este enfoque. Supongamos que dos mensajes del mismo dron llegan en el mismo lote de mensajes. Al escribirlos en paralelo, el mensaje anterior podría sobrescribir el mensaje posterior. En este escenario en particular, la aplicación puede tolerar la pérdida de un mensaje ocasional. Los drones envían nuevos datos de posición cada 5 segundos, por lo que los datos de Azure Cosmos DB se actualizan continuamente. En otros escenarios, sin embargo, puede ser importante procesar los mensajes en orden estricto.
Después de implementar este cambio en el código, la aplicación fue capaz de ingerir más de 2500 solicitudes por segundo, con un centro de IoT con 32 particiones.
Consideraciones del lado cliente
La experiencia general del cliente puede reducirse mediante una paralelización agresiva en el servidor. Considere la posibilidad de usar la biblioteca Bulk Executor de Azure Cosmos DB (no se muestra en esta implementación), que reduce significativamente los recursos de proceso necesarios en el cliente para saturar el rendimiento asignado a un contenedor de Azure Cosmos DB. Una aplicación de un solo proceso que escribe datos mediante la API de importación masiva logra diez veces más rendimiento de escritura en comparación con una aplicación multiproceso que escribe datos en paralelo, al tiempo que se satura la CPU del equipo cliente.
Resumen
En este escenario, se identificaron los siguientes cuellos de botella:
- Partición de escritura activa, debido a que faltaba un valor de clave de partición en los documentos que se escribían.
- Escritura de documentos en serie por cada partición de IoT Hub.
Para diagnosticar estos problemas, el equipo de desarrollo se basó en las siguientes métricas:
- Solicitudes limitadas en Azure Cosmos DB.
- Mapa térmico de particiones: número máximo de RU consumidas por partición.
- Mensajes recibidos frente a documentos creados.
- Retraso en los mensajes.
Pasos siguientes
Consulte Antipatrones de rendimiento.