Esta arquitectura de ejemplo se basa en la arquitectura de ejemplo de Aplicación web básica y la amplía para mostrar:
- Prácticas probadas para mejorar la escalabilidad y el rendimiento en una aplicación web Azure App Service.
- Cómo ejecutar una aplicación Azure App Service en varias regiones para lograr una alta disponibilidad
Architecture
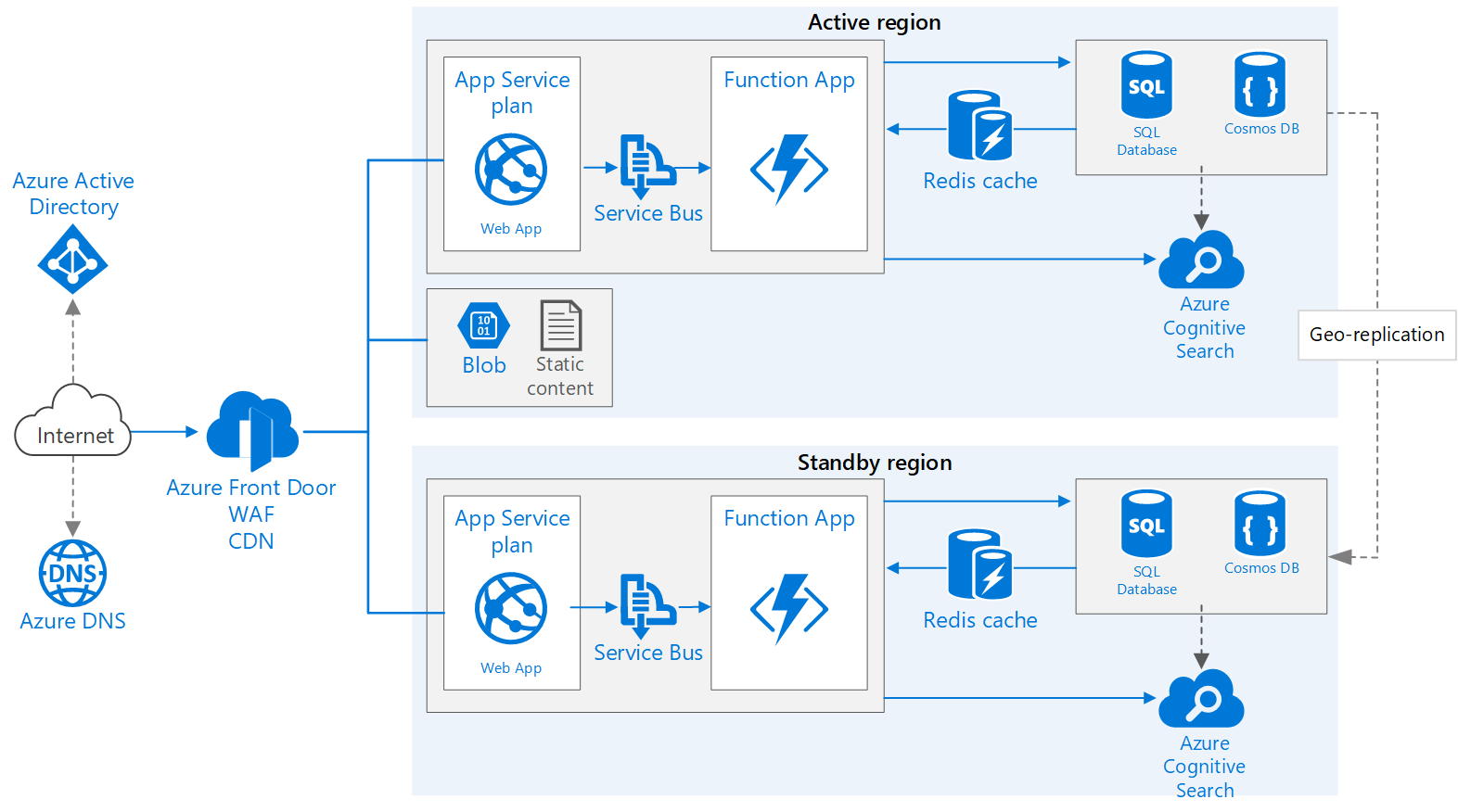
Descargue un archivo Visio de esta arquitectura.
Flujo de trabajo
Este flujo de trabajo aborda los aspectos multirregión de la arquitectura y se basa en la Aplicación web básica.
- Regiones primarias y secundarias Esta arquitectura emplea dos regiones para lograr una mayor disponibilidad. La aplicación se implementa en cada región. Durante las operaciones normales, el tráfico de red se enruta a la región primaria. Si la región primaria deja de estar disponible, el tráfico se enruta a la región secundaria.
- Front Door. Azure Front Door es el equilibrador de carga recomendado para implementaciones multirregión. Se integra con el firewall de aplicaciones web (WAF) para proteger contra vulnerabilidad de seguridad comunes y utiliza la funcionalidad nativa de almacenamiento en caché de contenido de Front Door. En esta arquitectura, Front Door está configurado para enrutamiento de prioridad, que envía todo el tráfico a la región principal a menos que no esté disponible. Si la región primaria deja de estar disponible, Front Door enrutará todo el tráfico a la región secundaria.
- Replicación geográfica de cuentas de almacenamiento, SQL Database y/o Azure Cosmos DB.
Nota
Para obtener una descripción detallada del uso de Azure Front Door en arquitecturas multirregión, incluida una configuración segura de red, consulte Implementación de entrada segura de red.
Componentes
Tecnologías clave que se usan para implementar esta arquitectura:
- Microsoft Entra ID es un servicio de administración de identidades y acceso basado en la nube que permite a los empleados acceder a aplicaciones en la nube desarrolladas para su organización.
- Azure DNS es un servicio de hospedaje para dominios DNS que permite resolver nombres mediante la infraestructura de Microsoft Azure. Al hospedar dominios en Azure, puede administrar los registros DNS con las mismas credenciales, API, herramientas y facturación que con los demás servicios de Azure. Para usar un nombre de dominio personalizado, como
contoso.com, cree registros DNS que asignen el nombre de dominio personalizado a la dirección IP. Para más información, consulte Configurar un nombre de dominio personalizado en Azure App Service. - Azure Content Delivery Network es una solución global para distribuir contenidos de gran ancho de banda almacenándolos en caché en nodos físicos estratégicamente situados en todo el mundo.
- Azure Front Door es un equilibrador de carga de capa 7. En esta arquitectura, enruta las solicitudes HTTP al front-end web. Front Door proporciona también un firewall de aplicaciones web (WAF) que protege la aplicación contra puntos vulnerables de la seguridad comunes. Front Door también se usa con una solución Content Delivery Network (CDN) en este diseño.
- Azure AppService es una plataforma totalmente administrada para crear e implementar aplicaciones en la nube. Permite definir un conjunto de recursos de proceso para que una aplicación web se ejecute, implemente aplicaciones web y configure ranuras de implementación.
- Azure Function Apps puede utilizarse para ejecutar tareas en segundo plano. Las funciones se invocan mediante un desencadenador como, por ejemplo, un evento del temporizador o un mensaje que se coloca en cola. Para las tareas con estado de ejecución prolongada, use Durable Functions.
- Azure Storage es una solución de almacenamiento en la nube para escenarios modernos de almacenamiento de datos, que ofrece un almacenamiento altamente disponible, masivamente escalable, duradero y seguro para una gran variedad de objetos de datos en la nube.
- Azure Redis Cache es un servicio de caché de alto rendimiento que proporciona un almacén de datos en memoria para una recuperación más rápida de los datos, basado en la implementación de código abierto Redis cache.
- Azure SQL Database es una base de datos como servicio relacional en la nube. SQL Database comparte su base de código con el motor de base de datos de Microsoft SQL Server.
- Azure Cosmos DB es una base de datos globalmente distribuida, totalmente administrada, de baja latencia, multi-modelo, multi-consulta-API para la administración de datos a gran escala.
- Azure Cognitive Search puede utilizarse para añadir funcionalidades de búsqueda como sugerencias de búsqueda, búsqueda difusa y búsqueda específica por idioma. Azure Search se usa normalmente en combinación con otro almacén de datos, en especial si el almacén de datos principal requiere una coherencia estricta. En este enfoque, almacene los datos acreditado en el otro almacén de datos y el índice de búsqueda en Azure Search. Azure Search también se puede usar para consolidar un índice de búsqueda sencillo desde varios almacenes de datos.
Detalles del escenario
Existen varios enfoques generales para lograr una alta disponibilidad en regiones:
Activo/pasivo con espera activa: el tráfico va a una región, mientras que el otro espera en espera activa. La espera activa significa que App Service de la región secundaria está asignado y está siempre en ejecución.
Activo/pasivo con espera en frío: el tráfico va a una región, mientras que el otro espera en espera en frío. El modo de espera pasiva significa que App Service de la región secundaria no se asigna hasta que sea necesario para la conmutación por error. Este enfoque tiene un coste menor de ejecución, pero generalmente tarda más en ponerse en línea durante un error.
Activo/Activo: ambas regiones están activas y se equilibra la carga de las solicitudes entre ellas. Si una región deja de estar disponible, se elimina de la rotación.
Esta referencia se centra en activo/pasivo con servidor en espera activa.
Posibles casos de uso
Estos casos de uso pueden beneficiarse de una implementación en varias regiones:
Diseño de un plan de continuidad empresarial y recuperación ante desastres para aplicaciones de LoB.
Implementación de aplicaciones críticas que se ejecutan en Windows o Linux.
Mejora de la experiencia del usuario al mantener las aplicaciones disponibles.
Recomendaciones
Los requisitos pueden diferir de los de la arquitectura que se describe aquí. Use las recomendaciones de esta sección como punto de partida.
Emparejamiento regional
Cada región de Azure se empareja con otra región de la misma zona geográfica. En general, elija regiones del mismo par de regional (por ejemplo, Este de EE. UU. 2 y Centro de EE. UU.). Las ventajas de hacerlo son:
- Si se produce una interrupción prolongada, se establece como prioridad la recuperación de al menos una región de cada par.
- Las actualizaciones planeadas del sistema de Azure se implementan en las regiones emparejadas de manera secuencial para reducir el posible tiempo de inactividad.
- En la mayoría de los casos, los pares regionales residen en la misma zona geográfica para cumplir los requisitos de residencia de datos.
Sin embargo, asegúrese de que ambas regiones admitan todos los servicios de Azure necesarios para la aplicación. Consulte Regiones de Azure. Para más información sobre los pares regionales, consulte Continuidad empresarial y recuperación ante desastres (BCDR): Regiones emparejadas de Azure.
Grupos de recursos
Considere la posibilidad de colocar la región primaria, la región secundaria y Front Door en grupos de recursos diferentes. Esta asignación le permite administrar los recursos implementados en cada región como una sola colección.
Aplicaciones de App Service
Se recomienda crear la aplicación web y la API web como aplicaciones de App Service independientes. Este diseño permite ejecutarlas en planes de App Service diferentes, por lo que se pueden escalar de forma independiente. Si inicialmente no necesita ese nivel de escalabilidad, puede implementar las aplicaciones en el mismo plan y moverlas más tarde a planes diferentes si es necesario.
Nota
Los planes Básico, Estándar, Premium y Aislado se facturan por las instancias de máquina virtual, no por aplicación. Consulte Precios de App Service.
Configuración de Front Door
Enrutamiento. Front Door admite varios mecanismos de enrutamiento. Para el escenario descrito en este artículo, use el enrutamiento de prioridad. Con esta configuración, Front Door envía todas las solicitudes a la región primaria, a menos que el punto de conexión de esa región se vuelva inaccesible. En ese momento, conmuta por error automáticamente a la región secundaria. Establezca el grupo de origen con distintos valores de prioridad, 1 para la región activa y 2 o superior para la región en espera o pasiva.
Sondeo de mantenimiento. Front Door usa un sondeo HTTPS para supervisar la disponibilidad de cada back-end. El sondeo proporciona a Front Door una prueba de acierto/error para conmutar por error a la región secundaria. Funciona mediante el envío de una solicitud a la ruta de acceso de una dirección URL especificada. Si recibe una respuesta distinta de 200 dentro de un período de tiempo de espera, el sondeo produce un error. Puede configurar la frecuencia de sondeo de mantenimiento, el número de muestras necesarias para la evaluación y el número de ejemplos correctos necesarios a fin de que el origen se marque como correcto. Si Front Door marca el origen como degradado, conmuta por error al otro origen. Para más información, consulte Sondeos de estado.
Como procedimiento recomendado, cree una ruta de acceso de sondeo de estado en el origen de la aplicación que indique el estado general de la aplicación. Este sondeo de estado debe comprobar dependencias críticas, como las aplicaciones de App Service, la cola de almacenamiento y SQL Database. En caso contrario, el sondeo podría informar de un origen correcto cuando realmente se producen errores en partes críticas de la aplicación. Por otro lado, no use el sondeo de estado para comprobar los servicios de prioridad inferior. Por ejemplo, si un servicio de correo electrónico queda fuera de servicio, la aplicación puede cambiar a un segundo proveedor o simplemente enviar los mensajes de correo electrónico más tarde. Para obtener más información sobre este modelo de diseño, consulte Patrón Health Endpoint Monitoring.
Proteger los orígenes de Internet es una parte fundamental de la implementación de una aplicación de acceso público. Consulte Implementación de entrada segura de red para obtener información sobre los patrones de implementación y diseño recomendados de Microsoft a fin de proteger las comunicaciones de entrada de la aplicación con Front Door.
CDN. Use la funcionalidad de red CDN nativa de Front Door para almacenar en caché el contenido estático. La principal ventaja de una red CDN es reducir la latencia de los usuarios, ya que el contenido se almacena en caché en un servidor perimetral que está geográficamente próximo al usuario. CDN también puede reducir la carga sobre la aplicación, ya que el la aplicación no administra el tráfico. Front Door también ofrece aceleración de sitios dinámicos, lo que le permite ofrecer una mejor experiencia de usuario general para la aplicación web de la que estaría disponible solo con el almacenamiento en caché de contenido estático.
Nota
La red CDN de Front Door no está diseñada para proporcionar contenido que requiera autenticación.
SQL Database
Use la replicación geográfica activa y los grupos de conmutación por error automática para que las bases de datos sean resistentes. La replicación geográfica activa permite replicar las bases de datos de la región primaria en una o varias (hasta cuatro) regiones distintas. Los grupos de conmutación por error automática se basan en la replicación geográfica activa, ya que le permiten conmutar por error a una base de datos secundaria sin necesidad de cambiar código en las aplicaciones. Las conmutaciones por error se pueden realizar manual o automáticamente, según las definiciones de directiva que cree. A fin de usar grupos de conmutación por error automática, deberá configurar las cadenas de conexión con la cadena de conexión de conmutación por error creada automáticamente para el grupo de conmutación por error, en lugar de las cadenas de conexión de las bases de datos individuales.
Azure Cosmos DB
Azure Cosmos DB admite la replicación geográfica entre regiones en el modelo activo-activo con varias regiones de escritura. Como alternativa, puede designar una región como la región de escritura y las demás como réplicas de solo lectura. Si se produce una interrupción regional del sistema, puede conmutar por error y seleccionar otra región como la región de escritura. El SDK de cliente envía automáticamente las solicitudes de escritura a la región de escritura actual, por lo que no es necesario actualizar la configuración del cliente después de una conmutación por error. Para más información, consulte Distribución de datos global con Azure Cosmos DB.
Storage
Para Azure Storage, use almacenamiento con redundancia geográfica con acceso de lectura (RA-GRS). Con el almacenamiento RA-GRS, los datos se replican en una región secundaria. Tiene acceso de solo lectura a los datos de la región secundaria mediante un punto de conexión independiente. La conmutación por error iniciada por el usuario a la región secundaria es compatible con las cuentas de almacenamiento con replicación geográfica. Al iniciar una conmutación por error de la cuenta de almacenamiento, se actualizan automáticamente los registros DNS para que la cuenta de almacenamiento secundaria sea la nueva cuenta de almacenamiento principal. Las conmutaciones por error solo deben realizarse cuando se considere que son necesarias. Este requisito lo define el plan de recuperación ante desastres de su organización y debe tener en cuenta las implicaciones que se describen en la sección Consideraciones, que encontrará a continuación.
Si se produce una interrupción o un desastre locales, el equipo de Azure Storage puede decidir realizar una conmutación por error geográfica a la región secundaria. Para estos tipos de conmutaciones por error, el cliente no necesita realizar ninguna acción. La conmutación por recuperación a la región primaria también la administra el equipo de almacenamiento de Azure en estos casos.
En algunos casos, la replicación de objetos para blobs en bloques será una solución de replicación suficiente para la carga de trabajo. Esta característica de replicación permite copiar blobs en bloques individuales de la cuenta de almacenamiento principal en una cuenta de almacenamiento de la región secundaria. Las ventajas de este enfoque son el tener un control pormenorizado sobre qué datos se replican. Puede definir una directiva de replicación para un control más granular de los tipos de blobs en bloques que se replican. Entre los ejemplos de definiciones de directiva se incluyen, entre otros, los siguientes:
- Solo se replican los blobs en bloques agregados posteriores a la creación de la directiva.
- Solo se replican los blobs en bloques agregados después de una fecha y hora determinada.
- Solo se replican los blobs en bloques que coinciden con un prefijo determinado.
Se hace referencia a Queue Storage como opción de mensajería alternativa a Azure Service Bus para este escenario. Sin embargo, si usa almacenamiento en cola para la solución de mensajería, la guía proporcionada anteriormente en relación con la replicación geográfica se aplica aquí, ya que el almacenamiento en cola reside en las cuentas de almacenamiento. No obstante, es importante saber que los mensajes no se replican en la región secundaria y su estado es inextricable desde la región.
Azure Service Bus
A fin de beneficiarse de la mayor resistencia que se ofrece para Azure Service Bus, use el nivel Premium para los espacios de nombres. El nivel Premium usa zonas de disponibilidad, lo que hace que los espacios de nombres sean resistentes a las interrupciones del centro de datos. Si se produce un desastre generalizado que afecte a varios centros de datos, la característica Recuperación ante desastres geográfica incluida con el nivel Prémium puede ayudarle a recuperarse. La característica de recuperación ante desastres geográfica garantiza que toda la configuración de un espacio de nombres (colas, temas, suscripciones y filtros) se replique continuamente de un espacio de nombres principal a uno secundario cuando se emparejan. Permite iniciar un movimiento de conmutación por error solo una vez desde el espacio de nombres principal al secundario en cualquier momento. El movimiento de la conmutación por error volverá a apuntar el nombre de alias elegido para el espacio de nombres al espacio de nombres secundario y, luego, interrumpirá el emparejamiento. La conmutación por error es casi instantánea una vez que se ha iniciado.
Azure Cognitive Search
En Cognitive Search, la disponibilidad se logra mediante varias réplicas, mientras que la continuidad empresarial y recuperación ante desastres (BCDR) se logra mediante varios servicios de búsqueda.
En Cognitive Search, las réplicas son copias del índice. Tener varias réplicas permite que Azure Cognitive Search realice tareas de reinicio y mantenimiento de la máquina en una réplica, mientras que la ejecución de consultas continúa en otras. Para obtener más información sobre cómo agregar réplicas, vea Adición o reducción de réplicas y particiones.
Puede agregar dos o más réplicas al servicio de búsqueda para utilizar Availability Zones con Azure Cognitive Search. Cada réplica se colocará en una zona de disponibilidad distinta dentro de la región.
Para conocer las consideraciones sobre BCDR, consulte la documentación relacionada con varios servicios en regiones geográficas independientes.
Azure Cache for Redis
Aunque todos los niveles de Azure Cache for Redis ofrecen replicación Estándar para alta disponibilidad, se recomienda el nivel Premium o Enterprise a fin de proporcionar un mayor nivel de resistencia y capacidad de recuperación. Revise Alta disponibilidad y recuperación ante desastres a fin de obtener una lista completa de características y opciones de resistencia y capacidad de recuperación para estos niveles. Los requisitos empresariales determinarán qué nivel es el más adecuado para su infraestructura.
Consideraciones
Estas consideraciones implementan los pilares del marco de buena arquitectura de Azure, que es un conjunto de principios guía que se pueden usar para mejorar la calidad de una carga de trabajo. Para más información, consulte Marco de buena arquitectura de Microsoft Azure.
Confiabilidad
La confiabilidad garantiza que la aplicación pueda cumplir los compromisos contraídos con los clientes. Para más información, consulte Resumen del pilar de fiabilidad. Tenga en cuenta estos puntos al diseñar para lograr una alta disponibilidad entre regiones.
Azure Front Door
Azure Front Door conmuta por error automáticamente si la región primaria deja de estar disponible. Cuando Front Door realiza la conmutación por error, hay un período de tiempo (normalmente de entre 20 y 60 segundos) en que los clientes no pueden acceder a la aplicación. La duración viene determinada por los siguientes factores:
- Frecuencia de los sondeos de estado. Cuanto mayor es la frecuencia de envío de sondeos de estado, más rápido puede detectar Front Door el tiempo de inactividad o la devolución del origen correcto.
- Configuración de tamaño de ejemplo. Esta configuración controla el número de muestras que se requieren para que el sondeo de estado detecte que el origen principal se ha vuelto inaccesible. Si este valor es demasiado bajo, podría obtener falsos positivos de problemas intermitentes.
Front Door es un posible punto de error en el sistema. Si el servicio no funciona, los clientes no pueden acceder a la aplicación durante el tiempo de inactividad. Consulte el contrato de nivel de servicio de Front Door y determine si el uso de Front Door por sí solo cumple sus requisitos empresariales de alta disponibilidad. Si no es así, considere la posibilidad de agregar otra solución de administración de tráfico como reserva. Si el servicio Front Door no funciona, cambie los registros de nombre canónico (CNAME) de DNS para que apunten al otro servicio de administración del tráfico. Este paso debe realizarse manualmente, y la aplicación dejará de estar disponible hasta que se propaguen los cambios de DNS.
Los niveles Estándar y Prémium de Azure Front Door combinan las funcionalidades de Azure Front Door (clásico), Azure CDN Estándar de Microsoft (clásico) y Azure WAF en una única plataforma. El uso de Azure Front Door Estándar o Premium reduce los puntos de error y permite un control, supervisión y seguridad mejorados. Para más información, consulte Información general del nivel de Azure Front Door.
SQL Database
El objetivo de punto de recuperación (RPO) y el objetivo de tiempo de recuperación estimado (RTO) de SQL Database se documentan en Introducción a la continuidad empresarial con Azure SQL Database y Azure SQL Managed Instance.
Tenga en cuenta que la replicación geográfica activa duplica eficazmente el costo de cada base de datos replicada. Las bases de datos de espacio aislado, prueba y desarrollo normalmente no se recomiendan para la replicación.
Azure Cosmos DB
El RPO y el RTO de Azure Cosmos DB se pueden configurar a través de los niveles de coherencia utilizados, que proporcionan ventajas y desventajas entre la disponibilidad, la durabilidad de los datos y el rendimiento. Azure Cosmos DB proporciona un RTO mínimo de 0 para un nivel de coherencia relajado con una arquitectura multimaestro, o un RPO de 0 para una coherencia fuerte con un solo maestro. Para obtener más información sobre los niveles de coherencia de Azure Cosmos DB, consulte Niveles de coherencia y durabilidad de los datos en Azure Cosmos DB.
Storage
El almacenamiento RA-GRS proporciona almacenamiento duradero, pero es importante tener en cuenta los factores siguientes al contemplar la realización de una conmutación por error:
Anticípese a la pérdida de datos: la replicación de datos en la región secundaria se realiza de forma asincrónica. Por consiguiente, si se realiza una conmutación por error geográfica, se debe prever cierta pérdida de datos si los cambios en la cuenta principal no se han sincronizado completamente con la cuenta secundaria. Puede comprobar la propiedad Hora de la última sincronización de la cuenta de almacenamiento secundaria para ver la última vez que los datos de la región primaria se escribieron correctamente en la región secundaria.
Planifique el objetivo de tiempo de recuperación (RTO) en consecuencia: la conmutación por error a la región secundaria suele tardar aproximadamente una hora, por lo que el plan de recuperación ante desastres debe tener en cuenta esta información a la hora de calcular los parámetros de RTO.
Planee cuidadosamente la conmutación por recuperación: es importante comprender que, cuando una cuenta de almacenamiento conmuta por error, los datos de la cuenta principal original se pierden. Es arriesgado intentar una conmutación por recuperación en la región primaria sin planearla meticulosamente. Una vez completada la conmutación por error, la nueva principal (en la región de conmutación por error) se configurará para el almacenamiento con redundancia local (LRS). Debe volver a configurarlo manualmente como almacenamiento con replicación geográfica para iniciar la replicación en la región primaria y, después, proporcionar tiempo suficiente a fin de permitir que las cuentas se sincronicen.
Los errores transitorios, como una interrupción de la red, no desencadenarán una conmutación por error del almacenamiento. Diseñe la aplicación para que sea resistente a los errores transitorios. Las opciones de mitigación incluyen:
- Realizar las operaciones de lectura desde la región secundaria.
- Cambiar temporalmente a otra cuenta de almacenamiento con nuevas operaciones de escritura (por ejemplo, poner en cola los mensajes).
- Copiar los datos de la región secundaria a otra cuenta de almacenamiento.
- Proporcionan funcionalidad reducida hasta que el sistema con errores conmute por recuperación.
Para más información, vea Qué hacer si se produce una interrupción del servicio Azure Storage.
Consulte la documentación sobre los requisitos previos y las advertencias de la replicación de objetos para conocer las consideraciones al usar la replicación de objetos para blobs en bloques.
Azure Service Bus
Es importante comprender que la característica de recuperación ante desastres geográfica incluida en el nivel Prémium de Azure Service Bus permite la continuidad instantánea de las operaciones con la misma configuración. Sin embargo, no replica los mensajes incluidos en colas, las suscripciones de temas ni las colas de mensajes fallidos. Por lo tanto, se requiere una estrategia de mitigación para garantizar una conmutación por error fluida a la región secundaria. Para obtener una descripción detallada de otras consideraciones y estrategias de mitigación, consulte los puntos importantes a tener en cuenta y la documentación sobre consideraciones de recuperación ante desastres.
Seguridad
La seguridad proporciona garantías contra ataques deliberados y el abuso de datos y sistemas valiosos. Para más información, consulte Introducción al pilar de seguridad.
Restringir el tráfico entrante Configure la aplicación para que solo acepte tráfico procedente de Front Door. Esto garantiza que todo el tráfico pase por el firewall de aplicaciones web antes de llegar a la aplicación. Para más información, consulte ¿Cómo puedo hacer que Azure Front Door sea el único que tenga acceso a mi back-end?
Cross-Origin Resource Sharing (CORS) Si crea un sitio web y una API web como aplicaciones separadas, el sitio web no podrá realizar llamadas AJAX del lado del cliente a la API a menos que active CORS.
Nota
La seguridad del explorador impide que una página web realice solicitudes AJAX a otro dominio. Esta restricción se conoce como la directiva de mismo origen y evita que un sitio malintencionado lea datos confidenciales de otro sitio. CORS es una norma de W3C que permite que un servidor "se relaje" con la directiva del mismo origen de forma que permite algunas solicitudes entre orígenes y rechaza otras.
App Services tiene compatibilidad integrada con CORS, sin necesidad de escribir ningún código de aplicación. Consulte Consumo de una aplicación de API desde JavaScript con CORS. Agregue el sitio web a la lista de orígenes permitidos para la API.
Encriptación de bases de datos SQL Utilice Cifrado de datos transparente si necesita cifrar datos en reposo en la base de datos. Esta característica realiza el cifrado y el descifrado en tiempo real de una base de datos completa (incluidas las copias de seguridad y los archivos de registros de transacciones) y no requiere realizar ningún cambio en la aplicación. El cifrado agrega alguna latencia, así que es conveniente separar los datos que deben estar protegidos en su propia base de datos y habilitar el cifrado únicamente para esa base de datos.
Identidad Cuando defina identidades para los componentes de esta arquitectura, utilice identidades administradas por el sistema siempre que sea posible para reducir la necesidad de administrar credenciales y los riesgos inherentes a la administración de credenciales. Cuando no sea posible usar identidades administradas por el sistema, asegúrese de que todas las identidades administradas por el usuario existan en una sola región y nunca se compartan fuera de los límites de la región.
Firewalls de servicio Al configurar los firewalls de servicio para los componentes, asegúrese tanto de que solo los servicios locales de la región tienen acceso a los servicios como de que los servicios solo permiten conexiones salientes, lo que se requiere explícitamente para la replicación y la funcionalidad de la aplicación. Considere la posibilidad de usar Azure Private Link para mejorar aún más el control y la segmentación. Para obtener más información sobre cómo proteger las aplicaciones web, consulte Aplicación web con redundancia de zona de alta disponibilidad de línea base.
Optimización de costos
La optimización de costos trata de buscar formas de reducir los gastos innecesarios y mejorar las eficiencias operativas. Para más información, vea Información general del pilar de optimización de costos.
Almacenamiento Utilice el almacenamiento en caché para reducir la carga de los servidores que sirven contenidos que no cambian con frecuencia. Cada ciclo de representación de una página puede afectar al costo, porque consume proceso, memoria y ancho de banda. Estos costos se pueden reducir significativamente mediante el uso del almacenamiento en caché, especialmente en el caso de los servicios de contenido estático, como las aplicaciones de página única de JavaScript y el contenido de streaming multimedia.
Si la aplicación tiene contenido estático, use CDN para reducir la carga en los servidores front-end. En el caso de los datos que no cambian con frecuencia, use Azure Cache for Redis.
Estado Las aplicaciones sin estado configuradas para el autoescalado son más rentables que las aplicaciones con estado. En el caso de una aplicación ASP.NET que usa estado de sesión, almacénela en la memoria con Azure Cache for Redis. Para más información, consulte Proveedor de estado de sesión de ASP.NET para Azure Cache for Redis. Otra opción es usar Azure Cosmos DB como un almacén de estado de back-end a través de un proveedor de estado de sesión. Consulte Uso de Azure Cosmos DB como un proveedor de almacenamiento en caché y estado de sesión de ASP.NET.
Funciones Considere la posibilidad de colocar una aplicación de funciones en un plan de App Service dedicado para que las tareas en segundo plano no se ejecuten en las mismas instancias que administran las solicitudes HTTP. Si las tareas en segundo plano se ejecutan de forma intermitente, considere la posibilidad de usar un plan de consumo, que se facture según el número de ejecuciones y recursos en lugar de por horas.
Para más información, consulte la sección sobre costos en Marco de buena arquitectura de Microsoft Azure.
Use la calculadora de precios para calcular los costos. Las recomendaciones de esta sección pueden ayudarle a reducir el costo.
Azure Front Door
La facturación de Azure Front Door presenta tres planes de tarifa: transferencias de datos de salida, transferencias de datos de entrada y reglas de enrutamiento. Para más información, consulte Precios de Azure Front Door. El gráfico de precios no incluye el costo de acceder a los datos desde los servicios de origen y su transferencia a Front Door. Estos costos se facturan en función de los cargos de transferencia de datos, que se describen en Detalles de precios de ancho de banda.
Azure Cosmos DB
Hay dos factores que determinan los precios de Azure Cosmos DB:
El rendimiento aprovisionado o las unidades de solicitud por segundo (RU/s).
Hay dos tipos de rendimiento que se pueden aprovisionar en Azure Cosmos DB: estándar y escalabilidad automática. El rendimiento estándar asigna los recursos necesarios para garantizar las RU/s que se especifiquen. Para la escalabilidad automática, se aprovisiona el rendimiento máximo, y Azure Cosmos DB se escala o reduce verticalmente de forma instantánea en función de la carga, con un mínimo de un 10 % del rendimiento máximo de escalabilidad automática. El rendimiento estándar se factura por el rendimiento aprovisionado cada hora. El rendimiento de la escalabilidad automática se factura por el rendimiento máximo cada hora.
Almacenamiento consumido. Se le cobrará una tarifa plana por la cantidad total de almacenamiento (GB) usada para los datos y los índices en una hora concreta.
Para más información, consulte la sección acerca de los costos del artículo sobre elmarco de buena arquitectura de Microsoft Azure.
Eficiencia del rendimiento
Una de las ventajas principales de Azure App Service es la posibilidad de escalar la aplicación en función de la carga. Estas son algunas consideraciones que se deben tener en cuenta al planear el escalado de la aplicación.
Aplicación de App Service
Si la solución incluye varias aplicaciones de App Service, podría implementarlas en planes de App Service diferentes. Este enfoque permite escalarlas por separado porque se ejecutan en instancias independientes.
SQL Database
Aumente la escalabilidad de una base de datos SQL mediante el particionamiento de la base de datos. El particionamiento hace referencia a la creación de particiones de la base de datos de manera horizontal. El particionamiento permite escalar la base de datos horizontalmente mediante las herramientas de Base de datos elástica. Entre las posibles ventajas del particionamiento se incluyen:
- Mejor rendimiento de las transacciones.
- Las consultas pueden ejecutarse con mayor rapidez sobre un subconjunto de los datos.
Azure Front Door
Front Door puede realizar la descarga SSL y también reduce el número total de conexiones TCP con la aplicación web de back-end. Esto mejora la escalabilidad porque la aplicación web administra un volumen menor de protocolos de enlace SSL y conexiones TCP. Estas mejoras de rendimiento se aplican aunque se reenvíen las solicitudes a la aplicación web como HTTPS, debido al alto nivel de reutilización de la conexión.
Azure Search
Azure Search quita la sobrecarga que supone realizar búsquedas de datos complejos desde el almacén de datos principal, y puede escalarse para administrar la carga. Consulte Escalado de niveles de recursos para cargas de trabajo de indexación y consulta en Azure Search.
Excelencia operativa
La excelencia operativa hace referencia a los procesos de operaciones que implementan una aplicación y lo mantienen en ejecución en producción, y es una extensión de la guía Fiabilidad del Marco de buena arquitectura. Esta guía proporciona información general detallada sobre la arquitectura de la resistencia en el marco de trabajo de la aplicación para asegurarse de que las cargas de trabajo están disponibles y pueden recuperarse de errores a cualquier escala. Un principio básico de este enfoque es diseñar la infraestructura de la aplicación para que sea de alta disponibilidad, óptimamente en varias regiones geográficas, tal como se muestra en este diseño.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Arvind Boggaram Pandurangaiah Setty | Consultor sénior
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.
Pasos siguientes
Profundización en Azure Front Door - métodos de enrutamiento de tráfico
Creación de sondeos de estado que informen del estado general de la aplicación en función de los patrones de supervisión de puntos de conexión
Habilitación de grupos de conmutación por error automática de Azure SQL
Recursos relacionados
La aplicación de n niveles de varias regiones es un escenario similar. Muestra una aplicación de n niveles que se ejecuta en varias regiones de Azure