Arquitectura de línea base crítica en Azure
Esta arquitectura proporciona instrucciones para diseñar una carga de trabajo crítica en Azure. Usa funcionalidades nativas de nube para maximizar la confiabilidad y la eficacia operativa. Aplica la metodología de diseño para cargas de trabajo críticas bien diseñadas a una aplicación accesible desde Internet, en la que se accede a la carga de trabajo a través de un punto de conexión público y que no requiere conectividad de red privada a otros recursos de la empresa.
Importante
 La guía está respaldada por una implementación de ejemplo de nivel de producción que muestra el desarrollo de aplicaciones críticas en Azure. Esta implementación se puede usar como base para el desarrollo de soluciones adicionales en el primer paso hacia la producción.
La guía está respaldada por una implementación de ejemplo de nivel de producción que muestra el desarrollo de aplicaciones críticas en Azure. Esta implementación se puede usar como base para el desarrollo de soluciones adicionales en el primer paso hacia la producción.
Nivel de confiabilidad
La confiabilidad es un concepto relativo y, para que una carga de trabajo sea adecuadamente confiable, debe reflejar los requisitos empresariales que la rodean, incluidos los objetivos de nivel de servicio (SLO) y los Acuerdos de Nivel de Servicio (SLA) para capturar el porcentaje de tiempo que la aplicación debe estar disponible.
Esta arquitectura tiene como objetivo un SLO del 99,99 %, lo que corresponde a un tiempo de inactividad anual permitido de 52 minutos y 35 segundos. Por lo tanto, todas las decisiones de diseño englobadas están pensadas para lograr este objetivo de SLO.
Sugerencia
Para definir un SLO realista, es importante comprender los objetivos de confiabilidad de todos los componentes de Azure y otros factores dentro del ámbito de la arquitectura. Para obtener más información, consulte Recomendaciones para definir objetivos de confiabilidad. Estos números individuales deben agregarse para determinar un SLO compuesto que debe estar alineado con los destinos de carga de trabajo.
Consulte Cargas de trabajo críticas diseñadas correctamente: Diseño para requisitos empresariales.
Estrategias de diseño principales
Hay muchos factores que pueden afectar a la confiabilidad de una aplicación, como la capacidad de recuperarse de errores, la disponibilidad regional, la eficacia de la implementación y la seguridad. Esta arquitectura aplica un conjunto de estrategias de diseño generales diseñadas para abordar estos factores y garantizar que se logre el nivel de confiabilidad deseado.
Redundancia en capas
Implementa en varias regiones en un modelo activo-activo. La aplicación se distribuye entre dos o más regiones de Azure que controlan el tráfico de usuario activo.
Usa zonas de disponibilidad para todos los servicios considerados para maximizar la disponibilidad dentro de una sola región de Azure, distribuyendo los componentes entre centros de datos físicamente independientes dentro de una región.
Elige los recursos que admiten la distribución global.
Consulte Cargas de trabajo críticas diseñadas correctamente: Distribución global.
Sellos de implementación
Implementa un sello regional como una unidad de escalado en la que un conjunto lógico de recursos se pueda aprovisionar de forma independiente para mantenerse al día con los cambios en la demanda. Cada sello también aplica varias unidades de escalado anidadas, como las API de front-end y los procesadores en segundo plano que se pueden reducir y escalar horizontalmente de forma independiente.
Consulte Cargas de trabajo críticas diseñadas correctamente: Arquitectura de unidad de escalado.
Implementaciones confiables y repetibles
Aplique el principio de infraestructura como código (IaC) al usar tecnologías como Terraform, ya que proporcionará un control de versiones y un enfoque operativo estandarizado para los componentes de infraestructura.
Implementa canalizaciones de implementación azul/verde sin tiempo de inactividad. Las canalizaciones de compilación y versión deben estar totalmente automatizadas para implementar los sellos como una única unidad de operaciones, mediante implementaciones azules/verdes con validación continua aplicada.
Aplica la coherencia del entorno en todos los entornos considerados con el mismo código de canalización de implementación en entornos de producción y de preproducción. Esto elimina los riesgos asociados a las variaciones de implementación y proceso entre entornos.
Dispón de una validación continua mediante la integración de pruebas automatizadas como parte de los procesos de DevOps, incluidas las pruebas de carga y caos sincronizadas, para validar completamente el estado tanto del código de la aplicación como de la infraestructura subyacente.
Consulte Cargas de trabajo críticas diseñadas correctamente: Implementación y pruebas.
Operational Insights
Dispón de áreas de trabajo federadas para datos de observabilidad. Los datos de supervisión de los recursos globales y regionales se almacenan de forma independiente. No se recomienda un almacén de observabilidad centralizado para evitar un único punto de error. Las consultas entre áreas de trabajo se usan para lograr un receptor de datos unificado y un único panel de cristal para las operaciones.
Construye un modelo de estado por capas que asigne el estado de la aplicación a un modelo de semáforo para la contextualización. Las puntuaciones de estado se calculan para cada uno de los componentes y luego se agregan a nivel de flujo de usuario y se combinan con requisitos clave no funcionales, como el rendimiento, como coeficientes para cuantificar el estado de la aplicación.
Consulte Cargas de trabajo críticas diseñadas correctamente: Modelado de estado.
Arquitectura

*Descargue un archivo de Visio de esta arquitectura.
Los componentes de esta arquitectura se pueden clasificar ampliamente de esta manera. Para obtener documentación del producto sobre los servicios de Azure, consulte Recursos relacionados.
Recursos globales
Los recursos globales son de larga duración y comparten la duración del sistema. Tienen la capacidad de estar disponibles globalmente en el contexto de un modelo de implementación de varias regiones.
Estas son las consideraciones de alto nivel sobre los componentes. Para obtener información detallada sobre las decisiones, consulte Recursos globales.
Equilibrador de carga global
Un equilibrador de carga global es fundamental para enrutar el tráfico de forma confiable a las implementaciones regionales con cierto nivel de garantía en función de la disponibilidad de los servicios back-end de una región. Además, este componente debe tener la capacidad de inspeccionar el tráfico de entrada, por ejemplo, a través del firewall de aplicaciones web.
Azure Front Door se usa como punto de entrada global para todo el tráfico HTTP(S) entrante de cliente, con funcionalidades de Web Application Firewall (WAF) aplicadas para garantizar el tráfico de entrada de Capa 7. Usa TCP Anycast para optimizar el enrutamiento mediante la red troncal de Microsoft y permite la conmutación por error transparente en caso de que se haya degradado el estado regional. El enrutamiento depende de sondeos de estado personalizados que comprueban el estado compuesto de los recursos regionales clave. Azure Front Door también proporciona una red de entrega de contenido (CDN) integrada para almacenar en caché los recursos estáticos del componente del sitio web.
Otra opción es Traffic Manager, que es un equilibrador de carga de Capa 4 basado en DNS. Sin embargo, el error no es transparente para todos los clientes, ya que debe producirse la propagación de DNS.
Consulte Cargas de trabajo críticas diseñadas correctamente: Enrutamiento del tráfico global.
Base de datos
Todo el estado relacionado con la carga de trabajo se almacena en una base de datos externa, Azure Cosmos DB for NoSQL. Esta opción se ha elegido porque tiene el conjunto de características necesarias para el ajuste del rendimiento y la confiabilidad, tanto en el lado del cliente como del servidor. Se recomienda encarecidamente que la cuenta tenga habilitada la escritura de arquitectura multimaestro.
Nota
Mientras que una configuración de escritura en varias regiones es la regla oro para la confiabilidad, existe una contrapartida importante en cuanto al costo que se debe tener en cuenta.
La cuenta se replica en cada sello regional y también tiene habilitada la redundancia de zona. Además, el escalado automático se habilita en el nivel de contenedor para que los contenedores escalen automáticamente el rendimiento aprovisionado según sea necesario.
Para obtener más información, consulte Plataforma de datos para cargas de trabajo críticas.
Registro de contenedor
Azure Container Registry se usa para almacenar todas las imágenes de contenedor. Tiene funcionalidades de replicación geográfica que permiten que los recursos funcionen como un registro único, sirviendo a varias regiones con registros regionales de arquitectura multimaestro.
Como medida de seguridad, solo permite el acceso a las entidades necesarias y autentica ese acceso. Por ejemplo, en la implementación, el acceso de administrador está deshabilitado. Por lo tanto, el clúster de proceso solo puede extraer imágenes con asignaciones de roles de Microsoft Entra.
Consulte Cargas de trabajo críticas diseñadas correctamente: Registro de contenedor.
Recursos regionales
Los recursos regionales se aprovisionan como parte de un sello de implementación en una sola región de Azure. Estos recursos no comparten nada con los recursos de otra región. Se pueden quitar o replicar de forma independiente en regiones adicionales. Sin embargo, comparten recursos globales entre sí.
En esta arquitectura, una canalización de implementación unificada implementa un sello con estos recursos.
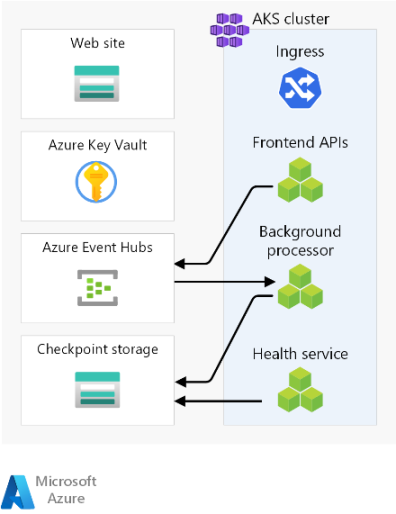
Estas son las consideraciones de alto nivel sobre los componentes. Para obtener información detallada sobre las decisiones, consulte Recursos de unidades de escalado regionales.
Front-end
Esta arquitectura usa una aplicación de página única (SPA) que envía solicitudes a los servicios de back-end. Una ventaja es que el proceso necesario para la experiencia del sitio web se descarga en el cliente en lugar de en los servidores. La SPA se hospeda como un sitio web estático en una cuenta de Azure Storage.
Normalmente, el contenido estático se almacena en caché en un almacén cercano al cliente mediante una red de entrega de contenido (CDN), de modo que los datos se puedan servir rápidamente sin comunicarse directamente con los servidores backend. Es una manera rentable de aumentar la confiabilidad y reducir la latencia de red. En esta arquitectura, las funcionalidades de CDN integradas de Azure Front Door se usan para almacenar en caché el contenido del sitio web estático en la red perimetral.
Clúster de proceso
El proceso de back-end ejecuta una aplicación compuesta de tres microservicios y sin estado. Por lo tanto, la contenedorización es una estrategia adecuada para hospedar la aplicación. Se ha elegido Azure Kubernetes Service (AKS) porque cumple con la mayoría de los requisitos empresariales y Kubernetes está adoptado ampliamente en muchos sectores. AKS admite topologías avanzadas de escalabilidad e implementación. El nivel de Acuerdo de Nivel de Servicio de tiempo de actividad de AKS es muy recomendable para hospedar aplicaciones críticas, ya que proporciona garantías de disponibilidad para el plano de control de Kubernetes.
Azure ofrece otros servicios de proceso, como Azure Functions y Azure App Services. Esas opciones descargan responsabilidades de administración adicionales en Azure a costa de la flexibilidad y la densidad.
Nota
Evita almacenar el estado en el clúster de proceso, teniendo en cuenta la naturaleza efímera de los sellos. En la medida de lo posible, conserve el estado en una base de datos externa para mantener ligeras las operaciones de escalado y recuperación. Por ejemplo, en AKS, los pods cambian con frecuencia. La asociación del estado a los pods agregará la carga de la coherencia de los datos.
Consulte Cargas de trabajo críticas diseñadas correctamente: Orquestación de contenedores y Kubernetes.
Agente de mensajes regional
Para optimizar el rendimiento y mantener la capacidad de respuesta durante la carga máxima, el diseño usa mensajería asincrónica para controlar los flujos de sistema intensivos. Como una solicitud se confirma rápidamente en las API de front-end, la solicitud también se pone en cola en un agente de mensajes. Estos mensajes los consume posteriormente un servicio de back-end que, por ejemplo, controla una operación de escritura en una base de datos.
El sello completo no tiene estado, excepto en determinados puntos, como este agente de mensajes. Los datos se ponen en cola en el agente durante un breve período de tiempo. El agente de mensajes debe garantizar al menos una entrega. Esto significa que si el agente deja de estar disponible, los mensajes estarán en la cola después de restaurar el servicio. Sin embargo, es responsabilidad del consumidor determinar si esos mensajes siguen necesitando procesamiento. La cola se purga después de procesar y almacenar el mensaje en una base de datos global.
En este diseño, se usa Azure Event Hubs. Se aprovisiona una cuenta de Azure Storage adicional para la creación de puntos de control. Event Hubs es la opción recomendada para casos de uso que requieren un alto rendimiento, como el streaming de eventos.
En los casos de uso que requieren garantías de mensajes adicionales, se recomienda Azure Service Bus. Permite confirmaciones en dos fases con un cursor del lado cliente, así como características como una cola de mensajes fallidos integrada y funcionalidades de desduplicación.
Para obtener más información, consulte Servicios de mensajería para cargas de trabajo críticas.
Almacén de secretos regionales
Cada sello tiene su propio Azure Key Vault que almacena secretos y configuración. Hay secretos comunes, como cadenas de conexión a la base de datos global, pero también hay información única para un solo sello, como la cadena de conexión de Event Hubs. Además, los recursos independientes evitan un único punto de error.
Consulte Cargas de trabajo críticas diseñadas correctamente: Protección de la integridad de datos.
Canalización de implementación
Las canalizaciones de compilación y versión para una aplicación crítica deben estar totalmente automatizadas. Por lo tanto, no es necesario realizar ninguna acción manualmente. Este diseño muestra canalizaciones totalmente automatizadas que implementan un sello validado de forma coherente cada vez. Otro enfoque alternativo consiste en implementar solo actualizaciones continuas en un sello existente.
Repositorio de código fuente
GitHub se usa para el control de código fuente, lo que proporciona una plataforma de alta disponibilidad basada en Git para la colaboración en el código de la aplicación y el código de la infraestructura.
Canalizaciones de integración continua o entrega continua (CI/CD)
Las canalizaciones automatizadas son necesarias para compilar, probar e implementar una carga de trabajo de misión en entornos de preproducción y producción. Se elige Azure Pipelines por su rico conjunto de herramientas que pueden dirigirse a Azure y a otras plataformas en la nube.
Otra opción es Acciones de GitHub para canalizaciones de CI/CD. La ventaja añadida es que el código fuente y la canalización se pueden colocar. Sin embargo, se eligió Azure Pipelines por sus mayores funcionalidades de CD.
Consulte Cargas de trabajo críticas diseñadas correctamente: Procesos de DevOps.
Agentes de compilación
Esta implementación usa agentes de compilación hospedados por Microsoft para reducir la complejidad y la sobrecarga de administración. Los agentes autohospedados se pueden usar para escenarios que requieren una posición de seguridad protegida.
Nota
El uso de agentes autohospedados se muestra en la implementación de referencia Misión crítica - Conectada.
Recursos de observabilidad
Los datos operativos de la aplicación y la infraestructura deben estar disponibles para permitir operaciones eficaces y maximizar la confiabilidad. Esta referencia proporciona una línea de base para lograr la observabilidad holística de una aplicación.
Receptor de datos unificado
- Azure Log Analytics se usa como receptor unificado para almacenar registros y métricas para todos los componentes de la aplicación y la infraestructura.
- Azure Application Insights se usa como herramienta de administración de rendimiento de aplicaciones (APM) para recopilar todos los datos de supervisión de aplicaciones y almacenarlos directamente en Log Analytics.

Los datos de supervisión de los recursos globales y regionales se deben almacenar de forma independiente. No se recomienda un almacén de observabilidad único y centralizado para evitar un único punto de error. Las consultas entre áreas de trabajo se usan para lograr un único panel de cristal.
En esta arquitectura, la supervisión de recursos dentro de una región debe ser independiente del propio sello, ya que si se anula un sello, se quiere seguir conservando la observabilidad. Cada sello regional tiene su propia área de trabajo dedicada a Application Insights y Log Analytics. Los recursos se aprovisionan por región, pero dependen de los sellos.
De forma similar, los datos de servicios compartidos, como Azure Front Door, Azure Cosmos DB y Container Registry, se almacenan en una instancia dedicada del área de trabajo de Log Analytics.
Archivado y análisis de datos
Los datos operativos que no son necesarios para las operaciones activas se exportan desde Log Analytics a las cuentas de Azure Storage tanto para fines de retención de datos como para proporcionar un origen analítico para AIOps, que puede aplicarse para optimizar el modelo de estado de la aplicación y los procedimientos operativos.
Flujos de solicitud y procesador
En esta imagen se muestra el flujo del procesador de solicitudes y de fondo de la implementación de referencia.

La descripción de este flujo se encuentra en las secciones siguientes.
Flujo de solicitudes del sitio web
Se envía una solicitud de la interfaz de usuario web a un equilibrador de carga global. Para esta arquitectura, el equilibrador de carga global es Azure Front Door.
Se evalúan las reglas de WAF. Las reglas de WAF afectan positivamente a la confiabilidad del sistema protegiendo contra diversos ataques, como el scripting entre sitios (XSS) y la inyección de SQL. Azure Front Door devolverá un error al solicitante si se infringe una regla waf y se detiene el procesamiento. Si no se infringe ninguna regla de WAF, Azure Front Door continúa el procesamiento.
Azure Front Door usa reglas de enrutamiento para determinar a qué grupo de back-end reenviar una solicitud. Cómo se hacen coincidir las solicitudes con una regla de enrutamiento. En esta implementación de referencia, las reglas de enrutamiento permiten a Azure Front Door enrutar las solicitudes de la interfaz de usuario y de la API de front-end a distintos recursos de back-end. En este caso, el patrón "/*" coincide con la regla de enrutamiento de la interfaz de usuario. Esta regla enruta la solicitud a un grupo de back-end que contiene cuentas de almacenamiento con sitios web estáticos que hospedan la aplicación de página única (SPA). Azure Front Door usa la prioridad y el peso asignados a los back-end del grupo para seleccionar el back-end para enrutar la solicitud. Métodos de enrutamiento del tráfico en el origen. Azure Front Door usa sondeos de estado para garantizar que las solicitudes no se enrutan a los back-end que no son correctos. La SPA se sirve desde la cuenta de almacenamiento seleccionada con el sitio web estático.
Nota
Los términos grupos de back-end y back-end en Azure Front Door Classic se denominan grupos de origen y orígenes en los niveles Estándar o Premium de Azure Front.
La SPA realiza una llamada API al host de front-end de Azure Front Door. El patrón de la dirección URL de solicitud de la API es "/api/*".
Flujo de solicitudes de API de front-end
Las reglas de WAF se evalúan como en el paso 2.
Azure Front Door hace coincidir la solicitud con la regla de enrutamiento de la API mediante el patrón "/api/*". La regla de enrutamiento de la API enruta la solicitud a un grupo de back-end que contiene las direcciones IP públicas de los controladores de entrada NGINX que saben cómo enrutar las solicitudes al servicio correcto en Azure Kubernetes Service (AKS). Al igual que antes, Azure Front Door usa la prioridad y el peso asignados a los back-end para seleccionar el back-end correcto del controlador de entrada NGINX.
En el caso de las solicitudes GET, la API de front-end realiza operaciones de lectura en una base de datos. Para esta implementación de referencia, la base de datos es una instancia global de Azure Cosmos DB. Azure Cosmos DB tiene varias características que lo convierten en una buena opción para una carga de trabajo crítica, incluida la capacidad de configurar fácilmente regiones de multiescritura, lo que permite la conmutación automática por error para lecturas y escrituras en regiones secundarias. La API usa el SDK del cliente configurado con lógica de reintento para comunicarse con Azure Cosmos DB. El SDK determina el orden óptimo de las regiones de Azure Cosmos DB disponibles con las que comunicarse en función del parámetro ApplicationRegion.
En el caso de las solicitudes POST o PUT, la API de front-end realiza escrituras en un agente de mensajes. En la implementación de referencia, el agente de mensajes es Azure Event Hubs. También puede elegir Service Bus. Un controlador leerá más adelante los mensajes del agente de mensajes y realizará las escrituras necesarias en Azure Cosmos DB. La API usa el SDK del cliente para realizar escrituras. El cliente puede ser configurado para realizar reintentos.
Flujo de procesador en segundo plano
Los procesadores en segundo plano procesan los mensajes del agente de mensajes. Los procesadores en segundo plano usan el SDK de cliente para realizar lecturas. El cliente puede ser configurado para realizar reintentos.
Los procesadores en segundo plano realizan las operaciones de escritura adecuadas en la instancia global de Azure Cosmos DB. Los procesadores en segundo plano usan el SDK del cliente configurado con reintento para conectarse a Azure Cosmos DB. La lista de regiones preferidas del cliente podría configurarse con varias regiones. En ese caso, si se produce un error en una escritura, el reintento se realizará en la siguiente región preferida.
Área de diseño
Se recomienda que explore estas áreas de diseño para obtener recomendaciones e instrucciones sobre procedimientos recomendados al definir su arquitectura crítica.
| Área de diseño | Descripción |
|---|---|
| Diseño de aplicación | Patrones de diseño que permiten el escalado y el control de errores. |
| Plataforma de aplicaciones | Opciones de infraestructura y mitigaciones para posibles casos de error. |
| Plataforma de datos | Opciones de tecnologías de almacén de datos, informadas mediante la evaluación de las características requeridas de volumen, velocidad, variedad y veracidad. |
| Redes y conectividad | Consideraciones de red para enrutar el tráfico entrante a los sellos. |
| Modelado de estado | Consideraciones de observabilidad a través de un análisis del impacto en el cliente correlacionado con la supervisión para determinar el estado general de la aplicación. |
| Implementación y pruebas | Estrategias para las canalizaciones de CI/CD y consideraciones de automatización, con escenarios de prueba incorporados, como pruebas de carga sincronizadas y pruebas de inyección de errores (caos). |
| Seguridad | Mitigación de vectores de ataque a través del modelo de Confianza cero de Microsoft. |
| Procedimientos operativos | Procesos relacionados con la implementación, la administración de claves, la aplicación de revisiones y las actualizaciones. |
** Indica las consideraciones sobre el área de diseño específicas de esta arquitectura.
Recursos relacionados
Para obtener documentación del producto sobre los servicios de Azure usados en esta arquitectura, consulte estos artículos.
- Puerta de entrada de Azure
- Azure Cosmos DB
- Azure Container Registry
- Azure Log Analytics
- Azure Key Vault
- Azure Service Bus
- Azure Kubernetes Service
- Azure Application Insights
- Azure Event Hubs
- Azure Blob Storage
Implementación de esta arquitectura
Despliega la implementación de referencia para comprender completamente los recursos considerados, incluida la forma en que se operacionalizan en un contexto crítico. Contiene una guía de implementación que se ha diseñado para ilustrar un enfoque orientado a la solución para el desarrollo de aplicaciones críticas en Azure.
Pasos siguientes
Si quiere ampliar la arquitectura de línea base con controles de red en el tráfico de entrada y salida, consulte esta arquitectura.